Datagestuurde organisaties behandelen data als een asset en gebruiken deze in verschillende branches (LOB's) om tijdig inzicht te krijgen en betere zakelijke beslissingen te nemen. Veel organisaties hebben gedistribueerde tools en infrastructuur over verschillende business units. Dit leidt tot het hebben van gegevens over veel instanties van datawarehouses en datalakes met behulp van een moderne data-architectuur in afzonderlijke AWS-accounts.
Amazon roodverschuiving het delen van gegevens stelt u in staat om veilig live, transactieconsistente gegevens in één te delen Amazon roodverschuiving datawarehouse met een ander Redshift-datawarehouse binnen hetzelfde AWS-account, tussen accounts en tussen regio's, zonder dat gegevens van het ene cluster naar het andere hoeven te worden gekopieerd of verplaatst. Klanten willen hun machtigingen op een centrale plek voor al hun bedrijfsmiddelen kunnen beheren. Voorheen was het beheer van Redshift-datashares beperkt tot alleen binnen Amazon Redshift, wat het moeilijk maakte om uw data lake-machtigingen en Amazon Redshift-machtigingen op één plek te beheren. U moest bijvoorbeeld naar een individueel account navigeren om toegangsinformatie voor Amazon Redshift en het datameer op te bekijken en te beheren Amazon eenvoudige opslagservice (Amazone S3). Naarmate een organisatie groeit, willen beheerders een mechanisme om het delen van gegevens tussen datalakes en datawarehouses effectief en centraal te beheren voor governance en auditing, en om fijnmazige toegangscontrole af te dwingen.
We hebben onlangs de integratie aangekondigd van het delen van gegevens met Amazon Redshift AWS Lake-formatie. Met deze functie kunnen klanten van Amazon Redshift nu het delen beheren, toegangsbeleid centraal toepassen en de toestemming effectief schalen met behulp van LF-Tags.
Lake Formation is een populaire keuze geweest voor het centraal besturen van datameren die worden ondersteund door Amazon S3. Nu, met Lake Formation-ondersteuning voor het delen van Amazon Redshift-gegevens, opent het nieuwe ontwerppatronen en verbreedt het beheer en de beveiligingspostuur in datawarehouses. Met deze integratie kunt u Lake Formation gebruiken om fijnmazige toegangscontrole te definiëren voor tabellen en weergaven die worden gedeeld met Amazon Redshift voor het delen van gegevens voor federatieve AWS Identiteits- en toegangsbeheer (IAM) gebruikers en IAM rollen. Lake Formation biedt ook op tags gebaseerde toegangscontrole (TBAC), die kan worden gebruikt om het beheer van gegevenscatalogusobjecten, zoals databases en tabellen, te vereenvoudigen en te schalen.
In dit bericht bespreken we deze nieuwe functie en hoe u TBAC implementeert voor uw datameer en Amazon Redshift-gegevensuitwisseling op Lake Formation.
Overzicht oplossingen
Toegangscontrole op basis van Lake Formation-tags (LF-TBAC) stelt u in staat om vergelijkbare groepen te groeperen AWS lijm Data Catalog-resources samen en definieer het beleid voor het toekennen of intrekken van machtigingen met behulp van een LF-Tag-expressie. LF-Tags zijn hiërarchisch in die zin dat wanneer een database is getagd met een LF-Tag, alle tabellen in die database de tag overnemen, en wanneer een LF-Tag wordt toegepast op een tabel, erven alle kolommen in die tabel de tag. Overgeërfde tags kunnen vervolgens indien nodig worden overschreven. Vervolgens kunt u toegangsbeleid maken binnen Lake Formation met behulp van LF-Tag-expressies om principals toegang te verlenen tot getagde bronnen met behulp van een LF-Tag-expressie. Zien Beheer van LF-Tags voor toegangscontrole metadata voor meer details.
Om LF-TBAC met centrale beheermogelijkheden voor gegevenstoegang te demonstreren, gebruiken we het scenario waarin twee afzonderlijke bedrijfseenheden bepaalde datasets bezitten en gegevens tussen teams moeten delen.
We hebben een klantenserviceteam dat de klanteninformatiedatabase beheert en bezit, inclusief demografische klantgegevens. En een marketingteam hebben dat eigenaar is van een dataset met klantleads, die informatie bevat over potentiële klanten en contactleads.
Om effectieve campagnes te kunnen voeren, heeft het marketingteam toegang nodig tot de klantgegevens. In dit bericht demonstreren we het proces van het delen van deze gegevens die zijn opgeslagen in het datawarehouse en het geven van toegang aan het marketingteam. Bovendien zijn er kolommen met persoonlijk identificeerbare informatie (PII) binnen de klantdataset die alleen toegankelijk mogen zijn voor een subset van hoofdgebruikers op een 'need-to-know'-basis. Op deze manier kunnen data-analisten binnen marketing alleen niet-PII-kolommen zien om anonieme klantsegmentanalyses uit te voeren, maar heeft een groep hoofdgebruikers toegang tot PII-kolommen (bijvoorbeeld het e-mailadres van de klant) om campagnes of enquêtes voor specifieke groepen klanten uit te voeren.
Het volgende diagram toont de structuur van de datasets waarmee we in dit bericht werken en een tagstrategie om fijnmazige toegang op kolomniveau te bieden.

Naast onze tagstrategie voor de gegevensbronnen, geeft de volgende tabel een overzicht van hoe we via tags toestemming moeten verlenen aan onze twee persona's.
| IAM-rol | Persona | Type bron | Toestemming | LF-Tag-expressie |
| marketing-analist | Een data-analist in het marketingteam | DB | beschrijven | (afdeling:marketing OF afdeling:klant) EN classificatie:privé |
| . | tafel | kiezen | (afdeling:marketing OF afdeling:klant) EN classificatie:privé | |
| . | . | . | . | . |
| marketing-poweruser | Een bevoorrechte gebruiker in het marketingteam | DB | beschrijven | (afdeling:marketing OF afdeling:klant) EN classificatie: privé |
| . | Tabel (kolom) | kiezen | (afdeling:marketing OF afdeling:klant) EN (classificatie:privé OF classificatie:pii-gevoelig) |
Het volgende diagram geeft een overzicht op hoog niveau van de instellingen die we in dit bericht implementeren.

Het volgende is een overzicht op hoog niveau van het gebruik van Lake Formation om machtigingen voor datashares te beheren:
Opstelling producent:
- In het AWS-account van de producent maakt de Amazon Redshift-beheerder die eigenaar is van de klantendatabase een Redshift-datashare op het producentencluster en verleent hij gebruik aan de AWS Glue-gegevenscatalogus in hetzelfde account.
- De beheerder van het producentencluster autoriseert het Lake Formation-account voor toegang tot de datashare.
- In Lake Formation ontdekt en registreert de Lake Formation-beheerder de datashares. Ze moeten de AWS Glue ARN's ontdekken waartoe ze toegang hebben en de datashares koppelen aan een AWS Glue Data Catalog ARN. Als je de AWS-opdrachtregelinterface (AWS CLI), kunt u datashares ontdekken en accepteren met de Redshift CLI-bewerkingen description-data-shares en associate-data-share-consumer. Gebruik de Lake Formation CLI-bewerkingsregisterresource om een datashare te registreren.
- De beheerder van Lake Formation maakt een gefedereerde database in de AWS Glue Data Catalog; wijst tags toe aan de databases, tabellen en kolommen; en configureert Lake Formation-machtigingen om gebruikerstoegang tot objecten binnen de datashare te regelen. Zie voor meer informatie over gefedereerde databases in AWS Glue Machtigingen beheren voor gegevens in een Amazon Redshift-datashare.
Consumentenconfiguratie:
- Aan de kant van de consument (marketing) ontdekt de Amazon Redshift-beheerder de AWS Glue-database-ARN's waartoe ze toegang hebben, maakt een externe database in het Redshift-consumentencluster met behulp van een AWS Glue-database-ARN en verleent gebruik aan databasegebruikers geverifieerd met IAM-referenties om te beginnen met het doorzoeken van de Redshift-database.
- Databasegebruikers kunnen de views gebruiken
SVV_EXTERNAL_TABLESenSVV_EXTERNAL_COLUMNSom alle tabellen of kolommen in de AWS Glue-database te vinden waartoe ze toegang hebben; dan kunnen ze de tabellen van de AWS Glue-database opvragen.
Wanneer de beheerder van het producentencluster besluit om de gegevens niet langer te delen met het consumentencluster, kan de beheerder van het producentencluster het gebruik intrekken, de autorisatie intrekken of de datashare van Amazon Redshift verwijderen. De bijbehorende machtigingen en objecten in Lake Formation worden niet automatisch verwijderd.
Vereisten:
Om de stappen in dit bericht te volgen, moet u aan de volgende voorwaarden voldoen:
Implementeer omgeving inclusief Redshift-clusters voor producenten en consumenten
Implementeer het volgende om de stappen in dit bericht te volgen AWS CloudFormatie stapel die de nodige bronnen bevat om het onderwerp van dit bericht te demonstreren:
- Kies Start stapel om een CloudFormation-sjabloon te implementeren.

- Geef een IAM-rol op die u al hebt geconfigureerd als Lake Formation-beheerder.
- Voltooi de stappen om de sjabloon te implementeren en alle instellingen op standaard te laten staan.
- kies Ik erken dat AWS CloudFormation IAM-bronnen kan creëren, kies dan Verzenden.

Deze CloudFormation-stack creëert de volgende bronnen:
- Producent Redshift-cluster – Eigendom van het klantenserviceteam en bevat klant- en demografische gegevens.
- Consumenten Redshift-cluster – Eigendom van het marketingteam en wordt gebruikt om gegevens te analyseren in datawarehouses en datameren.
- S3 datameer – Bevat de datasets voor webactiviteit en leads.
- Andere noodzakelijke bronnen om het proces van het delen van gegevens te demonstreren – Bijvoorbeeld IAM-rollen, Lake Formation-configuratie en meer. Bekijk de CloudFormation-sjabloon voor een volledige lijst met bronnen die door de stapel zijn gemaakt.
Nadat u deze CloudFormation-sjabloon hebt geïmplementeerd, zullen de gemaakte resources kosten met zich meebrengen voor uw AWS-account. Zorg er aan het einde van het proces voor dat u bronnen opruimt om onnodige kosten te voorkomen.
Nadat de CloudFormation-stack met succes is geïmplementeerd (status wordt weergegeven als CREATE_COMPLETE), let op de volgende punten op de Uitgangen tab:
- Rol van marketinganalist ARN
- Rol van marketinghoofdgebruiker ARN
- URL voor Amazon Redshift-beheerderswachtwoord opgeslagen in AWS-geheimenmanager

Maak een Redshift-datashare en voeg relevante tabellen toe
Op de AWS-beheerconsole, overstappen naar de rol die u hebt genomineerd als Lake Formation-beheerder bij het implementeren van de CloudFormation-sjabloon. Ga dan naar Query-editor v2. Als dit de eerste keer is dat u Query Editor V2 in uw account gebruikt, volgt u deze stappen om configureer uw AWS-account.
De eerste stap in Query Editor is om in te loggen op het Redshift-cluster van de klant met behulp van de referenties van de databasebeheerder om van uw IAM-beheerdersrol een DB-beheerder voor de database te maken.
- Kies het optiemenu (drie puntjes) naast de
lfunified-customer-dwh clusterEn kies Creëer verbinding.
- kies Database gebruikersnaam en wachtwoord.
- Verlof Database as
dev. - Voor gebruikersnaam, ga naar binnen
admin. - Voor Wachtwoord, voert u de volgende stappen uit:
- Ga naar de console-URL, dit is de waarde van het
RedShiftClusterPasswordCloudFormation-uitvoer in de vorige stap. De URL is de Secrets Manager-console voor dit wachtwoord. - Blader omlaag naar de Geheime waarde sectie en kies Haal geheime waarde op.

- Noteer het wachtwoord dat u later wilt gebruiken wanneer u verbinding maakt met de marketing Redshift-cluster.
- Vul deze waarde in voor Wachtwoord.
- Ga naar de console-URL, dit is de waarde van het
- Kies Verbinding maken.

Maak een datashare met behulp van een SQL-opdracht
Voer de volgende stappen uit om een datashare te maken in het dataproducentcluster (klantenservice) en deze te delen met Lake Formation:
- Kies op de Amazon Redshift-console in het navigatievenster editordan Query-editor V2.
- Kies (klik met de rechtermuisknop) de clusternaam en kies Bewerk verbinding or Verbinding maken.
- Voor authenticatieselecteer Tijdelijke inloggegevens met uw IAM-identiteit.
Verwijzen naar Verbinding maken met een Amazon Redshift-database voor meer informatie over de verschillende authenticatiemethoden.
- Voor Database, voer een databasenaam in (voor dit bericht,
dev). - Kies Verbinding maken om verbinding te maken met de database.

- Voer de volgende SQL-opdrachten uit om de datashare te maken en de te delen data-objecten toe te voegen:
- Voer de volgende SQL-opdracht uit om de datashare van de klant te delen met het huidige account via de AWS Glue Data Catalog:
- Controleer of de datashare is gemaakt en de objecten zijn gedeeld door de volgende SQL-opdracht uit te voeren:

Noteer de naamruimte en account-ID van het datashare-producercluster, die in de volgende stap worden gebruikt. U kunt de volgende acties uitvoeren op de console, maar voor de eenvoud gebruiken we AWS CLI-opdrachten.
- Ga naar CloudShell of uw AWS CLI en voer de volgende AWS CLI-opdracht uit om de datashare naar de Data Catalog te autoriseren, zodat Lake Formation ze kan beheren:
Het volgende is een voorbeelduitvoer:
Noteer uw datashare ARN die u in deze opdracht hebt gebruikt om in de volgende stappen te gebruiken.
Accepteer de datashare in de Lake Formation-catalogus
Voer de volgende stappen uit om de datashare te accepteren:
- Voer de volgende AWS CLI-opdracht uit om de Amazon Redshift-datashare te accepteren en te koppelen aan de AWS Glue Data Catalog:
Het volgende is een voorbeelduitvoer:
- Registreer de datashare in Lake Formation:
- Maak de AWS Glue-database die verwijst naar de geaccepteerde Redshift-datashare:
- Om dit te verifiëren, gaat u naar de Lake Formation-console en controleert u of de database
customer_db_sharedis gecreëerd.
Nu kan de data lake-beheerder zowel de database als de tabellen bekijken en toegang verlenen aan de persona's van het dataconsumententeam (marketing) met behulp van Lake Formation TBAC.
Wijs Lake Formation-tags toe aan bronnen
Voordat we passende toegang verlenen tot de IAM-principes van de data-analist en hoofdgebruiker binnen het marketingteam, moeten we LF-tags toewijzen aan tabellen en kolommen van de customer_db_shared databank. Vervolgens verlenen wij deze opdrachtgevers toestemming om LF-tags toe te passen.
Volg deze stappen om LF-tags toe te wijzen:
- Wijs de afdeling en classificatie LF-tag toe aan
customer_db_shared(Redshift datashare) op basis van de tagging-strategietabel in het oplossingsoverzicht. Je kunt de volgende acties uitvoeren op de console, maar voor dit bericht gebruiken we de volgende AWS CLI-opdracht:
Als de opdracht succesvol is, zou u een reactie zoals het volgende moeten krijgen:
- Ken de juiste afdeling en classificatie LF-tag toe aan
marketing_db(op het S3-datameer):
Merk op dat hoewel u de afdelings- en classificatietag alleen op databaseniveau toewijst, deze wordt overgenomen door de tabellen en kolommen in die database.
- Wijs de classificatie toe
pii-sensitiveLF-tag naar PII-kolommen van decustomertabel om de overgenomen waarde van het databaseniveau te overschrijven:
Toestemming verlenen op basis van LF-tag-associatie
Voer de volgende twee AWS CLI-opdrachten uit om de marketinggegevensanalist toegang te geven tot de klantentabel, met uitzondering van de pii-sensitive (PII) kolommen. Vervang de waarde voor DataLakePrincipalIdentifier met de MarketingAnalystRoleARN dat je hebt opgemerkt uit de uitvoer van de CloudFormation-stack:
Inmiddels hebben we marketinganalisten toegang verleend tot de klantendatabase en tabellen die dat niet zijn pii-sensitive.
Om krachtige marketinggebruikers toegang te geven tot tabelkolommen met beperkte LF-tag (PII-kolommen), voert u de volgende AWS CLI-opdracht uit:
We kunnen de toekenningen combineren in een enkele oproep voor toekenningstoestemmingen:
Valideer de oplossing
In dit gedeelte doorlopen we de stappen om het scenario te testen.
Gebruik de datashare in het datawarehouse voor consumenten (marketing).
Om de consumenten (marketingteam) toegang te geven tot de klantgegevens die met hen worden gedeeld via de datashare, moeten we eerst Query Editor v2 configureren. Deze configuratie is bedoeld om IAM-referenties te gebruiken als de principal voor de Lake Formation-machtigingen. Voer de volgende stappen uit:
- Meld u aan bij de console met de beheerdersrol die u hebt genomineerd bij het uitvoeren van de CloudFormation-sjabloonstap.
- Ga op de Amazon Redshift-console naar Query Editor v2.
- Kies het tandwielpictogram in het navigatievenster en kies vervolgens Accountinstellingen.

- Onder Verbindingsinstellingenselecteer Verifieer met IAM-referenties.
- Kies Bespaar.

Laten we nu verbinding maken met het marketing Redshift-cluster en de klantendatabase beschikbaar maken voor het marketingteam.
- Kies het optiemenu (drie puntjes) naast de
Serverless:lfunified-marketing-wgclusteren en kiezen Creëer verbinding. - kies Database gebruikersnaam en wachtwoord.
- Verlof Database as
dev. - Voor gebruikersnaam, ga naar binnen
admin. - Voor Wachtwoord, voer hetzelfde wachtwoord in dat u in een eerdere stap van Secrets Manager hebt opgehaald.
- Kies Verbinding maken.
- Eenmaal succesvol verbonden, kiest u het plusteken en kiest u editor om een nieuw tabblad Query-editor te openen.
- Zorg ervoor dat u de
Serverless: lfunified-marketing-wg workgroupendevdatabase.

- Voer de volgende SQL-opdracht uit op het nieuwe tabblad om de Redshift-database te maken op basis van de gedeelde catalogusdatabase:
- Voer de volgende SQL-opdrachten uit om gebruik van de Redshift-database te maken en toe te kennen aan de IAM-rollen voor de hoofdgebruikers en gegevensanalisten. U kunt de IAM-rolnamen ophalen uit de CloudFormation-stackuitvoer:
Maak het data lake-schema in AWS Glue en laat de marketingrol de lead- en webactiviteitsgegevens opvragen
Voer de volgende SQL-opdrachten uit om de leadgegevens in het S3-datameer beschikbaar te maken voor het marketingteam:
Voer een query uit op de gedeelde gegevensset als gebruiker van een marketinganalist
Voer de volgende stappen uit om te valideren dat de analisten van het marketingteam (IAM-rol marketing-analist-rol) toegang hebben tot de gedeelde database:
- Meld u aan bij de console (voor het gemak kunt u een andere browser gebruiken) en wissel van rol naar
lf-redshift-ds-MarketingAnalystRole-XXXXXXXXXXXX. - Ga op de Amazon Redshift-console naar Query Editor v2.
- Om verbinding te maken met het consumentencluster, kiest u de
Serverless: lfunified-marketing-wgconsumentendatawarehouse in het navigatievenster. - Wanneer daarom wordt gevraagd, voor authenticatieselecteer Federatieve gebruiker.
- Voor Database, voer de databasenaam in (voor dit bericht,
dev). - Kies Bespaar.
- Zodra u bent verbonden met de database, kunt u de huidige ingelogde gebruiker valideren met de volgende SQL-opdracht:
- Voer de volgende SQL-opdracht uit om de federatieve databases te vinden die op het consumentenaccount zijn gemaakt:
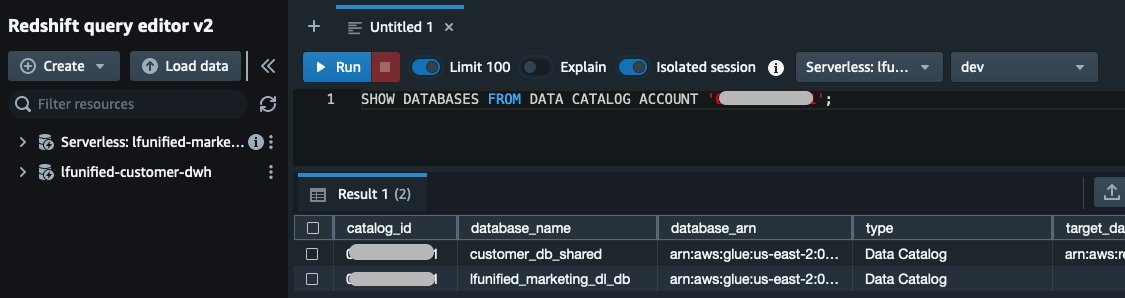
- Voer de volgende SQL-opdracht uit om machtigingen voor de rol van marketinganalist te valideren:

Zoals u in de volgende schermafbeelding kunt zien, heeft de marketinganalist met succes toegang tot de klantgegevens, maar alleen tot de niet-PII-attributen, wat onze bedoeling was.
- Laten we nu valideren dat de marketinganalist geen toegang heeft tot de PII-kolommen van dezelfde tabel:

Voer query's uit op de gedeelde datasets als een krachtige marketinggebruiker
Om te valideren dat de marketing power users (IAM-rol lf-redshift-ds-MarketingPoweruserRole-YYYYYYYYYYYY) toegang hebben tot pii-sensetive kolommen in de gedeelde database voert u de volgende stappen uit:
- Log in op de console (voor het gemak kunt u een andere browser gebruiken) en verander uw rol naar
lf-redshift-ds-MarketingPoweruserRole-YYYYYYYYYYYY. - Ga op de Amazon Redshift-console naar Query Editor v2.
- Om verbinding te maken met het consumentencluster, kiest u de
Serverless: lfunified-marketing-wgconsumentendatawarehouse in het navigatievenster. - Wanneer daarom wordt gevraagd, voor authenticatieselecteer Federatieve gebruiker.
- Voor Database, voer de databasenaam in (voor dit bericht,
dev). - Kies Bespaar.
- Zodra u bent verbonden met de database, kunt u de huidige ingelogde gebruiker valideren met de volgende SQL-opdracht:
- Laten we nu valideren dat de marketingmachtsrol toegang heeft tot de PII-kolommen van de klantentabel:

- Valideer dat de hoofdgebruikers binnen het marketingteam nu een query kunnen uitvoeren om gegevens te combineren uit verschillende datasets waartoe ze toegang hebben om effectieve campagnes uit te voeren:


Opruimen
Nadat u de stappen in dit bericht hebt voltooid, verwijdert u de CloudFormation-stack om bronnen op te ruimen:
- Selecteer op de AWS CloudFormation-console de stapel die u aan het begin van dit bericht hebt geïmplementeerd.
- Kies Verwijder en volg de aanwijzingen om de stapel te verwijderen.
Conclusie
In dit bericht hebben we laten zien hoe je Lake Formation-tags kunt gebruiken en machtigingen kunt beheren voor je data lake en het delen van Amazon Redshift-gegevens met behulp van Lake Formation. Het gebruik van Lake Formation LF-TBAC voor gegevensbeheer helpt u bij het op grote schaal beheren van uw data lake en Amazon Redshift-machtigingen voor het delen van gegevens. Het maakt ook het delen van gegevens tussen bedrijfseenheden mogelijk met fijnmazige toegangscontrole. Door de toegang tot uw data lake en Redshift-datashares op één plek te beheren, wordt een beter beheer mogelijk, wat helpt bij gegevensbeveiliging en naleving.
Als u vragen of suggesties heeft, kunt u deze indienen in het opmerkingengedeelte.
Raadpleeg voor meer informatie over het door Lake Formation beheerde Amazon Redshift-gegevens delen en op tags gebaseerde toegangscontrole Beheer toegang en machtigingen centraal voor het delen van Amazon Redshift-gegevens met AWS Lake Formation en Beheer uw data lake eenvoudig op schaal met behulp van op AWS Lake Formation Tag gebaseerde toegangscontrole.
Over de auteurs
 Praveen Kumar is een Analytics Solution Architect bij AWS met expertise in het ontwerpen, bouwen en implementeren van moderne data- en analyseplatforms met behulp van cloud-native services. Zijn interessegebieden zijn serverloze technologie, moderne datawarehouses in de cloud, streaming en ML-applicaties.
Praveen Kumar is een Analytics Solution Architect bij AWS met expertise in het ontwerpen, bouwen en implementeren van moderne data- en analyseplatforms met behulp van cloud-native services. Zijn interessegebieden zijn serverloze technologie, moderne datawarehouses in de cloud, streaming en ML-applicaties.
 Srividya Parthasarathy is een Senior Big Data Architect in het AWS Lake Formation-team. Ze vindt het leuk om data mesh-oplossingen te bouwen en deze te delen met de community.
Srividya Parthasarathy is een Senior Big Data Architect in het AWS Lake Formation-team. Ze vindt het leuk om data mesh-oplossingen te bouwen en deze te delen met de community.
 Paul Villena is een Analytics Solutions Architect in AWS met expertise in het bouwen van moderne data- en analyseoplossingen om bedrijfswaarde te vergroten. Hij werkt samen met klanten om hen te helpen de kracht van de cloud te benutten. Zijn interessegebieden zijn infrastructuur als code, serverloze technologieën en coderen in Python.
Paul Villena is een Analytics Solutions Architect in AWS met expertise in het bouwen van moderne data- en analyseoplossingen om bedrijfswaarde te vergroten. Hij werkt samen met klanten om hen te helpen de kracht van de cloud te benutten. Zijn interessegebieden zijn infrastructuur als code, serverloze technologieën en coderen in Python.
 Mostafa Safipour is een Solutions Architect bij AWS in Sydney. Hij werkt samen met klanten om bedrijfsresultaten te realiseren met behulp van technologie en AWS. In de afgelopen tien jaar heeft hij veel grote organisaties in de ANZ-regio geholpen bij het bouwen van hun data-, digitale en enterprise-workloads op AWS.
Mostafa Safipour is een Solutions Architect bij AWS in Sydney. Hij werkt samen met klanten om bedrijfsresultaten te realiseren met behulp van technologie en AWS. In de afgelopen tien jaar heeft hij veel grote organisaties in de ANZ-regio geholpen bij het bouwen van hun data-, digitale en enterprise-workloads op AWS.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/implement-tag-based-access-control-for-your-data-lake-and-amazon-redshift-data-sharing-with-aws-lake-formation/

