Dit is een gastpost die is geschreven in samenwerking met Raghu Boppanna van Vanguard.
At Voorhoede, verbetert de branche Enterprise Advice de resultaten voor investeerders door digitale toegang tot superieur, persoonlijk en betaalbaar financieel advies. Ze maakten het deels mogelijk door schaalvoordelen over de hele wereld te stimuleren voor beleggers met een zeer veerkrachtig en efficiënt technisch platform. Vanguard koos voor een architectuur met meerdere regio's voor deze werklast om te helpen beschermen tegen beperkingen van regionale diensten. Voor doeleinden met hoge beschikbaarheid is het nodig om de gegevens die door de werkbelasting worden gebruikt, niet alleen beschikbaar te maken in de primaire regio, maar ook in de secundaire regio met minimale replicatievertraging. In het geval van een servicebeperking in de primaire regio, moet de oplossing een failover kunnen uitvoeren naar de secundaire regio met zo min mogelijk gegevensverlies en de mogelijkheid om de gegevensopname te hervatten.
Vanguard Cloud Technology Office en AWS werkten samen om een infrastructuuroplossing op AWS te bouwen die voldeed aan hun veerkrachtvereisten. De oplossing voor meerdere regio's maakt een robuust failover-mechanisme mogelijk, met ingebouwde observatie en herstel. De oplossing ondersteunt ook het streamen van gegevens van meerdere bronnen naar verschillende Kinesis-gegevensstromen. De oplossing wordt momenteel uitgerold naar de verschillende bedrijfsteams om de veerkracht van hun werklast te verbeteren.
De hier besproken use case vereist Change Data Capture (CDC) om gegevens te streamen van een externe gegevensbron (mainframe DB2) naar Amazon Kinesis-gegevensstromen, omdat de zakelijke mogelijkheden van deze gegevens afhangen. Kinesis Data Streams is een volledig beheerde, enorm schaalbare, duurzame en goedkope streamingdienst die continu grote hoeveelheden gegevens uit meerdere bronnen kan vastleggen en streamen, en de gegevens binnen milliseconden beschikbaar maakt voor gebruik. De service is gebouwd om zeer veerkrachtig te zijn en gebruikt meerdere beschikbaarheidszones om gegevens te verwerken en op te slaan.
De oplossing die in dit bericht wordt besproken, legt uit hoe AWS en Vanguard innoveerden om een veerkrachtige architectuur te bouwen om aan hun doelstellingen voor hoge beschikbaarheid te voldoen.
Overzicht oplossingen
De oplossing maakt gebruik van AWS Lambda om gegevens van Kinesis-gegevensstromen in de primaire regio naar een secundaire regio te repliceren. In het geval van een servicebeperking die van invloed is op de CDC-pijplijn, promoveert het failoverproces de secundaire regio naar primair voor de producenten en consumenten. We gebruiken Amazon DynamoDB globale tabellen voor replicatiecontrolepunten waarmee gegevensstreaming vanaf het controlepunt kan worden hervat en ook een primaire regioconfiguratievlag onderhoudt die een oneindige replicatielus van dezelfde gegevens heen en weer voorkomt.
De oplossing biedt ook de flexibiliteit voor consumenten van Kinesis Data Streams om de primaire of secundaire regio binnen hetzelfde AWS-account te gebruiken.
Het volgende diagram illustreert de referentiearchitectuur.
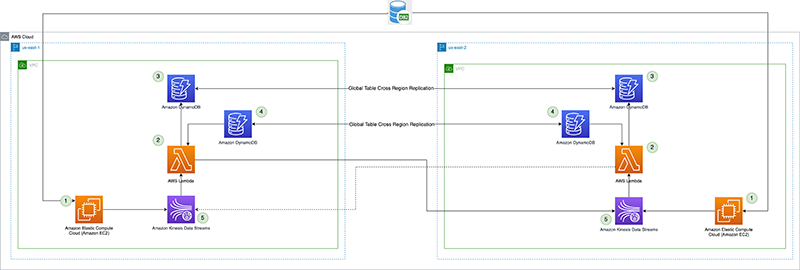
Laten we elk onderdeel in detail bekijken:
- CDC-processor (producent) – In deze referentiearchitectuur wordt de producent ingezet Amazon Elastic Compute-cloud (Amazon EC2) in zowel de primaire als de secundaire regio, en is actief in de primaire regio en in stand-bymodus in de secundaire regio. Het vangt CDC-gegevens op van de externe gegevensbron (zoals een DB2-database zoals weergegeven in de bovenstaande architectuur) en streamt naar Kinesis-gegevensstromen in de primaire regio. Vanguard gebruikt een 3rd party-tool Qlik Replicate als hun CDC-processor. Het produceert een goed gevormde payload, inclusief het DB2-commit-tijdstempel voor de Kinesis-gegevensstroom, naast de daadwerkelijke rijgegevens van de externe gegevensbron. (
example-stream-1in dit voorbeeld). De volgende code is een voorbeeld van een payload die alleen de primaire sleutel bevat van de record die is gewijzigd en het tijdstempel voor het vastleggen (voor de eenvoud wordt de rest van de tabelrijgegevens hieronder niet weergegeven):{ "eventSource": "aws:kinesis", "kinesis": { "ApproximateArrivalTimestamp": "Mon July 18 20:00:00 UTC 2022", "SequenceNumber": "49544985256907370027570885864065577703022652638596431874", "PartitionKey": "12349999", "KinesisSchemaVersion": "1.0", "Data": "eyJLZXkiOiAxMjM0OTk5OSwiQ29tbWl0VGltZXN0YW1wIjogIjIwMjItMDctMThUMjA6MDA6MDAifQ==" }, "eventId": "shardId-000000000000:49629136582982516722891309362785181370337771525377097730", "invokeIdentityArn": "arn:aws:iam::6243876582:role/kds-crr-LambdaRole-1GZWP67437SD", "eventName": "aws:kinesis:record", "eventVersion": "1.0", "eventSourceARN": "arn:aws:kinesis:us-east-1:6243876582:stream/kds-stream-1/consumer/kds-crr:6243876582", "awsRegion": "us-east-1" }De Base64 gedecodeerde waarde van
Datais als volgt. Het daadwerkelijke Kinesis-record zou de volledige rijgegevens bevatten van de tabelrij die is gewijzigd, naast de primaire sleutel en het commit-tijdstempel.{"Key": 12349999,"CommitTimestamp": "2022-07-18T20:00:00"}De
CommitTimestampin deDataveld wordt gebruikt in het replicatiecontrolepunt en is van cruciaal belang om nauwkeurig bij te houden hoeveel van de stroomgegevens zijn gerepliceerd naar de secundaire regio. Het controlepunt kan vervolgens worden gebruikt om een failover van de CDC-processor (producent) te vergemakkelijken en het produceren van gegevens nauwkeurig te hervatten vanaf het tijdstempel van het replicatiecontrolepunt.Het alternatief voor het gebruik van een externe gegevensbron
CommitTimestamp(indien niet beschikbaar) is om deApproximateArrivalTimestamp(dit is het tijdstempel wanneer het record daadwerkelijk naar de gegevensstroom wordt geschreven). - Cross-Region replicatie Lambda-functie – De functie wordt ingezet voor zowel primaire als secundaire regio's. Het is ingesteld met een toewijzing van een gebeurtenisbron aan de gegevensstroom die CDC-gegevens bevat. Dezelfde functie kan worden gebruikt om gegevens van meerdere streams te repliceren. Het wordt aangeroepen met een batch records van Kinesis Data Streams en repliceert de batch naar een doelreplicatieregio (die wordt geleverd via de Lambda-configuratieomgeving). Als de CDC-gegevens alleen actief worden geproduceerd in de primaire regio, kan uit kostenoverwegingen de gereserveerde gelijktijdigheid van de functie in de secundaire regio worden ingesteld op nul en worden gewijzigd tijdens regionale failover. De functie heeft AWS Identiteits- en toegangsbeheer (IAM) rolmachtigingen om het volgende te doen:
- Lees en schrijf naar de globale DynamoDB-tabellen die in deze oplossing worden gebruikt, binnen hetzelfde account.
- Lees en schrijf naar Kinesis-gegevensstromen in beide regio's binnen hetzelfde account.
- Publiceer aangepaste statistieken naar Amazon Cloud Watch in beide Gewesten binnen dezelfde rekening.
- Controlepunt voor replicatie – Het replicatiecontrolepunt gebruikt de algemene DynamoDB-tabel in zowel de primaire als de secundaire regio. Het wordt gebruikt door de Lambda-functie voor replicatie tussen verschillende regio's om de commit-tijdstempel van het laatste replicatierecord te behouden als het replicatiecontrolepunt voor elke stream die is geconfigureerd voor replicatie. Voor dit bericht maken en gebruiken we een globale tabel met de naam
kdsReplicationCheckpoint. - Actieve Regio config – De actieve regio gebruikt de algemene DynamoDB-tabel in zowel primaire als secundaire regio's. Het maakt gebruik van de native interregionale replicatiemogelijkheid van de globale tabel om de configuratie te repliceren. Het is vooraf gevuld met gegevens over de primaire regio voor een stream, om replicatie naar de primaire regio door de Lambda-functie in de standby-regio te voorkomen. Deze configuratie is mogelijk niet vereist als de Lambda-functie in de standby-regio een gereserveerde gelijktijdigheid heeft ingesteld op nul, maar kan dienen als een veiligheidscontrole om oneindige replicatielus van de gegevens te voorkomen. Voor dit bericht maken we een globale tabel met de naam
kdsActiveRegionConfigen plaats een item met de volgende gegevens:{ "stream-name": "example-stream-1", "active-region" : "us-east-1" } - Kinesis-gegevensstromen – De stream waarnaar de CDC-processor de gegevens produceert. Voor dit bericht gebruiken we een stream genaamd
example-stream-1in beide regio's, met dezelfde shardconfiguratie en hetzelfde toegangsbeleid.
Volgorde van stappen in replicatie tussen regio's
Laten we kort kijken hoe de architectuur wordt toegepast met behulp van het volgende sequentiediagram.

De volgorde bestaat uit de volgende stappen:
- De CDC-processor (in
us-east-1) leest de CDC-gegevens van de externe gegevensbron. - De CDC-processor (in
us-east-1) streamt de CDC-gegevens naar Kinesis Data Streams (inus-east-1). - De interregionale replicatie Lambda-functie (in us-east-1) verbruikt de gegevens uit de gegevensstroom (in
us-east-1). Het verbeterde fan-out patroon wordt aanbevolen voor speciale en verhoogde doorvoer voor replicatie tussen regio's. - De replicator Lambda-functie (in
us-east-1) valideert zijn huidige regio met de actieve regioconfiguratie voor de stream die wordt verbruikt, met behulp van dekdsActiveRegionConfigDynamoDB globale tabelDe volgende voorbeeldcode (in Java) kan helpen bij het illustreren van de voorwaarde die wordt geëvalueerd:// Fetch the current AWS Region from the Lambda function’s environment String currentAWSRegion = System.getenv(“AWS_REGION”); // Read the stream name from the first Kinesis Record once for the entire batch being processed. This is done because we are reusing the same Lambda function for replicating multiple streams. String currentStreamNameConsumed = kinesisRecord.getEventSourceARN().split(“:”)[5].split(“/”)[1]; // Build the DynamoDB query condition using the stream name Map<String, Condition> keyConditions = singletonMap(“streamName”, Condition.builder().comparisonOperator(EQ).attributeValueList(AttributeValue.builder().s(currentStreamNameConsumed).build()).build()); // Query the DynamoDB Global Table QueryResponse queryResponse = ddbClient.query(QueryRequest.builder().tableName("kdsActiveRegionConfig").keyConditions(keyConditions).attributesToGet(“ActiveRegion”).build()); - De functie evalueert het antwoord van DynamoDB met de volgende code:
// Evaluate the response if (queryResponse.hasItems()) { AttributeValue activeRegionForStream = queryResponse.items().get(0).get(“ActiveRegion”); return currentAWSRegion.equalsIgnoreCase(activeRegionForStream.s()); } - Afhankelijk van het antwoord voert de functie de volgende acties uit:
- Als de reactie is
true, produceert de replicatorfunctie de records naar Kinesis Data Streams inus-east-2op een sequentiële manier.- Als er een storing is, wordt het volgnummer van het record bijgehouden en wordt de iteratie verbroken. De functie retourneert de lijst met mislukte volgnummers. Door het mislukte volgnummer te retourneren, gebruikt de oplossing de functie van Lambda-controlepunten om de verwerking van een batch records met gedeeltelijke fouten te kunnen hervatten. Dit is handig bij het afhandelen van servicebeperkingen, waarbij de functie probeert de gegevens over regio's te repliceren om stream-pariteit en geen gegevensverlies te garanderen.
- Als er geen fouten zijn, wordt een lege lijst geretourneerd, wat aangeeft dat de batch is geslaagd.
- Als de reactie is
false, keert de replicatorfunctie terug zonder enige replicatie uit te voeren. Om de kosten van de Lambda-aanroepen te verlagen, kunt u de gereserveerde gelijktijdigheid van de functie instellen in de DR-regio (us-east-2) naar nul. Dit voorkomt dat de functie wordt aangeroepen. Wanneer u een failover uitvoert, kunt u deze waarde bijwerken naar een geschikt aantal op basis van de CDC-doorvoer en de gereserveerde gelijktijdigheid van de functie instellen inus-east-1naar nul om te voorkomen dat het onnodig wordt uitgevoerd.
- Als de reactie is
- Nadat alle records zijn geproduceerd om Kinesis Data Streams in te voeren
us-east-2, controleert de replicatorfunctie dekdsReplicationCheckpointDynamoDB globale tabel (inus-east-1) met de volgende gegevens:{ "streamName": "example-stream-1", "lastReplicatedTimestamp": "2022-07-18T20:00:00" } - De functie keert terug na het succesvol verwerken van de batch records.
Prestatieoverwegingen
De prestatieverwachtingen van de oplossing moeten worden begrepen met betrekking tot de volgende factoren:
- Regio selectie - De replicatielatentie is recht evenredig met de afstand die door de gegevens wordt afgelegd, dus begrijp uw regioselectie
- Snelheid – De inkomende snelheid van de gegevens of het volume van de gegevens die worden gerepliceerd
- Laadvermogen – De grootte van de payload die wordt gerepliceerd
Bewaak de Cross-Region-replicatie
Het wordt aanbevolen om de replicatie bij te houden en te observeren terwijl deze plaatsvindt. U kunt de Lambda-functie aanpassen om aangepaste statistieken naar CloudWatch te publiceren met de volgende statistieken aan het einde van elke aanroep. Door deze statistieken te publiceren naar zowel de primaire als de secundaire regio, kunt u uzelf beschermen tegen beperkingen die de waarneembaarheid in de primaire regio beïnvloeden.
- Doorvoer – De huidige batchgrootte van de Lambda-aanroep
- ReplicatieLagSeconds – Het verschil tussen de huidige tijdstempel (na verwerking van alle records) en de
ApproximateArrivalTimestampvan het laatste record dat werd gerepliceerd
Het volgende voorbeeld van een metrische CloudWatch-grafiek laat zien dat de gemiddelde replicatievertraging 2 seconden was met een doorvoer van 100 records gerepliceerd vanuit us-east-1 naar us-east-2.

Gemeenschappelijke failover-strategie
Tijdens eventuele bijzondere waardeverminderingen die van invloed zijn op de CDC-pijplijn in de primaire regio, kunnen bedrijfscontinuïteit of noodherstelbehoeften een pijplijnfailover naar de secundaire (stand-by) regio dicteren. Dit betekent dat er een aantal dingen moeten worden gedaan als onderdeel van dit failoverproces:
- Stop indien mogelijk alle CDC-taken in de CDC-processortool in
us-east-1. - Er moet een failover worden uitgevoerd voor de CDC-processor naar de secundaire regio, zodat deze de CDC-gegevens van de gegevensbron op afstand kan lezen terwijl deze vanuit de standby-regio werkt.
- De
kdsActiveRegionConfigDynamoDB globale tabel moet worden bijgewerkt. Bijvoorbeeld voor de streamexample-stream-1gebruikt in ons voorbeeld, wordt de actieve regio gewijzigd inus-east-2:
{ "stream-name": "example-stream-1", "active-Region" : "us-east-2"
}- Alle stream checkpoints moeten worden gelezen uit de
kdsReplicationCheckpointDynamoDB globale tabel (inus-east-2), en de tijdstempels van elk van de controlepunten worden gebruikt om de CDC-taken in de producer-tool te startenus-east-2Regio. Dit minimaliseert de kans op gegevensverlies en hervat nauwkeurig het streamen van de CDC-gegevens vanaf de externe gegevensbron vanaf het tijdstempel van het controlepunt. - Als u gereserveerde gelijktijdigheid gebruikt om Lambda-aanroepen te beheren, stelt u de waarde in op nul in de primaire Regio(
us-east-1) en naar een geschikte waarde anders dan nul in de secundaire Regio(us-east-2).
Vanguard's multi-step failover-strategie
Sommige tools van derden die Vanguard gebruikt, hebben een CDC-proces in twee stappen voor het streamen van gegevens van een externe gegevensbron naar een bestemming. De favoriete tool van Vanguard voor hun CDC-processor volgt deze aanpak in twee stappen:
- De eerste stap omvat het opzetten van een logstream-taak die de gegevens leest van de externe gegevensbron en blijft bestaan op een staging-locatie.
- De tweede stap omvat het opzetten van individuele consumententaken die gegevens lezen van de staging-locatie, die mogelijk is ingeschakeld Amazon elastisch bestandssysteem (Amazon EFS) of Amazon FSx, bijvoorbeeld, en stream het naar de bestemming. De flexibiliteit hier is dat elk van deze consumententaken kan worden getriggerd om te streamen vanuit verschillende commit-tijdstempels. De logstream-taak begint meestal met het lezen van gegevens vanaf het minimum van alle commit-tijdstempels die door de consumententaken worden gebruikt.
Laten we een voorbeeld bekijken om het scenario uit te leggen:
- Consumententaak A streamt gegevens vanaf een commit-tijdstempel 2022-07-19T20:00:00 naar
example-stream-1. - Consumententaak B streamt gegevens vanaf een commit-tijdstempel 2022-07-19T21:00:00 naar
example-stream-2. - In deze situatie moet de logstream gegevens lezen van de externe gegevensbron vanaf het minimum van de tijdstempels die door de consumententaken worden gebruikt, namelijk 2022-07-19T20:00:00.
Het volgende sequentie diagram toont de exacte stappen die moeten worden uitgevoerd tijdens een failover naar us-east-2 (de standby-regio).

De stappen zijn als volgt:
- Het failoverproces wordt geactiveerd in de standby-regio (
us-east-2in dit voorbeeld) indien nodig. Houd er rekening mee dat de trigger kan worden geautomatiseerd met behulp van uitgebreide gezondheidscontroles van de pijplijn in de primaire regio. - Het failoverproces werkt de kdsActiveRegionConfig DynamoDB globale tabel bij met de nieuwe waarde voor de regio als
us-east-2voor alle streamnamen. - De volgende stap is het ophalen van alle stream-checkpoints van het
kdsReplicationCheckpointDynamoDB globale tabel (inus-east-2). - Nadat de controlepuntinformatie is gelezen, vindt het failoverproces het minimum van alle
lastReplicatedTimestamp. - De logstream-taak in de CDC-processortool wordt gestart in
us-east-2met het tijdstempel gevonden in stap 4. Het begint met het lezen van CDC-gegevens van de externe gegevensbron vanaf dit tijdstempel en zet ze vast op de staging-locatie op AWS. - De volgende stap is het starten van alle consumententaken om gegevens van de verzamellocatie te lezen en naar de bestemmingsgegevensstroom te streamen. Hier wordt elke consumententaak voorzien van het juiste tijdstempel van de
kdsReplicationCheckpointtafel volgens destreamNamewaarnaar de taak de gegevens streamt.
Nadat alle consumententaken zijn gestart, worden gegevens geproduceerd naar de Kinesis-gegevensstromen in us-east-2. Vanaf dat moment is het proces van regio-overschrijdende replicatie hetzelfde als eerder beschreven - de replicatie Lambda-functie in us-east-2 begint met het repliceren van gegevens naar de gegevensstroom in us-east-1.
Van de consumententoepassingen die gegevens uit de streams lezen, wordt verwacht dat ze idempotent zijn om duplicaten te kunnen verwerken. Duplicaten kunnen om verschillende redenen in de stream worden geïntroduceerd, waarvan sommige hieronder worden genoemd.
- De producent of de CDC-processor introduceert duplicaten in de stream terwijl de CDC-gegevens opnieuw worden afgespeeld tijdens een failover
- DynamoDB Global Table gebruikt asynchrone replicatie van gegevens tussen regio's en als de
kdsReplicationCheckpointtabelgegevens een replicatievertraging hebben, kan het failoverproces mogelijk een ouder checkpoint-tijdstempel gebruiken om de CDC-gegevens opnieuw af te spelen.
Ook moeten consumententoepassingen de CommitTimestamp controleren van de laatste record die is verbruikt. Dit om een betere monitoring en herstel mogelijk te maken.
Pad naar volwassenheid: geautomatiseerd herstel
De ideale toestand is om het failoverproces volledig te automatiseren, waardoor de hersteltijd wordt verkort en de veerkrachtige Service Level Objective (SLO) wordt gehaald. In de meeste organisaties vereist de beslissing om te failoveren, failbacken en de failover te activeren handmatige tussenkomst bij het beoordelen van de situatie en het bepalen van de uitkomst. Het creëren van gescripte automatisering om de failover uit te voeren die door een mens kan worden uitgevoerd, is een goed begin.
Vanguard heeft alle stappen van de failover geautomatiseerd, maar laat mensen nog steeds beslissen wanneer ze deze gebruiken. U kunt de oplossing aanpassen aan uw behoeften en afhankelijk van de CDC-processortool die u in uw omgeving gebruikt.
Conclusie
In dit bericht hebben we beschreven hoe Vanguard innoveerde en een oplossing bouwde voor het repliceren van gegevens tussen regio's in Kinesis-gegevensstromen om de gegevens in hoge mate beschikbaar te maken. We hebben ook een robuuste checkpoint-strategie gedemonstreerd om een regionale failover van het replicatieproces mogelijk te maken wanneer dat nodig is. De oplossing illustreerde ook hoe de globale tabellen van DynamoDB moeten worden gebruikt voor het volgen van de replicatiecontrolepunten en configuratie. Met deze architectuur was Vanguard in staat om werklasten, afhankelijk van de CDC-gegevens, in meerdere regio's in te zetten om te voldoen aan de bedrijfsbehoeften van hoge beschikbaarheid in het licht van servicebeperkingen die van invloed zijn op CDC-pijplijnen in de primaire regio.
Als je feedback hebt, laat dan een reactie achter in het gedeelte Opmerkingen hieronder.
Over de auteurs
 Raghu Boppanna werkt als Enterprise Architect bij het Chief Technology Office van Vanguard. Raghu is gespecialiseerd in data-analyse, datamigratie/replicatie inclusief CDC-pijplijnen, noodherstel en databases. Hij heeft verschillende AWS-certificeringen behaald, waaronder AWS Certified Security - Specialty & AWS Certified Data Analytics - Specialty.
Raghu Boppanna werkt als Enterprise Architect bij het Chief Technology Office van Vanguard. Raghu is gespecialiseerd in data-analyse, datamigratie/replicatie inclusief CDC-pijplijnen, noodherstel en databases. Hij heeft verschillende AWS-certificeringen behaald, waaronder AWS Certified Security - Specialty & AWS Certified Data Analytics - Specialty.
 Parameswaran V Vaidyanathan is een Senior Cloud Resilience Architect bij Amazon Web Services. Hij helpt grote ondernemingen de zakelijke doelen te bereiken door schaalbare en veerkrachtige oplossingen op de AWS Cloud te ontwerpen en te bouwen.
Parameswaran V Vaidyanathan is een Senior Cloud Resilience Architect bij Amazon Web Services. Hij helpt grote ondernemingen de zakelijke doelen te bereiken door schaalbare en veerkrachtige oplossingen op de AWS Cloud te ontwerpen en te bouwen.
 Richa Kal is een Senior Leader in Customer Solutions ten dienste van klanten in de financiële dienstverlening. Ze is gevestigd in New York. Ze heeft uitgebreide ervaring in grootschalige cloudtransformatie, uitmuntendheid van medewerkers en digitale oplossingen van de volgende generatie. Zij en haar team richten zich op het optimaliseren van de waarde van de cloud door performante, veerkrachtige en flexibele oplossingen te bouwen. Richa houdt van multisporten zoals triatlons, muziek en het leren over nieuwe technologieën.
Richa Kal is een Senior Leader in Customer Solutions ten dienste van klanten in de financiële dienstverlening. Ze is gevestigd in New York. Ze heeft uitgebreide ervaring in grootschalige cloudtransformatie, uitmuntendheid van medewerkers en digitale oplossingen van de volgende generatie. Zij en haar team richten zich op het optimaliseren van de waarde van de cloud door performante, veerkrachtige en flexibele oplossingen te bouwen. Richa houdt van multisporten zoals triatlons, muziek en het leren over nieuwe technologieën.
 Mithil Prasad is een Principal Customer Solutions Manager bij Amazon Web Services. In zijn rol werkt Mithil samen met klanten om de realisatie van cloud-waarde te stimuleren, om kennisleiderschap te bieden om bedrijven te helpen snelheid, flexibiliteit en innovatie te bereiken.
Mithil Prasad is een Principal Customer Solutions Manager bij Amazon Web Services. In zijn rol werkt Mithil samen met klanten om de realisatie van cloud-waarde te stimuleren, om kennisleiderschap te bieden om bedrijven te helpen snelheid, flexibiliteit en innovatie te bereiken.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/how-vanguard-made-their-technology-platform-resilient-and-efficient-by-building-cross-region-replication-for-amazon-kinesis-data-streams/

