Dit is een gastpost die mede is geschreven door Alex Naumov, Principal Data Architect bij smava.
smava GmbH is een van de toonaangevende financiële dienstverleners in Duitsland en maakt persoonlijke leningen transparant, eerlijk en betaalbaar voor consumenten. Op basis van digitale processen vergelijkt smava leningaanbiedingen van meer dan twintig banken. Op deze manier kunnen kredietnemers op een snelle, gedigitaliseerde en efficiënte manier de deals kiezen die voor hen het gunstigst zijn.
smava gelooft in en profiteert van datagedreven beslissingen om marktleider te worden. Het Data Platform-team is verantwoordelijk voor het ondersteunen van datagestuurde beslissingen bij smava door dataproducten aan te bieden aan alle afdelingen en vestigingen van het bedrijf. De afdelingen omvatten teams van engineering tot verkoop en marketing. De branches variëren per product, namelijk B2C-leningen, B2B-leningen en voorheen ook B2C-hypotheken. De dataproducten die binnen het bedrijf worden gebruikt, omvatten onder meer inzichten uit gebruikerstrajecten, operationele rapporten en marketingcampagneresultaten. Het dataplatform verwerkt gemiddeld 60 zoekopdrachten per dag. Het datavolume bedraagt dubbelcijferige TB's en groeit gestaag naarmate het bedrijf en de databronnen evolueren.
Het Data Platform-team van smava stond voor de uitdaging om data te leveren aan belanghebbenden met verschillende SLA's, terwijl de flexibiliteit behouden bleef om op en neer te schalen en tegelijkertijd kostenefficiënt te blijven. Het duurde tot drie uur om de dagelijkse rapportage te genereren, wat van invloed was op de zakelijke besluitvorming wanneer er overdag herberekeningen moesten plaatsvinden. Om de selfservice-analyses te versnellen en innovatie op basis van data te bevorderen, was er een oplossing nodig die manieren bood waarmee elk team op gedecentraliseerde wijze zelf dataproducten kon creëren. Voor het maken en beheren van de dataproducten maakt smava gebruik van Amazon roodverschuiving, een clouddatawarehouse.
In dit bericht laten we zien hoe smava hun dataplatform heeft geoptimaliseerd door gebruik te maken van Amazon Redshift Serverloos en Amazon Redshift-gegevens delen om uitdagingen op het gebied van de juiste omvang van onvoorspelbare werklasten te overwinnen en de prijs-prestatie verder te verbeteren. Door de optimalisaties realiseerde smava tot 50% kostenbesparingen en tot drie keer snellere rapportgeneratie vergeleken met de vorige analyse-infrastructuur.
Overzicht van de oplossing
Als datagedreven bedrijf vertrouwt smava op de AWS Cloud om hun analytische gebruiksscenario's te ondersteunen. Om hun klanten de beste deals en gebruikerservaring te bieden, volgt smava de moderne data-architectuur principes met een datameer als schaalbare, duurzame dataopslag en speciaal gebouwde datastores voor analytische verwerking en dataconsumptie.
smava neemt gegevens uit verschillende externe en interne gegevensbronnen op in een landingsplatform op het datameer op basis van Amazon eenvoudige opslagservice (Amazone S3). Om de gegevens op te nemen, gebruikt smava een reeks populaire klantgegevensplatforms van derden, aangevuld met aangepaste scripts.
Nadat de gegevens in Amazon S3 zijn beland, gebruikt smava de AWS lijm Gegevenscatalogus en crawlers om de beschikbare gegevens automatisch te catalogiseren, de metagegevens vast te leggen en een interface te bieden waarmee alle gegevens kunnen worden bevraagd.
Data-analisten die toegang nodig hebben tot de onbewerkte assets op het datameer gebruiken Amazone Athene, een serverloze, interactieve analyseservice voor verkenning met ad-hocquery's. Voor de downstream-consumptie door alle afdelingen in de organisatie bereidt het Data Platform-team van smava samengestelde dataproducten voor volgens de extraheren, laden en transformeren (ELT)-patroon. smava gebruikt Amazon Redshift als hun clouddatawarehouse om gegevens en gebruik te transformeren, op te slaan en te analyseren Amazon Roodverschuivingsspectrum om gestructureerde en semi-gestructureerde gegevens efficiënt op te vragen en op te halen uit het datameer met behulp van SQL.
smava volgt de data kluis modellering methodologie met de Raw Vault-, Business Vault- en Data Mart-fasen om de dataproducten voor eindgebruikers voor te bereiden. De Raw Vault beschrijft objecten die rechtstreeks vanuit de gegevensbronnen zijn geladen en vertegenwoordigt een kopie van de landingsplaats in het datameer. De Business Vault wordt gevuld met gegevens afkomstig uit de Raw Vault en getransformeerd volgens de bedrijfsregels. Ten slotte worden de gegevens samengevoegd tot specifieke dataproducten gericht op een specifieke bedrijfstak. Dit is de Datamart fase. De dataproducten uit de Business Vault- en Data Mart-fasen zijn nu beschikbaar voor consumenten. smava besloot Tableau te gebruiken voor business intelligence, datavisualisatie en verdere analyses. De datatransformaties worden beheerd met dbt om het workflowbeheer en de teamsamenwerking te vereenvoudigen.
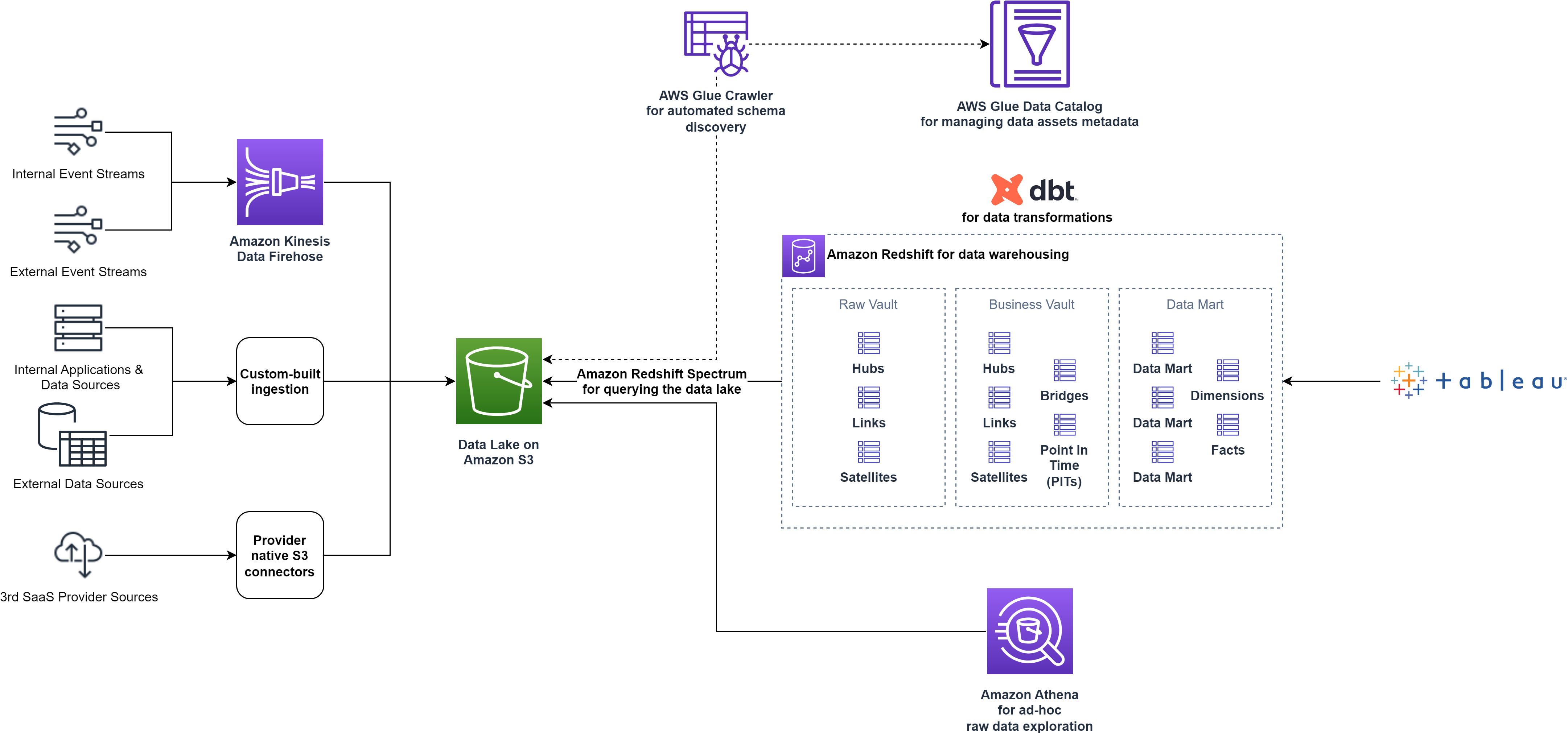
Het volgende diagram toont de architectuur van het dataplatform op hoog niveau vóór de optimalisaties.
Evolutie van de vereisten voor het dataplatform
smava begon met één enkel Redshift-cluster om alle drie de gegevensfasen te hosten. Ze kozen voor ingerichte clusterknooppunten van de RA3-type Met Gereserveerde exemplaren (RI's) voor kostenoptimalisatie. Omdat de datavolumes jaar na jaar met 53% groeiden, namen ook de complexiteit en vereisten van verschillende analytische workloads toe.
smava pakte snel de groeiende datavolumes aan door het cluster op de juiste maat te brengen en te gebruiken Amazon Redshift gelijktijdigheidsschaling voor piekbelastingen. Bovendien wilde smava alle teams de mogelijkheid geven om op een selfservice manier hun eigen dataproducten te creëren om het innovatietempo te verhogen. Om interferentie met de centraal beheerde dataproducten te voorkomen, moesten de gedecentraliseerde productontwikkelingsomgevingen strikt geïsoleerd worden. Dezelfde vereiste werd ook toegepast voor de isolatie van verschillende productfasen, samengesteld door het Data Platform-team.
Het optimaliseren van de architectuur met data delen en Redshift Serverless
Om aan de veranderende eisen te voldoen, besloot smava de werklast te scheiden door het enkel ingerichte Redshift-cluster op te splitsen in meerdere datawarehouses, waarbij elk magazijn een andere fase bedient. Daarnaast heeft smava nieuwe staging-omgevingen toegevoegd aan de Business Vault om nieuwe dataproducten te ontwikkelen zonder het risico te lopen de bestaande productpijplijnen te verstoren. Om interferentie met de centraal beheerde dataproducten van het Data Platform-team te voorkomen, introduceerde smava een extra Redshift-cluster, dat de gedecentraliseerde werklasten isoleert.
smava was op zoek naar een kant-en-klare oplossing om werklastisolatie te bereiken zonder een complexe datareplicatiepijplijn te beheren.
Direct na de lancering van Het delen van roodverschuivingsgegevens mogelijkheden in 2021 erkende het Data Platform-team dat dit de oplossing was waarnaar ze op zoek waren. smava heeft de functie voor het delen van gegevens overgenomen om de gegevens van producentenclusters beschikbaar te maken voor leestoegang op verschillende consumentenclusters, waarbij elk van deze consumentenclusters een ander stadium bedient.
Het delen van Redshift-gegevens maakt directe, gedetailleerde en snelle gegevenstoegang mogelijk binnen Redshift-clusters zonder dat gegevens hoeven te worden gekopieerd. Het biedt live toegang tot gegevens, zodat gebruikers altijd de meest actuele en consistente informatie zien zoals deze wordt bijgewerkt in het datawarehouse. Met het delen van gegevens kunt u veilig live gegevens delen met Redshift-clusters in dezelfde of verschillende AWS-accounts en tussen regio's.
Met het delen van Redshift-gegevens kon smava de gegevensarchitectuur optimaliseren door de gegevenswerklasten te verdelen over individuele consumentenclusters zonder de gegevens te hoeven repliceren. Het volgende diagram illustreert de architectuur van het dataplatform op hoog niveau na het splitsen van het enkele Redshift-cluster in meerdere clusters.
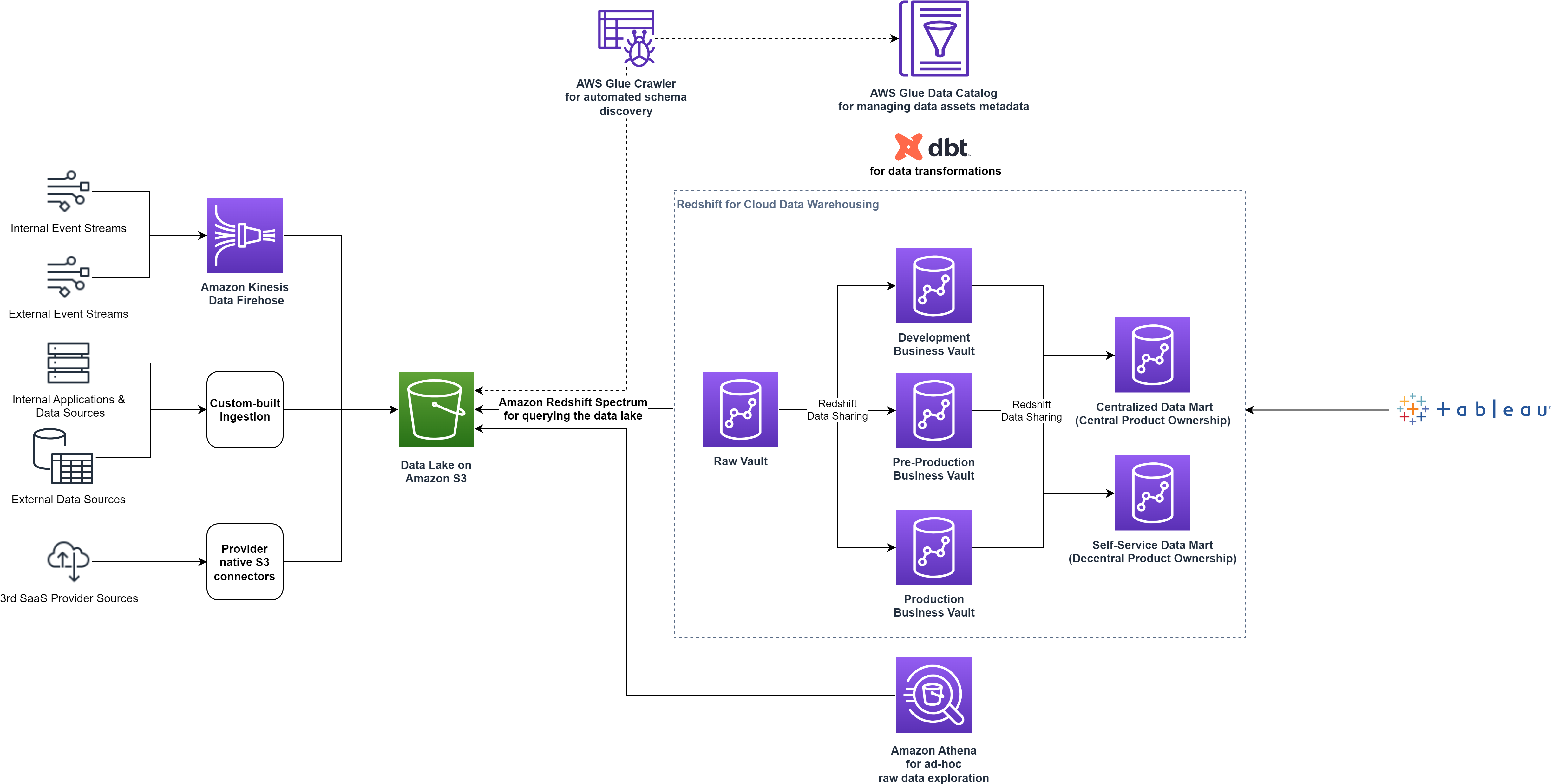
Door een zelfbedieningsdatamart aan te bieden, verhoogde smava de datademocratisering door gebruikers toegang te geven tot alle aspecten van de data. Ze voorzagen teams ook van een reeks aangepaste tools voor het ontdekken van data, ad-hocanalyse, prototyping en het exploiteren van de volledige levenscyclus van volwassen dataproducten.
Na het verzamelen van operationele gegevens van de afzonderlijke clusters, identificeerde het Data Platform-team verdere potentiële optimalisaties: het Raw Vault-cluster stond 24/7 onder constante belasting, maar de Business Vault-clusters werden alleen 's nachts bijgewerkt. Om de kosten te optimaliseren, gebruikte smava de mogelijkheden voor pauzeren en hervatten van door Redshift ingerichte clusters. Deze mogelijkheden zijn handig voor clusters die op specifieke tijden beschikbaar moeten zijn. Terwijl het cluster is onderbroken, wordt facturering op aanvraag opgeschort. Alleen voor de opslag van het cluster worden kosten in rekening gebracht.
Dankzij de pauze- en hervattingsfunctie kon Smava de kosten optimaliseren, maar er was extra operationele overhead voor nodig om de clusterbewerkingen te activeren. Bovendien bleven de ontwikkelingsclusters tijdens werkuren onderhevig aan inactiviteit. Deze uitdagingen werden uiteindelijk opgelost door Redshift Serverless in 2022 te adopteren. Het Data Platform-team besloot de Business Data Vault-faseclusters te verplaatsen naar Redshift Serverless, waardoor ze alleen voor het datawarehouse konden betalen wanneer het in gebruik, betrouwbaar en efficiënt was.
Redshift Serverless is ideaal voor gevallen waarin het moeilijk is om rekenbehoeften te voorspellen, zoals variabele werklasten, periodieke werklasten met inactieve tijd en stabiele werklasten met pieken. Naarmate de gebruiksvraag evolueert met nieuwe werklasten en meer gelijktijdige gebruikers, voorziet Redshift Serverless bovendien automatisch in de juiste computerbronnen, en schaalt het datawarehouse naadloos en automatisch, zonder de noodzaak van handmatige tussenkomst. Het delen van gegevens wordt in beide richtingen ondersteund tussen Redshift Serverless en ingerichte Redshift-clusters met RA3-nodes, dus er waren geen wijzigingen aan de smava-architectuur nodig. Het volgende diagram toont de architectuuropstelling op hoog niveau na de overstap naar Redshift Serverless.
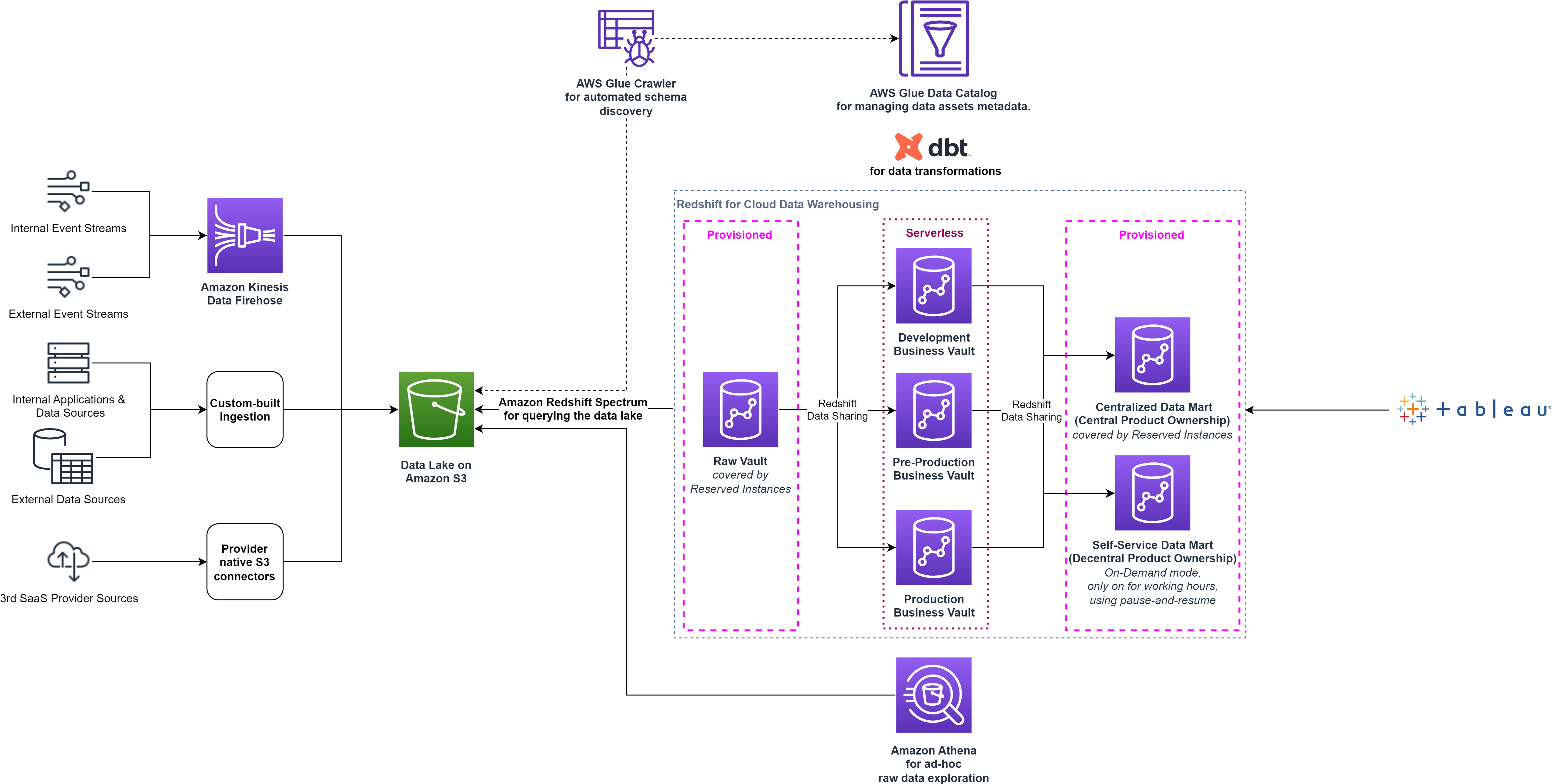
smava combineerde de voordelen van Redshift Serverless en dbt via een naadloze CI/CD-pijplijn, waarbij een op trunk gebaseerde ontwikkelingsmethodologie werd toegepast. Wijzigingen in de Git-repository worden automatisch geïmplementeerd in een testfase en gevalideerd met behulp van geautomatiseerde integratietests. Deze aanpak verhoogde de efficiëntie van ontwikkelaars en verminderde de gemiddelde productietijd van dagen naar minuten.
smava heeft een architectuur aangenomen die zowel ingerichte als serverloze Redshift-datawarehouses gebruikt, samen met de mogelijkheid om gegevens te delen om de werklasten te isoleren. Door de juiste architecturale patronen voor hun behoeften te kiezen, kon smava het volgende bereiken:
- Vereenvoudig de datapijplijnen en verminder de operationele overhead
- Verkort de releasetijd van functies van dagen naar minuten
- Verhoog de prijs-prestatieverhouding door de inactieve tijden te verminderen en de werklast op de juiste maat te maken
- Realiseer tot drie keer snellere rapportgeneratie (snellere berekeningen en hogere parallellisatie) tegen 50% van de oorspronkelijke installatiekosten
- Vergroot de wendbaarheid van alle afdelingen en ondersteun datagestuurde besluitvorming door de toegang tot data te democratiseren
- Vergroot de snelheid van innovatie door selfservice-datamogelijkheden beschikbaar te stellen voor teams op alle afdelingen en door de A/B-testmogelijkheden te versterken om het volledige klanttraject te dekken
Nu gebruiken alle afdelingen bij smava de beschikbare dataproducten om datagestuurde, nauwkeurige en flexibele beslissingen te nemen.
Toekomst visie
Voor de toekomst is smava van plan het dataplatform te blijven optimaliseren op basis van operationele statistieken. Ze overwegen om meer ingerichte clusters, zoals het Self-Service Data Mart-cluster, over te zetten naar serverloos. Daarnaast optimaliseert smava de ELT-orkestratietoolchain om het aantal parallelle datapijplijnen dat moet worden uitgevoerd te vergroten. Dit zal het gebruik van de ingerichte Redshift-bronnen vergroten en kostenbesparingen mogelijk maken.
Met de introductie van de gedecentraliseerde zelfservice voor het maken van dataproducten heeft smava een stap voorwaarts gezet in de richting van een data mesh-architectuur. In de toekomst is het Data Platform-team van plan de behoeften van hun servicegebruikers verder te evalueren en verdere data mesh-principes vast te stellen, zoals federatieve data governance.
Conclusie
In dit bericht hebben we laten zien hoe smava hun dataplatform heeft geoptimaliseerd door omgevingen en workloads te isoleren met behulp van Redshift Serverless en functies voor het delen van gegevens. Deze Redshift-omgevingen zijn goed geïntegreerd met hun infrastructuur, flexibel in het opschalen op aanvraag, zeer beschikbaar en vereisen minimale beheerinspanningen. Over het geheel genomen heeft smava de prestaties met drie keer verhoogd, terwijl de totale platformkosten met 50% zijn verlaagd. Bovendien hebben ze de operationele overhead tot een minimum beperkt, terwijl de bestaande SLA's voor het genereren van rapporten behouden bleven. Bovendien heeft smava de cultuur van innovatie versterkt door mogelijkheden voor zelfbedieningsdataproducten te bieden om de time-to-market te versnellen.
Als je meer wilt weten over de mogelijkheden van Amazon Redshift, raden we je aan de meest recente te bekijken Wat is er nieuw met de Amazon Redshift-sessie in het AWS Events-kanaal om een overzicht te krijgen van de functies die onlangs aan de service zijn toegevoegd. Je kunt ook de zelfbedienings-, praktijkgerichte Amazon Redshift-labs om op een begeleide manier te experimenteren met de belangrijkste Amazon Redshift-functionaliteiten.
Je kunt er ook dieper in duiken Redshift Serverloze gebruiksscenario's en Gebruiksscenario's voor het delen van gegevens. Bekijk bovendien de beste praktijken voor het delen van gegevens en ontdek hoe andere klanten geoptimaliseerd voor kosten en prestaties met het delen van Redshift-gegevens om inspiratie op te doen voor uw eigen workloads.
Als je de voorkeur geeft aan boeken, kijk dan eens Amazon Redshift: The Definitive Guide door O'Reilly, waar de auteurs de mogelijkheden van Amazon Redshift gedetailleerd beschrijven en u inzicht geven in overeenkomstige patronen en technieken.
Over de auteurs
 Alex Naumov is Principal Data Architect bij smava GmbH en leidt de transformatieprojecten op de Data-afdeling. Alex heeft eerder tien jaar gewerkt als consultant en data-/oplossingsarchitect in een grote verscheidenheid aan domeinen, zoals telecommunicatie, het bankwezen, energie en financiën, met behulp van verschillende tech-stacks, en in veel verschillende landen. Hij heeft een grote passie voor data en het transformeren van organisaties om datagedreven te worden en de beste te worden in wat ze doen.
Alex Naumov is Principal Data Architect bij smava GmbH en leidt de transformatieprojecten op de Data-afdeling. Alex heeft eerder tien jaar gewerkt als consultant en data-/oplossingsarchitect in een grote verscheidenheid aan domeinen, zoals telecommunicatie, het bankwezen, energie en financiën, met behulp van verschillende tech-stacks, en in veel verschillende landen. Hij heeft een grote passie voor data en het transformeren van organisaties om datagedreven te worden en de beste te worden in wat ze doen.
 Lingli Zheng werkt als Business Development Manager bij de wereldwijde gespecialiseerde organisatie van AWS en ondersteunt klanten in de DACH-regio om de beste waarde uit de analysediensten van Amazon te halen. Met meer dan 12 jaar ervaring in energie, automatisering en de software-industrie met een focus op data-analyse, AI en ML, is ze toegewijd om klanten te helpen tastbare bedrijfsresultaten te bereiken door middel van digitale transformatie.
Lingli Zheng werkt als Business Development Manager bij de wereldwijde gespecialiseerde organisatie van AWS en ondersteunt klanten in de DACH-regio om de beste waarde uit de analysediensten van Amazon te halen. Met meer dan 12 jaar ervaring in energie, automatisering en de software-industrie met een focus op data-analyse, AI en ML, is ze toegewijd om klanten te helpen tastbare bedrijfsresultaten te bereiken door middel van digitale transformatie.
 Alexander Spivak is een Senior Startup Solutions Architect bij AWS, gericht op B2B ISV-klanten in EMEA Noord. Vóór AWS werkte Alexander als consultant in financiële dienstverlening, waaronder verschillende rollen in softwareontwikkeling en architectuur. Hij heeft een passie voor data-analyse, serverloze architecturen en het creëren van efficiënte organisaties.
Alexander Spivak is een Senior Startup Solutions Architect bij AWS, gericht op B2B ISV-klanten in EMEA Noord. Vóór AWS werkte Alexander als consultant in financiële dienstverlening, waaronder verschillende rollen in softwareontwikkeling en architectuur. Hij heeft een passie voor data-analyse, serverloze architecturen en het creëren van efficiënte organisaties.
Dit bericht is beoordeeld op technische nauwkeurigheid door David Greenshtein, Senior Analytics Solutions Architect.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/how-smava-makes-loans-transparent-and-affordable-using-amazon-redshift-serverless/

