Naarmate Roblox de afgelopen ruim zestien jaar is gegroeid, groeit ook de omvang en complexiteit van de technische infrastructuur die miljoenen meeslepende 16D-co-ervaringen ondersteunt. Het aantal machines dat we ondersteunen is de afgelopen twee jaar meer dan verdrievoudigd, van ongeveer 3 op 36,000 juni 30 tot bijna 2021 vandaag. Om deze ‘always-on’-ervaringen voor mensen over de hele wereld te ondersteunen zijn meer dan 145,000 interne diensten nodig. Om ons te helpen de kosten en netwerklatentie onder controle te houden, implementeren en beheren we deze machines als onderdeel van een op maat gemaakte en hybride private cloud-infrastructuur die voornamelijk op locatie draait.
Onze infrastructuur ondersteunt momenteel meer dan 70 miljoen dagelijks actieve gebruikers over de hele wereld, inclusief de makers die vertrouwen op Roblox's economie voor hun bedrijven. Al deze miljoenen mensen verwachten een zeer hoog niveau van betrouwbaarheid. Gezien de meeslepende aard van onze ervaringen, is er een extreem lage tolerantie voor vertragingen of latentie, laat staan uitval. Roblox is een platform voor communicatie en verbinding, waar mensen samenkomen in meeslepende 3D-ervaringen. Wanneer mensen communiceren als hun avatar in een meeslepende ruimte, zijn zelfs kleine vertragingen of storingen meer merkbaar dan tijdens een tekstgesprek of een telefonische vergadering.
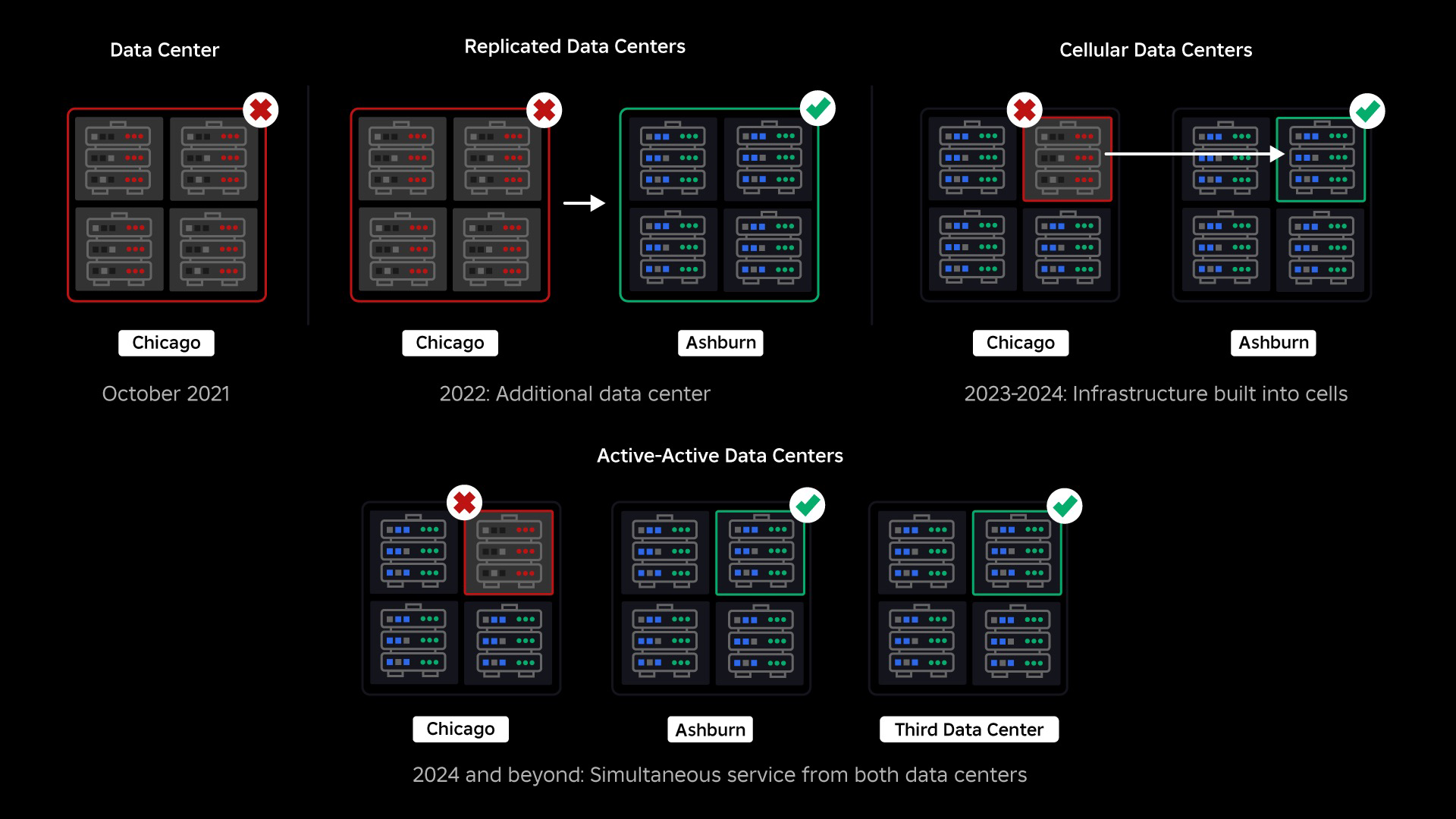
In oktober 2021 hadden we te maken met een systeembrede storing. Het begon klein, met een probleem in één component in één datacenter. Maar tijdens het onderzoek verspreidde het zich snel en resulteerde uiteindelijk in een storing van 73 uur. Destijds deelden we beide details over wat er is gebeurd en enkele van onze eerste lessen uit dit probleem. Sindsdien hebben we deze lessen bestudeerd en gewerkt aan het vergroten van de veerkracht van onze infrastructuur tegen de soorten fouten die optreden in alle grootschalige systemen als gevolg van factoren zoals extreme verkeerspieken, het weer, hardwarestoringen, softwarefouten of gewoon mensen die fouten maken. Wanneer deze fouten optreden, hoe zorgen we er dan voor dat een probleem in een enkel onderdeel of een groep componenten zich niet naar het volledige systeem verspreidt? Deze vraag heeft de afgelopen twee jaar onze aandacht gehad en terwijl het werk voortduurt, werpt wat we tot nu toe hebben gedaan nu al vruchten af. In de eerste helft van 2023 hebben we bijvoorbeeld 125 miljoen engagement-uren per maand bespaard vergeleken met de eerste helft van 2022. Vandaag delen we het werk dat we al hebben gedaan, evenals onze langere termijnvisie voor het bouwen een veerkrachtiger infrastructuursysteem.
Het bouwen van een achtervang
Binnen grootschalige infrastructuursystemen komen kleinschalige storingen vele malen per dag voor. Als één machine een probleem heeft en buiten gebruik moet worden gesteld, is dat beheersbaar omdat de meeste bedrijven meerdere exemplaren van hun back-endservices onderhouden. Dus als één exemplaar faalt, nemen anderen de werklast over. Om deze frequente fouten op te lossen, zijn verzoeken over het algemeen zo ingesteld dat ze automatisch opnieuw proberen als ze een foutmelding krijgen.
Dit wordt een uitdaging wanneer een systeem of persoon te agressief opnieuw probeert, wat een manier kan zijn waarop deze kleinschalige mislukkingen zich door de infrastructuur kunnen verspreiden naar andere diensten en systemen. Als het netwerk of een gebruiker het herhaaldelijk opnieuw probeert, zal het uiteindelijk elk exemplaar van die service en mogelijk ook andere systemen wereldwijd overbelasten. Onze storing in 2021 was het resultaat van iets dat vrij vaak voorkomt bij grootschalige systemen: een storing begint klein en verspreidt zich vervolgens door het systeem, en wordt zo snel groot dat het moeilijk op te lossen is voordat alles uitvalt.
Ten tijde van onze storing hadden we één actief datacenter (met componenten daarin die als back-up fungeerden). We hadden de mogelijkheid nodig om handmatig een failover naar een nieuw datacenter uit te voeren wanneer een probleem het bestaande datacenter platlegde. Onze eerste prioriteit was ervoor te zorgen dat we een back-upimplementatie van Roblox hadden, dus hebben we die back-up in een nieuw datacenter gebouwd, gelegen in een andere geografische regio. Dat zorgde voor extra bescherming voor het worstcasescenario: een storing die zich naar voldoende componenten binnen een datacenter verspreidt, zodat deze volledig onbruikbaar wordt. We hebben nu één datacenter dat de werklast afhandelt (actief) en één datacenter dat op stand-by staat en als back-up dient (passief). Ons langetermijndoel is om van deze actief-passieve configuratie over te stappen naar een actief-actieve configuratie, waarin beide datacenters de werklast afhandelen, met een load balancer die verzoeken onderling verdeelt op basis van latentie, capaciteit en status. Zodra dit is doorgevoerd, verwachten we een nog hogere betrouwbaarheid voor heel Roblox en kunnen we vrijwel onmiddellijk een failover uitvoeren in plaats van over meerdere uren. 
Verhuizen naar een mobiele infrastructuur
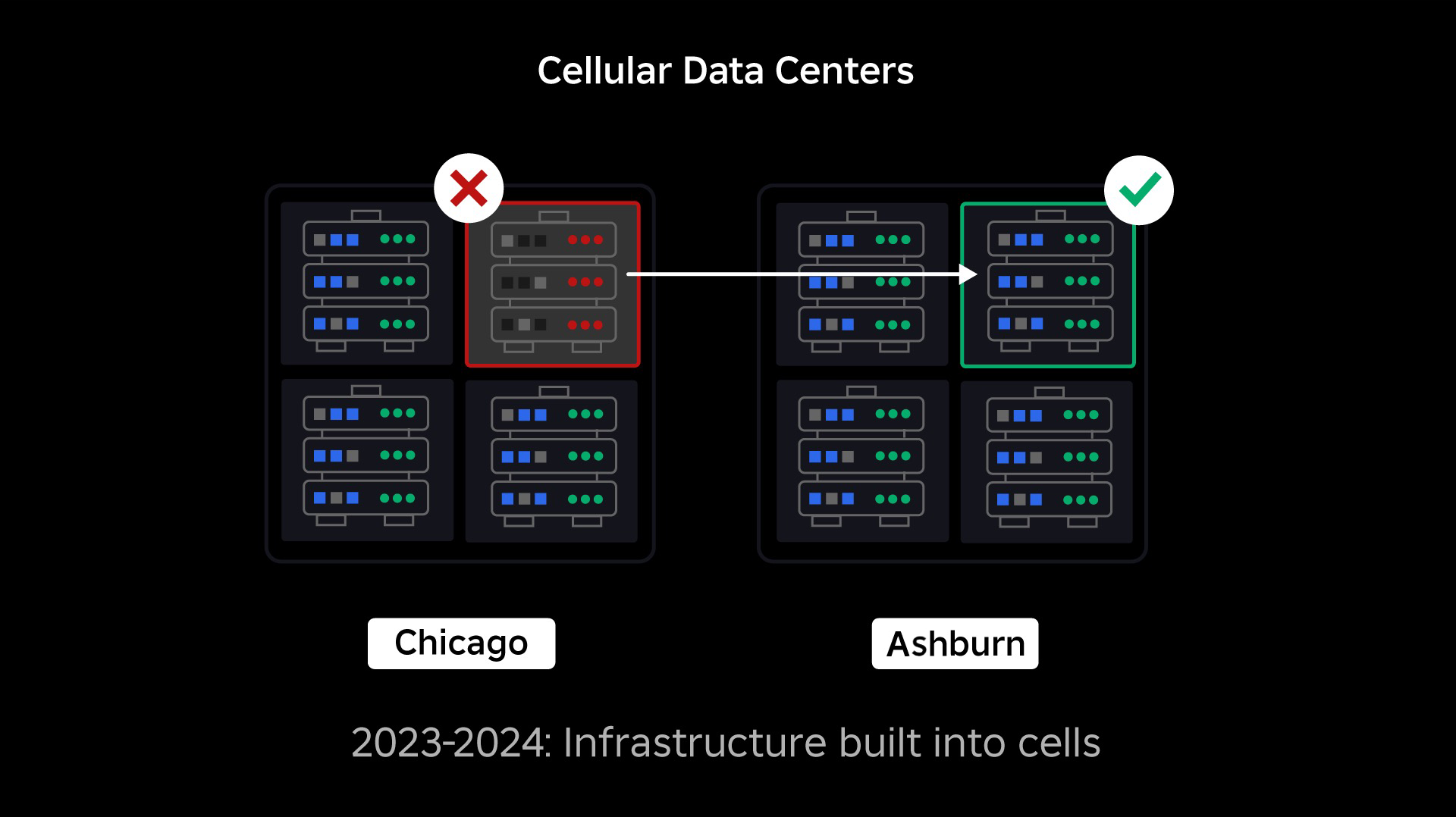
Onze volgende prioriteit was het creëren van sterke explosiemuren in elk datacenter om de kans te verkleinen dat een heel datacenter uitvalt. Cellen (sommige bedrijven noemen ze clusters) zijn in wezen een reeks machines en de manier waarop we deze muren creëren. We repliceren services zowel binnen als tussen cellen voor extra redundantie. Uiteindelijk willen we dat alle diensten bij Roblox in cellen draaien, zodat ze kunnen profiteren van zowel sterke explosiemuren als redundantie. Als een cel niet meer functioneert, kan deze veilig worden gedeactiveerd. Door replicatie tussen cellen kan de service blijven draaien terwijl de cel wordt gerepareerd. In sommige gevallen kan celreparatie een volledige herinrichting van de cel betekenen. In de hele sector is het wissen en opnieuw inrichten van een individuele machine, of een klein aantal machines, vrij gebruikelijk, maar dit voor een hele cel, die ongeveer 1,400 machines bevat, is dat niet.
Om dit te laten werken, moeten deze cellen grotendeels uniform zijn, zodat we werklasten snel en efficiënt van de ene cel naar de andere kunnen verplaatsen. We hebben bepaalde eisen gesteld waar diensten aan moeten voldoen voordat ze in een cel kunnen draaien. Services moeten bijvoorbeeld in containers worden ondergebracht, wat ze veel draagbaarder maakt en voorkomt dat iemand configuratiewijzigingen op besturingssysteemniveau aanbrengt. We hebben een infrastructuur-als-code-filosofie voor cellen aangenomen: in onze broncodeopslagplaats nemen we de definitie op van alles wat zich in een cel bevindt, zodat we deze snel vanaf nul kunnen herbouwen met behulp van geautomatiseerde tools.
Momenteel voldoen niet alle services aan deze vereisten. Daarom hebben we gewerkt om service-eigenaren waar mogelijk te helpen hieraan te voldoen, en hebben we nieuwe tools ontwikkeld om het gemakkelijk te maken services naar cellen te migreren wanneer ze klaar zijn. Onze nieuwe implementatietool 'stript' bijvoorbeeld automatisch een service-implementatie over cellen heen, zodat service-eigenaren niet hoeven na te denken over de replicatiestrategie. Dit niveau van nauwkeurigheid maakt het migratieproces veel uitdagender en tijdrovender, maar de beloning op de lange termijn zal een systeem zijn waarin:
- Het is veel gemakkelijker om een storing onder controle te houden en te voorkomen dat deze zich naar andere cellen verspreidt;
- Onze infrastructuuringenieurs kunnen efficiënter zijn en sneller handelen; En
- De ingenieurs die de diensten op productniveau bouwen die uiteindelijk in cellen worden ingezet, hoeven niet te weten of zich zorgen te maken over in welke cellen hun diensten draaien.
Grotere uitdagingen oplossen
Vergelijkbaar met de manier waarop branddeuren worden gebruikt om vlammen tegen te houden, fungeren cellen als sterke explosiemuren binnen onze infrastructuur om te helpen welk probleem dan ook dat een storing binnen een enkele cel veroorzaakt, onder controle te houden. Uiteindelijk zullen alle diensten waaruit Roblox bestaat, redundant worden ingezet in en tussen cellen. Als dit werk eenmaal is voltooid, kunnen problemen zich nog steeds wijd genoeg verspreiden om een hele cel onbruikbaar te maken, maar het zou uiterst moeilijk zijn als een probleem zich buiten die cel zou verspreiden. En als we erin slagen cellen uitwisselbaar te maken, zal het herstel aanzienlijk sneller verlopen omdat we dan een failover kunnen uitvoeren naar een andere cel en kunnen voorkomen dat het probleem gevolgen heeft voor eindgebruikers.
Waar dit lastig wordt, is het voldoende scheiden van deze cellen om de kans op het verspreiden van fouten te verkleinen, terwijl de zaken performant en functioneel blijven. In een complex infrastructuursysteem moeten services met elkaar communiceren om vragen, informatie, werklasten, enz. te delen. Terwijl we deze services in cellen repliceren, moeten we goed nadenken over de manier waarop we met kruiscommunicatie omgaan. In een ideale wereld leiden we verkeer van de ene ongezonde cel naar andere gezonde cellen. Maar hoe gaan we om met een 'vraag naar de dood'? veroorzakend een cel ongezond? Als we die zoekopdracht omleiden naar een andere cel, kan dit ertoe leiden dat die cel ongezond wordt, precies op de manier die we proberen te vermijden. We moeten mechanismen vinden om 'goed' verkeer van ongezonde cellen te verplaatsen, terwijl we het verkeer dat ervoor zorgt dat cellen ongezond worden, kunnen detecteren en onderdrukken.
Op de korte termijn hebben we kopieën van computerservices in elke rekencel geïmplementeerd, zodat de meeste verzoeken aan het datacenter door één enkele cel kunnen worden afgehandeld. We verdelen ook het verkeer over de cellen. Als we verder kijken, zijn we begonnen met het bouwen van een service-ontdekkingsproces van de volgende generatie, dat zal worden benut door een service mesh, dat we in 2024 hopen te voltooien. Dit zal ons in staat stellen geavanceerd beleid te implementeren dat communicatie tussen cellen alleen mogelijk maakt als het heeft geen negatieve invloed op de failover-cellen. In 2024 komt er ook een methode voor het doorsturen van afhankelijke verzoeken naar een serviceversie in dezelfde cel, waardoor het verkeer tussen cellen wordt geminimaliseerd en daardoor het risico op de verspreiding van fouten tussen cellen wordt verkleind.
Op het hoogtepunt wordt meer dan 70 procent van ons back-end-serviceverkeer vanuit cellen bediend en we hebben veel geleerd over het maken van cellen, maar we verwachten nog meer onderzoek en testen terwijl we onze services blijven migreren tot 2024 en voorbij. Naarmate we verder komen, zullen deze explosiemuren steeds sterker worden.
Migreren van een permanente infrastructuur
Roblox is een mondiaal platform dat gebruikers over de hele wereld ondersteunt, dus we kunnen services niet verplaatsen tijdens de daluren of 'downtime', wat het proces van het migreren van al onze machines naar cellen en onze services om in die cellen te draaien nog ingewikkelder maakt. . We hebben miljoenen ‘altijd aan’-ervaringen die ondersteund moeten blijven, zelfs als we de machines waarop ze draaien en de services die ze ondersteunen verplaatsen. Toen we met dit proces begonnen, hadden we geen tienduizenden machines die ongebruikt bleven staan en beschikbaar waren om deze workloads naartoe te migreren.
Wel hadden we een klein aantal extra machines aangeschaft met het oog op toekomstige groei. Om te beginnen hebben we met die machines nieuwe cellen gebouwd en vervolgens de werklasten ernaar gemigreerd. We hechten waarde aan efficiëntie en betrouwbaarheid, dus in plaats van meer machines te gaan kopen zodra de “reserve”-machines op waren, hebben we meer cellen gebouwd door de machines waarvan we waren gemigreerd, te wissen en opnieuw in te richten. Vervolgens hebben we de werklasten naar de opnieuw ingerichte machines gemigreerd en het proces opnieuw gestart. Dit proces is complex: naarmate machines worden vervangen en vrijgemaakt om in cellen te worden ingebouwd, komen ze niet op een ideale, ordelijke manier vrij. Ze zijn fysiek gefragmenteerd over datahallen, waardoor we ze stukje bij beetje kunnen inrichten, wat een defragmentatieproces op hardwareniveau vereist om de hardwarelocaties op één lijn te houden met grootschalige fysieke storingsdomeinen.
Een deel van ons infrastructuurengineeringteam is gericht op het migreren van bestaande workloads van onze oude, of ‘pre-cell’-omgeving naar cellen. Dit werk zal doorgaan totdat we duizenden verschillende infrastructuurdiensten en duizenden back-enddiensten naar nieuw gebouwde cellen hebben gemigreerd. We verwachten dat dit het hele volgend jaar en mogelijk tot 2025 zal duren, vanwege een aantal complicerende factoren. Ten eerste vereist dit werk dat er robuust gereedschap wordt gebouwd. We hebben bijvoorbeeld tools nodig om grote aantallen services automatisch opnieuw in evenwicht te brengen wanneer we een nieuwe cel implementeren, zonder gevolgen voor onze gebruikers. We hebben ook services gezien die zijn gebouwd met aannames over onze infrastructuur. We moeten deze diensten herzien, zodat ze niet afhankelijk zijn van dingen die in de toekomst kunnen veranderen als we naar cellen verhuizen. We hebben ook een manier geïmplementeerd om te zoeken naar bekende ontwerppatronen die niet goed werken met cellulaire architectuur, evenals een methodisch testproces voor elke service die wordt gemigreerd. Deze processen helpen ons eventuele gebruikersproblemen te voorkomen die worden veroorzaakt doordat een service niet compatibel is met cellen.
Tegenwoordig worden bijna 30,000 machines beheerd door cellen. Het is slechts een fractie van onze totale vloot, maar tot nu toe is de overgang heel soepel verlopen, zonder negatieve gevolgen voor de spelers. Ons uiteindelijke doel is dat onze systemen elke maand een uptime van 99.99 procent van de gebruikers bereiken, wat betekent dat we niet meer dan 0.01 procent van de betrokkenheidsuren zouden verstoren. In de hele sector kan downtime niet volledig worden geëlimineerd, maar ons doel is om eventuele downtime van Roblox te verminderen tot een niveau dat deze bijna onmerkbaar is.
Toekomstbestendig terwijl we opschalen
Hoewel onze eerste inspanningen succesvol blijken, is ons werk aan cellen nog lang niet klaar. Terwijl Roblox blijft opschalen, zullen we blijven werken aan het verbeteren van de efficiëntie en veerkracht van onze systemen via deze en andere technologieën. Naarmate we verder komen, zal het platform steeds beter bestand zijn tegen problemen, en alle problemen die zich voordoen zouden steeds minder zichtbaar en ontwrichtend moeten worden voor de mensen op ons platform.
Samenvattend hebben we tot nu toe:
- Een tweede datacenter gebouwd en met succes de actieve/passieve status bereikt.
- We creëerden cellen in onze actieve en passieve datacenters en migreerden met succes meer dan 70 procent van ons back-end serviceverkeer naar deze cellen.
- Stel de vereisten en best practices vast die we moeten volgen om alle cellen uniform te houden terwijl we doorgaan met het migreren van de rest van onze infrastructuur.
- Startte een continu proces van het bouwen van sterkere ‘blastmuren’ tussen cellen.
Naarmate deze cellen beter uitwisselbaar worden, zal er minder overspraak tussen cellen zijn. Dit ontsluit een aantal zeer interessante mogelijkheden voor ons in termen van toenemende automatisering rond monitoring, probleemoplossing en zelfs het automatisch verschuiven van werklasten.
In september zijn we ook begonnen met het uitvoeren van actieve/actieve experimenten in onze datacenters. Dit is een ander mechanisme dat we testen om de betrouwbaarheid te verbeteren en de failover-tijden te minimaliseren. Deze experimenten hebben geholpen bij het identificeren van een aantal systeemontwerppatronen, grotendeels rond gegevenstoegang, die we moeten herwerken terwijl we streven naar volledig actief-actief. Over het geheel genomen was het experiment succesvol genoeg om het door te laten gaan voor verkeer van een beperkt aantal van onze gebruikers.
We zijn blij dat we dit werk kunnen blijven voortzetten om het platform efficiënter en veerkrachtiger te maken. Dit werk aan cellen en actief-actieve infrastructuur, samen met onze andere inspanningen, zal het voor ons mogelijk maken om uit te groeien tot een betrouwbaar, goed presterend nutsbedrijf voor miljoenen mensen en om te blijven opschalen terwijl we werken aan het verbinden van een miljard mensen in reële omstandigheden. tijd.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://blog.roblox.com/2023/12/making-robloxs-infrastructure-efficient-resilient/

