Introductie
Artificial Intelligence heeft veel gebruiksscenario's, en enkele van de beste bevinden zich in de gezondheidssector. Het kan mensen echt helpen een gezonder leven te leiden. Met de toenemende hausse in generatieve AIworden bepaalde toepassingen tegenwoordig met minder complexiteit gemaakt. Een zeer nuttige applicatie die kan worden gebouwd, is de Calorie Advisor-app. In dit artikel zullen we hier alleen naar kijken, geïnspireerd door het zorgen voor onze gezondheid. We gaan een eenvoudige Calorie Advisor-app bouwen waarin we de afbeeldingen van het voedsel kunnen invoeren, en de app zal ons helpen de calorieën te berekenen van elk item dat in het voedsel aanwezig is. Dit project is onderdeel van NutriGen en richt zich op gezondheid door middel van AI.

Leerdoel
- De app die we in dit artikel gaan maken, is gebaseerd op basistechnieken van Prompt-engineering en beeldverwerking.
- We zullen de Google Gemini Pro Vision API gebruiken voor onze use case.
- Vervolgens zullen we de structuur van de code creëren, waar we Image Processing en Prompt Engineering zullen uitvoeren. Ten slotte zullen we werken aan de gebruikersinterface met behulp van Streamlit.
- Daarna zullen we onze app implementeren op de Gezicht knuffelen Platform gratis.
- We zullen ook enkele van de problemen zien waarmee we te maken zullen krijgen in de uitvoer waarbij Gemini er niet in slaagt een voedselproduct weer te geven en het verkeerde aantal calorieën voor dat voedsel weergeeft. We zullen ook verschillende oplossingen voor dit probleem bespreken.
Pre-Benodigdheden
Laten we beginnen met de implementatie van ons project, maar zorg ervoor dat u eerst een basiskennis heeft van generatieve AI en LLM's. Het is prima als je heel weinig weet, want in dit artikel zullen we de dingen helemaal opnieuw implementeren.
Voor Essential Python Prompt Engineering is een basiskennis van Generatieve AI en bekendheid met Google Gemini vereist. Daarnaast is basiskennis van Gestroomlijnd, GitHub en Gezicht knuffelen bibliotheken zijn noodzakelijk. Bekendheid met bibliotheken zoals PIL voor beeldvoorbewerking is ook een voordeel.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Projectpijplijn
In dit artikel gaan we werken aan het bouwen van een AI-assistent die voedingsdeskundigen en individuen helpt bij het nemen van weloverwogen beslissingen over hun voedingskeuzes en het handhaven van een gezonde levensstijl.
De stroom zal als volgt zijn: invoerafbeelding -> beeldverwerking -> prompt engineering -> laatste functieaanroep om de uitvoer van de invoerafbeelding van het voedsel te krijgen. Dit is een kort overzicht van hoe we deze probleemstelling gaan aanpakken.
Overzicht van Gemini Pro Vision
Gemini Pro is multimodaal LLM gebouwd door Google. Het is vanaf de basis getraind om multimodaal te zijn. Het kan goed presteren bij verschillende taken, waaronder ondertiteling van afbeeldingen, classificatie, samenvatting, vraagbeantwoording, enz. Een van de fascinerende feiten erover is dat het onze beroemde Transformer Decoder-architectuur gebruikt. Het werd getraind op meerdere soorten gegevens, waardoor de complexiteit van het oplossen van multimodale inputs werd verminderd en kwaliteitsoutputs werden geleverd.
Stap 1: Het creëren van de virtuele omgeving
Het creëren van een virtuele omgeving is een goede gewoonte om ons project en de afhankelijkheden ervan zodanig te isoleren dat ze niet samenvallen met andere, en we kunnen altijd verschillende versies van bibliotheken hebben die we nodig hebben in verschillende virtuele omgevingen. We gaan dus nu een virtuele omgeving voor het project creëren. Om dit te doen, volgt u de onderstaande stappen:
- Maak een lege map op het bureaublad voor het project.
- Open deze map in VS Code.
- Open de terminal.
Schrijf de volgende opdracht:
pip install virtualenv
python -m venv genai_projectU kunt de volgende opdracht gebruiken als u een sa et-uitvoeringsbeleidsfout krijgt:
Set-ExecutionPolicy RemoteSigned -Scope ProcessNu moeten we onze virtuele omgeving activeren, gebruik daarvoor het volgende commando:
.genai_projectScriptsactivateWe hebben met succes onze virtuele omgeving gecreëerd.
Stap Creëer een virtuele omgeving in Google Colab
We kunnen onze virtuele omgeving ook creëren in Google Colab; hier is de stapsgewijze procedure om dat te doen:
- Maak een nieuw Colab-notitieboekje
- Gebruik de onderstaande opdrachten stap voor stap
!which python
!python --version
#to check if python is installed or not%env PYTHONPATH=
# setting python path environment variable in empty value ensuring that python
# won't search for modules and packages in additional directory. It helps
# in avoiding conflicts or unintended module loading.!pip install virtualenv # create virtual environment
!virtualenv genai_project!wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
#This will help download the miniconda installer script which is used to create
# and manage virtual environments in python!chmod +x Miniconda3-latest-Linux-x86_64.sh
# this command is making our mini conda installer script executable within
# the colab environment. !./Miniconda3-latest-Linux-x86_64.sh -b -f -p /usr/local
# this is used to run miniconda installer script and
# specify the path where miniconda should be installed!conda install -q -y --prefix /usr/local python=3.8 ujson
#this will help install ujson and python 3.8 installation in our venv.import sys
sys.path.append('/usr/local/lib/python3.8/site-packages/')
#it will allow python to locate and import modules from a venv directoryimport os
os.environ['CONDA_PREFIX'] = '/usr/local/envs/myenv'
# used to activate miniconda enviornment
!python --version
#checks the version of python within the activated miniconda environmentDaarom hebben we onze virtuele omgeving ook in Google Colab gecreëerd. Laten we nu eens kijken hoe we daar een eenvoudig .py-bestand kunnen maken.
!source myenv/bin/activate
#activating the virtual environment!echo "print('Hello, world!')" >> my_script.py
# writing code using echo and saving this code in my_script.py file!python my_script.py
#running my_script.py fileHierdoor wordt Hello World voor ons afgedrukt in de uitvoer. Dus dat is het. Dat ging allemaal over het werken met virtuele omgevingen in Google Colab. Laten we nu doorgaan met het project.
Stap 2: Noodzakelijke bibliotheken importeren
import streamlit as st
import google.generativeaias genai
import os
from dotenv import load_dotenv
load_dotenv()
from PIL import ImageAls u problemen ondervindt bij het importeren van een van de bovenstaande bibliotheken, kunt u altijd het commando “pip install bibliotheeknaam” gebruiken om deze te installeren.
We gebruiken de Streamlit-bibliotheek om de basisgebruikersinterface te creëren. De gebruiker kan een afbeelding uploaden en de uitvoer verkrijgen op basis van die afbeelding.
We gebruiken Google Genative om de LLM te verkrijgen en analyseren de afbeelding om het aantal calorieën in ons voedsel per item te bepalen.
Afbeelding wordt gebruikt om een aantal basisvoorbewerkingen van afbeeldingen uit te voeren.
Stap 3: De API-sleutel instellen
Maak een nieuw .env-bestand in dezelfde map en sla uw API-sleutel op. Je kunt de Google krijgen Gemini-API sleutel van Google MakerSuite.
Stap 4: Reactiegeneratorfunctie
Hier zullen we een responsgeneratorfunctie maken. Laten we het stap voor stap opsplitsen:
Ten eerste hebben we genen gebruikt. Configureren om de API te configureren die we hebben gemaakt op de Google MakerSuite-website. Vervolgens hebben we de functie get_gemini_response gemaakt, die twee invoerparameters bevat: de invoerprompt en de afbeelding. Dit is de primaire functie die de uitvoer in tekst retourneert.
genai.configure(api_key=os.getenv("GOOGLE_API_KEY"))
def get_gemini_response(input_prompt, image):
model = genai.GenerativeModel('gemini-pro-vision')
response = model.generate_content([input_prompt, image[0]])
return responseHier gebruiken we het 'Gemini-pro-vision'-model omdat het multimodaal is. Nadat we ons model hebben aangeroepen vanuit de genie.GenerativeModel-afhankelijkheid, geven we alleen onze prompt en de afbeeldingsgegevens door aan het model. Ten slotte zal het model, op basis van de instructies in de prompt en de afbeeldingsgegevens die we hebben ingevoerd, de uitvoer retourneren in de vorm van tekst die het aantal calorieën weergeeft van de verschillende voedingsmiddelen die in de afbeelding aanwezig zijn.
Stap 5: Voorbewerking van afbeeldingen
Deze functie controleert of de parameter uploaded_file Geen is, wat betekent dat de gebruiker een bestand heeft geüpload. Als een bestand is geüpload, gaat de code verder met het lezen van de bestandsinhoud in bytes met behulp van de getvalue() -methode van het uploaded_file-object. Hierdoor worden de onbewerkte bytes van het geüploade bestand geretourneerd.
De bytesgegevens die uit het geüploade bestand worden verkregen, worden opgeslagen in een woordenboekindeling onder het sleutelwaardepaar ‘mime_type’ en ‘data’. De sleutel “mime_type” slaat het MIME-type van het geüploade bestand op, dat het type inhoud aangeeft (bijvoorbeeld afbeelding/jpeg, afbeelding/png). De “data”-sleutel slaat de onbewerkte bytes van het geüploade bestand op.
De afbeeldingsgegevens worden vervolgens opgeslagen in een lijst met de naam image_parts, die een woordenboek bevat met het MIME-type en de gegevens van het geüploade bestand.
def input_image_setup(uploaded_file):
if uploaded_file isnotNone:
#Read the file into bytes
bytes_data = uploaded_file.getvalue()
image_parts = [
{
"mime_type":uploaded_file.type,
"data":bytes_data
}
]
return image_parts
else:
raise FileNotFoundError("No file uploaded")
Stap 6: De gebruikersinterface maken
Dus eindelijk is het tijd om de gebruikersinterface voor ons project te maken. Zoals eerder vermeld, zullen we de Streamlit-bibliotheek gebruiken om de code voor de front-end te schrijven.
## initialising the streamlit app
st.set_page_config(page_title="Calories Advisor App")
st.header("Calories Advisor App")
uploaded_file = st.file_uploader("Choose an image...", type=["jpg", "jpeg", "png"])
image = ""
if uploaded_file isnotNone:
image = Image.open(uploaded_file)
st.image(image, caption="Uploaded Image", use_column_width=True)
submit = st.button("Tell me about the total calories")In eerste instantie hebben we de paginaconfiguratie ingesteld met set_page_config en de app een titel gegeven. Vervolgens hebben we een header gemaakt en een vak voor het uploaden van bestanden toegevoegd waarin gebruikers afbeeldingen kunnen uploaden. St. Image toont de afbeelding die de gebruiker naar de gebruikersinterface heeft geüpload. Eindelijk is er een verzendknop, waarna we de uitvoer van ons grote taalmodel, Gemini Pro Vision, krijgen.
Stap 7: De systeemprompt schrijven
Dit is het moment om creatief te zijn. Hier zullen we onze invoerprompt creëren, waarbij we het model vragen om op te treden als een deskundige voedingsdeskundige. Het is niet nodig om de onderstaande prompt te gebruiken; u kunt ook uw aangepaste prompt opgeven. We vragen ons model om voorlopig op een bepaalde manier te handelen. Op basis van de invoerafbeelding van het geleverde voedsel vragen we ons model om die afbeeldingsgegevens te lezen en de uitvoer te genereren, die ons het aantal calorieën geeft van de voedselproducten in de afbeelding en een oordeel geeft over de vraag of het voedsel gezond is. of ongezond. Als het voedsel schadelijk is, vragen we het om voedzamere alternatieven te bieden voor de voedselproducten naar ons beeld. U kunt het nog meer aanpassen aan uw behoeften en een uitstekende manier krijgen om uw gezondheid bij te houden.
Soms kan het de beeldgegevens niet goed lezen. Ook hiervoor bespreken we oplossingen aan het einde van dit artikel.
input_prompt = """
You are an expert nutritionist where you need to see the food items from the
image and calculate the total calories, also give the details of all
the food items with their respective calorie count in the below fomat.
1. Item 1 - no of calories
2. Item 2 - no of calories
----
----
Finally you can also mention whether the food is healthy or not and also mention
the percentage split ratio of carbohydrates, fats, fibers, sugar, protein and
other important things required in our diet. If you find that food is not healthy
then you must provide some alternative healthy food items that user can have
in diet.
"""
if submit:
image_data = input_image_setup(uploaded_file)
response = get_gemini_response(input_prompt, image_data)
st.header("The Response is: ")
st.write(response)Ten slotte controleren we of als de gebruiker op de knop Verzenden klikt, we de afbeeldingsgegevens van de
input_image_setup functie die we eerder hebben gemaakt. Vervolgens geven we onze invoerprompt en deze afbeeldingsgegevens door aan de get_gemini_response-functie die we eerder hebben gemaakt. We roepen alle functies aan die we eerder hebben gemaakt om de uiteindelijke uitvoer als reactie op te slaan.
Stap 8: De app implementeren op knuffelgezicht
Nu is het tijd voor implementatie. Laten we beginnen.
Zal de eenvoudigste manier uitleggen om deze app die we hebben gemaakt te implementeren. Er zijn twee opties waar we naar kunnen kijken als we onze app willen inzetten: de ene is Streamlit Share en de andere is Hugging Face. Hier zullen we Hugging Face gebruiken voor de inzet; je kunt de implementatie op Streamlit Share iFaceu proberen als je wilt. Hier is de referentielink daarvoor: implementatie op Streamlit Share
Laten we eerst snel het bestand require.txt maken dat we nodig hebben voor de implementatie.
Open de terminal en voer de onderstaande opdracht uit om een vereisten.txt-bestand te maken.
pip freeze > requirements.txt1plainTextHierdoor wordt een nieuw tekstbestand met de naam 'requirements' gemaakt. Alle projectafhankelijkheden zullen daar beschikbaar zijn. Als dit een fout veroorzaakt, is dat geen probleem. Je kunt altijd een nieuw tekstbestand in je werkmap maken en het bestand require.txt kopiëren en plakken via de GitHub-link die ik hierna zal geven.
Zorg er nu voor dat u deze bestanden bij de hand heeft (want dat hebben we nodig voor de implementatie):
- app.py
- .env (voor de API-inloggegevens)
- requirements.txt
Als je er geen hebt, neem dan al deze bestanden en maak een account aan op het knuffelgezicht. Maak vervolgens een nieuwe ruimte en upload de bestanden daar. Dat is alles. Uw app wordt op deze manier automatisch geïmplementeerd. U kunt ook in realtime zien hoe de implementatie plaatsvindt. Als er een fout optreedt, kunt u deze altijd achterhalen met de eenvoudige interface en natuurlijk de knuffelgezichtsgemeenschap, die veel inhoud bevat over het oplossen van enkele veelvoorkomende bugs tijdens de implementatie.
Na enige tijd zul je de app werkend kunnen zien. Woehoe! We hebben eindelijk onze app voor het voorspellen van calorieën gemaakt en geïmplementeerd. Gefeliciteerd!!, Je kunt de werkende link van de app delen met de vrienden en familie die je zojuist hebt gebouwd.
Hier is de werkende link naar de app die we zojuist hebben gemaakt: de Alorcalorieisor app
Laten we onze app testen door er een invoerafbeelding aan toe te voegen:
Vooraf:
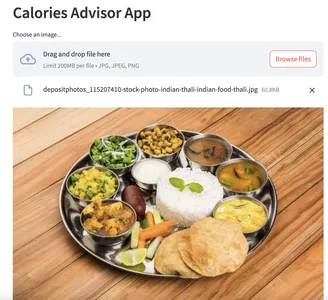
Na:

Voltooi de Project GitHub-link
Hier is de complete github repository-link die de broncode en andere nuttige informatie over het project bevat.
U kunt de repository klonen en aanpassen aan uw vereisten. Probeer creatiever en duidelijker te zijn in uw prompt, omdat dit uw model meer kracht geeft om correcte en correcte uitvoer te genereren.
Reikwijdte van verbetering
Problemen die kunnen optreden in de outputs die door het model worden gegenereerd en hun oplossingen:
Soms kunnen er situaties zijn waarin u niet de juiste uitvoer uit het model krijgt. Dit kan gebeuren omdat het model het beeld niet correct kon voorspellen. Als u bijvoorbeeld invoerafbeeldingen van uw voedsel geeft en uw voedselproduct augurken bevat, kan ons model dit als iets anders beschouwen. Dit is hier de voornaamste zorg.
- Eén manier om dit aan te pakken is door middel van effectieve prompt engineering-technieken, zoals Few-Shot Prompt Engineering, waarbij je het model kunt voeden met voorbeelden, en vervolgens de output zal genereren op basis van de lessen uit die voorbeelden en de prompt die je hebt gegeven.
- Een andere oplossing die hier kan worden overwogen, is het creëren van onze aangepaste gegevens en het verfijnen ervan. We kunnen gegevens creëren met een afbeelding van het voedselproduct in de ene kolom en een beschrijving van de voedselproducten in de andere kolom. Dit zal ons model helpen de onderliggende patronen te leren kennen en de items correct te voorspellen in de weergegeven afbeelding. Het is dus van essentieel belang dat u een correcter resultaat krijgt van het aantal calorieën voor de foto's van het voedsel.
- We kunnen nog een stap verder gaan door de gebruiker te vragen naar zijn/haar voedingsdoelen en het model te vragen op basis daarvan resultaten te genereren. (Op deze manier kunnen we de door het model gegenereerde output op maat maken en meer gebruikersspecifieke output geven.)
Conclusie
We hebben ons verdiept in de praktische toepassing van Generatieve AI in de gezondheidszorg, met de nadruk op de creatie van de Calorie Advisor App. Dit project toont het potentieel van AI om individuen te helpen bij het nemen van weloverwogen beslissingen over hun voedselkeuzes en het handhaven van een gezonde levensstijl. Van het opzetten van onze omgeving tot het implementeren van beeldverwerking en snelle engineeringtechnieken: we hebben de essentiële stappen besproken. De inzet van de app op Hugging Face demonstreert de toegankelijkheid ervan voor een breder publiek. Uitdagingen zoals onnauwkeurigheden in de beeldherkenning werden aangepakt met oplossingen zoals effectieve snelle engineering. Zoals we concluderen, is de Calorie Advisor-app een bewijs van de transformerende kracht van generatieve AI bij het bevorderen van welzijn.
Key Takeaways
- We hebben tot nu toe veel besproken, te beginnen met de projectpijplijn en vervolgens een basisintroductie van het grote taalmodel Gemini Pro Vision.
- Vervolgens zijn we begonnen met de praktijkgerichte implementatie. We hebben onze virtuele omgeving en API-sleutel gemaakt vanuit Google MakerSuite.
- Vervolgens hebben we al onze codering uitgevoerd in de gecreëerde virtuele omgeving. Verder bespraken we hoe we de app op meerdere platforms konden implementeren, zoals Hugging Face en Streamlit Share.
- Daarnaast hebben we gekeken naar de mogelijke problemen die kunnen optreden en de oplossingen voor die problemen besproken.
- Daarom was het leuk om aan dit project te werken. Bedankt dat je tot het einde van dit artikel bent gebleven; Ik hoop dat je iets nieuws hebt geleerd.
Veelgestelde Vragen / FAQ
Google heeft Gemini Pro Vision ontwikkeld, een gerenommeerde LLM die bekend staat om zijn multimodale mogelijkheden. Het voert taken uit zoals het ondertitelen, genereren en samenvatten van afbeeldingen. Gebruikers kunnen op de MakerSuite-website een API-sleutel aanmaken om toegang te krijgen tot Gemini Pro Vision.
A. Generatieve AI heeft veel potentieel voor het oplossen van problemen in de echte wereld. Enkele manieren waarop het kan worden toegepast op het gebied van gezondheid en voeding is dat het artsen kan helpen medicijnen voor te schrijven op basis van symptomen en kan optreden als voedingsadviseur, waar gebruikers gezonde aanbevelingen voor hun dieet kunnen krijgen.
A. Snelle engineering is tegenwoordig een essentiële vaardigheid die je onder de knie moet krijgen. De beste plek om trompt-engineering te leren, van basis tot gevorderd, is hier – https://www.promptingguide.ai/
A. Om het vermogen van het model om correctere resultaten te genereren te vergroten, kunnen we de volgende tactieken gebruiken: Effective Prompting, Fine Tuning en Retrieval-Augmented Generation (RAG).
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2024/04/how-to-build-a-calorie-advisor-app-using-genai/

