Dit is een gastpost die is geschreven in samenwerking met Brandon Abear, Dinesh Sharma, John Bush en Ozcan IIikhan van GoDaddy.
GoDaddy ondersteunt alledaagse ondernemers door alle hulp en hulpmiddelen te bieden om online succesvol te zijn. Met meer dan 20 miljoen klanten wereldwijd is GoDaddy de plek waar mensen naartoe komen om hun ideeën een naam te geven, een professionele website te bouwen, klanten aan te trekken en hun werk te beheren.
Bij GoDaddy zijn we er trots op een datagedreven bedrijf te zijn. Ons niet aflatende streven naar waardevolle inzichten uit data voedt onze zakelijke beslissingen en zorgt voor klanttevredenheid. Ons streven naar efficiëntie is onwrikbaar en we hebben een spannend initiatief ondernomen om onze batchverwerkingstaken te optimaliseren. Tijdens dit traject hebben we een gestructureerde aanpak geïdentificeerd die we de zeven lagen van verbetermogelijkheden noemen. Deze methodologie is onze leidraad geworden in het streven naar efficiëntie.
In dit bericht bespreken we hoe we de operationele efficiëntie hebben verbeterd met Amazon EMR Serverloos. We delen onze benchmarkresultaten en methodologie, en inzichten in de kosteneffectiviteit van EMR Serverless versus vaste capaciteit Amazon EMR op EC2 tijdelijke clusters op onze gegevensworkflows die zijn georkestreerd met behulp van Door Amazon beheerde workflows voor Apache Airflow (Amazone MWAA). We delen onze strategie voor de adoptie van EMR Serverless op gebieden waar deze uitblinkt. Onze bevindingen onthullen aanzienlijke voordelen, waaronder een kostenbesparing van meer dan 60%, 50% snellere Spark-workloads, een opmerkelijke vijfvoudige verbetering in de ontwikkelings- en testsnelheid en een aanzienlijke vermindering van onze ecologische voetafdruk.
Achtergrond
Eind 2020 startte het dataplatform van GoDaddy zijn AWS Cloud-reis, waarbij een Hadoop-cluster met 800 knooppunten en 2.5 PB aan gegevens werd gemigreerd van het datacenter naar EMR op EC2. Deze lift-and-shift-aanpak maakte een directe vergelijking tussen on-premises en cloud-omgevingen mogelijk, waardoor een soepele overgang naar AWS-pijplijnen werd verzekerd en gegevensvalidatieproblemen en migratievertragingen tot een minimum werden beperkt.
Begin 2022 hebben we onze big data-workloads met succes gemigreerd naar EMR op EC2. Met behulp van de best practices die we uit het AWS FinHack-programma hebben geleerd, hebben we resource-intensieve taken verfijnd, Pig- en Hive-taken omgezet naar Spark en onze batch-workload-uitgaven met 22.75% verlaagd in 2022. Er ontstonden echter schaalbaarheidsproblemen als gevolg van de veelheid aan taken . Dit was voor GoDaddy aanleiding om aan een systematisch optimalisatietraject te beginnen, waarmee een basis werd gelegd voor een duurzamere en efficiëntere verwerking van big data.
Zeven lagen met verbetermogelijkheden
In onze zoektocht naar operationele efficiëntie hebben we zeven verschillende lagen van mogelijkheden voor optimalisatie geïdentificeerd binnen onze batchverwerkingstaken, zoals weergegeven in de volgende afbeelding. Deze lagen variëren van nauwkeurige verbeteringen op codeniveau tot uitgebreidere platformverbeteringen. Deze meerlaagse aanpak is onze strategische blauwdruk geworden in het voortdurende streven naar betere prestaties en hogere efficiëntie.

De lagen zijn als volgt:
- Code-optimalisatie – Richt zich op het verfijnen van de codelogica en hoe deze kan worden geoptimaliseerd voor betere prestaties. Dit omvat prestatieverbeteringen door selectieve caching, partitie- en projectie-pruning, join-optimalisaties en andere taakspecifieke afstemming. Het gebruik van AI-coderingsoplossingen is ook een integraal onderdeel van dit proces.
- Software updates - Updaten naar de nieuwste versies van open source software (OSS) om te profiteren van nieuwe functies en verbeteringen. Adaptive Query Execution in Spark 3 zorgt bijvoorbeeld voor aanzienlijke prestatie- en kostenverbeteringen.
- Aangepaste Spark-configuraties - Afstemming van aangepaste Spark-configuraties om het resourcegebruik, het geheugen en het parallellisme te maximaliseren. We kunnen aanzienlijke verbeteringen bereiken door taken op de juiste maat te maken, zoals through
spark.sql.shuffle.partitions,spark.sql.files.maxPartitionBytes,spark.executor.coresenspark.executor.memory. Deze aangepaste configuraties kunnen echter contraproductief zijn als ze niet compatibel zijn met de specifieke Spark-versie. - Tijd voor het inrichten van resources - De tijd die nodig is om middelen zoals kortstondige EMR-clusters te lanceren Amazon Elastic Compute-cloud (Amazone EC2). Hoewel sommige factoren die van invloed zijn op deze tijd buiten de controle van een ingenieur vallen, kan het identificeren en aanpakken van de factoren die kunnen worden geoptimaliseerd de totale inrichtingstijd helpen verkorten.
- Fijnmazige schaling op taakniveau - Dynamisch aanpassen van bronnen zoals CPU, geheugen, schijf en netwerkbandbreedte op basis van de behoeften van elke fase binnen een taak. Het doel hier is om vaste clustergroottes te vermijden die tot verspilling van hulpbronnen zouden kunnen leiden.
- Fijnmazige schaling voor meerdere taken in een workflow - Aangezien elke taak unieke resourcevereisten heeft, kan het handhaven van een vaste resourcegrootte resulteren in onder- of overprovisioning voor bepaalde taken binnen dezelfde workflow. Traditioneel bepaalt de grootte van de grootste taak de clustergrootte voor een workflow met meerdere taken. Het dynamisch aanpassen van bronnen voor meerdere taken en stappen binnen een workflow resulteert echter in een kosteneffectievere implementatie.
- Verbeteringen op platformniveau – Verbeteringen op voorgaande lagen kunnen alleen een bepaalde taak of workflow optimaliseren. Platformverbetering is gericht op het bereiken van efficiëntie op bedrijfsniveau. We kunnen dit op verschillende manieren bereiken, zoals het updaten of upgraden van de kerninfrastructuur, het introduceren van nieuwe raamwerken, het toewijzen van de juiste middelen voor elk functieprofiel, het balanceren van het servicegebruik, het optimaliseren van het gebruik van spaarplannen en spotinstances, of het implementeren van andere uitgebreide veranderingen om de prestaties te verbeteren. efficiëntie voor alle taken en workflows.
Lagen 1–3: Eerdere kostenbesparingen
Nadat we van on-premise naar AWS Cloud waren gemigreerd, hebben we onze kostenoptimalisatie-inspanningen vooral geconcentreerd op de eerste drie lagen die in het diagram worden weergegeven. Door onze duurste oudere Pig- en Hive-pijplijnen over te zetten naar Spark en Spark-configuraties voor Amazon EMR te optimaliseren, hebben we aanzienlijke kostenbesparingen gerealiseerd.
Een oudere Pig-taak kostte bijvoorbeeld 10 uur om te voltooien en behoorde tot de top 10 van duurste EMR-taken. Bij het bekijken van TEZ-logboeken en clusterstatistieken ontdekten we dat het cluster enorm overbezet was voor het datavolume dat werd verwerkt en gedurende het grootste deel van de runtime onderbenut bleef. De overstap van Pig naar Spark was efficiënter. Hoewel er geen geautomatiseerde tools beschikbaar waren voor de conversie, zijn er handmatige optimalisaties doorgevoerd, waaronder:
- Minder onnodig schrijven naar schijven, waardoor serialisatie- en deserialisatietijd wordt bespaard (laag 1)
- Parallellisatie van Airflow-taken vervangen door Spark, waardoor de Airflow DAG wordt vereenvoudigd (laag 1)
- Overbodige Spark-transformaties geëlimineerd (laag 1)
- Geüpgraded van Spark 2 naar 3, met behulp van Adaptive Query Execution (Laag 2)
- Scheve verbindingen aangepakt en kleinere dimensietabellen geoptimaliseerd (laag 3)
Als gevolg hiervan daalden de taakkosten met 95% en werd de voltooiingstijd van de taak teruggebracht tot 1 uur. Deze aanpak was echter arbeidsintensief en niet schaalbaar voor tal van banen.
Lagen 4–6: Vind en implementeer de juiste computeroplossing
Eind 2022, na onze aanzienlijke prestaties op het gebied van optimalisatie op de vorige niveaus, verschoof onze aandacht naar het verbeteren van de resterende lagen.
Inzicht in de status van onze batchverwerking
We gebruiken Amazon MWAA om onze dataworkflows op grote schaal in de cloud te orkestreren. Apache-luchtstroom is een open source-tool die wordt gebruikt voor het programmatisch schrijven, plannen en monitoren van reeksen processen en taken, ook wel ' workflows. In dit bericht de voorwaarden workflow en baan worden door elkaar gebruikt, verwijzend naar de Directed Acyclic Graphs (DAG's), bestaande uit taken georkestreerd door Amazon MWAA. Voor elke workflow hebben we sequentiële of parallelle taken, en zelfs een combinatie van beide in de DAG ertussen create_emr en terminate_emr taken die worden uitgevoerd op een tijdelijk EMR-cluster met vaste rekencapaciteit gedurende de hele workflow. Zelfs nadat we een deel van onze werklast hadden geoptimaliseerd, hadden we nog steeds talloze niet-geoptimaliseerde workflows die onderbenut waren als gevolg van overmatige provisioning van computerbronnen op basis van de meest resource-intensieve taak in de workflow, zoals weergegeven in de volgende afbeelding.
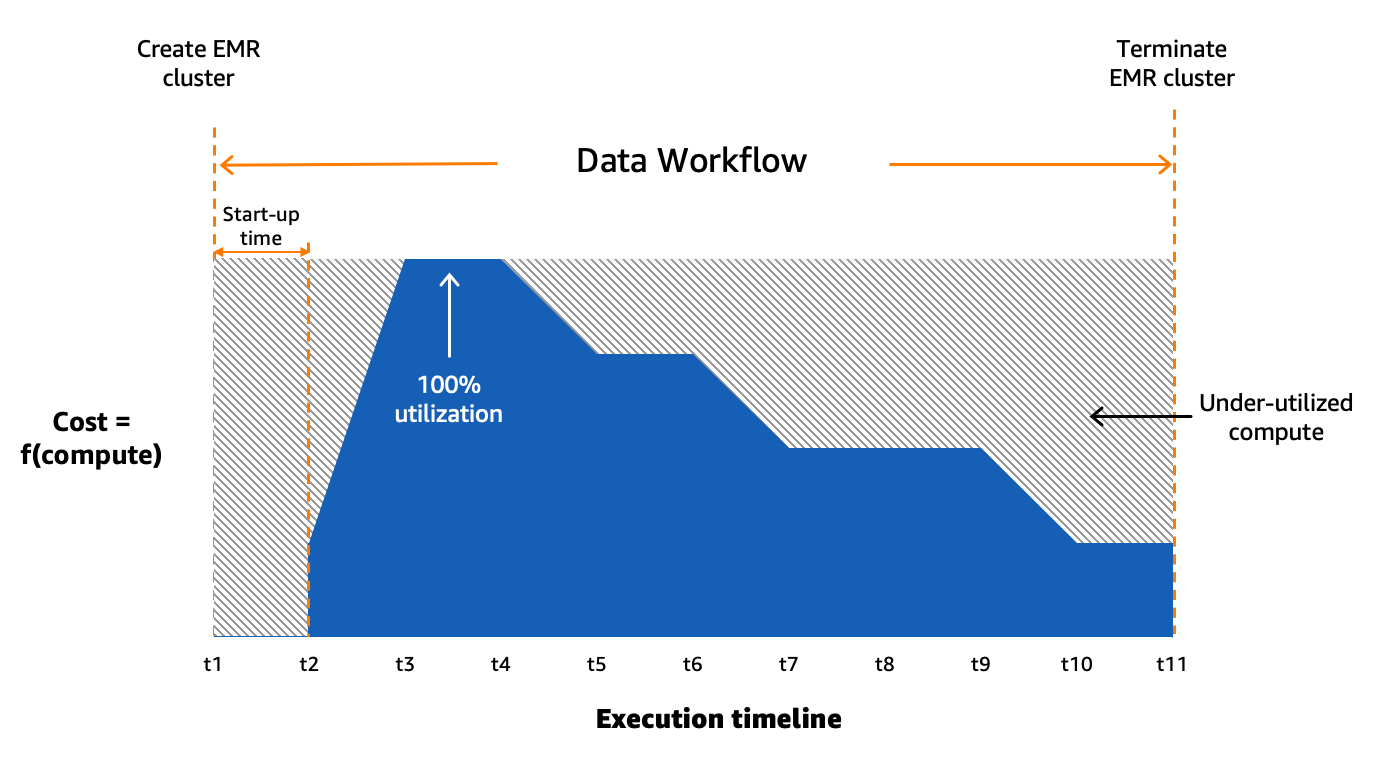
Dit benadrukte de onpraktischheid van statische toewijzing van hulpbronnen en bracht ons tot het onderkennen van de noodzaak van een dynamisch systeem voor toewijzing van hulpbronnen (DRA). Voordat we een oplossing voorstelden, hebben we uitgebreide gegevens verzameld om onze batchverwerking grondig te begrijpen. Het analyseren van de staptijd van het cluster, exclusief provisioning en inactieve tijd, bracht belangrijke inzichten aan het licht: een rechtsscheve verdeling waarbij meer dan de helft van de workflows in 20 minuten of minder wordt voltooid en slechts 10% meer dan 60 minuten in beslag neemt. Deze distributie was de leidraad voor onze keuze voor een snelle computeroplossing, waardoor de runtimes van de workflow drastisch werden verkort. Het volgende diagram illustreert de staptijden (exclusief inrichting en inactieve tijd) van EMR op tijdelijke EC2-clusters in een van onze batchverwerkingsaccounts.
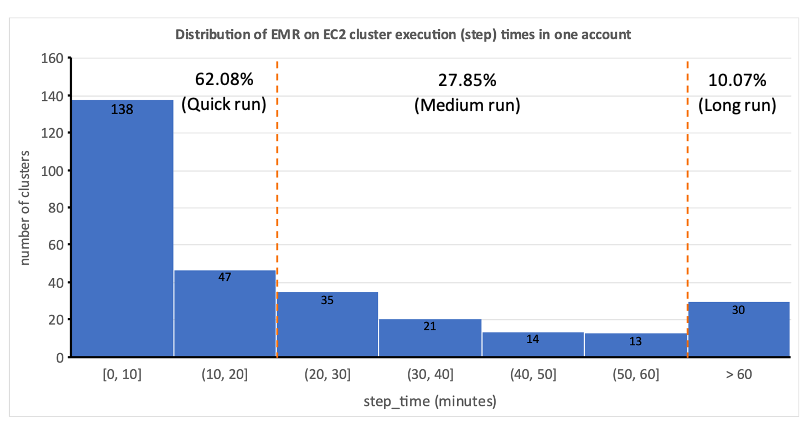
Bovendien hebben we, op basis van de staptijdverdeling (exclusief provisioning en inactieve tijd) van de workflows, onze workflows in drie groepen gecategoriseerd:
- Sprintje – Duurt 20 minuten of minder
- Middellange termijn – Duur tussen 20 en 60 minuten
- Lange termijn – Langer dan 60 minuten, vaak meerdere uren of langer
Een andere factor waarmee we rekening moesten houden, was het uitgebreide gebruik van tijdelijke clusters om redenen als veiligheid, banen- en kostenisolatie, en speciaal gebouwde clusters. Bovendien was er een aanzienlijke variatie in de behoefte aan hulpbronnen tussen piekuren en periodes van lage benutting.
In plaats van clusters van vaste grootte zouden we mogelijk beheerde schaling van EMR op EC2 kunnen gebruiken om enkele kostenvoordelen te behalen. De migratie naar EMR Serverless lijkt echter een meer strategische richting voor ons dataplatform. Naast potentiële kostenvoordelen biedt EMR Serverless extra voordelen, zoals een upgrade met één klik naar de nieuwste Amazon EMR-versies, een vereenvoudigde operationele en foutopsporingservaring en automatische upgrades naar de nieuwste generaties bij de uitrol. Deze functies vereenvoudigen gezamenlijk het proces van het exploiteren van een platform op grotere schaal.
Evaluatie van EMR Serverless: een casestudy bij GoDaddy
EMR Serverless is een serverloze optie in Amazon EMR die de complexiteit van het configureren, beheren en schalen van clusters elimineert bij het uitvoeren van big data-frameworks zoals Apache Spark en Apache Hive. Met EMR Serverless kunnen bedrijven profiteren van tal van voordelen, waaronder kosteneffectiviteit, snellere provisioning, vereenvoudigde ontwikkelaarservaring en verbeterde veerkracht bij storingen in de Availability Zone.
Omdat we het potentieel van EMR Serverless erkenden, hebben we een diepgaande benchmarkstudie uitgevoerd met behulp van echte productieworkflows. Het onderzoek had tot doel de prestaties en efficiëntie van EMR Serverless te beoordelen en tegelijkertijd een adoptieplan voor grootschalige implementatie te creëren. De bevindingen waren zeer bemoedigend en laten zien dat EMR Serverless onze werkdruk effectief kan verwerken.
Benchmarking methodologie
We hebben onze gegevensworkflows in drie categorieën verdeeld op basis van de totale staptijd (exclusief inrichting en inactieve tijd): snelle uitvoering (0-20 minuten), middellange uitvoering (20-60 minuten) en lange uitvoering (meer dan 60 minuten). We hebben de impact van het EMR-implementatietype (Amazon EC2 vs. EMR Serverless) geanalyseerd op twee belangrijke maatstaven: kostenefficiëntie en totale runtime-versnelling, die dienden als onze algemene evaluatiecriteria. Hoewel we het gebruiksgemak en de veerkracht niet formeel hebben gemeten, zijn deze factoren tijdens het evaluatieproces in aanmerking genomen.
De stappen op hoog niveau om het milieu te beoordelen zijn als volgt:
- Bereid de gegevens en omgeving voor:
- Kies drie tot vijf willekeurige productieopdrachten uit elke functiecategorie.
- Implementeer de benodigde aanpassingen om interferentie met de productie te voorkomen.
- Tests uitvoeren:
- Voer scripts uit over meerdere dagen of via meerdere iteraties om nauwkeurige en consistente gegevenspunten te verzamelen.
- Voer tests uit met EMR op EC2 en EMR Serverless.
- Valideer gegevens en testruns:
- Valideer invoer- en uitvoergegevenssets, partities en rijtellingen om identieke gegevensverwerking te garanderen.
- Verzamel statistieken en analyseer resultaten:
- Verzamel relevante statistieken uit de tests.
- Analyseer de resultaten om inzichten en conclusies te trekken.
Benchmarkresultaten
Onze benchmarkresultaten lieten significante verbeteringen zien in alle drie de functiecategorieën wat betreft zowel runtime-snelheid als kostenefficiëntie. De verbeteringen waren het meest uitgesproken voor snelle opdrachten, die rechtstreeks voortvloeiden uit snellere opstarttijden. Een gegevensworkflow van 20 minuten (inclusief het inrichten en afsluiten van het cluster) die wordt uitgevoerd op een EMR op een tijdelijk EC2-cluster met vaste rekencapaciteit, is bijvoorbeeld in 10 minuten voltooid op EMR Serverless, wat een kortere runtime oplevert met kostenvoordelen. Over het geheel genomen heeft de overstap naar EMR Serverless aanzienlijke prestatieverbeteringen en kostenbesparingen op schaal voor alle taakgroepen opgeleverd, zoals te zien is in de volgende afbeelding.
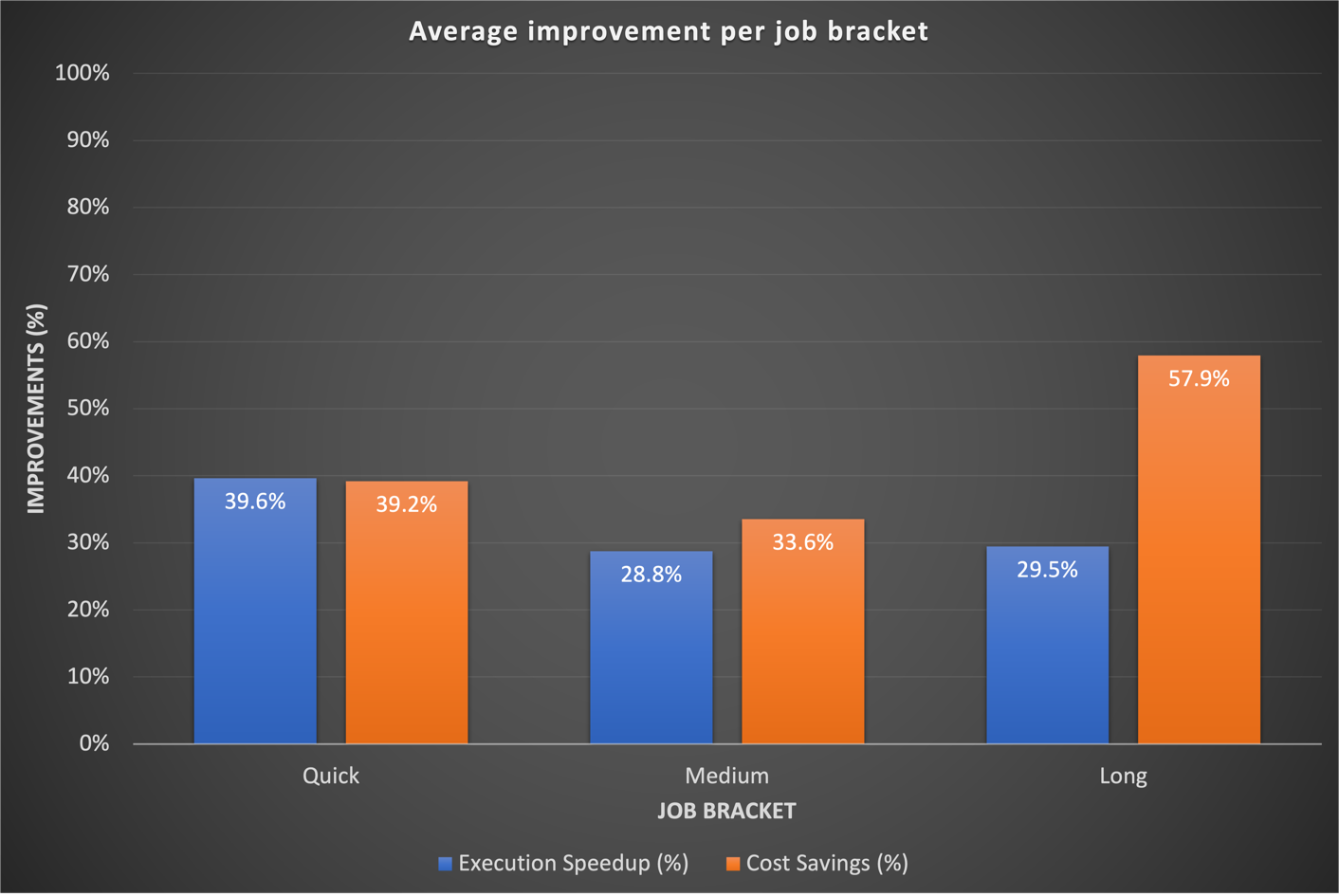
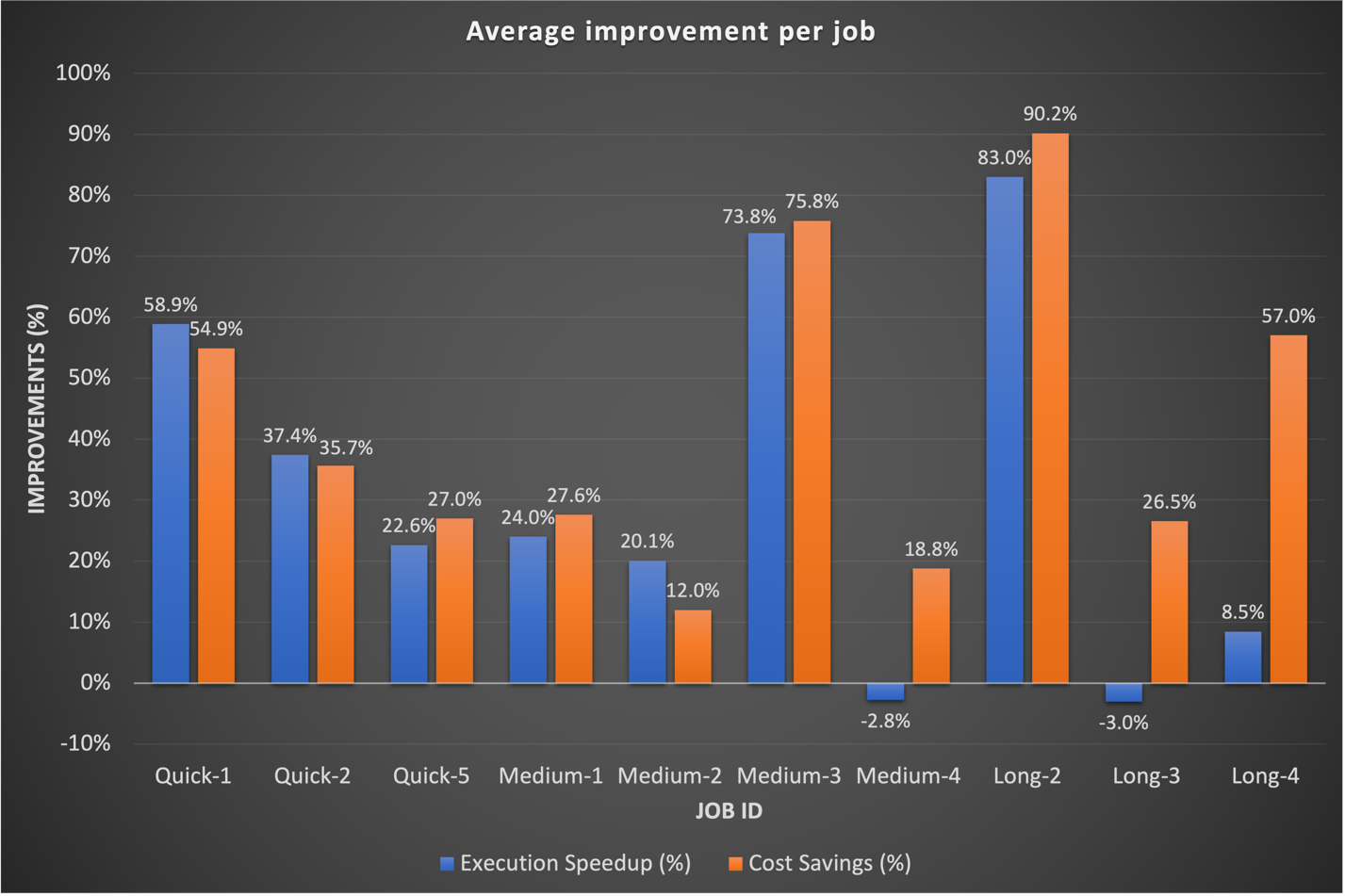
Historisch gezien besteedden we meer tijd aan het afstemmen van onze langetermijnworkflows. Interessant genoeg ontdekten we dat de bestaande aangepaste Spark-configuraties voor deze taken niet altijd goed vertaalden naar EMR Serverless. In gevallen waarin de resultaten onbeduidend waren, was een gebruikelijke aanpak het weggooien van eerdere Spark-configuraties met betrekking tot executorkernen. Door EMR Serverless deze Spark-configuraties autonoom te laten beheren, hebben we vaak betere resultaten waargenomen. De volgende grafiek toont de gemiddelde runtime- en kostenverbetering per taak bij het vergelijken van EMR Serverless met EMR op EC2.
De volgende tabel toont een voorbeeldvergelijking van resultaten voor dezelfde workflow die wordt uitgevoerd op verschillende implementatieopties van Amazon EMR (EMR op EC2 en EMR Serverless).
| metrisch | EMR op EC2 (Gemiddelde) |
EMR-serverloos (Gemiddelde) |
EMR op EC2 vs EMR-serverloos |
| Totale exploitatiekosten ($) | $ 5.82 | $ 2.60 | 55% |
| Totale looptijd (minuten) | 53.40 | 39.40 | 26% |
| Voorzieningentijd (minuten) | 10.20 | 0.05 | . |
| Voorzieningenkosten ($) | € 1.19 | . | . |
| Stappen Tijd (minuten) | 38.20 | 39.16 | -3% |
| Stappenkosten ($) | € 4.30 | . | . |
| Inactieve tijd (minuten) | 4.80 | . | . |
| EMR-vrijgavelabel | emr-6.9.0 | . | |
| Hadoop-distributie | Amazon 3.3.3 | . | |
| Spark-versie | Vonk 3.3.0 | . | |
| Hive/HCatalog-versie | Hive 3.1.3, HCatalog 3.1.3 | . | |
| Type baan | Vonk | . | |
AWS Graviton2 op EMR Serverloze prestatie-evaluatie
Nadat we overtuigende resultaten hadden gezien met EMR Serverless voor onze workloads, hebben we besloten de prestaties van de AWS Graviton2 (arm64) architectuur binnen EMR Serverless. AWS had gebenchmarkt Verhoog de workloads op Graviton2 EMR Serverless met behulp van de TPC-DS 3TB-schaal, wat een algemene prijs-prestatieverbetering van 27% oplevert.
Om de voordelen van de integratie beter te begrijpen, hebben we ons eigen onderzoek uitgevoerd met behulp van GoDaddy's productiewerklasten volgens een dagelijks schema en hebben we een indrukwekkende prijs-prestatieverbetering van 23.8% waargenomen bij een reeks taken bij het gebruik van Graviton2. Voor meer details over dit onderzoek, zie GoDaddy-benchmarking resulteert in een tot 24% betere prijs-prestatieverhouding voor hun Spark-workloads met AWS Graviton2 op Amazon EMR Serverless.
Adoptiestrategie voor EMR Serverless
We hebben op strategische wijze een gefaseerde uitrol van EMR Serverless geïmplementeerd via implementatieringen, waardoor systematische integratie mogelijk is. Dankzij deze geleidelijke aanpak kunnen we verbeteringen valideren en, indien nodig, de verdere adoptie van EMR Serverless stopzetten. Het diende zowel als vangnet om problemen vroegtijdig op te sporen als als middel om onze infrastructuur te verfijnen. Het proces verzachtte de impact van veranderingen door soepele operaties en bouwde tegelijkertijd de teamexpertise van onze Data Engineering- en DevOps-teams op. Bovendien zorgde het voor nauwe feedbackloops, waardoor snelle aanpassingen mogelijk waren en een efficiënte EMR-serverloze integratie werd gegarandeerd.
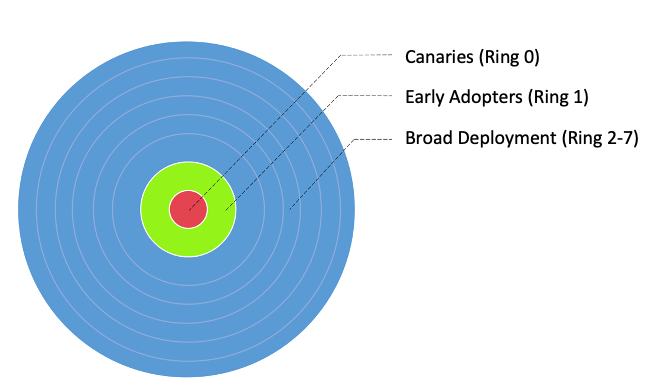
We hebben onze workflows onderverdeeld in drie hoofdadoptiegroepen, zoals weergegeven in de volgende afbeelding:
- Kanarie - Deze groep helpt bij het opsporen en oplossen van eventuele problemen in een vroeg stadium van de implementatie.
- Vroege adoptanten - Dit is de tweede reeks workflows die de nieuwe computeroplossing adopteren nadat de eerste problemen zijn geïdentificeerd en verholpen door de Canaries-groep.
- Brede inzetringen - De grootste groep ringen, deze groep vertegenwoordigt de grootschalige inzet van de oplossing. Deze worden ingezet na succesvol testen en implementeren in de voorgaande twee groepen.
We hebben deze workflows verder opgesplitst in gedetailleerde implementatieringen om EMR Serverless te implementeren, zoals weergegeven in de volgende tabel.
| Ring # | Naam | Details |
| ring 0 | Kanarie | Banen met een laag adoptierisico die naar verwachting enige kostenbesparende voordelen zullen opleveren. |
| ring 1 | Early Adopters | Laag risico Snelle uitvoering Zorg voor banen die naar verwachting hoge winsten zullen opleveren. |
| ring 2 | Sprintje | Rest van de snelle run (step_time <= 20 min) Spark-taken |
| ring 3 | GrotereJobs_EZ | Hoge potentiële winst, gemakkelijke verplaatsing, Spark-banen op middellange en lange termijn |
| ring 4 | Grotere banen | Rest van de middellange en lange termijn Spark-banen met potentiële winst |
| ring 5 | Bijenkorf | Voeg banen bij met potentieel hogere kostenbesparingen |
| ring 6 | Roodverschuiving_EZ | Eenvoudige migratie Redshift-taken die geschikt zijn voor EMR Serverloos |
| ring 7 | Lijm_EZ | Eenvoudige migratie Lijmklussen die bij EMR passen Serverloos |
Samenvatting van de resultaten van productie-adoptie
De bemoedigende resultaten op het gebied van benchmarking en canary-adoptie zorgden voor aanzienlijke belangstelling voor een bredere adoptie van EMR Serverless bij GoDaddy. Tot op heden is de uitrol van EMR Serverless nog steeds aan de gang. Tot nu toe heeft het de kosten met 62.5% verlaagd en de voltooiing van de totale batchworkflow met 50.4% versneld.
Op basis van voorlopige benchmarks verwachtte ons team aanzienlijke winsten voor snelle klussen. Tot onze verbazing overtroffen de daadwerkelijke productie-implementaties de verwachtingen, gemiddeld 64.4% sneller versus 42% verwacht, en 71.8% goedkoper versus 40% voorspeld.
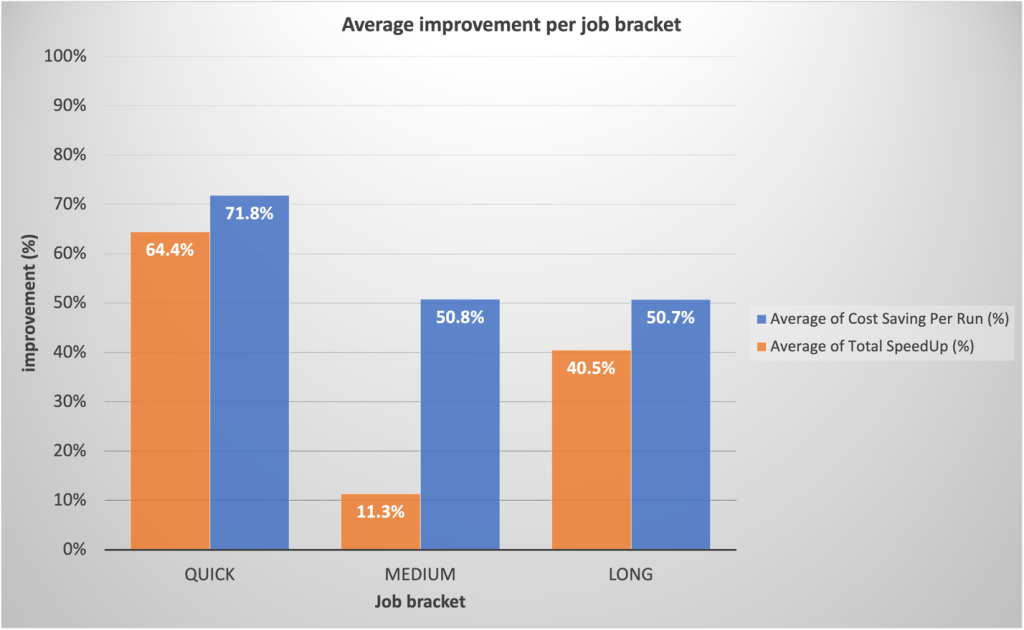
Opmerkelijk is dat langlopende taken ook aanzienlijke prestatieverbeteringen kenden dankzij de snelle provisioning van EMR Serverless en agressieve schaling, mogelijk gemaakt door dynamische toewijzing van bronnen. We hebben een substantiële parallellisatie waargenomen tijdens segmenten met veel resources, resulterend in een 40.5% snellere totale runtime vergeleken met traditionele benaderingen. Het volgende diagram illustreert de gemiddelde verbeteringen per functiecategorie.
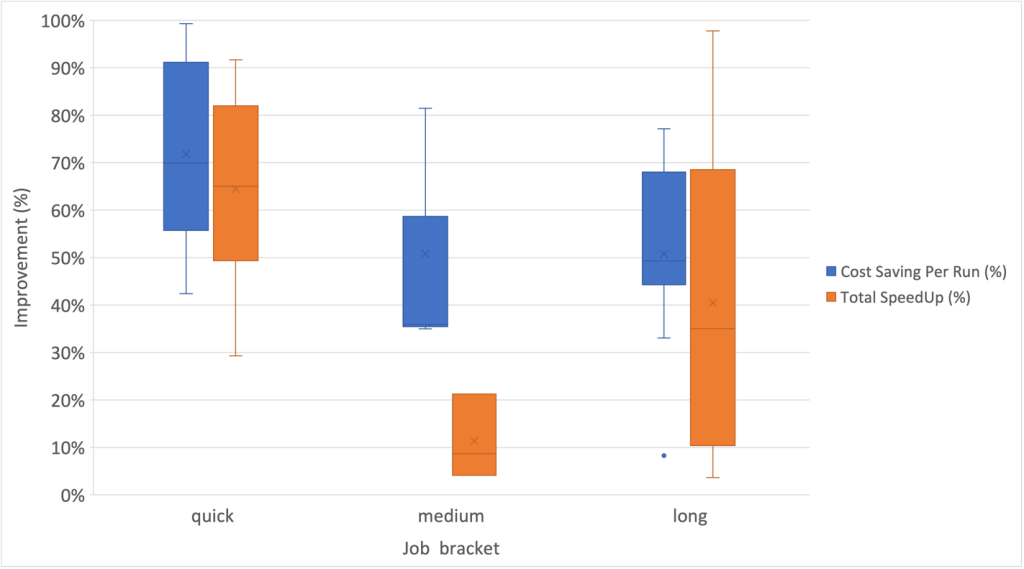
Bovendien hebben we de hoogste mate van spreiding waargenomen voor snelheidsverbeteringen binnen de functiecategorie op de lange termijn, zoals weergegeven in de volgende box-and-whisker-grafiek.
Voorbeeldworkflows met EMR Serverless
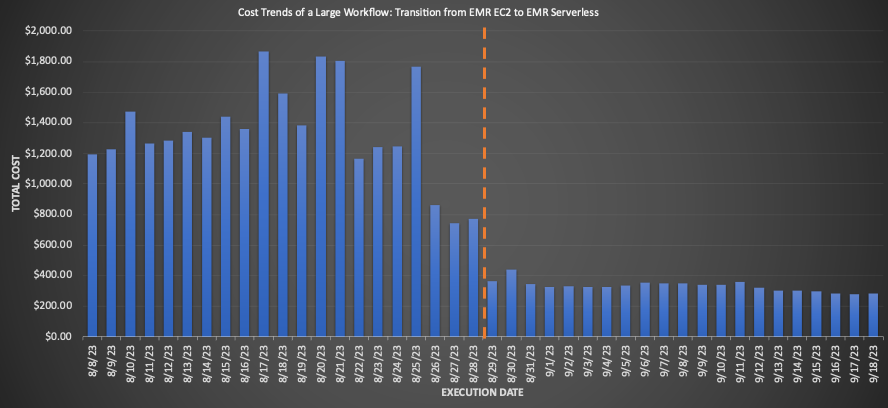
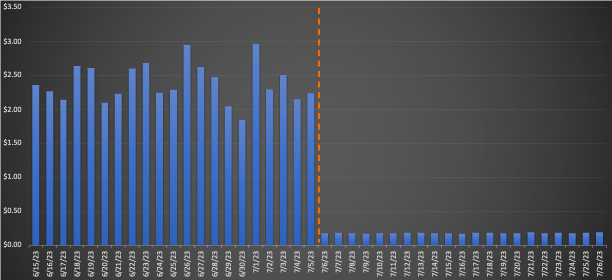
Voor een grote workflow die naar EMR Serverless werd gemigreerd, bracht het vergelijken van de gemiddelden over drie weken vóór en na de migratie indrukwekkende kostenbesparingen aan het licht: een daling van 3% op basis van retailprijzen met een verbetering van 75.30% in de totale runtime, wat de operationele efficiëntie ten goede komt. De volgende grafiek illustreert de kostenontwikkeling.
Hoewel snel uitgevoerde opdrachten een minimale kostenbesparing per dollar opleverden, leverden ze de grootste procentuele kostenbesparing op. Omdat duizenden van deze workflows dagelijks worden uitgevoerd, zijn de totale besparingen aanzienlijk. De volgende grafiek toont de kostentrend voor een kleine werklast die is gemigreerd van EMR op EC2 naar EMR Serverless. Een vergelijking van de gemiddelden over drie weken vóór en na de migratie bracht een opmerkelijke kostenbesparing van 3% op de on-demand retailprijzen aan het licht, naast een versnelling van 92.43% in de totale runtime.
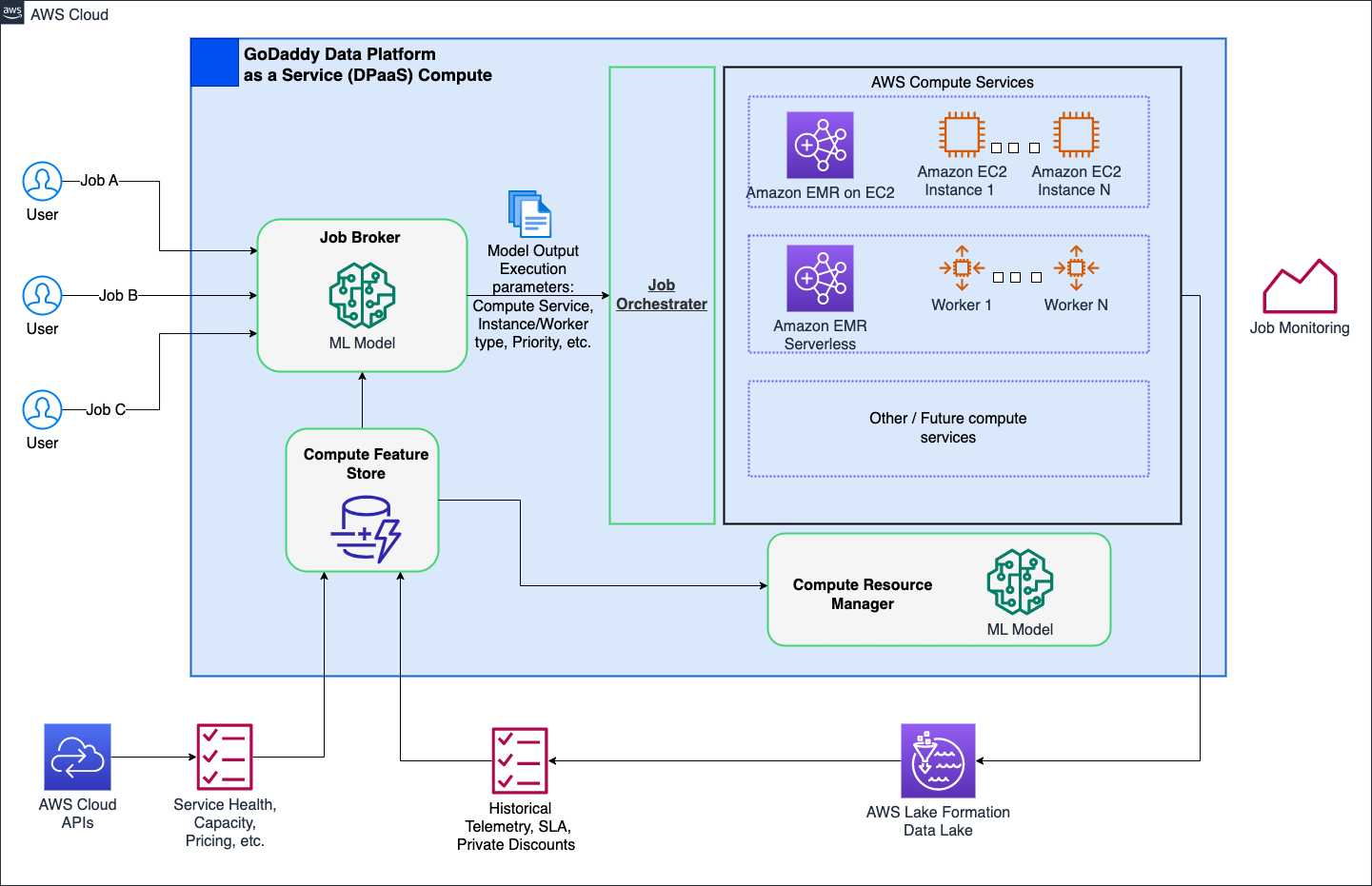
Laag 7: Platformbrede verbeteringen
We streven ernaar een revolutie teweeg te brengen in de computeractiviteiten bij GoDaddy, door vereenvoudigde maar krachtige oplossingen te bieden voor alle gebruikers met ons Intelligent Compute Platform. Met AWS-rekenoplossingen zoals EMR Serverless en EMR op EC2 zorgde het voor geoptimaliseerde runs van dataverwerking en machine learning (ML)-workloads. Een door ML aangedreven opdrachtmakelaar bepaalt op intelligente wijze wanneer en hoe opdrachten moeten worden uitgevoerd op basis van verschillende parameters, terwijl hoofdgebruikers nog steeds de mogelijkheid hebben om deze aan te passen. Bovendien kan een op ML gebaseerde Compute Resource Manager resources vooraf inrichten op basis van de belasting en historische gegevens, waardoor een efficiënte, snelle inrichting tegen optimale kosten wordt geboden. Intelligente rekenkracht biedt gebruikers kant-en-klare optimalisatie, waarbij diverse persona's worden bediend zonder dat de hoofdgebruikers in gevaar komen.
Het volgende diagram toont een illustratie op hoog niveau van de intelligente computerarchitectuur.
Inzichten en aanbevolen best practices
In het volgende gedeelte worden de inzichten besproken die we hebben verzameld en de aanbevolen best practices die we hebben ontwikkeld tijdens onze voorbereidende en bredere adoptiefasen.
Voorbereiding van de infrastructuur
Hoewel EMR Serverless een implementatiemethode binnen EMR is, vereist het enige paraatheid van de infrastructuur om het potentieel ervan te optimaliseren. Houd rekening met de volgende vereisten en praktische richtlijnen voor de implementatie:
- Gebruik grote subnetten over meerdere beschikbaarheidszones – Wanneer u serverloze EMR-workloads uitvoert binnen uw VPC, zorg er dan voor dat de subnetten zich over meerdere beschikbaarheidszones uitstrekken en niet worden beperkt door IP-adressen. Verwijzen naar VPC-toegang configureren en Best practices voor subnetplanning voor meer info.
- Wijzig het maximale gelijktijdige vCPU-quotum - Voor uitgebreide rekenvereisten wordt aanbevolen om uw max. aantal gelijktijdige vCPU's per account servicequotum.
- Compatibiliteit met Amazon MWAA-versies - Bij de adoptie van EMR Serverless zorgde GoDaddy's gedecentraliseerde Amazon MWAA-ecosysteem voor datapijplijnorkestratie voor compatibiliteitsproblemen bij verschillende AWS Providers-versies. Het direct upgraden van Amazon MWAA was efficiënter dan het updaten van talloze DAG's. We hebben de adoptie gefaciliteerd door zelf Amazon MWAA-instances te upgraden, problemen te documenteren en bevindingen en inspanningsschattingen te delen voor een nauwkeurige upgradeplanning.
- GoDaddy EMR-operator - Om de migratie van talloze Airflow DAG's van EMR op EC2 naar EMR Serverless te stroomlijnen, hebben we aangepaste operators ontwikkeld die bestaande interfaces aanpassen. Dit maakte naadloze overgangen mogelijk met behoud van bekende afstemmingsopties. Data-ingenieurs kunnen pijplijnen eenvoudig migreren met eenvoudige zoek-vervang-import en onmiddellijk EMR Serverless gebruiken.
Beperking van onverwacht gedrag
Hier volgen enkele onverwachte gedragingen die we zijn tegengekomen en wat we hebben gedaan om deze te beperken:
- Spark DRA agressieve schaling - Voor sommige banen (8.33% van de initiële benchmarks, 13.6% van de productie) stegen de kosten na de migratie naar EMR Serverless. Dit was te wijten aan het feit dat Spark DRA nieuwe medewerkers buitensporig kortstondig toewees, waarbij prestatie prioriteit kreeg boven kosten. Om dit tegen te gaan, stellen we maximale uitvoerderdrempels in door deze aan te passen
spark.dynamicAllocation.maxExecutor, waardoor EMR Serverless-schalingsagressie effectief wordt beperkt. Wanneer u migreert van EMR op EC2, raden we u aan het maximale aantal kernen in de gebruikersinterface van Spark History te observeren om vergelijkbare rekenlimieten in EMR Serverless te repliceren, zoals--conf spark.executor.coresen--conf spark.dynamicAllocation.maxExecutors. - Schijfruimte beheren voor grootschalige taken - Bij het overzetten van taken die grote gegevensvolumes verwerken met aanzienlijke shuffles en aanzienlijke schijfvereisten naar EMR Serverless, raden we aan om
spark.emr-serverless.executor.diskdoor te verwijzen naar bestaande Spark-taakstatistieken. Bovendien zijn configuraties zoalsspark.executor.coresgecombineerd metspark.emr-serverless.executor.diskenspark.dynamicAllocation.maxExecutorsmaken controle mogelijk over de onderliggende werkgrootte en de totale aangesloten opslag wanneer dat voordelig is. Een shuffle-zware taak met een relatief laag schijfgebruik kan bijvoorbeeld baat hebben bij het gebruik van een grotere werker om de kans op lokaal ophalen in willekeurige volgorde te vergroten.
Conclusie
Zoals besproken in dit bericht zijn onze ervaringen met het adopteren van EMR Serverless op arm64 overweldigend positief. De indrukwekkende resultaten die we hebben behaald, waaronder een kostenbesparing van 60%, een 50% snellere uitvoering van batch-Spark-workloads en een verbazingwekkende vijfvoudige verbetering in de ontwikkelings- en testsnelheid, spreken boekdelen over het potentieel van deze technologie. Bovendien suggereren onze huidige resultaten dat we, door Graviton2 op EMR Serverless op grote schaal toe te passen, de CO60-voetafdruk voor onze batchverwerking mogelijk met wel XNUMX% kunnen verminderen.
Het is echter van cruciaal belang om te begrijpen dat deze resultaten geen one-size-fits-all scenario zijn. De verbeteringen die u kunt verwachten zijn afhankelijk van factoren, waaronder, maar niet beperkt tot, de specifieke aard van uw workflows, clusterconfiguraties, resourcegebruiksniveaus en schommelingen in de rekencapaciteit. Daarom pleiten wij sterk voor een datagestuurde, ringgebaseerde implementatiestrategie wanneer we de integratie van EMR Serverless overwegen, wat kan helpen de voordelen ervan optimaal te optimaliseren.
Met speciale dank aan Mukul Sharma en Boris Berlijn voor hun bijdragen aan benchmarking. Hartelijk dank aan Travis Mühlestein (CDO), Abhijit Kundu (VP Engels), Vincent Yong (Sr. Directeur Eng.), en Wai Kin Lau (Sr. Directeur Data Eng.) voor hun voortdurende steun.
Over de auteurs
 Brandon Abeer is een Principal Data Engineer in de Data & Analytics (DNA)-organisatie bij GoDaddy. Hij houdt van alles wat met big data te maken heeft. In zijn vrije tijd houdt hij van reizen, films kijken en ritmespellen spelen.
Brandon Abeer is een Principal Data Engineer in de Data & Analytics (DNA)-organisatie bij GoDaddy. Hij houdt van alles wat met big data te maken heeft. In zijn vrije tijd houdt hij van reizen, films kijken en ritmespellen spelen.
 Dinesh Sharma is een Principal Data Engineer in de Data & Analytics (DNA)-organisatie bij GoDaddy. Hij heeft een passie voor gebruikerservaring en productiviteit van ontwikkelaars, waarbij hij altijd op zoek is naar manieren om engineeringprocessen te optimaliseren en kosten te besparen. In zijn vrije tijd houdt hij van lezen en is hij een fervent mangafan.
Dinesh Sharma is een Principal Data Engineer in de Data & Analytics (DNA)-organisatie bij GoDaddy. Hij heeft een passie voor gebruikerservaring en productiviteit van ontwikkelaars, waarbij hij altijd op zoek is naar manieren om engineeringprocessen te optimaliseren en kosten te besparen. In zijn vrije tijd houdt hij van lezen en is hij een fervent mangafan.
 Johannes Bush is een Principal Software Engineer in de Data & Analytics (DNA)-organisatie bij GoDaddy. Hij heeft een passie om het voor organisaties gemakkelijker te maken om gegevens te beheren en deze te gebruiken om hun bedrijf vooruit te helpen. In zijn vrije tijd houdt hij van wandelen, kamperen en fietsen op zijn e-bike.
Johannes Bush is een Principal Software Engineer in de Data & Analytics (DNA)-organisatie bij GoDaddy. Hij heeft een passie om het voor organisaties gemakkelijker te maken om gegevens te beheren en deze te gebruiken om hun bedrijf vooruit te helpen. In zijn vrije tijd houdt hij van wandelen, kamperen en fietsen op zijn e-bike.
 Ozcan Ilikhan is technisch directeur voor het data- en ML-platform bij GoDaddy. Hij heeft meer dan twintig jaar multidisciplinaire leiderschapservaring, van startups tot mondiale ondernemingen. Hij heeft een passie voor het inzetten van data en AI bij het creëren van oplossingen die klanten blij maken, hen in staat stellen meer te bereiken en de operationele efficiëntie te vergroten. Buiten zijn professionele leven houdt hij van lezen, wandelen, tuinieren, vrijwilligerswerk doen en aan doe-het-zelf-projecten beginnen.
Ozcan Ilikhan is technisch directeur voor het data- en ML-platform bij GoDaddy. Hij heeft meer dan twintig jaar multidisciplinaire leiderschapservaring, van startups tot mondiale ondernemingen. Hij heeft een passie voor het inzetten van data en AI bij het creëren van oplossingen die klanten blij maken, hen in staat stellen meer te bereiken en de operationele efficiëntie te vergroten. Buiten zijn professionele leven houdt hij van lezen, wandelen, tuinieren, vrijwilligerswerk doen en aan doe-het-zelf-projecten beginnen.
 Moeilijk Vardhan is een AWS Solutions Architect, gespecialiseerd in big data en analytics. Hij heeft ruim 8 jaar ervaring op het gebied van big data en data science. Hij heeft een passie voor het helpen van klanten bij het toepassen van best practices en het ontdekken van inzichten uit hun data.
Moeilijk Vardhan is een AWS Solutions Architect, gespecialiseerd in big data en analytics. Hij heeft ruim 8 jaar ervaring op het gebied van big data en data science. Hij heeft een passie voor het helpen van klanten bij het toepassen van best practices en het ontdekken van inzichten uit hun data.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/how-the-godaddy-data-platform-achieved-over-60-cost-reduction-and-50-performance-boost-by-adopting-amazon-emr-serverless/

