In een moderne gegevensarchitectuur kunt u met uniforme analyses toegang krijgen tot de gegevens die u nodig hebt, ongeacht of deze zijn opgeslagen in een datameer of een datawarehouse. We zien met name een toenemend aantal klanten die hun gegevens combineren en integreren in een Amazon roodverschuiving datawarehouse om enorme hoeveelheden gegevens op schaal te analyseren en complexe query's uit te voeren om hun zakelijke doelen te bereiken.
Een van de meest voorkomende use-cases voor gegevensvoorbereiding op Amazon Redshift is het opnemen en transformeren van gegevens uit verschillende datastores in een Amazon Redshift-datawarehouse. Dit wordt meestal bereikt via AWS lijm, een serverloze, schaalbare gegevensintegratieservice die het gemakkelijker maakt om gegevens uit meerdere bronnen te ontdekken, voor te bereiden, te verplaatsen en te integreren. AWS Glue biedt een uitbreidbare architectuur die gebruikers in staat stelt met verschillende gebruiksscenario's voor gegevensverwerking, en werkt goed samen met Amazon Redshift. Op AWS re:Invent 2022 hebben we ondersteuning aangekondigd voor de nieuwe Amazon Redshift-integratie met Apache Spark beschikbaar in AWS Glue 4.0, dat verbeterde ETL- (extract, transform en load) en ELT-mogelijkheden biedt met verbeterde prestaties.
Vandaag kondigen we met genoegen nieuwe en verbeterde mogelijkheden voor het schrijven van visuele taken aan voor Amazon Redshift ETL- en ELT-workflows op de visuele editor van AWS Glue Studio. De nieuwe ontwerpervaring biedt u de mogelijkheid om:
- Ga sneller aan de slag met Amazon Redshift door direct door Amazon Redshift-schema's en -tabellen te bladeren vanuit de visuele interface van AWS Glue Studio
- Flexibele authoring via native Amazon Redshift SQL-ondersteuning als bron of aangepaste preactions en postactions
- Vereenvoudig algemene bewerkingen voor het laden van gegevens in Amazon Redshift door nieuwe ondersteuning voor INSERT-, TRUNCATE-, DROP- en MERGE-opdrachten
Met deze verbeteringen kun je bestaande transformaties en connectoren in AWS Glue Studio gebruiken om snel datapijplijnen voor Amazon Redshift te maken. Gebruikers zonder code kunnen end-to-end-taken uitvoeren met alleen de visuele interface, SQL-gebruikers kunnen hun bestaande Amazon Redshift SQL binnen AWS Glue hergebruiken en alle gebruikers kunnen hun logica afstemmen met aangepaste acties op de visuele editor.
In dit bericht verkennen we de nieuwe gestroomlijnde gebruikersinterface en gaan we dieper in op het gebruik van deze mogelijkheden. Om deze nieuwe mogelijkheden te demonstreren, laten we het volgende zien:
- Een aangepaste SQL JOIN-instructie doorgeven aan Amazon Redshift
- De resultaten gebruiken om een AWS Glue Studio visuele transformatie toe te passen
- Een APPEND uitvoeren op de resultaten om ze in een bestemmingstabel te laden
Resources instellen met AWS CloudFormation
Om de visuele editorervaring van AWS Glue Studio met Amazon Redshift te demonstreren, bieden we een AWS CloudFormatie sjabloon waarmee u snel basisresources kunt instellen. De sjabloon maakt de volgende bronnen voor u aan:
- Een Amazon VPC, subnetten, routetabellen, een internetgateway en NAT-gateways
- Een Amazon Redshift-cluster
- An AWS Identiteits- en toegangsbeheer (IAM) rol geassocieerd met het Amazon Redshift-cluster
- Een IAM-rol voor het uitvoeren van de AWS Glue-taak
- An Amazon eenvoudige opslagservice (Amazon S3) bucket om te gebruiken als tijdelijke locatie voor Amazon Redshift ETL
- An AWS-geheimenmanager geheim dat de gebruikersnaam en het wachtwoord voor het Amazon Redshift-cluster opslaat
Merk op dat op het moment van schrijven van dit bericht Amazon Redshift MERGE in preview is en dat het gemaakte cluster een preview-cluster is.
Voer de volgende stappen uit om de CloudFormation-stack te starten:
- Kies op de AWS CloudFormation-console Maak een stapel en kies dan Met nieuwe middelen (standaard).

- Voor Sjabloonbronselecteer Upload een sjabloonbestand, en upload het verstrekte sjabloon.
- Kies Volgende.
- Voer een naam in voor de CloudFormation-stack en kies vervolgens Volgende.

- Erken dat deze stapel IAM-resources voor u kan creëren en maak vervolgens uw keuze Verzenden.
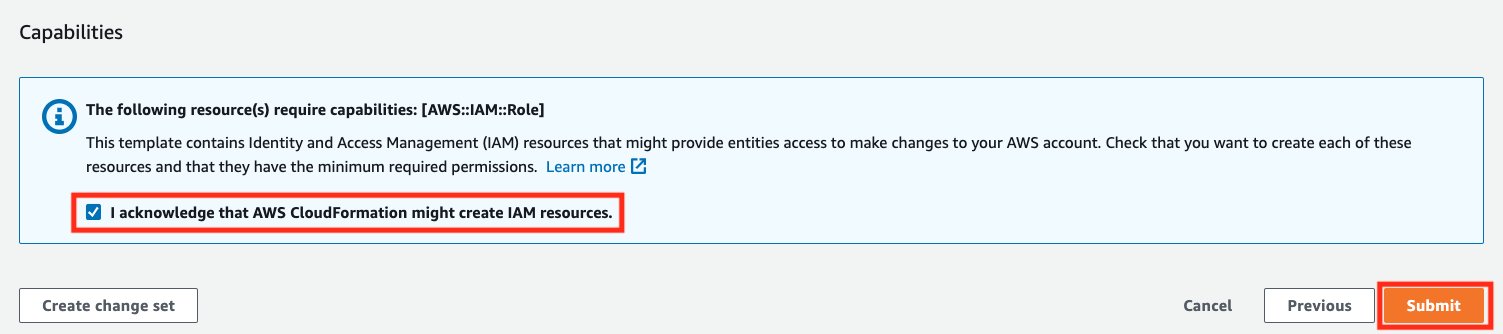
- Nadat de CloudFormation-stack met succes is gemaakt, volgt u de stappen vermeld bij https://docs.aws.amazon.com/redshift/latest/gsg/rs-gsg-create-sample-db.html om voorbeeldticketgegevens in de gemaakte Redshift-cluster te laden
Verkennen van Amazon Redshift leest
In deze sectie bespreken we de nieuwe leesfunctionaliteit in de visuele editor van AWS Glue Studio en laten we zien hoe we een aangepaste SQL-instructie kunnen uitvoeren via de nieuwe gebruikersinterface.
- Kies op de AWS Glue-console: ETL-banen in het navigatievenster.

- Selecteer het Visueel met een leeg canvas, omdat we een taak helemaal opnieuw schrijven, kies dan creëren.

- Kies in het lege canvas het plusteken om een Amazon Redshift-knooppunt van het type toe te voegen bron.

Wanneer u de knooppuntselector sluit, zou u een Amazon Redshift-bronknooppunt op het canvas moeten zien, samen met de eigenschappen van de gegevensbron.

U kunt kiezen uit twee methoden om toegang te krijgen tot uw Amazon Redshift-gegevens:
- Directe dataverbinding - Met deze nieuwe methode kunt u een verbinding tot stand brengen met uw Amazon Redshift-bronnen zonder dat u ze hoeft te catalogiseren
- Glue Data Catalog-tabellen - Voor deze methode moet u uw Amazon Redshift-tabellen al hebben gecrawld of gegenereerd in de AWS Glue Data Catalog
Voor dit bericht gebruiken we de Directe dataverbinding optie.
- Voor Redshift-toegangstype, Selecteert u de Directe dataverbinding.
- Voor Roodverschuiving verbinding, kies je AWS Glue Connection
redshift-demo-blog-connectiongemaakt in de CloudFormation-stack.
Door de verbinding op te geven, worden automatisch alle netwerkgerelateerde details geconfigureerd, samen met de naam van de database waarmee u verbinding wilt maken.
De gebruikersinterface biedt vervolgens een keuze over hoe u toegang wilt krijgen tot de gegevens vanuit de database van uw geselecteerde Amazon Redshift-cluster:
- Kies een enkele tafel – Met deze optie kunt u een enkel schema en een enkele tabel uit uw database selecteren. U kunt direct vanuit de AWS Glue Studio visuele editor zelf door al uw beschikbare schema's en tabellen bladeren, waardoor het kiezen van uw brontabel veel eenvoudiger wordt.

- Voer een aangepaste zoekopdracht in - Als u uw ETL wilt uitvoeren op een subset van gegevens uit uw Amazon Redshift-tabellen, kunt u een Amazon Redshift-query schrijven vanuit de gebruikersinterface van AWS Glue Studio. Deze query wordt doorgegeven aan het verbonden Amazon Redshift-cluster en het geretourneerde queryresultaat is beschikbaar in downstream-transformaties op AWS Glue Studio.
Voor de doeleinden van dit bericht schrijven we onze eigen aangepaste query die gegevens uit de vooraf geladen gegevens samenvoegt event tafel en venue tafel.
- kies Voer een aangepaste zoekopdracht in en voer de volgende query in de query-editor in:
De bedoeling van deze query is om de venueid van de locaties die tussen 2008-01-01 14:00:00 en 2008-01-01 15:00:00 een evenement hebben gehad en venueseats = 0. Als we een vergelijkbare query uitvoeren vanuit de Amazon Redshift Query Editor, kunnen we zien dat er binnen dat tijdsbestek in feite vijf van dergelijke locaties zijn. We willen deze gegevens weer samenvoegen in Amazon Redshift zonder deze rijen op te nemen.
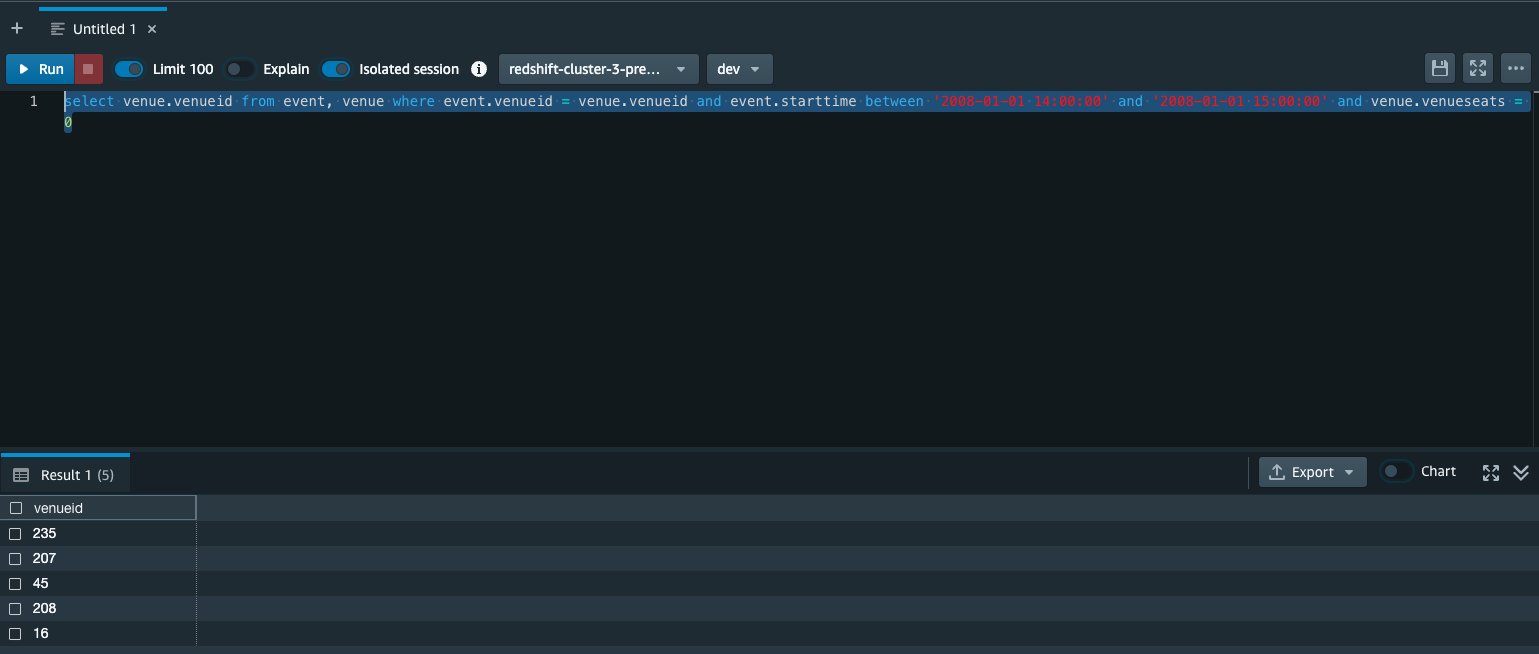
- Kies Schema afleiden, waarmee de visuele editor van AWS Glue Studio het schema van de geretourneerde kolommen van uw query kan begrijpen.

U kunt het schema zien op de Uitvoerschema Tab.
- Onder Prestaties en beveiligingvoor S3 staging-directory, kies de S3 tijdelijke maplocatie gemaakt door de CloudFormation-stack ( RoodverschuivingS3TempPath ).
- Voor IAM-rol, kies de IAM-rol gespecificeerd door RoodverschuivingIamRoleARN in de CloudFormation-stack.

Nu gaan we een transformatie toevoegen om dubbele rijen uit ons join-resultaat te verwijderen. Dit zorgt ervoor dat de MERGE-bewerking in de volgende stappen geen conflicterende sleutels heeft bij het uitvoeren van de bewerking.
- Kies de Laat duplicaten vallen node om de node-eigenschappen weer te geven.

- Op de Transformeren tabblad, voor Duplicaten laten vallenselecteer Pas specifieke sleutels aan.
- Voor Sleutels om rijen te matchen, kiezen
venueid.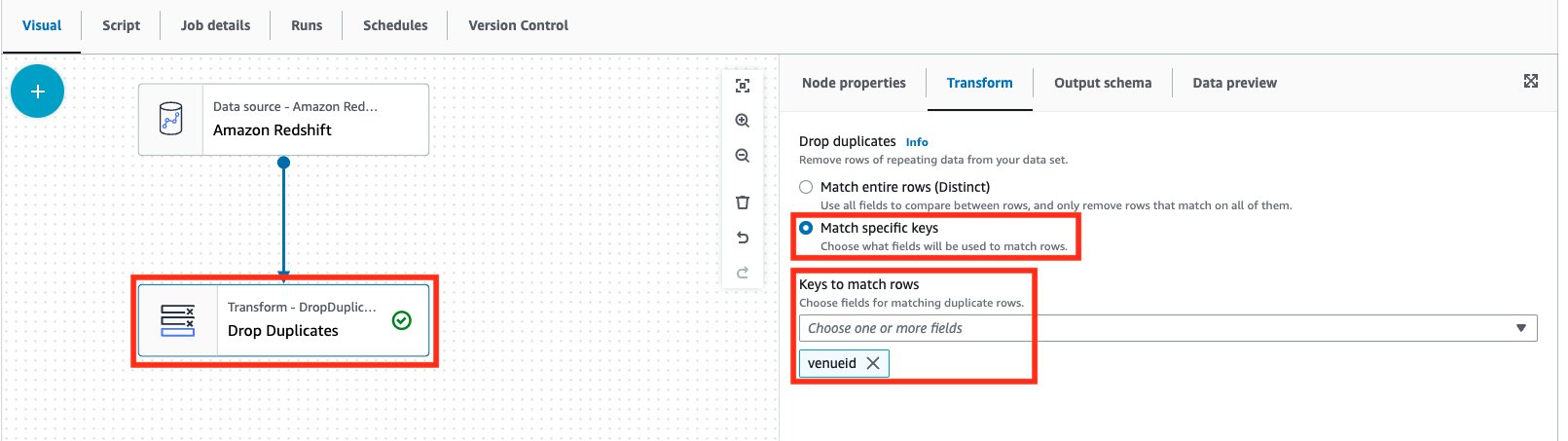
In deze sectie hebben we de stappen gedefinieerd om de uitvoer van een aangepaste JOIN-query te lezen. Vervolgens hebben we de dubbele records van de geretourneerde waarde verwijderd. In de volgende sectie onderzoeken we het schrijfpad voor dezelfde taak.
Amazon verkennen Redshift schrijft
Nu bespreken we de verbeteringen voor het schrijven naar Amazon Redshift als bestemming. Deze sectie behandelt alle vereenvoudigde opties voor het schrijven naar Amazon Redshift, maar belicht de nieuwe Amazon Redshift MERGE-mogelijkheden voor de doeleinden van dit bericht.
De MERGE-operator biedt grote flexibiliteit voor het voorwaardelijk samenvoegen van rijen van een bron naar een bestemmingstabel. MERGE is krachtig omdat het bewerkingen vereenvoudigt die traditioneel alleen haalbaar waren door meerdere insert-, update- of delete-instructies afzonderlijk te gebruiken. Binnen AWS Glue Studio, met name met de aangepaste MERGE-optie, kunt u een complexere overeenkomstvoorwaarde definiëren om het vinden van de bij te werken records af te handelen.
- Selecteer op de canvaspagina van de taak die in de vorige sectie is gebruikt Amazon roodverschuiving om een Amazon Redshift-knooppunt van het type toe te voegen doelwit.

Wanneer u de selector sluit, zou u uw Amazon Redshift-doelknooppunt moeten zien toegevoegd aan het Amazon Glue Studio-canvas, samen met mogelijke opties.
- Voor Redshift-toegangstype, kiezen Directe dataverbinding.
Vergelijkbaar met het Amazon Redshift-bronknooppunt, de Directe dataverbinding methode kunt u rechtstreeks naar uw Amazon Redshift-tabellen schrijven zonder dat u ze hoeft te catalogiseren in de AWS Glue Data Catalog.
- Voor Roodverschuiving verbinding, kies je AWS Glue-verbinding
redshift-demo-blog-connectiongemaakt in de CloudFormation-stack.
- Voor Schema, kiezen publiek.

- Voor tafel, kies de plaats table als de bestemmings-Amazon Redshift-tabel waar we de samengevoegde gegevens zullen opslaan.
- Kies MERGE gegevens in de doeltabel.
Deze selectie biedt de gebruiker twee opties:
- Kies toetsen en eenvoudige acties – Dit is een gebruiksvriendelijke versie van de MERGE-bewerking. U specificeert eenvoudig de overeenkomende sleutels en kiest wat er gebeurt met de rijen die overeenkomen met de sleutel (update ze of verwijder ze) of die geen overeenkomsten hebben (voeg ze in).
- Voer een aangepaste MERGE-instructie in – Deze optie biedt de meeste flexibiliteit. U kunt uw eigen aangepaste logica invoeren voor MERGE.
Voor dit bericht gebruiken we de methode eenvoudige acties voor het uitvoeren van een MERGE-bewerking.
- Voor Verwerking van gegevens en doeltabelselecteer MERGE gegevens in de doeltabelEn selecteer Kies toetsen en eenvoudige acties.
- Voor Bijpassende sleutelsselecteer
venueid.
Dit veld wordt onze MERGE-voorwaarde voor het controleren van sleutels
- Voor Wanneer afgestemd, Selecteert u de Record in de tabel verwijderen
- Voor Wanneer niet afgestemdselecteer Voeg brongegevens in als een nieuwe rij in de tabel

Met deze selecties hebben we de AWS Glue-taak geconfigureerd om een MERGE-instructie uit te voeren op Amazon Redshift tijdens het invoegen van onze gegevens. Bovendien gebruiken we voor het uitvoeren van deze MERGE-bewerking de als toets (u kunt meerdere toetsen selecteren). Als er een sleutelovereenkomst is met het record van de bestemmingstabel, verwijderen we dat record. Anders voegen we het record in de bestemmingstabel in.
- Navigeer naar de Details van de baan Tab.
- Voor Naam, voer een naam in voor de taak.
- Selecteer voor de vervolgkeuzelijst IAM-rol de RoodverschuivingIk benRol rol die is gemaakt via de CloudFormation-sjabloon.
- Kies Besparen.

- Kies lopen en wacht tot de klus is geklaard.
U kunt de voortgang volgen op de Runs Tab.
- Nadat de run een succesvolle status heeft bereikt, navigeert u terug naar de Amazon Redshift Query Editor.
- Voer dezelfde query opnieuw uit om te ontdekken dat die rijen zijn verwijderd in overeenstemming met onze MERGE-specificaties.

In deze sectie hebben we een Amazon Redshift-doelknooppunt geconfigureerd om een MERGE-instructie te schrijven om records voorwaardelijk bij te werken in onze bestemmings-Amazon Redshift-tabel. Vervolgens hebben we de AWS Glue-taak opgeslagen en uitgevoerd, en we zagen het effect van de MERGE-instructie op onze bestemming Amazon Redshift-tabel.
Andere beschikbare schrijfopties
Naast MERGE ondersteunt het Amazon Redshift-bestemmingsknooppunt van de visuele editor van AWS Glue Studio ook een aantal andere veelvoorkomende bewerkingen:
- APPEND – Toevoegen aan uw doeltabel voert een invoeging uit in de geselecteerde tabel zonder een van de bestaande records bij te werken (als er duplicaten zijn, blijven beide records behouden). In gevallen waarin u naast het toevoegen van nieuwe rijen ook bestaande rijen wilt bijwerken (vaak een UPSERT-bewerking genoemd), kunt u de Werk ook bestaande records in de doeltabel bij keuze. Merk op dat zowel alleen APPEND als UPSERT (APPEND met UPDATE) een eenvoudiger subset zijn van de eerder besproken MERGE-functionaliteit.
- AFKNOPEN – De TRUNCATE-optie wist alle gegevens in de bestaande tabel maar behoudt al het bestaande tabelschema, gevolgd door een TOEVOEGEN van alle nieuwe gegevens aan de lege tabel. Deze optie wordt vaak gebruikt wanneer de volledige dataset moet worden vernieuwd en downstream-services of -tools afhankelijk zijn van consistentie van het tabelschema. Elke nacht moet bijvoorbeeld een Amazon Redshift-tabel volledig worden bijgewerkt met de nieuwste klantinformatie die door een Amazon QuickSight dashboard. In dit geval zou de ETL-ontwikkelaar TRUNCATE kiezen om ervoor te zorgen dat de gegevens volledig worden vernieuwd, maar dat het tabelschema gegarandeerd niet verandert.
- DROP – Deze optie wordt gebruikt wanneer de volledige dataset moet worden vernieuwd en de downstream-services of tools die afhankelijk zijn van het schema of de systemen mogelijke schemawijzigingen kunnen verwerken zonder te breken.
Hoe schrijfbewerkingen worden afgehandeld op de backend
De Amazon Redshift-connector ondersteunt twee parameters genoemd preactions en postactions. Met deze parameters kunt u SQL-instructies uitvoeren die worden doorgegeven aan het Amazon Redshift-datawarehouse voor en nadat de daadwerkelijke schrijfbewerking door Spark is uitgevoerd.
Op de Script tabblad op de AWS Glue Studio-pagina, kunnen we zien welke SQL-statements worden uitgevoerd.

Gebruik een aangepaste implementatie voor het schrijven van gegevens naar Amazon Redshift
In het geval dat de geleverde presets meer maatwerk vereisen, of uw use case meer geavanceerde implementaties vereist voor het schrijven naar Amazon Redshift, kunt u met AWS Glue Studio ook vrij selecteren welke preactions en postactions kunnen worden uitgevoerd bij het schrijven naar Amazon Redshift.
Om een voorbeeld te geven, maken we een Amazon Redshift-datashare als een preaction, voer dan het opschonen van dezelfde datashare uit als een postaction via AWS Glue Studio.
OPMERKING: dit gedeelte wordt niet uitgevoerd als onderdeel van de bovenstaande blog en wordt als voorbeeld gegeven.
- Kies het Amazon Redshift-gegevensdoelknooppunt.
- Op de Eigenschappen van gegevensdoel tabblad, vouw het uit Aangepaste roodverschuivingsparameters pagina.
- Voeg voor de parameters het volgende toe:
- Parameter:
preactionsmet waardeBEGIN; CREATE DATASHARE ds1; END - Parameter:
postactionsmet waardeBEGIN; DROP DATASHARE ds1; END
- Parameter:

Zoals je kunt zien, kunnen we meerdere Amazon Redshift-statements specificeren als onderdeel van zowel de preactions en postactions parameters. Onthoud dat deze uitspraken alle bestaande preactions of postactions zullen overschrijven met uw gespecificeerde acties (zoals u kunt zien in de volgende gegenereerde code).

Opruimen
Zorg ervoor dat u alle onnodige bronnen en bestanden verwijdert om extra kosten te voorkomen:
- Leeg en verwijder de inhoud van de tijdelijke S3-bucket
- Als u de voorbeeld-CloudFormation-stack hebt geïmplementeerd, verwijdert u de CloudFormation-stack via de AWS CloudFormation-console. Zorg ervoor dat maak de S3-emmer leeg voordat u de bucket verwijdert.
Conclusie
In dit bericht hebben we de nieuwe visuele opties van AWS Glue Studio besproken voor het uitvoeren van lees- en schrijfbewerkingen van Amazon Redshift. We zagen ook de eenvoud waarmee je door je Amazon Redshift-tabellen kunt bladeren, rechtstreeks vanuit de gebruikersinterface van de visuele editor van AWS Glue Studio, en hoe je je eigen aangepaste SQL-instructies kunt uitvoeren tegen je Amazon Redshift-bronnen. Vervolgens hebben we onderzocht hoe eenvoudige ETL-laadtaken tegen Amazon Redshift met slechts een paar klikken kunnen worden uitgevoerd, en hebben we de nieuwe Amazon Redshift MERGE-instructie gepresenteerd.
Ga naar om dieper in te gaan op de nieuwe Amazon Redshift-integraties voor de visuele editor van AWS Glue Studio Verbinding maken met Redshift in AWS Glue Studio.
Over de auteurs
 Aniket Jidigoudar is een Big Data Architect in het AWS Glue-team. Hij werkt samen met klanten om hun big data-workloads te helpen verbeteren. In zijn vrije tijd houdt hij van nieuwe gerechten uitproberen, videogames spelen en kickboksen.
Aniket Jidigoudar is een Big Data Architect in het AWS Glue-team. Hij werkt samen met klanten om hun big data-workloads te helpen verbeteren. In zijn vrije tijd houdt hij van nieuwe gerechten uitproberen, videogames spelen en kickboksen.
 Sean Ma is een Principal Product Manager in het AWS Glue-team. Hij heeft meer dan 18 jaar ervaring in het innoveren en leveren van zakelijke producten die de kracht van data voor gebruikers ontsluiten. Naast zijn werk houdt Sean van duiken en universiteitsvoetbal.
Sean Ma is een Principal Product Manager in het AWS Glue-team. Hij heeft meer dan 18 jaar ervaring in het innoveren en leveren van zakelijke producten die de kracht van data voor gebruikers ontsluiten. Naast zijn werk houdt Sean van duiken en universiteitsvoetbal.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/exploring-new-etl-and-elt-capabilities-for-amazon-redshift-from-the-aws-glue-studio-visual-editor/

