Afbeelding door Redacteur | Leerstroom overbrengen van Skyengine.ai
Als het gaat om machine learning, waar de honger naar data onverzadigbaar is, heeft niet iedereen de luxe om toegang te krijgen tot enorme datasets om in een opwelling van te leren – dat is waar overdracht leren komt u te hulp, vooral als u met beperkte gegevens zit of als de kosten voor het aanschaffen van meer gegevens gewoon te hoog zijn.
Dit artikel gaat dieper in op de magie van transfer learning en laat zien hoe het op slimme wijze gebruik maakt van modellen die al hebben geleerd van enorme datasets om uw eigen machine learning-projecten een aanzienlijke boost te geven, zelfs als uw gegevens aan de kleine kant zijn.
Ik ga de hindernissen aanpakken die gepaard gaan met het werken in omgevingen met weinig gegevens, een kijkje nemen in wat de toekomst zou kunnen brengen, en de veelzijdigheid en effectiviteit vieren van overdrachtsonderwijs op allerlei verschillende gebieden.
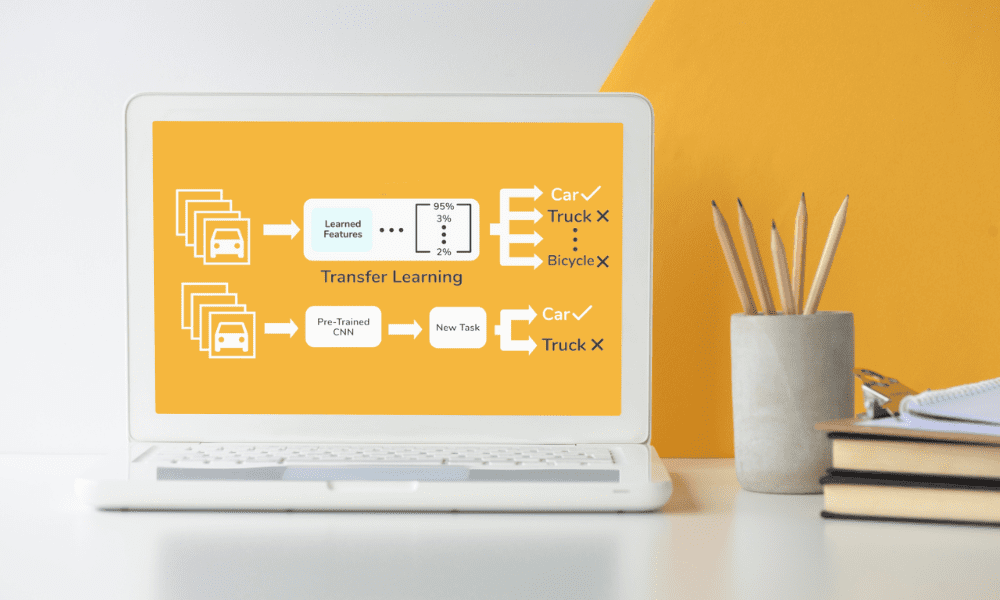
Transferleren is een techniek die wordt gebruikt bij machinaal leren waarbij een model dat voor de ene taak is ontwikkeld, wordt hergebruikt voor een tweede, gerelateerde taak, en het verder wordt ontwikkeld.
In de kern berust deze benadering op het idee dat kennis die wordt opgedaan tijdens het leren van het ene probleem, kan helpen bij het oplossen van een ander, enigszins vergelijkbaar probleem.
Bijvoorbeeld een model dat is getraind om objecten in afbeeldingen te herkennen kan worden aangepast om specifieke soorten dieren op foto's te herkennen, waarbij gebruik wordt gemaakt van de reeds bestaande kennis van vormen, texturen en patronen.
Het versnelt actief het trainingsproces en vermindert tegelijkertijd de benodigde hoeveelheid gegevens aanzienlijk. In kleine datascenario's is dit vooral gunstig, omdat het de traditionele behoefte aan enorme datasets om een hoge modelnauwkeurigheid te bereiken omzeilt.
Door gebruik te maken van vooraf getrainde modellen kunnen beoefenaars veel van de problemen omzeilen initiële hindernissen die vaak worden geassocieerd met modelontwikkeling, zoals functieselectie en modelarchitectuurontwerp.
Vooraf getrainde modellen dienen als de echte basis voor transferleren, en deze modellen, vaak ontwikkeld en getraind op grootschalige datasets door onderzoeksinstellingen of technologiegiganten, worden beschikbaar gesteld voor openbaar gebruik.
De veelzijdigheid van voorgetrainde modellen is opmerkelijk, met toepassingen variërend van beeld- en spraakherkenning tot natuurlijke taalverwerking. Het adopteren van deze modellen voor nieuwe taken kan de ontwikkeltijd en de middelen die je nodig hebt drastisch verkorten.
Bijvoorbeeld modellen getraind in de ImageNet-database, dat miljoenen gelabelde afbeeldingen in duizenden categorieën bevat, biedt een rijke functieset voor een breed scala aan beeldherkenningstaken.
Het aanpassingsvermogen van deze modellen aan nieuwe, kleinere datasets onderstreept hun waarde, waardoor complexe kenmerken kunnen worden geëxtraheerd zonder de noodzaak van uitgebreide computerbronnen.
Werken met beperkte gegevens brengt unieke uitdagingen met zich mee:de voornaamste zorg is overfitting, waarbij een model de trainingsgegevens te goed leert, inclusief de ruis en uitschieters, wat leidt tot slechte prestaties op onzichtbare gegevens.
Transfer learning verkleint dit risico door gebruik te maken van modellen die vooraf zijn getraind op diverse datasets, waardoor de generalisatie wordt bevorderd.
De effectiviteit van transferleren hangt echter af van de relevantie van het vooraf getrainde model voor de nieuwe taak. Als de betrokken taken te veel van elkaar verschillen, kunnen de voordelen van transferleren mogelijk niet volledig tot uiting komen.
Bovendien, het verfijnen van een vooraf getraind model met een kleine dataset vereist een zorgvuldige aanpassing van parameters om te voorkomen dat de waardevolle kennis die het model al heeft verworven verloren gaat.
Naast deze hindernissen is er een ander scenario waarin gegevens in gevaar kunnen komen tijdens het compressieproces. Dit geldt zelfs voor vrij eenvoudige handelingen, bijvoorbeeld wanneer je dat wilt comprimeer pdf-bestanden, maar gelukkig kunnen dit soort gebeurtenissen worden voorkomen met nauwkeurige wijzigingen.
In de context van machinaal leren, het waarborgen van de volledigheid en kwaliteit van de gegevens zelfs wanneer compressie wordt ondergaan voor opslag of transmissie is dit essentieel voor het ontwikkelen van een betrouwbaar model.
Transferleren, met zijn afhankelijkheid van vooraf getrainde modellen, benadrukt nog eens de noodzaak van zorgvuldigheid beheer van gegevensbronnen om verlies van informatie te voorkomen en ervoor te zorgen dat elk stukje data optimaal wordt gebruikt in de trainings- en toepassingsfasen.
Het balanceren van het behoud van geleerde kenmerken met de aanpassing aan nieuwe taken is een delicaat proces dat een diep begrip van zowel het model als de beschikbare gegevens vereist.
De De horizon van transferleren breidt zich voortdurend uit, waarbij onderzoek de grenzen verlegt van wat mogelijk is.
Een opwindende weg hier is de ontwikkeling van meer universele modellen die met minimale aanpassingen kan worden toegepast op een breder scala aan taken.
Een ander onderzoeksgebied is de verbetering van algoritmen voor de overdracht van kennis tussen enorm verschillende domeinen, waardoor de flexibiliteit van het overdrachtsonderwijs wordt vergroot.
Er is ook een groeiende belangstelling voor het automatiseren van het proces van het selecteren en verfijnen van vooraf getrainde modellen voor specifieke taken, wat de toegangsdrempel voor het gebruik van geavanceerde machine learning-technieken verder zou kunnen verlagen.
Deze ontwikkelingen beloven transferleren nog toegankelijker en effectiever te maken, waardoor nieuwe mogelijkheden ontstaan voor de toepassing ervan op gebieden waar gegevens schaars of moeilijk te verzamelen zijn.
De schoonheid van transferleren ligt in het aanpassingsvermogen dat van toepassing is op allerlei verschillende domeinen.
Vanuit de zorg, waar het kan helpen bij het diagnosticeren van ziekten Met beperkte patiëntgegevens, tot robotica, waar het het leren van nieuwe taken versnelt zonder uitgebreide training, zijn de potentiële toepassingen enorm.
In het gebied van natuurlijke taalverwerkingheeft transfer learning aanzienlijke vooruitgang mogelijk gemaakt in taalmodellen met relatief kleine datasets.
Dit aanpassingsvermogen demonstreert niet alleen de efficiëntie van transfer learning, het benadrukt ook het potentieel ervan om de toegang tot geavanceerde machinale leertechnieken te democratiseren, zodat kleinere organisaties en onderzoekers projecten kunnen ondernemen die voorheen buiten hun bereik lagen vanwege databeperkingen.
Zelfs als het een Django-platform, kunt u transfer learning gebruiken om de mogelijkheden van uw toepassing te verbeteren zonder vanaf nul te beginnen helemaal opnieuw.
Transfer learning overstijgt de grenzen van specifieke programmeertalen of raamwerken, waardoor het mogelijk wordt geavanceerde machine learning-modellen toe te passen op projecten die in diverse omgevingen zijn ontwikkeld.
Overdrachtsleren is niet zomaar over het overwinnen van dataschaarste; het is ook een bewijs van de efficiëntie en optimalisatie van hulpbronnen bij machinaal leren.
Door voort te bouwen op de kennis uit vooraf getrainde modellen kunnen onderzoekers en ontwikkelaars significante resultaten bereiken met minder rekenkracht en tijd.
Deze efficiëntie is bijzonder belangrijk in scenario's waarin de middelen beperkt zijn, of het nu gaat om data, rekenmogelijkheden of beide.
Sinds 43% van alle websites gebruiken WordPress als hun CMS, dit is een geweldige proeftuin voor ML-modellen die gespecialiseerd zijn in, laten we zeggen, web schrapen of het vergelijken van verschillende soorten inhoud op contextuele en taalkundige verschillen.
Dit onderstreept de praktische voordelen van transferleren in praktijkscenario's, waar de toegang tot grootschalige, domeinspecifieke gegevens beperkt kan zijn. Transfer learning moedigt ook het hergebruik van bestaande modellen aan, in lijn met duurzame praktijken door de behoefte aan energie-intensieve training vanaf het begin te verminderen.
De aanpak illustreert hoe strategisch gebruik van hulpbronnen kan leiden tot substantiële vooruitgang op het gebied van machinaal leren, waardoor geavanceerde modellen toegankelijker en milieuvriendelijker worden.
Nu we ons onderzoek naar transfer learning afsluiten, is het duidelijk dat deze techniek het machine learning zoals we dat kennen aanzienlijk verandert, vooral voor projecten die worstelen met beperkte databronnen.
Transfer learning maakt het effectieve gebruik van vooraf getrainde modellen mogelijk, waardoor zowel kleine als grootschalige projecten opmerkelijke resultaten kunnen bereiken zonder de noodzaak van uitgebreide datasets of rekenhulpmiddelen.
Vooruitkijkend is het potentieel voor transferleren enorm en gevarieerd, en het vooruitzicht om machine learning-projecten haalbaarder en minder middelenintensief te maken is niet alleen veelbelovend; het wordt al werkelijkheid.
Deze verschuiving naar meer toegankelijke en efficiëntere machinale leerpraktijken heeft het potentieel om innovatie op tal van terreinen te stimuleren, van gezondheidszorg tot milieubescherming.
Transfer learning democratiseert machinaal leren, waardoor geavanceerde technieken beschikbaar worden voor een veel breder publiek dan ooit tevoren.
Nahla Davies is een softwareontwikkelaar en technisch schrijver. Voordat ze haar werk fulltime aan technisch schrijven wijdde, slaagde ze er onder meer in om als hoofdprogrammeur te dienen bij een Inc. 5,000 ervaringsgerichte merkorganisatie met klanten als Samsung, Time Warner, Netflix en Sony.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/exploring-the-potential-of-transfer-learning-in-small-data-scenarios?utm_source=rss&utm_medium=rss&utm_campaign=exploring-the-potential-of-transfer-learning-in-small-data-scenarios

