
Afbeelding gemaakt door auteur met DALL•E 3
Key Takeaways
- Chain of Code (CoC) is een nieuwe benadering van de interactie met taalmodellen, waarbij het redeneervermogen wordt verbeterd door een combinatie van codeschrijven en selectieve code-emulatie.
- CoC breidt de mogelijkheden van taalmodellen uit voor logische, rekenkundige en taalkundige taken, vooral voor taken die een combinatie van deze vaardigheden vereisen.
- Met CoC schrijven taalmodellen code en emuleren ze ook delen ervan die niet kunnen worden gecompileerd, wat een unieke aanpak biedt voor het oplossen van complexe problemen.
- CoC toont effectiviteit voor zowel grote als kleine LM's.
Het belangrijkste idee is om LM's aan te moedigen om taalkundige subtaken in een programma op te maken als flexibele pseudocode die de compiler expliciet ongedefinieerd gedrag kan opvangen en doorgeven om te simuleren met een LM (als een 'LMulator').
Er komen steeds nieuwe taalmodel (LM)-aanwijzingen, communicatie- en trainingstechnieken op om de LM-redeneer- en prestatiemogelijkheden te verbeteren. Eén van die ontwikkelingen is de ontwikkeling van de Codeketen (CoC), een methode bedoeld om codegestuurd redeneren in LM's te bevorderen. Deze techniek is een samensmelting van traditionele codering en de innovatieve emulatie van LM-code-uitvoering, waardoor een krachtig hulpmiddel ontstaat voor het aanpakken van complexe taalkundige en rekenkundige redeneringstaken.
CoC onderscheidt zich door zijn vermogen om ingewikkelde problemen aan te pakken die logica, rekenkunde en taalverwerking combineren, wat, zoals al geruime tijd bekend is bij LM-gebruikers, lange tijd een uitdaging is geweest voor standaard LM's. De effectiviteit van CoC is niet beperkt tot grote modellen, maar strekt zich uit over verschillende formaten, wat de veelzijdigheid en brede toepasbaarheid in AI-redeneringen aantoont.
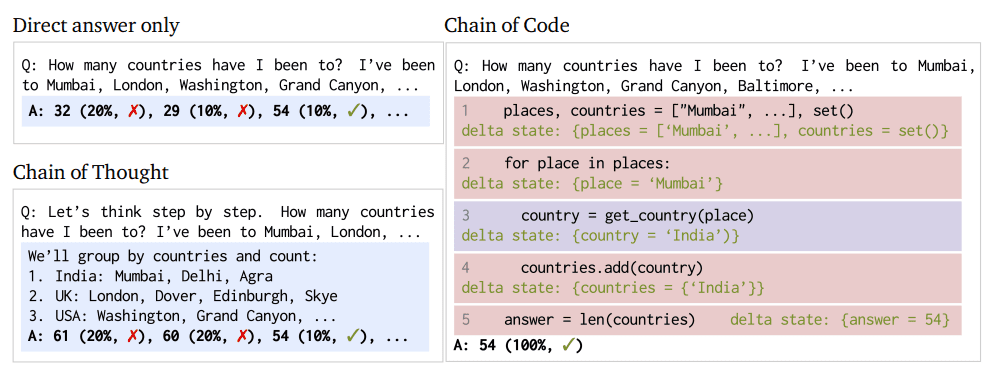
Figuur 1: Chain of Code-aanpak en procesvergelijking (Afbeelding van papier)
CoC is een paradigmaverschuiving in LM-functionaliteit; dit is geen eenvoudige aansporingstactiek om de kans te vergroten dat de gewenste reactie van een LM wordt uitgelokt. In plaats daarvan herdefinieert CoC de benadering van de LM van de bovengenoemde redeneertaken.
In de kern stelt CoC LM's in staat om niet alleen code te schrijven, maar ook delen ervan te emuleren, vooral die aspecten die niet direct uitvoerbaar zijn. Deze dualiteit stelt LM's in staat een breder scala aan taken uit te voeren, waarbij taalkundige nuances worden gecombineerd met het oplossen van logische en rekenkundige problemen. CoC kan taalkundige taken opmaken als pseudocode en effectief de kloof overbruggen tussen traditionele codering en AI-redeneringen. Deze overbrugging zorgt voor een flexibel en capabeler systeem voor het oplossen van complexe problemen. De LMulator, een hoofdcomponent van de toegenomen mogelijkheden van CoC, maakt de simulatie en interpretatie mogelijk van uitvoer van code-uitvoering die anders niet direct beschikbaar zou zijn voor de LM.
CoC heeft opmerkelijk succes laten zien in verschillende benchmarks en presteert aanzienlijk beter dan bestaande benaderingen zoals Chain of Thought, vooral in scenario's die een mix van taalkundig en computationeel redeneren vereisen.
Experimenten tonen aan dat Chain of Code beter presteert dan Chain of Thought en andere baselines op verschillende benchmarks; op BIG-Bench Hard behaalt Chain of Code 84%, een winst van 12% ten opzichte van Chain of Thought.
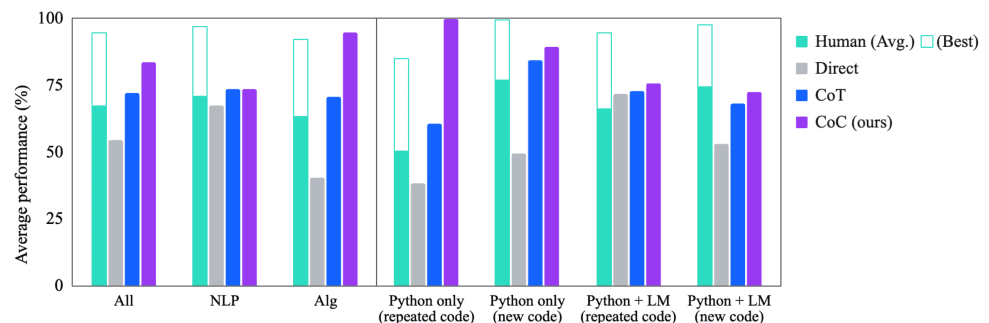
Figuur 2: Vergelijking van prestatiecodeketens (Afbeelding van papier)
De implementatie van CoC impliceert een onderscheidende benadering van redeneertaken, waarbij coderings- en emulatieprocessen worden geïntegreerd. CoC moedigt LM's aan om complexe redeneertaken op te maken als pseudocode, die vervolgens wordt geïnterpreteerd en opgelost. Dit proces bestaat uit meerdere stappen:
- Redeneringstaken identificeren: Bepaal de taalkundige of rekenkundige taak waarvoor redenering vereist is
- Code schrijven: De LM schrijft pseudocode of flexibele codefragmenten om een oplossing te schetsen
- Emulatie van code: voor delen van de code die niet direct uitvoerbaar zijn, emuleert de LM het verwachte resultaat, waardoor de uitvoering van de code effectief wordt gesimuleerd
- Uitgangen combineren: De LM combineert de resultaten van zowel de daadwerkelijke uitvoering van de code als de emulatie ervan om een alomvattende oplossing voor het probleem te vormen
Deze stappen stellen LM’s in staat een breder scala aan redeneervragen aan te pakken door ‘in code te denken’, waardoor hun probleemoplossende vermogen wordt vergroot.
De LMulator kan, als onderdeel van het CoC-framework, aanzienlijk helpen bij het verfijnen van zowel code als redenering op een aantal specifieke manieren:
- Foutidentificatie en -simulatie: wanneer een taalmodel code schrijft die fouten of niet-uitvoerbare delen bevat, kan de LMulator simuleren hoe deze code zich zou gedragen als deze zou worden uitgevoerd, waarbij logische fouten, oneindige lussen of randgevallen worden beoordeeld en de LM wordt begeleid. om de codelogica te heroverwegen en aan te passen.
- Omgaan met ongedefinieerd gedrag: In gevallen waarin de code ongedefinieerd of dubbelzinnig gedrag inhoudt dat een standaardinterpreter niet kan uitvoeren, gebruikt de LMulator het begrip van de context en de intentie van het taalmodel om af te leiden wat de output of het gedrag zou moeten zijn, en levert zo een beredeneerde, gesimuleerde output waar traditionele executie zou mislukken.
- Verbetering van het redeneren in code: wanneer een mix van taalkundig en computationeel redeneren vereist is, zorgt de LMulator ervoor dat het taalmodel de eigen codegeneratie kan herhalen, waarbij de resultaten van verschillende benaderingen worden gesimuleerd, waardoor effectief door middel van code kan worden 'redeneerd', wat leidt tot nauwkeuriger en efficiënter oplossingen.
- Edge Case Exploration: De LMulator kan verkennen en testen hoe code omgaat met edge cases door verschillende invoer te simuleren, wat vooral handig is om ervoor te zorgen dat de code robuust is en een verscheidenheid aan scenario's aankan.
- Feedbackloop voor leren: Terwijl de LMulator problemen of potentiële verbeteringen in de code simuleert en identificeert, kan deze feedback door het taalmodel worden gebruikt om zijn benadering van coderen en probleemoplossing te leren en te verfijnen, wat een voortdurend leerproces is dat de codeer- en redeneermogelijkheden van het model in de loop van de tijd.
De LMulator verbetert het vermogen van het taalmodel om code te schrijven, testen en verfijnen door een platform te bieden voor simulatie en iteratieve verbetering.
De CoC-techniek is een vooruitgang in het verbeteren van het redeneervermogen van LM's. CoC verbreedt de reikwijdte van de problemen die LM's kunnen aanpakken door het schrijven van code te integreren met selectieve code-emulatie. Deze aanpak demonstreert het potentieel van AI om complexere, realistische taken uit te voeren die genuanceerd denken vereisen. Belangrijk is dat CoC heeft bewezen uit te blinken in zowel kleine als grote LM's, waardoor een pad wordt gecreëerd voor het toenemende aantal kleinere modellen om hun redeneervermogen potentieel te verbeteren en hun effectiviteit dichter bij die van grotere modellen te brengen.
Voor een diepgaander begrip, bekijk hier het volledige artikel.
Matthijs Mayo (@mattmayo13) heeft een masterdiploma in computerwetenschappen en een universitair diploma in datamining. Als hoofdredacteur van KDnuggets wil Matthew complexe datawetenschapsconcepten toegankelijk maken. Zijn professionele interesses omvatten de verwerking van natuurlijke taal, machine learning-algoritmen en het verkennen van opkomende AI. Hij wordt gedreven door een missie om kennis in de data science-gemeenschap te democratiseren. Matthew codeert al sinds hij zes jaar oud was.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/enhancing-llm-reasoning-unveiling-chain-of-code-prompting?utm_source=rss&utm_medium=rss&utm_campaign=enhancing-llm-reasoning-unveiling-chain-of-code-prompting

