Uw eerste gedistribueerde Python-toepassing schrijven met Ray
Met Ray kun je Python-code gebruiken die opeenvolgend wordt uitgevoerd en deze transformeren in een gedistribueerde applicatie met minimale codewijzigingen. Lees verder om erachter te komen waarom u Ray zou moeten gebruiken en hoe u aan de slag kunt gaan.
By Michaël Galarnyk, Data Science-professional

Ray laat parallel en gedistribueerd computergebruik werken zoals je zou hopen (beeldbron)
straal is een snel, eenvoudig gedistribueerd uitvoeringsraamwerk dat het eenvoudig maakt om uw applicaties te schalen en gebruik te maken van geavanceerde machine learning-bibliotheken. Met Ray kun je Python-code gebruiken die opeenvolgend wordt uitgevoerd en deze transformeren in een gedistribueerde applicatie met minimale codewijzigingen.
Het doel van deze tutorial is om het volgende te onderzoeken:
- Waarom zou je parallelliseren en distribueren met Ray
- Aan de slag met Ray
- Trade-offs in gedistribueerd computergebruik (rekenkosten, geheugen, I/O, enz.)
Waarom zou je met Ray parallelliseren en distribueren?
Als vorige post wees op, parallel en gedistribueerd computergebruik zijn een hoofdbestanddeel van moderne toepassingen. Het probleem is dat het nemen van bestaande Python-code en proberen deze te parallelliseren of te distribueren, kan betekenen dat bestaande code moet worden herschreven, soms helemaal opnieuw. Bovendien hebben moderne applicaties vereisten die bestaande modules leuk vinden: multiverwerking gebrek. Deze vereisten omvatten:
- Dezelfde code op meer dan één machine uitvoeren
- Het bouwen van microservices en actoren die een staat hebben en kunnen communiceren
- Sierlijke afhandeling van machinestoringen en voorrang
- Efficiënt omgaan met grote objecten en numerieke gegevens
De Ray-bibliotheek voldoet aan deze vereisten en stelt u in staat uw applicaties te schalen zonder ze te herschrijven. Om parallel en gedistribueerd computergebruik eenvoudig te maken, neemt Ray functies en klassen en vertaalt deze naar de gedistribueerde omgeving als taken en actoren. In de rest van deze tutorial worden deze concepten onderzocht, evenals enkele belangrijke zaken waarmee u rekening moet houden bij het bouwen van parallelle en gedistribueerde toepassingen.

Hoewel deze tutorial onderzoekt hoe Ray het gemakkelijk maakt om gewone Python-code te parallelliseren, is het belangrijk op te merken dat Ray en zijn ecosysteem het ook gemakkelijk maken om bestaande bibliotheken zoals scikit-leren, XGBoost, LichtGBM, PyTorchEn nog veel meer.
Aan de slag met Ray
Python-functies omzetten in externe functies (Ray-taken)
Ray kan worden geïnstalleerd via pip.
pip install 'ray[default]'Laten we onze Ray-reis beginnen door een Ray-taak te maken. Dit kan door een normale Python-functie te versieren met @ray.remote. Dit creëert een taak die kan worden gepland over de CPU-kernen van uw laptop (of Ray-cluster).
Beschouw de twee onderstaande functies die Fibonacci-reeksen genereren (gehele reeks die wordt gekenmerkt door het feit dat elk getal na de eerste twee de som is van de twee voorgaande). De eerste is een normale python-functie en de tweede is een Ray-taak.
import os import time import ray # Normal Python def fibonacci_local(sequence_size): fibonacci = [] for i in range(0, sequence_size): if i 2: fibonacci.append(i) continue fibonacci.append(fibonacci[i-1] +fibonacci[i-2]) return sequence_size # Ray task @ray.remote def fibonacci_distributed(sequence_size): fibonacci = [] for i in range(0, sequence_size): if i 2: fibonacci.append(i) ga verder met fibonacci. append(fibonacci[i-1]+fibonacci[i-2]) return sequence_size
Er zijn een paar dingen om op te merken met betrekking tot deze twee functies. Ten eerste zijn ze identiek, behalve de @ray.remote decorateur op de functie fibonacci_distributed.
Het tweede ding om op te merken is de kleine retourwaarde. Ze retourneren niet de Fibonacci-reeksen zelf, maar de reeksgrootte, die een geheel getal is. Dit is belangrijk, omdat het de waarde van een gedistribueerde functie kan verminderen door deze zo te ontwerpen dat er veel gegevens (parameters) voor nodig zijn of worden geretourneerd. Ingenieurs noemen dit vaak de input/output (IO) van een gedistribueerde functie.
Lokale versus externe prestaties vergelijken
Met de functies in deze sectie kunnen we vergelijken hoe lang het duurt om meerdere lange Fibonacci-reeksen te genereren, zowel lokaal als parallel. Het is belangrijk op te merken dat beide functies hieronder gebruik maken van os.cpu_count() die het aantal CPU's in het systeem retourneert.
os.cpu_count()
De machine die in deze tutorial wordt gebruikt, heeft acht CPU's, wat betekent dat elke onderstaande functie 8 Fibonacci-reeksen zal genereren.
# Normale Python def run_local(sequence_size): start_time = time.time() results = [fibonacci_local(sequence_size) for _ in range(os.cpu_count())] duration = time.time() - start_time print('Sequence size: {}, Lokale uitvoeringstijd: {}'.format(sequence_size, duration)) # Ray def run_remote(sequence_size): # Start Ray ray.init() start_time = time.time() results = ray.get([fibonacci_distributed. remote(sequence_size) for _ in range(os.cpu_count())]) duration = time.time() - start_time print('Sequence size: {}, Remote execution time: {}'.format(sequence_size, duration))
Voordat we ingaan op hoe de code voor run_local en run_remote werken, laten we beide functies uitvoeren om te zien hoe lang het duurt om meerdere Fibonacci-reeksen met 100000 nummers te genereren, zowel lokaal als op afstand.
run_local(100000) run_remote(100000)

De functie run_remote parallelleerde de berekening over meerdere CPU's, wat resulteerde in een kleinere verwerkingstijd (1.76 s versus 4.20 s).
De Ray-API
Om beter te begrijpen waarom run_remote sneller was, laten we de code kort doornemen en uitleggen hoe de Ray API werkt.

De opdracht ray.init() start alle relevante Ray-processen. Ray maakt standaard één werkproces per CPU-kern. Als u Ray op een cluster wilt uitvoeren, moet u een clusteradres doorgeven met iets als ray.init(address= 'InsertAddressHere').

fibonacci_distributed.remote(100000)

Het aanroepen van fibonacci_distributed.remote(sequence_size) retourneert onmiddellijk een toekomst en niet de geretourneerde waarde van de functie. De daadwerkelijke uitvoering van de functie vindt op de achtergrond plaats. Omdat het onmiddellijk terugkeert, kan elke functieaanroep parallel worden uitgevoerd. Hierdoor kost het genereren van die meerdere 100000 lange fibonacci-reeksen minder tijd.


ray.get haalt de resulterende waarde van de taak op wanneer deze is voltooid.
Ten slotte is het belangrijk op te merken dat wanneer het proces dat ray.init() aanroept, wordt beëindigd, de Ray-runtime ook wordt beëindigd. Merk op dat als je ray.init() meer dan eens probeert uit te voeren, je een RuntimeError kunt krijgen (misschien heb je ray.init per ongeluk twee keer aangeroepen?). Dit kan worden opgelost door gebruik te maken van ray.shutdown()
# Om Ray expliciet te stoppen of opnieuw te starten, gebruikt u de afsluit-API ray.shutdown()
Ray-dashboard
Ray wordt geleverd met een dashboard dat beschikbaar is op http://127.0.0.1:8265 nadat u de ray.init-functie hebt aangeroepen.
Onder andere dingen, kunt u op het dashboard:
- Begrijp Ray-geheugengebruik en debug geheugenfouten.
- Bekijk het gebruik van resources per actor, uitgevoerde taken, logboeken en meer.
- Clusterstatistieken bekijken.
- Dood acteurs en profileer je Ray-banen.
- Zie fouten en uitzonderingen in één oogopslag.
- Bekijk logboeken over veel machines in één paneel.
- Bekijk Ray Tune banen en proefinformatie.
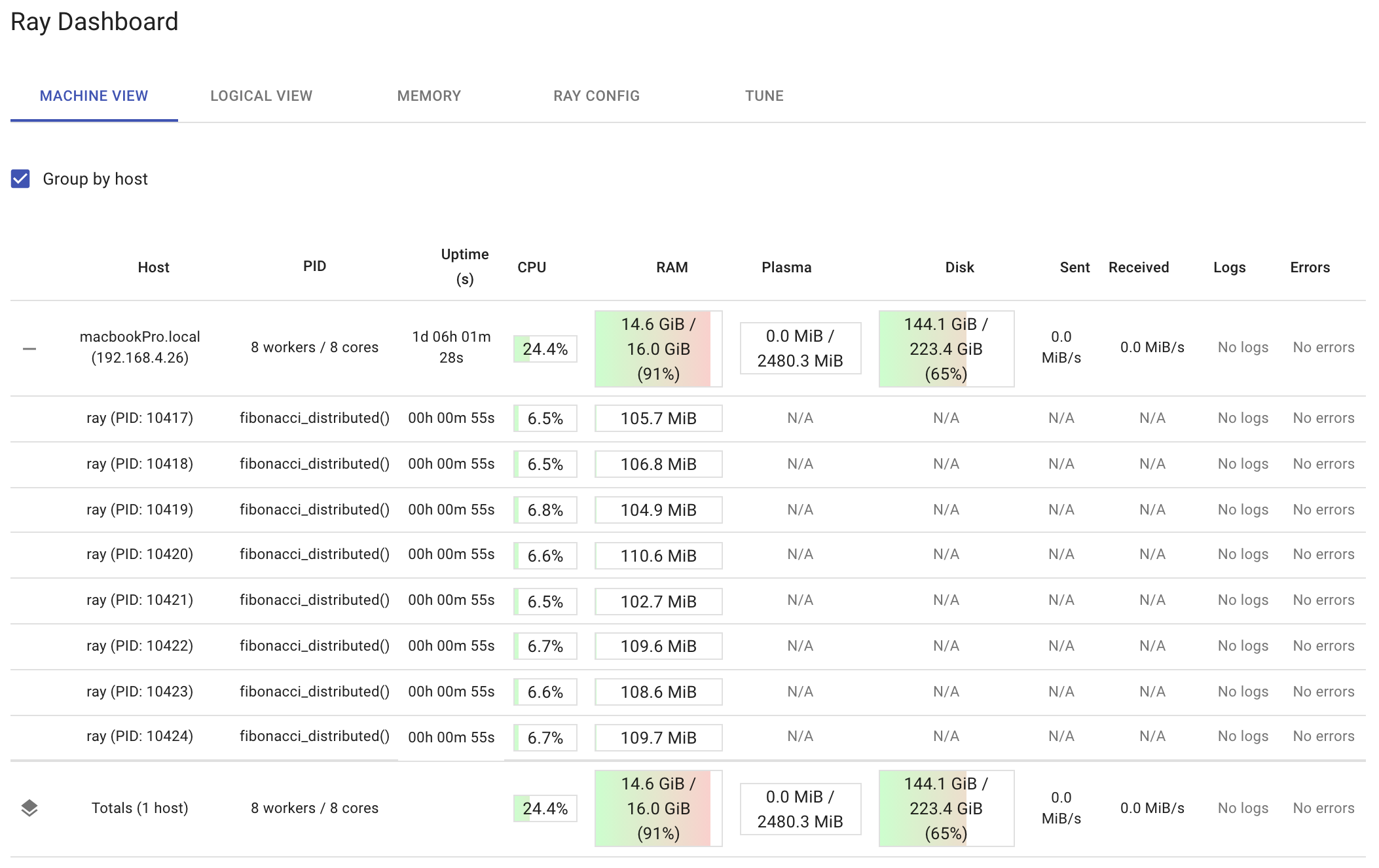
Het onderstaande dashboard toont het resourcegebruik per knoop punt en per werknemer na het uitvoeren van run_remote(200000). Merk op hoe het dashboard de functie fibonacci_distributed toont die in elke worker wordt uitgevoerd. Het is een goed idee om uw gedistribueerde functies te observeren terwijl ze worden uitgevoerd. Op die manier, als u één werknemer al het werk ziet doen, gebruikt u mogelijk de ray.get-functie verkeerd. Als u ziet dat uw totale CPU-gebruik bijna 100 procent wordt, doet u mogelijk te veel.
Trade-offs in gedistribueerde computing
Deze tutorial gebruikte Fibonacci-reeksen omdat ze verschillende opties bieden voor het aanpassen van computergebruik en IO. U kunt de hoeveelheid rekenwerk die elke functieaanroep vereist, wijzigen door de reeksgrootte te vergroten en te verkleinen. Hoe groter de sequentiegrootte, hoe meer rekenkracht u nodig hebt om de sequentie te genereren, terwijl hoe kleiner de sequentiegrootte, hoe minder rekenkracht u nodig hebt. Als de berekening die je distribueert te klein is, zou de overhead van Ray de totale verwerkingstijd domineren, en zou je geen waarde halen uit het distribueren van onze functies.
IO is ook essentieel bij het verdelen van functies. Als u deze functies hebt gewijzigd om de reeksen die ze berekenen te retourneren, zou de IO toenemen naarmate de reeks groter werd. Op een gegeven moment zou de tijd die nodig is om de gegevens te verzenden de totale tijd domineren die nodig is om de meerdere oproepen naar de gedistribueerde functie te voltooien. Dit is belangrijk als u uw functies over een cluster verdeelt. Hiervoor is het gebruik van een netwerk vereist, en netwerkoproepen zijn duurder dan de communicatie tussen processen die in deze zelfstudie wordt gebruikt.
Daarom wordt aanbevolen om te experimenteren met zowel de gedistribueerde Fibonacci-functie als de lokale Fibonacci-functie. Probeer de minimale reeksgrootte te bepalen die nodig is om te profiteren van een externe functie. Als je eenmaal achter de computer bent gekomen, kun je met de IO spelen om te zien wat er met de algehele prestaties gebeurt. Gedistribueerde architecturen, ongeacht de tool die u gebruikt, werken het beste als ze niet veel gegevens hoeven te verplaatsen.
Gelukkig is een groot voordeel van Ray de mogelijkheid om hele objecten op afstand te onderhouden. Dit helpt het IO-probleem te verminderen. Laten we daar eens naar kijken.
Objecten op afstand als acteurs
Net zoals Ray Python-functies vertaalt naar de gedistribueerde setting als taken, vertaalt Ray Python-klassen naar de gedistribueerde setting als actoren. Ray biedt acteurs waarmee u een instantie van een klasse kunt parallelliseren. Wat de code betreft, hoef je alleen maar de @ray.remote-decorateur toe te voegen aan een Python-klasse om er een acteur van te maken. Wanneer u een instantie van die klasse maakt, maakt Ray een nieuwe actor, een proces dat in het cluster wordt uitgevoerd en een kopie van het object bevat.
Omdat het externe objecten zijn, kunnen ze gegevens bevatten en kunnen hun methoden die gegevens manipuleren. Dit helpt de communicatie tussen processen te verminderen. Overweeg een actor te gebruiken als u merkt dat u te veel taken schrijft die gegevens retourneren, die op hun beurt naar andere taken worden verzonden.
Laten we nu naar de onderstaande acteur kijken.
uit collecties import nametuple import csv import tarfile import tijd import ray @ray.remote class GSODActor(): def __init__(self, year, high_temp): self.high_temp = float(high_temp) self.high_temp_count = Geen self.rows = [] self.stations = Geen self.year = jaar def get_row_count(self): return len(self.rows) def get_high_temp_count(self): if self.high_temp_count is None: gefilterd = [l voor l in self.rows if float(l .TEMP) >= self.high_temp] self.high_temp_count = len(gefilterd) return self.high_temp_count def get_station_count(self): return len(self.stations) def get_stations(self): return self.stations def get_high_temp_count(self, stations ): filtered_rows = [l for l in self.rows if float(l.TEMP) >= self.high_temp en l.STATION in stations] return len(filtered_rows) def load_data(self): file_name = self.year + '. tar.gz' row = namedtuple('Rij', ('STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'ELEVATION', 'NAME', 'TEMP', 'TEMP_ATTRIBUTES', 'DEWP', ' DEWP_ATTRIBUTES', 'SLP', 'SLP_ATTRIBUTES ', 'STP', 'STP_ATTRIBUTES', 'VISIB', 'VISIB_ATTRIBUTES', 'WDSP', 'WDSP_ATTRIBUTES', 'MXSPD', 'GUST', 'MAX', 'MAX_ATTRIBUTES', 'MIN', 'MIN_ATTRIBUTES', 'PRCP', 'PRCP_ATTRIBUTES', 'SNDP', 'FRSHTT')) tar = tarfile.open(file_name, 'r:gz') voor lid in tar.getmembers(): member_handle = tar.extractfile(lid) byte_data = member_handle.read() decoded_string = byte_data.decode() lines = decoded_string.splitlines() reader = csv.reader(lines, delimiter=',') # Haal alle rijen in het lid op. Sla de kop over. _ = volgende(lezer) file_rows = [rij(*l) voor l in lezer] self.rows += file_rows self.stations = {l.STATION voor l in zelf.rijen}
De bovenstaande code kan worden gebruikt om gegevens te laden en te manipuleren uit een openbare dataset die bekend staat als de Global Surface Summary of the Day (GSOD). De dataset wordt beheerd door de National Oceanic and Atmospheric Administration (NOAA) en is vrij beschikbaar op hun website. NOAA houdt momenteel gegevens bij van meer dan 9,000 stations wereldwijd en de GSOD-dataset bevat dagelijkse samenvattende informatie van deze stations. Er is één gzip-bestand voor elk jaar van 1929 tot 2020. Voor deze tutorial hoef je alleen de bestanden te downloaden voor 1980 en 2020.
Het doel van dit actor-experiment is om te berekenen hoeveel metingen uit 1980 en 2020 100 graden of hoger waren en te bepalen of 2020 extremere temperaturen had dan 1980. Om een eerlijke vergelijking te maken, zouden alleen stations die in zowel 1980 als 2020 bestonden, moeten overwogen worden. De logica van dit experiment ziet er dus als volgt uit:
- Gegevens uit 1980 laden.
- Gegevens uit 2020 laden.
- Hier krijg je een lijst van stations die bestonden in 1980.
- Hier krijg je een lijst van stations die bestonden in 2020.
- Bepaal de kruising van stations.
- Verkrijg het aantal metingen dat in 100 1980 graden of meer was vanaf de kruising van stations.
- Verkrijg het aantal metingen dat in 100 2020 graden of meer was vanaf de kruising van stations.
- Druk de resultaten af.
Het probleem is dat deze logica volledig sequentieel is; het ene gebeurt pas na het andere. Met Ray kan veel van deze logica parallel worden gedaan.
De onderstaande tabel toont een meer parallelliseerbare logica.

Het op deze manier uitschrijven van de logica is een uitstekende manier om ervoor te zorgen dat u alles wat u kunt op een parallelliseerbare manier uitvoert. De onderstaande code implementeert deze logica.
# Code gaat ervan uit dat je de bestanden 1980.tar.gz en 2020.tar.gz in je huidige werkdirectory hebt staan. def Compare_years(year1, year2, high_temp): # als u weet dat u minder dan het standaard aantal werkers nodig heeft, # kunt u de parameter num_cpus wijzigen ray.init(num_cpus=2) # Maak actorprocessen gsod_y1 = GSODActor.remote( year1, high_temp) gsod_y2 = GSODActor.remote(year2, high_temp) ray.get([gsod_y1.load_data.remote(), gsod_y2.load_data.remote()]) y1_stations, y2_stations = ray.get([gsod_y1.get_stations.remote (), gsod_y2.get_stations.remote()]) intersectie = set.intersection(y1_stations, y2_stations) y1_count, y2_count = ray.get([gsod_y1.get_high_temp_count.remote(intersection), gsod_y2.get_high_temp_count.remote(intersection)] print('Aantal gemeenschappelijke stations: {}'.format(len(intersection))) print('{} - Hoog tijdelijk aantal stations: {}'.format(year1, y1_count)) print('{} - Aantal hoge temperaturen voor veelvoorkomende stations: {}'.format(year2, y2_count)) #Als u de onderstaande code uitvoert, wordt weergegeven welk jaar meer extreme temperaturen had. Compare_years('1980', '2020', 100)

Er zijn een paar belangrijke dingen om te vermelden over de bovenstaande code. Ten eerste, door de @ray.remote-decorateur op klasseniveau te plaatsen, konden alle klassenmethoden op afstand worden aangeroepen. Ten tweede gebruikt de bovenstaande code twee actorprocessen (gsod_y1 en gsod_y2) die methoden parallel kunnen uitvoeren (hoewel elke actor slechts één methode tegelijk kan uitvoeren). Hierdoor konden de gegevens van 1980 en 2020 tegelijkertijd worden geladen en verwerkt.
Conclusie
straal is een snel, eenvoudig gedistribueerd uitvoeringsraamwerk dat het eenvoudig maakt om uw applicaties te schalen en gebruik te maken van geavanceerde machine learning-bibliotheken. Deze tutorial liet zien hoe het gebruik van Ray het gemakkelijk maakt om je bestaande Python-code die opeenvolgend wordt uitgevoerd, om te zetten in een gedistribueerde applicatie met minimale codewijzigingen. Terwijl de experimenten hier allemaal op dezelfde machine werden uitgevoerd, Ray maakt het ook gemakkelijk om uw Python-code op elke grote cloudprovider te schalen. Als je meer wilt weten over Ray, bekijk dan de Ray-project op GitHubVolg @raydistributed op twitter, en meld u aan voor de Ray nieuwsbrief.
Bio: Michaël Galarnyk is een Data Science Professional en werkt in Developer Relations bij Anyscale.
ORIGINELE. Met toestemming opnieuw gepost.
Zie ook:
PlatoAi. Web3 opnieuw uitgevonden. Gegevensintelligentie versterkt.
Klik hier om toegang te krijgen.
Bron: https://www.kdnuggets.com/2021/08/distributed-python-application-ray.html

