In de snelle wereld van vandaag lijkt het concept van geduld als een deugd te vervagen, omdat mensen nergens meer op willen wachten. Als het laden van Netflix te lang duurt of als de dichtstbijzijnde Lyft te ver weg is, schakelen gebruikers snel over naar alternatieve opties. De vraag naar directe resultaten is niet beperkt tot consumentendiensten zoals videostreaming en ride-sharing; het strekt zich uit tot het rijk van Data analytics, met name bij het bedienen van gebruikers op schaal en geautomatiseerde besluitvormingsworkflows. Het vermogen om tijdig inzicht te geven, weloverwogen beslissingen te nemen en onmiddellijk actie te ondernemen op basis van realtime gegevens wordt steeds belangrijker. Bedrijven zoals Confluent, Target en tal van andere zijn marktleiders omdat ze gebruik maken van real-time analyses en data-architecturen die analysegestuurde operaties mogelijk maken. Dit vermogen stelt hen in staat om voorop te blijven in hun respectieve industrieën.
Deze blogpost gaat dieper in op het concept van real-time analyse voor data-architecten die beginnen met het verkennen van ontwerppatronen, en biedt inzicht in de definitie ervan en de geprefereerde bouwstenen en data-architectuur die gewoonlijk in dit domein worden gebruikt.
Wat is real-time analyse precies?
Realtime analytics worden gekenmerkt door twee fundamentele kwaliteiten: up-to-date data en snelle inzichten. Ze worden gebruikt in tijdgevoelige toepassingen waarbij de snelheid waarmee nieuwe gebeurtenissen worden omgezet in bruikbare inzichten een kwestie van seconden is.
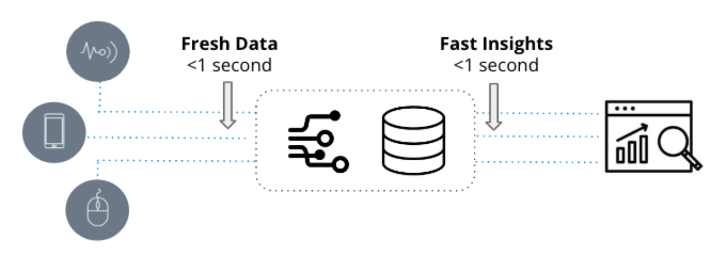
Aan de andere kant, traditionele analyse, beter bekend als business intelligence, verwijst naar statische representaties van bedrijfsgegevens die voornamelijk worden gebruikt voor rapportagedoeleinden. Deze analyses zijn gebaseerd op datawarehouses zoals Snowflake en Amazon Redshift en worden gevisualiseerd door middel van business intelligence-tools zoals Tableau of PowerBI.
In tegenstelling tot traditionele analyses, die afhankelijk zijn van historische gegevens die dagen of weken oud kunnen zijn, maken real-time analyses gebruik van nieuwe gegevens en worden ze gebruikt in operationele workflows die snelle reacties op mogelijk ingewikkelde vragen vereisen.

Neem bijvoorbeeld een supply chain-manager die historische trends zoekt in maandelijkse voorraadwijzigingen. In dit scenario is traditionele analyse de ideale keuze, aangezien de leidinggevende het zich kan veroorloven om nog een paar minuten te wachten voordat het rapport is verwerkt. Aan de andere kant probeert een beveiligingsteam afwijkingen in het netwerkverkeer op te sporen en te diagnosticeren. Dit is waar real-time analyse om de hoek komt kijken, aangezien het SecOps-team een snelle analyse van duizenden tot miljoenen real-time logboekvermeldingen in intervallen van minder dan een seconde nodig heeft om patronen te identificeren en abnormaal gedrag te onderzoeken.
Is de keuze van architectuur significant?
Veel databaseleveranciers beweren geschikt te zijn voor real-time analyse, en ze hebben wat dat betreft wel wat mogelijkheden. Denk bijvoorbeeld aan het scenario van weermonitoring, waarbij elke seconde temperatuurmetingen van duizenden weerstations moeten worden bemonsterd en vragen betrekking hebben op op drempels gebaseerde waarschuwingen en trendanalyse. SingleStore, InfluxDB, MongoDB en zelfs PostgreSQL kunnen dit met gemak aan. Door een push-API te maken om de statistieken rechtstreeks naar de database te sturen en een eenvoudige query uit te voeren, kunnen realtime analyses worden bereikt.
Dus, wanneer neemt de complexiteit van realtime analyses toe? In het genoemde voorbeeld is de dataset relatief klein en zijn de betrokken analyses eenvoudig. Met slechts één temperatuurgebeurtenis die per seconde wordt gegenereerd en een eenvoudige SELECT-query met een WHERE-instructie om de nieuwste gebeurtenissen op te halen, is minimale verwerkingskracht vereist, waardoor het beheersbaar is voor elke tijdreeks of OLTP-database.
De echte uitdagingen doen zich voor en databases worden tot het uiterste gedreven wanneer het aantal opgenomen gebeurtenissen toeneemt, query's complexer worden met talloze dimensies en datasets terabytes of zelfs petabytes groot worden. Hoewel Apache Cassandra vaak wordt overwogen voor opname met hoge doorvoer, voldoen de analyseprestaties mogelijk niet aan de verwachtingen. In gevallen waarin de use-case voor analyse vereist dat meerdere realtime gegevensbronnen op schaal worden samengevoegd, moeten alternatieve oplossingen worden onderzocht.
Hier volgen enkele factoren waarmee u rekening moet houden bij het bepalen van de benodigde specificaties voor de juiste architectuur:
- Werk je met hoge events per seconde, van duizenden tot miljoenen?
- Is het belangrijk om de latentie tussen gemaakte gebeurtenissen te minimaliseren tot het moment waarop ze kunnen worden opgevraagd?
- Is uw totale dataset groot en niet slechts een paar GB?
- Hoe belangrijk zijn queryprestaties - minder dan een seconde of minuten per query?
- Hoe ingewikkeld zijn de queries, het exporteren van enkele rijen of grootschalige aggregaties?
- Is het voorkomen van downtime van de datastroom en analyse-engine belangrijk?
- Probeert u meerdere gebeurtenisstromen samen te voegen voor analyse?
- Moet u real-time data in context plaatsen met historische data?
- Verwacht u veel gelijktijdige queries?
Als een van deze aspecten relevant is, laten we de kenmerken van de ideale architectuur bespreken.
Building Blocks
Realtime analyse vereist meer dan alleen een bekwame database. Het begint met de noodzaak om verbindingen tot stand te brengen, real-time gegevens te verzenden en te verwerken, en leidt ons naar het eerste basiselement: het streamen van gebeurtenissen.
1. Evenementen streamen
In situaties waarin real-time van het allergrootste belang is, komen conventionele op batch gebaseerde datapijplijnen vaak te laat, waardoor er berichtenwachtrijen ontstaan. In het verleden was de bezorging van berichten afhankelijk van tools zoals ActiveMQ, RabbitMQ en TIBCO. De hedendaagse aanpak omvat echter het streamen van evenementen met technologieën zoals Apache Kafka en Amazon Kinesis.
Apache Kafka en Amazon Kinesis pakken de schaalbaarheidsbeperkingen aan die vaak voorkomen bij traditionele berichtenwachtrijen, waardoor publicatie-/abonneermechanismen met hoge verwerkingscapaciteit in staat worden gesteld om op efficiënte wijze uitgebreide stromen gebeurtenisgegevens van diverse bronnen (in Amazon-terminologie producenten genoemd) te verzamelen en te distribueren naar verschillende bestemmingen ( consumenten genoemd in Amazon-terminologie) in realtime.
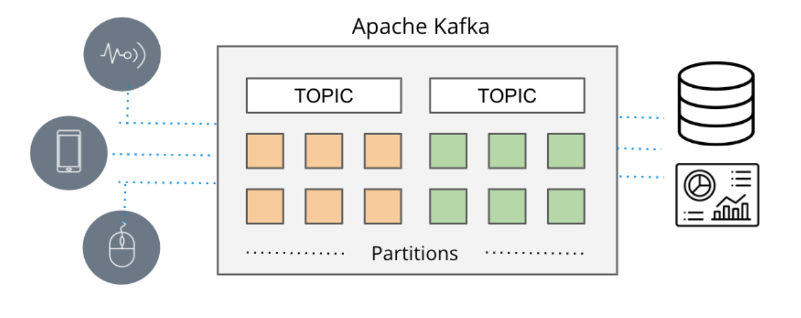
Deze systemen verwerven naadloos real-time gegevens uit een reeks bronnen, zoals databases, sensoren en cloudservices, en vangen deze op als gebeurtenisstromen en vergemakkelijken de overdracht ervan naar andere applicaties, databases en services.
Gezien hun indrukwekkende schaalbaarheid (zoals geïllustreerd door Apache Kafka's ondersteuning van meer dan zeven biljoen berichten per dag op LinkedIn) en het vermogen om meerdere gelijktijdige databronnen te accommoderen, is event streaming naar voren gekomen als het heersende mechanisme voor het leveren van real-time data in applicaties.
Nu we de mogelijkheid hebben om realtime gegevens vast te leggen, is de volgende stap om te onderzoeken hoe we deze in realtime kunnen analyseren.
2. Realtime analysedatabase
Realtime analyse vereist een gespecialiseerde database die volledig gebruik kan maken van streaminggegevens van Apache Kafka en Amazon Kinesis, waardoor realtime inzichten worden verkregen. Apache Druïde is precies die database.
Apache Druid is naar voren gekomen als de voorkeursdatabase voor real-time analysetoepassingen vanwege de hoge prestaties en het vermogen om streaminggegevens te verwerken. Met zijn ondersteuning voor echte stream-opname en efficiënte verwerking van grote datavolumes in tijdframes van minder dan een seconde, zelfs onder zware belasting, blinkt Apache Druid uit in het leveren van snelle inzichten in nieuwe data. De naadloze integratie met Apache Kafka en Amazon Kinesis verstevigt zijn positie als de beste keuze voor realtime analyses.
Bij het kiezen van een analysedatabase voor het streamen van gegevens, zijn overwegingen zoals schaal, latentie en gegevenskwaliteit cruciaal. De mogelijkheid om de volledige omvang van het streamen van gebeurtenissen aan te kunnen, meerdere Kafka-onderwerpen of Kinesis-shards op te nemen en te correleren, op gebeurtenissen gebaseerde opname te ondersteunen en de gegevensintegriteit tijdens verstoringen te waarborgen, zijn belangrijke vereisten. Apache Druid voldoet niet alleen aan deze criteria, maar doet er alles aan om aan deze verwachtingen te voldoen en extra mogelijkheden te bieden.
Druid is met opzet ontworpen om uit te blinken in snelle opname en real-time bevraging van gebeurtenissen zodra ze aankomen. Het heeft een unieke benadering voor het streamen van gegevens, waarbij gebeurtenissen op individuele basis worden opgenomen in plaats van te vertrouwen op sequentiële batchgegevensbestanden om een stroom te simuleren. Dit elimineert de noodzaak voor connectoren naar Kafka of Kinesis. Bovendien zorgt Druid ervoor Datakwaliteit door exact-eenmalige semantiek te ondersteunen, waardoor de integriteit en nauwkeurigheid van de opgenomen gegevens wordt gegarandeerd.
Net als Apache Kafka is Apache Druid speciaal ontworpen om gebeurtenisgegevens op internetschaal te verwerken. De op services gebaseerde architectuur maakt onafhankelijke schaalbaarheid van opname en queryverwerking mogelijk, waardoor het bijna oneindig kan worden geschaald. Door opnametaken in kaart te brengen met Kafka-partities, schaalt Druid naadloos samen met Kafka-clusters, waardoor een efficiënte en parallelle verwerking van gegevens wordt gegarandeerd.
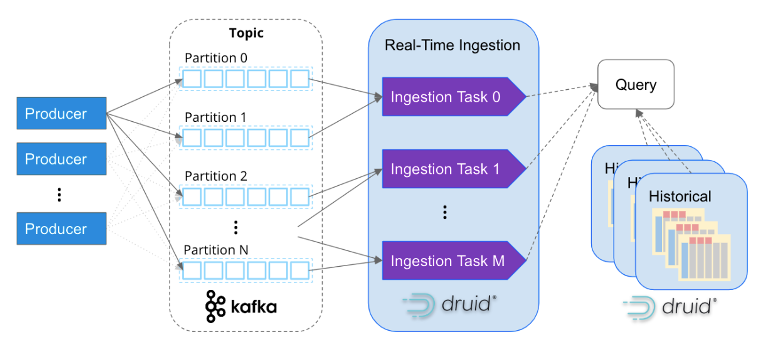
Het komt steeds vaker voor dat bedrijven miljoenen gebeurtenissen per seconde opnemen in Apache Druid. Confluent, de makers van Kafka, heeft bijvoorbeeld zijn observatieplatform gebouwd met behulp van Druid en verwerkt met succes meer dan vijf miljoen gebeurtenissen per seconde van Kafka. Dit toont de schaalbaarheid en krachtige mogelijkheden van Druid bij het afhandelen van enorme evenementenvolumes.
Realtime analyse gaat echter verder dan alleen toegang hebben tot realtime gegevens. Om inzicht te krijgen in patronen en gedragingen is het essentieel om ook historische data te correleren. Apache Druid blinkt in dit opzicht uit, zoals weergegeven in het bovenstaande diagram, door zowel real-time als historische analyse naadloos te ondersteunen via een enkele SQL-query. Druid beheert efficiënt grote hoeveelheden gegevens, zelfs tot petabytes, op de achtergrond, waardoor uitgebreide en geïntegreerde analyses over verschillende tijdsperioden mogelijk zijn.
Wanneer alle stukjes bij elkaar worden gebracht, ontstaat een zeer schaalbare data-architectuur voor real-time analyse. Deze architectuur is de voorkeurskeuze van duizenden gegevensarchitecten wanneer ze hoge schaalbaarheid, lage latentie en de mogelijkheid om complexe aggregaties op realtime gegevens uit te voeren, nodig hebben. Door gebruik te maken van event streaming met Apache Kafka of Amazon Kinesis, gecombineerd met de kracht van Apache Druid voor efficiënte real-time en historische analyse, kunnen organisaties robuuste en uitgebreide inzichten uit hun data halen.
Casestudy: zorgen voor een eersteklas kijkervaring - de Netflix-benadering
Realtime analyse is een cruciaal onderdeel in het niet-aflatende streven van Netflix om een uitzonderlijke ervaring te bieden aan meer dan 200 miljoen gebruikers, die samen dagelijks 250 miljoen uur aan content consumeren. Met een observatietoepassing die is afgestemd op real-time monitoring, houdt Netflix effectief toezicht op meer dan 300 miljoen apparaten om optimale prestaties en klanttevredenheid te garanderen.

Door gebruik te maken van realtime logboeken die zijn gegenereerd door afspeelapparaten, die naadloos worden gestreamd via Apache Kafka en gebeurtenis voor gebeurtenis worden opgenomen in Apache Druid, verkrijgt Netflix waardevolle inzichten en kwantificeerbare metingen met betrekking tot de prestaties van gebruikersapparaten tijdens browse- en afspeelactiviteiten.
Met een verbazingwekkende verwerkingscapaciteit van meer dan twee miljoen gebeurtenissen per seconde en razendsnelle query's van minder dan een seconde die worden uitgevoerd op een enorme dataset van 1.5 biljoen rijen, beschikken Netflix-technici over de mogelijkheid om afwijkingen in hun infrastructuur, eindpuntactiviteit en contentstroom nauwkeurig te identificeren en te onderzoeken .
Ontgrendel realtime inzichten met Apache Druid, Apache Kafka en Amazon Kinesis
Als je geïnteresseerd bent in het bouwen van realtime analyseoplossingen, raad ik je ten zeerste aan om Apache Druid te verkennen in combinatie met Apache Kafka en Amazon Kinesis.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://www.dataversity.net/architecting-real-time-analytics-for-speed-and-scale/

