
Afbeelding gemaakt door auteur met Midjourney
- De Chain-of-Thought (CoVe) prompt engineering-methode is ontworpen om hallucinaties bij LLM's te verminderen, door het genereren van plausibele maar onjuiste feitelijke informatie aan te pakken
- Via een proces in vier stappen stelt CoVe LLM's in staat antwoorden op te stellen, te verifiëren en te verfijnen, waardoor een zelfverifiërend mechanisme wordt bevorderd dat de nauwkeurigheid verbetert, gestructureerde zelfverificatie
- CoVe heeft verbeterde prestaties aangetoond bij verschillende taken, zoals op lijsten gebaseerde vragen en het genereren van lange tekst, waarmee het potentieel ervan wordt aangetoond bij het verminderen van hallucinaties en het versterken van de juistheid van door AI gegenereerde tekst
We bestuderen het vermogen van taalmodellen om na te denken over de antwoorden die ze geven, om zo hun fouten te corrigeren.
Het meedogenloze streven naar nauwkeurigheid en betrouwbaarheid op het gebied van kunstmatige intelligentie (AI) heeft geleid tot baanbrekende technieken op het gebied van snelle engineering. Deze technieken spelen een cruciale rol bij het begeleiden van generatieve modellen om nauwkeurige en betekenisvolle antwoorden te geven op een groot aantal vragen. De recente komst van de Keten van verificatie (CoVe)-methode markeert een belangrijke mijlpaal in deze zoektocht. Deze innovatieve techniek heeft tot doel een berucht probleem in grote taalmodellen (LLM's) aan te pakken: het genereren van plausibele maar onjuiste feitelijke informatie, in de volksmond bekend als hallucinaties. Door modellen in staat te stellen na te denken over hun antwoorden en een zelfverifiërend proces te ondergaan, schept CoVe een veelbelovend precedent bij het verbeteren van de betrouwbaarheid van gegenereerde tekst.
Het snelgroeiende ecosysteem van LLM's, met hun vermogen om tekst te verwerken en te genereren op basis van enorme corpora aan documenten, heeft blijk gegeven van opmerkelijke vaardigheid in verschillende taken. Er blijft echter een slepende zorg bestaan: de neiging om gehallucineerde informatie te genereren, vooral over minder bekende of zeldzame onderwerpen. De Chain-of-Verification-methode komt naar voren als een baken van hoop te midden van deze uitdagingen en biedt een gestructureerde aanpak om hallucinaties te minimaliseren en de nauwkeurigheid van de gegenereerde reacties te verbeteren.
CoVe ontvouwt een mechanisme in vier stappen om hallucinaties bij LLM's te verminderen:
- Het opstellen van een eerste reactie
- Verificatievragen plannen om het concept op feiten te controleren
- Deze vragen onafhankelijk beantwoorden om vooringenomenheid te voorkomen
- Het genereren van een definitief geverifieerd antwoord op basis van de antwoorden
Deze systematische aanpak pakt niet alleen de bezorgdheid over hallucinaties aan, maar omvat ook een zelfverifiërend proces dat de juistheid van de gegenereerde tekst naar een hoger niveau tilt. De werkzaamheid van de methode is aangetoond bij een verscheidenheid aan taken, waaronder op lijsten gebaseerde vragen, QA met gesloten boek en het genereren van lange teksten, wat een afname van het aantal hallucinaties en een verbetering van de prestaties laat zien.
Het adopteren van CoVe impliceert het integreren van het vierstappenproces in de workflow van LLM's. Als een LLM die CoVe gebruikt bijvoorbeeld de opdracht krijgt om een lijst met historische gebeurtenissen te genereren, stelt hij in eerste instantie een antwoord op, plant hij verificatievragen om elke gebeurtenis op feiten te controleren, beantwoordt hij deze vragen onafhankelijk en genereert hij ten slotte een geverifieerde lijst op basis van de ontvangen validatie. .
Het rigoureuze verificatieproces dat inherent is aan CoVe zorgt voor een hogere mate van nauwkeurigheid en betrouwbaarheid in de gegenereerde antwoorden. Deze gedisciplineerde benadering van verificatie verrijkt niet alleen de kwaliteit van informatie, maar bevordert ook een cultuur van verantwoordelijkheid binnen het AI-generatieproces, wat een aanzienlijke stap betekent in de richting van betrouwbaardere, door AI gegenereerde tekst.
Voorbeeld 1
- Vraag: Lijst opmerkelijke uitvindingen uit de 20e eeuw.
- Eerste ruwe versie: Internet, kwantummechanica, ontdekking van DNA-structuren
- Verificatievragen: Is het internet uitgevonden in de 20e eeuw? Is de kwantummechanica in de 20e eeuw ontwikkeld? Werd de structuur van DNA ontdekt in de 20e eeuw?
- Laatste geverifieerde reactie: Internet, ontdekking van penicilline, ontdekking van DNA-structuur
Voorbeeld 2
- Vraag: Geef een lijst met landen in Afrika op.
- Eerste ruwe versie: Nigeria, Ethiopië, Egypte, Zuid-Afrika, Soedan
- Verificatievragen: Ligt Nigeria in Afrika? Ligt Ethiopië in Afrika? Ligt Egypte in Afrika? Ligt Zuid-Afrika in Afrika? Ligt Soedan in Afrika?
- Laatste geverifieerde reactie: Nigeria, Ethiopië, Egypte, Zuid-Afrika, Soedan
Het adopteren van CoVe impliceert het integreren van het vierstappenproces in de workflow van LLM's. Als een LLM die CoVe gebruikt bijvoorbeeld de opdracht krijgt om een lijst met historische gebeurtenissen te genereren, stelt hij in eerste instantie een antwoord op, plant hij verificatievragen om elke gebeurtenis op feiten te controleren, beantwoordt hij deze vragen onafhankelijk en genereert hij ten slotte een geverifieerde lijst op basis van de ontvangen validatie. .
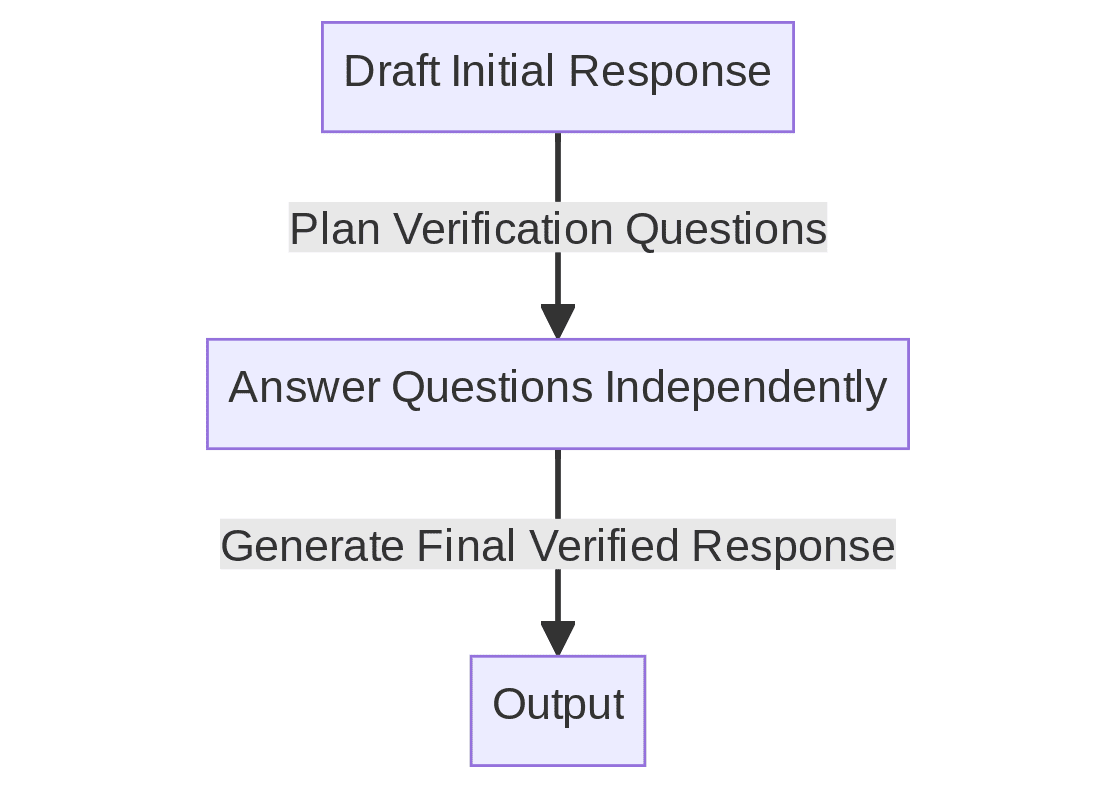
Figuur 1: Het vereenvoudigde proces van verificatieketen (Afbeelding door auteur)
De methodologie zou voorbeelden uit de context vereisen, samen met de vraag om de LLM te stellen, of een LLM zou kunnen worden verfijnd op CoVe-voorbeelden om elke vraag op deze manier te benaderen, mocht dat gewenst zijn.
De komst van de Chain-of-Verification-methode is een bewijs van de vooruitgang die is geboekt op het gebied van snelle engineering in de richting van het bereiken van betrouwbare en nauwkeurige door AI gegenereerde tekst. Door het hallucinatieprobleem frontaal aan te pakken, biedt CoVe een robuuste oplossing die de kwaliteit van de door LLM's gegenereerde informatie verbetert. De gestructureerde aanpak van de methode, in combinatie met het zelfverifiërende mechanisme, belichaamt een aanzienlijke sprong in de richting van het bevorderen van een betrouwbaarder en feitelijker AI-generatieproces.
De implementatie van CoVe is een luide oproep aan zowel praktijkmensen als onderzoekers om door te gaan met het verkennen en verfijnen van technieken op het gebied van snelle engineering. Het omarmen van dergelijke innovatieve methoden zal van groot belang zijn bij het ontsluiten van het volledige potentieel van grote taalmodellen, en belooft een toekomst waarin de betrouwbaarheid van door AI gegenereerde tekst niet alleen een streven is, maar een realiteit.
Matthijs Mayo (@mattmayo13) heeft een masterdiploma in computerwetenschappen en een universitair diploma in datamining. Als hoofdredacteur van KDnuggets wil Matthew complexe datawetenschapsconcepten toegankelijk maken. Zijn professionele interesses omvatten de verwerking van natuurlijke taal, machine learning-algoritmen en het verkennen van opkomende AI. Hij wordt gedreven door een missie om kennis in de data science-gemeenschap te democratiseren. Matthew codeert al sinds hij zes jaar oud was.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/unlocking-reliable-generations-through-chain-of-verification?utm_source=rss&utm_medium=rss&utm_campaign=unlocking-reliable-generations-through-chain-of-verification-a-leap-in-prompt-engineering

