
Afbeelding door redacteur
Datawetenschap is een vakgebied dat de afgelopen honderd jaar enorm is gegroeid dankzij de vooruitgang op het gebied van de informatica. Nu de kosten voor computer- en cloudopslag goedkoper worden, kunnen we nu grote hoeveelheden gegevens tegen zeer lage kosten opslaan in vergelijking met een paar jaar geleden. Met de toename van de rekenkracht kunnen we machine learning-algoritmen op grote sets gegevens uitvoeren en deze gebruiken om inzichten te produceren. Dankzij de vooruitgang op het gebied van netwerken kunnen we razendsnel gegevens via internet genereren en verzenden. Als gevolg van dit alles leven we in een tijdperk waarin elke seconde een overvloed aan gegevens wordt gegenereerd. We beschikken over gegevens in de vorm van e-mail, financiële transacties, sociale media-inhoud, webpagina’s op internet, klantgegevens van bedrijven, medische dossiers van patiënten, fitnessgegevens van smartwatches, video-inhoud op YouTube, telemetrie van smart-devices en de lijst gaat verder. Deze overvloed aan gegevens, zowel in gestructureerd als ongestructureerd formaat, heeft ons doen belanden in een vakgebied dat Data Mining heet.
Data Mining is het proces van het ontdekken van patronen, afwijkingen en correlaties uit grote datasets om een uitkomst te voorspellen. Hoewel dataminingtechnieken op elke vorm van data kunnen worden toegepast, is een dergelijke tak van datamining dat wel Text Mining wat verwijst naar het vinden van betekenisvolle informatie uit ongestructureerde tekstuele gegevens. In dit artikel zal ik me concentreren op een veel voorkomende taak in Text Mining, namelijk het vinden van Documentgelijkenis.
Documentgelijkenis helpt bij het efficiënt ophalen van informatie. Toepassingen van documentovereenkomst zijn onder meer: het detecteren van plagiaat, het effectief beantwoorden van zoekopdrachten op internet, het clusteren van onderzoeksartikelen op onderwerp, het vinden van soortgelijke nieuwsartikelen, het clusteren van soortgelijke vragen in een vraag- en antwoordsite zoals Quora, StackOverflow, Reddit en het groeperen van producten op Amazon op basis van de beschrijving , enz. Documentgelijkenis wordt ook gebruikt door bedrijven als DropBox en Google Drive om te voorkomen dat dubbele kopieën van hetzelfde document worden opgeslagen, waardoor verwerkingstijd en opslagkosten worden bespaard.
Er zijn verschillende stappen om de gelijkenis van documenten te berekenen. De eerste stap is om het document in vectorformaat weer te geven. We kunnen dan paarsgewijze gelijkenisfuncties op deze vectoren gebruiken. Een gelijkenisfunctie is een functie die de mate van gelijkenis tussen een paar vectoren berekent. Er zijn verschillende paarsgewijze gelijkenisfuncties zoals: – Euclidische afstand, cosinus-gelijkenis, Jaccard-gelijkenis, Pearson's correlatie, Spearman's correlatie, Kendall's Tau, enzovoort [2]. Een functie voor paarsgewijze gelijkenis kan worden toegepast op twee documenten, twee zoekopdrachten of tussen een document en een zoekopdracht. Hoewel functies voor paarsgewijze gelijkenis goed geschikt zijn voor het vergelijken van een kleiner aantal documenten, zijn er andere, meer geavanceerde technieken zoals Doc2Vec en BERT die gebaseerd zijn op deep learning-technieken en die door zoekmachines zoals Google worden gebruikt voor het efficiënt ophalen van informatie op basis van de zoekopdracht. In dit artikel zal ik me concentreren op Jaccard-overeenkomst, Euclidische afstand, cosinus-overeenkomst, cosinus-overeenkomst met TF-IDF, Doc2Vec en BERT.
Voorbewerking
Een gebruikelijke stap bij het berekenen van de afstand tussen documenten of overeenkomsten tussen documenten is het uitvoeren van enige voorbewerking op het document. De voorverwerkingsstap omvat het converteren van alle tekst naar kleine letters, het tokeniseren van de tekst, het verwijderen van stopwoorden, het verwijderen van leestekens en het lemmatiseren van woorden[4].
Tokenisatie: Deze stap omvat het opsplitsen van de zinnen in kleinere eenheden voor verwerking. Een token is het kleinste lexicale atoom waarin een zin kan worden opgesplitst. Een zin kan worden opgesplitst in tokens door een spatie als scheidingsteken te gebruiken. Dit is een manier van tokeniseren. Een zin in de vorm 'tokenisatie is een heel coole stap' wordt bijvoorbeeld opgesplitst in tokens van de vorm ['tokenisatie', 'is', a, 'echt', 'cool', 'stap']. Deze tokens vormen de bouwstenen van Text Mining en zijn een van de eerste stappen in het modelleren van tekstuele data.
Kleine letters: Hoewel het behouden van hoofdletters en kleine letters in sommige speciale gevallen nodig kan zijn, willen we in de meeste gevallen woorden met verschillende hoofdletters als één geheel behandelen. Deze stap is belangrijk om consistente resultaten uit een grote dataset te verkrijgen. Als een gebruiker bijvoorbeeld zoekt naar het woord ‘India’, willen we relevante documenten ophalen die woorden in verschillende hoofdletters bevatten, namelijk ‘India’, ‘INDIA’ en ‘india’, als ze relevant zijn voor de zoekopdracht.
Leestekens verwijderen: Door leestekens en spaties te verwijderen, kunt u de zoekopdracht concentreren op belangrijke woorden en tokens.
Stopwoorden verwijderen: Stopwoorden zijn een reeks woorden die vaak in de Engelse taal worden gebruikt. Het verwijderen van dergelijke woorden kan helpen bij het ophalen van documenten die overeenkomen met belangrijkere woorden die de context van de zoekopdracht weergeven. Dit helpt ook bij het verkleinen van de grootte van de kenmerkvector, waardoor de verwerkingstijd wordt vergroot.
Lemmatisering: Lemmatisering helpt bij het verminderen van schaarsheid door woorden aan hun hoofdwoord toe te wijzen. ‘Speelingen’, ‘Gespeeld’ en ‘Spelen’ zijn bijvoorbeeld allemaal toegewezen aan spelen. Door dit te doen verkleinen we ook de omvang van de functieset en matchen we alle variaties van een woord in verschillende documenten om het meest relevante document naar voren te brengen.
Deze methode is een van de gemakkelijkste methoden. Het tokeniseert de woorden en berekent de som van het aantal gedeelde termen tot de som van het totale aantal termen in beide documenten. Als de twee documenten vergelijkbaar zijn, is de score één, als de twee documenten verschillend zijn, is de score nul [3].
Bron afbeelding: O'Reilly
Samengevat: Deze methode heeft enkele nadelen. Naarmate de omvang van het document toeneemt, zal het aantal veel voorkomende woorden toenemen, ook al zijn de twee documenten semantisch verschillend.
Na het voorbewerken van het document, zetten wij het document om naar een vector. Het gewicht van de vector kan de termfrequentie zijn, waarbij we het aantal keren tellen dat de term in het document voorkomt, of het kan de relatieve termfrequentie zijn, waarbij we de verhouding tussen het aantal termen en het totale aantal termen berekenen. in het document [3].
Laat d1 en d2 twee documenten zijn, weergegeven als vectoren van n termen (die n dimensies vertegenwoordigen); we kunnen dan de kortste afstand tussen twee documenten berekenen met behulp van de stelling van Pythagoras om een rechte lijn tussen twee vectoren te vinden. Hoe groter de afstand, hoe lager de gelijkenis; hoe kleiner de afstand, hoe groter de gelijkenis tussen twee documenten.
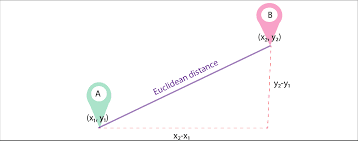
Afbeeldingsbron: Medium.com
Overzicht: Het grote nadeel van deze aanpak is dat wanneer de documenten qua grootte verschillen, de Euclidische afstand een lagere score zal opleveren, ook al zijn de twee documenten qua aard vergelijkbaar. Kleinere documenten zullen resulteren in vectoren met een kleinere omvang en grotere documenten zullen resulteren in vectoren met een grotere omvang, aangezien de grootte van de vector recht evenredig is met het aantal woorden in het document, waardoor de totale afstand groter wordt.
Cosinusgelijkenis meet de gelijkenis tussen documenten door de cosinus van de hoek tussen de twee vectoren te meten. Cosinus-overeenkomstresultaten kunnen een waarde tussen 0 en 1 aannemen. Als de vectoren in dezelfde richting wijzen, is de overeenkomst 1, als de vectoren in tegengestelde richtingen wijzen, is de overeenkomst 0. [6].
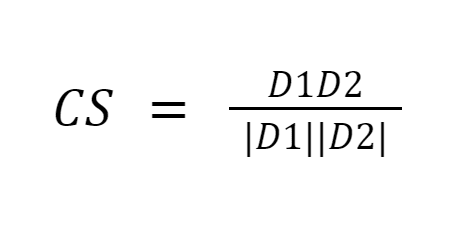
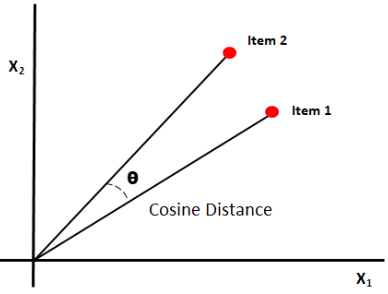
Afbeeldingsbron: Medium.com
Samengevat: Het goede aan cosinusgelijkenis is dat het de oriëntatie tussen vectoren berekent en niet de grootte. Het zal dus de gelijkenis vastleggen tussen twee documenten die vergelijkbaar zijn, ondanks dat ze een verschillende grootte hebben.
Het fundamentele nadeel van de bovengenoemde drie benaderingen is dat de meting het niet oplevert om vergelijkbare documenten op basis van semantiek te vinden. Bovendien kunnen al deze technieken alleen paarsgewijs worden uitgevoerd, waardoor meer vergelijkingen nodig zijn.
Deze methode voor het vinden van documentovereenstemming wordt gebruikt in standaard zoekimplementaties van ElasticSearch en bestaat al sinds 1972 [4]. tf-idf staat voor term frequentie-inverse documentfrequentie. We berekenen eerst de term frequentie met behulp van deze formule
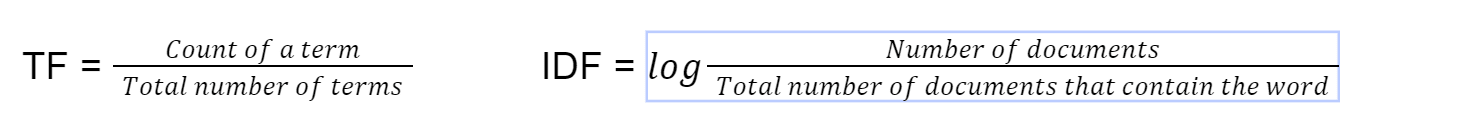
Tenslotte berekenen we tf-idf door TF*IDF te vermenigvuldigen. Vervolgens gebruiken we cosinusovereenkomst op de vector met tf-idf als het gewicht van de vector.
Samengevat: Door de termfrequentie te vermenigvuldigen met de inverse documentfrequentie, worden bepaalde woorden gecompenseerd die in het algemeen vaker voorkomen in documenten en wordt de nadruk gelegd op woorden die per document verschillen. Deze techniek helpt bij het vinden van documenten die overeenkomen met een zoekopdracht door de zoekopdracht te concentreren op belangrijke trefwoorden.
Hoewel het gemakkelijker te implementeren is om individuele woorden (BOW – Bag of Words) uit documenten te gebruiken om ze naar vectoren te converteren, geeft dit geen enkele betekenis aan de volgorde van woorden in een zin. Doc2Vec is gebouwd bovenop Word2Vec. Terwijl Word2Vec de betekenis van een woord vertegenwoordigt, vertegenwoordigt Doc2Vec de betekenis van een document of paragraaf [5].
Deze methode wordt gebruikt om een document naar zijn vectorrepresentatie te converteren, terwijl de semantische betekenis van het document behouden blijft. Deze aanpak converteert teksten met een variabele lengte, zoals zinnen, alinea's of documenten, naar vectoren [5]. Vervolgens wordt de doc2vec-modus getraind. De training van de modellen is vergelijkbaar met het trainen van andere machine learning-modellen door trainingssets en testsetdocumenten te kiezen en de afstemmingsparameters aan te passen om betere resultaten te bereiken.
Samengevat: Een dergelijke gevectoriseerde vorm van het document behoudt de semantische betekenis van het document, aangezien paragrafen met een vergelijkbare context of betekenis dichter bij elkaar zullen staan tijdens de conversie naar vector.
BERT is een op transformatoren gebaseerd machine learning-model dat wordt gebruikt in NLP-taken, ontwikkeld door Google.
Met de komst van BERT (Bidirectionele Encoder Representaties van Transformers) worden NLP-modellen getraind met enorme, ongelabelde tekstcorpora die een tekst zowel van rechts naar links als van links naar rechts bekijken. BERT gebruikt een techniek genaamd “Aandacht” om de resultaten te verbeteren. De zoekresultaten van Google verbeterden met een enorme marge na het gebruik van BERT [4]. Enkele van de unieke kenmerken van BERT zijn onder meer
- Vooraf getraind met Wikipedia-artikelen uit 104 talen.
- Kijkt naar tekst zowel van links naar rechts als van rechts naar links
- Helpt bij het begrijpen van de context
Samengevat: Als gevolg hiervan kan BERT worden verfijnd voor een groot aantal toepassingen, zoals het beantwoorden van vragen, het parafraseren van zinnen, Spam Classifier, Build-taaldetector zonder substantiële taakspecifieke architectuurwijzigingen.
Het was geweldig om te leren hoe gelijkenisfuncties worden gebruikt bij het vinden van documentovereenkomst. Momenteel is het aan de ontwikkelaar om een gelijkenisfunctie te kiezen die het beste bij het scenario past. tf-idf is momenteel bijvoorbeeld de stand van de techniek voor het matchen van documenten, terwijl BERT de stand van de techniek is voor het zoeken naar zoekopdrachten. Het zou geweldig zijn om een tool te bouwen die automatisch detecteert welke gelijkenisfunctie het meest geschikt is op basis van het scenario en zo een gelijkenisfunctie te kiezen die is geoptimaliseerd voor geheugen en verwerkingstijd. Dit zou enorm kunnen helpen in scenario's zoals het automatisch matchen van cv's met functiebeschrijvingen, het clusteren van documenten op categorie, het classificeren van patiënten in verschillende categorieën op basis van medische dossiers van patiënten, enz.
In dit artikel heb ik enkele opmerkelijke algoritmen besproken om de gelijkenis van documenten te berekenen. Het is geenszins een uitputtende lijst. Er zijn verschillende andere methoden om de gelijkenis van documenten te vinden en de beslissing om de juiste te kiezen hangt af van het specifieke scenario en de gebruikssituatie. Eenvoudige statistische methoden zoals tf-idf, Jaccard, Euclidien en Cosine-gelijkenis zijn zeer geschikt voor eenvoudiger gebruiksscenario's. Je kunt eenvoudig een configuratie maken met bestaande bibliotheken die beschikbaar zijn in Python en R en de gelijkenisscore berekenen zonder dat daarvoor zware machines of verwerkingsmogelijkheden nodig zijn. Geavanceerdere algoritmen zoals BERT zijn afhankelijk van het vooraf trainen van neurale netwerken, wat uren kan duren, maar efficiënte resultaten oplevert voor analyse waarvoor begrip van de context van het document vereist is.
Referentie
[1] Heidarian, A., & Dinneen, MJ (2016). Een hybride geometrische benadering voor het meten van het gelijkenisniveau tussen documenten en documentclustering. 2016 IEEE Tweede internationale conferentie over big data computing-services en -applicaties (BigDataService), 1-5. https://doi.org/10.1109/bigdataservice.2016.14
[2] Kavitha Karun A, Philip, M., & Lubna, K. (2013). Vergelijkende analyse van gelijkenismaatregelen bij documentclustering. Internationale conferentie over groen computergebruik, communicatie en energiebehoud 2013 (ICGCE), 1-4. https://doi.org/10.1109/icgce.2013.6823554
[3] Lin, Y.-S., Jiang, J.-Y., & Lee, S.-J. (2014). Een gelijkenismaatstaf voor tekstclassificatie en clustering. IEEE-transacties op kennis- en data-engineering, 26(7), 1575-1590. https://doi.org/10.1109/tkde.2013.19
[4] Nishimura, M. (2020, 9 september). Het beste algoritme voor documentovereenstemming in 2020: een beginnershandleiding – op weg naar datawetenschap. Medium. https://towardsdatascience.com/the-best-document-similarity-algorithm-in-2020-a-beginners-guide-a01b9ef8cf05
[5] Sharaki, O. (2020, 10 juli). Documentovereenstemming detecteren met Doc2vec – Op weg naar datawetenschap. Medium. https://towardsdatascience.com/detecting-document-similarity-with-doc2vec-f8289a9a7db7
[6] Lüthe, M. (2019, 18 november). Bereken gelijkenis – de meest relevante statistieken in een notendop – richting datawetenschap. Medium. https://towardsdatascience.com/calculate-similarity-the-most-relevant-metrics-in-a-nutshell-9a43564f533e
[7] S. (2019, 27 oktober). Gelijkenismaatstaven – Scoren van tekstartikelen – Op weg naar datawetenschap. Medium. https://towardsdatascience.com/similarity-measures-e3dbd4e58660
Poornima Muthukumar is een Senior Technical Product Manager bij Microsoft met meer dan 10 jaar ervaring in het ontwikkelen en leveren van innovatieve oplossingen voor verschillende domeinen zoals cloud computing, kunstmatige intelligentie, gedistribueerde en big data-systemen. Ik heb een masterdiploma in Data Science van de Universiteit van Washington. Ik heb vier patenten bij Microsoft, gespecialiseerd in AI/ML en Big Data Systems, en was de winnaar van de Global Hackathon in 2016 in de categorie Artificial Intelligence. Ik had de eer om dit jaar 2023 deel uit te maken van het beoordelingspanel van de Grace Hopper Conference voor de categorie Software Engineering. Het was een lonende ervaring om de inzendingen van getalenteerde vrouwen op deze gebieden te lezen en te evalueren en ook bij te dragen aan de vooruitgang van vrouwen in de technologie. om van hun onderzoek en inzichten te leren. Ik was ook commissielid voor de conferentie Microsoft Machine Learning AI and Data Science (MLADS) in juni 2023. Ik ben ook ambassadeur bij de Women in Data Science Worldwide Community en Women Who Code Data Science Community.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/evaluating-methods-for-calculating-document-similarity?utm_source=rss&utm_medium=rss&utm_campaign=evaluating-methods-for-calculating-document-similarity

