Introductie
Retrieval Augmented Generation bestaat al een tijdje. Er worden veel tools en applicaties rond dit concept gebouwd, zoals vectorwinkels, ophaalframeworks en LLM's, waardoor het gemakkelijk wordt om met aangepaste documenten te werken, vooral semi-gestructureerde gegevens met Langchain. Werken met lange, compacte teksten was nog nooit zo eenvoudig en leuk. De conventionele VOD werkt goed met ongestructureerde, tekstrijke bestanden zoals DOC, PDF's, enz. Deze aanpak past echter niet goed bij semi-gestructureerde gegevens, zoals ingesloten tabellen in PDF's.
Bij het werken met semi-gestructureerde gegevens zijn er meestal twee problemen.
- Bij de conventionele extractie- en tekstsplitsingsmethoden wordt geen rekening gehouden met tabellen in PDF's. Meestal breken ze de tafels af. Met als gevolg informatieverlies.
- Het insluiten van tabellen vertaalt zich mogelijk niet in nauwkeurig semantisch zoeken.
Daarom zullen we in dit artikel met Langchain een Retrieval-generatiepijplijn voor semi-gestructureerde gegevens bouwen om deze twee problemen met semi-gestructureerde gegevens aan te pakken.
leerdoelen
- Begrijp het verschil tussen gestructureerde, ongestructureerde en semi-gestructureerde gegevens.
- Een milde opfrisser over Retrieval Augement Generation en Langchain.
- Leer hoe u een multi-vector retriever kunt bouwen om semi-gestructureerde gegevens te verwerken met Langchain.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Typen gegevens
Er zijn doorgaans drie soorten gegevens. Gestructureerd, semi-gestructureerd en ongestructureerd.
- Gestructureerde gegevens: De gestructureerde gegevens zijn de gestandaardiseerde gegevens. De gegevens volgen een vooraf gedefinieerd schema, zoals rijen en kolommen. SQL-databases, spreadsheets, dataframes, enz.
- Ongestructureerde gegevens: Ongestructureerde gegevens volgen, in tegenstelling tot gestructureerde gegevens, geen gegevensmodel. De gegevens zijn zo willekeurig als maar kan. Bijvoorbeeld PDF's, teksten, afbeeldingen, enz.
- Semi-gestructureerde gegevens: Het is de combinatie van de vorige gegevenstypen. In tegenstelling tot de gestructureerde gegevens heeft deze geen rigide, vooraf gedefinieerd schema. De gegevens behouden echter nog steeds een hiërarchische volgorde op basis van enkele markeringen, wat in tegenstelling is tot ongestructureerde typen. Bijvoorbeeld CSV's, HTML, ingesloten tabellen in PDF's, XML's, enz.

Wat is RAG?
RAG staat voor Retrieval Augmented Generation. Het is de eenvoudigste manier om de grote taalmodellen te voeden met nieuwe informatie. Laten we dus een korte introductie geven over RAG.
In een typische RAG-pijplijn hebben we kennisbronnen, zoals lokale bestanden, webpagina's, databases, enz., een inbeddingsmodel, een vectordatabase en een LLM. We verzamelen de gegevens uit verschillende bronnen, splitsen de documenten, verkrijgen de insluiting van tekstblokken en slaan deze op in een vectordatabase. Nu geven we de inbedding van query's door aan het vectorarchief, halen de documenten op uit het vectorarchief en genereren uiteindelijk antwoorden met de LLM.
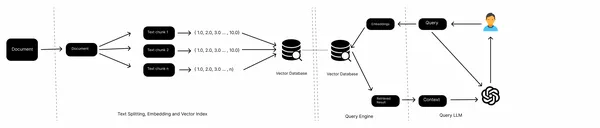
Dit is een workflow van een conventionele RAG en werkt goed met ongestructureerde gegevens zoals teksten. Als het echter gaat om semi-gestructureerde gegevens, bijvoorbeeld ingebedde tabellen in een PDF, presteert het vaak niet goed. In dit artikel leren we hoe u met deze ingebedde tabellen kunt omgaan.
Wat is Langchain?
De Langchain is een open-sourceframework voor het bouwen van op LLM gebaseerde applicaties. Sinds de lancering heeft het project brede acceptatie gekregen onder softwareontwikkelaars. Het biedt een uniforme reeks tools en technologieën om AI-applicaties sneller te bouwen. Langchain herbergt tools zoals vectorwinkels, documentladers, retrievers, inbeddingsmodellen, tekstsplitters, enz. Het is een alles-in-één oplossing voor het bouwen van AI-applicaties. Maar er zijn twee kernwaardeproposities waardoor het zich onderscheidt.
- LLM-ketens: Langchain biedt meerdere ketens. Deze ketens koppelen verschillende hulpmiddelen aan elkaar om één enkele taak te volbrengen. ConversationalRetrievalChain koppelt bijvoorbeeld een LLM, Vector Store Retriever, inbeddingsmodel en een chatgeschiedenisobject aan elkaar om antwoorden op een query te genereren. De tools zijn hard gecodeerd en moeten expliciet worden gedefinieerd.
- LLM-agenten: In tegenstelling tot LLM-ketens beschikken AI-agenten niet over hardgecodeerde tools. In plaats van de ene tool na de andere aan elkaar te koppelen, laten we de LLM beslissen welke tool hij selecteert en wanneer, op basis van tekstbeschrijvingen van tools. Dit maakt het ideaal voor het bouwen van complexe LLM-toepassingen waarbij redenering en besluitvorming betrokken zijn.
Aanleg van de RAG-pijpleiding
Nu we een inleiding hebben over de concepten. Laten we de aanpak voor het bouwen van de pijpleiding bespreken. Het werken met semi-gestructureerde data kan lastig zijn, omdat er geen conventioneel schema voor het opslaan van informatie wordt gevolgd. En om met ongestructureerde data te kunnen werken, hebben we gespecialiseerde tools nodig die op maat zijn gemaakt voor het extraheren van informatie. In dit project zullen we dus zo'n tool gebruiken die 'ongestructureerd' wordt genoemd; het is een open-source tool voor het extraheren van informatie uit verschillende ongestructureerde dataformaten, zoals tabellen in PDF's, HTML, XML, etc. Unstructured gebruikt Tesseract en Poppler onder de motorkap om meerdere dataformaten in bestanden te verwerken. Laten we dus onze omgeving opzetten en afhankelijkheden installeren voordat we in het codeergedeelte duiken.
Ontwikkelaaromgeving instellen
Open, net als bij elk ander Python-project, een Python-omgeving en installeer Poppler en Tesseract.
!sudo apt install tesseract-ocr
!sudo apt-get install poppler-utilsInstalleer nu de afhankelijkheden die we nodig hebben in ons project.
!pip install "unstructured[all-docs]" Langchain openaiNu we de afhankelijkheden hebben geïnstalleerd, gaan we gegevens uit een PDF-bestand extraheren.
from unstructured.partition.pdf import partition_pdf
pdf_elements = partition_pdf(
"mistral7b.pdf",
chunking_strategy="by_title",
extract_images_in_pdf=True,
max_characters=3000,
new_after_n_chars=2800,
combine_text_under_n_chars=2000,
image_output_dir_path="./"
)Als u het uitvoert, worden verschillende afhankelijkheden zoals YOLOx geïnstalleerd die nodig zijn voor OCR en worden objecttypen geretourneerd op basis van geëxtraheerde gegevens. Als u extract_images_in_pdf inschakelt, kunt u ongestructureerde ingebedde afbeeldingen uit bestanden extraheren. Dit kan helpen bij het implementeren van multimodale oplossingen.
Laten we nu de categorieën met elementen uit onze PDF verkennen.
# Create a dictionary to store counts of each type
category_counts = {}
for element in pdf_elements:
category = str(type(element))
if category in category_counts:
category_counts[category] += 1
else:
category_counts[category] = 1
# Unique_categories will have unique elements
unique_categories = set(category_counts.keys())
category_countsAls u dit uitvoert, worden elementcategorieën en hun aantal weergegeven.
Nu scheiden we de elementen voor eenvoudige bediening. We creëren een elementtype dat overneemt van het documenttype van Langchain. Dit is om te zorgen voor meer georganiseerde gegevens, die gemakkelijker te verwerken zijn.
from unstructured.documents.elements import CompositeElement, Table
from langchain.schema import Document
class Element(Document):
type: str
# Categorize by type
categorized_elements = []
for element in pdf_elements:
if isinstance(element, Table):
categorized_elements.append(Element(type="table", page_content=str(element)))
elif isinstance(element, CompositeElement):
categorized_elements.append(Element(type="text", page_content=str(element)))
# Tables
table_elements = [e for e in categorized_elements if e.type == "table"]
# Text
text_elements = [e for e in categorized_elements if e.type == "text"]Multi-vector retriever
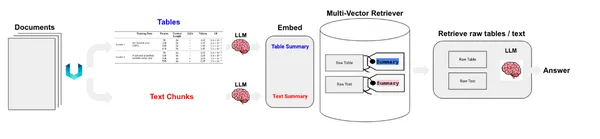
We hebben tabel- en tekstelementen. Er zijn twee manieren waarop we hiermee om kunnen gaan. We kunnen de ruwe elementen opslaan in een documentopslag of samenvattingen van teksten opslaan. Tabellen kunnen een uitdaging vormen voor semantisch zoeken; in dat geval maken we de samenvattingen van tabellen en slaan deze samen met de onbewerkte tabellen op in een documentopslag. Om dit te bereiken zullen we MultiVectorRetriever gebruiken. Deze retriever beheert een vectoropslag waarin we de insluitingen van samenvattingsteksten opslaan en een eenvoudige documentopslag in het geheugen om onbewerkte documenten op te slaan.
Bouw eerst een samenvattende keten om de tabel- en tekstgegevens samen te vatten die we eerder hebben geëxtraheerd.
from langchain.chat_models import cohere
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
prompt_text = """You are an assistant tasked with summarizing tables and text.
Give a concise summary of the table or text. Table or text chunk: {element} """
prompt = ChatPromptTemplate.from_template(prompt_text)
model = cohere.ChatCohere(cohere_api_key="your_key")
summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()
tables = [i.page_content for i in table_elements]
table_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})
texts = [i.page_content for i in text_elements]
text_summaries = summarize_chain.batch(texts, {"max_concurrency": 5})Ik heb Cohere LLM gebruikt voor het samenvatten van gegevens; u kunt OpenAI-modellen zoals GPT-4 gebruiken. Betere modellen zullen betere resultaten opleveren. Soms geven de modellen tabeldetails mogelijk niet perfect weer. Het is dus beter om capabele modellen te gebruiken.
Nu maken we de MultivectorRetriever.
from langchain.retrievers import MultiVectorRetriever
from langchain.prompts import ChatPromptTemplate
import uuid
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema.document import Document
from langchain.storage import InMemoryStore
from langchain.vectorstores import Chroma
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name="collection",
embedding_function=OpenAIEmbeddings(openai_api_key="api_key"))
# The storage layer for the parent documents
store = InMemoryStore()
id_key = ""id"
# The retriever
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=store,
id_key=id_key,
)
# Add texts
doc_ids = [str(uuid.uuid4()) for _ in texts]
summary_texts = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
for i, s in enumerate(text_summaries)
]
retriever.vectorstore.add_documents(summary_texts)
retriever.docstore.mset(list(zip(doc_ids, texts)))
# Add tables
table_ids = [str(uuid.uuid4()) for _ in tables]
summary_tables = [
Document(page_content=s, metadata={id_key: table_ids[i]})
for i, s in enumerate(table_summaries)
]
retriever.vectorstore.add_documents(summary_tables)
retriever.docstore.mset(list(zip(table_ids, tables)))
We gebruikten Chroma-vectoropslag voor het opslaan van samenvattingen van teksten en tabellen en een in-memory documentopslag om onbewerkte gegevens op te slaan.
VOD
Nu onze retriever klaar is, kunnen we een RAG-pijplijn bouwen met behulp van Langchain Expression Language.
from langchain.schema.runnable import RunnablePassthrough
# Prompt template
template = """Answer the question based only on the following context,
which can include text and tables::
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# LLM
model = ChatOpenAI(temperature=0.0, openai_api_key="api_key")
# RAG pipeline
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
Nu kunnen we vragen stellen en antwoorden ontvangen op basis van opgehaalde inbedding uit de vectorwinkel.
chain.invoke(input = "What is the MT bench score of Llama 2 and Mistral 7B Instruct??")Conclusie
Veel informatie blijft verborgen in semi-gestructureerde dataformaten. En het is een uitdaging om conventionele RAG's op deze gegevens te extraheren en uit te voeren. In dit artikel gingen we van het extraheren van teksten en ingesloten tabellen in de PDF naar het bouwen van een multi-vector retriever en RAG-pijplijn met Langchain. Hier zijn dus de belangrijkste conclusies uit het artikel.
Key Takeaways
- Conventionele RAG wordt vaak geconfronteerd met uitdagingen bij het omgaan met semi-gestructureerde gegevens, zoals het opsplitsen van tabellen tijdens het splitsen van tekst en onnauwkeurige semantische zoekopdrachten.
- Unstructured, een open source-tool voor semi-gestructureerde gegevens, kan ingesloten tabellen extraheren uit PDF's of soortgelijke semi-gestructureerde gegevens.
- Met Langchain kunnen we een multi-vector retriever bouwen voor het opslaan van tabellen, teksten en samenvattingen in documentarchieven voor beter semantisch zoeken.
Veelgestelde Vragen / FAQ
A: Semi-gestructureerde gegevens hebben, in tegenstelling tot gestructureerde gegevens, geen rigide schema, maar hebben andere vormen van markeringen om hiërarchieën af te dwingen.
A. Voorbeelden van semi-gestructureerde gegevens zijn CSV, e-mails, HTML, XML, parketbestanden, enz.
A. LangChain is een open-sourceframework dat het maken van applicaties met behulp van grote taalmodellen vereenvoudigt. Het kan voor verschillende taken worden gebruikt, waaronder chatbots, RAG, het beantwoorden van vragen en generatieve taken.
A. Een RAG-pijplijn haalt documenten op uit externe datastores, verwerkt ze om ze op te slaan in een kennisbank en biedt tools om ze te bevragen.
A. Llama Index ontwerpt expliciet zoek- en ophaaltoepassingen, terwijl Langchain flexibiliteit biedt voor het maken van aangepaste AI-agents.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/12/building-a-rag-pipeline-for-semi-structured-data-with-langchain/

