Er is tegenwoordig geen gebrek aan tekstgegevens. Elke dag worden enorme hoeveelheden tekst gemaakt, met deze gegevens variërend van volledig gestructureerd tot semi-gestructureerd tot volledig ongestructureerd.
Wat kunnen we met deze tekst? Nou ja, nogal wat eigenlijk; afhankelijk van wat uw doelstellingen precies zijn, zijn er 2 ingewikkeld gerelateerde maar gedifferentieerde takenpakketen die kunnen worden benut om de beschikbaarheid van al deze gegevens te benutten.
Laten we beginnen met enkele definities.
Natuurlijke taalverwerking (NLP) houdt zich bezig met de interactie tussen natuurlijke menselijke talen en computerapparatuur. NLP is een belangrijk aspect van computerlinguïstiek en valt ook binnen de domeinen van informatica en kunstmatige intelligentie.
Tekstmining bestaat in een soortgelijk domein als NLP, in die zin dat het zich bezighoudt met het identificeren van interessante, niet-triviale patronen in tekstuele gegevens.
Zoals je misschien uit het bovenstaande kunt opmaken, zijn de exacte grenzen van deze 2 concepten niet goed gedefinieerd en overeengekomen, en lopen ze in verschillende mate in elkaar over, afhankelijk van de beoefenaars en onderzoekers met wie men dergelijke zaken zou bespreken . Ik vind het het gemakkelijkst om te differentiëren naar mate van inzicht. Als onbewerkte tekst gegevens is, kan tekstmining eruit halen informatie, terwijl NLP extracten kennis (zie de piramide van begrip hieronder). Syntaxis versus semantiek, zo u wilt.

De piramide van begrip: data, informatie, kennis
Er zijn verschillende andere verklaringen voor de precieze relatie tussen text mining en NLP, en je bent vrij om iets te vinden dat beter voor je werkt. We zijn niet zo bezorgd over de exact definities — absoluut of relatief — evenzeer als we zijn met de intuïtieve herkenning dat de concepten met enige overlap samenhangen, maar toch verschillend zijn.
Het punt waar we verder mee gaan: hoewel NLP en tekstmining niet hetzelfde zijn, zijn ze nauw verwant, hebben ze te maken met hetzelfde ruwe datatype en hebben ze enige cross-over in hun gebruik. Voor de rest van onze discussie zullen we deze twee concepten gemakshalve NLP noemen. Belangrijk is dat veel van de voorverwerking van gegevens voor de taken die onder deze 2 paraplu's vallen identiek is.
Ongeacht de exacte NLP-taak die u wilt uitvoeren, het handhaven van de tekstbetekenis en het vermijden van dubbelzinnigheid is van het grootste belang. Als zodanig vormen pogingen om ambiguïteit te vermijden een groot deel van het tekstvoorverwerkingsproces. We willen de bedoelde betekenis behouden en tegelijkertijd ruis elimineren. Om dit te doen, is het volgende vereist:
- Kennis over taal
- Kennis over de wereld
- Een manier om kennisbronnen te combineren
Als dit gemakkelijk was, zouden we er waarschijnlijk niet over praten. Wat zijn enkele redenen waarom het verwerken van tekst moeilijk is?

Bron: CS124 Stanford (https://web.stanford.edu/class/cs124/)
Je hebt misschien iets merkwaardigs opgemerkt aan het bovenstaande: "niet-standaard Engels." Hoewel het zeker niet de bedoeling van de figuur is – we halen het hier volledig uit de context – om verschillende redenen, heeft veel van NLP-onderzoek historisch gezien plaatsgevonden binnen de grenzen van de Engelse taal. Dus we kunnen toevoegen aan de vraag "Waarom is het verwerken van tekst moeilijk?" de extra lagen van problemen die niet-Engelse talen — en vooral talen met een kleiner aantal sprekers, of zelfs bedreigde talen — moeten doorlopen om verwerkt te worden en inzichten te verkrijgen.

Gewoon bewust zijn van het feit dat NLP ≠ Engels bij het denken en spreken over NLP is een kleine manier waarop deze vooringenomenheid kan worden tegengegaan.
Kunnen we een voldoende algemeen kader scheppen voor het benaderen van tekstuele datawetenschapstaken? Het blijkt dat het verwerken van tekst erg lijkt op andere niet-tekstverwerkingstaken, en dus kunnen we kijken naar de KDD-proces voor inspiratie.
We kunnen stellen dat dit de belangrijkste stappen zijn van een generieke tekstgebaseerde taak, die valt onder text mining of NLP.
1. Gegevensverzameling of -assemblage
- Verkrijg of bouw een corpus, dat van alles kan zijn, van e-mails tot de hele reeks Engelse Wikipedia-artikelen, tot de financiële rapporten van ons bedrijf, tot de volledige werken van Shakespeare, tot iets heel anders
2. Voorverwerking van gegevens
- Voer de voorbereidingstaken uit op het onbewerkte tekstcorpus in afwachting van tekstmining of NLP-taak
- De voorverwerking van gegevens bestaat uit een aantal stappen, waarvan elk aantal al dan niet van toepassing is op een bepaalde taak, maar die over het algemeen onder de brede categorieën van tokenisatie, normalisatie en vervanging vallen.
3. Gegevensverkenning en -visualisatie
- Ongeacht wat onze gegevens zijn - tekst of niet - het verkennen en visualiseren ervan is een essentiële stap om inzicht te krijgen
- Veelvoorkomende taken zijn onder meer het visualiseren van het aantal woorden en distributies, het genereren van wordclouds en het uitvoeren van afstandsmetingen
4. Modelbouw
- Hier vindt onze brood en boter text mining of NLP taak plaats (inclusief training en testen)
- Bevat ook functieselectie en engineering indien van toepassing
- Taalmodellen: Eindige-toestandsmachines, Markov-modellen, vectorruimtemodellering van woordbetekenissen
- Machine learning classificaties: Naïeve bayes, logistische regressie, beslissingsbomen, Support Vector Machines, neurale netwerken
- Sequentiemodellen: Verborgen Markov-modellen, recursieve neurale netwerken (RNN's), neurale netwerken op lange korte termijn (LSTM's)
5. Modelevaluatie
- Presteerde het model zoals verwacht?
- Metrieken zijn afhankelijk van het type tekstmining of NLP-taak
- Zelfs out of the box denken met chatbots (een NLP-taak) of generatieve modellen: enige vorm van evaluatie is noodzakelijk
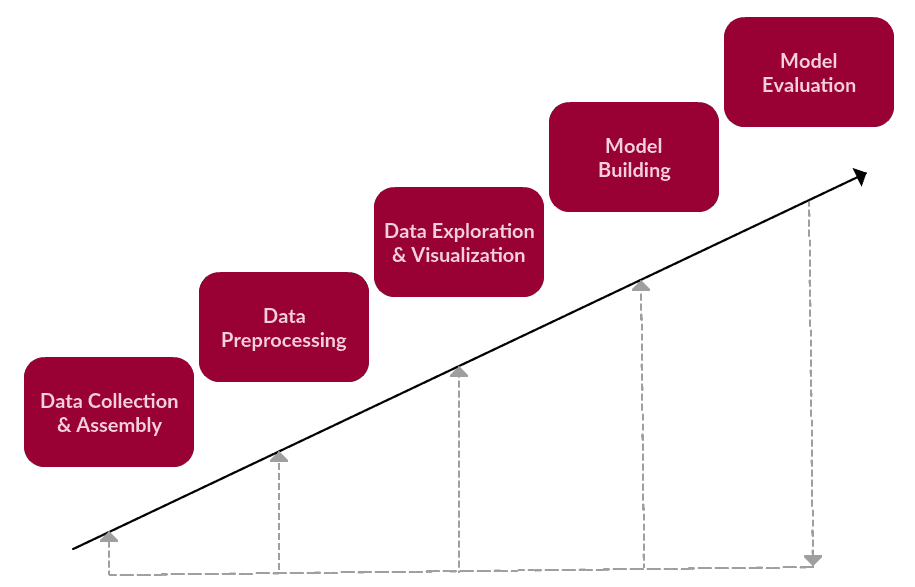
Een eenvoudig tekstueel gegevenstaakkader
Het is duidelijk dat elk raamwerk dat gericht is op de voorbewerking van tekstuele gegevens synoniem moet zijn met stap nummer 2. In het bijzonder op deze stap voortbouwend, hadden we het volgende te zeggen over wat deze stap waarschijnlijk zou inhouden:
- Voer de voorbereidingstaken uit op het onbewerkte tekstcorpus in afwachting van tekstmining of NLP-taak
- De voorverwerking van gegevens bestaat uit een aantal stappen, waarvan elk aantal al dan niet van toepassing is op een bepaalde taak, maar die over het algemeen onder de brede categorieën van tokenisatie, normalisatie en vervanging vallen.
- Meer in het algemeen zijn we geïnteresseerd in het nemen van een vooraf bepaalde hoeveelheid tekst en het uitvoeren van een aantal fundamentele analyses en transformaties, om te blijven zitten met artefacten die veel nuttiger zullen zijn voor het uitvoeren van een verdere, meer betekenisvolle analytische taak daarna. Deze verdere taak zou ons kernwerk zijn voor tekstmining of natuurlijke taalverwerking.
Dus, zoals hierboven vermeld, lijkt het alsof er 3 hoofdcomponenten zijn van tekstvoorverwerking:
- tokenization
- normalisatie
- substitutie
Als we een raamwerk schetsen voor het benaderen van voorverwerking, moeten we deze concepten op hoog niveau in gedachten houden.
We zullen dit raamwerk conceptueel introduceren, onafhankelijk van tools. We zullen dan de volgende keer een praktische implementatie van deze stappen volgen om te zien hoe ze zouden worden uitgevoerd in het Python-ecosysteem.
De volgorde van deze taken is niet noodzakelijkerwijs als volgt, en er kan ook enige herhaling op voorkomen.
1. Ruisverwijdering
Ruisverwijdering voert enkele van de vervangende taken van het raamwerk uit. Ruisverwijdering is een veel taakspecifieker onderdeel van het raamwerk dan de volgende stappen.
Houd er nogmaals rekening mee dat we niet te maken hebben met een lineair proces, waarvan de stappen uitsluitend in een bepaalde volgorde moeten worden uitgevoerd. Ruisverwijdering kan daarom plaatsvinden voor of na de eerder geschetste secties, of ergens tussenin).
Corpus (letterlijk Latijn voor lichaam) verwijst naar een verzameling teksten. Dergelijke verzamelingen kunnen bestaan uit een enkele teksttaal of kunnen meerdere talen omvatten; er zijn talloze redenen waarom meertalige corpora (het meervoud van corpus) nuttig kan zijn. Corpora kan ook bestaan uit thematische teksten (historisch, bijbels, etc.). Corpora worden over het algemeen alleen gebruikt voor statistische linguïstische analyse en het testen van hypothesen.
Wat dacht je van iets concreters. Laten we aannemen dat we een corpus van het world wide web hebben gehaald en dat het in een onbewerkt webformaat is ondergebracht. We kunnen dan aannemen dat er een grote kans is dat onze tekst in HTML- of XML-tags kan worden verpakt. Hoewel deze verwerking van metagegevens kan plaatsvinden als onderdeel van het tekstverzamelings- of assemblageproces (stap 1 van ons tekstuele gegevenstaakkader), hangt het af van hoe de gegevens zijn verkregen en samengesteld. Soms hebben we controle over dit gegevensverzamelings- en assemblageproces, en dus is ons corpus mogelijk al geruisloos gemaakt tijdens het verzamelen.
Maar dit is niet altijd het geval. Als het corpus dat je gebruikt luidruchtig is, moet je ermee omgaan. Bedenk dat over analytische taken vaak wordt gesproken als 80% datavoorbereiding!
Het goede ding is dat patroonherkenning hier je vriend kan zijn, net als bestaande softwaretools die zijn gebouwd om met zulke patroonherkenningstaken om te gaan.
- kopteksten, voetteksten van tekstbestanden verwijderen
- verwijder HTML, XML, etc. opmaak en metadata
- waardevolle gegevens extraheren uit andere formaten, zoals JSON, of uit databases
- als je bang bent voor reguliere expressies, kan dit het deel van de tekstvoorverwerking zijn waarin je ergste angsten worden gerealiseerd
Normale uitdrukkingen, vaak afgekort regexp or regexp, zijn een beproefde methode om tekstpatronen beknopt te beschrijven. Een reguliere expressie wordt zelf weergegeven als een speciale tekenreeks en is bedoeld voor het ontwikkelen van zoekpatronen op selecties van tekst. Reguliere expressies kunnen worden gezien als een uitgebreide set regels die verder gaan dan de jokertekens van ? en *. Hoewel vaak aangehaald als frustrerend om te leren, zijn reguliere expressies ongelooflijk krachtige hulpmiddelen voor het doorzoeken van tekst.
Zoals u zich kunt voorstellen, is de grens tussen het verwijderen van ruis en het verzamelen en samenstellen van gegevens vaag, en als zodanig moet enige ruisverwijdering absoluut plaatsvinden vóór andere voorbewerkingsstappen. Het is bijvoorbeeld duidelijk dat alle tekst die vereist is voor een JSON-structuur, vóór tokenisatie moet worden verwijderd.
2. Normalisatie
Voor verdere verwerking moet de tekst worden genormaliseerd.
Normalisatie verwijst over het algemeen naar een reeks gerelateerde taken die bedoeld zijn om alle tekst op een gelijk speelveld te plaatsen: alle tekst converteren naar hetzelfde hoofdlettergebruik (hoger of lager), leestekens verwijderen, samentrekkingen uitbreiden, getallen converteren naar hun woordequivalenten, enzovoort. Normalisatie plaatst alle woorden op gelijke voet en zorgt ervoor dat de verwerking uniform verloopt.
Het normaliseren van tekst kan het uitvoeren van een aantal taken betekenen, maar voor ons raamwerk zullen we normalisatie in 3 verschillende stappen benaderen: (1) stammen, (2) lemmatiseren en (3) al het andere.
running → run
Het stammen van het woord 'beter' zou bijvoorbeeld de citatievorm niet teruggeven (een ander woord voor lemma); lemmatisering zou echter resulteren in het volgende:
better → good
Het zou gemakkelijk moeten zijn in te zien waarom de implementatie van een stemmer de minder moeilijke prestatie van de twee zou zijn.
Al het andere
Een slimme vangst, toch? Stemming en lemmatisering zijn belangrijke onderdelen van het voorbewerken van tekst, en als zodanig moeten ze worden behandeld met het respect dat ze verdienen. Dit zijn geen simpele tekstmanipulaties; ze vertrouwen op een gedetailleerd en genuanceerd begrip van grammaticale regels en normen.
Er zijn echter tal van andere stappen die kunnen worden genomen om alle tekst op gelijke voet te brengen, waarvan vele de relatief eenvoudige ideeën van vervanging of verwijdering inhouden. Ze zijn echter niet minder belangrijk voor het totale proces. Waaronder:
- zet alle tekens op kleine letters
- verwijder nummers (of converteer nummers naar tekstuele representaties)
- verwijder interpunctie (meestal onderdeel van tokenisatie, maar toch de moeite waard om in dit stadium in gedachten te houden, zelfs als bevestiging)
- strip witruimte (ook over het algemeen onderdeel van tokenization)
- verwijder standaard stopwoorden (algemene Engelse stopwoorden)
The quick brown fox jumps over the lazy dog.
- verwijder opgegeven (taakspecifieke) stopwoorden
- verwijder schaarse termen (hoewel niet altijd nodig of nuttig!)
Op dit punt moet het duidelijk zijn dat de voorverwerking van tekst sterk afhankelijk is van vooraf gebouwde woordenboeken, databases en regels. U zult opgelucht zijn om te ontdekken dat wanneer we een praktische tekstvoorverwerkingstaak uitvoeren in het Python-ecosysteem in ons volgende artikel, deze vooraf gebouwde ondersteuningstools direct beschikbaar zijn voor ons gebruik; het is niet nodig om onze eigen wielen uit te vinden.
3. Tokenisatie
tokenization is over het algemeen een vroege stap in het NLP-proces, een stap die langere tekstreeksen in kleinere stukken of tokens splitst. Grotere stukken tekst kunnen worden omgezet in zinnen, zinnen kunnen worden omgezet in woorden, enz. Verdere verwerking wordt over het algemeen uitgevoerd nadat een stuk tekst op de juiste manier is getokeniseerd.
Tokenisatie wordt ook wel tekstsegmentatie of lexicale analyse genoemd. Soms segmentatie wordt gebruikt om te verwijzen naar het opsplitsen van een groot stuk tekst in stukken die groter zijn dan woorden (bijv. alinea's of zinnen), terwijl tokenisatie is gereserveerd voor het afbraakproces dat uitsluitend in woorden resulteert.
Dit klinkt misschien als een eenvoudig proces, maar dat is het allesbehalve. Hoe worden zinnen geïdentificeerd binnen grotere stukken tekst? Zo uit je hoofd zeg je waarschijnlijk 'interpunctie-einde van de zin', en misschien denk je zelfs even dat zo'n uitspraak ondubbelzinnig is.
Natuurlijk, deze zin is gemakkelijk te herkennen aan enkele basissegmentatieregels:
The quick brown fox jumps over the lazy dog.
Maar hoe zit het met deze:
Dr. Ford did not ask Col. Mustard the name of Mr. Smith's dog.
Of deze:
"What is all the fuss about?" asked Mr. Peters.
En dat zijn maar zinnen. Hoe zit het met woorden? Makkelijk, toch? Rechts?
This full-time student isn't living in on-campus housing, and she's not wanting to visit Hawai'i.
Het moet intuïtief zijn dat er verschillende strategieën zijn, niet alleen voor het identificeren van segmentgrenzen, maar ook voor wat te doen wanneer grenzen worden bereikt. We kunnen bijvoorbeeld een segmentatiestrategie gebruiken die (correct) een bepaalde grens tussen woordtekens identificeert als de apostrof in het woord ze is (een strategie tokenizing op witruimte alleen zou niet voldoende zijn om dit te herkennen). Maar we zouden dan kunnen kiezen tussen concurrerende strategieën, zoals het behouden van de interpunctie met een deel van het woord, of het helemaal weggooien. Een van deze benaderingen lijkt gewoon correct en lijkt geen echt probleem te vormen. Maar denk eens aan alle andere speciale gevallen in alleen de Engelse taal waarmee we rekening zouden moeten houden.
Overweging: als we tekstbrokken in zinnen segmenteren, moeten we dan scheidingstekens aan het einde van de zin behouden? Zijn we geïnteresseerd in het onthouden waar zinnen eindigden?
We hebben enkele tekst(voor)verwerkingsstappen behandeld die nuttig zijn voor NLP-taken, maar hoe zit het met de taken zelf?
Er zijn geen harde lijnen tussen deze taaktypen; veel zijn echter redelijk goed gedefinieerd op dit punt. Een bepaalde macro NLP-taak kan een verscheidenheid aan subtaken bevatten.
We hebben eerst de belangrijkste benaderingen geschetst, aangezien de technologieën vaak gericht zijn op beginners, maar het is goed om een concreet idee te hebben van welke soorten NLP-taken er zijn. Hieronder staan de hoofdcategorieën van NLP-taken.
1. Tekstclassificatietaken
- Vertegenwoordiging: zak met woorden, n-grammen, one-hot codering (sparse matrix) - deze methoden behouden de woordvolgorde niet
- Doel: tags, categorieën, sentiment voorspellen
- Toepassing: spam-e-mails filteren, documenten classificeren op basis van dominante inhoud
Werkelijke opslagmechanismen voor de representatie van de woordenzak kunnen variëren, maar het volgende is een eenvoudig voorbeeld waarbij een woordenboek wordt gebruikt voor intuïtiviteit. Voorbeeldtekst:
"Well, well, well," said John.
'Daar, daar,' zei James. "Daar daar."
De resulterende zak met woorden als een woordenboek:
{
'well': 3,
'said': 2,
'john': 1,
'there': 4,
'james': 1
}Een voorbeeld van een trigram-model (3 gram) van de tweede zin van het bovenstaande voorbeeld ("Daar, daar", zei James. "Daar, daar.") verschijnt als een lijstweergave hieronder:
[
"there there said",
"there said james",
"said james there",
"james there there",
]
Voorafgaand aan het wijdverbreide gebruik van neurale netwerken in NLP - in wat we "traditionele" NLP zullen noemen - vond vectorisering van tekst vaak plaats via one-hot codering (merk op dat dit nog steeds een nuttige coderingsoefening is voor een aantal oefeningen en niet uit de mode is geraakt door het gebruik van neurale netwerken). Voor one-hot-codering komt elk woord of teken in een tekst overeen met een vectorelement.
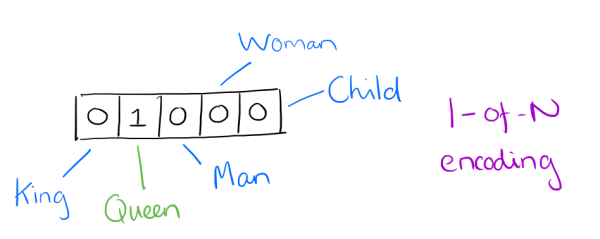
We zouden de afbeelding hierboven bijvoorbeeld kunnen beschouwen als een klein fragment van een vector die de zin 'De koningin kwam de kamer binnen' vertegenwoordigt. Merk op dat alleen het element voor "koningin" is geactiveerd, terwijl die voor "koning", "man", enz. niet zijn geactiveerd. Je kunt je voorstellen hoe anders de een-het-het-vectorrepresentatie van de zin "De koning was ooit een man, maar is nu een kind" zou verschijnen in hetzelfde vectorelementgedeelte als hierboven afgebeeld.
2. Woordreekstaken
- Weergave: sequenties (behoudt woordvolgorde)
- Doel: taalmodellering – voorspel volgende/vorige woord(en), tekstgeneratie
- Toepassing: vertaling, chatbots, sequentietagging (voorspel POS-tags voor elk woord in volgorde), entiteitsherkenning genoemd
Taalmodellering is het proces van het bouwen van een statistisch taalmodel dat bedoeld is om een schatting te geven van een natuurlijke taal. Voor een reeks invoerwoorden zou het model een waarschijnlijkheid toewijzen aan de gehele reeks, wat bijdraagt aan de geschatte waarschijnlijkheid van verschillende mogelijke reeksen. Dit kan vooral handig zijn voor NLP-toepassingen die tekst genereren of voorspellen.
3. Tekst Betekenis Taken
- Representatie: woordvectoren, de toewijzing van woorden aan vectoren (n-dimensionale numerieke vectoren) oftewel inbeddingen
- Doel: hoe representeren we betekenis?
- Toepassing: zoeken naar vergelijkbare woorden (vergelijkbare vectoren), zinsinsluitingen (in tegenstelling tot woordinbeddingen), onderwerpmodellering, zoeken, vragen beantwoorden
Dichte inbeddingsvectoren aka woordinbeddingen resulteren in de weergave van kernfuncties die zijn ingebed in een inbeddingsruimte van formaat d dimensies. We kunnen, als u wilt, het aantal dimensies dat wordt gebruikt om 20,000 unieke woorden weer te geven, comprimeren tot misschien 50 of 100 dimensies. In deze benadering heeft elk object niet langer zijn eigen dimensie, maar wordt het in plaats daarvan toegewezen aan een vector.
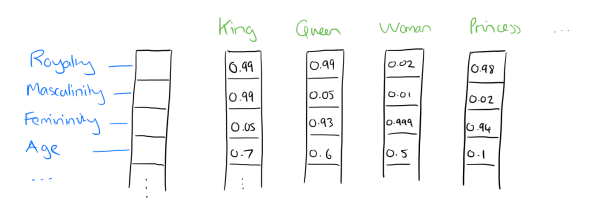
Dus, wat zijn deze functies precies? We laten het aan een neuraal netwerk over om de belangrijke aspecten van relaties tussen woorden te bepalen. Hoewel menselijke interpretatie van deze kenmerken niet precies mogelijk zou zijn, geeft bovenstaande afbeelding inzicht in hoe het onderliggende proces eruit kan zien, met betrekking tot de beroemde King - Man + Woman = Queen voorbeeld.

Gedeeltelijk taggen bestaat uit het toewijzen van een categorietag aan de tokenized delen van een zin. De meest populaire POS-tagging is het identificeren van woorden als zelfstandige naamwoorden, werkwoorden, bijvoeglijke naamwoorden, enz.
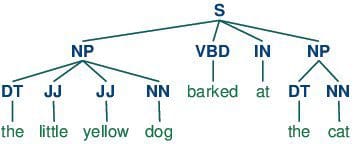
Gedeeltelijk taggen
4. Taken van volgorde naar volgorde
- Veel taken in NLP kunnen als zodanig worden geframed
- Voorbeelden zijn machinevertaling, samenvatting, vereenvoudiging, Q&A-systemen
- Dergelijke systemen worden gekenmerkt door encoders en decoders, die complementair werken om een verborgen weergave van tekst te vinden en die verborgen weergave te gebruiken
5. Dialoogsystemen
- 2 hoofdcategorieën van dialoogsystemen, gecategoriseerd op basis van hun toepassingsgebied
- Doelgerichte dialoogsystemen zijn erop gericht bruikbaar te zijn in een bepaald, beperkt domein; meer precisie, minder generaliseerbaar
- Conversationele dialoogsystemen houden zich bezig met behulpzaam of onderhoudend zijn in een veel algemenere context; minder precisie, meer generalisatie
Of het nu gaat om dialoogsystemen of het praktische verschil tussen op regels gebaseerde en meer complexe benaderingen voor het oplossen van NLP-taken, let op de wisselwerking tussen precisie en generaliseerbaarheid; je offert over het algemeen op het ene gebied voor een toename in het andere.
Hoewel het niet eenvoudig is, zijn er 3 hoofdgroepen van benaderingen voor het oplossen van NLP-taken.
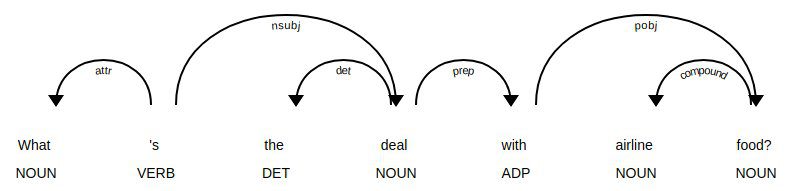
Afhankelijkheid ontleden boom met spaCy
1. Op regels gebaseerd
Op regels gebaseerde benaderingen zijn de oudste benaderingen van NLP. Waarom worden ze nog steeds gebruikt, vraag je je misschien af? Het is omdat ze zijn beproefd en waar, en het is bewezen dat ze goed werken. Regels die op tekst worden toegepast, kunnen veel inzicht bieden: bedenk wat je over willekeurige tekst kunt leren door te zoeken welke woorden zelfstandige naamwoorden zijn, of welke werkwoorden eindigen op -ing, of dat een patroon herkenbaar is als Python-code. Normale uitdrukkingen en contextvrije grammatica's zijn schoolvoorbeelden van op regels gebaseerde benaderingen van NLP.
Op regels gebaseerde benaderingen:
- hebben de neiging om zich te concentreren op het matchen of ontleden van patronen
- kan vaak worden gezien als methoden om de lege plekken in te vullen
- zijn lage precisie, hoge recall, wat betekent dat ze hoge prestaties kunnen leveren in specifieke gebruikssituaties, maar vaak te lijden hebben van prestatievermindering wanneer ze worden gegeneraliseerd
2. "Traditionele" machine learning
"Traditionele" machine learning-benaderingen omvatten probabilistische modellering, waarschijnlijkheidsmaximalisatie en lineaire classificaties. Dit zijn met name geen neurale netwerkmodellen (zie hieronder).
Traditionele machine learning-benaderingen worden gekenmerkt door:
- trainingsgegevens – in dit geval een corpus met opmaak
- feature engineering - woordtype, omringende woorden, hoofdletters, meervoud, enz.
- een model trainen op parameters, gevolgd door passen op testgegevens (typisch voor machine learning-systemen in het algemeen)
- gevolgtrekking (model toepassen op testgegevens) gekenmerkt door het vinden van de meest waarschijnlijke woorden, het volgende woord, de beste categorie, enz.
- “semantische slotvulling”
3. Neurale netwerken
Dit is vergelijkbaar met "traditionele" machine learning, maar met een paar verschillen:
- feature engineering wordt over het algemeen overgeslagen, omdat netwerken belangrijke functies zullen "leren" (dit is over het algemeen een van de beweerde grote voordelen van het gebruik van neurale netwerken voor NLP)
- in plaats daarvan worden stromen van onbewerkte parameters ("woorden" - eigenlijk vectorrepresentaties van woorden) zonder technische functies ingevoerd in neurale netwerken
- zeer groot opleidingscorpus
Specifieke neurale netwerken die in NLP worden gebruikt, omvatten "historisch" terugkerende neurale netwerken (RNN's) en convolutionele neurale netwerken (CNN's). Tegenwoordig is de enige architectuur die ze allemaal regeert de transformator.
Waarom "traditionele" machine learning (of op regels gebaseerde) benaderingen gebruiken voor NLP?
- nog steeds goed voor sequentielabeling (met behulp van probabilistische modellering)
- sommige ideeën in neurale netwerken lijken erg op eerdere methoden (word2vec is qua concept vergelijkbaar met semantische distributiemethoden)
- gebruik methoden van traditionele benaderingen om neurale netwerkbenaderingen te verbeteren (bijvoorbeeld woorduitlijningen en aandachtsmechanismen zijn vergelijkbaar)
Waarom deep learning in plaats van 'traditionele' machine learning?
- SOTA in veel toepassingen (bijvoorbeeld machinevertaling)
- veel onderzoek (meerderheid?) in NLP gebeurt hier nu
Belangrijk, zowel neurale netwerkbenaderingen als niet-neurale netwerkbenaderingen kunnen op zichzelf nuttig zijn voor hedendaagse NLP; ze kunnen ook samen worden gebruikt of bestudeerd voor een maximaal potentieel voordeel
Referenties
- Van talen tot informatie, Stanford
- Natural Language Processing, Nationale Onderzoeksuniversiteit Hogere School voor Economie (Coursera)
- Neurale netwerkmethoden voor natuurlijke taalverwerkingYoav Goldberg
- Natural Language Processing, Yandex-gegevensschool
Matthijs Mayo (@mattmayo13) is een datawetenschapper en de hoofdredacteur van KDnuggets, het baanbrekende online hulpmiddel voor gegevenswetenschap en machine learning. Zijn interesses liggen in natuurlijke taalverwerking, ontwerp en optimalisatie van algoritmen, leren zonder toezicht, neurale netwerken en geautomatiseerde benaderingen van machine learning. Matthew heeft een master in computerwetenschappen en een graduaat in datamining. Hij is te bereiken via editor1 op kdnuggets[dot]com.

