Introductie
Met de komst van grote taalmodellen (LLM's), zijn ze in talloze toepassingen doorgedrongen en hebben ze kleinere transformatormodellen zoals BERT of op regels gebaseerde modellen in veel gevallen Natuurlijke taalverwerking (NLP) taken. LLM's zijn veelzijdig en kunnen taken uitvoeren zoals tekstclassificatie, samenvatting, sentimentanalyse en onderwerpmodellering, dankzij hun uitgebreide vooropleiding. Ondanks hun brede mogelijkheden blijven LLM's echter vaak achter in nauwkeurigheid vergeleken met hun kleinere tegenhangers.
Om deze beperking aan te pakken, is een effectieve strategie het afstemmen van vooraf opgeleide LLM's om uit te blinken in specifieke taken. Het finetunen van grote modellen levert vaak optimale resultaten op. Opvallend is dat Google's Gemini, naast andere grote modellen, gebruikers nu de mogelijkheid biedt om deze modellen te verfijnen met hun eigen trainingsgegevens. In deze handleiding doorlopen we het proces van het verfijnen van Gemini-modellen voor specifieke problemen, en hoe we een dataset kunnen samenstellen met behulp van bronnen van HuggingFace.
leerdoelen
- Begrijp de prestaties van de Gemini-modellen van Google.
- Leer datasetvoorbereiding voor het afstemmen van Gemini-modellen.
- Configureer parameters voor fijnafstemming van het Gemini-model.
- Bewaak de voortgang en statistieken van het afstemmen.
- Test de prestaties van het Gemini-model op nieuwe gegevens.
- Ontdek Gemini-modeltoepassingen voor PII-maskering.

Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Google kondigt Tuning Gemini aan
Gemini komt in twee versies: Pro en Ultra. In de Pro-versie zijn er Gemini 1.0 Pro en de nieuwe Gemini 1.5 Pro. Deze modellen van Google concurreren met andere geavanceerde modellen zoals ChatGPT en Claude. Gemini-modellen zijn voor iedereen gemakkelijk toegankelijk via de AI Studio UI en een gratis API.
Onlangs heeft Google een nieuwe feature voor Gemini-modellen aangekondigd: finetuning. Dit betekent dat iedereen het Gemini-model kan aanpassen aan zijn of haar behoeften. U kunt Gemini verfijnen met behulp van de AI Studio UI of hun API. Bij fijnafstemming geven we onze eigen gegevens aan Gemini, zodat deze zich kan gedragen zoals wij willen. Google gebruikt Parameter Efficient Tuning (PET) om snel een paar belangrijke onderdelen van het Gemini-model aan te passen, waardoor het bruikbaar wordt voor verschillende taken.
De gegevensset voorbereiden
Voordat we beginnen met het verfijnen van het model, beginnen we met het installeren van de benodigde bibliotheken. Voor deze handleiding werken we trouwens samen met Colab.
Noodzakelijke bibliotheken installeren
Hieronder volgen de Python-modules die nodig zijn om aan de slag te gaan:
!pip install -q google-generativeai datasets- google-generatiefai: Het is een bibliotheek van het Google-team waarmee we toegang hebben tot het Google Gemini-model. Met dezelfde bibliotheek kan worden gewerkt om het Gemini-model te verfijnen.
- gegevenssets: Dit is een bibliotheek van HuggingFace waarmee we kunnen werken om verschillende datasets van de HuggingFace-hub te downloaden. We zullen met deze datasetbibliotheek werken om de PII-dataset (Personal Identifiable Information) te downloaden en deze aan het Gemini-model te geven voor verfijning.
Als u de volgende code uitvoert, worden de Google Generatieve AI en de Datasets-bibliotheek in onze Python-omgeving gedownload en geïnstalleerd.
OAuth instellen
In de volgende stap moeten we een OAuth instellen voor deze zelfstudie. De OAuth is nodig zodat de gegevens die we naar Google sturen voor Fine-Tuning Gemini veilig zijn. Volg dit om de OAuth te verkrijgen link. Download vervolgens client_secret.json nadat u de OAuth hebt gemaakt. Sla de inhoud van client_secrent.json op in Colab Secrets onder de naam CLIENT_SECRET en voer de onderstaande code uit:
import os
if 'COLAB_RELEASE_TAG' in os.environ:
from google.colab import userdata
import pathlib
pathlib.Path('client_secret.json').write_text(userdata.get('CLIENT_SECRET'))
# Use `--no-browser` in colab
!gcloud auth application-default login --no-browser
--client-id-file client_secret.json --scopes=
'https://www.googleapis.com/auth/cloud-platform,
https://www.googleapis.com/auth/generative-language.tuning'
else:
!gcloud auth application-default login --client-id-file
client_secret.json --scopes=
'https://www.googleapis.com/auth/cloud-platform,
https://www.googleapis.com/auth/generative-language.tuning'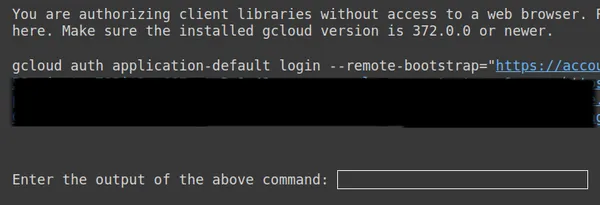
Kopieer hierboven de tweede link en plak deze in uw lokale CMD-systeem en voer deze uit.
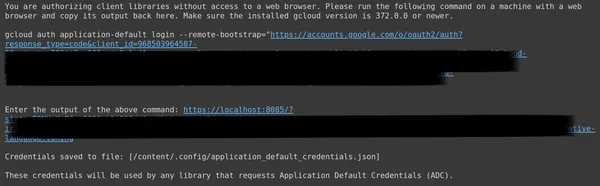
Vervolgens wordt u doorgestuurd naar de webbrowser om in te loggen met het e-mailadres waarmee u OAuth hebt ingesteld. Na het inloggen krijgen we in de CMD een URL, plak die URL nu in de 3e regel en druk op enter. Nu zijn we klaar met het uitvoeren van de OAuth met Google.
De gegevensset downloaden en voorbereiden
Allereerst downloaden we de dataset waarmee we gaan werken om deze af te stemmen op het Gemini-model. Hiervoor werken we met de datasetsbibliotheek. De code hiervoor zal zijn:
from datasets import load_dataset
dataset = load_dataset("ai4privacy/pii-masking-200k")
print(dataset)- Hier beginnen we met het importeren van de load_dataset-functie uit de datasetsbibliotheek.
- Aan deze functie load_dataset() geven we de dataset door die we willen downloaden. Hier in ons voorbeeld is dit “ai4privacy/pii-masking-200k”, dat 200 rijen gemaskeerde en ongemaskeerde PII-gegevens bevat.
- Vervolgens printen we de dataset.

We zien dat de dataset 209261 rijen met trainingsgegevens bevat en geen testgegevens. En elke rij bevat verschillende kolommen, zoals masked_text, unmasked_text, privacy_mask, span_labels, bio_labels en tokenised_text. De voorbeeldgegevens worden hieronder vermeld:
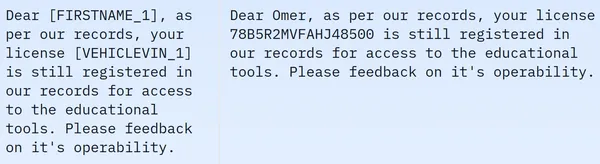
In het weergegeven beeld zien we zowel gemaskerde als ongemaskerde zinnen. Concreet worden in de gemaskeerde zin bepaalde elementen, zoals de naam van de persoon en het voertuignummer, verborgen door specifieke tags. Om de gegevens voor te bereiden voor verdere verwerking, moeten we nu een aantal gegevensvoorbewerkingen uitvoeren. Hieronder vindt u de code voor deze voorverwerkingsstap:
df = dataset['train'].to_pandas()
df = df[['unmasked_text','masked_text']][:2000]
df.columns = ['input','output']
- Ten eerste halen we het trainingsgedeelte van de gegevens uit de dataset (de dataset die we hebben gedownload bevat alleen het trainingsgedeelte). Vervolgens zetten wij dit om naar Pandas Dataframe.
- Om Gemini te verfijnen, hebben we hier alleen de kolommen unmasked_text en masked_text nodig, dus nemen we alleen deze twee.
- Vervolgens krijgen we de eerste 2000 rijen met gegevens. We gaan met de eerste 2000 rijen aan de slag om Gemini te verfijnen.
- Vervolgens bewerken we de kolomnamen van unmasked_text en masked_text naar invoer- en uitvoerkolommen, omdat we, wanneer we de invoertekstgegevens met de PII (persoonlijk identificeerbare informatie) aan het Gemini-model doorgeven, verwachten dat dit de uitvoertekstgegevens zal genereren waar de PII is gemaskeerd.
Gegevens opmaken voor het verfijnen van Gemini
De volgende stap is het formatteren van onze gegevens. Om dit te doen, zullen we een formatterfunctie maken:
def formatter(x):
text = f"""
Given the information below, mask the personal identifiable information.
Input:
{x['input']}
Output:
"""
return text
df['text_input'] = df.apply(formatter,axis=1)
print(df['text_input'][0])- Hier definiëren we een functieformatter, die x inneemt, een rij van onze gegevens.
- Vervolgens definieert het een variabele tekst met f-strings, waarbij we de context opgeven, gevolgd door de invoergegevens uit het dataframe.
- Ten slotte retourneren we de opgemaakte tekst.
- De laatste regel past de formatter-functie toe op elke rij van het dataframe die we hebben gemaakt via de functie apply().
- De as=1 geeft aan dat de functie op elke rij van het dataframe wordt toegepast.
Het uitvoeren van de code zal resulteren in het maken van een nieuwe kolom met de naam “trein” die de opgemaakte tekst voor elke rij bevat, inclusief het invoerveld. Laten we proberen een van de elementen van het dataframe te observeren:
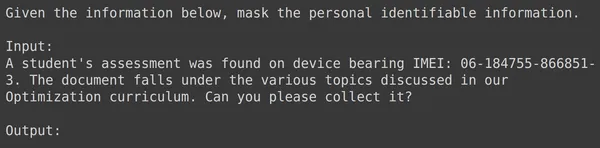
Gegevens opdelen in trein- en testsets
We kunnen zien dat de text_input de gegevens bevat waarbij elke rij de context bevat aan het begin van de gegevens die aangeeft dat de PII moet worden gemaskeerd en vervolgens wordt gevolgd door de invoergegevens en gevolgd door het woord uitvoer, waar het model de uitvoer moet genereren. Nu moeten we het dataframe verdelen in trainen en testen:
df = df[['text_input','output']]
df_train = df.iloc[:1900,:]
df_test = df.iloc[1900:,:]- We beginnen met het filteren van de gegevens zodat deze de kolommen text_input en output bevatten. Dit zijn de kolommen die de Google Fine-Tune-bibliotheek verwacht om de Gemini te trainen
- De Gemini krijgt de tekstinvoer en leert de uitvoer te schrijven
- We verdelen de gegevens in df_train, die de 1900 rijen van onze oorspronkelijke gegevens bevat
- En een df_test die ongeveer 100 rijen met de originele gegevens bevat
- We trainen de Gemini op df_train en testen hem vervolgens door 3-4 voorbeelden uit de df_test te nemen om de output te zien die erdoor wordt gegenereerd
Het uitvoeren van de code filtert dus onze gegevens en verdeelt deze in trainen en testen. Ten slotte zijn we klaar met het voorverwerkingsgedeelte van de gegevens.
Verfijning van het Gemini-model
Volg de onderstaande stappen om uw Gemini-model te verfijnen:
Tuningparameters instellen
In deze sectie zullen we het proces van het afstemmen van het Gemini-model doorlopen. Hiervoor gaan we werken met de volgende code:
import google.generativeai as genai
bm_name = "models/gemini-1.0-pro-001"
name = 'pii-model'
operation = genai.create_tuned_model(
source_model=bm_name,
training_data=df_train,
id = name,
epoch_count = 2,
batch_size=4,
learning_rate=0.001,
)
- Importeer de google.generativeai-bibliotheek: deze bibliotheek biedt API's voor interactie met de generatieve AI-services van Google.
- Geef de naam van het basismodel op: Dit is de naam van het vooraf getrainde model waarmee we willen werken als uitgangspunt voor ons verfijnde model. Op dit moment is het enige afstembare model models/gemini-1.0-pro-001, we slaan dit op in de variabele bm_name.
- Geef de naam op van het verfijnde model: Dit is de naam die we aan ons verfijnde model willen geven. Hier geven we het de naam “pii-model”.
- Maak een Tuned Model Operation-object: dit object vertegenwoordigt de bewerking van het maken van een verfijnd model. Er zijn de volgende argumenten nodig:
- source_model: De naam van het basismodel
- training_data: De trainingsgegevens voor het verfijnde model dat we zojuist hebben gemaakt, namelijk df_train
- id: De ID/naam van het verfijnde model
- epoch_count: het aantal trainingsepochs. Voor dit voorbeeld gaan we uit van twee tijdperken
- batch_size: de batchgrootte voor training. Voor dit voorbeeld gaan we uit van de waarde 4
- learning_rate: het leerpercentage voor training. Hier geven we de waarde 0.001
- We zijn klaar met het verstrekken van de parameters. Door deze code uit te voeren, wordt een verfijnd modelobject gemaakt. Nu moeten we beginnen met het trainen van de Gemini LLM. Hiervoor werken we met de volgende code.
We zijn klaar met het instellen van de parameters. Als u deze code uitvoert, wordt een afgestemd modelobject gemaakt. Nu moeten we beginnen met het trainen van de Gemini LLM. Hiervoor werken we met de volgende code:
model = genai.get_tuned_model(f'tunedModels/{name}')
print(model)Een afgestemd model creëren
Hier gebruiken we de functie .get_tuned_model() uit de genai-bibliotheek, waarbij we de naam van ons gedefinieerde model doorgeven en het trainingsproces starten. Vervolgens printen we het model, zoals weergegeven in de onderstaande afbeelding:
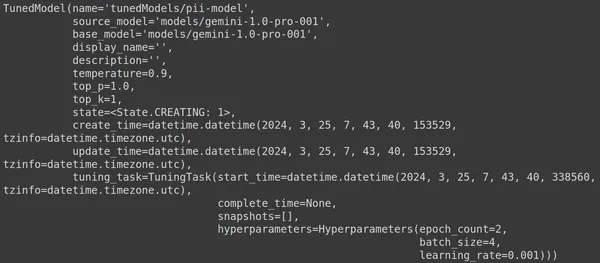
Het model is van het type TunedModel. Hier kunnen we verschillende parameters waarnemen voor het model dat we hebben gedefinieerd. Zij zijn:
- naam: Deze variabele bevat de naam die we hebben opgegeven voor ons afgestemde model
- source_model: Dit is het bronmodel dat we aan het verfijnen zijn, in ons voorbeeld models/gemini-1.0-pro
- base_model: Dit is opnieuw het basismodel dat we aan het verfijnen zijn, in ons voorbeeld modellen/Gemini-1.0-pro. Het basismodel kan zelfs een eerder verfijnd model zijn. Hier zijn we hetzelfde voor beide
- display_name: de weergavenaam voor het afgestemde model
- beschrijving: Het bevat een beschrijving van ons model en waar het model over gaat
- temperatuur: Hoe hoger de waarde, hoe creatiever de antwoorden worden gegenereerd op basis van het Grote Taalmodel. Hier is deze standaard ingesteld op 0.9
- top_p: Definieert de hoogste waarschijnlijkheid voor de tokenselectie tijdens het genereren van tekst. Hoe vaker er top_p meer tokens worden geselecteerd, dwz tokens worden geselecteerd uit een grotere steekproef van gegevens
- top_k: Het vertelt dat u bij elke stap uit de k meest waarschijnlijke volgende tokens moet samplen. Hier is top_k 1, wat impliceert dat het meest waarschijnlijke volgende token het token is dat zal worden geselecteerd, dat wil zeggen dat het token met de hoogste waarschijnlijkheid altijd zal worden geselecteerd.
- staat: De staat creëert, dit houdt in dat het model momenteel wordt verfijnd
- create_time: Het tijdstip waarop het model is gemaakt
- update_time: Dit is het tijdstip waarop het model voor het laatst is afgestemd
- tuning_task: Bevat de parameters die we hebben gedefinieerd voor afstemming, waaronder temperatuur, tijdperken en batchgrootte
Initiëren van een trainingsproces
We kunnen zelfs de status en de metadata van het afgestemde model verkrijgen via de volgende code:
print(operation.metadata)
Hier worden de totale stappen weergegeven, dat wil zeggen 950, wat voorspelbaar is. Omdat we in ons voorbeeld 1900 rijen met trainingsgegevens hebben. Bij elke stap nemen we een batch van 4, dat wil zeggen 4 rijen, dus voor een volledig tijdperk hebben we 1900/4, dat wil zeggen 475 stappen. We hebben 2 tijdperken voor training ingesteld, wat inhoudt dat 2*475 = 950 stappen.
Bewaken van de voortgang van de training
Met de onderstaande code wordt een statusbalk gemaakt die aangeeft hoeveel procent van de training is voltooid en hoeveel tijd het duurt om het hele trainingsproces te voltooien:
import time
for status in operation.wait_bar():
time.sleep(30)
De bovenstaande code creëert een voortgangsbalk. Wanneer voltooid, betekent dit dat ons afstemmingsproces is beëindigd.
Trainingsprestaties visualiseren
Het operatieobject bevat zelfs de momentopnamen van de training. Dat het de evaluatiestatistieken zal bevatten, zoals het gemiddelde verlies per tijdperk. We kunnen dit visualiseren met de volgende code:
import pandas as pd
import seaborn as sns
model = operation.result()
snapshots = pd.DataFrame(model.tuning_task.snapshots)
sns.lineplot(data=snapshots, x = 'epoch', y='mean_loss')- Hier krijgen we het uiteindelijk afgestemde model van operatie.result()
- Wanneer we het model trainen, maakt het model met regelmatige tussenpozen momentopnamen. Deze momentopnamen bevatten gegevens zoals het gemiddelde verlies. Daarom extraheren we de snapshots van het afgestemde model door model.tuning_task.snapshots aan te roepen
- We maken een dataframe van deze snapshots door de snapshots door te geven aan het pd.DataFrame en ze op te slaan in de snapshots-variabele
- Ten slotte maken we een lijndiagram van de geëxtraheerde momentopnamegegevens
Het uitvoeren van de code resulteert in de volgende grafiek:
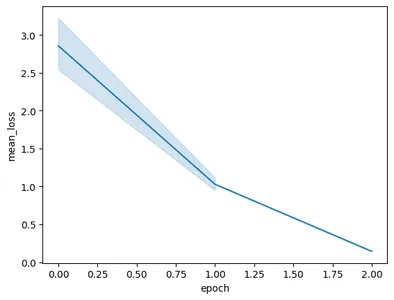
In deze afbeelding kunnen we zien dat we het verlies in slechts twee trainingsperioden hebben teruggebracht van 3 naar minder dan 0.5. Eindelijk zijn we klaar met het trainen van het Gemini-model
Het verfijnde Gemini-model testen
In deze sectie zullen we ons model testen op de testgegevens. Om nu met het afgestemde model te werken, werken we met de volgende code:
model = genai.GenerativeModel(model_name=f'tunedModels/{name}')De bovenstaande code laadt het afgestemde model dat we zojuist hebben getraind met de persoonlijk identificeerbare informatiegegevens. Nu gaan we dit model testen met enkele voorbeelden uit de testgegevens die we terzijde hebben gelegd. Laten we hiervoor de willekeurige text_input en de bijbehorende uitvoer uit de testset afdrukken:
print(df_test['text_input'][1900])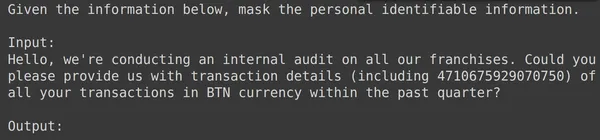
df_test['output'][1900]
Hierboven zien we een willekeurige tekst_invoer en de uitvoer uit de testset. Nu zullen we deze text_input doorgeven aan het model en de gegenereerde output observeren:
text = df_test['text_input'][1900]
res = model.generate_content(text)
print(res.text)
We zien dat het model succesvol was in het maskeren van de persoonlijk identificeerbare informatie voor de gegeven tekstinvoer en dat de door het model gegenereerde uitvoer exact overeenkomt met de uitvoer van de testset. Laten we dit nu eens proberen met nog een paar voorbeelden:
print(df_test['text_input'][1969])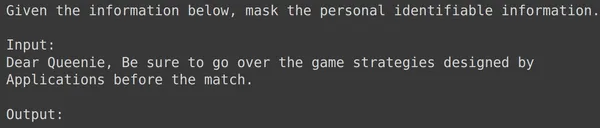
print(df_test['output'][1969])
text = df_test['text_input'][1969]
res = model.generate_content(text)
print(res.text)
print(df_test['text_input'][1987])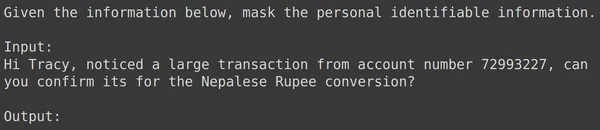
print(df_test['output'][1987])
text = df_test['text_input'][1987]
res = model.generate_content(text)
print(res.text)
print(df_test['text_input'][1933])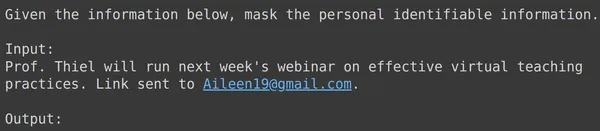
print(df_test['output'][1933])
text = df_test['text_input'][1933]
res = model.generate_content(text)
print(res.text)
Voor alle bovenstaande voorbeelden zien we dat onze verfijnde modelprestaties goed zijn. Het model kon leren van de gegeven trainingsgegevens en de maskering correct toepassen om gevoelige persoonlijke informatie te verbergen. We hebben dus van begin tot eind gezien hoe we een dataset kunnen creëren voor verfijning en hoe we het Gemini-model op een dataset kunnen verfijnen, en de resultaten die we zien zien er veelbelovend uit voor een verfijnd model.
Conclusie
Concluderend: deze gids biedt een uitgebreide uitleg over het verfijnen van de vlaggenschip Gemini-modellen van Google voor het maskeren van persoonlijk identificeerbare informatie (PII). We zijn begonnen met het verkennen van de blogpost van Google over de verfijningsmogelijkheden voor Gemini-modellen, waarbij we de noodzaak benadrukten om deze modellen te verfijnen om taakspecifieke nauwkeurigheid te bereiken. Via praktische stappen die in de handleiding worden beschreven, waaronder het voorbereiden van datasets, het verfijnen van het Gemini-model en het testen van de prestaties ervan, kunnen gebruikers de kracht van grote taalmodellen benutten voor PII-maskeringstaken.
Dit zijn de belangrijkste punten uit deze gids:
- Gemini-modellen bieden een krachtige bibliotheek voor fijnafstemming, waardoor gebruikers ze kunnen afstemmen op specifieke taken, waaronder PII-maskering, via Parameter-Efficient Tuning (PET)
- Het voorbereiden van datasets is een cruciale stap, die de installatie van de benodigde modules omvat, het initiëren van de OAuth voor gegevensbeveiliging en het formatteren van de gegevens voor training
- Het verfijningsproces omvat het verstrekken van parameters zoals het basismodel, het aantal tijdperken, de batchgrootte en de leersnelheid om het Gemini-model te trainen op de voorbereide gegevensset
- Het monitoren van de voortgang van de training wordt vergemakkelijkt door statusupdates en visualisaties van statistieken zoals gemiddeld verlies per tijdperk
- Door het verfijnde model op een afzonderlijke testdataset te testen, worden de prestaties bij het nauwkeurig maskeren van PII geverifieerd, terwijl de integriteit van de gegevens behouden blijft
- De gegeven voorbeelden demonstreren de effectiviteit van het verfijnde Gemini-model bij het succesvol maskeren van gevoelige persoonlijke informatie, wat veelbelovende resultaten aangeeft voor toepassingen in de echte wereld
Veelgestelde Vragen / FAQ
A. Parameter Efficient Tuning (PET) is een van de technieken voor fijnafstemming die slechts een kleine set parameters van het model fijnafstemt. Dit wordt door Google gebruikt om belangrijke lagen in het Gemini-model snel te verfijnen. Het past het model efficiënt aan de gegevens van de gebruiker aan, waardoor de prestaties voor specifieke taken worden verbeterd
A. Het afstemmen van een Gemini-model omvat het verstrekken van parameters zoals de naam van het basismodel, het aantal tijdperken, de batchgrootte en het leerpercentage. Deze parameters beïnvloeden het trainingsproces en beïnvloeden uiteindelijk de prestaties van het model
A. Gebruikers kunnen de trainingsvoortgang van een verfijnd Gemini-model volgen via statusupdates, visualisaties van statistieken zoals gemiddeld verlies per tijdperk, en door momentopnamen van het trainingsproces te observeren
A. Voordat gebruikers een Gemini-model kunnen verfijnen, moeten ze de benodigde bibliotheken zoals google-generativeai en datasets installeren. Daarnaast zijn het initiëren van OAuth voor gegevensbeveiliging en het formatteren van de dataset voor training belangrijke stappen
A. Een verfijnd Gemini-model kan worden toegepast in verschillende domeinen waar PII-maskering noodzakelijk is, zoals het anonimiseren van gegevens, het behoud van privacy in NLP-toepassingen en het naleven van regelgeving op het gebied van gegevensbescherming, zoals de AVG
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2024/03/guide-to-fine-tuning-gemini-for-masking-pii-data/

