Introductie
Op het gebied van academisch onderzoek kan de reis van ruwe gegevens naar inzichtelijke conclusies lastig zijn als je een beginner of beginneling bent. Met de juiste aanpak en hulpmiddelen is het transformeren van gegevens in betekenisvolle kennis echter een enorm lonende ervaring. In deze gids leiden we u door een typische workflow voor academische data-analyse, aan de hand van een praktisch voorbeeld uit een recent onderzoek naar de effectiviteit van verschillende diëten op het gebied van gewichtsverlies.

Inhoudsopgave
Leerdoel
We gebruiken een geavanceerde AI-gegevenstool - Julius, om de analyse uit te voeren. Ons doel is om het analyseproces van academisch onderzoek te demystificeren en te laten zien hoe gegevens, mits zorgvuldig en correct geanalyseerd, fascinerende trends kunnen belichten en antwoorden kunnen bieden op kritische onderzoeksvragen.
Navigeren door de academische gegevensworkflow met Julius
In academisch onderzoek is de manier waarop we met data omgaan van cruciaal belang voor het blootleggen van nieuwe inzichten. Dit deel van onze gids leidt u door de standaardstappen voor het analyseren van onderzoeksgegevens. Van het beginnen met een duidelijke vraag tot het delen van de eindresultaten: elke stap is cruciaal.
We laten zien hoe onderzoekers, door dit duidelijke pad te volgen, ruwe gegevens kunnen omzetten in betrouwbare en waardevolle bevindingen. Vervolgens begeleiden we u bij elke stap aan de hand van een voorbeeldcasestudy, waarin we u laten zien hoe u tijd kunt besparen en tegelijkertijd resultaten van hogere kwaliteit kunt garanderen door Julius gedurende het hele proces te gebruiken.
1. Vraagformulering
Begin met het duidelijk definiëren van uw onderzoeksvraag of hypothese. Dit begeleidt de gehele analyse en bepaalt de methoden die u gaat gebruiken.
2. Gegevensverzameling
Verzamel de benodigde gegevens en zorg ervoor dat deze aansluiten bij uw onderzoeksvraag. Hierbij kan het gaan om het verzamelen van nieuwe data of het gebruiken van bestaande datasets. De gegevens moeten variabelen bevatten die relevant zijn voor uw onderzoek.
3. Gegevensopschoning en voorverwerking
Bereid uw dataset voor op analyse. Deze stap omvat het garanderen van gegevensconsistentie (zoals gestandaardiseerde meeteenheden), het omgaan met ontbrekende waarden en het identificeren van eventuele fouten of uitschieters in uw gegevens.
4. Verkennende gegevensanalyse (EDA)
Voer een eerste onderzoek van de gegevens uit. Dit omvat het analyseren van de verdeling van variabelen, het identificeren van patronen of uitschieters, en het begrijpen van de kenmerken van uw dataset.
5. Methodeselectie
- Analysetechnieken bepalen: Kies passende statistische methoden of modellen op basis van jouw data en onderzoeksvraag. Hierbij kan het gaan om het vergelijken van groepen, het identificeren van relaties of het voorspellen van uitkomsten.
- Overwegingen bij de methodekeuze: De selectie wordt beïnvloed door het type gegevens (bijvoorbeeld categorisch of continu), het aantal groepen dat wordt vergeleken en de aard van de relaties die u onderzoekt.
6. Statistische analyse
- Variabelen operationeel maken: Creëer indien nodig nieuwe variabelen die de concepten die u bestudeert beter vertegenwoordigen.
- Statistische tests uitvoeren: Pas de gekozen statistische methoden toe om uw gegevens te analyseren. Dit kunnen tests zijn zoals t-tests, ANOVA, regressieanalyse, enz.
- Boekhouding voor covariaten: Neem in complexere analyses andere relevante variabelen op om hun potentiële effecten te controleren.
7. Interpretatie
Interpreteer de resultaten zorgvuldig in de context van je onderzoeksvraag. Dit houdt in dat u begrijpt wat de statistische bevindingen in praktische termen betekenen en dat u rekening houdt met eventuele beperkingen.
8. Rapportage
Verzamel uw bevindingen, methodologie en interpretaties in een uitgebreid rapport of academisch artikel. Dit moet duidelijk, beknopt en goed gestructureerd zijn om uw onderzoek effectief te communiceren.
Casestudy Inleiding
In deze casestudy onderzoeken we hoe verschillende diëten gewichtsverlies beïnvloeden. We hebben gegevens over onder meer leeftijd, geslacht, startgewicht, dieettype en gewicht na zes weken. Ons doel is om erachter te komen welke diëten het meest effectief zijn om af te vallen, met behulp van echte gegevens van echte mensen.
Vraagformulering
In elk onderzoek, zoals ons onderzoek naar diëten en gewichtsverlies, begint alles met een goede vraag. Het is als een routekaart voor uw onderzoek, die u begeleidt waar u zich op moet concentreren.
Met onze voedingsgegevens vroegen we bijvoorbeeld: “Leidt een specifiek dieet tot aanzienlijk gewichtsverlies in zes weken?"
Deze vraag is eenvoudig en vertelt ons precies waar we op moeten letten in onze gegevens, waaronder details zoals het dieettype van elke persoon, het gewicht vóór en na zes weken, de leeftijd en het geslacht. Een duidelijke vraag als deze zorgt ervoor dat we op koers blijven en naar de juiste dingen in onze data kijken om de antwoorden te vinden die we nodig hebben.
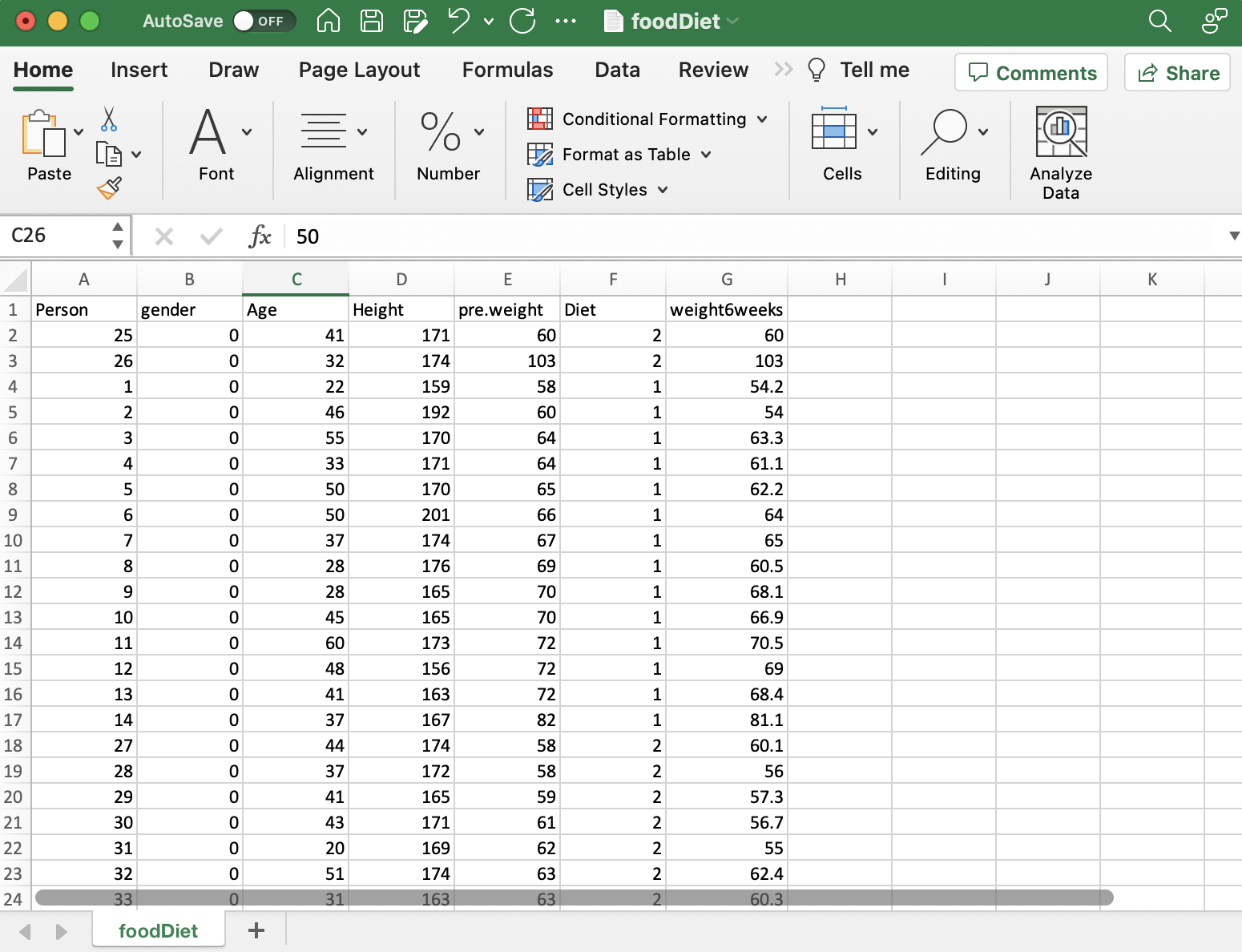
Data Collection
Bij onderzoek is het verzamelen van de juiste data van cruciaal belang. Voor ons onderzoek naar diëten en gewichtsverlies hebben we informatie verzameld over het dieettype van elke persoon, hun gewicht voor en na het dieet, leeftijd en geslacht. Het is belangrijk om ervoor te zorgen dat de gegevens passen bij uw onderzoeksvraag. In sommige gevallen moet u mogelijk nieuwe informatie verzamelen, maar hier hebben we bestaande gegevens gebruikt die al alle details bevatten die we nodig hadden. Het verkrijgen van goede gegevens is de eerste grote stap om erachter te komen wat u wilt weten.

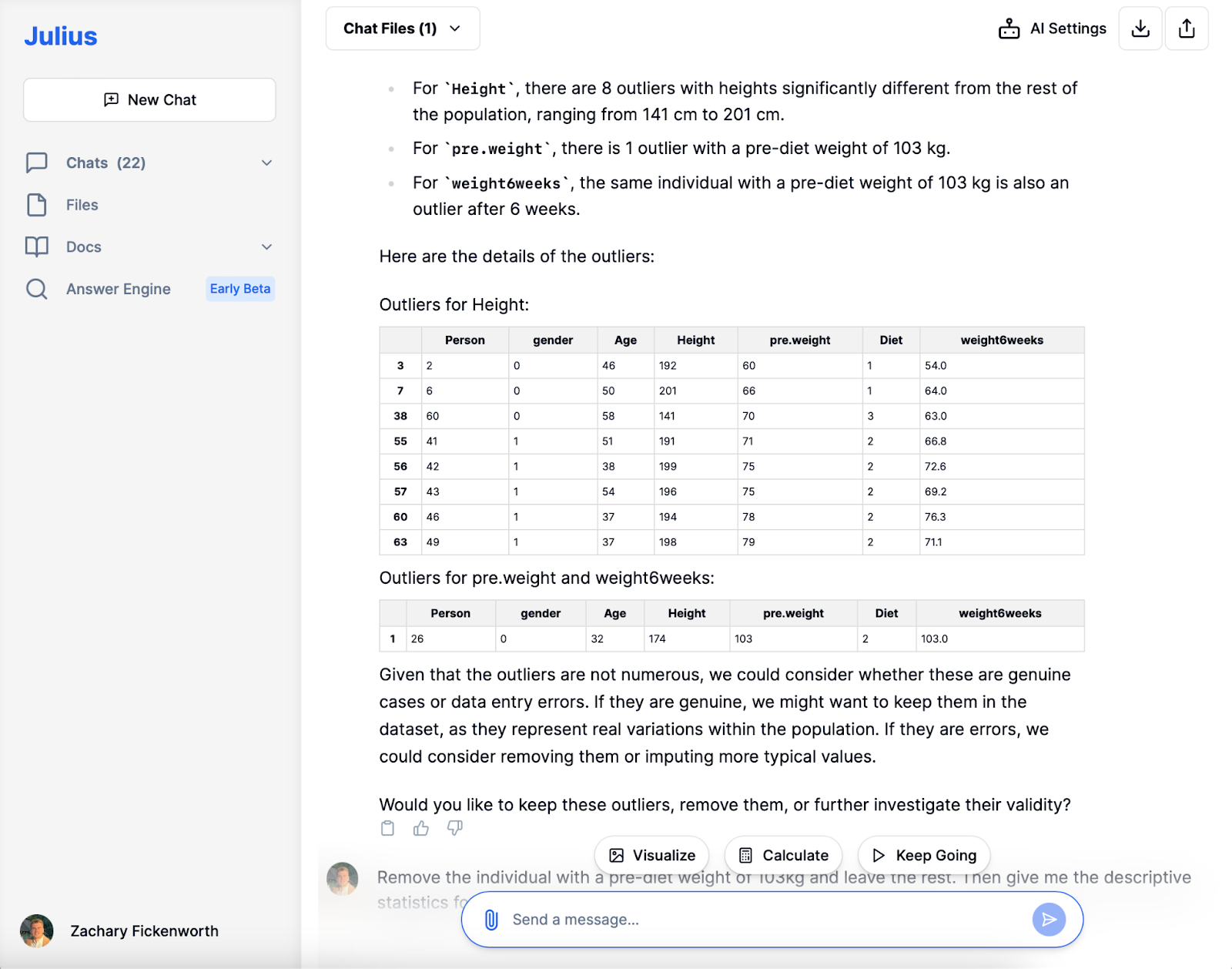
Gegevens opschonen en voorbewerken
In ons dieetonderzoek was het opschonen van gegevens met Julius cruciaal. Na het laden van de gegevens identificeerde Julius ontbrekende waarden en duplicaten, waardoor de duidelijkheid van de dataset werd gewaarborgd. Terwijl we de hoogte-uitschieters voor diversiteit behouden, hebben we ervoor gekozen om een individu met een uitzonderlijk hoog gewicht vóór het dieet (103 kg) uit te sluiten om de analyse-integriteit te behouden en ervoor te zorgen dat de dataset gereed is voor de volgende stadia.
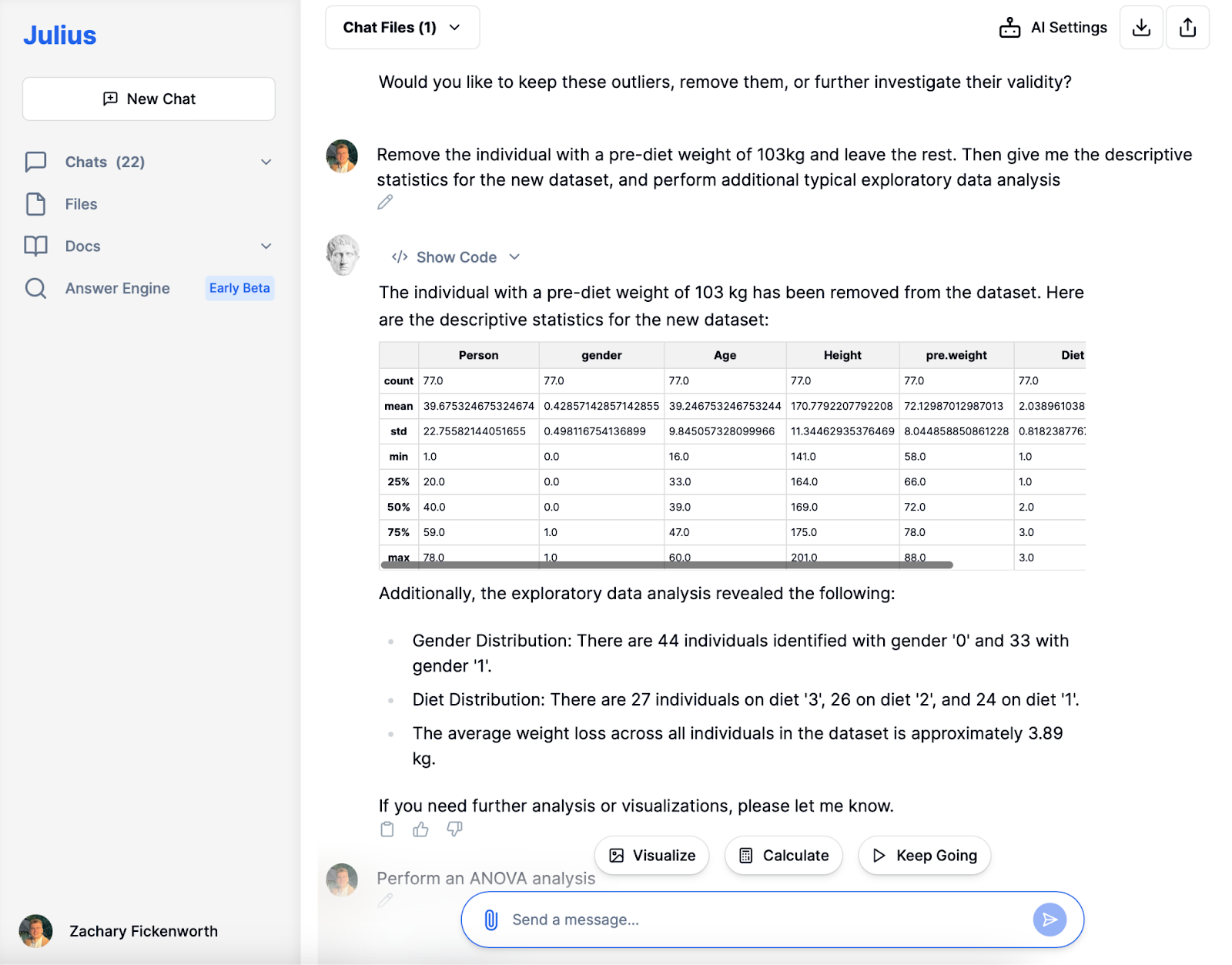
Verkennende gegevensanalyse (EDA)
Na het verwijderen van de uitbijter met een ongewoon hoog gewicht vóór het dieet, zijn we in de verkennende data-analyse (EDA) fase gedoken. Julius zorgde snel voor nieuwe beschrijvende statistieken, die een duidelijker beeld gaven van onze 77 deelnemers. Het ontdekken van een gemiddeld gewicht vóór het dieet van ongeveer 72 kg en een gemiddeld gewichtsverlies van ongeveer 3.89 kg leverde waardevolle inzichten op.
Naast basisstatistieken faciliteerde Julius een onderzoek naar de verdeling van geslacht en dieettype. Het onderzoek bracht een evenwichtige verdeling tussen de geslachten en een gelijkmatige verdeling over de verschillende diëten aan het licht. Deze EDA vat niet alleen gegevens samen; het onthult patronen en trends, cruciaal voor een diepere analyse. Het begrijpen van het gemiddelde gewichtsverlies vormt bijvoorbeeld de basis voor het bepalen van het meest effectieve dieet. Deze door AI aangedreven fase legt de basis voor daaropvolgende gedetailleerde analyses.
Methode selectie
In ons dieetonderzoek was het selecteren van de juiste statistische methoden een cruciale stap. Ons belangrijkste doel was om het gewichtsverlies van verschillende diëten te vergelijken, wat onze keuze voor analysetechnieken direct beïnvloedde. Aangezien we meer dan twee groepen (de verschillende voedingstypen) hadden om te vergelijken, was een Variantieanalyse (ANOVA) de ideale keuze. ANOVA is krachtig in situaties als de onze, waarin we moeten begrijpen of er significante verschillen zijn in een continue variabele (gewichtsverlies) tussen verschillende onafhankelijke groepen (de dieettypen).
Hoewel ANOVA ons vertelt of er verschillen zijn, specificeert het niet waar deze verschillen liggen. Om vast te stellen welke specifieke diëten het meest effectief waren, hadden we een meer gerichte aanpak nodig. Dit is waar paarsgewijze vergelijkingen in beeld kwamen. Nadat we significante resultaten hadden gevonden met ANOVA, gebruikten we paarsgewijze vergelijkingen om de verschillen in gewichtsverlies tussen elk paar dieettypen te onderzoeken.
Deze aanpak in twee stappen – beginnend met ANOVA om eventuele algemene verschillen op te sporen, gevolgd door paarsgewijze vergelijkingen om deze verschillen in detail te beschrijven – was van strategisch belang. Het gaf een uitgebreid inzicht in hoe elk dieet presteerde in relatie tot de andere, waardoor een grondige en genuanceerde analyse van onze voedingsgegevens werd verzekerd.
Statistische analyse

ANOVA
In het hart van ons statistisch onderzoek hebben we een ANOVA analyse om te begrijpen of de verschillen in gewichtsverlies tussen de verschillende dieettypen statistisch significant waren. De resultaten waren behoorlijk onthullend. Met een F-waarde van 5.772 suggereerde de analyse een opmerkelijke variantie tussen de dieetgroepen vergeleken met de variantie binnen elke groep. Deze F-waarde, die hoger was, was indicatief voor significante verschillen in gewichtsverlies tussen de diëten.
Belangrijker nog was dat de P-waarde van 0.00468 opviel. Deze waarde, die ruim onder de conventionele drempel van 0.05 lag, suggereerde sterk dat de verschillen die we in gewichtsverlies tussen de dieetgroepen waarnamen, niet louter toevallig waren. In statistische termen betekende dit dat we de nulhypothese – die zou veronderstellen dat er geen verschil in gewichtsverlies tussen de diëten is – konden verwerpen en konden concluderen dat het type dieet inderdaad een significante invloed had op het gewichtsverlies. Dit ANOVA-resultaat was een cruciale mijlpaal, die ons ertoe bracht verder te onderzoeken welke diëten precies van elkaar verschilden.

paarsgewijs
In de volgende analysefase met Julius voerden we paarsgewijze vergelijkingen uit tussen voedingstypen om specifieke verschillen in gewichtsverlies te identificeren. De Tukey HSD-test gaf geen significant verschil aan tussen Dieet 1 en Dieet 2. Het onthulde echter dat Dieet 3 resulteerde in een aanzienlijk groter gewichtsverlies vergeleken met zowel Dieet 1 als Dieet 2, ondersteund door statistisch significante p-waarden. Deze beknopte maar inzichtelijke analyse van Julius speelde een cruciale rol bij het begrijpen van de relatieve effectiviteit van elk dieet.

Interpretatie
In ons onderzoek naar de effectiviteit van voeding speelde Julius een sleutelrol bij het interpreteren en verklaren van de resultaten van de ANOVA en paarsgewijze vergelijkingen. Hier leest u hoe het ons heeft geholpen de bevindingen te begrijpen:
ANOVA-interpretatie
Eerst werden de ANOVA-resultaten geanalyseerd, die een significante F-waarde en een P-waarde van minder dan 0.05 vertoonden. Dit gaf aan dat er betekenisvolle verschillen waren in gewichtsverlies tussen de verschillende dieetgroepen. Het hielp ons te begrijpen dat dit betekende dat niet alle diëten in het onderzoek even effectief waren in het bevorderen van gewichtsverlies.
Interpretatie van paarsgewijze vergelijkingen
- Dieet 1 versus Dieet 2: Het vergeleek deze twee diëten en vond geen significant verschil in gewichtsverlies. Deze interpretatie betekende dat deze twee diëten statistisch gezien even effectief waren.
- Dieet 1 versus Dieet 3 & Dieet 2 versus Dieet 3: In beide vergelijkingen heb ik vastgesteld dat Dieet 3 aanzienlijk effectiever was in het bevorderen van gewichtsverlies dan Dieet 1 of Dieet 2.
De interpretatie van Julius was cruciaal bij het trekken van concrete conclusies uit onze analyse. Het maakte duidelijk dat, hoewel diëten 1 en 2 qua effectiviteit vergelijkbaar waren, dieet 3 de beste optie was om af te vallen. Deze interpretatie gaf ons niet alleen een duidelijk resultaat van het onderzoek, maar demonstreerde ook de praktische implicaties van onze bevindingen. Met deze informatie kunnen we vol vertrouwen suggereren dat Dieet 3 de betere keuze zou kunnen zijn voor mensen die op zoek zijn naar effectieve oplossingen voor gewichtsverlies.
Rapportage
In de laatste fase van ons dieetonderzoek zouden we een rapport maken dat ons hele onderzoeksproces en onze bevindingen netjes samenvat. Dit rapport, gebaseerd op de analyse die samen met Julius is gedaan, zou het volgende omvatten:
- Inleiding: Een korte uitleg van het doel van de studie, namelijk het evalueren van de effectiviteit van verschillende diëten op gewichtsverlies.
- Methodologie: Een beknopte beschrijving van hoe we de gegevens hebben opgeschoond, de gebruikte statistische methoden (ANOVA en Tukey's HSD) en waarom deze zijn gekozen.
- Bevindingen en interpretatie: Een duidelijke presentatie van de resultaten, inclusief de significante verschillen tussen de diëten, waarbij vooral de effectiviteit van Dieet 3 wordt benadrukt.
- Conclusie: Het trekken van definitieve conclusies uit de gegevens en het voorstellen van praktische implicaties of aanbevelingen op basis van onze bevindingen.
- Referenties: Onder verwijzing naar de tools en statistische methoden, zoals Julius, die onze analyse ondersteunden.
Dit rapport zou dienen als een duidelijk, gestructureerd en alomvattend verslag van ons onderzoek, waardoor het toegankelijk en informatief zou worden voor zijn lezers.
Conclusie
We zijn aan het einde gekomen van onze reis in academisch onderzoek, waarbij we een dataset over diëten hebben omgezet in betekenisvolle inzichten. Dit proces, van de initiële vraag tot het eindrapport, laat zien hoe de juiste tools en methoden data-analyse toegankelijk kunnen maken, zelfs voor beginners.
gebruik Julius, onze geavanceerde AI-tool, hebben we gezien hoe gestructureerde stappen in de data-analyse belangrijke trends kunnen onthullen en belangrijke vragen kunnen beantwoorden. Ons onderzoek naar diëten en gewichtsverlies is slechts één voorbeeld van hoe gegevens, wanneer ze zorgvuldig worden geanalyseerd, niet alleen een verhaal vertellen, maar ook duidelijke, bruikbare conclusies opleveren. We hopen dat deze gids licht heeft geworpen op het data-analyseproces, waardoor het minder intimiderend en spannender wordt voor iedereen die geïnteresseerd is in het ontdekken van de verhalen die in hun data verborgen zitten.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2024/01/guide-to-academic-data-analysis-with-julius-ai/

