In 2006 had Tim Berners-Lee een visie op het bouwen van een semantisch web, mogelijk gemaakt door Linked Data. Nu wordt zijn visie meer dan ooit werkelijkheid, omdat naast mensen ook AI en grote taalmodellen deze gegevens nodig hebben om nieuwe ervaringen te kunnen opleveren.
In dit artikel onderzoeken we wat Linked Data is en delen we voorbeelden van Linked Data-projecten die door velen in de SEO- en technologiegemeenschap kennisgrafieken worden genoemd.
Wat zijn gekoppelde gegevens?
Linked Data is een reeks ontwerpprincipes voor het publiceren van machinaal leesbare, onderling verbonden gegevens op internet.
De term ‘Linked Data’ verscheen voor het eerst in 2006 Tim Berners-Lee publiceerde een ontwerp opmerking over ons het Semantische Web. Hij probeerde Linked Data te gebruiken als een manier om de relatie tussen verschillende dingen op internet weer te geven. Het internet zou dan een enorme database van onderling verbonden (gekoppelde) objecten (data) worden en het Semantische Web worden.
Bedrijven of ondernemingen kunnen Linked Data gebruiken om dingen en de relaties daartussen te definiëren. Bedrijven als Facebook, Twitter en LinkedIn hebben bijvoorbeeld Linked Data-projecten ondernomen om sociale netwerken te vertegenwoordigen. Wanneer gebruikers acties uitvoeren zoals verbinding maken met andere gebruikers of inhoud leuk vinden en opnieuw delen, worden deze acties weerspiegeld in een grafische weergave van wie ze zijn, wie ze kennen en wat ze leuk vinden.

Als gevolg hiervan kunnen deze sociale-mediaplatforms kennis over een persoon opdoen en zaken als gerichte reclame voor gebruikers mogelijk maken op basis van hun relatie tot andere dingen. De kennis die deze sociale-mediaplatforms ontlenen aan hun gekoppelde gegevens is echter bedrijfseigen en niet gelicentieerd voor extern gebruik.
Dit leidde tot een beweging die opriep om Linked Data open te stellen voor mensen om vrijelijk te gebruiken voor onderzoeksdoeleinden – vooral van overheidsorganisaties en andere publieke instellingen zoals musea.
In 2010 wijzigde Tim Berners-Lee zijn oorspronkelijke ontwerpnota om principes toe te voegen voor Linked Open Data, een variant van Linked Data die hergebruik mogelijk maakt.
Linked Open Data (LOD) is Linked Data die is vrijgegeven onder een open licentie, waardoor anderen deze vrijelijk kunnen openen en hergebruiken.
Principes van gekoppelde gegevens
Toen Tim Berners-Lee voor het eerst de designnota over Linked Data publiceerde, definieerde hij de 4 principes van Linked Data. Op basis van deze notitie zouden mensen of machines het dataweb kunnen verkennen als het zich aan de volgende vier principes zou houden:
1. Gebruik URI's als namen voor dingen
Een URI (Uniform Resource Identifier) is een reeks tekens die een bron identificeert. Het biedt een consistente manier om bronnen in verschillende systemen en protocollen te identificeren. Een hulpbron (ook wel een entiteit genoemd) is alles wat kan worden geïdentificeerd en beschreven, zoals mensen, plaatsen, objecten of concepten.
2. Gebruik HTTP [of HTTPS] URI's zodat mensen die namen kunnen opzoeken
Een HTTP/HTTPS-URI is een specifiek type URI dat gebruikmaakt van het Hypertext Transfer Protocol of Protocol Secure. Dit betekent dat wanneer u toegang krijgt tot een HTTP/HTTPS-URI in een webbrowser of via een HTTP-verzoek, u informatie terugkrijgt over de bron die deze identificeert.
3. Wanneer iemand een URI opzoekt, geef dan nuttige informatie, gebruik makend van de standaarden (RDF, SPARQL)
Wanneer een gebruiker of applicatie toegang krijgt tot een Uniform Resource Identifier (URI), moet de geretourneerde informatie zowel betekenisvol als gestructureerd zijn volgens gestandaardiseerde semantische technologieën, met name RDF (voor het uitdrukken van de gegevens) en SPARQL (voor het opvragen van de gegevens).
4. Voeg links naar andere URI's toe, zodat ze meer dingen kunnen ontdekken
Wanneer u gegevens maakt of publiceert, moet u in uw gegevens koppelingen naar andere bronnen of entiteiten opnemen (in de vorm van URI's). Deze URI's kunnen verwijzen naar gerelateerde of relevante informatie, zoals andere bronnen, definities of attributen. Dit biedt extra context over uw eigen bronnen.
Door deze principes te volgen, draagt u bij aan een groeiend netwerk van onderling verbonden gegevens op internet. Hierdoor kunnen consumenten van de gegevens (mens of machine) meer inzichten, context en kennis verzamelen.
Het voordeel van het gebruik van Linked Data voor SEO
Linked Data is geweldig voor SEO omdat het zoekmachines meer contextuele kennis over uw inhoud kan bieden. Zoekmachines kijken nu naar de relevantie om zoekers de meest nauwkeurige resultaten te bieden.
Een van de meest voorkomende vormen van gekoppelde gegevens op internet is Schema Markup, die voornamelijk de inhoud van webpagina's voor zoekmachines beschrijft. Schema Markup maakt gebruik van de Schema.org-vocabulaire die aan RDF gekoppelde gegevens kan uitdrukken in formaten zoals JSON-LD.
Wanneer u machineleesbare code zoals Schema Markup gebruikt om de relatie tussen de entiteiten op uw site tot uitdrukking te brengen, helpt dit zoekmachines uw organisatie te begrijpen en er kennis over af te leiden.
Als u bijvoorbeeld een pagina heeft over de eigen softwareapplicatie van uw organisatie, kunt u zoekmachines laten weten dat deze softwareapplicatie door uw organisatie wordt geleverd door de URI die alle informatie over uw organisatie bevat, te koppelen aan de providereigenschap in de opmaak voor uw organisatie. bladzijde.
{ "@context": "http://schema.org/", "@type": "SoftwareApplicatie", "@id": "https://www.schemaapp.com/solutions/schema-app-highlighter/ #SoftwareApplication", "name": "Schema App Highlighter", "description": "Gebruik de Schema App Highlighter om uw Schema Markup aan te passen...", "applicationCategory": "Search Engine Optimization", "provider": { "@type": "Organisatie",
"@id": "https://www.schemaapp.com/#Organisatie", "url": "https://www.schemaapp.com/", "name": "Schema App", "description": "Schema App is een end-to-end Schema Markup-oplossing...", "telephone": "18554448624",
"email": "support@schemaapp.com",
"areaServed": "http://www.wikidata.org/entity/Q13780930", }}
De URI verschijnt in JSON-LD in het kenmerk @id. Uw Schema Markup kan worden gegenereerd en geschreven zonder ID's (@id) op te nemen. Zoekmachines zoals Google zullen het nog steeds lezen en ervoor zorgen dat het in aanmerking komt voor rijke resultaten. Door uw Schema Markup met een URI te genereren, kunt u deze echter aan andere entiteiten koppelen.
U kunt uw Schema Markup ook koppelen aan andere Linked Data-projecten om explicieter te zijn over de entiteiten waarover u het heeft op uw website.
Als je het bijvoorbeeld op een pagina over voetbal hebt, kan dit verwarrend zijn voor zoekmachines, omdat de term voetbal verschillende dingen kan betekenen, afhankelijk van waar ter wereld je je bevindt. U kunt zoekmachines helpen duidelijk te maken naar welke voetbal u verwijst door uw pagina te koppelen aan dezelfde entiteit die wordt beschreven in Wikipedia, Wikidata of de Knowledge Graph van Google.
Als je het over Amerikaans voetbal hebt, kun je de hetzelfde als eigenschap in uw Schema Markup om te linken naar dezelfde entiteit op Wikipedia, Wikidata of de Knowledge Graph van Google.
{ "@context": "http://schema.org/", "@type": "BlogPosting", "@id": "https://www.schemaapp.com/blog/what-is-football/ #BlogPosting", "url": "https://www.schemaapp.com/blog/wat-is-voetbal/", "name": "Wat is voetbal?", "headline": "Wat is voetbal?" , "description": "Leer meer over de regels en geschiedenis van voetbal.", "mentions": { "@type": "Ding",
"name": "Voetbal", "sameAs": "https://www.wikidata.org/wiki/Q41323", "sameAs": "https://en.wikipedia.org/wiki/American_football", "sameAs ": "kg:/m/0jm_", }}
Het toepassen van Linked Data op uw site kan echter een technisch uitdagende taak zijn.
- Kwaliteit – U moet de gegevens actueel, accuraat en volledig houden.
- Schaalbaarheid – Het verwerken van deze enorme hoeveelheid gegevens kan tijdrovend en arbeidsintensief zijn.
- Expertise – Het transformeren van uw inhoud in Linked Data vereist kennis van de technologieën om dit werk te doen en hoe u deze effectief kunt toepassen.
- Duurzaamheid – Je hebt middelen nodig om de datakwaliteit op peil te houden.
Voorbeelden van Linked Data-projecten in SEO
Er zijn veel voorbeelden van Linked Data-projecten die tegenwoordig worden gebruikt. Deze Linked Data Projecten worden ook wel Kennisgrafieken genoemd.
Kennis grafieken zijn een verzameling gerelateerde entiteiten, uitgedrukt als RDF-triples. Wanneer u Schema Markup gebruikt om de relatie tussen twee entiteiten op uw site tot uitdrukking te brengen, implementeert u Linked Data. Wanneer u de verschillende entiteiten op uw site met elkaar verbindt, ontwikkelt u effectief een interne kennisgrafiek over uw organisatie. Uw interne kennisgrafiek wordt nog robuuster en nuttiger wanneer deze wordt gekoppeld aan andere externe kennisgrafieken.
Sommige van deze externe kennisgrafieken zijn ook nuttig voor zoekmachineoptimalisatie (SEO). SEO-teams kunnen hun interne kennisgrafieken verbinden met externe kennisgrafieken om zoekmachines te vertellen dat de entiteit die in deze externe kennisgrafiek is gedefinieerd, dezelfde is als de entiteit die op hun website is gedefinieerd.
Laten we een aantal van de Linked Data Projecten/Externe Kennisgrafieken verkennen die betrekking hebben op de SEO-wereld.
Google's Knowledge Graph
Google's Knowledge Graph is een kennisdatabase die Google gebruikt om snel antwoord te geven op vragen over bepaalde onderwerpen of entiteiten (mensen, plaatsen, organisaties, dingen). Dit kan in de zoekresultaten verschijnen in de vorm van een kennispaneel. De kennis paneel bevat een momentopname van informatie over het onderwerp, gebaseerd op het inzicht van Google in de beschikbare inhoud op internet.
Het verhaal van Google's Knowledge Graph begint met Freebase, een Metaweb-project dat in 2007 werd gelanceerd. beschreven als “een systeem voor het bouwen van de synapsen voor het mondiale brein”. Deze enorme kennisbasis, die in 2008 formeel een linked open data-project werd, was een van de grootste en meest ambitieuze Linked Data-projecten van zijn tijd.
In 2010, Google Freebase overgenomen van Metaweb en importeerde de enorme kennisbank van Freebase in de eigen Knowledge Graph van Google. Kort daarna introduceerde Google hun Knowledge Graph in hun beroemde 'dingen, geen snaren' artikel, wat een verschuiving aangeeft van lexicaal naar semantisch zoeken.
De Google Knowledge Graph is een Linked Data-project omdat het voldoet aan de 4 principes van Linked Data. De Google Knowledge Graph is dat echter wel NIET een gekoppeld open dataproject omdat de data niet met een open licentie worden gepubliceerd. Dat gezegd hebbende, is het mogelijk om identifiers (URI's) voor entiteiten in de Google Knowledge Graph te vinden en deze te koppelen aan uw eigen kennisgrafiek.
Hoe krijg ik toegang tot de Kennisgrafiek van Google?
De Google Knowledge Graph heeft een zoek-API dat is alleen-lezen. U zult merken dat de URI's in de uitvoer zijn gestructureerd met een 'kg'-naamruimte (die staat voor http://g.co/kg) en /m/ of /g/ vóór een reeks tekens. Deze identificatiegegevens worden “mid”s of machine IDs, een oudere term van Freebase.
Het Freebase-object voor de entiteit Barack Obama heeft bijvoorbeeld mid /m/02mjmr. Dezelfde entiteit is toegankelijk in de Kennisgrafiek van Google door naar te gaan https://www.google.com/search?kgmid=/m/02mjmr. De entiteit heeft hetzelfde midden in de Knowledge Graph van Google.
Hoe wordt de Knowledge Graph van Google gebruikt?
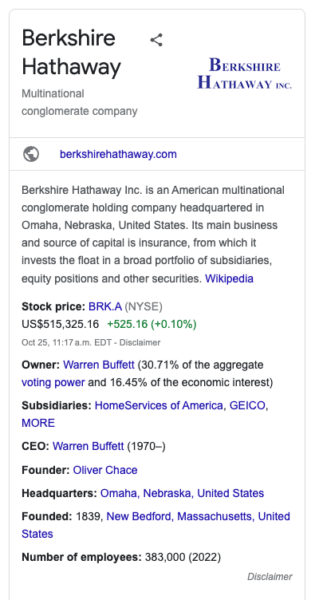
Google gebruikt zijn kennisgrafiek om de zoekervaring op zijn zoekmachine te verbeteren. Wanneer u zoekt naar zoiets als 'Berkshire Hathaway', identificeert Google de entiteiten in uw zoekopdracht en verstrekt informatie over die entiteiten uit zowel de kennisgrafiek als andere bronnen op internet. Een van de meest voorkomende bronnen is Wikipedia.
Wikipedia en DBpedia
Wikipedia is een gratis, collaboratieve online-encyclopedie die bestaat uit meer dan 61 miljoen artikelen. Wikipedia-artikelen vertegenwoordigen entiteiten, zoals mensen, plaatsen, gebeurtenissen, concepten of andere dingen.
De URL's van Wikipedia-artikelen fungeren ook als URI's voor de entiteiten die ze vertegenwoordigen. Dus de URL https://en.wikipedia.org/wiki/Kathryn_Janeway is zowel een artikel dat op internet kan worden bezocht, als de URI die de entiteit, Kathryn Janeway, vertegenwoordigt in de kennisbank van Wikipedia.
Artikelen binnen Wikipedia bevatten gestructureerde elementen, evenals links naar andere gerelateerde entiteiten. Hoewel Wikipedia op zichzelf geen traditioneel Linked Data-project is, speelt het een belangrijke rol in het Linked Data-ecosysteem op internet, vooral met betrekking tot DBpedia en Wikidata.
DBpedia is een gekoppeld open dataproject dat informatie uit Wikipedia haalt om RDF-triples te genereren, die semantisch kunnen worden opgevraagd naast andere gerelateerde datasets. Het haalt informatie uit de gestructureerde elementen van Wikipedia-pagina's, zoals "infobox"-tabellen zoals deze:
Hoewel Wikipedia misschien een uitstekende bron van samengevatte informatie voor algemeen gebruik is, betekent de diepte en breedte van de informatie op Wikipedia dat het een essentiële bron van trainingsgegevens is geworden voor veel AI-initiatieven zoals natuurlijke taalverwerking, herkenning van benoemde entiteiten en de ontwikkeling van Kennisgrafieken zoals de Kennisgrafiek van Google.
 Bericht van Wikipedia Engineering Manager, Joseph S.; geïnspireerd door https://xkcd.com/2347/
Bericht van Wikipedia Engineering Manager, Joseph S.; geïnspireerd door https://xkcd.com/2347/
Wikidata
Wikidata is een samenwerkend Linked Open Data-project dat sinds de oprichting in 2012 wordt beheerd door de Wikimedia Foundation ((bron)).
Ondanks dat Wiki in zijn naam staat, is Wikidata niet hetzelfde als Wikipedia. Wikidata is een bredere kennisbank dan Wikipedia, die gegevens bevat over een breder scala aan onderwerpen. Met Wikidata kunnen gebruikers ook rechtstreeks RDF Linked Data creëren.
Ook al zijn Wikidata en DBpedia beide Linked Open Data-projecten gerelateerd aan Wikipedia, toch is dat zo verschillende doeleinden en vervullen verschillende functies.
DBpedia extraheert informatie om gekoppelde gegevens te genereren uit de gestructureerde bronnen van Wikipedia, zoals infoboxen. Als gevolg hiervan behandelt DBpedia de verkregen kennis als feiten.
In plaats van informatie uit Wikipedia te halen, creëert Wikidata Linked Data voor Wikipedia ((bron)). Omdat Wikidata verklaringen binnen de Linked Data ook als claims behandelt in plaats van als feiten, moeten deze verklaringen worden geannoteerd met informatie over de herkomst (dat wil zeggen wie elke claim heeft gemaakt).
In plaats van 'mid's (identificaties gebruikt door Freebase/Google's Knowledge Graph), heeft elke entiteit in Wikidata een 'qid'.
Hier volgt een samenvatting van de ID's voor elk van de hierboven genoemde Linked Data-projecten.
Google's Knowledge Graph, Wikipedia en Wikidata zijn de meest voorkomende Linked Data-projecten die worden gebruikt in SEO. Als we het hebben over het verbinden van uw Schema Markup met externe gezaghebbende kennisbanken bij Schema App, zijn dit de externe kennisgrafieken waar we het over hebben.
Hoe u Linked Data gebruikt met de Schema-app
Bij Schema App zorgen onze semantische technologieën ervoor dat SEO-teams eenvoudig Linked Data voor hun website-inhoud kunnen genereren.
Genereer URI's voor uw entiteiten
Wanneer u uw Schema Markup publiceert met behulp van de Schema App Editor of Highlighter, genereert onze tool automatisch HTTPS-URI's voor de entiteiten die u in uw Schema Markup definieert. Deze URI's, die verschijnen in het @id-attribuut, linken naar de URL's van de pagina's waarop ze worden vermeld.
We publiceren bijvoorbeeld organisatiemarkeringen op de startpagina van onze Schema-app. De URI voor onze Organisatie-entiteit zou dan de URL zijn van onze startpagina + #Organisatie – https://www.schemaapp.com/#Organization. Als u naar deze URI navigeert, komt u op de pagina over onze organisatie.
Door URI's voor entiteiten op uw site te maken, kunt u eenvoudig naar die entiteiten linken in uw Schema-opmaak. Als uw organisatie bijvoorbeeld een blogpost heeft gepubliceerd, kunt u uw organisatie-URI koppelen aan de uitgeverseigenschap in uw BlogPosting Schema Markup.
{ "@context": "http://schema.org/", "@type": "BlogPosting", "@id": "https://www.schemaapp.com/schema-markup/what-is- a-rich-result/#BlogPosting", "url": "https://www.schemaapp.com/schema-markup/what-is-a-rich-result/", "name": "Wat is een Rich Resultaat?", "headline": "Wat is een rijk resultaat?", "description": "Een rijk resultaat is een verbeterd zoekresultaat dat wordt weergegeven op de resultatenpagina van een zoekmachine. Ontdek hoe u een rijk resultaat voor uw pagina kunt bereiken. ", "publisher": { "@type": "Organisatie", "@id": "https://www.schemaapp.com/#Organisatie",
"url": "https://www.schemaapp.com/", "name": "Schema-app",
"description": "Schema App is een end-to-end Schema Markup-oplossing...", "telephone": "18554448624",
"email": "support@schemaapp.com",
"areaServed": "http://www.wikidata.org/entity/Q13780930", }}
Koppeling met externe entiteiten
Met onze tools kunnen SEO-teams ook linken naar externe entiteiten via verschillende methoden, zoals:
U kunt dit artikel lezen voor meer informatie over onze methoden voor het koppelen van entiteiten.
Overwin de uitdagingen bij het implementeren van Linked Data
Samenvattend faciliteert Linked Data de verbinding van gegevens uit verschillende bronnen om machines van meer contextuele informatie te voorzien, waardoor ze nieuwe kennis uit bestaande feiten kunnen afleiden.
Door gekoppelde gegevens toe te passen via de Schema Markup op uw site kunnen zoekmachines de relatie tussen de entiteiten op uw site beter begrijpen en de entiteiten die in uw inhoud worden genoemd, ondubbelzinnig maken.
Als u hulp nodig heeft bij het implementeren van Linked Data op uw site, kunnen wij u helpen. Bij Schema App bieden we SEO-teams de tools en expertise om Linked Data op schaal te implementeren. Neem contact met ons op bij ons om meer te weten te komen.

Jasmine is de Product Enablement Lead bij Schema App. Schema App is een end-to-end Schema Markup-oplossing die SEO-teams van ondernemingen helpt bij het creëren, implementeren en beheren van Schema Markup om op te vallen in de zoekresultaten.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.schemaapp.com/schema-markup/linked-data-in-seo-what-you-need-to-know/

