Omdat bedrijven steeds grotere hoeveelheden gegevens uit verschillende bronnen verzamelen, moeten de structuur en organisatie van die gegevens in de loop van de tijd vaak veranderen om aan de veranderende analytische behoeften te voldoen. Het wijzigen van schema- en tabelpartities in traditionele datameren kan echter een ontwrichtende en tijdrovende taak zijn, waarbij volledige tabellen moeten worden hernoemd of opnieuw moeten worden gemaakt en grote datasets opnieuw moeten worden verwerkt. Dit belemmert de wendbaarheid en de tijd tot inzicht.
Schema-evolutie maakt het toevoegen, verwijderen, hernoemen of wijzigen van kolommen mogelijk zonder bestaande gegevens te herschrijven. Dit is van cruciaal belang voor snel evoluerende ondernemingen om datastructuren uit te breiden om nieuwe gebruiksscenario's te ondersteunen. Een e-commercebedrijf kan bijvoorbeeld nieuwe demografische klantkenmerken of bestelstatusvlaggen toevoegen om de analyses te verrijken. Apache-ijsberg beheert deze schemawijzigingen op een achterwaarts compatibele manier via zijn innovatieve metadatatabel-evolutiearchitectuur.
Op dezelfde manier maakt partitie-evolutie het naadloos toevoegen, verwijderen of splitsen van partities mogelijk. Een e-commercemarktplaats kan bijvoorbeeld in eerste instantie de bestelgegevens per dag verdelen. Naarmate de bestellingen zich opstapelen en het opvragen per dag inefficiënt wordt, kunnen deze worden opgesplitst in dag- en klant-ID-partities. Met tabelpartitionering worden grote gegevenssets op de meest efficiënte manier georganiseerd voor de prestaties van query's. Iceberg geeft bedrijven de flexibiliteit om partities stapsgewijs aan te passen in plaats van vervelende herbouwprocedures te vereisen. Nieuwe partities kunnen op een volledig compatibele manier worden toegevoegd zonder downtime of het herschrijven van bestaande gegevensbestanden.
Dit bericht laat zien hoe je Iceberg kunt benutten, Amazon eenvoudige opslagservice (Amazone S3), AWS lijm, AWS Lake-formatie en AWS Identiteits- en toegangsbeheer (IAM) om een transactioneel datameer te implementeren dat een naadloze evolutie ondersteunt. Door pijnloze schema- en partitieaanpassingen mogelijk te maken naarmate data-inzichten evolueren, kunt u profiteren van de toekomstbestendige flexibiliteit die nodig is voor zakelijk succes.
Overzicht van de oplossing
In ons voorbeeld verwerkt een fictief groot e-commercebedrijf elke dag duizenden bestellingen. Wanneer bestellingen worden ontvangen, bijgewerkt, geannuleerd, verzonden, afgeleverd of geretourneerd, worden de wijzigingen aangebracht in hun lokale systeem en moeten deze wijzigingen worden gerepliceerd naar een S3-datameer, zodat data-analisten query's kunnen uitvoeren. Amazone Athene. De wijzigingen kunnen ook schema-updates bevatten. Vanwege de beveiligingsvereisten van verschillende organisaties moeten ze via Lake Formation een fijnmazige toegangscontrole voor de analisten beheren.
Het volgende diagram illustreert de oplossingsarchitectuur.
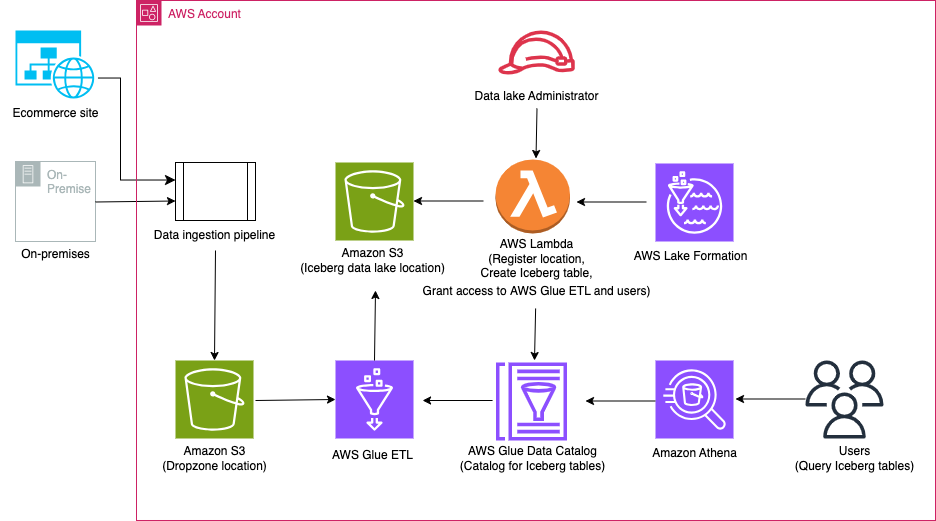
De oplossingsworkflow omvat de volgende belangrijke stappen:
- Gegevens opnemen van on-premises naar een Dropzone-locatie met behulp van een pijplijn voor gegevensopname.
- Voeg de gegevens van de Dropzone-locatie samen met Iceberg met behulp van AWS Glue.
- Vraag de gegevens op met Athena.
Voorwaarden
Voor deze walkthrough moet u aan de volgende vereisten voldoen:
Zet de infrastructuur op met AWS CloudFormation
Om uw infrastructuur te creëren met een AWS CloudFormatie sjabloon, voert u de volgende stappen uit:
- Log in als beheerder op uw AWS-account.
- Open de AWS CloudFormation-console.
- Kies Start Stack:

- Voor Stack naam, voer een naam in (voor dit bericht, ijsbergdemo1).
- Kies Volgende.
- Geef informatie op voor de volgende parameters:
DatalakeUserNameDatalakeUserPasswordDatabaseNameTableNameDatabaseLFTagKeyDatabaseLFTagValueTableLFTagKeyTableLFTagValue
- Kies Volgende.
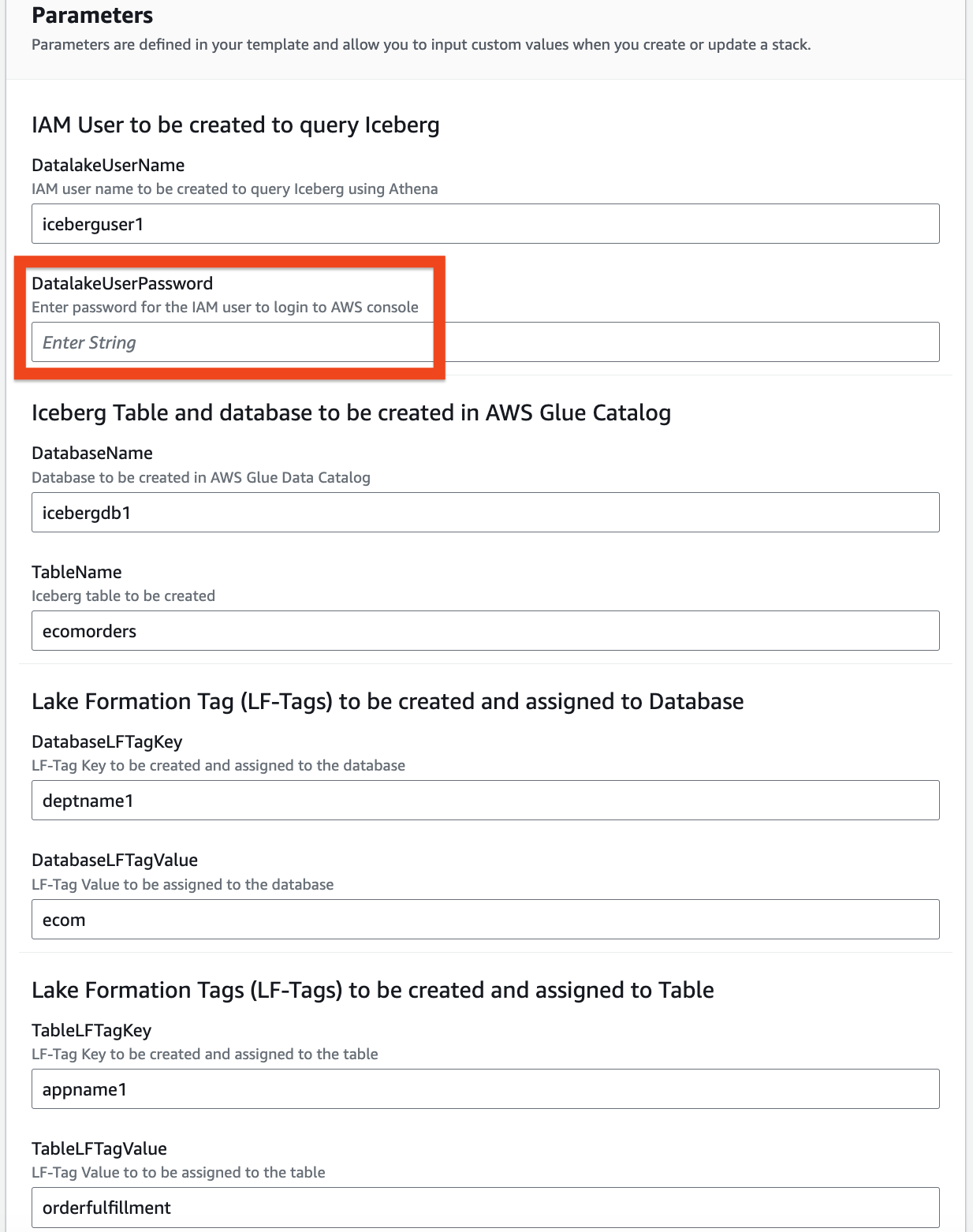
- Kies Volgende weer.
- In het Beoordeling sectie, controleer de waarden die u hebt ingevoerd.
- kies Ik erken dat AWS CloudFormation IAM-bronnen met aangepaste namen kan maken En kies Verzenden.
Binnen een paar minuten verandert de stapelstatus in CREATE_COMPLETE.
U kunt naar de Tabblad Uitgangen van de stapel om alle bronnen te zien die deze heeft ingericht. De bronnen worden voorafgegaan door de stapelnaam die u heeft opgegeven (voor dit bericht icebergdemo1).
Maak een ijsbergtabel met Lambda en verleen toegang met Lake Formation
Voer de volgende stappen uit om een ijsbergtabel te maken en er toegang toe te verlenen:
- Navigeer naar de Resources tabblad van de CloudFormation-stack icebergdemo1 en zoek naar logische ID met de naam
LambdaFunctionIceberg. - Kies de hyperlink van de bijbehorende fysieke ID.
U wordt doorgestuurd naar de Lambda-functie icebergdemo1-Lambda-Create-Iceberg-and-Grant-access.
- Op de Configuratie tabblad, kies Omgevingsvariabelen in het linkerdeelvenster.

- Op de Code tabblad kunt u de functiecode inspecteren.
De functie maakt gebruik van de AWS SDK voor Python (Boto3) API's om de bronnen in te richten. Het neemt de ingerichte rol van Data Lake-beheerder over om de volgende taken uit te voeren:
- Grant DATA_LOCATION_ACCESS toegang tot de data lake-beheerdersrol op de geregistreerde data lake-locatie
- creëren Tags voor meerformatie (LF-Tags)
- Maak een database in de AWS Glue Data Catalog met behulp van AWS Glue create_database API
- Wijs LF-Tags toe aan de database
- Verleen DESCRIBE-toegang tot de database met behulp van LF-Tags aan de data lake IAM-gebruiker en AWS Glue ETL IAM-rol
- Maak een ijsbergtafel met behulp van de AWS Glue maak_tabel API:
- Wijs LF-Tags toe aan de tafel
- Verleen DESCRIBE en SELECT op de Iceberg-tabel LF-Tags voor de data lake IAM-gebruiker
- Verleen ALL, DESCRIBE, SELECT, INSERT, DELETE en ALTER toegang tot de Iceberg-tabel LF-Tags voor de AWS Glue ETL IAM-rol
- Op de test tabblad, kies test om de functie uit te voeren.

Wanneer de functie voltooid is, ziet u de melding “Functie uitvoeren: geslaagd.”
Lake Formation helpt u gegevens centraal te beheren, beveiligen en wereldwijd te delen voor analyse en machine learning. Met Lake Formation kunt u een fijnmazig toegangscontrole beheren voor uw data lake-gegevens op Amazon S3 en de bijbehorende metadata in de Data Catalog.
Om een Amazon S3-locatie toe te voegen als Iceberg-opslag in uw data lake, registreer de locatie met de vorming van meren. Vervolgens kunt u Lake Formation-machtigingen gebruiken voor gedetailleerd toegangscontrole tot de Data Catalog-objecten die naar deze locatie verwijzen, en naar de onderliggende gegevens op de locatie.
De CloudFormation-stack registreerde de data lake-locatie.

Toestemmingen voor gegevenslocatie in Lake Formation kunnen opdrachtgevers Data Catalog-bronnen maken en wijzigen die verwijzen naar de aangewezen geregistreerde Amazon S3-locaties. Toestemmingen voor gegevenslocatie werken als aanvulling op Lake Formation gegevensrechten om informatie in uw data lake te beveiligen.
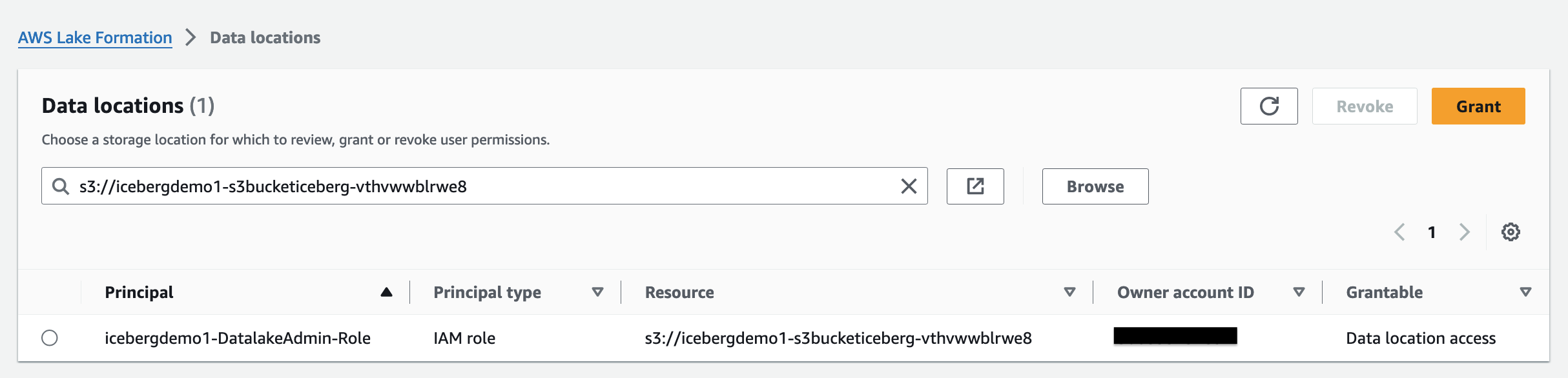
Op tags gebaseerde toegangscontrole op Lake Formation (LF-TBAC) is een autorisatiestrategie die machtigingen definieert op basis van attributen. In Lake Formation worden deze attributen LF-Tags genoemd. U kunt LF-Tags koppelen aan Data Catalog-resources, Lake Formation-principals en tabelkolommen. U kunt machtigingen voor Lake Formation-resources toewijzen en intrekken met behulp van deze LF-Tags. Lake Formation staat bewerkingen op deze resources toe wanneer de tag van de opdrachtgever overeenkomt met de resourcetag.
Controleer de ijsbergtabel vanaf de Lake Formation-console
Voer de volgende stappen uit om de ijsbergtabel te verifiëren:
- Kies op de Lake Formation-console databases in het navigatievenster.
- Open de detailpagina voor
icebergdb1.
U kunt de bijbehorende database LF-Tags zien.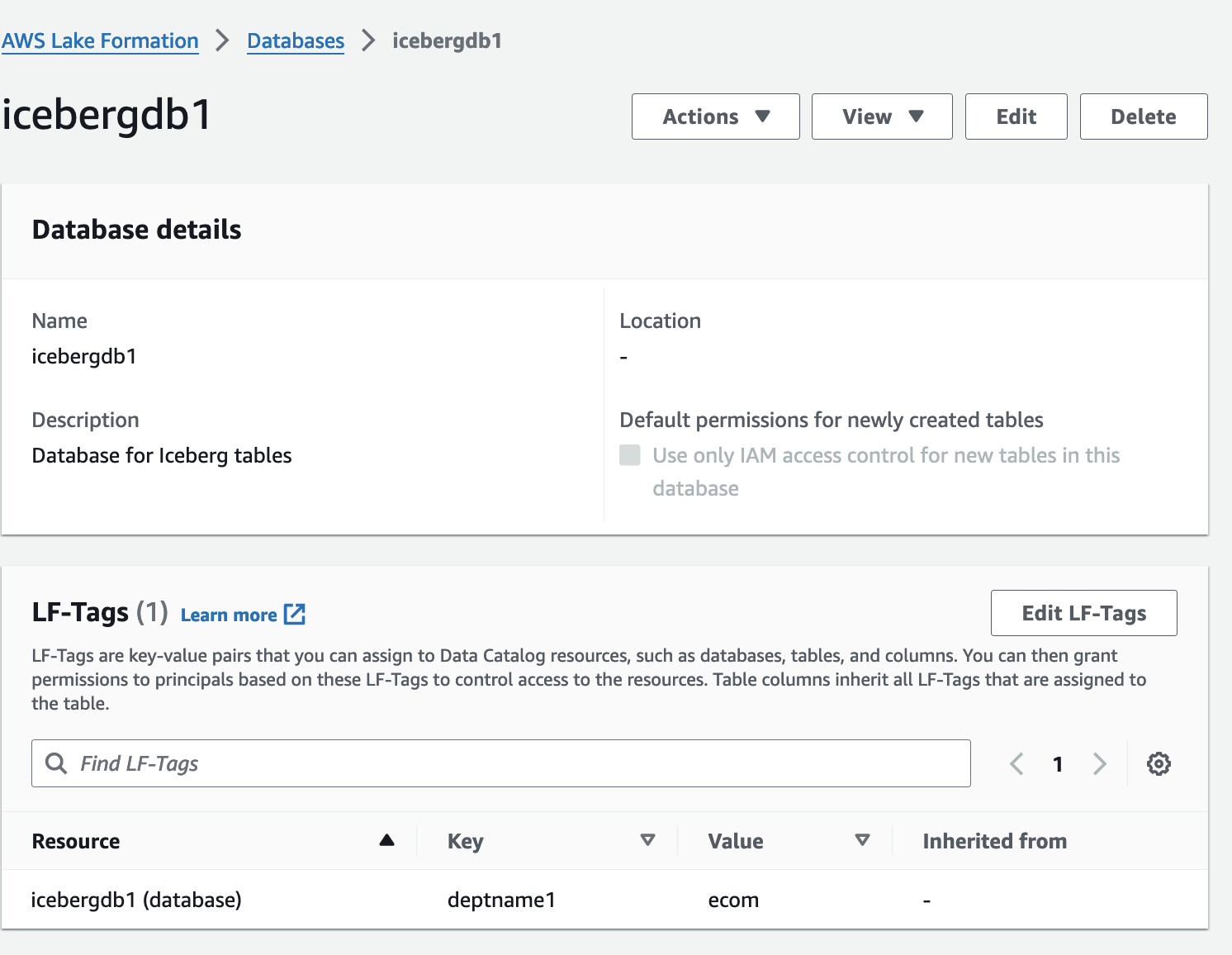
- Kies Tafels in het navigatievenster.
- Open de detailpagina voor
ecomorders.
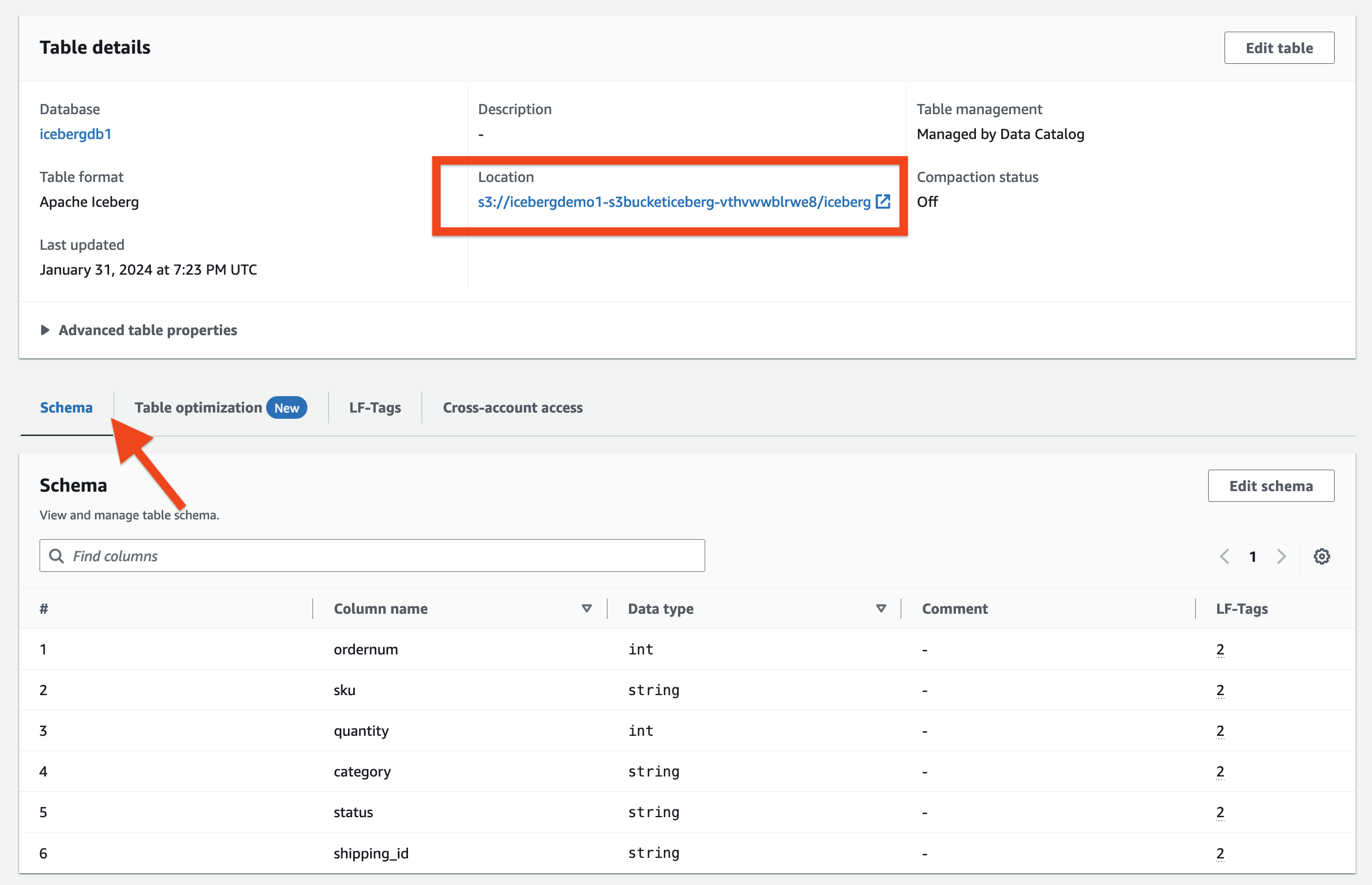
In het Tabeldetails sectie kunt u het volgende waarnemen:
- Tabelformaat wordt weergegeven als Apache-ijsberg
- Tafelbeheer wordt weergegeven als Beheerd door Data Catalog
- Locatie geeft de data lake-locatie van de ijsbergtabel weer
In het LF-tags sectie kunt u de bijbehorende tabel LF-Tags bekijken.
In het Tabeldetails sectie, uitbreiden Geavanceerde tabeleigenschappen om het volgende te bekijken:
metadata_locationverwijst naar de locatie van het metagegevensbestand van de ijsbergtabeltable_typewordt weergegeven alsICEBERG
Op de Schema Op het tabblad kunt u de kolommen bekijken die zijn gedefinieerd in de ijsbergtabel.
Integreer Iceberg met de AWS Glue Data Catalog en Amazon S3
Iceberg houdt individuele gegevensbestanden bij in een tabel in plaats van in mappen. Wanneer er een expliciete commit op tafel ligt, maakt Iceberg gegevensbestanden en voegt deze toe aan de tabel. Iceberg onderhoudt de tabelstatus in metadatabestanden. Elke wijziging in de tabelstatus creëert een nieuw metadatabestand dat de oudere metadata atomair vervangt. Metagegevensbestanden houden het tabelschema, de partitieconfiguratie en andere eigenschappen bij.
Iceberg vereist dat bestandssystemen die de bewerkingen ondersteunen compatibel zijn met objectstores zoals Amazon S3.
Iceberg maakt momentopnamen voor de tabelinhoud. Elke momentopname is een complete set gegevensbestanden in de tabel op een bepaald tijdstip. Gegevensbestanden in momentopnamen worden opgeslagen in een of meer manifestbestanden die een rij bevatten voor elk gegevensbestand in de tabel, de partitiegegevens en de bijbehorende statistieken.
Het volgende diagram illustreert deze hiërarchie.
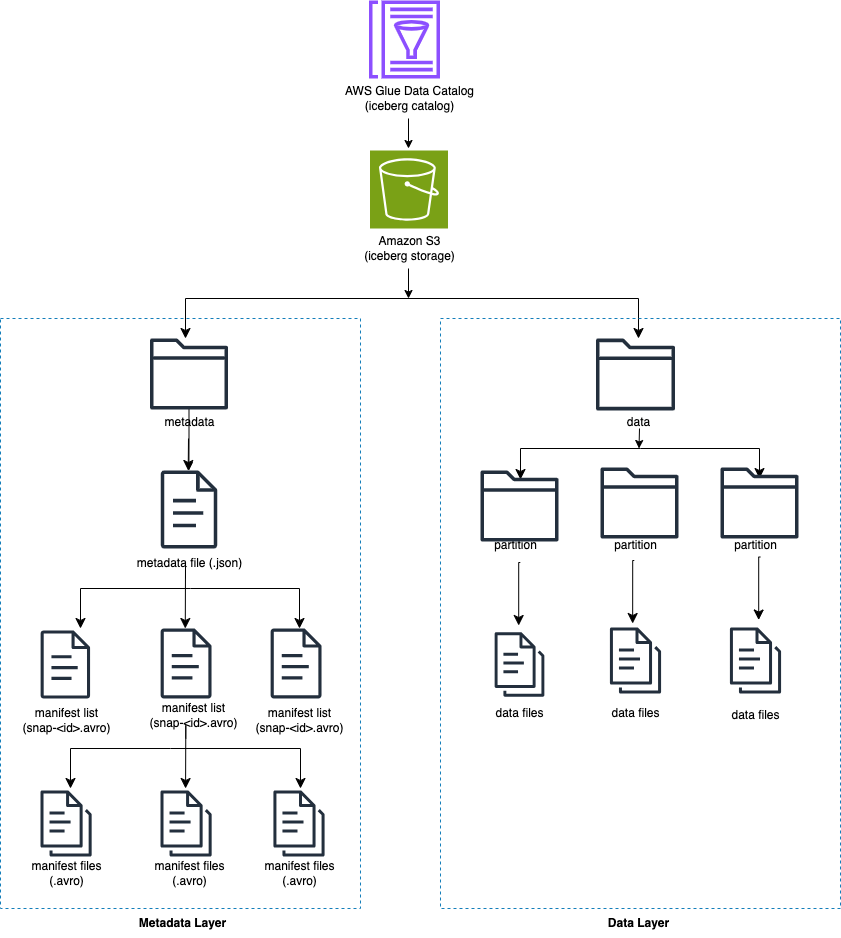
Wanneer u een ijsbergtabel maakt, wordt eerst de metagegevensmap gemaakt en een metagegevensbestand in de metagegevensmap. De gegevensmap wordt gemaakt wanneer u gegevens in de Iceberg-tabel laadt.

Inhoud van het Iceberg-metadatabestand
Het Iceberg-metagegevensbestand bevat veel informatie, waaronder de volgende:
- formaat-versie –Versie van de ijsbergtafel
- Locatie – Amazon S3-locatie van de tafel
- schema's – Naam en gegevenstype van alle kolommen in de tabel
- partitie-specificaties – Gepartitioneerde kolommen
- sorteervolgorde – Sorteervolgorde van kolommen
- vastgoed – Tabeleigenschappen
- huidige momentopname-id – Huidige momentopname
- scheidsrechters – Tabelreferenties
- snapshots – Lijst met snapshots, elk met de volgende informatie:
- volgnummer – Volgnummer van snapshots in chronologische volgorde (het hoogste nummer vertegenwoordigt de huidige snapshot, 1 voor de eerste snapshot)
- momentopname-id – Momentopname-ID
- tijdstempel-ms – Tijdstempel waarop de momentopname is vastgelegd
- beknopte versie – Samenvatting van de vastgelegde wijzigingen
- manifest-lijst – Lijst met manifesten; deze bestandsnaam begint met snap-<snapshot-id >
- schema-id – Volgnummer van het schema in chronologische volgorde (het hoogste getal vertegenwoordigt het huidige schema)
- momentopname-log – Lijst met momentopnamen in chronologische volgorde
- metadata-log – Lijst met metadatabestanden in chronologische volgorde
Het metadatabestand bevat alle historische wijzigingen in de gegevens en het schema van de tabel. Het rechtstreeks bekijken van de inhoud van het metabestandbestand kan een tijdrovende taak zijn. Gelukkig kunt u de IJsbergmetadata met behulp van Athena.
IJsbergframework in AWS Glue
AWS Glue 4.0 ondersteunt Iceberg-tabellen geregistreerd bij Lake Formation. In de AWS Glue ETL-taken hebt u de volgende code nodig schakel het Iceberg-framework in:
Voor lees-/schrijftoegang tot onderliggende gegevens werd, naast Lake Formation-machtigingen, de AWS Glue IAM-rol toegekend om de AWS Glue ETL-taken uit te voeren meervorming: GetDataAccess IAM-toestemming. Met deze toestemming willigt Lake Formation het verzoek in voor tijdelijke inloggegevens voor toegang tot de gegevens.
De CloudFormation-stack heeft de vier AWS Glue ETL-taken voor u ingericht. De naam van elke taak begint met uw stapelnaam (icebergdemo1). Voer de volgende stappen uit om de vacatures te bekijken:
- Log in als beheerder op uw AWS-account.
- Kies op de AWS Glue-console: ETL-banen in het navigatievenster.
- Zoek naar vacatures met
icebergdemo1in de naam.
Voeg gegevens uit Dropzone samen met de Iceberg-tabel
Voor ons gebruik neemt het bedrijf dagelijks de gegevens van hun e-commercebestellingen op van hun lokale locatie naar een Amazon S3 Dropzone-locatie. De CloudFormation-stack laadde drie bestanden met voorbeeldbestellingen gedurende drie dagen, zoals weergegeven in de volgende afbeeldingen. U ziet de gegevens op de Dropzone-locatie s3://icebergdemo1-s3bucketdropzone-kunftrcblhsk/data.
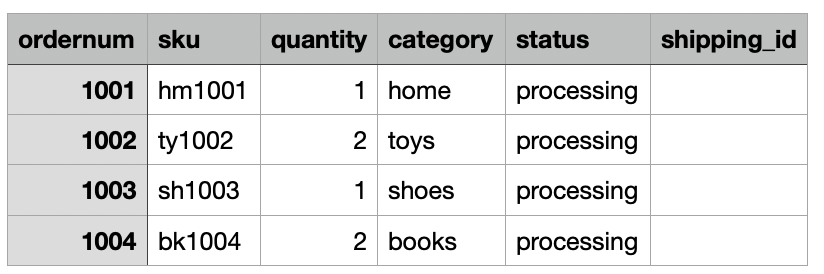


De AWS Glue ETL-taak icebergdemo1-GlueETL1-merge wordt dagelijks uitgevoerd om de gegevens samen te voegen met de ijsbergtabel. Het heeft de volgende logica om de gegevens op Iceberg toe te voegen of bij te werken:
- Maak een Spark DataFrame op basis van invoergegevens:
- Voor een nieuwe bestelling voegt u deze toe aan de tabel
- Als de tafel een overeenkomende volgorde heeft, update dan de status en
shipping_id:
Voer de volgende stappen uit om de AWS Glue-samenvoegtaak uit te voeren:
- Kies op de AWS Glue-console: ETL-banen in het navigatievenster.
- Selecteer de ETL-taak
icebergdemo1-GlueETL1-merge. - Op de Acties vervolgkeuzemenu, kies Uitvoeren met parameters.
- Op de Parameters uitvoeren pagina, ga naar Taakparameters.
- Voor de
--dropzone_pathparameter, geef de S3-locatie van de invoergegevens op (icebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge1). - Voer de taak uit om alle bestellingen toe te voegen: 1001, 1002, 1003 en 1004.
- Voor de
--dropzone_path parameter, wijzig de S3-locatie naaricebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge2. - Voer de taak opnieuw uit om orders 2001 en 2002 toe te voegen en orders 1001, 1002 en 1003 bij te werken.
- Voor de
--dropzone_pathparameter, wijzig de S3-locatie naaricebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge3. - Voer de taak opnieuw uit om order 3001 toe te voegen en orders 1001, 1003, 2001 en 2002 bij te werken.
Ga naar de gegevensmap van de tabel om de gegevensbestanden te bekijken die door Iceberg zijn geschreven toen u de gegevens in de tabel hebt samengevoegd met behulp van de Glue ETL-taak icebergdemo1-GlueETL1-merge.

Query Iceberg met behulp van Athena
De CloudFormation-stack heeft de IAM-gebruiker iceberguser1 gemaakt, die leestoegang heeft tot de Iceberg-tabel met behulp van LF-Tags. Om Iceberg te bevragen met Athena via deze gebruiker, voert u de volgende stappen uit:
- Inloggen als
iceberguser1aan de AWS-beheerconsole. - Kies op de Athena-console Werkgroepen in het navigatievenster.
- Zoek de werkgroep die CloudFormation heeft ingericht (
icebergdemo1-workgroup) - Controleer versie 3 van de Athena-motor.
De Athena-motorversie 3 ondersteunt IJsberg bestandsformaten, inclusief Parquet, ORC en Avro.
- Ga naar de Athena-queryeditor.
- Kies de werkgroep ijsbergdemo1-werkgroep in het vervolgkeuzemenu.
- Voor Database, kiezen
icebergdb1. Je zult de tafel zienecomorders. - Voer de volgende query uit om de gegevens in de ijsbergtabel te bekijken:
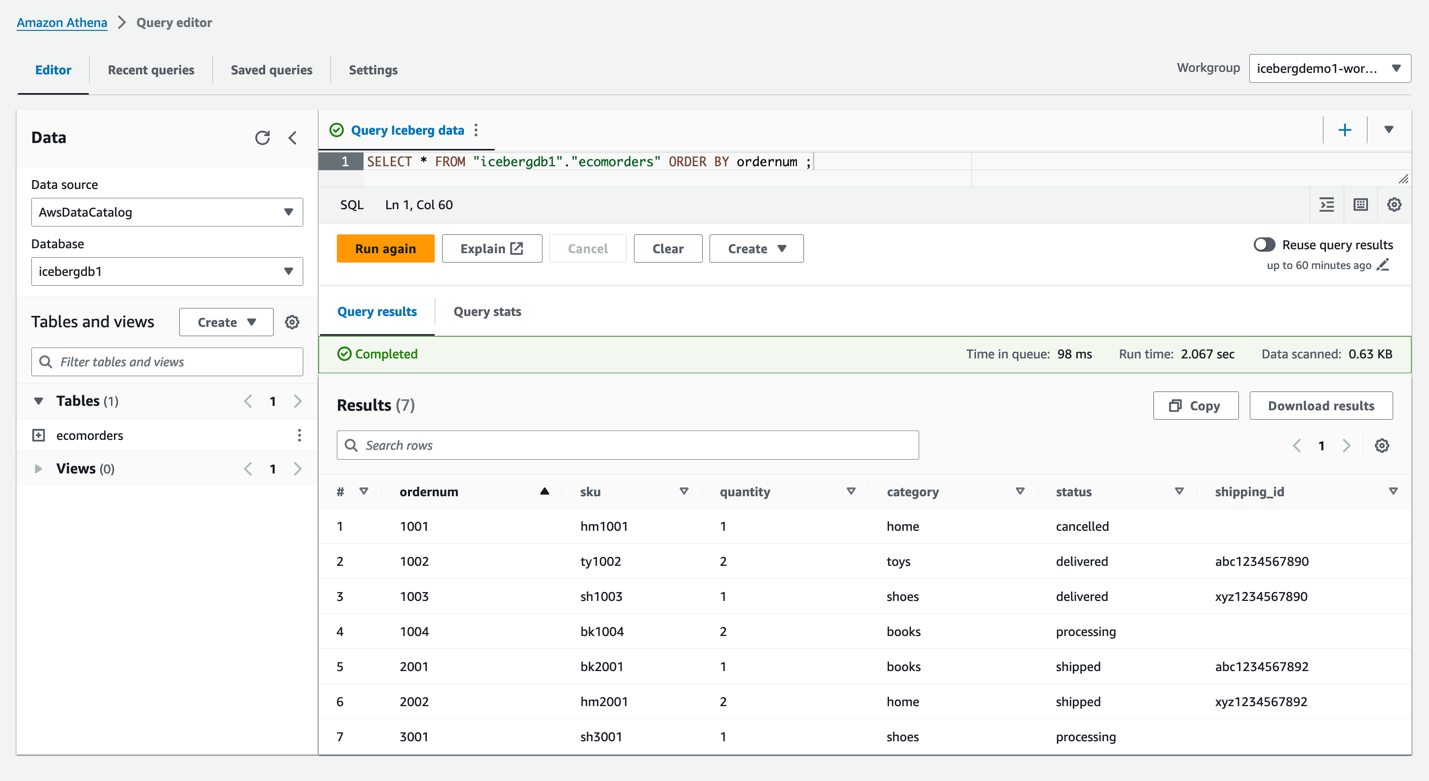
- Voer de volgende query uit om de huidige partities van de tabel te bekijken:
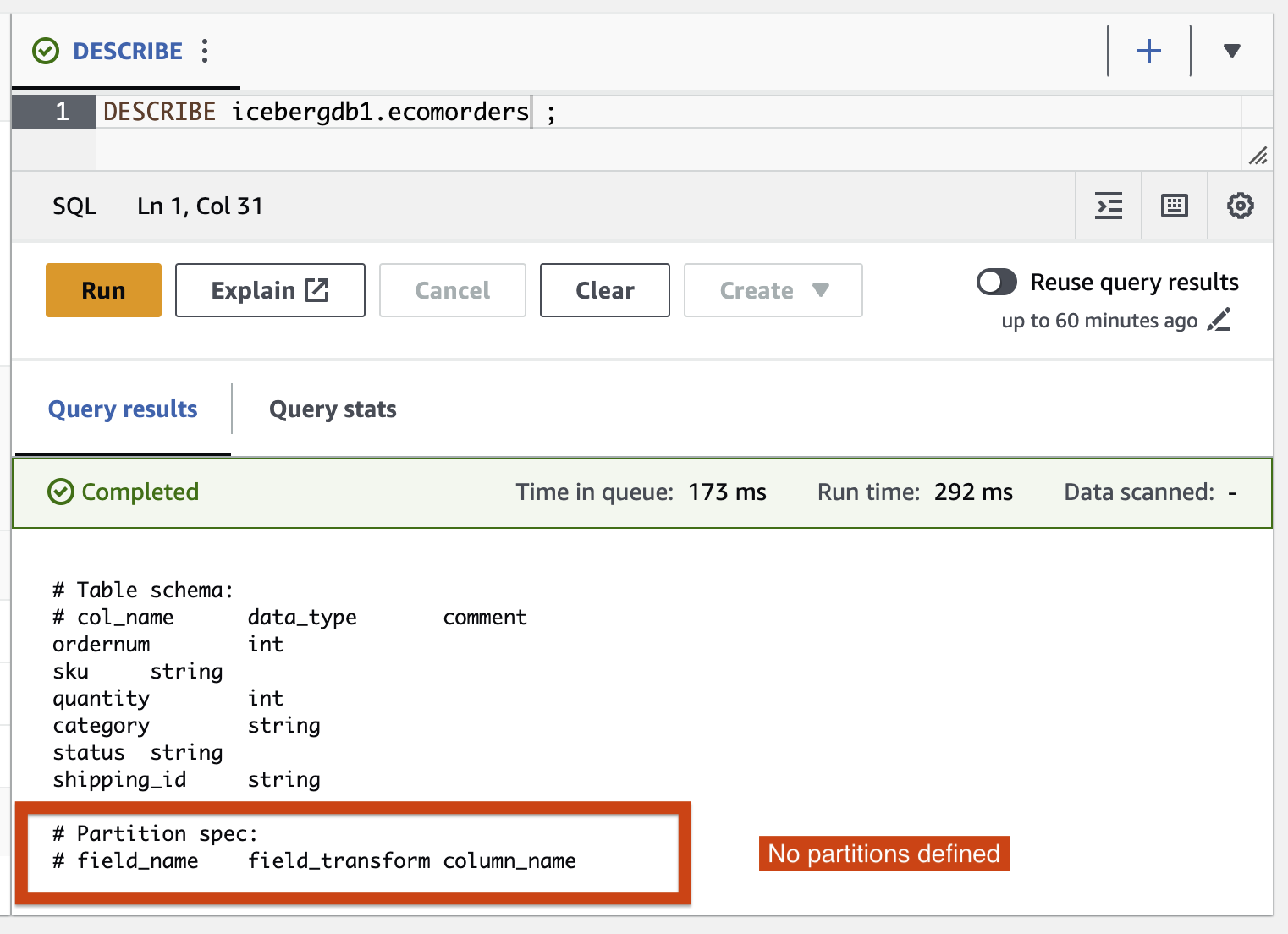
Partition-spec beschrijft hoe de tabel is gepartitioneerd. In dit voorbeeld zijn er geen gepartitioneerde velden omdat u geen partities in de tabel hebt gedefinieerd.
Evolutie van ijsbergpartities
Mogelijk moet u uw partitiestructuur wijzigen; bijvoorbeeld als gevolg van trendveranderingen van algemene zoekpatronen in downstream-analyses. Een wijziging van de partitiestructuur voor traditionele tabellen is een aanzienlijke operatie waarvoor een volledige gegevenskopie nodig is.
Iceberg maakt dit eenvoudig. Wanneer u de partitiestructuur op Iceberg wijzigt, hoeft u de gegevensbestanden niet te herschrijven. De oude gegevens die met eerdere partities zijn geschreven, blijven ongewijzigd. Nieuwe gegevens worden geschreven met behulp van de nieuwe specificaties in een nieuwe lay-out. Metagegevens voor elk van de partitieversies worden afzonderlijk bewaard.
Laten we de partitieveldcategorie toevoegen aan de Iceberg-tabel met behulp van de AWS Glue ETL-taak icebergdemo1-GlueETL2-partition-evolution:
Voer de ETL-taak uit op de AWS Glue-console icebergdemo1-GlueETL2-partition-evolution. Wanneer de taak is voltooid, kunt u partities opvragen met Athena.
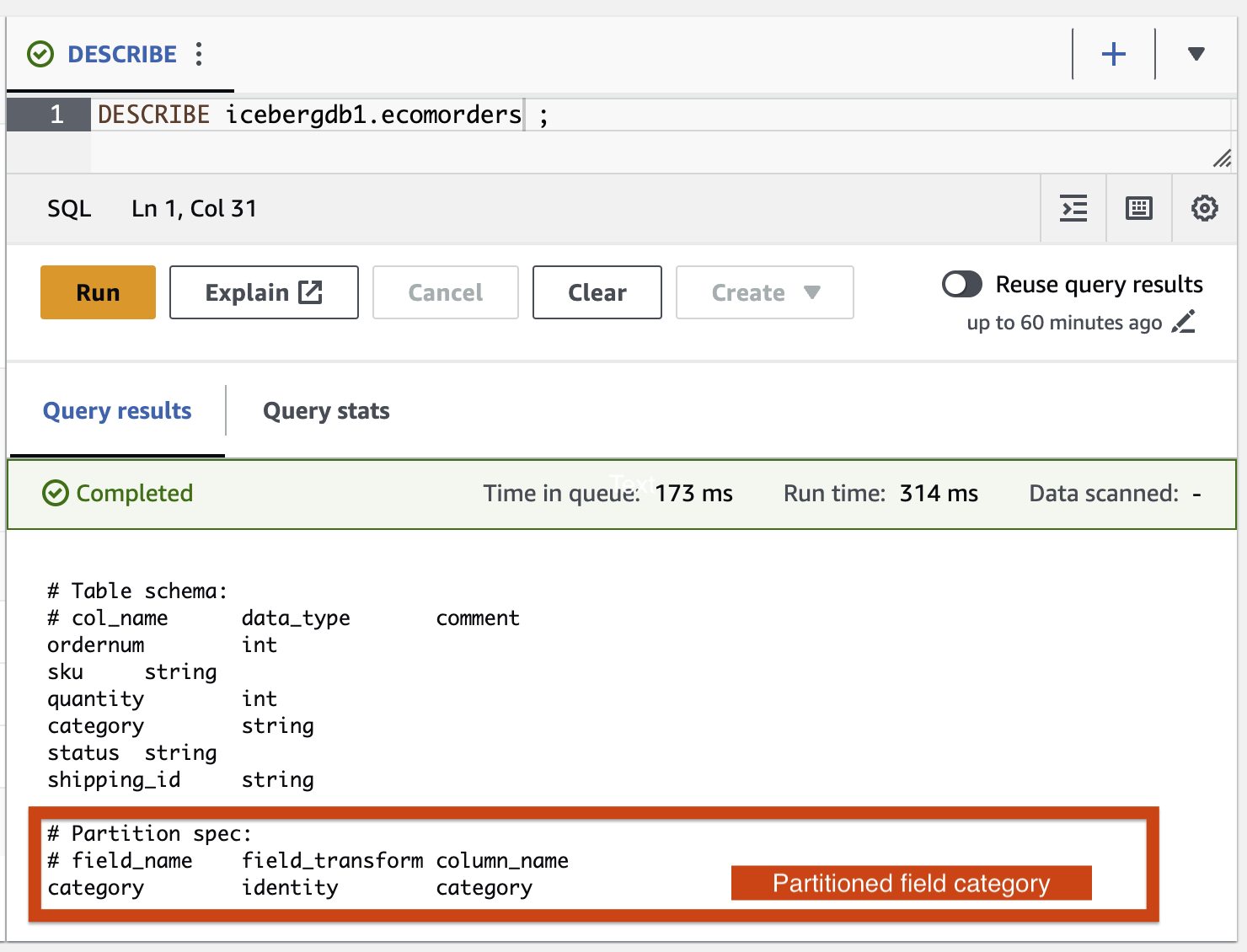
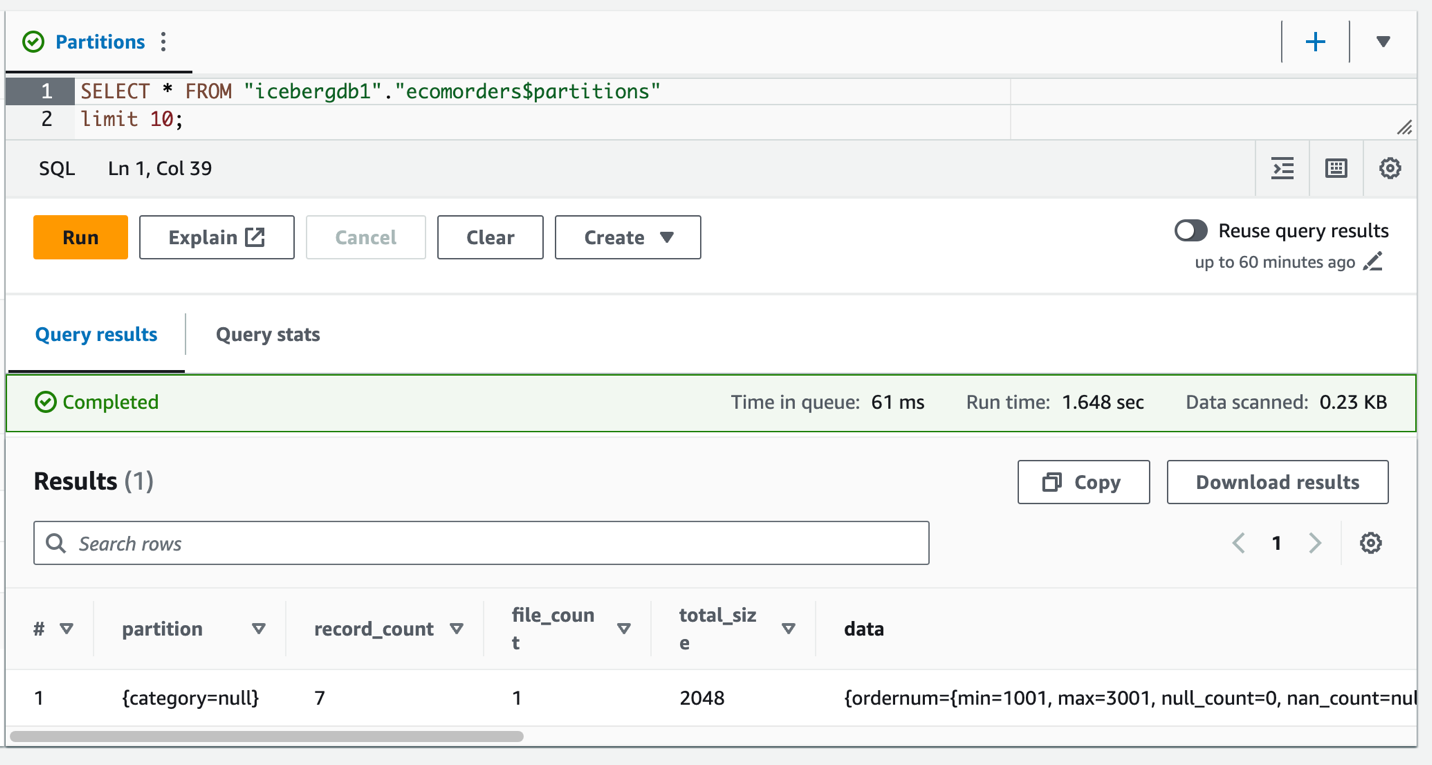
U kunt de categorie van het partitieveld zien, maar de partitiewaarden zijn nul. Er zijn geen nieuwe gegevensbestanden in de gegevensmap, omdat partitie-evolutie een metagegevensbewerking is en gegevensbestanden niet herschrijft. Wanneer u gegevens toevoegt of bijwerkt, ziet u dat de overeenkomstige partitiewaarden worden ingevuld.
Evolutie van het ijsbergschema
Iceberg ondersteunt interne tafelevolutie. Jij kan een tabelschema ontwikkelen net als SQL. IJsberg-schema-updates zijn wijzigingen in de metagegevens, dus er hoeven geen gegevensbestanden te worden herschreven om de schema-evolutie uit te voeren.
Voer de ETL-taak uit om de evolutie van het ijsbergschema te verkennen icebergdemo1-GlueETL3-schema-evolution via de AWS Glue-console. De taak voert de volgende SparkSQL-instructies uit:
Voer in de Athena-query-editor de volgende query uit:

U kunt de schemawijzigingen in de ijsbergtabel verifiëren:
- Er is een nieuwe kolom toegevoegd genaamd
shipping_carrier - De kolom
shipping_idis hernoemd naartracking_number - Het gegevenstype van de kolom
ordernumis veranderd van int naar bigint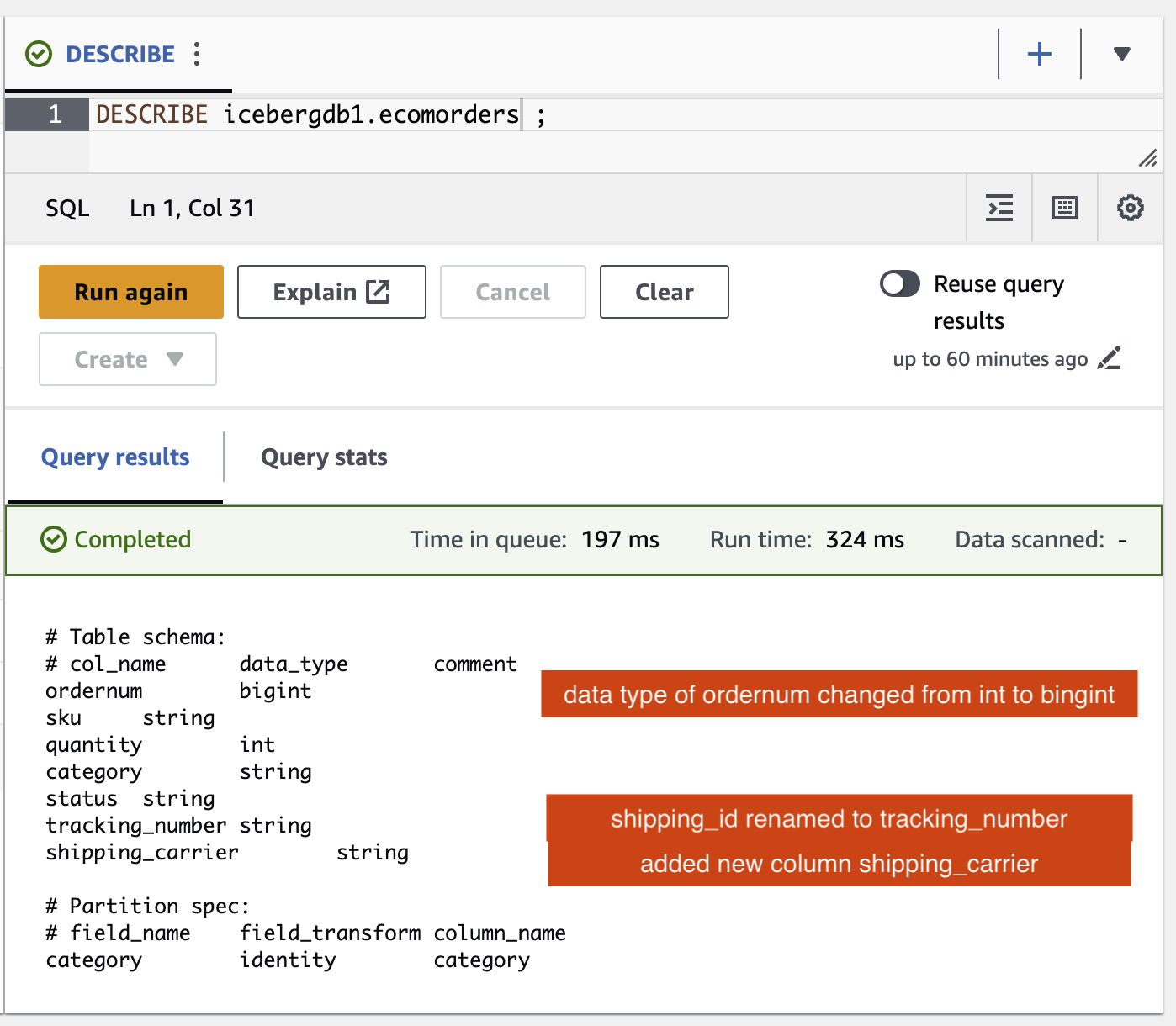
Positionele update
De gegevens binnen tracking_number bevat de vervoerder, samengevoegd met het trackingnummer. Laten we aannemen dat we deze gegevens willen splitsen om de vervoerder in de shipping_carrier veld en het trackingnummer in het tracking_number veld.
Voer de ETL-taak uit op de AWS Glue-console icebergdemo1-GlueETL4-update-table. De taak voert de volgende SparkSQL-instructie uit om de tabel bij te werken:
Voer een query uit op de Iceberg-tabel om de bijgewerkte gegevens te verifiëren tracking_number en shipping_carrier.
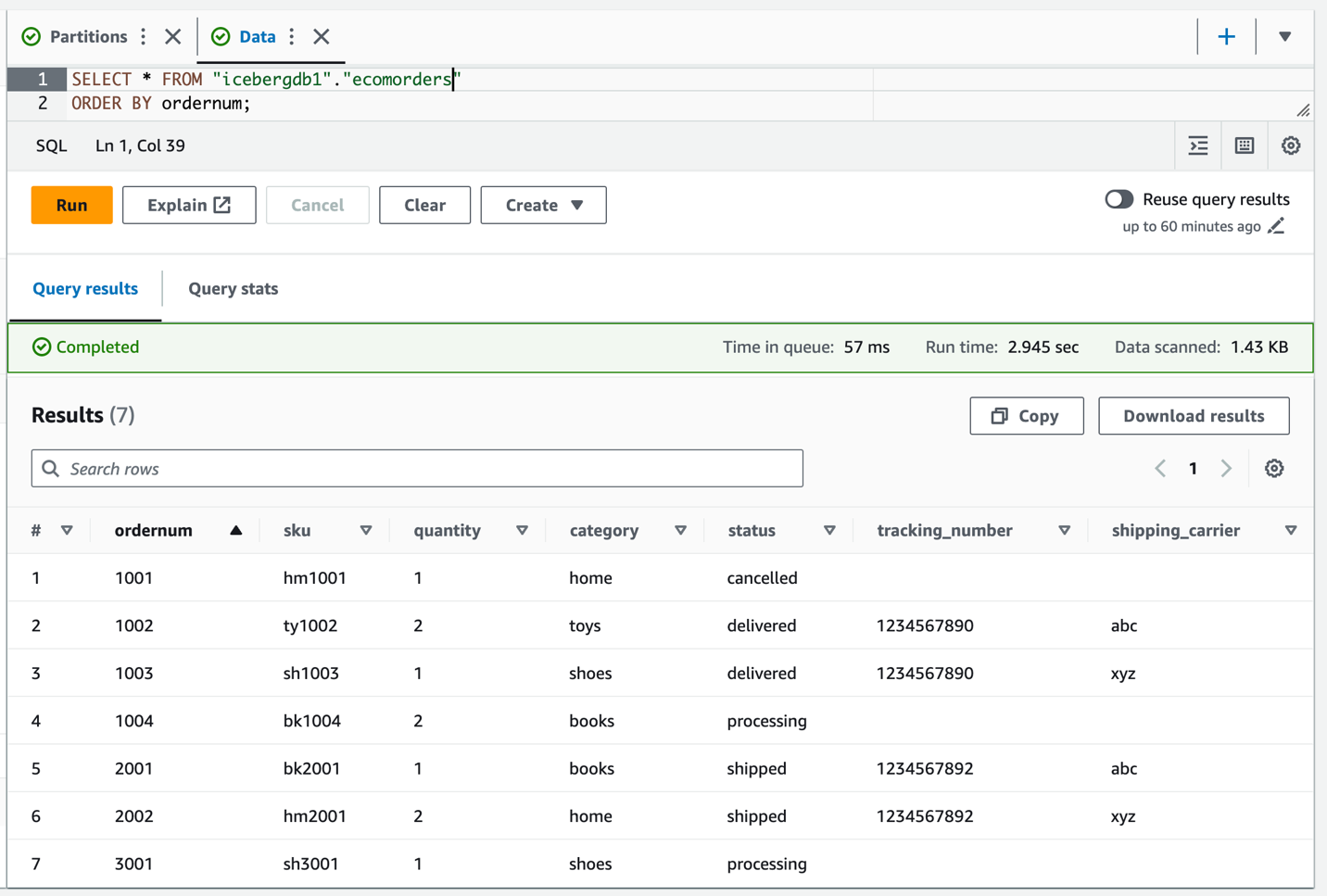
Nu de gegevens in de tabel zijn bijgewerkt, zouden de partitiewaarden voor categorie moeten zijn ingevuld:

Opruimen
Om toekomstige kosten te voorkomen, ruimt u de bronnen op die u heeft gemaakt:
- Open op de Lambda-console de detailpagina voor de functie
icebergdemo1-Lambda-Create-Iceberg-and-Grant-access. - In het Omgevingsvariabelen sectie, kies de sleutel
Task_To_Performen update de waarde naarCLEANUP. - Voer de functie uit, waardoor de database, de tabel en de bijbehorende LF-Tags worden verwijderd.
- Verwijder op de AWS CloudFormation-console de stack icebergdemo1.
Conclusie
In dit bericht heb je een Iceberg-tabel gemaakt met behulp van de AWS Glue API en Lake Formation gebruikt om de toegang tot de Iceberg-tabel in een transactioneel datameer te controleren. Met AWS Glue ETL-taken voegde u gegevens samen in de Iceberg-tabel en voerde u schema-evolutie en partitie-evolutie uit zonder de Iceberg-tabel te herschrijven of opnieuw te maken. Met Athena hebt u de gegevens en metagegevens van de ijsberg opgevraagd.
Op basis van de concepten en demonstraties uit dit bericht kunt u nu een transactioneel datameer in een onderneming bouwen met behulp van Iceberg, AWS Glue, Lake Formation en Amazon S3.
Over de auteur
 Satya Adimula is een Senior Data Architect bij AWS, gevestigd in Boston. Met meer dan twintig jaar ervaring in data en analytics helpt Satya organisaties om op grote schaal zakelijke inzichten uit hun data te halen.
Satya Adimula is een Senior Data Architect bij AWS, gevestigd in Boston. Met meer dan twintig jaar ervaring in data en analytics helpt Satya organisaties om op grote schaal zakelijke inzichten uit hun data te halen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/use-aws-glue-etl-to-perform-merge-partition-evolution-and-schema-evolution-on-apache-iceberg/

