Machine learning-modellen zijn een integraal onderdeel geworden van de besluitvorming in meerdere sectoren, maar toch stuiten ze vaak op problemen bij het omgaan met luidruchtige of diverse datasets. Dat is waar Ensembleleren om de hoek komt kijken.
Dit artikel zal het leren van ensembles ontrafelen en je kennis laten maken met het krachtige willekeurige bosalgoritme. Of u nu een datawetenschapper bent die uw toolkit wil aanscherpen of een ontwikkelaar die op zoek is naar praktische inzichten in het bouwen van robuuste machine learning-modellen, dit stuk is voor iedereen bedoeld!
Aan het einde van dit artikel zul je een grondige kennis verwerven van Ensemble Learning en hoe Random Forests in Python werken. Dus of u nu een ervaren datawetenschapper bent of gewoon nieuwsgierig bent om uw vaardigheden op het gebied van machine learning uit te breiden, ga met ons mee op dit avontuur en vergroot uw expertise op het gebied van machine learning!
Ensemble learning is een machine learning-aanpak waarbij voorspellingen van meerdere zwakke modellen met elkaar worden gecombineerd om sterkere voorspellingen te krijgen. Het concept achter ensembleleren is het verminderen van de vooroordelen en fouten van afzonderlijke modellen door gebruik te maken van de voorspellende kracht van elk model.
Laten we, om een beter voorbeeld te krijgen, een levensvoorbeeld nemen. Stel je voor dat je een dier hebt gezien en je weet niet tot welke soort dit dier behoort. Dus in plaats van het aan één deskundige te vragen, vraagt u het aan tien deskundigen en krijgt u de stem van de meerderheid van hen. Dit staat bekend als harde stemming.
Moeilijk stemmen is wanneer we rekening houden met de klassevoorspellingen voor elke classificator en vervolgens een invoer classificeren op basis van de maximale stemmen voor een bepaalde klasse. Aan de andere kant, zacht stemmen is wanneer we rekening houden met de waarschijnlijkheidsvoorspellingen voor elke klasse door elke classificator en vervolgens een invoer voor de klasse classificeren met maximale waarschijnlijkheid op basis van de gemiddelde waarschijnlijkheid (gemiddeld over de kansen van de classificator) voor die klasse.
Ensemble-leren wordt altijd gebruikt om de modelprestaties te verbeteren, waaronder het verbeteren van de classificatienauwkeurigheid en het verlagen van de gemiddelde absolute fout voor regressiemodellen. Bovendien leveren ensembleleerlingen altijd een stabieler model op. Ensemble-leerlingen werken op hun best als de modellen niet gecorreleerd zijn. Elk model kan dan iets unieks leren en werken aan het verbeteren van de algehele prestaties.
Hoewel ensembleleren op veel manieren kan worden toegepast, zijn er, als het gaat om de toepassing ervan in de praktijk, drie strategieën die veel populariteit hebben gewonnen vanwege hun eenvoudige implementatie en gebruik. Deze drie strategieën zijn:
- bagging: Bagging, wat een afkorting is van bootstrap-aggregatie, is een ensemble-leerstrategie waarbij de modellen worden getraind met behulp van willekeurige steekproeven uit de dataset.
- stapelen: Stapelen, wat een afkorting is voor gestapelde generalisatie, is een ensemble-leerstrategie waarbij we een model trainen om meerdere modellen te combineren die op onze gegevens zijn getraind.
- Het stimuleren van: Boosting is een ensemble-leertechniek die zich richt op het selecteren van de verkeerd geclassificeerde gegevens waarop de modellen moeten worden getraind.
Laten we dieper ingaan op elk van deze strategieën en kijken hoe we Python kunnen gebruiken om deze modellen op onze dataset te trainen.
Bagging neemt willekeurige gegevensmonsters en maakt gebruik van leeralgoritmen en middelen om de kansen op bagging te vinden; ook bekend als bootstrap-aggregatie; het verzamelt resultaten uit meerdere modellen om één brede uitkomst te krijgen.
Deze aanpak omvat:
- Het opsplitsen van de originele dataset in meerdere subsets met vervanging.
- Ontwikkel basismodellen voor elk van deze subsets.
- Alle modellen gelijktijdig uitvoeren voordat alle voorspellingen worden uitgevoerd om definitieve voorspellingen te verkrijgen.
Scikit leren biedt ons de mogelijkheid om zowel a BaggingClassifier en BaggingRegressor. Een BaggingMetaEstimator identificeert willekeurige subsets van een originele dataset die bij elk basismodel passen en voegt vervolgens individuele basismodelvoorspellingen (door middel van stemmen of middelen) samen tot een uiteindelijke voorspelling door individuele basismodelvoorspellingen samen te voegen tot een geaggregeerde voorspelling met behulp van stemmen of middelen. . Deze methode vermindert de variantie door het constructieproces te randomiseren.
Laten we een voorbeeld nemen waarin we de bagging-schatter gebruiken met behulp van scikit learn:
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bagging = BaggingClassifier(base_estimator=DecisionTreeClassifier(),n_estimators=10, max_samples=0.5, max_features=0.5)
De zakclassificator houdt rekening met verschillende parameters:
- basisschatter: Het basismodel dat wordt gebruikt bij de opzakkingsaanpak. Hier gebruiken we de beslisboomclassificator.
- n_schatters: Het aantal schatters dat we zullen gebruiken bij de opzakkingsaanpak.
- max_monsters: het aantal steekproeven dat voor elke basisschatter uit de trainingsset wordt getrokken.
- max_functies: Het aantal functies dat wordt gebruikt om elke basisschatter te trainen.
Nu passen we deze classificator op de trainingsset en scoren deze.
bagging.fit(X_train, y_train)
bagging.score(X_test,y_test)
Hetzelfde kunnen we doen voor regressietaken, met het verschil dat we in plaats daarvan regressieschatters gaan gebruiken.
from sklearn.ensemble import BaggingRegressor
bagging = BaggingRegressor(DecisionTreeRegressor())
bagging.fit(X_train, y_train)
model.score(X_test,y_test)Stapelen is een techniek voor het combineren van meerdere schatters om hun vertekeningen te minimaliseren en nauwkeurige voorspellingen te produceren. Voorspellingen van elke schatter worden vervolgens gecombineerd en ingevoerd in een ultiem voorspellingsmetamodel dat is getraind door middel van kruisvalidatie; stapelen kan worden toegepast op zowel classificatie- als regressieproblemen.
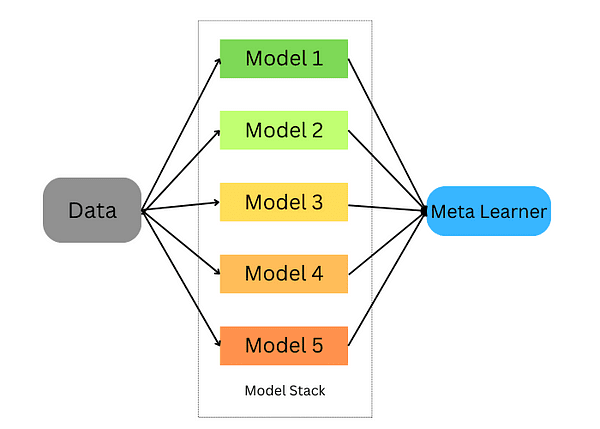
Samenspelleren stapelen
Het stapelen gebeurt in de volgende stappen:
- Splits de gegevens op in een trainings- en validatieset
- Verdeel de trainingsset in K-plooien
- Train een basismodel op k-1-vouwen en doe voorspellingen over de k-de vouw
- Herhaal dit totdat je een voorspelling voor elke vouw hebt
- Monteer het basismodel op de hele trainingsset
- Gebruik het model om voorspellingen te doen op de testset
- Herhaal stap 3 t/m 6 voor andere basismodellen
- Gebruik voorspellingen uit de testset als kenmerken van een nieuw model (het metamodel)
- Maak definitieve voorspellingen over de testset met behulp van het metamodel
In dit voorbeeld hieronder beginnen we met het maken van twee basisclassifiers (RandomForestClassifier en GradientBoostingClassifier) en één meta-classifier (LogisticRegression) en gebruiken we K-voudige kruisvalidatie om voorspellingen van deze classifiers te gebruiken op trainingsgegevens (iris-dataset) voor invoerfuncties voor onze meta-classificator (LogisticRegression).
Na het gebruik van K-voudige kruisvalidatie om voorspellingen te doen op basis van de basisclassificatoren op testgegevenssets als invoerfuncties voor onze meta-classificator, worden voorspellingen over testsets gemaakt door beide sets samen te gebruiken en hun nauwkeurigheid te vergelijken met hun gestapelde ensemble-tegenhangers.
# Load the dataset
data = load_iris()
X, y = data.data, data.target # Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Define base classifiers
base_classifiers = [ RandomForestClassifier(n_estimators=100, random_state=42), GradientBoostingClassifier(n_estimators=100, random_state=42)
] # Define a meta-classifier
meta_classifier = LogisticRegression() # Create an array to hold the predictions from base classifiers
base_classifier_predictions = np.zeros((len(X_train), len(base_classifiers))) # Perform stacking using K-fold cross-validation
kf = KFold(n_splits=5, shuffle=True, random_state=42)
for train_index, val_index in kf.split(X_train): train_fold, val_fold = X_train[train_index], X_train[val_index] train_target, val_target = y_train[train_index], y_train[val_index] for i, clf in enumerate(base_classifiers): cloned_clf = clone(clf) cloned_clf.fit(train_fold, train_target) base_classifier_predictions[val_index, i] = cloned_clf.predict(val_fold) # Train the meta-classifier on base classifier predictions
meta_classifier.fit(base_classifier_predictions, y_train) # Make predictions using the stacked ensemble
stacked_predictions = np.zeros((len(X_test), len(base_classifiers)))
for i, clf in enumerate(base_classifiers): stacked_predictions[:, i] = clf.predict(X_test) # Make final predictions using the meta-classifier
final_predictions = meta_classifier.predict(stacked_predictions) # Evaluate the stacked ensemble's performance
accuracy = accuracy_score(y_test, final_predictions)
print(f"Stacked Ensemble Accuracy: {accuracy:.2f}")Boosting is een machinaal lerende ensembletechniek die vooroordelen en variantie vermindert door van zwakke leerlingen sterke leerlingen te maken. Deze zwakke leerlingen worden opeenvolgend op de dataset toegepast; ten eerste door een eerste model te maken en dit aan de trainingsset toe te passen. Zodra fouten uit het eerste model zijn geïdentificeerd, wordt een ander model ontworpen om deze te corrigeren.
Er zijn populaire algoritmen en implementaties voor het stimuleren van ensemble-leertechnieken. Laten we de bekendste verkennen.
6.1. AdaBoost
AdaBoost is een effectieve ensemble-leertechniek, waarbij zwakke leerlingen opeenvolgend worden ingezet voor trainingsdoeleinden. Elke iteratie geeft prioriteit aan onjuiste voorspellingen, terwijl het gewicht wordt verlaagd dat wordt toegewezen aan correct voorspelde gevallen; deze strategische nadruk op uitdagende observaties dwingt AdaBoost om in de loop van de tijd steeds nauwkeuriger te worden, waarbij de uiteindelijke voorspelling wordt bepaald door het samenvoegen van meerderheidsstemmen of de gewogen som van zijn zwakke leerlingen.
AdaBoost is een veelzijdig algoritme dat geschikt is voor zowel regressie- als classificatietaken, maar hier concentreren we ons op de toepassing ervan op classificatieproblemen met behulp van Scikit-learn. Laten we in het onderstaande voorbeeld bekijken hoe we het kunnen gebruiken voor classificatietaken:
from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier(n_estimators=100)
model.fit(X_train, y_train)
model.score(X_test,y_test)
In dit voorbeeld hebben we de AdaBoostClassifier van scikit learn gebruikt en de n_estimators ingesteld op 100. De standaard learn is een beslissingsboom en u kunt deze wijzigen. Daarnaast kunnen de parameters van de beslisboom worden afgestemd.
2. EXtreme gradiëntversterking (XGBoost)
eXtreme Gradient Boosting, of beter bekend als XGBoost, is een van de beste implementaties voor het stimuleren van ensemble-leerlingen vanwege de parallelle berekeningen, waardoor het zeer geoptimaliseerd is om op één computer te draaien. XGBoost is beschikbaar voor gebruik via het xgboost-pakket dat is ontwikkeld door de machine learning-gemeenschap.
import xgboost as xgb
params = {"objective":"binary:logistic",'colsample_bytree': 0.3,'learning_rate': 0.1, 'max_depth': 5, 'alpha': 10}
model = xgb.XGBClassifier(**params)
model.fit(X_train, y_train)
model.fit(X_train, y_train)
model.score(X_test,y_test)3. LichtGBM
LightGBM is een ander gradiëntverhogend algoritme dat is gebaseerd op boomleren. Het verschilt echter van andere op bomen gebaseerde algoritmen doordat het gebruik maakt van bladgewijze boomgroei, waardoor het sneller convergeert.
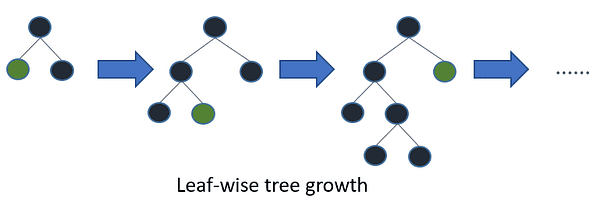
Bladgewijze boomgroei / Afbeelding door LichtGBM
In het onderstaande voorbeeld passen we LightGBM toe op een binair classificatieprobleem:
import lightgbm as lgb
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
params = {'boosting_type': 'gbdt', 'objective': 'binary', 'num_leaves': 40, 'learning_rate': 0.1, 'feature_fraction': 0.9 }
gbm = lgb.train(params, lgb_train, num_boost_round=200, valid_sets=[lgb_train, lgb_eval], valid_names=['train','valid'], )
Ensemble learning en willekeurige forests zijn krachtige machine learning-modellen die altijd worden gebruikt door beoefenaars van machine learning en datawetenschappers. In dit artikel hebben we de basisintuïtie erachter besproken, wanneer we ze moeten gebruiken, en ten slotte hebben we de meest populaire algoritmen besproken en hoe we ze in Python kunnen gebruiken.
Youssef Rafaat is een computer vision-onderzoeker en datawetenschapper. Zijn onderzoek richt zich op het ontwikkelen van real-time computer vision-algoritmen voor toepassingen in de gezondheidszorg. Hij werkte ook meer dan 3 jaar als datawetenschapper in het domein van marketing, financiën en gezondheidszorg.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://www.kdnuggets.com/ensemble-learning-techniques-a-walkthrough-with-random-forests-in-python?utm_source=rss&utm_medium=rss&utm_campaign=ensemble-learning-techniques-a-walkthrough-with-random-forests-in-python

