Introductie
Voor Wordle Sudoku puzzel was de rage en het is nog steeds erg populair. De laatste jaren is het gebruik van optimalisatie methoden om de puzzel op te lossen is een dominant thema geweest. Zien “Sudoku-puzzel oplossen met behulp van optimalisatie in Arkieva'.
Tegenwoordig is het gebruik van kunstmatige intelligentie (AI) gericht op machinaal leren, dat een breed scala aan methoden omvat, van lasso-regressie tot versterkend leren. Het gebruik van AI heeft opnieuw opgekomen complex aan te pakken scheduling uitdagingen. Eén methode, zoeken met backtracking, wordt veel gebruikt en is perfect voor Sudoku.
Deze blog geeft een gedetailleerde beschrijving van hoe u deze methode kunt gebruiken om Sudoku op te lossen. Het blijkt dat ‘backtracking’ te vinden is in optimalisatie- en machine learning-engines en een hoeksteen is van de geavanceerde heuristieken die Arkieva gebruikt voor planning. Het algoritme is geïmplementeerd in een ‘Array Programming Language’, een functiegerichte programmeertaal die a rijke reeks arraystructuren.
Basisprincipes van Sudoku
Van Wikipedia: Sudoku is een op logica gebaseerde, combinatorische puzzel voor het plaatsen van getallen. Het doel is om een 9×9-raster met cijfers te vullen, zodat elke kolom, elke rij en elk van de negen 3×3-subrasters waaruit het raster bestaat (ook wel ‘vakken’, ‘blokken’, ‘regio’s’ genoemd) of “subvierkanten”) bevat alle cijfers van 1 tot en met 9. De puzzelzetter biedt een gedeeltelijk voltooid raster, dat doorgaans een unieke oplossing heeft. Voltooide puzzels zijn altijd een soort Latijns vierkant met een extra beperking op de inhoud van individuele regio's. Hetzelfde gehele getal mag bijvoorbeeld niet twee keer voorkomen in dezelfde rij of kolom van 9×9 speelborden of in een van de negen 3×3 subregio's van het 9×9 speelbord.
Tabel 1 bevat een voorbeeldprobleem. Er zijn 9 rijen en 9 kolommen voor een totaal van 81 cellen. Elke cel mag één en slechts één van de negen gehele getallen tussen 1 en 9 hebben. In de startoplossing heeft een cel óf één enkele waarde – waardoor de waarde in deze cel op die waarde wordt vastgelegd, óf de cel is leeg, wat aangeeft dat we om een waarde voor deze cel te vinden. De cel (1,1) heeft de waarde 2 en cel (6,5) heeft de waarde 6. Cel (1,2) en cel (2,3) zijn leeg en het algoritme zal een waarde voor deze cellen vinden.

De complicatie
Naast dat een cel tot slechts één rij en kolom behoort, behoort een cel tot slechts één vakje. Er zijn 1 vakjes en deze worden in Tabel 9 met kleur aangegeven. Tabel 1 gebruikt een uniek geheel getal tussen 2 en 1 om elk vakje of raster te identificeren. De cellen met een rijwaarde van (9, 1 of 2) en kolomwaarde van (3, 1 of 2) behoren tot vak 3. Vak 1 zijn rijwaarden van (6, 4, 5) en kolomwaarden (6, 7). , 8). De doos-ID wordt bepaald door de formule BOX_ID = {9x(vloer((ROW_ID-3) /1)} + plafond (COL_ID/3). Voor de cel (3), 5,7 = 6x(vloer(3-5 ))/1) + plafond (3/8)= 3×3 + 1 = 3+3.

Het hart van de puzzel
Om voor elke onbekende cel één geheel getal tussen 1 en 9 te vinden, zodat de gehele getallen 1 tot en met 9 slechts één keer worden gebruikt voor elke kolom, elke rij en elk vak.
Laten we naar cel (1,3) kijken, die leeg is. Rij 1 bevat al de waarden 2 en 7. Deze zijn in deze cel niet toegestaan. Kolom 3 heeft al de waarden 3, 5,6, 7,9. Deze zijn niet toegestaan. Vak 1 (geel) heeft de waarden 2, 3 en 8. Deze zijn niet toegestaan. De volgende waarden zijn niet toegestaan (2,7); (3, 5, 6, 7, 9); (2, 3, 8). De unieke waarden die niet zijn toegestaan, zijn (2, 3, 5, 6, 7, 8, 9). De enige kandidaatwaarden zijn (1,4).
Een oplossingsbenadering zou zijn om tijdelijk 1 toe te wijzen aan cel (1,3) en vervolgens te proberen kandidaatwaarden voor een andere cel te vinden.
Een backtracking-oplossing: startcomponenten
Arraystructuur
Het beginpunt is het bepalen van een arraystructuur om het bronprobleem op te slaan en de zoekactie te ondersteunen. Tabel 3 heeft deze arraystructuur. Kolom 1 is een uniek geheel getal-ID voor elke cel. De waarden variëren van 1 tot 81. Kolom 2 is de rij-ID van de cel. Kolom 3 is de kolom-ID van de cel. Kolom 4 is de box-ID. Kolom 5 is de waarde in de cel. Observeer dat een cel zonder waarde de waarde nul krijgt in plaats van blanco of null. Hierdoor blijft dit een “array met alleen gehele getallen” – veel beter qua prestaties.

In APL zou deze array worden opgeslagen in een tweedimensionale array waarbij de vorm 2 bij 81 is. Neem aan dat de elementen van Tabel 5 zijn opgeslagen in de variabele MAT. Voorbeeldfuncties zijn:
Het commando MAT[1 2 3;]pakt de eerste 3 rijen MAT
1 1 1 1 2
2 1 2 1 0
3 1 3 1 0
MAT[1 2 3; 4 5] beveiligt rijen 1, 2, 3 en alleen kolommen 4 en 5
1
1
1
(MAT[;5]=0)/MAT[;1] vindt alle cellen die een waarde nodig hebben.
PLAATS TABEL 3
Gezondheidscontrole: duplicaten
Voordat u met zoeken begint, is het van cruciaal belang dat u uw gezondheid controleert! Dat is de haalbare startoplossing. Haalbaar voor Sudoku is dat er nu duplicaten in elke rij, kolom of vak staan. De huidige startoplossing, bijvoorbeeld 1, is haalbaar. Tabel 4 geeft een voorbeeld waarbij de uitgangsoplossing duplicaten heeft. Rij 1 heeft twee waarden 2. Gebied 1 heeft twee waarden 2. De functie “SANITY_DUPE” verwerkt deze logica.

Sanity Check: opties voor cellen zonder waarden
Een zeer nuttig stukje informatie zijn alle mogelijke waarden voor een cel zonder waarde. Als er geen kandidaten zijn, is deze puzzel niet oplosbaar. Een cel kan geen waarde aannemen die al door zijn buurman is geclaimd. Gebruik tabel 1 voor cel (1,3,'1' – deze laatste 1 is de boxid), de buren zijn rij 1, kolom 3 en box 1. Rij 1 heeft de waarden (2,7); kolom 3 heeft de waarden (3,5,6,7,9); vak 1 heeft de waarden (2,3,8). Cel (1,3.1) kan de volgende waarden (2,3,5,6,7,8,9) niet aannemen. De enige opties voor cel (1,3,1) zijn (1,4). Voor cel (4,1,2) worden de waarden 1, 2, 3, 5, 6, 7, 9 al gebruikt in rij 4, kolom 1 en/of vak 4. De enige kandidaatwaarden zijn (4,8) . De unctie “SANITY_CAND” verwerkt deze logica.
Tabel 5 toont de kandidaten, bijvoorbeeld 1 aan het begin van het zoekproces. Als aan een cel in de startvoorwaarden (Tabel 1) al een waarde is toegekend, wordt deze waarde herhaald en in rood weergegeven. Als een cel die een waarde nodig heeft slechts één optie heeft, wordt dit in het wit weergegeven. Cel (8,7,9) heeft de enkele waarde 7 in het wit. (2,5,8,4,3) worden geclaimd door aangrenzende kolom 7. (1, 2, 9) door rij 8. (3,2,6) door vak 9. Alleen de waarde 7 wordt niet geclaimd.
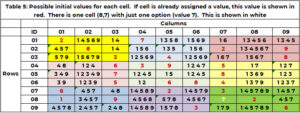
Sanity Check: op zoek naar conflicten
De informatie die alle opties identificeert voor cellen die een waarde nodig hebben (geplaatst in Tabel 4), stelt ons in staat een conflict te identificeren voordat het zoekproces wordt gestart. Er ontstaat een conflict wanneer twee cellen die een waarde nodig hebben slechts één kandidaat hebben, de kandidaatwaarde hetzelfde is en de twee cellen buren zijn. Uit Tabel 4 weten we dat de enige cel die een waarde nodig heeft en slechts één kandidaat heeft, cel (8,7,9) is. Bijvoorbeeld 1: er is geen conflict.
Wat zou een conflict zijn? Als de enige mogelijke waarde voor cel (3,7,3) 7 was (in plaats van 1, 6, 7), dan is er sprake van een conflict. Cel (8,7) en cel (3,7) zijn buren – dezelfde kolom. Als de enige mogelijke waarde voor cel (4,9,2) echter 7 was (in plaats van 1, 2, 7), zou dit geen conflict zijn. Deze cellen zijn geen buren.
Samenvatting van de Sanity Check
- Als er duplicaten zijn, is de startoplossing niet haalbaar.
- Als een cel die een waarde nodig heeft, geen kandidaten heeft, dan is er geen mogelijke oplossing voor deze puzzel. De lijst met kandidaatwaarden voor elke cel kan worden gebruikt om de zoekruimte te verkleinen – zowel voor backtracking als voor optimalisatie.
- Het vermogen om conflicten te vinden identificeert de puzzel en is niet haalbaar – heeft geen oplossing – zonder een zoekproces. Bovendien identificeert het de “probleemcellen”.
Een backtracking-oplossing: zoekproces
Nu de kerngegevensstructuren en de geestelijke gezondheid zijn gecontroleerd, richten we onze aandacht op het zoekproces. Het terugkerende thema is opnieuw het opzetten van datastructuren om zoeken te ondersteunen.
Het volgen van de zoekopdracht
De array Tracker houdt de gemaakte opdrachten bij
- Kolom 1 is de teller
- Kolom 2 is het aantal beschikbare opties om aan deze cel toe te wijzen
- 1 betekent dat er 1 optie beschikbaar is, 2 betekent twee opties, enz.
- 0 betekent – geen optie beschikbaar of resetten naar 0 (geen toegewezen waarde) en teruggaan
- Kolom 3 is de cel waaraan een waarde-indexnummer is toegewezen (1 tot 81)
- Kolom 4 is de waarde die aan de cel is toegewezen in de trackgeschiedenis
- Een waarde van 9999 betekent dat deze cel zich bevond op het moment dat de doodlopende weg werd gevonden
- De waarde van een geheel getal tussen 1 en 9 is de toegewezen waarde aan deze cel op dit punt in het zoekproces.
- Een waarde van 0 betekent dat deze cel een toewijzing nodig heeft
De trackerarray wordt gebruikt om het zoekproces te ondersteunen. De array TRACKHIST heeft dezelfde structuur als de tracker maar houdt de geschiedenis van het gehele zoekproces bij. Tabel 6 bevat een deel van TRACKHIST, bijvoorbeeld 1. Dit wordt in een later gedeelte gedetailleerder uitgelegd.

Bovendien is de array PAV (een vector van een vector), houdt eerder toegewezen waarden aan deze cel bij. Dit zorgt ervoor dat we een mislukte oplossing niet opnieuw bekijken – vergelijkbaar met wat er in TABU wordt gedaan.
Er is een optioneel logproces waarbij het zoekproces elke stap opschrijft.
Het zoeken starten
Nu de boekhouding en de geestelijke gezondheid zijn gecontroleerd, kunnen we nu beginnen met het zoekproces. De stappen zijn:
- Zijn er nog cellen over die een waarde nodig hebben? – zo nee, dan zijn we klaar.
- Zoek voor elke cel die een waarde nodig heeft, alle kandidaatopties voor elke cel. Tabel 4 bevat deze waarden aan het begin van het oplossingsproces. Bij elke iteratie wordt dit bijgewerkt om tegemoet te komen aan de waarden die aan cellen zijn toegewezen.
- Evalueer de opties in deze volgorde.
- Als een cel NUL-opties heeft, stel dan backtracking in
- Zoek alle cellen met één optie, selecteer een van deze cellen, maak deze toewijzing,
- en update de trackingtabel, de huidige oplossing en PAV.
- Als alle cellen meer dan één optie hebben, selecteert u één cel en één waarde en werkt u deze bij
- en update de trackingtabel, de huidige oplossing en PAV
We zullen Tabel 6 gebruiken, die deel uitmaakt van de geschiedenis van het oplossingsproces (TRACKHIST genoemd) om elke stap te illustreren.
In de eerste iteratie (CTR=1) wordt cel 70 (rij 8, kolom 7, vak 9) geselecteerd om een waarde te krijgen. Er is alleen kandidaat (7) en deze waarde wordt toegewezen aan cel 70. Bovendien wordt de waarde 7 opgeteld bij de vector van eerder toegewezen waarden (PAV) voor cel 70.
In de tweede iteratie krijgt cel 30 de waarde 1 toegewezen. Deze cel had twee kandidaatwaarden. De kleinste kandidaatwaarde wordt aan de cel toegewezen (slechts een willekeurige regel om de logica eenvoudig te volgen).
Het proces van het identificeren van een cel die een waarde nodig heeft en het toekennen van een waarde werkt prima tot iteratie (CTR) 20. Cel 9 heeft waarde nodig, maar het aantal kandidaten is NUL. Er zijn twee opties:
- Er is geen oplossing voor deze puzzel.
- We maken een aantal opdrachten ongedaan (terugdraaien) en nemen een ander pad.
We hebben gezocht naar de celtoewijzing die hier het dichtst bij lag, waarbij er meer dan één optie was. In dit voorbeeld gebeurde dit bij iteratie 18, waarbij cel 5 de waarde 3 krijgt toegewezen, maar er waren twee kandidaatwaarden voor cel 5: waarden 3 en 8.
Tussen cel 5 (CTR = 18) en cel 9 (CTR = 20) krijgt cel 8 de waarde 4 (CTR = 19). We plaatsen de cellen 8 en 5 terug op de lijst ‘waarde nodig’. Dit wordt vastgelegd in de tweede en derde CTR=20-invoer, waarbij de waarde is ingesteld op 0. De waarde 3 wordt bewaard in de PAV-vector voor cel 5. Dat wil zeggen dat de zoekmachine de waarde 3 niet aan cel 5 kan toewijzen.
De zoekmachine start opnieuw op om een waarde voor cel 5 te identificeren (waarbij 3 niet langer een optie is) en wijst de waarde 8 toe aan cel 5 (CTR=21). Dit gaat door totdat alle cellen een waarde hebben of er een cel is zonder optie en er geen teruglooppad is. De oplossing staat in Tabel 7.

Let op: als er meer dan één kandidaat is voor een cel, is dit een kans op parallelle verwerking.
Vergelijking met MILP-optimalisatieoplossing
Aan de oppervlakte is de weergave van de Sudoku-puzzel dramatisch anders. De AI-aanpak maakt gebruik van gehele getallen en is hoe dan ook een strakkere en intuïtievere weergave. Bovendien bieden de sanity checkers nuttige informatie om een sterkere formulering te maken. De MILP-weergave is eindeloos binaries (0/1). De binaire bestanden zijn echter krachtige representaties gezien de kracht van moderne MILP-oplossers.
Intern houdt de MILP-oplosser de binaire bestanden echter niet bij, maar gebruikt hij een spaarzame array-methode om het opslaan van alle nullen te elimineren. Bovendien verschijnen de algoritmen om binaire bestanden op te lossen pas in de jaren tachtig en negentig. Het artikel uit 1980 van Crowder, Johnson en Padberg rapporteert over een van de eerste praktische oplossingen voor optimalisatie met binaire bestanden. Ze wijzen op het belang van slimme voorverwerking en branch-and-bound-methoden als cruciaal voor een succesvolle oplossing.
De recente explosie van het gebruik van constraint programming en software zoals lokale oplosser heeft het belang duidelijk gemaakt van het gebruik van AI-methoden met de originele optimalisatiemethoden zoals lineaire programmering en kleinste kwadraten.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://blog.arkieva.com/an-artificial-intelligence-based-solution-to-sudoku/?utm_source=rss&utm_medium=rss&utm_campaign=an-artificial-intelligence-based-solution-to-sudoku

