Een inleiding tot versterkend leren met OpenAI Gym, RLlib en Google Colab
Krijg een inleiding tot Reinforcement Learning door te proberen een virtuele CartPole in evenwicht te brengen met OpenAI Gym, RLlib en Google Colab.
By Michaël Galarnyk & Sven Micha
In deze zelfstudie wordt wapeningsleren (RL) gebruikt om een virtuele CartPole in evenwicht te brengen. De video- hierboven van PilcoLearner toont de resultaten van het gebruik van RL in een echte CartPole-omgeving.
Een mogelijke definitie van versterkingsleren (RL) is een computationele benadering om te leren hoe de totale som van beloningen kan worden gemaximaliseerd bij interactie met een omgeving. Hoewel een definitie nuttig is, is deze tutorial bedoeld om te illustreren wat versterkingsleren is door middel van afbeeldingen, code en videovoorbeelden en gaandeweg het introduceren van termen voor versterkingsleer, zoals agenten en omgevingen.
In deze zelfstudie wordt in het bijzonder onderzocht:
- Wat is versterkend leren?
- De OpenAI Gym CartPole-omgeving
- De rol van agenten bij leren over versterking
- Hoe een agent te trainen met behulp van de Python-bibliotheek RLlib
- Een GPU gebruiken om de training te versnellen
- Hyperparameter afstemmen met Ray Tune
Wat is versterkend leren?
Als vorige post opgemerkt, machine learning (ML), een subveld van AI, maakt gebruik van neurale netwerken of andere soorten wiskundige modellen om te leren hoe complexe patronen te interpreteren. Twee gebieden van ML die recentelijk erg populair zijn geworden vanwege hun hoge mate van volwassenheid, zijn gesuperviseerd leren (SL), waarbij neurale netwerken leren voorspellingen te doen op basis van grote hoeveelheden gegevens, en versterkingsleren (RL), waarbij de netwerken leren om met vallen en opstaan goede actiebeslissingen te nemen met behulp van een simulator.

RL is de technologie achter verbijsterende successen zoals DeepMind's AlphaGo Zero en de StarCraft II AI (AlphaStar) of OpenAI's DOTA 2 AI ("OpenAI Five"). Let op: er zijn veel indrukwekkende toepassingen van versterkend leren en de reden waarom het zo krachtig en veelbelovend is voor echte besluitvormingsproblemen, is omdat RL in staat is om continu te leren - soms zelfs in steeds veranderende omgevingen - te beginnen zonder te weten welke beslissingen ze moeten nemen (willekeurig gedrag).
Agenten en omgevingen

Het bovenstaande diagram toont de interacties en communicatie tussen een agent en een omgeving. Bij versterkingsleren werken een of meer agenten samen in een omgeving die een simulatie kan zijn zoals CartPole in deze zelfstudie of een verbinding met echte sensoren en actuatoren. Bij elke stap ontvangt de agent een observatie (dwz de toestand van de omgeving), onderneemt hij een actie en ontvangt hij meestal een beloning (de frequentie waarmee een agent een beloning ontvangt, hangt af van een bepaalde taak of probleem). Agenten leren van herhaalde proeven, en een reeks daarvan wordt een episode genoemd - de reeks acties van een eerste observatie tot een "succes" of "falen" waardoor de omgeving zijn "klaar"-status bereikt. Het leergedeelte van een RL-raamwerk traint een beleid over welke acties (dwz opeenvolgende beslissingen) ervoor zorgen dat agenten hun cumulatieve langetermijnbeloningen maximaliseren.
De OpenAI Gym Cartpole-omgeving

WinkelwagenPole
Het probleem dat we proberen op te lossen, is proberen een paal rechtop te houden. In het bijzonder is de paal door een niet-aangedreven verbinding bevestigd aan een kar, die langs een wrijvingsloos spoor beweegt. De slinger begint rechtop en het doel is om te voorkomen dat hij omvalt door de snelheid van de kar te verhogen en te verlagen.

In plaats van deze omgeving helemaal opnieuw te coderen, gebruikt deze tutorial AI-sportschool openen dat is een toolkit die een breed scala aan gesimuleerde omgevingen biedt (Atari-spellen, bordspellen, fysieke 2D- en 3D-simulaties, enzovoort). Gym doet geen aannames over de structuur van je agent (wat de kar naar links of rechts duwt in dit cartpole-voorbeeld) en is compatibel met elke numerieke rekenbibliotheek, zoals numpy.
De onderstaande code laadt de cartpole-omgeving.
import gym env = gym.make("CartPole-v0")
Laten we nu beginnen deze omgeving te begrijpen door naar de actieruimte te kijken.
env.action_space

De output Discreet(2) betekent dat er twee acties zijn. In cartpole komt 0 overeen met "kar naar links duwen" en 1 komt overeen met "kar naar rechts duwen". Merk op dat in dit specifieke voorbeeld stilstaan geen optie is. Bij versterkingsleren produceert de agent een actie-output en deze actie wordt naar een omgeving gestuurd die vervolgens reageert. De omgeving produceert een observatie (samen met een beloningssignaal, hier niet getoond) die we hieronder kunnen zien:
env.reset()

De waarneming is een vector van dim=4, die de x-positie van de kar, de snelheid van de kar x, de poolhoek in radialen (1 radiaal = 57.295 graden) en de hoeksnelheid van de pool bevat. De hierboven getoonde cijfers zijn de eerste waarneming na het starten van een nieuwe aflevering (`env.reset()`). Met elke tijdstap (en actie) veranderen de waarnemingswaarden, afhankelijk van de staat van de kar en paal.
Een agent opleiden
Bij versterkingsleren is het doel van de agent om in de loop van de tijd steeds slimmere acties te produceren. Dat doet hij met beleid. Bij diep versterkend leren wordt dit beleid weergegeven met een neuraal netwerk. Laten we eerst communiceren met de sportschoolomgeving zonder een neuraal netwerk of machine learning-algoritme van welke aard dan ook. In plaats daarvan beginnen we met willekeurige bewegingen (links of rechts). Dit is alleen om de mechanismen te begrijpen.

De onderstaande code reset de omgeving en neemt 20 stappen (20 cycli), waarbij altijd een willekeurige actie wordt ondernomen en de resultaten worden afgedrukt.
# retourneert een eerste waarneming env.reset() voor i in range(20): # env.action_space.sample() produceert 0 (links) of 1 (rechts). observatie, beloning, gedaan, info = env.step(env.action_space.sample()) print("step", i, observatie, beloning, gedaan, info) env.close()
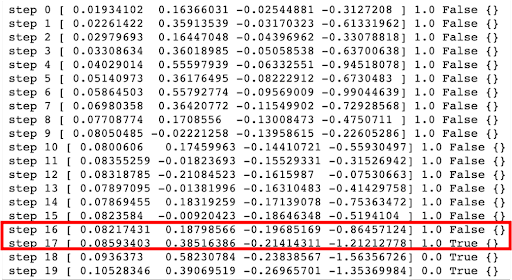
Voorbeelduitvoer. Er zijn meerdere voorwaarden voor afleveringsbeëindiging in cartpole. In de afbeelding wordt de aflevering beëindigd omdat deze meer dan 12 graden is (0.20944 rad). Andere voorwaarden voor het beëindigen van een aflevering zijn: de positie van het winkelwagentje is meer dan 2.4 (midden van het wagentje bereikt de rand van het scherm), de lengte van de aflevering is groter dan 200, of de opgeloste eis waarbij het gemiddelde rendement groter is dan of gelijk is aan 195.0 over 100 opeenvolgende proeven.
De afgedrukte uitvoer hierboven laat de volgende dingen zien:
- stap (hoe vaak hij door de omgeving is gefietst). In elke tijdstap kiest een agent een actie en de omgeving retourneert een observatie en een beloning
- waarneming van de omgeving [x karpositie, x karsnelheid, poolhoek (rad), poolhoeksnelheid]
- beloning behaald door de vorige actie. De schaal varieert tussen omgevingen, maar het doel is altijd om je totale beloning te verhogen. De beloning is 1 voor elke stap die voor cartpole wordt gezet, inclusief de beëindigingsstap. Nadat het 0 is (stap 18 en 19 in de afbeelding).
- gedaan is een boolean. Het geeft aan of het tijd is om de omgeving opnieuw te resetten. De meeste taken zijn opgedeeld in goed gedefinieerde afleveringen, en als 'waar' is voltooid, geeft dit aan dat de aflevering is beëindigd. In de kar-paal kan het zijn dat de paal te ver is gekanteld (meer dan 12 graden/0.20944 radialen), de positie is meer dan 2.4, wat betekent dat het midden van de kar de rand van het scherm bereikt, de lengte van de aflevering is groter dan 200, of de opgeloste vereiste dat is wanneer het gemiddelde rendement groter is dan of gelijk is aan 195.0 over 100 opeenvolgende proeven.
- info wat diagnostische informatie is die nuttig is voor het opsporen van fouten. Het is leeg voor deze cartpole-omgeving.
Hoewel deze cijfers nuttige outputs zijn, kan een video duidelijker zijn. Als u deze code uitvoert in Google Colab, is het belangrijk op te merken dat er geen weergavestuurprogramma beschikbaar is voor het genereren van video's. Het is echter mogelijk om een virtueel beeldschermstuurprogramma te installeren om het werkend te krijgen.
# installatieafhankelijkheden die nodig zijn voor het opnemen van video's !apt-get install -y xvfb x11-utils !pip install pyvirtualdisplay==0.2.*
De volgende stap is het starten van een instantie van de virtuele weergave.
van pyvirtualdisplay import Display display = Display(visible=False, size=(1400, 900)) _ = display.start()
OpenAI gym heeft een VideoRecorder-wrapper die een video van de hardloopomgeving in MP4-formaat kan opnemen. De onderstaande code is hetzelfde als voorheen, behalve dat deze voor 200 stappen is en aan het opnemen is.
from gym.wrappers.monitoring.video_recorder import VideoRecorder before_training = "before_training.mp4" video = VideoRecorder(env, before_training) # retourneert een eerste observatie env.reset() voor i in range(200): env.render() video. capture_frame() # env.action_space.sample() produceert 0 (links) of 1 (rechts). observatie, beloning, gedaan, info = env.step(env.action_space.sample()) # Deze keer niet afdrukken #print("step", i, observation, reward, done, info) video.close() env.close ()

Meestal beëindigt u de simulatie wanneer u klaar bent met 1 (True). De bovenstaande code laat de omgeving doorgaan nadat een beëindigingsvoorwaarde is bereikt. In CartPole kan dit bijvoorbeeld zijn wanneer de paal omvalt, de paal van het scherm verdwijnt of andere beëindigingsvoorwaarden bereikt.
De bovenstaande code heeft het videobestand op de Colab-schijf opgeslagen. Om het in het notitieboek weer te geven, hebt u een hulpfunctie nodig.
from base64 import b64encode def render_mp4(videopath: str) -> str: """ Haalt een string op die een b4-gecodeerde versie van de MP4-video op het gespecificeerde pad bevat. """ mp4 = open(videopath, 'rb'). read() base64_encoded_mp4 = b64encode(mp4).decode() return f' '
De onderstaande code geeft de resultaten weer. Je zou een video moeten krijgen die lijkt op die hieronder.
van IPython.display import HTML html = render_mp4(before_training) HTML(html)
Het afspelen van de video laat zien dat het willekeurig kiezen van een actie geen goed beleid is om de CartPole rechtop te houden.
Hoe een agent te trainen met Ray's RLlib
In het vorige gedeelte van de tutorial liet onze agent willekeurige acties uitvoeren zonder rekening te houden met de observaties en beloningen uit de omgeving. Het doel van het hebben van een agent is om in de loop van de tijd steeds slimmere acties te produceren en willekeurige acties bereiken dat niet. Om een agent in de loop van de tijd slimmere acties te laten ondernemen, heeft hij een beter beleid nodig. Bij diepgaand leren wordt het beleid weergegeven met een neuraal netwerk.

Deze tutorial gebruikt de RLlib-bibliotheek om een slimmere agent op te leiden. RLlib heeft vele voordelen zoals:
- Extreme flexibiliteit. Hiermee kunt u elk aspect van de RL-cyclus aanpassen. Dit gedeelte van de tutorial maakt bijvoorbeeld een aangepast neuraal netwerkbeleid met behulp van PyTorch (RLlib heeft ook native ondersteuning voor TensorFlow).
- Schaalbaarheid. Reinforcement learning-applicaties kunnen behoorlijk rekenintensief zijn en moeten vaak worden opgeschaald naar een cluster voor snellere training. RLlib biedt niet alleen eersteklas ondersteuning voor GPU's, maar is ook gebouwd op straal wat het schalen van Python-programma's van een laptop naar een cluster eenvoudig maakt.
- Een uniforme API en ondersteuning voor offline, modelgebaseerde, modelvrije algoritmen met meerdere agenten en meer (deze algoritmen worden in deze zelfstudie niet onderzocht).
- Deel uitmaken van de Ray Project-ecosysteem. Een voordeel hiervan is dat RLlib kan worden uitgevoerd met andere bibliotheken in het ecosysteem, zoals: Ray Tune, een bibliotheek voor het uitvoeren van experimenten en het afstemmen van hyperparameters op elke schaal (hierover later meer).
Hoewel sommige van deze functies in dit bericht niet volledig zullen worden gebruikt, zijn ze zeer handig als je iets ingewikkelders wilt doen en problemen in de echte wereld wilt oplossen. U kunt meer te weten komen over enkele indrukwekkende use-cases van RLlib hier.
Om met RLlib aan de slag te gaan, moet u het eerst installeren.
!pip install 'ray[rllib]'==1.6
Nu kunt u een PyTorch-model trainen met behulp van het Proximal Policy Optimization (PPO)-algoritme. Het is een zeer goed afgerond, one size fits all type algoritme waar u meer over kunt leren hier. De onderstaande code gebruikt een neuraal netwerk dat bestaat uit een enkele verborgen laag van 32 neuronen en lineaire activeringsfuncties.
import ray from ray.rllib.agents.ppo import PPOTrainer config = { "env": "CartPole-v0", # Verander de volgende regel in `"framework": "tf"` om tensorflow "framework" te gebruiken: "torch" , "model": { "fcnet_hiddens": [32], "fcnet_activation": "lineair", }, } stop = {"episode_reward_mean": 195} ray.shutdown() ray.init( num_cpus=3, include_dashboard=False , negeer_reinit_error=True, log_to_driver=False, ) # voer trainingsanalyse uit = ray.tune.run( "PPO", config=config, stop=stop, checkpoint_at_end=True, )
Deze code zou behoorlijk wat output moeten produceren. De uiteindelijke invoer zou er ongeveer zo uit moeten zien:

De invoer laat zien dat het 35 iteraties kostte, in totaal meer dan 258 seconden, om de omgeving op te lossen. Dit zal elke keer anders zijn, maar zal waarschijnlijk ongeveer 7 seconden per iteratie zijn (258 / 35 = 7.3). Merk op dat als je de Ray API wilt leren en wilt zien wat commando's zoals ray.shutdown en ray.init doen, je bekijk deze tutorial.
Een GPU gebruiken om de training te versnellen
Hoewel de rest van de tutorial gebruik maakt van CPU's, is het belangrijk op te merken dat je modeltraining kunt versnellen door een GPU in Google Colab te gebruiken. Dit kan door te kiezen voor Runtime> Runtime-type wijzigen en zet hardwareversneller op GPU. Selecteer vervolgens Runtime > Opnieuw opstarten en alles uitvoeren.

Merk op dat, hoewel het aantal trainingsiteraties ongeveer hetzelfde kan zijn, de tijd per iteratie aanzienlijk is afgenomen (van 7 seconden naar 5.5 seconden).
Een video maken van het getrainde model in actie
RLlib biedt een Trainer-klasse met een beleid voor interactie met de omgeving. Via de trainerinterface kan een beleid worden getraind, actie worden berekend en worden gecontroleerd. Terwijl het analyseobject terugkeerde van ray.tune.run bevatte eerder geen trainersexemplaren, het heeft alle informatie die nodig is om er een te reconstrueren vanaf een opgeslagen checkpoint omdat checkpoint_at_end=Waar als parameter doorgegeven. Onderstaande code laat dit zien.
# herstel een trainer van de laatste checkpoint-proef = analysis.get_best_logdir("episode_reward_mean", "max") checkpoint = analysis.get_best_checkpoint( trial, "training_iteration", "max", ) trainer = PPOTrainer(config=config) trainer.restore (controlepunt)
Laten we nu nog een video maken, maar deze keer de actie kiezen die wordt aanbevolen door het getrainde model in plaats van willekeurig te handelen.
after_training = "after_training.mp4" after_video = VideoRecorder(env, after_training) observation = env.reset() done = False terwijl niet klaar: env.render() after_video.capture_frame() action = trainer.compute_action(observatie) observatie, beloning , klaar, info = env.step(action) after_video.close() env.close() # Je zou een video moeten krijgen die lijkt op die hieronder. html = render_mp4(after_training) HTML(html)
Deze keer balanceert de paal mooi, wat betekent dat de agent de cartpaalomgeving heeft opgelost!
Hyperparameter afstemmen met Ray Tune

Het Ray Ecosysteem
RLlib is een versterkende leerbibliotheek die deel uitmaakt van het Ray Ecosystem. Ray is een zeer schaalbaar universeel raamwerk voor parallelle en gedistribueerde python. Het is heel algemeen en die algemeenheid is belangrijk voor het ondersteunen van het bibliotheekecosysteem. Het ecosysteem omvat alles van opleiding, te productie serveren, te gegevensverwerking en meer. U kunt meerdere bibliotheken samen gebruiken en toepassingen bouwen die al deze dingen doen.
Dit deel van de tutorial maakt gebruik van Ray Tune dat is een andere bibliotheek in het Ray Ecosystem. Het is een bibliotheek voor het uitvoeren van experimenten en het afstemmen van hyperparameters op elke schaal. Hoewel deze zelfstudie alleen rasterzoekopdrachten gebruikt, moet u er rekening mee houden dat Ray Tune u ook toegang geeft tot efficiëntere algoritmen voor het afstemmen van hyperparameters, zoals training op basis van bevolking, BayesOptSearch en HyperBand/ASHA.
Laten we nu proberen hyperparameters te vinden die de CartPole-omgeving in de minste tijdstappen kunnen oplossen.
Voer de volgende code in en wees erop voorbereid dat het even kan duren voordat het wordt uitgevoerd:
parameter_search_config = { "env": "CartPole-v0", "framework": "torch", # Hyperparameter tuning "model": { "fcnet_hiddens": ray.tune.grid_search([[32], [64]]), "fcnet_activation": ray.tune.grid_search(["linear", "relu"]), }, "lr": ray.tune.uniform(1e-7, 1e-2) } # Om Ray expliciet te stoppen of opnieuw te starten, gebruik de afsluit-API. ray.shutdown() ray.init( num_cpus=12, include_dashboard=False, negeer_reinit_error=True, log_to_driver=False, ) parameter_search_analysis = ray.tune.run( "PPO", config=parameter_search_config, stop=stop=5, num_samples metric="timesteps_total", mode="min", ) print( "Beste hyperparameters gevonden:", parameter_search_analysis.best_config, )
Door om 12 CPU-cores te vragen door num_cpus=12 door te geven aan ray.init, worden vier proeven parallel uitgevoerd over elk drie CPU's. Als dit niet werkt, heeft Google misschien de beschikbare VM's op Colab gewijzigd. Elke waarde van drie of meer zou moeten werken. Als Colab fouten maakt doordat het RAM-geheugen bijna op is, moet u mogelijk het volgende doen: Runtime > Runtime fabrieksreset, Gevolgd door Runtime > Alles uitvoeren. Merk op dat er een gebied is in de rechterbovenhoek van de Colab-notebook dat het RAM- en schijfgebruik toont.
Als u num_samples=5 opgeeft, betekent dit dat u vijf willekeurige steekproeven krijgt voor de leersnelheid. Voor elk daarvan zijn er twee waarden voor de grootte van de verborgen laag en twee waarden voor de activeringsfunctie. Er zullen dus 5 * 2 * 2 = 20 proeven zijn, weergegeven met hun statussen in de uitvoer van de cel terwijl de berekening wordt uitgevoerd.
Merk op dat Ray de huidige beste configuratie afdrukt terwijl deze werkt. Dit omvat alle standaardwaarden die zijn ingesteld, wat een goede plek is om andere parameters te vinden die kunnen worden aangepast.
Nadat dit is uitgevoerd, kan de uiteindelijke uitvoer vergelijkbaar zijn met de volgende uitvoer:
INFO tune.py:549 — Totale looptijd: 3658.24 seconden (3657.45 seconden voor de afstemlus).
Beste gevonden hyperparameters: {'env': 'CartPole-v0', 'framework': 'torch', 'model': {'fcnet_hiddens': [64], 'fcnet_activation': 'relu'}, 'lr': 0.006733929096170726 };”'
Dus van de twintig sets hyperparameters presteerde die met 64 neuronen, de ReLU-activeringsfunctie en een leersnelheid van rond de 6.7e-3 het beste.
Conclusie

Neural MMO is een omgeving die is gemodelleerd naar Massively Multiplayer Online-games - een genre dat honderden tot duizenden gelijktijdige spelers ondersteunt. U kunt leren hoe Ray en RLlib helpen bij het inschakelen van enkele belangrijke functies van dit en andere projecten hier.
Deze tutorial illustreerde wat versterkingsleren is door terminologie voor versterkingsleer te introduceren, door te laten zien hoe agenten en omgevingen met elkaar omgaan, en door deze concepten te demonstreren door middel van code- en videovoorbeelden. Als je meer wilt weten over versterkend leren, bekijk dan de RLlib-tutorial door Sven Mika. Het is een geweldige manier om meer te weten te komen over de best practices van RLlib, algoritmen voor meerdere agenten en nog veel meer. Als je op de hoogte wilt blijven van alles wat met RLlib en Ray te maken heeft, overweeg dan: @raydistributed volgen op twitter en meld je aan voor de Ray-nieuwsbrief.
ORIGINELE. Met toestemming opnieuw gepost.
Zie ook:
| Topverhalen afgelopen 30 dagen | |||||
|---|---|---|---|---|---|
|
|
||||
PlatoAi. Web3 opnieuw uitgevonden. Gegevensintelligentie versterkt.
Klik hier om toegang te krijgen.
Bron: https://www.kdnuggets.com/2021/09/intro-reinforcement-learning-openai-gym-rllib-colab.html

