I
In dit technische tijdperk is Big Data even revolutionair als onverwacht groeiend. Volgens de onderzoeksrapporten is ongeveer 90% van de huidige gegevens pas in de afgelopen twee jaar gegenereerd. Big data is niets anders dan het enorme volume aan datasets
Big data helpt meerdere bedrijven om hun producten en diensten beter te leren kennen en er waardevolle inzichten over te genereren. Big Daechnology breidt zich uit op elk gebied en kan worden gebruikt om de marketingcampagnes en -technieken van de branche te verfijnen, en het helpt ook bij de uitbreiding van kunstmatige intelligentie (AI)-segmenten en automatisering.
Tegenwoordig zijn de werkgelegenheidskansen enorm, aangezien elk bedrijf over de hele wereld op zoek is naar vereisten voor Big Data-professionals om hun zakelijke services te stroomlijnen en te beheren. Werkgevers kunnen de baan gemakkelijk halen door hun sterke kennis en interesse in data en de markt te tonen. Big Data biedt verschillende functies zoals Data Analyst, Data Scientist, Database administrator(DBA), Big Data Engineer(BDA), Hadoop Engineer, etc.
leerdoelen
- Begrijp Big Data om het tempo te bepalen voor een sterke carrière als Big Data-analist.
- Heb een grondige kennis van big data en zijn typen.
- Ken de essentiële V's in big data en hun belang.
- Lees meer over de use cases en toepassingen van big data en Hadoop.
- Begrijp hoe Hadoop wordt gebruikt in big data.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
- De term Big Data begrijpen
- Verschillende soorten big data
- De 5 V's in Big Data
- Top 3 use-cases van big data en Hadoop
4.1 Netflix
4.2 Uber
Walmart 4.3 - Het gebruik van Hadoop in Big Data
- Conclusie
De term begrijpen: big data
Big data wordt geassocieerd met uitgebreide en vaak gecompliceerde datasets, die groot genoeg zijn dat conventionele relationele databases niet aankunnen. Ze hebben speciale tools en methodologieën nodig om bewerkingen uit te voeren op een enorme gegevensverzameling. Big data bestaat uit gestructureerde, semi-gestructureerde en ongestructureerde datasets zoals audio, video's, foto's, websites, enz. Er zijn n-aantal bronnen waaruit we deze gegevens halen. Enkele van de gegevensbronnen zijn: -
-
E-mail volgen
-
Server logs
-
Smartphones en smartwatches
-
Internet cookies
-
Social media
-
Medische gegevens
-
Machinesensoren en IoT-apparaten
-
Online aankooptransactieformulieren
Bedrijven verzamelen dagelijks deze ongestructureerde en onbewerkte datasets en om deze gegevens te beheren en hun bedrijf beter te begrijpen, hebben ze big data-technologie nodig. Big data beheren de datasets door zinvolle informatie te extraheren, die industrieën helpt om betere zakelijke beslissingen te nemen, ondersteund door data.
Laten we de werking van Big Data begrijpen als een proces in drie stappen!
-
integratie: is de eerste stap van werken, waarbij gegevens uit verschillende heterogene bronnen worden verzameld. Het voegt de verzamelde gegevens samen en kneedt deze tot een formaat dat zodanig kan worden geanalyseerd dat het zakelijke inzichten oplevert.
-
Beheer: Na verzameling moeten de gegevens zorgvuldig worden beheerd om waardevolle informatie te ontginnen en om te zetten in werkbare inzichten. De enorme hoeveelheid Big Data is ongestructureerd, dus we kunnen het niet opslaan in conventionele relationele databases, die gegevens opslaan in tabelvorm.
-
Analyse: In deze analysefase worden gegevens verzameld en gebruiken datawetenschappers vaak geavanceerde technologieën zoals machine learning, deep learning en voorspellende modellering om grote datasets te onderzoeken en een beter begrip van de gegevens te krijgen.
Verschillende soorten big data
Drie soorten Big Data zijn gestructureerd, semi-gestructureerd en ongestructureerd. Laten we ze allemaal begrijpen!

Bron: devopedia.org
Gestructureerde gegevens: Zoals de naam al doet vermoeden, zijn gegevens sterk georganiseerde gegevens die een specifiek formaat volgen om gegevens op te slaan en te verwerken. We kunnen de gegevens gemakkelijk ophalen als de attributen zijn geordend, bijvoorbeeld mobiele nummers, burgerservicenummers, pincodes, werknemersgegevens, aanwijzingsgegevens en salarissen. Gegevens die zijn opgeslagen in RDBMS (Relationeel databasebeheer) zijn een voorbeeld van gestructureerde gegevens en kunnen we gebruiken SQL (Structured Query Language) om dergelijke gegevens te verwerken en te beheren.
Ongestructureerde gegevens: Zoals de naam al doet vermoeden, ongestructureerde gegevens zijn zeer ongeorganiseerde gegevens die geen specifieke structuur of indeling volgen om gegevens op te slaan en te verwerken. Het kan niet worden opgeslagen in RDBMS en we kunnen het niet eens analyseren totdat het is omgezet in een gestructureerd formaat. Ongestructureerde gegevens zijn de gegevens die dagelijks het meest worden gegenereerd en zijn beschikbaar in meerdere formaten, zoals afbeeldingen, audio, video, posts op sociale media, bewakingsgegevens, gegevens over online winkelen, enz. Volgens experts is ongeveer 80% van de gegevens in een organisatie is ongestructureerd.
Semi-gestructureerde gegevens: Semi-gestructureerde gegevens zijn een combinatie van gestructureerde en ongestructureerde gegevens die geen specifiek formaat hebben, maar wel classificerende kenmerken hebben. Video's en afbeeldingen kunnen bijvoorbeeld interne semantische tags of metadata of markeringen bevatten met betrekking tot de plaats, datum of door wie ze zijn gemaakt, maar de informatie binnenin heeft geen structuur. XML- of JSON-bestanden zijn veel voorkomende voorbeelden van semi-gestructureerde gegevens.
De 5 V's in Big Data
De term 5 V's in Big data staat voor:
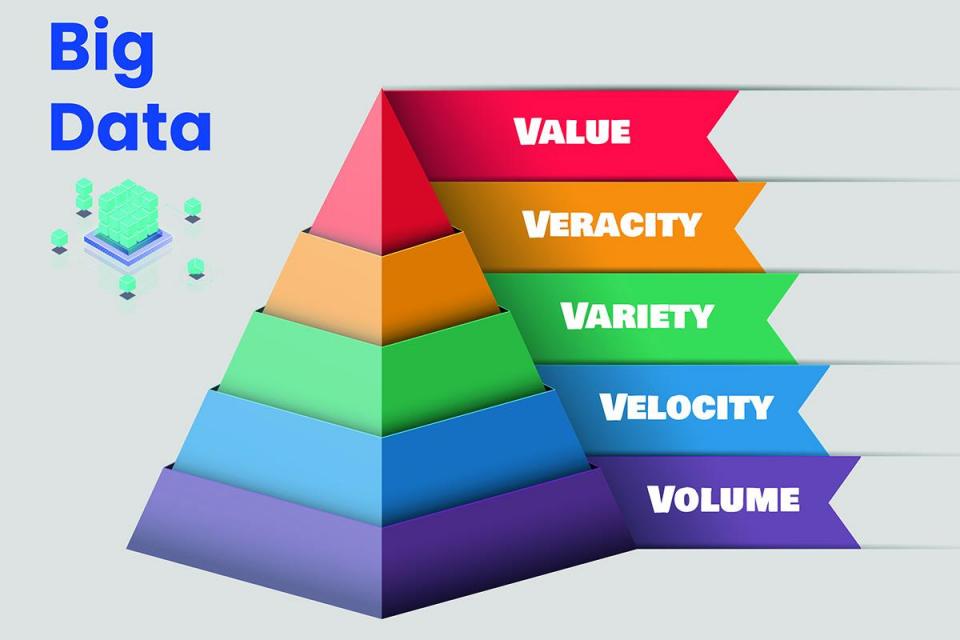
Bron: timesofmalta.com
-
Volume: Volume is niets anders dan de gigantische hoeveelheid gegevens die in hoog tempo groeit. Tegenwoordig is het datavolume in terabytes, petabytes of zelfs meer. Deze enorme hoeveelheid gegevens is opgeslagen in magazijnen en moet worden onderzocht en verwerkt. De gegevens zijn zo groot dat we ze niet kunnen opslaan in relationele databases. We hebben gedistribueerde systemen nodig zoals Hadoop en MongoDB om de delen van gegevens op meerdere locaties op te slaan en samengebracht door software.
-
Snelheid: Snelheid is de snelheid waarmee enorme hoeveelheden gegevens worden gegenereerd, opgeslagen en geanalyseerd. Velocity toont de snelheid waarmee gegevens in realtime worden gegenereerd. We kunnen het voorbeeld nemen van sociale media, die elke seconde audio, video's, berichten, enz. Genereren. Daarom neemt ongestructureerde data razendsnel toe over de hele wereld.
-
Verscheidenheid: Verscheidenheid betekent de verschillende soorten gegevens die we dagelijks gebruiken. In het verleden waren gegevens heel eenvoudig en konden ze in een gestructureerd formaat worden opgeslagen (naam, mobiel nummer, adres, e-mail-id, enz.), maar nu zijn gegevens heel anders. Nu hebben we een verscheidenheid aan gegevens die gestructureerd, ongestructureerd en semi-gestructureerd kunnen zijn, verzameld uit verschillende bronnen. We hebben specifieke analyse- en verwerkingstechnologieën nodig met innovatieve en geschikte algoritmen om de gegevens in verschillende formaten te verwerken, zoals tekst, audio, video's, enz.
-
veracity: Waarachtigheid is niets anders dan de kwaliteit of betrouwbaarheid van beschikbare gegevens. Gegevenswaarachtigheid gaat over de nauwkeurigheid en zekerheid van de geanalyseerde gegevens. Bijvoorbeeld, Twitter genereert berichten per seconde met hashtags, spelling, afkortingen, typefouten, enz., en deze tonnen gegevens zijn nutteloos als we de nauwkeurigheid en kwaliteit van de gegevens niet kunnen vertrouwen.
-
Waarde: Er worden dagelijks ruwe gegevens geproduceerd, maar het is nutteloos. We moeten het omzetten in iets waardevols om er nuttige informatie uit te halen. We kunnen de gegevens als waardevol beschouwen als we een zinvol beleggingsrendement opleveren.
Verschillende benaderingen voor het omgaan met big data
Big data het is bewezen dat het een buitengewoon competitieve arm is voor een bedrijf ten opzichte van zijn concurrenten; een bedrijf kan beslissen hoe het de mogelijkheden van big data wil benutten. Organisaties kunnen de verschillende bedrijfsactiviteiten stroomlijnen volgens hun doelstellingen en het potentieel van Big Data gebruiken volgens hun vereisten.
De basisaanpak voor het omgaan met Big Data is gebaseerd op de behoeften/eisen van de business en de beschikbare budgettaire voorzieningen. Eerst moeten we beslissen welk probleem we oplossen, wat voor soort gegevens we nodig hebben, wat we willen dat onze gegevens beantwoorden en wat we daarmee willen bereiken. Hierna kunnen we gaan met de onderstaande benaderingen voor Big Data-verwerking.
-
Batchverwerking: Bij batchverwerking verzamelen we vergelijkbare gegevens, groeperen deze (batch genoemd) en voeren deze in een analysesysteem in voor verwerking. We kunnen batchverwerking gebruiken wanneer we een grote hoeveelheid gegevens moeten verwerken en de gegevensomvang bekend en eindig is.
-
Stroomverwerking: Bij stroomverwerking verwerken we een continue stroom gegevens onmiddellijk wanneer deze wordt geproduceerd, en de verwerking gebeurt meestal in realtime. We kunnen stroomverwerking gebruiken wanneer de gegevensstroom continu is en onmiddellijke reactie vereist en de gegevensomvang onbekend en oneindig is.
Top 3 use-cases van big data en Hadoop
Netflix
Netflix is een wereldberoemd entertainmentbedrijf dat on-demand streaming video van hoge kwaliteit biedt aan zijn gebruikers.
Netflix bepaalt het tempo in de markt door zijn gebruikers precies de inhoud te bieden die ze leuk vinden. Maar weet je hoe Netflix weet wat je leuk vindt? Het antwoord ligt voor de hand met behulp van Big Data Analytics.
Netflix gebruikt big data-analyse om zijn zeer nauwkeurige aanbevelingssysteem op te bouwen en aan de vraag van de gebruiker te voldoen.
Denken, hoe?
Netflix analyseert onze gegevens over wat we kijken of zoeken, haalt daar de gegevenspunten uit, zoals welke titels klanten kijken, welk genre ze leuk vinden, hoe vaak het afspelen is gestopt, beoordelingen worden gegeven, enz., en voert dat door naar zijn aanbevelingen systeem. Dit zal beslissingen soepel en stevig maken in termen van het kennen van de behoeften van de klant in plaats van deze aan te nemen (wat de meeste bedrijven doen).
De belangrijkste datastructuren die in dit proces worden gebruikt, zijn Hadoop, Hive, Pig en andere traditionele business intelligence.
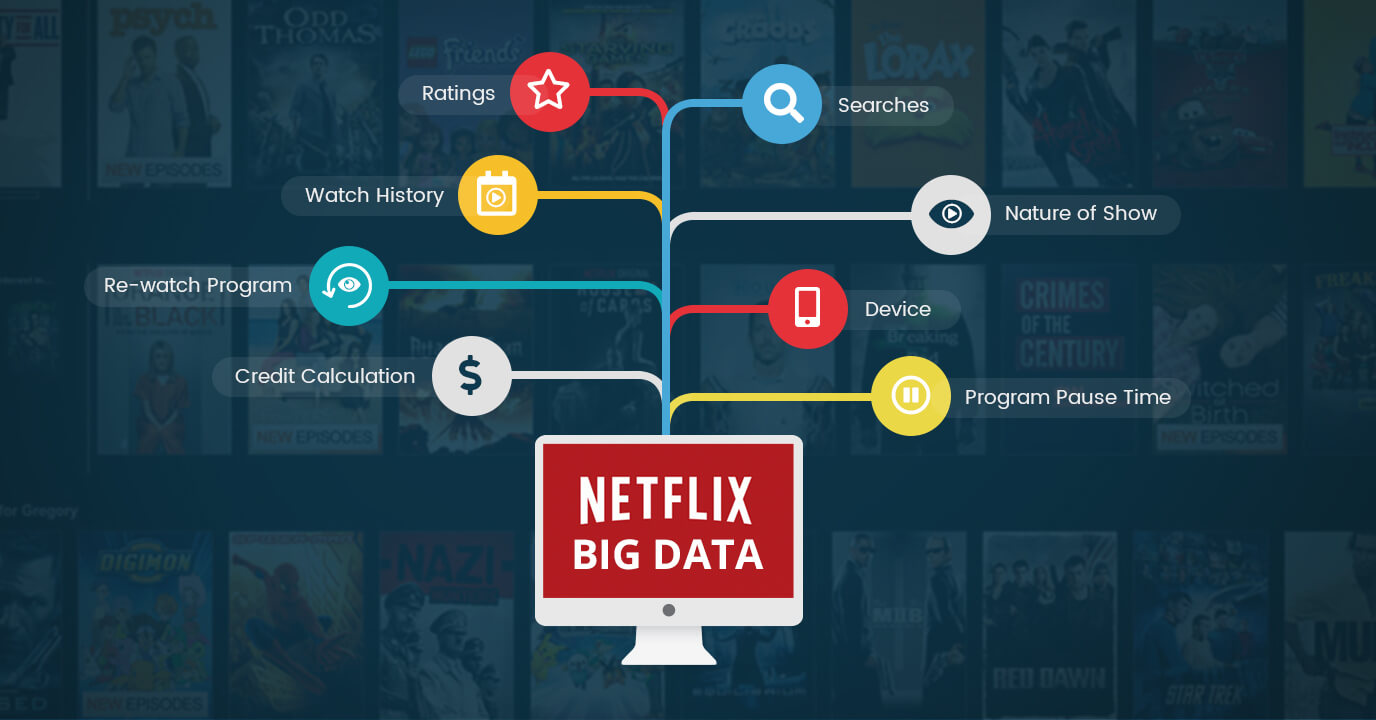
Bron: www.muvi.com/
Uber
Tegenwoordig kunnen we ons leven zonder Uber niet meer voorstellen; waar we ook heen willen, Uber is slechts een klik verwijderd en we kunnen het ook gebruiken om deliverables te verzenden.
Nu denk je misschien na over hoe Uber onze data gebruikt of de rol van big data in Uber.
Dus, laten we eerst eens nadenken, je ging vaak naar dezelfde plaatsen, maar betaalde je elke keer hetzelfde bedrag? Het antwoord is duidelijk nee.
Dit is hoe Uber onze gegevens gebruikt. Uber richt zich op de vraag naar de diensten en het aanbod om de prijzen van de geleverde diensten te beheren.
Surge Pricing is het grote voordeel van big data van Uber. Als u bijvoorbeeld op zoek bent naar een taxi naar een treinstation of luchthaven, bent u bereid om het gevraagde bedrag te betalen, en Uber begrijpt deze kritieke tijd en verhoogt de prijzen. Of zelfs op festivaldagen zie je een stijging van de prijzen.
Walmart
Walmart is 's werelds grootste retailer en omzetgigant, met meer dan 2 miljoen werknemers en 20,000 winkels in 28 landen.
Walmart gebruikt al jaren big data-analyse, zelfs toen we de term 'big data' nog niet kenden. Het is het ontdekken van gegevenspatronen, het geven van productaanbevelingen en het analyseren van de eisen van klanten met behulp van Data Mining.
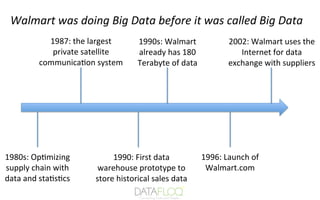
Bron: www.slideshare.net
Dit gebruik van analyses helpt Walmart de conversieratio van klanten te verhogen, de winkelervaring te optimaliseren en de beste e-commercetechnologieën te bieden om een superieure klantervaring te bieden.
Walmart gebruikt technologieën zoals NoSQL en Hadoop om interne gebruikers toegang te geven tot realtime gegevens die uit verschillende bronnen zijn verzameld en gecentraliseerd voor effectief gebruik.
Het gebruik van Hadoop in Big Data
Big data bestaat uit volumes van verschillende soorten data, die in ongestructureerde en gestructureerde data met hoge snelheid kunnen worden gegenereerd. Big Data kan als een troef worden beschouwd, en we hebben een tool nodig om met die troef om te gaan. Hadoop is een tool die wordt gebruikt om het probleem van het opslaan, verwerken en analyseren van big data aan te pakken. Hadoop is een open-source softwareprogramma dat wordt gebruikt voor het verwerken, opslaan en analyseren van complexe ongestructureerde datasets en het uitvoeren van applicaties op clusters van basishardware. Het biedt enorme opslag voor alle gegevens en maakt het gemakkelijk omdat het over meerdere machines wordt verdeeld en parallel wordt verwerkt.
Laten we enkele van de veelgebruikte Hadoop-commando's bespreken om te begrijpen hoe Hadoop big data op een betere manier verwerkt!
1. Het Mkdir-commando in Hadoop
De mkdir staat voor "make directory"; de opdracht maakt een nieuwe map aan met een opgegeven naam in het opgegeven pad van het Hadoop-cluster; de enige beperking is dat de directory nog niet mag bestaan. Als de map met dezelfde naam aanwezig is in het cluster, wordt er een fout gegenereerd die aangeeft dat de map bestaat.
Syntaxis:-
Hadoop fs -Mkdir /padnaam/mapnaam
2. Het "Touchz" -commando in Hadoop
De opdracht "Touchz" in Hadoop wordt gebruikt om een nieuw leeg bestand te maken met een opgegeven naam in het opgegeven pad van het Hadoop-cluster. Deze opdracht werkt alleen als de opgegeven map anders bestaat, er wordt geen bestand gemaakt en in plaats daarvan wordt een fout weergegeven die aangeeft dat de map niet in het cluster aanwezig is.
Syntaxis:-
Hadoop fs -touchz/mapnaam/bestandsnaam
3. LS-opdracht in Hadoop
LS staat voor lijst in Hadoop; de opdracht toont de lijst met bestanden/inhoud die beschikbaar is in de opgegeven map of het pad. We kunnen verschillende opties toevoegen met het ls-commando om meer informatie over de bestanden te krijgen of om informatie in een gefilterd formaat te krijgen, bijvoorbeeld:
-
-c: We kunnen de optie "-c" gebruiken met de opdracht "ls" om het volledige adres van de bestanden of mappen te krijgen.
-
-R: Deze optie wordt gebruikt wanneer we de inhoud van mappen in een recursieve volgorde willen hebben.
-
-S: Deze optie sorteert de bestanden in de map op basis van hun grootte. Dus wanneer we het bestand met de hoogste of de laagste grootte willen, kunnen we deze functie gebruiken.
-
-t: Dit is ook de meest gebruikte optie met de opdracht "ls", omdat het bestand wordt gesorteerd op basis van de wijzigingstijd, wat betekent dat het meest recent gebruikte bestand op de eerste positie van de lijst wordt geplaatst.
Syntaxis:-
Hadoop fs -ls/padnaam
4. Testopdracht in Hadoop
Zoals de naam al doet vermoeden, wordt deze opdracht gebruikt om het bestaan van een bestand in het Hadoop-cluster te testen en wordt alleen '1' geretourneerd als het pad in het cluster bestaat. Deze opdracht gebruikt meerdere opties zoals "[defsz]", laten we ze begrijpen!
Syntaxis:-
Hadoop fs -test -[defsz]
Opties:-
-
-d: Deze optie test of het door de gebruiker opgegeven pad een map is of niet, en als het pad een map is, zal het "0" retourneren.
-
-e: Deze optie test of het pad dat door de gebruiker is opgegeven bestaat, en als het pad in het cluster bestaat, wordt "0" geretourneerd.
-
-f: Deze optie test of het pad dat door de gebruiker is opgegeven een bestand is of niet, en als het gegeven pad een bestand is, wordt "0" geretourneerd.
-
-s: Deze optie test of het door de gebruiker opgegeven pad leeg is, en als het pad niet leeg is, wordt "0" geretourneerd.
-
-r: Deze optie test of het door de gebruiker verstrekte pad bestaat of niet en of het leesrechten heeft. Het retourneert alleen "0" als het pad bestaat en er ook leesrechten zijn verleend.
-
-w: Deze optie test of het pad dat de gebruiker opgeeft bestaat en of het is verleend met schriftelijke toestemming. Het retourneert alleen "0" als het pad bestaat en er ook schrijfrechten zijn verleend.
-
-z: Deze optie test of de grootte van het gegeven bestand nul bytes is of niet, en als de bestandsgrootte nul bytes is, wordt "0" geretourneerd.
5. Zoek opdracht in Hadoop
Zoals de naam al doet vermoeden, wordt deze opdracht gebruikt om de bestanden in het Hadoop-cluster te doorzoeken. Het scant de opgegeven uitdrukking in de opdracht met alle bestanden in het cluster en retourneert de bestanden die overeenkomen met de gedefinieerde uitdrukking. Als we het pad niet expliciet specificeerden, nam het standaard de huidige werkmap in beslag.
Syntaxis:-
Hadoop fs -vind ..
6. Tekstopdracht in Hadoop
Het tekstcommando in Hadoop wordt voornamelijk gebruikt om het zipbestand te decoderen en de inhoud van het bronbestand in tekstformaat weer te geven. Het codeert het bronbestand, verwerkt het en decodeert uiteindelijk de inhoud in platte tekst.
Syntaxis:-
Hadoop fs-tekst
7. Het Count-commando in Hadoop
Zoals de naam al doet vermoeden, telt deze opdracht het aantal bestanden, mappen en bytes onder het opgegeven pad. We kunnen de opdracht count gebruiken met verschillende opties om de uitvoer aan te passen aan onze vereisten, bijvoorbeeld:
-
-q – Deze optie wordt gebruikt om het quotum weer te geven, wat de limiet betekent voor het totale aantal namen en het ruimtegebruik voor individuele mappen.
-
-u – Deze optie geeft alleen de quota en het gebruik weer.
-
-h – Deze optie geeft de bestandsgrootte weer in een voor mensen leesbaar formaat.
-
-v – Deze optie wordt gebruikt om de kopregel weer te geven.
Syntaxis:-
Hadoop fs -count [optie]
8. GetMerge-opdracht in Hadoop
Hoe voor de hand liggend de naam ook is, de opdracht Getmerge voegt een of meerdere bestanden in een opgegeven map op het Hadoop-cluster samen tot één lokaal bestand op het lokale bestandssysteem. De woorden "src_dest" en "local_dest" in de syntaxis vertegenwoordigen de bron en lokale bestemmingen.
Syntaxis:-
Hadoop fs-Getmerge
9. AppendToFile-opdracht in Hadoop
Deze shell-opdracht wordt gebruikt om de inhoud van enkele of meerdere lokale bestanden toe te voegen aan een enkel bestand op het opgegeven bestemmingsbestand in het Hadoop-cluster. Tijdens het uitvoeren van deze opdracht worden de gegeven lokale bronbestanden toegevoegd aan de doelbron op basis van de bestandsnaam die in de opdracht is gegeven. Als het doelbestand zich niet in de map bevindt, wordt er een nieuw bestand met die naam gemaakt.
Syntaxis:-
Hadoop fs-AppendToFile
Conclusie
Deze blog behandelt enkele belangrijke Big Data-onderwerpen die u zullen helpen bij het starten van uw carrière in big data-analyse. Door deze onderwerpen voor beginners als referentie te gebruiken, kunt u het concept van big data en Hadoop beter begrijpen, waardoor u zich kunt voorbereiden op interviews en een tempo kunt bepalen om een data-analist, Hadoop-ontwikkelaar, datawetenschapper, enz. te worden. datablogs zijn:
-
Big Data is een niet-conventionele strategie die voornamelijk door bedrijven en organisaties wordt gebruikt om hun producten of diensten te begrijpen en daaruit waardevolle inzichten te verkrijgen.
-
We hebben de verschillende gegevenstypen besproken die zijn gegenereerd uit meerdere bronnen, zoals berichten op sociale media, e-mails, mobiele telefoons, creditcards, enz.
-
We bespraken de 5 V's van Big data, waaronder:
-
Volume: - Hoeveelheid gegevens die we hebben.
-
Snelheid: - Snelheid waarmee gegevens worden gemaakt, verplaatst of geopend.
-
Verscheidenheid:- De verschillende soorten gegevensbronnen die we hebben.
-
Waarheidsgetrouwheid: - Hoe betrouwbaar zijn onze gegevens?
-
Waarde:- Het zinvolle rendement dat onze gegevens opleveren op investering.
-
We bespraken ook stream- en batchverwerking in big data.
-
We bespraken een beetje over Hadoop, een door Java geschreven framework dat wordt gebruikt om de enorme hoeveelheid gegevens optimaal te verwerken.
-
Ten slotte hebben we enkele veelgebruikte Hadoop-commando's met hun syntaxis besproken.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/02/a-beginners-guide-to-the-basics-of-big-data-and-hadoop/

