Gegevens verliezen na verloop van tijd hun waarde. We horen van onze klanten dat ze de zakelijke transacties graag realtime willen analyseren. Traditioneel gebruikten klanten batchgebaseerde benaderingen voor het verplaatsen van gegevens van operationele systemen naar analytische systemen. Batchbelasting kan één of meerdere keren per dag plaatsvinden. Een batchgebaseerde aanpak kan latentie in de gegevensbeweging introduceren en de waarde van gegevens voor analyses verminderen. Op Change Data Capture (CDC) gebaseerde benadering is naar voren gekomen als alternatief voor batchgebaseerde benaderingen. Een op CDC gebaseerde aanpak legt de gegevenswijzigingen vast en maakt ze beschikbaar in datawarehouses voor verdere analyse in realtime.
CDC houdt wijzigingen bij die zijn aangebracht in de brondatabase, zoals invoegingen, updates en verwijderingen, en werkt deze wijzigingen voortdurend bij in de doeldatabase. Wanneer de CDC hoogfrequent is, verandert de brondatabase snel en moet de doeldatabase (dat wil zeggen meestal een datawarehouse) deze veranderingen vrijwel in realtime weerspiegelen.
Met de explosie van data is het aantal datasystemen in organisaties gegroeid. Datasilo’s zorgen ervoor dat data zich in verschillende bronnen bevinden, wat het lastig maakt om analyses uit te voeren.
Om diepere en rijkere inzichten te krijgen, kunt u alle wijzigingen uit verschillende datasilo's op één plek samenbrengen, zoals een datawarehouse. Dit post laat zien hoe u streaming-opname kunt gebruiken om gegevens naar toe te brengen Amazon roodverschuiving.
Roodverschuiving streaming-opname biedt gegevensopname met lage latentie en hoge doorvoer, waardoor klanten binnen enkele seconden in plaats van minuten inzichten kunnen verkrijgen. Het is eenvoudig in te stellen en neemt rechtstreeks streaminggegevens op in uw datawarehouse Amazon Kinesis-gegevensstromen en Amazon beheerde streaming voor Kafka (Amazon MSK) zonder dat je hoeft in te grijpen Amazon eenvoudige opslagservice (Amazone S3). U kunt gerealiseerde weergaven maken met behulp van SQL-instructies. Daarna kunt u met behulp van de gematerialiseerde weergavevernieuwing honderden megabytes aan gegevens per seconde opnemen.
Overzicht oplossingen
In dit bericht creëren we een gegevensreplicatie met lage latentie tussen Amazon Aurora MySQL naar Amazon Redshift Data Warehouse, met behulp van Roodverschuiving streaming-opname van Amazon MSK. Met Amazon MSK streamen we veilig gegevens met een volledig beheerde, zeer beschikbare Apache Kafka-service. Apache Kafka is een open-source gedistribueerd platform voor het streamen van evenementen dat door duizenden bedrijven wordt gebruikt voor hoogwaardige datapijplijnen, streaminganalyses, data-integratie en bedrijfskritische applicaties. We slaan CDC-gebeurtenissen voor een bepaalde tijd op in Amazon MSK, waardoor het mogelijk is om CDC-gebeurtenissen naar extra bestemmingen te leveren, zoals het Amazon S3-datameer.
Wij zetten in Debezium MySQL bron Kafka-connector op Amazon MSK Connect. Amazon MSK Connect maakt het eenvoudig om connectoren te implementeren, monitoren en automatisch te schalen die gegevens verplaatsen tussen Apache Kafka-clusters en externe systemen zoals databases, bestandssystemen en zoekindices. Amazon MSK Connect is volledig compatibel met Apache Kafka Connect, waarmee u uw Apache Kafka Connect-applicaties kunt tillen en verplaatsen zonder codewijzigingen.
Deze oplossing maakt gebruik van Amazon Aurora MySQL die de voorbeelddatabase host salesdb. Gebruikers van de database kunnen de bewerkingen INSERT, UPDATE en DELETE op rijniveau uitvoeren om de wijzigingsgebeurtenissen in het voorbeeld te produceren salesdb database. Debezium MySQL bron Kafka Connector leest deze wijzigingsgebeurtenissen en verzendt deze naar de Kafka-onderwerpen in Amazon MSK. Amazon Redshift leest vervolgens de berichten uit de Kafka-onderwerpen van Amazon MSK met behulp van de Amazon Redshift Streaming-functie. Amazon Redshift slaat deze berichten op met behulp van gematerialiseerde weergaven en verwerkt ze zodra ze binnenkomen.
U kunt zien hoe CDC een gebeurtenis maakt door naar dit voorbeeld te kijken hier. We gaan het OP-veld gebruiken. De verplichte string beschrijft het type bewerking dat ervoor zorgde dat de connector de gebeurtenis genereerde, in onze oplossing voor verwerking. In dit voorbeeld geeft c aan dat de bewerking een rij heeft gemaakt. Geldige waarden voor het OP-veld zijn:
- c = creëren
- u = bijwerken
- d = verwijderen
- r = lezen (geldt alleen voor snapshots)
Het volgende diagram illustreert de oplossingsarchitectuur:
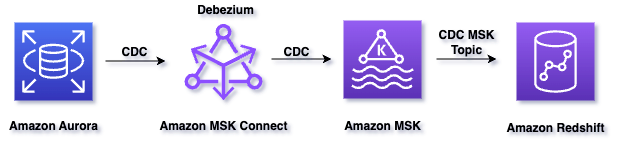
De workflow van de oplossing bestaat uit de volgende stappen:
- Amazon Aurora MySQL heeft een binair logboek (dwz binlog) dat alle bewerkingen (INSERT, UPDATE, DELETE) registreert in de volgorde waarin ze in de database zijn vastgelegd.
- Amazon MSK Connect voert de bron-Kafka-connector uit, genaamd Debezium-connector voor MySQL, leest de binlog, produceert wijzigingsgebeurtenissen voor INSERT-, UPDATE- en DELETE-bewerkingen op rijniveau en verzendt de wijzigingsgebeurtenissen naar Kafka-onderwerpen in Amazon MSK.
- Een door Amazon Redshift ingericht cluster is de streamconsument en kan berichten lezen van Kafka-onderwerpen van Amazon MSK.
- Een gematerialiseerde weergave in Amazon Redshift is het landingsgebied voor gegevens die uit de stream worden gelezen en die worden verwerkt zodra deze binnenkomen.
- Wanneer de gerealiseerde weergave wordt vernieuwd, wijzen Amazon Redshift-rekenknooppunten een groep Kafka-partities toe aan een rekensegment.
- Elk segment verbruikt gegevens van de toegewezen partities totdat de weergave pariteit bereikt met de laatste Offset voor het Kafka-onderwerp.
- Daaropvolgende gerealiseerde weergave vernieuwt leesgegevens vanaf de laatste offset van de vorige vernieuwing totdat deze pariteit bereikt met de onderwerpgegevens.
- Binnen de Amazon Redshift hebben we een opgeslagen procedure gemaakt om CDC-records te verwerken en de doeltabel bij te werken.
Voorwaarden
In dit bericht wordt ervan uitgegaan dat je een actieve Amazon MSK Connect-stack in je omgeving hebt met de volgende componenten:
- Aurora MySQL die een database host. In dit bericht gebruik je de voorbeelddatabase
salesdb. - De Debezium MySQL-connector die draait op Amazon MSK Connect en die Amazon MSK in uw Amazon virtuele privécloud (Amazone VPC).
- Amazon MSK-cluster
Als je geen Amazon MSK Connect-stack hebt, volg dan de instructies in de MSK Connect lab-opstelling en controleer of uw bronconnector repliceert gegevenswijzigingen in de Amazon MSK-onderwerpen.
U moet het Amazon Redshift-cluster inrichten in dezelfde VPC als het Amazon MSK-cluster. Als u er nog geen heeft geïmplementeerd, volgt u de stappen hier in de AWS-documentatie.
We gebruiken AWS Identity en Access Management (AWS IAM) authenticatie voor communicatie tussen Amazon MSK en Amazon Redshift-cluster. Zorg ervoor dat u een AWS IAM-rol heeft aangemaakt met een vertrouwensbeleid waarmee uw Amazon Redshift-cluster de rol op zich kan nemen. Zie voor informatie over het configureren van het vertrouwensbeleid voor de AWS IAM-rol Amazon Redshift autoriseren om namens u toegang te krijgen tot andere AWS-services. Nadat deze is gemaakt, moet de rol het volgende AWS IAM-beleid hebben, dat toestemming geeft voor communicatie met het Amazon MSK-cluster.
Vervang het ARN met xxx uit het bovenstaande voorbeeldbeleid door de ARN van uw Amazon MSK-cluster.
- Controleer ook of het Amazon Redshift-cluster toegang heeft tot het Amazon MSK-cluster. Voeg in de beveiligingsgroep van Amazon Redshift Cluster de inkomende regel toe voor de MSK-beveiligingsgroep die poort 9098 toestaat. Om te zien hoe u de roodverschuivingsclusterbeveiligingsgroep beheert, raadpleegt u VPC-beveiligingsgroepen beheren voor een cluster.

- En voeg in de beveiligingsgroep van het Amazon MSK-cluster de inkomende regel toe die poort 9098 toestaat als leider-IP-adres van uw Amazon Redshift Cluster, zoals weergegeven in het volgende diagram. U kunt het IP-adres voor het leiderknooppunt van uw Amazon Redshift Cluster vinden op het tabblad Eigenschappen van het Amazon Redshift-cluster AWS-beheerconsole.

walkthrough
Navigeer naar de Amazon Redshift-service vanuit de AWS Management Console en stel vervolgens Amazon Redshift-streamingopname voor Amazon MSK in door de volgende stappen uit te voeren:
- Schakel_case_sensitive_identifier in op true – Als u de standaardparametergroep voor Amazon Redshift Cluster gebruikt, kunt u deze niet instellen
enable_case_sensitive_identifiernaar waar. Je kunt nieuwe creëren parametergroep Metenable_case_sensitive_identifierop true en koppel het aan het Amazon Redshift-cluster. Nadat u parameterwaarden hebt gewijzigd, moet u alle clusters die aan de gewijzigde parametergroep zijn gekoppeld opnieuw opstarten. Het kan enkele minuten duren voordat het Amazon Redshift-cluster opnieuw opstart.
Deze configuratie waarde die bepaalt of naam-ID's van databases, tabellen en kolommen hoofdlettergevoelig zijn. Als u klaar bent, opent u een nieuwe Amazon Redshift Query Editor V2, zodat de door ons aangebrachte configuratiewijzigingen worden weergegeven en volgt u vervolgens de volgende stappen.
- Maak een extern schema dat is toegewezen aan de streaminggegevensbron.
Als u klaar bent, controleert u of u onderstaande tabellen ziet die zijn gemaakt met MSK-onderwerpen:
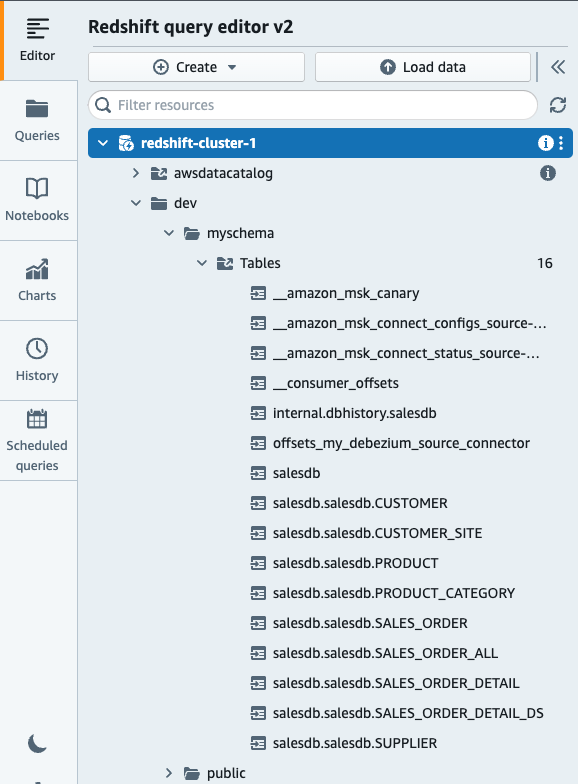
- Maak een gerealiseerde weergave die verwijst naar het externe schema.
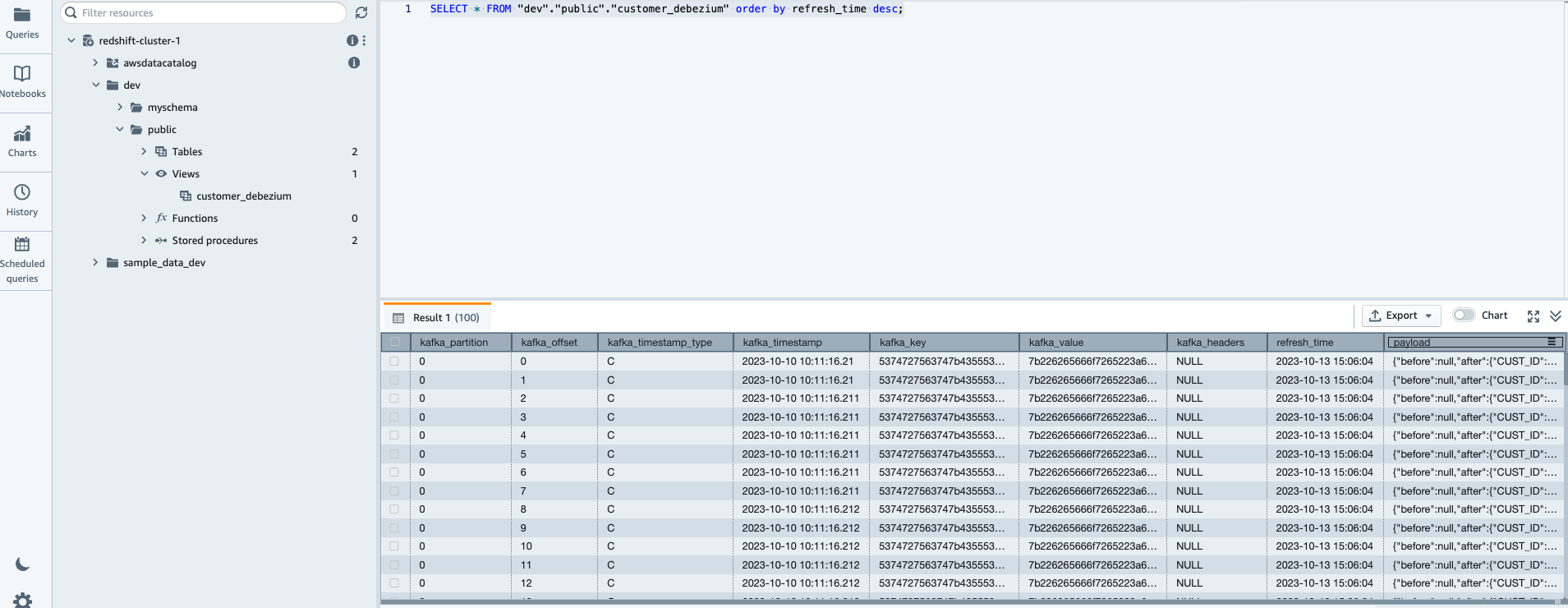
Nu kunt u de nieuw gemaakte gematerialiseerde weergave customer_debezium opvragen met behulp van de onderstaande opdracht.
Controleer of de gerealiseerde weergave is gevuld met de CDC-records
- VERNIEUW GEMATERIALISEERDE WEERGAVE (optioneel). Deze stap is optioneel zoals we al hebben gespecificeerd
AUTO REFRESH AS YEStijdens het maken van MV (gematerialiseerde weergave).
OPMERKING: Bovenstaande weergave wordt automatisch vernieuwd, wat betekent dat als u de records niet onmiddellijk ziet, u een paar seconden moet wachten en de select-instructie opnieuw moet uitvoeren. De Amazon Redshift streaming-opnameweergave wordt ook geleverd met de optie van handmatig vernieuwen, waarmee u het object handmatig kunt vernieuwen. U kunt de volgende query gebruiken die streaminggegevens onmiddellijk naar het Redshift-object haalt.
Verwerk CDC-records in Amazon Redshift
In de volgende stappen maken we de verzameltabel om de CDC-gegevens op te slaan. Dit is de doeltabel die de laatste momentopname bevat en de opgeslagen procedure om CDC-records te verwerken en bij te werken in de doeltabel.
- Verzameltabel maken: De opsteltafel is een tijdelijke tabel die alle gegevens bevat die zullen worden gebruikt om wijzigingen aan te brengen in de doel tafel, inclusief zowel updates als inserts.
- Doeltabel maken
Wij gebruiken customer_target tabel om de verwerkte CDC-gebeurtenissen te laden.
- creëren
Last_extract_timedebezium-tabel en Dummy-waarde invoegen.
We moeten de tijdstempel van de laatst geëxtraheerde CDC-gebeurtenissen opslaan. Wij gebruiken van debezium_last_extract tafel voor dit doel. Voor de eerste registratie voegen we een dummywaarde in, waardoor we een vergelijking kunnen maken tussen de huidige en de volgende CDC-verwerkingstijdstempel.
- Maak een opgeslagen procedure
Deze opgeslagen procedure verwerkt de CDC-records en werkt de doeltabel bij met de laatste wijzigingen.

Test de oplossing
Voorbeeld bijwerken salesdb gehost op Amazon Aurora
- Dit wordt jouw Amazon Aurora database en we hebben er toegang toe vanuit Amazon Elastic Compute Cloud (Amazon EC2) exemplaar met
Name= KafkaClientInstance. - Alstublieft vervang het Amazon Aurora-eindpunt door de waarde van uw Amazon Aurora-eindpunt en voer de volgende opdracht uit en de
use salesdb.
- Voer een update uit, voeg in en verwijder een van de gemaakte tabellen. Je kunt de update ook meerdere keren uitvoeren om de laatst bijgewerkte record later in Amazon Redshift te controleren.
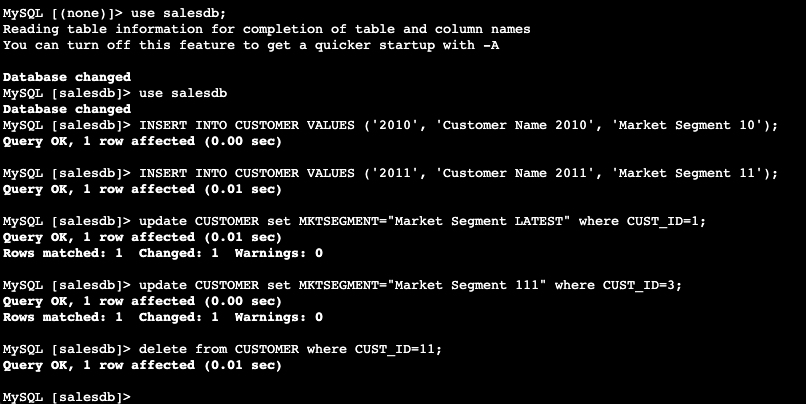
- Roep de opgeslagen procedure aan incrementele_synchronisatie_klant gemaakt in de bovenstaande stappen vanuit Amazon Redshift Query Editor v2. U kunt proc handmatig uitvoeren met de volgende opdracht of plan het in.
call incremental_sync_customer();- Controleer de doeltabel voor de laatste wijzigingen. Deze stap is bedoeld om de nieuwste waarden in de doeltabel te controleren. U zult zien dat alle updates en verwijderingen die u in de brontabel hebt uitgevoerd, bovenaan worden weergegeven als resultaatvolgorde
refresh_time.

De oplossing uitbreiden
In deze oplossing hebben we CDC-verwerking voor de klantentabel laten zien, en u kunt dezelfde aanpak gebruiken om deze uit te breiden naar andere tabellen in het voorbeeld salesdb database of voeg meer databases toe MSK Connect-configuratie eigendom database.include.list.
Onze voorgestelde aanpak kan werken met elke MySQL-bron die wordt ondersteund door Debezium MySQL bron Kafka-connector. Op dezelfde manier moet u, om dit voorbeeld uit te breiden naar uw werkbelastingen en gebruiksscenario's, de staging- en doeltabellen maken volgens het schema van de brontabel. Dan moet je de coalesce(payload.after."CUST_ID",payload.before."CUST_ID")::varchar as customer_id instructies met de kolomnamen en typen in uw bron- en doeltabellen. Zoals in het voorbeeld in dit bericht hebben we LZO-codering gebruikt als LZO-codering, wat goed werkt voor CHAR- en VARCHAR-kolommen die zeer lange tekenreeksen opslaan. U kunt BYTEDICT ook gebruiken als dit overeenkomt met uw gebruiksscenario. Een andere overweging waarmee u rekening moet houden bij het maken van doel- en faseringstabellen is het kiezen van een distributiestijl en -sleutel op basis van gegevens in de brondatabase. Hier hebben we de distributiestijl als sleutel gekozen met Customer_id, die gebaseerd is op brongegevens en schema-updates door de genoemde best practices te volgen hier.
Schoonmaken
- Verwijder alle Amazon Redshift-clusters
- Verwijder Amazon MSK Cluster en MSK Connect Cluster
- Als u Amazon Redshift-clusters niet wilt verwijderen, kunt u MV en tabellen die tijdens dit bericht zijn gemaakt handmatig verwijderen met behulp van onderstaande opdrachten:
Verwijder ook de inkomende beveiligingsregels die zijn toegevoegd aan uw Amazon Redshift- en Amazon MSK-clusters, samen met de AWS IAM-rollen die zijn aangemaakt in het gedeelte Vereisten.
Conclusie
In dit bericht hebben we je laten zien hoe Amazon Redshift-streaming-opname zorgde voor een hoge doorvoer en lage latentie-opname van streaminggegevens van Amazon Kinesis-gegevensstromen en Amazon MSK naar een gematerialiseerde visie van Amazon Redshift. We hebben de snelheid verhoogd en de kosten voor het streamen van gegevens naar Amazon Redshift verlaagd door de noodzaak om gebruik te maken van tussenliggende diensten te elimineren.
Verder hebben we ook laten zien hoe CDC-gegevens na generatie snel kunnen worden verwerkt, met behulp van een eenvoudige SQL-interface waarmee klanten bijna realtime analyses kunnen uitvoeren op verschillende gegevensbronnen (bijv. Internet-of-Things [IoT]-apparaten, systeemtelemetrie gegevens of clickstreamgegevens) van een drukke website of applicatie.
Terwijl u de opties verkent om bijna realtime analyses voor uw CDC-gegevens te vereenvoudigen en mogelijk te maken,
We hopen dat dit bericht u waardevolle begeleiding biedt. We verwelkomen alle gedachten of vragen in het opmerkingengedeelte.
Over de auteurs
 Umesh Chaudhari is een streamingoplossingenarchitect bij AWS. Hij werkt samen met AWS-klanten om realtime gegevensverwerkingssystemen te ontwerpen en bouwen. Hij heeft 13 jaar werkervaring in software-engineering, waaronder het ontwerpen, ontwerpen en ontwikkelen van data-analysesystemen.
Umesh Chaudhari is een streamingoplossingenarchitect bij AWS. Hij werkt samen met AWS-klanten om realtime gegevensverwerkingssystemen te ontwerpen en bouwen. Hij heeft 13 jaar werkervaring in software-engineering, waaronder het ontwerpen, ontwerpen en ontwikkelen van data-analysesystemen.
 Vishal Khatri is Sr. Technical Account Manager en Analytics-specialist bij AWS. Vishal werkt samen met de staats- en lokale overheid en helpt bij het opleiden en delen van best practices met klanten door leiding te geven aan en eigenaar te zijn van de ontwikkeling en levering van technische inhoud, terwijl ze end-to-end klantoplossingen ontwerpen.
Vishal Khatri is Sr. Technical Account Manager en Analytics-specialist bij AWS. Vishal werkt samen met de staats- en lokale overheid en helpt bij het opleiden en delen van best practices met klanten door leiding te geven aan en eigenaar te zijn van de ontwikkeling en levering van technische inhoud, terwijl ze end-to-end klantoplossingen ontwerpen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/break-data-silos-and-stream-your-cdc-data-with-amazon-redshift-streaming-and-amazon-msk/

