Veel organisaties, klein en groot, werken aan het migreren en moderniseren van hun analyseworkloads op Amazon Web Services (AWS). Er zijn veel redenen voor klanten om naar AWS te migreren, maar een van de belangrijkste redenen is de mogelijkheid om volledig beheerde services te gebruiken in plaats van tijd te besteden aan het onderhouden van de infrastructuur, patching, monitoring, back-ups en meer. Leiderschaps- en ontwikkelingsteams kunnen meer tijd besteden aan het optimaliseren van de huidige oplossingen en zelfs aan het experimenteren met nieuwe gebruiksscenario's, in plaats van aan het onderhouden van de huidige infrastructuur.
Omdat u snel kunt schakelen met AWS, moet u ook verantwoordelijk zijn voor de gegevens die u ontvangt en verwerkt terwijl u doorgaat met opschalen. Deze verantwoordelijkheden omvatten onder meer het naleven van wet- en regelgeving op het gebied van gegevensprivacy en het niet opslaan of openbaar maken van gevoelige gegevens zoals persoonlijk identificeerbare informatie (PII) of beschermde gezondheidsinformatie (PHI) uit upstream-bronnen.
In dit artikel doorlopen we een architectuur op hoog niveau en een specifieke gebruikscasus die laat zien hoe u het dataplatform van uw organisatie kunt blijven schalen zonder dat u grote hoeveelheden ontwikkelingstijd hoeft te besteden aan het aanpakken van zorgen over gegevensprivacy. We gebruiken AWS lijm om PII-gegevens te detecteren, maskeren en redigeren voordat deze erin worden geladen Amazon OpenSearch-service.
Overzicht oplossingen
Het volgende diagram illustreert de oplossingsarchitectuur op hoog niveau. We hebben alle lagen en componenten van ons ontwerp gedefinieerd in lijn met de AWS goed ontworpen raamwerk voor data-analyse.
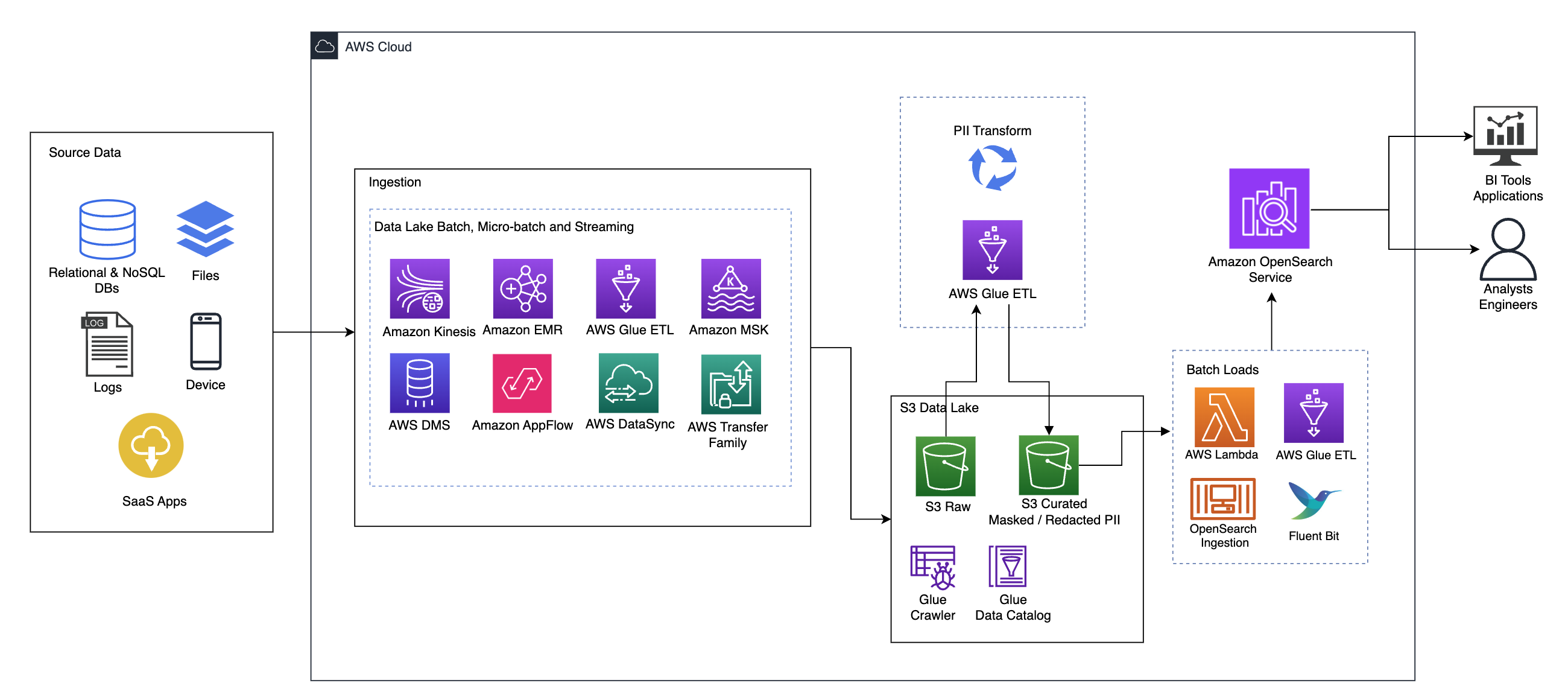
De architectuur bestaat uit een aantal componenten:
Brongegevens
Gegevens kunnen afkomstig zijn uit vele tientallen tot honderden bronnen, waaronder databases, bestandsoverdrachten, logboeken, Software as a Service (SaaS)-applicaties en meer. Organisaties hebben mogelijk niet altijd controle over welke gegevens via deze kanalen en in hun downstream-opslag en applicaties binnenkomen.
Inname: Data Lake-batch, micro-batch en streaming
Veel organisaties plaatsen hun brongegevens op verschillende manieren in hun data lake, waaronder batch-, micro-batch- en streaming-taken. Bijvoorbeeld, Amazon EMR, AWS lijm en AWS-databasemigratieservice (AWS DMS) kunnen allemaal worden gebruikt om batch- en/of streaming-bewerkingen uit te voeren die naar een datameer zinken Amazon eenvoudige opslagservice (Amazone S3). Amazon-app-stroom kan worden gebruikt om gegevens van verschillende SaaS-applicaties over te dragen naar een datameer. AWS-gegevenssynchronisatie en AWS Transfer-familie kan helpen bij het verplaatsen van bestanden van en naar een datameer via een aantal verschillende protocollen. Amazon Kinesis en Amazon MSK hebben ook mogelijkheden om gegevens rechtstreeks naar een datameer op Amazon S3 te streamen.
S3 datameer
Het gebruik van Amazon S3 voor uw datameer past in de moderne datastrategie. Het biedt goedkope opslag zonder dat dit ten koste gaat van de prestaties, betrouwbaarheid of beschikbaarheid. Met deze aanpak kunt u waar nodig rekenkracht naar uw gegevens brengen en alleen betalen voor de capaciteit die deze nodig heeft.
In deze architectuur kunnen onbewerkte gegevens afkomstig zijn uit verschillende bronnen (intern en extern), die gevoelige gegevens kunnen bevatten.
Met behulp van AWS Glue-crawlers kunnen we de gegevens ontdekken en catalogiseren, die de tabelschema's voor ons zullen bouwen, en uiteindelijk het eenvoudig maken om AWS Glue ETL te gebruiken met de PII-transformatie om gevoelige gegevens die mogelijk zijn geland te detecteren, maskeren of redigeren. in het datameer.
Bedrijfscontext en datasets
Om de waarde van onze aanpak te demonstreren, stellen we ons voor dat u deel uitmaakt van een data-engineeringteam voor een financiële dienstverlener. Uw vereisten zijn het detecteren en maskeren van gevoelige gegevens wanneer deze worden opgenomen in de cloudomgeving van uw organisatie. De gegevens zullen worden gebruikt door stroomafwaartse analytische processen. In de toekomst kunnen uw gebruikers veilig historische betalingstransacties doorzoeken op basis van datastromen verzameld uit interne banksystemen. Zoekresultaten van operationele teams, klanten en interfacetoepassingen moeten in gevoelige velden worden gemaskeerd.
De volgende tabel toont de gegevensstructuur die voor de oplossing wordt gebruikt. Voor de duidelijkheid hebben we onbewerkte kolomnamen toegewezen aan samengestelde kolomnamen. U zult merken dat meerdere velden binnen dit schema als gevoelige gegevens worden beschouwd, zoals voornaam, achternaam, burgerservicenummer (SSN), adres, creditcardnummer, telefoonnummer, e-mailadres en IPv4-adres.
| Ruwe kolomnaam | Samengestelde kolomnaam | Type |
| c0 | Voornaam | snaar |
| c1 | achternaam | snaar |
| c2 | ssn | snaar |
| c3 | adres | snaar |
| c4 | Postcode | snaar |
| c5 | Land | snaar |
| c6 | aankoop_site | snaar |
| c7 | creditcardnummer | snaar |
| c8 | creditcard_provider | snaar |
| c9 | valuta | snaar |
| c10 | aankoopwaarde | geheel getal |
| c11 | transactie datum | gegevens |
| c12 | telefoonnummer | snaar |
| c13 | snaar | |
| c14 | ipv4 | snaar |
Gebruiksvoorbeeld: PII-batchdetectie vóór laden naar OpenSearch Service
Klanten die de volgende architectuur implementeren, hebben hun datameer op Amazon S3 gebouwd om verschillende soorten analyses op schaal uit te voeren. Deze oplossing is geschikt voor klanten die geen realtime opname in de OpenSearch Service nodig hebben en van plan zijn tools voor gegevensintegratie te gebruiken die volgens een schema worden uitgevoerd of worden geactiveerd door gebeurtenissen.
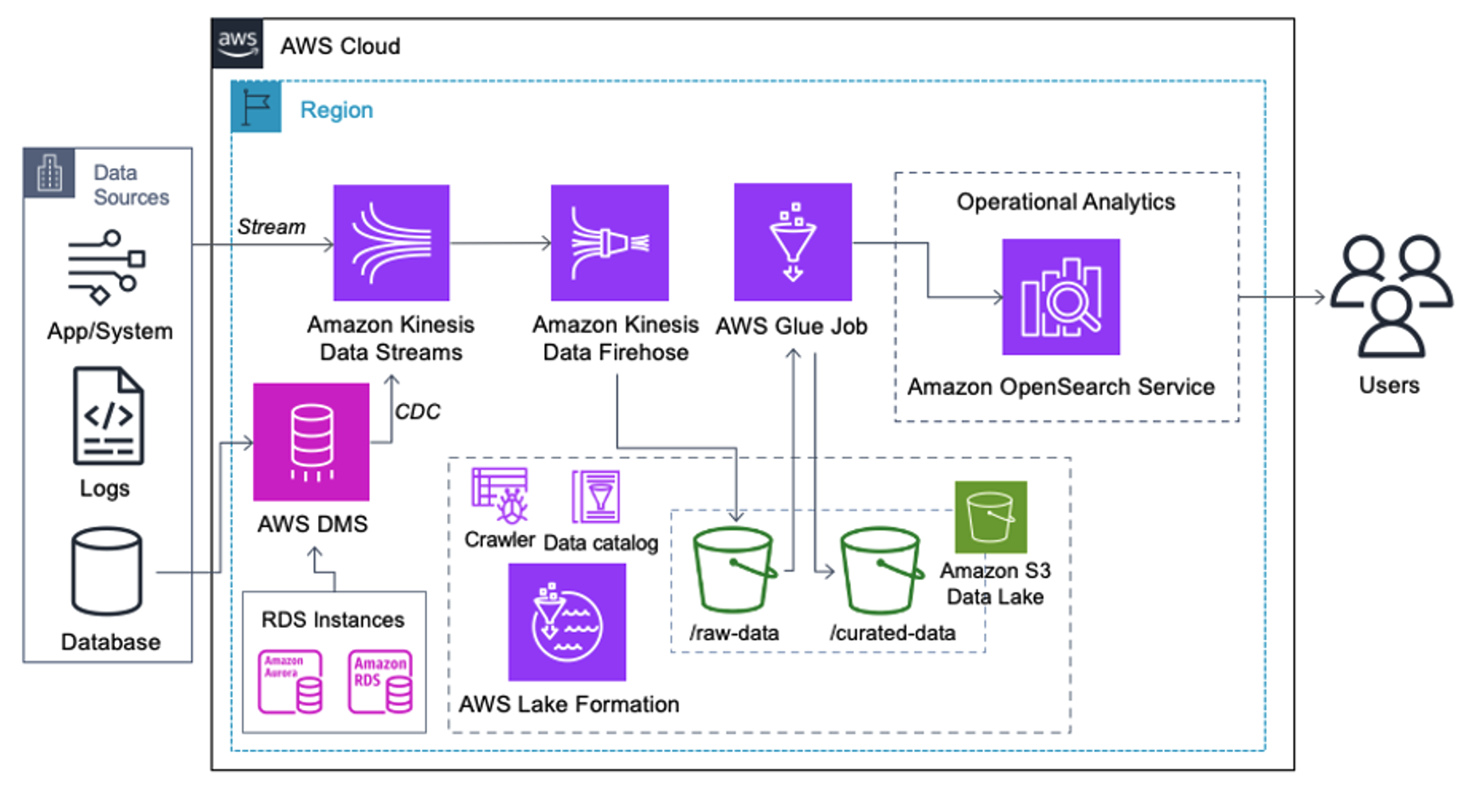
Voordat datarecords op Amazon S3 terechtkomen, implementeren we een opnamelaag om alle datastromen betrouwbaar en veilig naar het datameer te brengen. Kinesis Data Streams wordt ingezet als opnamelaag voor een versnelde inname van gestructureerde en semi-gestructureerde datastromen. Voorbeelden hiervan zijn relationele databasewijzigingen, applicaties, systeemlogboeken of clickstreams. Voor gebruiksscenario's voor het vastleggen van wijzigingsgegevens (CDC) kunt u Kinesis Data Streams gebruiken als doelwit voor AWS DMS. Applicaties of systemen die streams genereren die gevoelige gegevens bevatten, worden via een van de drie ondersteunde methoden naar de Kinesis-datastroom verzonden: de Amazon Kinesis Agent, de AWS SDK voor Java of de Kinesis Producer Library. Als laatste stap, Amazon Kinesis-gegevens Firehose helpt ons op betrouwbare wijze vrijwel realtime gegevensbatches in onze S3-datalake-bestemming te laden.
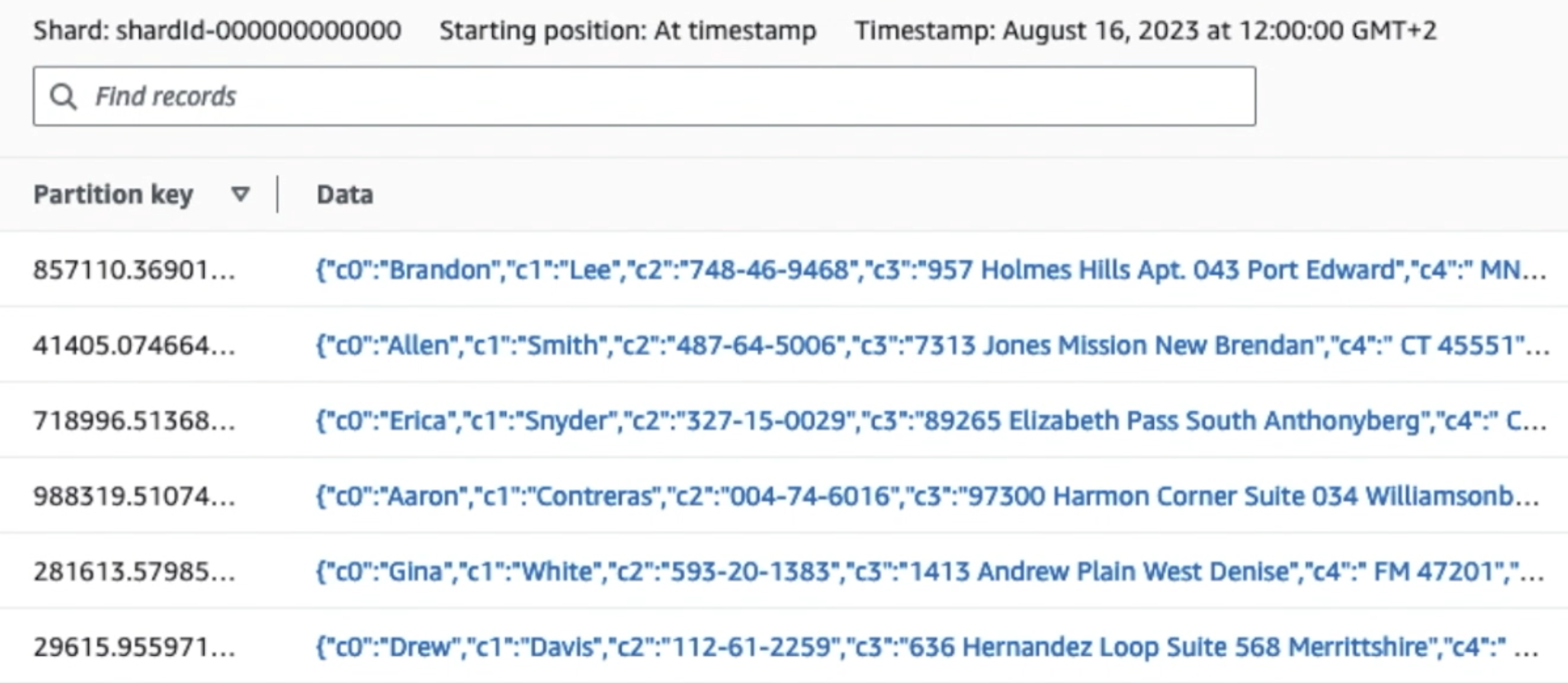
De volgende schermafbeelding laat zien hoe gegevens door Kinesis Data Streams stromen via de Gegevensviewer en haalt voorbeeldgegevens op die op het onbewerkte S3-voorvoegsel terechtkomen. Voor deze architectuur hebben we de gegevenslevenscyclus voor S3-voorvoegsels gevolgd, zoals aanbevolen in Stichting Datalake.
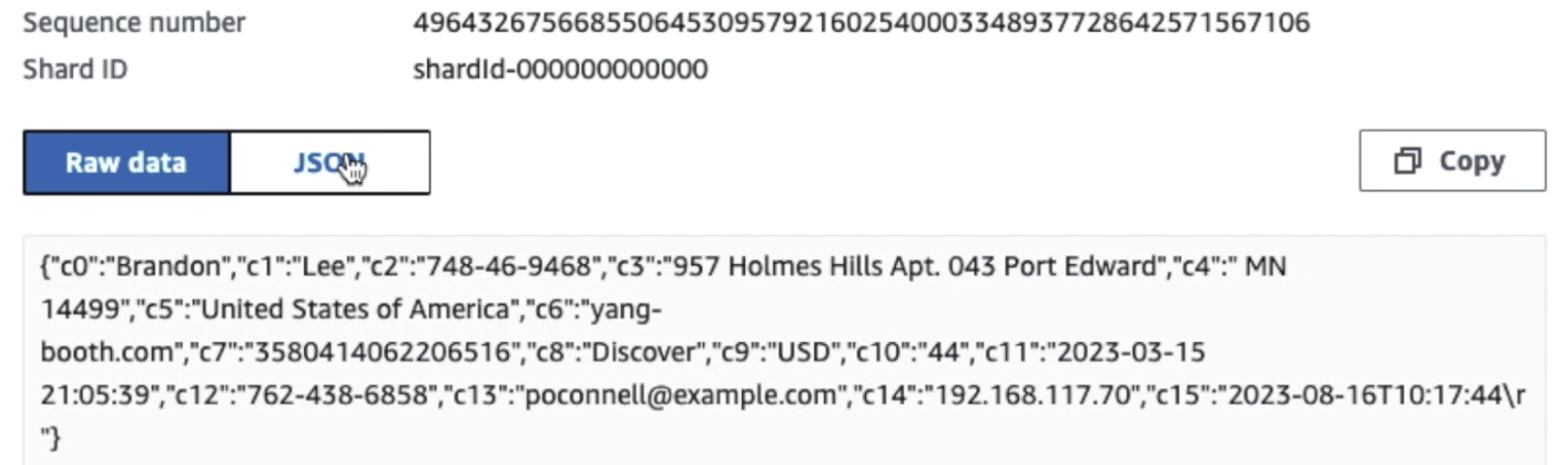
Zoals u kunt zien aan de hand van de details van de eerste record in de volgende schermafbeelding, volgt de JSON-payload hetzelfde schema als in de vorige sectie. Je kunt zien dat de niet-geredigeerde gegevens de Kinesis-gegevensstroom binnenstromen, die later in de volgende fasen versluierd zal worden.
Nadat de gegevens zijn verzameld en opgenomen in Kinesis Data Streams en met behulp van Kinesis Data Firehose in de S3-bucket zijn afgeleverd, neemt de verwerkingslaag van de architectuur het over. We gebruiken de AWS Glue PII-transformatie om de detectie en maskering van gevoelige gegevens in onze pijplijn te automatiseren. Zoals blijkt uit het volgende workflowdiagram, hebben we een visuele ETL-aanpak zonder code gevolgd om onze transformatietaak in AWS Glue Studio te implementeren.
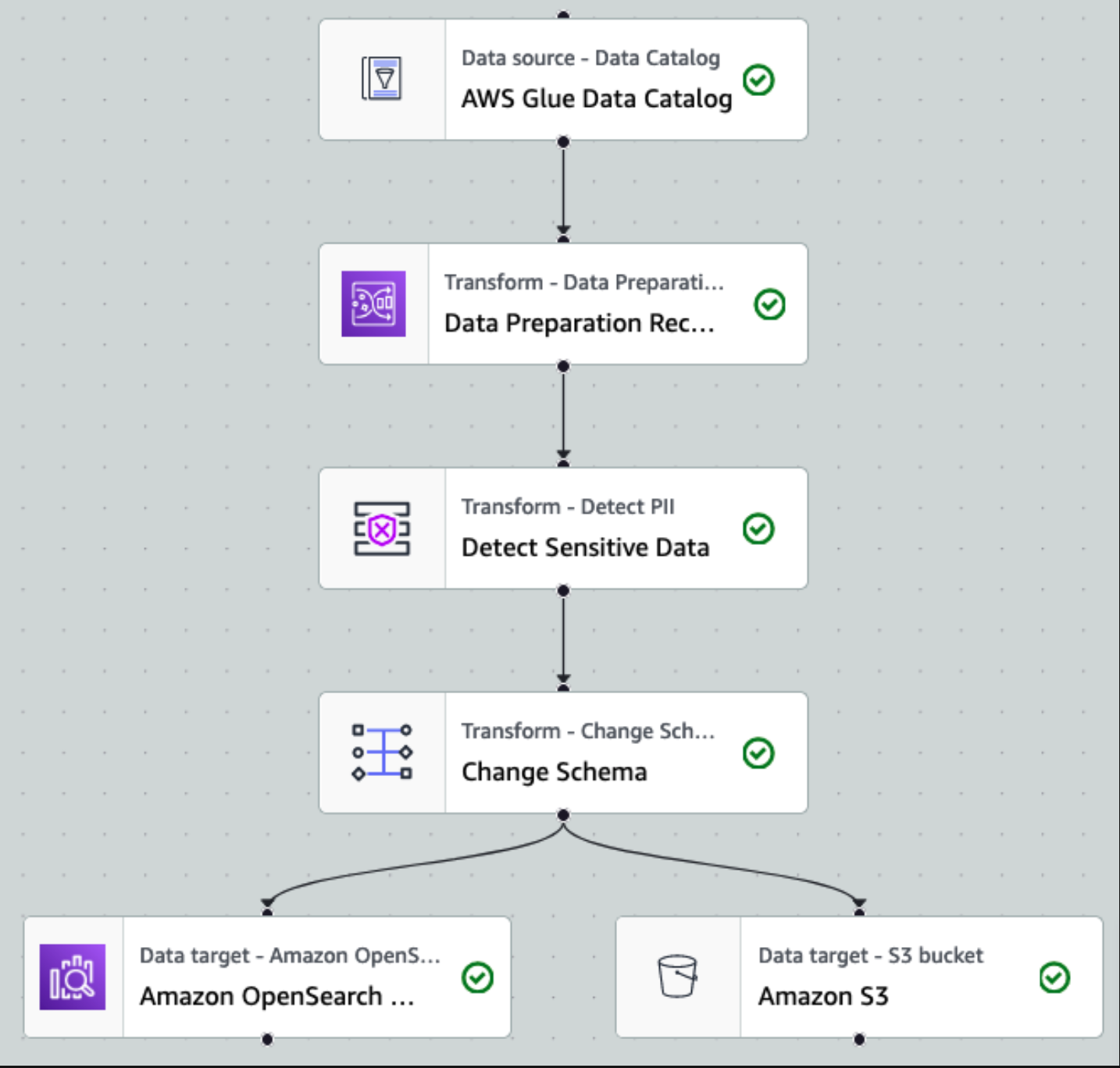
Eerst hebben we toegang tot de onbewerkte brongegevenscatalogustabel uit de pii_data_db database. De tabel heeft de schemastructuur die in de vorige sectie is gepresenteerd. Om de onbewerkte verwerkte gegevens bij te houden, gebruikten we baan bladwijzers.

We maken gebruik van de AWS Glue DataBrew-recepten in de visuele ETL-taak van AWS Glue Studio om twee datumattributen te transformeren zodat ze compatibel zijn met de verwachte OpenSearch formaten. Hierdoor kunnen we een volledige no-code-ervaring hebben.

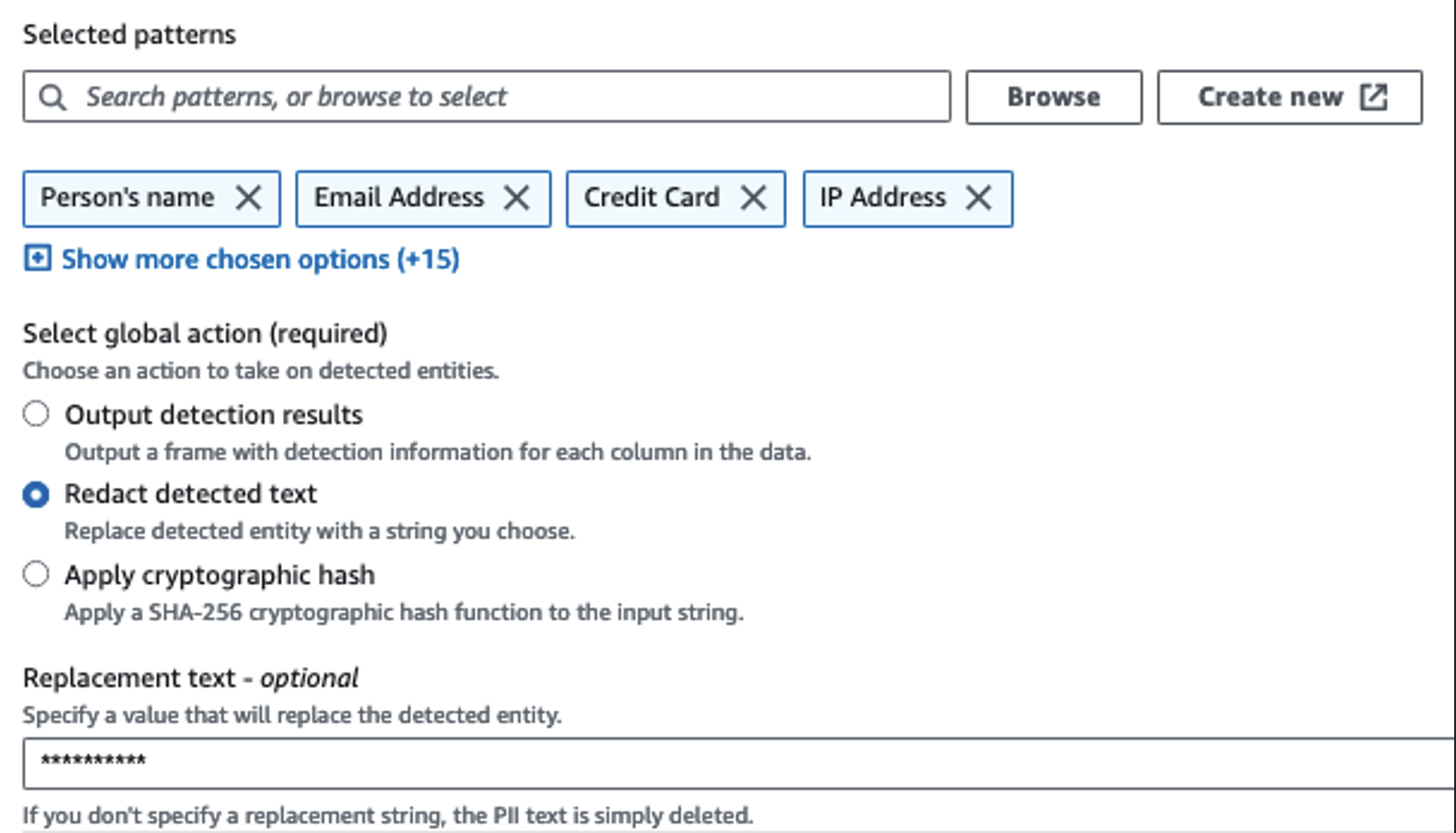
We gebruiken de actie PII detecteren om gevoelige kolommen te identificeren. We laten AWS Glue dit bepalen op basis van geselecteerde patronen, detectiedrempel en voorbeeldgedeelte van rijen uit de dataset. In ons voorbeeld hebben we patronen gebruikt die specifiek van toepassing zijn op de Verenigde Staten (zoals SSN's) en mogelijk geen gevoelige gegevens uit andere landen detecteren. U kunt zoeken naar beschikbare categorieën en locaties die van toepassing zijn op uw gebruiksscenario of reguliere expressies (regex) gebruiken in AWS Glue om detectie-entiteiten te creëren voor gevoelige gegevens uit andere landen.
Het is belangrijk om de juiste bemonsteringsmethode te selecteren die AWS Glue biedt. In dit voorbeeld is het bekend dat de gegevens die uit de stream binnenkomen in elke rij gevoelige gegevens bevatten, dus het is niet nodig om 100% van de rijen in de dataset te bemonsteren. Als u een vereiste heeft waarbij er geen gevoelige gegevens naar downstreambronnen mogen worden verzonden, overweeg dan om 100% van de gegevens te bemonsteren voor de door u gekozen patronen, of scan de volledige gegevensset en handel op elke afzonderlijke cel om ervoor te zorgen dat alle gevoelige gegevens worden gedetecteerd. Het voordeel dat u haalt uit het nemen van monsters zijn lagere kosten, omdat u niet zoveel gegevens hoeft te scannen.

Met de actie PII detecteren kunt u een standaardtekenreeks selecteren bij het maskeren van gevoelige gegevens. In ons voorbeeld gebruiken we de tekenreeks **********.
We gebruiken de mapping-bewerking toepassen om onnodige kolommen te hernoemen en te verwijderen, zoals ingestion_year, ingestion_month en ingestion_day. Met deze stap kunnen we ook het gegevenstype van een van de kolommen wijzigen (purchase_value) van tekenreeks naar geheel getal.

Vanaf dit punt wordt de taak opgesplitst in twee uitvoerbestemmingen: OpenSearch Service en Amazon S3.
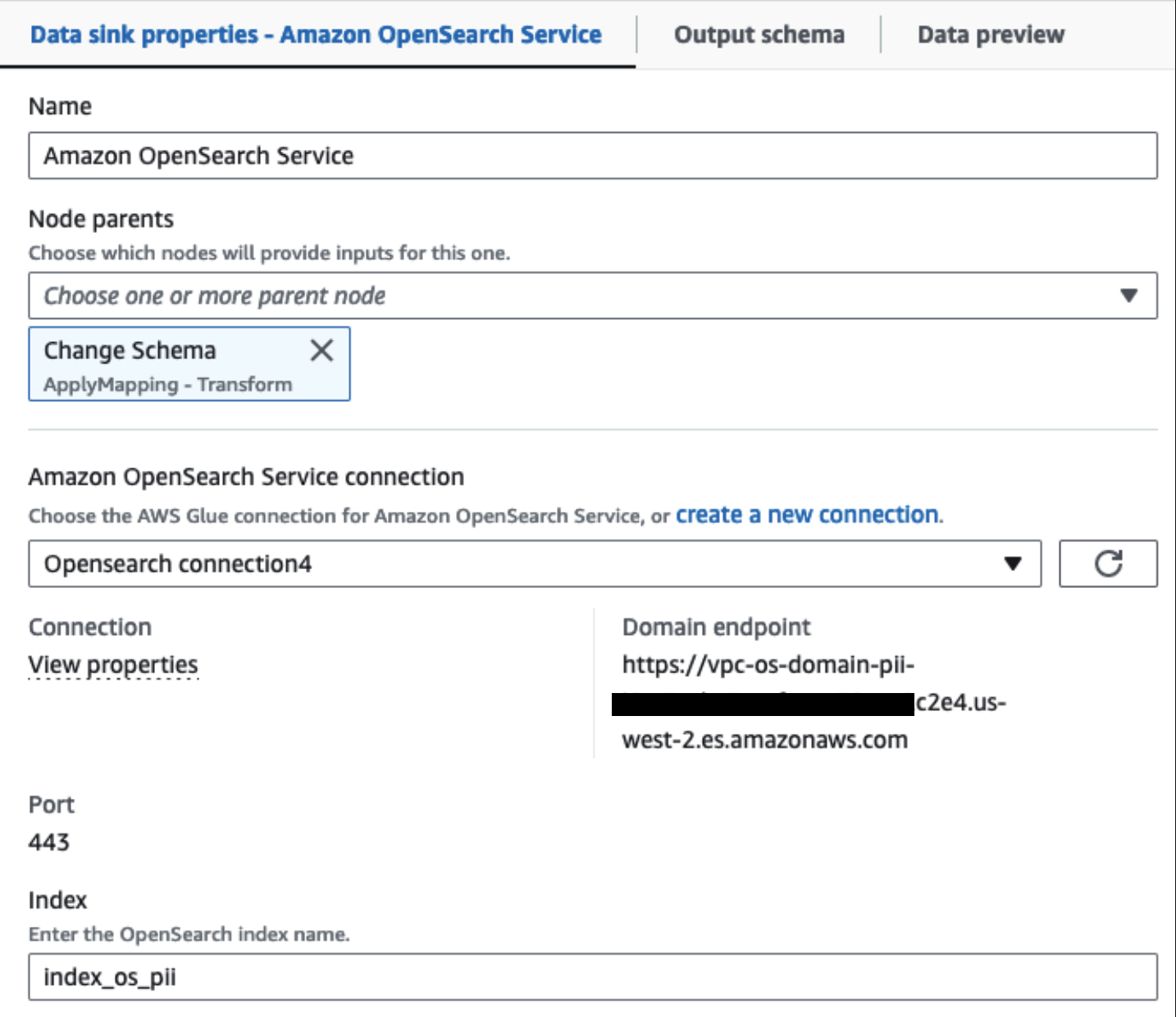
Ons ingerichte OpenSearch Service-cluster is verbonden via de OpenSearch ingebouwde connector voor Glue. We specificeren de OpenSearch Index waarnaar we willen schrijven en de connector verwerkt de inloggegevens, het domein en de poort. In de onderstaande schermafbeelding schrijven we naar de opgegeven index index_os_pii.
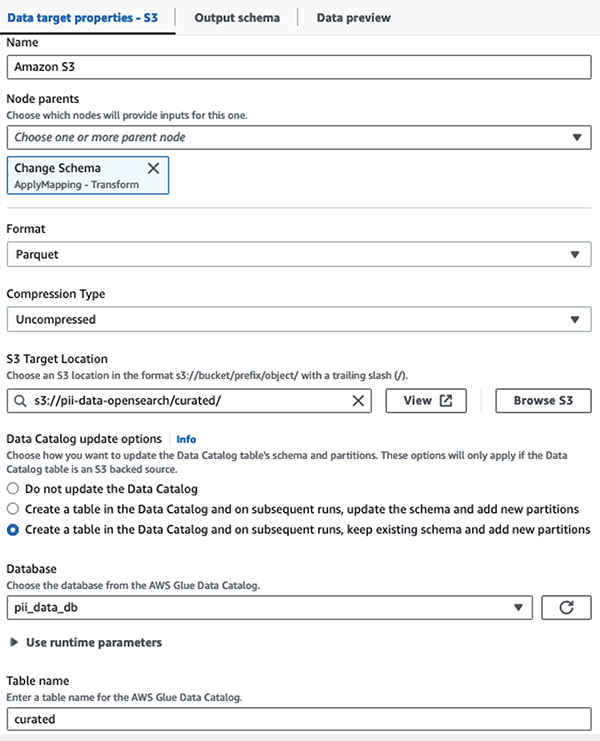
We slaan de gemaskeerde dataset op in het samengestelde S3-voorvoegsel. Daar hebben we gegevens die zijn genormaliseerd voor een specifieke gebruikssituatie en veilig gebruik door datawetenschappers of voor ad-hocrapportagebehoeften.
Voor uniform beheer, toegangscontrole en audittrails van alle gegevenssets en gegevenscatalogi-tabellen kunt u gebruik maken van AWS Lake-formatie. Dit helpt u de toegang tot de AWS Glue Data Catalog-tabellen en onderliggende gegevens te beperken tot alleen die gebruikers en rollen aan wie de benodigde machtigingen zijn verleend om dit te doen.
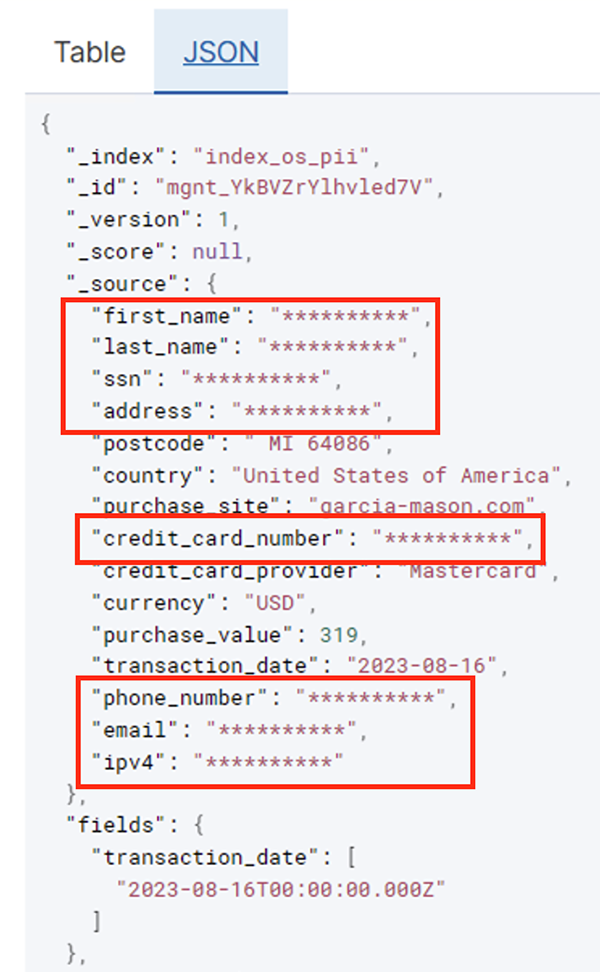
Nadat de batchtaak succesvol is uitgevoerd, kunt u OpenSearch Service gebruiken om zoekopdrachten of rapporten uit te voeren. Zoals te zien is in de volgende schermafbeelding maskeerde de pijplijn gevoelige velden automatisch zonder dat er code werd ontwikkeld.

U kunt trends identificeren uit de operationele gegevens, zoals het aantal transacties per dag gefilterd per creditcardaanbieder, zoals weergegeven in de voorgaande schermafbeelding. U kunt ook de locaties en domeinen bepalen waar gebruikers aankopen doen. De transaction_date attribuut helpt ons deze trends in de loop van de tijd te zien. De volgende schermafbeelding toont een record waarin alle transactiegegevens op de juiste manier zijn geredigeerd.
Voor alternatieve methoden voor het laden van gegevens in Amazon OpenSearch raadpleegt u Streaminggegevens laden in Amazon OpenSearch Service.
Bovendien kunnen gevoelige gegevens ook worden ontdekt en gemaskeerd met behulp van andere AWS-oplossingen. Je zou bijvoorbeeld kunnen gebruiken Amazone Macie om gevoelige gegevens in een S3-bucket te detecteren en vervolgens te gebruiken Amazon begrijpt het om de gevoelige gegevens die zijn gedetecteerd te redigeren. Voor meer informatie, zie Algemene technieken om PHI- en PII-gegevens te detecteren met behulp van AWS Services.
Conclusie
In dit bericht werd het belang besproken van het omgaan met gevoelige gegevens binnen uw omgeving en verschillende methoden en architecturen om compliant te blijven en tegelijkertijd uw organisatie in staat te stellen snel te schalen. U zou nu een goed begrip moeten hebben van hoe u uw gegevens kunt detecteren, maskeren of redigeren en in de Amazon OpenSearch Service kunt laden.
Over de auteurs
 Michael Hamilton is een Sr Analytics Solutions Architect die zich richt op het helpen van zakelijke klanten bij het moderniseren en vereenvoudigen van hun analyseworkloads op AWS. Hij houdt van mountainbiken en brengt graag tijd door met zijn vrouw en drie kinderen als hij niet werkt.
Michael Hamilton is een Sr Analytics Solutions Architect die zich richt op het helpen van zakelijke klanten bij het moderniseren en vereenvoudigen van hun analyseworkloads op AWS. Hij houdt van mountainbiken en brengt graag tijd door met zijn vrouw en drie kinderen als hij niet werkt.
 Daniël Rozo is een Senior Solutions Architect die met AWS klanten in Nederland ondersteunt. Zijn passie is het ontwikkelen van eenvoudige data- en analyseoplossingen en het helpen van klanten bij de overstap naar moderne data-architecturen. Buiten zijn werk houdt hij van tennis en fietsen.
Daniël Rozo is een Senior Solutions Architect die met AWS klanten in Nederland ondersteunt. Zijn passie is het ontwikkelen van eenvoudige data- en analyseoplossingen en het helpen van klanten bij de overstap naar moderne data-architecturen. Buiten zijn werk houdt hij van tennis en fietsen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/detect-mask-and-redact-pii-data-using-aws-glue-before-loading-into-amazon-opensearch-service/

