Dit is een gastpost die samen met Scott Gutterman van de PGA TOUR is geschreven.
Generatieve kunstmatige intelligentie (generatieve AI) heeft nieuwe mogelijkheden mogelijk gemaakt voor het bouwen van intelligente systemen. Recente verbeteringen in op generatieve AI gebaseerde grote taalmodellen (LLM's) hebben het gebruik ervan in een verscheidenheid aan toepassingen rond het ophalen van informatie mogelijk gemaakt. Gezien de gegevensbronnen boden LLM's tools waarmee we binnen enkele weken een vraag- en antwoordchatbot konden bouwen, in plaats van wat jaren eerder zou hebben geduurd, en waarschijnlijk met slechtere prestaties. We hebben een Retrieval-Augmented-Generation (RAG)-oplossing geformuleerd waarmee de PGA TOUR een prototype kan creëren voor een toekomstig platform voor fanbetrokkenheid dat zijn gegevens op een interactieve manier en in een conversatieformaat toegankelijk zou kunnen maken voor fans.
Het gebruik van gestructureerde gegevens om vragen te beantwoorden vereist een manier om effectief gegevens te extraheren die relevant zijn voor de zoekopdracht van een gebruiker. We hebben een tekst-naar-SQL-aanpak geformuleerd waarbij de zoekopdracht in natuurlijke taal van een gebruiker wordt omgezet in een SQL-instructie met behulp van een LLM. De SQL wordt beheerd door Amazone Athene om de relevante gegevens terug te sturen. Deze gegevens worden opnieuw verstrekt aan een LLM, die wordt gevraagd de vraag van de gebruiker op basis van de gegevens te beantwoorden.
Voor het gebruik van tekstgegevens is een index nodig die kan worden gebruikt om te zoeken en relevante context te bieden aan een LLM om een zoekopdracht van een gebruiker te beantwoorden. Om het snel ophalen van informatie mogelijk te maken, gebruiken wij Amazon Kendra als index voor deze documenten. Wanneer gebruikers vragen stellen, doorzoekt onze virtuele assistent snel de Amazon Kendra-index om relevante informatie te vinden. Amazon Kendra maakt gebruik van natuurlijke taalverwerking (NLP) om zoekopdrachten van gebruikers te begrijpen en de meest relevante documenten te vinden. De relevante informatie wordt vervolgens aan de LLM verstrekt voor het genereren van definitieve antwoorden. Onze uiteindelijke oplossing is een combinatie van deze tekst-naar-SQL- en tekst-RAG-benaderingen.
In dit bericht belichten we hoe de AWS Generatief AI-innovatiecentrum werkte samen met de AWS professionele services en PGA TOUR om een prototype van een virtuele assistent te ontwikkelen met behulp van Amazonebodem waarmee fans op een naadloze, interactieve manier informatie kunnen verkrijgen over elk evenement, speler, hole of slagniveau. Amazon Bedrock is een volledig beheerde service die via één enkele API een keuze biedt uit goed presterende basismodellen (FM's) van toonaangevende AI-bedrijven zoals AI21 Labs, Anthropic, Cohere, Meta, Stability AI en Amazon, samen met een brede reeks mogelijkheden die u nodig hebt om generatieve AI-toepassingen te bouwen met beveiliging, privacy en verantwoorde AI.
Ontwikkeling: het gereedmaken van de gegevens
Zoals bij elk datagedreven project zullen de prestaties slechts zo goed zijn als de data. We hebben de gegevens verwerkt zodat de LLM relevante gegevens effectief kan opvragen en ophalen.
Voor de wedstrijdgegevens in tabelvorm hebben we ons gericht op een subset van gegevens die relevant zijn voor het grootste aantal gebruikersquery's en hebben we de kolommen intuïtief gelabeld, zodat ze gemakkelijker te begrijpen zijn voor LLM's. We hebben ook enkele hulpkolommen gemaakt om de LLM te helpen concepten te begrijpen waarmee hij anders misschien moeite zou hebben. Als een golfer bijvoorbeeld één slag minder dan par schiet (bijvoorbeeld in 3 schoten in de hole op een par 4 of in 4 schoten op een par 5), wordt dit gewoonlijk een slag genoemd. vogeltje. Als een gebruiker vraagt: “Hoeveel birdies heeft speler X het afgelopen jaar gemaakt?”, is alleen het hebben van de score en par in de tabel niet voldoende. Als gevolg hiervan hebben we kolommen toegevoegd om veelgebruikte golftermen aan te geven, zoals bogey, birdie en eagle. Daarnaast hebben we de Competitiegegevens gekoppeld aan een aparte videocollectie, door een kolom samen te voegen voor a video_id, waardoor onze app de video die bij een bepaalde opname hoort, uit de wedstrijdgegevens kan halen. We hebben het ook mogelijk gemaakt om tekstgegevens aan de tabelgegevens te koppelen, bijvoorbeeld door biografieën voor elke speler toe te voegen als tekstkolom. In de volgende afbeeldingen ziet u stapsgewijs hoe een query wordt verwerkt voor de tekst-naar-SQL-pijplijn. De cijfers geven de reeks stappen aan om een vraag te beantwoorden.
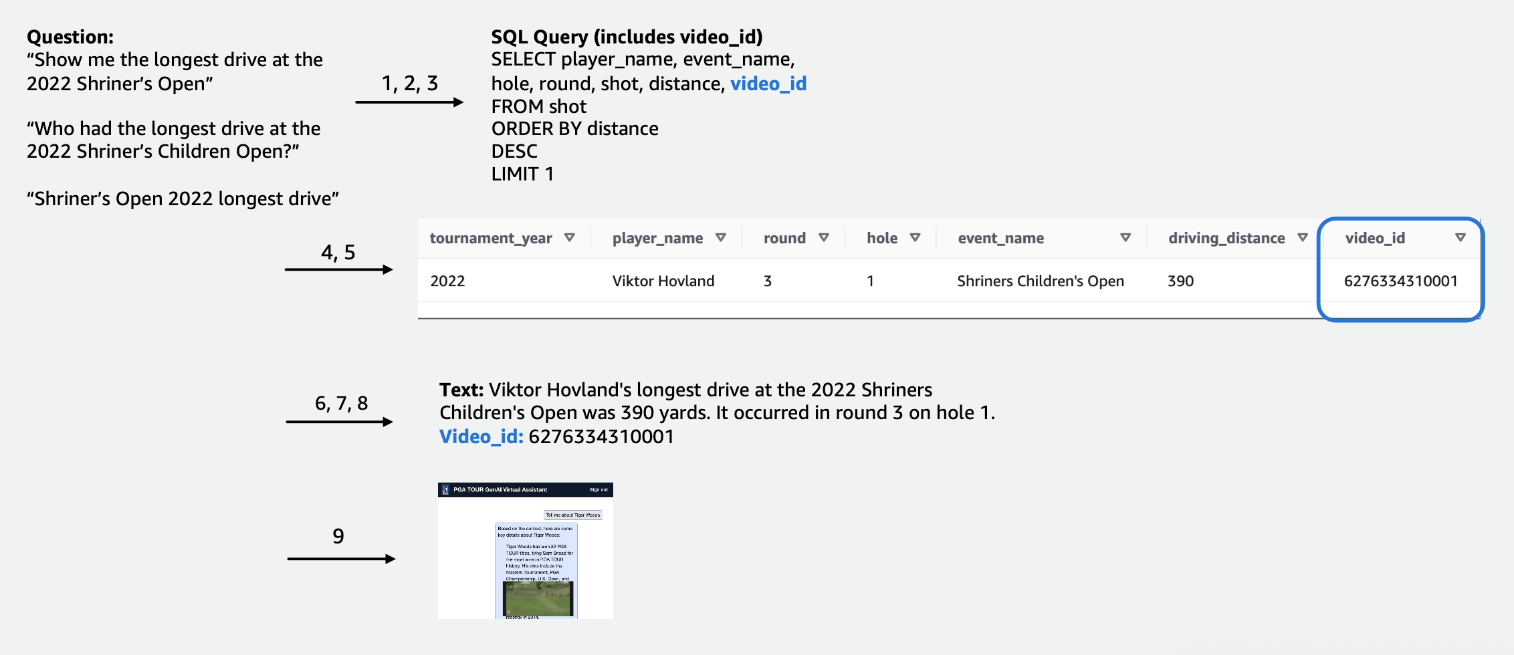
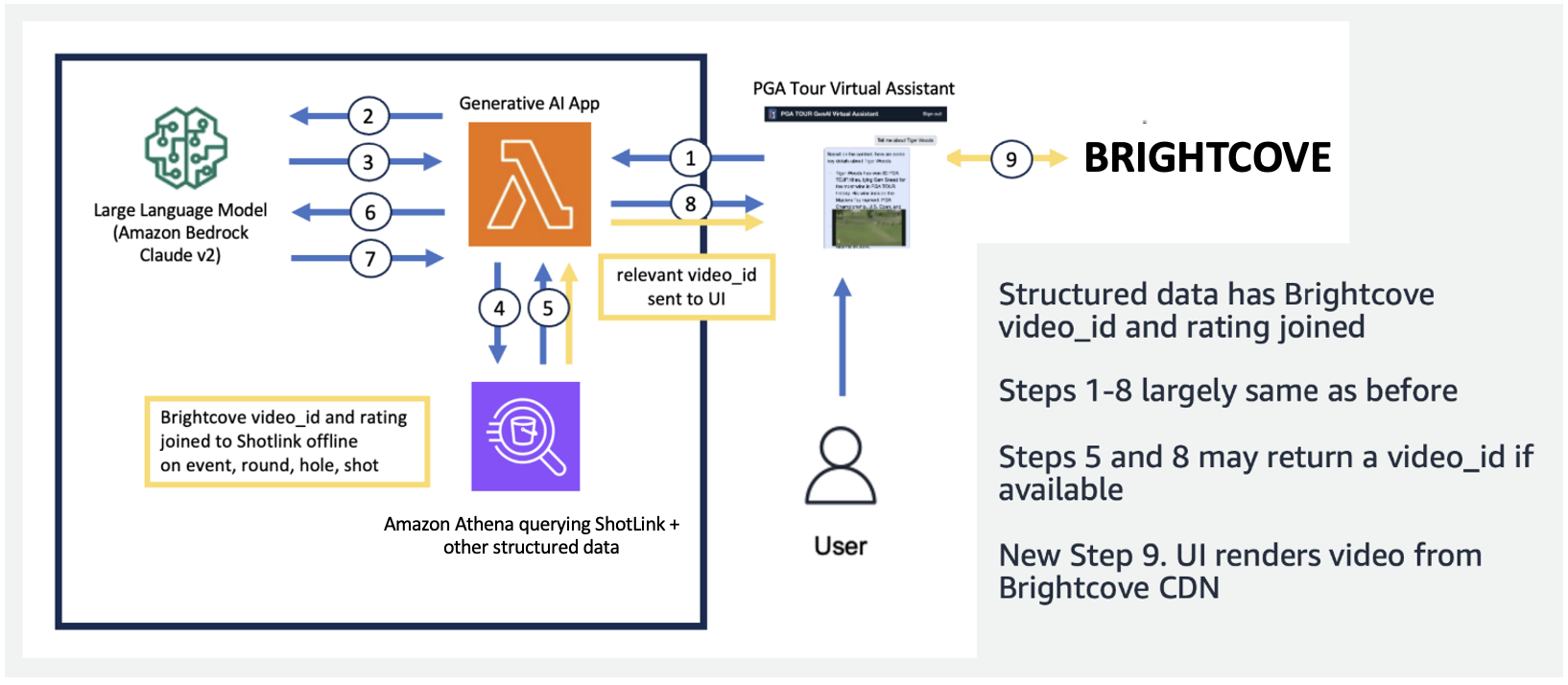
In de volgende afbeelding demonstreren we onze end-to-end pijplijn. We gebruiken AWS Lambda als onze orkestratiefunctie die verantwoordelijk is voor de interactie met verschillende gegevensbronnen, LLM's en foutcorrectie op basis van de gebruikersquery. Stappen 1-8 zijn vergelijkbaar met wat wordt weergegeven in de vervolgafbeelding. Er zijn kleine wijzigingen voor de ongestructureerde gegevens, die we hierna bespreken.
Tekstgegevens vereisen unieke verwerkingsstappen die lange documenten opsplitsen (of segmenteren) in delen die verteerbaar zijn voor de LLM, terwijl de samenhang van het onderwerp behouden blijft. We hebben met verschillende benaderingen geëxperimenteerd en zijn tot een chunking-schema op paginaniveau gekomen dat goed aansluit bij het formaat van de mediagidsen. We gebruikten Amazon Kendra, een beheerde service die zorgt voor het indexeren van documenten, zonder dat de insluitingen hoeven te worden gespecificeerd, terwijl het een eenvoudige API biedt voor het ophalen. De volgende afbeelding illustreert deze architectuur.

Dankzij de uniforme, schaalbare pijplijn die we hebben ontwikkeld, kan de PGA TOUR opschalen naar de volledige gegevensgeschiedenis, waarvan een deel teruggaat tot de 1800e eeuw. Het maakt toekomstige toepassingen mogelijk die de cursuscontext live kunnen volgen om rijke realtime ervaringen te creëren.
Ontwikkeling: LLM's evalueren en generatieve AI-toepassingen ontwikkelen
We hebben de LLM's van eerste en derde partijen die beschikbaar zijn in Amazon Bedrock zorgvuldig getest en geëvalueerd om het model te kiezen dat het meest geschikt is voor onze pijplijn en gebruiksscenario. We hebben Claude v2 en Claude Instant van Anthropic geselecteerd op Amazon Bedrock. Voor onze laatste gestructureerde en ongestructureerde datapijplijn zien we dat Claude 2 van Anthropic op Amazon Bedrock betere algemene resultaten genereerde voor onze uiteindelijke datapijplijn.
Vragen stellen is een cruciaal aspect om ervoor te zorgen dat LLM's tekst naar wens uitvoeren. We hebben veel tijd besteed aan het experimenteren met verschillende aanwijzingen voor elk van de taken. Voor de tekst-naar-SQL-pijplijn hadden we bijvoorbeeld verschillende fallback-prompts, met toenemende specificiteit en geleidelijk vereenvoudigde tabelschema's. Als een SQL-query ongeldig was en resulteerde in een fout van Athena, ontwikkelden we een foutcorrectieprompt die de fout en onjuiste SQL doorgaf aan de LLM en deze vroeg om deze te repareren. De laatste prompt in de tekst-naar-SQL-pijplijn vraagt de LLM om de Athena-uitvoer, die kan worden geleverd in Markdown- of CSV-indeling, te nemen en een antwoord aan de gebruiker te geven. Voor de ongestructureerde tekst hebben we algemene aanwijzingen ontwikkeld om de context van Amazon Kendra te gebruiken om de gebruikersvraag te beantwoorden. De prompt bevatte instructies om alleen de informatie te gebruiken die was opgehaald van Amazon Kendra en niet te vertrouwen op gegevens uit de LLM-vooropleiding.
Latentie is vaak een probleem bij generatieve AI-toepassingen, en dat is hier ook het geval. Het is vooral een probleem voor tekst-naar-SQL, waarvoor een initiële LLM-aanroep voor het genereren van SQL vereist is, gevolgd door een LLM-aanroep voor het genereren van een antwoord. Als we een grote LLM gebruiken, zoals Claude V2 van Anthropic, verdubbelt dit effectief de latentie van slechts één LLM-aanroep. We hebben geëxperimenteerd met verschillende configuraties van grote en kleinere LLM's om zowel de looptijd als de correctheid te evalueren. De volgende tabel toont een voorbeeld voor één vraag hieronder die de latentie demonstreert, evenals de gegenereerde antwoorden met Claude V2 en Claude Instant van Anthropic op Amazon Bedrock.

Prototype
In onze applicatie hebben we een Lambda-functie gebruikt om de snelle keuzes en communicatie tussen Amazon Athena, Amazon Kendra en Amazon Bedrock te orkestreren. De virtuele assistent beschikt over een conversatie-interface, gebouwd met React en het Cloudscape Design System, die tekst en video's gebruikt om met gebruikers in contact te komen.
Onze virtuele assistent kan een breed scala aan vragen beantwoorden over PGA TOUR-evenementen, spelers, statistieken, geschiedenis en meer. Wanneer hem bijvoorbeeld wordt gevraagd naar de langste ritten van Tony Finau tijdens de Shriners Children's Open (een van de Signature-evenementen van de PGA TOUR), kan de assistent gestructureerde gegevens opvragen om zijn schotniveaugegevens op te halen. Met behulp van de tekst-naar-SQL-pijplijn kan het de exacte afstand in yards, het ronde getal en het gat bepalen waarin hij dit record heeft bereikt. De assistent interpreteert vervolgens deze numerieke gegevens om een definitief antwoord te genereren. De volgende tabel bevat enkele voorbeeldreacties.
| Vraag | antwoord |
| Wat was de langste drive van Tony Finau tijdens de Shriners Children's Open? | De langste drive die Tony Finau sloeg in het Shriners Childrens Open was 382 yards, die hij sloeg tijdens de eerste ronde op hole nummer 4 in 2018. |
| Wat was de langste drive van Collin Morikawa tijdens de Shriners Children's Open? | Collin Morikawa's langste rit op de Shriners Childrens Open was 334 meter. Dit gebeurde in 2019 tijdens de eerste ronde op hole nummer 15. |
| Heeft iemand een topprestatie behaald op de Shriners Children's Open 2022? | Ja, Adam Hadwin maakte een hole-in-one op hole 14 tijdens ronde 3 van het Shriners Children's Open 2022 |
De volgende uitlegvideo belicht enkele voorbeelden van interactie met de virtuele assistent.
Bij de eerste tests heeft onze virtuele assistent PGA TOUR een grote belofte getoond in het verbeteren van fanervaringen. Door AI-technologieën zoals tekst-naar-SQL, semantisch zoeken en het genereren van natuurlijke taal te combineren, levert de assistent informatieve, boeiende antwoorden. Fans hebben nu moeiteloos toegang tot gegevens en verhalen die voorheen moeilijk te vinden waren.
Wat brengt de toekomst?
Naarmate we de ontwikkeling voortzetten, zullen we het aantal vragen uitbreiden dat onze virtuele assistent kan beantwoorden. Dit vereist uitgebreide tests, via samenwerking tussen AWS en de PGA TOUR. In de loop van de tijd willen we de assistent ontwikkelen tot een gepersonaliseerde, omnichannel-ervaring die toegankelijk is via internet, mobiele apparaten en spraakinterfaces.
Door de oprichting van een cloudgebaseerde generatieve AI-assistent kan de PGA TOUR zijn enorme gegevensbron presenteren aan meerdere interne en externe belanghebbenden. Naarmate het generatieve AI-landschap in de sport evolueert, wordt het creëren van nieuwe inhoud mogelijk. Je kunt bijvoorbeeld AI en machine learning (ML) gebruiken om inhoud naar boven te halen die fans willen zien terwijl ze naar een evenement kijken, of terwijl productieteams op zoek zijn naar beelden van eerdere toernooien die overeenkomen met een actueel evenement. Als Max Homa zich bijvoorbeeld klaarmaakt om zijn laatste kans te maken op het PGA TOUR Championship vanaf een plek op zes meter van de pin, kan de PGA TOUR AI en ML gebruiken om clips van hem te identificeren en te presenteren, met door AI gegenereerd commentaar. vijf keer eerder een soortgelijk schot geprobeerd. Met dit soort toegang en gegevens kan een productieteam onmiddellijk waarde toevoegen aan de uitzending of kan een fan het type gegevens aanpassen dat hij/zij wil zien.
“De PGA TOUR is marktleider in het gebruik van geavanceerde technologie om de fanervaring te verbeteren. AI loopt voorop in onze technologiestapel, waardoor we een boeiendere en interactievere omgeving voor fans kunnen creëren. Dit is het begin van onze generatieve AI-reis in samenwerking met het AWS Generative AI Innovation Center voor een transformationele end-to-end klantervaring. We werken eraan om Amazon Bedrock en onze eigendomsgegevens te gebruiken om een interactieve ervaring te creëren voor PGA TOUR-fans om op een interactieve manier interessante informatie te vinden over een evenement, speler, statistieken of andere inhoud.
– Scott Gutterman, SVP van Broadcast en Digital Properties bij PGA TOUR.
Conclusie
Het project dat we in dit bericht hebben besproken, illustreert hoe gestructureerde en ongestructureerde gegevensbronnen kunnen worden samengevoegd met behulp van AI om virtuele assistenten van de volgende generatie te creëren. Voor sportorganisaties maakt deze technologie een meeslepende betrokkenheid van fans mogelijk en ontgrendelt het interne efficiëntie. De data-intelligentie die we naar boven halen, helpt PGA TOUR-belanghebbenden zoals spelers, coaches, officials, partners en media om sneller weloverwogen beslissingen te nemen. Naast sport kan onze methodologie in elke branche worden gerepliceerd. Dezelfde principes zijn van toepassing op bouwassistenten die klanten, werknemers, studenten, patiënten en andere eindgebruikers betrekken. Met doordacht ontwerp en testen kan vrijwel elke organisatie profiteren van een AI-systeem dat hun gestructureerde databases, documenten, afbeeldingen, video's en andere inhoud contextualiseert.
Als u geïnteresseerd bent in het implementeren van vergelijkbare functionaliteiten, overweeg dan om Agenten voor Amazon Bedrock en Kennisbanken voor Amazon Bedrock als alternatieve, volledig door AWS beheerde oplossing. Deze aanpak zou verder onderzoek kunnen doen naar het bieden van intelligente automatisering en mogelijkheden voor het zoeken naar gegevens via aanpasbare agenten. Deze agenten kunnen de interacties tussen gebruikerstoepassingen mogelijk transformeren om natuurlijker, efficiënter en effectiever te zijn.
Over de auteurs
 Scott Gutterman is de SVP Digital Operations voor de PGA TOUR. Hij is verantwoordelijk voor de algemene digitale activiteiten en productontwikkeling van de TOUR en stuurt hun GenAI-strategie aan.
Scott Gutterman is de SVP Digital Operations voor de PGA TOUR. Hij is verantwoordelijk voor de algemene digitale activiteiten en productontwikkeling van de TOUR en stuurt hun GenAI-strategie aan.
 Ahsan Ali is een Applied Scientist bij het Amazon Generative AI Innovation Center, waar hij samenwerkt met klanten uit verschillende domeinen om hun urgente en dure problemen op te lossen met behulp van Generative AI.
Ahsan Ali is een Applied Scientist bij het Amazon Generative AI Innovation Center, waar hij samenwerkt met klanten uit verschillende domeinen om hun urgente en dure problemen op te lossen met behulp van Generative AI.
 Tahin Syed is een Applied Scientist bij het Amazon Genative AI Innovation Center, waar hij met klanten samenwerkt om bedrijfsresultaten te helpen realiseren met generatieve AI-oplossingen. Buiten zijn werk houdt hij ervan om nieuw eten uit te proberen, te reizen en taekwondoles te geven.
Tahin Syed is een Applied Scientist bij het Amazon Genative AI Innovation Center, waar hij met klanten samenwerkt om bedrijfsresultaten te helpen realiseren met generatieve AI-oplossingen. Buiten zijn werk houdt hij ervan om nieuw eten uit te proberen, te reizen en taekwondoles te geven.
 Grace Lang is een Associate Data & ML-ingenieur bij AWS Professional Services. Gedreven door een passie voor het overwinnen van lastige uitdagingen, helpt Grace klanten hun doelen te bereiken door oplossingen op basis van machine learning te ontwikkelen.
Grace Lang is een Associate Data & ML-ingenieur bij AWS Professional Services. Gedreven door een passie voor het overwinnen van lastige uitdagingen, helpt Grace klanten hun doelen te bereiken door oplossingen op basis van machine learning te ontwikkelen.
 Jae Lee is een Senior Engagement Manager in de M&E-branche van ProServe. Ze leidt en levert complexe opdrachten, beschikt over sterke probleemoplossende vaardigheden, beheert de verwachtingen van belanghebbenden en cureert presentaties op directieniveau. Ze werkt graag aan projecten gericht op sport, generatieve AI en klantervaring.
Jae Lee is een Senior Engagement Manager in de M&E-branche van ProServe. Ze leidt en levert complexe opdrachten, beschikt over sterke probleemoplossende vaardigheden, beheert de verwachtingen van belanghebbenden en cureert presentaties op directieniveau. Ze werkt graag aan projecten gericht op sport, generatieve AI en klantervaring.
 Karn Chahar is een Security Consultant bij het shared delivery-team bij AWS. Hij is een technologieliefhebber die graag met klanten samenwerkt om hun beveiligingsuitdagingen op te lossen en hun beveiligingspositie in de cloud te verbeteren.
Karn Chahar is een Security Consultant bij het shared delivery-team bij AWS. Hij is een technologieliefhebber die graag met klanten samenwerkt om hun beveiligingsuitdagingen op te lossen en hun beveiligingspositie in de cloud te verbeteren.
 Mike Amjadi is een Data & ML Engineer met AWS ProServe, gericht op het mogelijk maken van klanten om de waarde uit data te maximaliseren. Hij is gespecialiseerd in het ontwerpen, bouwen en optimaliseren van datapijplijnen volgens goed ontworpen principes. Mike heeft een passie voor het gebruik van technologie om problemen op te lossen en streeft ernaar de beste resultaten voor onze klanten te leveren.
Mike Amjadi is een Data & ML Engineer met AWS ProServe, gericht op het mogelijk maken van klanten om de waarde uit data te maximaliseren. Hij is gespecialiseerd in het ontwerpen, bouwen en optimaliseren van datapijplijnen volgens goed ontworpen principes. Mike heeft een passie voor het gebruik van technologie om problemen op te lossen en streeft ernaar de beste resultaten voor onze klanten te leveren.
 Vrushali Sawant is een Front End Engineer bij Proserve. Ze is zeer bedreven in het maken van responsive websites. Ze werkt graag met klanten, begrijpt hun behoeften en biedt hen schaalbare, eenvoudig te implementeren UI/UX-oplossingen.
Vrushali Sawant is een Front End Engineer bij Proserve. Ze is zeer bedreven in het maken van responsive websites. Ze werkt graag met klanten, begrijpt hun behoeften en biedt hen schaalbare, eenvoudig te implementeren UI/UX-oplossingen.
 Neelam Patel is Customer Solutions Manager bij AWS en leidt belangrijke initiatieven voor generatieve AI en cloudmodernisering. Neelam werkt samen met belangrijke managers en technologie-eigenaren om hun uitdagingen op het gebied van cloudtransformatie aan te pakken en helpt klanten de voordelen van cloudadoptie te maximaliseren. Ze heeft een MBA van de Warwick Business School, VK en een bachelordiploma in Computer Engineering, India.
Neelam Patel is Customer Solutions Manager bij AWS en leidt belangrijke initiatieven voor generatieve AI en cloudmodernisering. Neelam werkt samen met belangrijke managers en technologie-eigenaren om hun uitdagingen op het gebied van cloudtransformatie aan te pakken en helpt klanten de voordelen van cloudadoptie te maximaliseren. Ze heeft een MBA van de Warwick Business School, VK en een bachelordiploma in Computer Engineering, India.
 Dr. Murali Baktha is Global Golf Solution Architect bij AWS en leidt cruciale initiatieven op het gebied van generatieve AI, data-analyse en geavanceerde cloudtechnologieën. Murali werkt samen met belangrijke managers en technologie-eigenaren om de zakelijke uitdagingen van klanten te begrijpen en ontwerpt oplossingen om deze uitdagingen aan te pakken. Hij heeft een MBA in Finance van UConn en een doctoraat van de Iowa State University.
Dr. Murali Baktha is Global Golf Solution Architect bij AWS en leidt cruciale initiatieven op het gebied van generatieve AI, data-analyse en geavanceerde cloudtechnologieën. Murali werkt samen met belangrijke managers en technologie-eigenaren om de zakelijke uitdagingen van klanten te begrijpen en ontwerpt oplossingen om deze uitdagingen aan te pakken. Hij heeft een MBA in Finance van UConn en een doctoraat van de Iowa State University.
 Mehdi Noor is een Applied Science Manager bij Generative Ai Innovation Center. Met een passie voor het overbruggen van technologie en innovatie helpt hij AWS-klanten bij het ontsluiten van het potentieel van generatieve AI, waarbij hij potentiële uitdagingen omzet in kansen voor snelle experimenten en innovatie door zich te concentreren op schaalbaar, meetbaar en impactvol gebruik van geavanceerde AI-technologieën, en het pad te stroomlijnen naar productie.
Mehdi Noor is een Applied Science Manager bij Generative Ai Innovation Center. Met een passie voor het overbruggen van technologie en innovatie helpt hij AWS-klanten bij het ontsluiten van het potentieel van generatieve AI, waarbij hij potentiële uitdagingen omzet in kansen voor snelle experimenten en innovatie door zich te concentreren op schaalbaar, meetbaar en impactvol gebruik van geavanceerde AI-technologieën, en het pad te stroomlijnen naar productie.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/the-journey-of-pga-tours-generative-ai-virtual-assistant-from-concept-to-development-to-prototype/

