Afbeelding door auteur
Er zijn veel cursussen en bronnen beschikbaar over machine learning en datawetenschap, maar heel weinig over data-engineering. Dit roept enkele vragen op. Is het een moeilijk vakgebied? Biedt het een laag loon? Wordt het niet als net zo spannend beschouwd als andere technische functies? De realiteit is echter dat veel bedrijven actief op zoek zijn naar data-engineeringtalent en substantiële salarissen aanbieden, soms tot boven de $200,000 USD. Data-ingenieurs spelen een cruciale rol als architecten van dataplatforms. Ze ontwerpen en bouwen de fundamentele systemen waarmee datawetenschappers en machine learning-experts effectief kunnen functioneren.
Om deze kloof in de sector aan te pakken, heeft DataTalkClub een transformatieve en gratis bootcamp geïntroduceerd: “Zoomcamp voor data-engineering“. Deze cursus is bedoeld om beginners of professionals die van carrière willen veranderen, te voorzien van essentiële vaardigheden en praktische ervaring in data-engineering.
Dit is een Bootcamp van 6 weken waar je leert door middel van meerdere cursussen, leesmateriaal, workshops en projecten. Aan het einde van elke module krijgt u huiswerk mee om in de praktijk te brengen wat u geleerd heeft.
- Week 1: Inleiding tot GCP, Docker, Postgres, Terraform en omgevingsconfiguratie.
- Week 2: Workflow-orkestratie met Mage.
- Week 3: Datawarehousing met BigQuery en machine learning met BigQuery.
- Week 4: Analytisch ingenieur met dbt, Google Data Studio en Metabase.
- Week 5: Batchverwerking met Spark.
- Week 6: Streamen met Kafka.
Afbeelding van DataTalksClub/data-engineering-zoomcamp
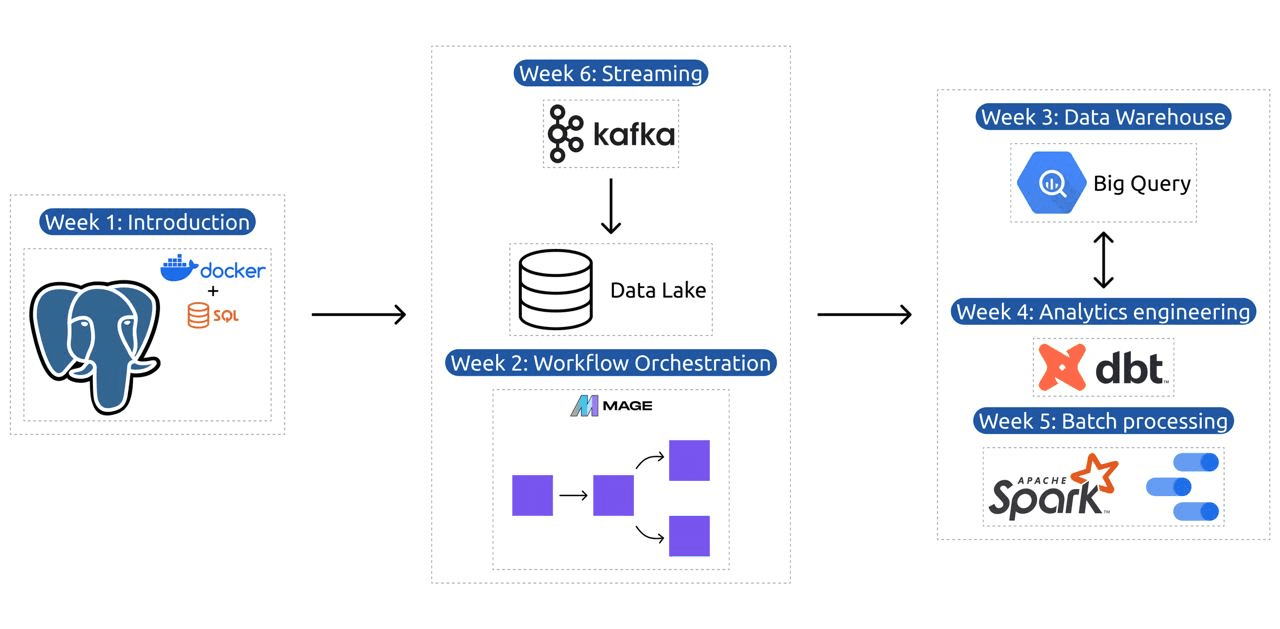
De syllabus bevat 6 modules, 2 workshops en een project dat alles omvat wat nodig is om een professionele data engineer te worden.
Module 1: Beheersing van containerisatie en infrastructuur als code
In deze module leert u over de Docker en Postgres, te beginnen met de basis en verder te gaan via gedetailleerde tutorials over het maken van datapijplijnen, het uitvoeren van Postgres met Docker en meer.
De module behandelt ook essentiële tools zoals pgAdmin, Docker-compose en SQL refresher-onderwerpen, met optionele inhoud over Docker-netwerken en een speciale walkthrough voor Linux-gebruikers van het Windows-subsysteem. Uiteindelijk laat de cursus u kennismaken met GCP en Terraform, waardoor u een holistisch begrip krijgt van containerisatie en infrastructuur als code, essentieel voor moderne cloudgebaseerde omgevingen.
Module 2: Workflow Orchestration-technieken
De module biedt een diepgaande verkenning van Mage, een innovatief open-source hybride raamwerk voor datatransformatie en -integratie. Deze module begint met de basisprincipes van workfloworkestratie en gaat over in praktische oefeningen met Mage, inclusief het instellen ervan via Docker en het bouwen van ETL-pijplijnen van API naar Postgres en Google Cloud Storage (GCS) en vervolgens naar BigQuery.
De mix van video's, bronnen en praktische taken van de module zorgt voor een uitgebreide leerervaring, waardoor leerlingen de vaardigheden krijgen om geavanceerde gegevensworkflows te beheren met Mage.
Workshop 1: Strategieën voor gegevensopname
In de eerste workshop beheers je het bouwen van efficiënte data-inname-pipelines. De workshop richt zich op essentiële vaardigheden zoals het extraheren van gegevens uit API's en bestanden, het normaliseren en laden van gegevens en incrementele laadtechnieken. Na het voltooien van deze workshop ben jij in staat om als een senior data engineer efficiënte data pipelines te creëren.
Module 3: Datawarehousing
De module is een diepgaande verkenning van gegevensopslag en -analyse, waarbij de nadruk ligt op Data Warehousing met BigQuery. Het behandelt belangrijke concepten zoals partitionering en clustering, en duikt in de best practices van BigQuery. De module gaat dieper in op geavanceerde onderwerpen, met name de integratie van Machine Learning (ML) met BigQuery, waarbij het gebruik van SQL voor ML wordt benadrukt en bronnen worden geboden over afstemming van hyperparameters, voorverwerking van functies en modelimplementatie.
Module 4: Analytics-engineering
De analytics engineering-module richt zich op het bouwen van een project met behulp van dbt (Data Build Tool) met een bestaand datawarehouse, BigQuery of PostgreSQL.
De module behandelt het opzetten van dbt in zowel cloud- als lokale omgevingen, introduceert analytische engineeringconcepten, ETL versus ELT en datamodellering. Het behandelt ook geavanceerde dbt-functies zoals incrementele modellen, tags, hooks en snapshots.
Uiteindelijk introduceert de module technieken voor het visualiseren van getransformeerde gegevens met behulp van tools als Google Data Studio en Metabase, en biedt het hulpmiddelen voor het oplossen van problemen en het efficiënt laden van gegevens.
Module 5: Vaardigheid in batchverwerking
Deze module behandelt batchverwerking met Apache Spark, te beginnen met een introductie tot batchverwerking en Spark, samen met installatie-instructies voor Windows, Linux en MacOS.
Het omvat het verkennen van Spark SQL en DataFrames, het voorbereiden van gegevens, het uitvoeren van SQL-bewerkingen en het begrijpen van Spark-internals. Ten slotte wordt afgesloten met het uitvoeren van Spark in de cloud en het integreren van Spark met BigQuery.
Module 6: De kunst van het streamen van gegevens met Kafka
De module begint met een inleiding tot concepten voor stroomverwerking, gevolgd door een diepgaande verkenning van Kafka, inclusief de basisprincipes ervan, integratie met Confluent Cloud en praktische toepassingen waarbij producenten en consumenten betrokken zijn.
De module behandelt ook Kafka-configuratie en -streams, waarbij onderwerpen als stream-joins, testen, windowing en het gebruik van Kafka ksqldb & Connect aan de orde komen. Daarnaast breidt het zijn focus uit naar Python- en JVM-omgevingen, met Faust voor Python-streamverwerking, Pyspark – Structured Streaming en Scala-voorbeelden voor Kafka Streams.
Workshop 2: Streamverwerking met SQL
U leert streaminggegevens verwerken en beheren met RisingWave, dat een kostenefficiënte oplossing biedt met een PostgreSQL-achtige ervaring om uw streamverwerkingstoepassingen te versterken.
Project: Real-World Data Engineering-applicatie
Het doel van dit project is om alle concepten die we in deze cursus hebben geleerd te implementeren om een end-to-end datapijplijn te bouwen. Je gaat een dashboard maken dat bestaat uit twee tegels door een dataset te selecteren, een pijplijn te bouwen voor het verwerken van de gegevens en deze op te slaan in een datameer, een pijplijn te bouwen voor het overbrengen van de verwerkte gegevens van het datameer naar een datawarehouse, het transformeren de gegevens in het datawarehouse en het voorbereiden ervan voor het dashboard, en ten slotte het bouwen van een dashboard om de gegevens visueel te presenteren.
Cohortdetails 2024
- registratie: Schrijf nu in
- Startdatum: 15 januari 2024, om 17:00 CET
- Zelfstudie met begeleide ondersteuning
- Cohortmap met huiswerk en deadlines
- Interactief Slack-gemeenschap voor peer-learning
Voorwaarden
- Basisvaardigheden op het gebied van coderen en opdrachtregel
- Basis in SQL
- Python: nuttig maar niet verplicht
Deskundige instructeurs die uw reis leiden
- Ankoesj Khanna
- Victoria Pérez Mola
- Alexey Grigorev
- Mat Palmer
- Luis Oliveira
- Michaël Schoenmaker
Sluit je aan bij ons cohort van 2024 en begin met leren bij een geweldige data-engineeringgemeenschap. Met door experts geleide training, praktijkervaring en een curriculum dat is afgestemd op de behoeften van de branche, voorziet deze bootcamp je niet alleen van de nodige vaardigheden, maar positioneert je je ook in de voorhoede van een lucratief en veelgevraagd carrièrepad. Schrijf u vandaag nog in en zet uw ambities om in werkelijkheid!
Abid Ali Awan (@1abidaliawan) is een gecertificeerde datawetenschapper-professional die dol is op het bouwen van machine learning-modellen. Momenteel richt hij zich op het creëren van content en het schrijven van technische blogs over machine learning en data science-technologieën. Abid heeft een Master in Technologie Management en een Bachelor in Telecommunicatie Engineering. Zijn visie is om een AI-product te bouwen met behulp van een grafisch neuraal netwerk voor studenten die worstelen met een psychische aandoening.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/the-only-free-course-you-need-to-become-a-professional-data-engineer?utm_source=rss&utm_medium=rss&utm_campaign=the-only-free-course-you-need-to-become-a-professional-data-engineer

