Auteur: Vitalik Buterin via de Vitalik Buterin-blog
Speciale dank aan de teams van Worldcoin en Modulus Labs, Xinyuan Sun, Martin Koeppelmann en Illia Polosukhin voor feedback en discussie.
Veel mensen hebben mij door de jaren heen een soortgelijke vraag gesteld: wat zijn de kruispunten tussen crypto en AI die ik als het meest vruchtbaar beschouw? Het is een redelijke vraag: crypto en AI zijn de twee belangrijkste diepgaande (software)technologietrends van het afgelopen decennium, en het voelt alsof er Dan moet je een soort verbinding tussen de twee zijn. Het is gemakkelijk om synergieën te bedenken op een oppervlakkig niveau: crypto-decentralisatie kan dat wel breng de centralisatie van AI in evenwichtAI is ondoorzichtig en crypto brengt transparantie, AI heeft data nodig en blockchains zijn goed voor het opslaan en volgen van data. Maar door de jaren heen, als mensen mij vroegen om een niveau dieper te graven en over specifieke toepassingen te praten, was mijn antwoord teleurstellend: “Ja, er zijn een paar dingen, maar niet zo veel”.
In de afgelopen drie jaar, met de opkomst van veel krachtigere AI in de vorm van moderne LLM's, en de opkomst van veel krachtigere cryptovaluta in de vorm van niet alleen blockchain-schaaloplossingen, maar ook ZKP's, FHE, (tweepartijen en N-partijen) MPCIk begin deze verandering te zien. Er zijn inderdaad enkele veelbelovende toepassingen van AI binnen blockchain-ecosystemen, of AI samen met cryptografie, hoewel het belangrijk is om voorzichtig te zijn met de manier waarop de AI wordt toegepast. Een bijzondere uitdaging is: bij cryptografie is open source de enige manier om iets echt veilig te maken, maar bij AI is een model (of zelfs de trainingsgegevens ervan) open sterk toeneemt zijn kwetsbaarheid voor vijandige machine learning aanvallen. Dit bericht zal een classificatie doornemen van verschillende manieren waarop crypto + AI elkaar kunnen kruisen, en de vooruitzichten en uitdagingen van elke categorie.
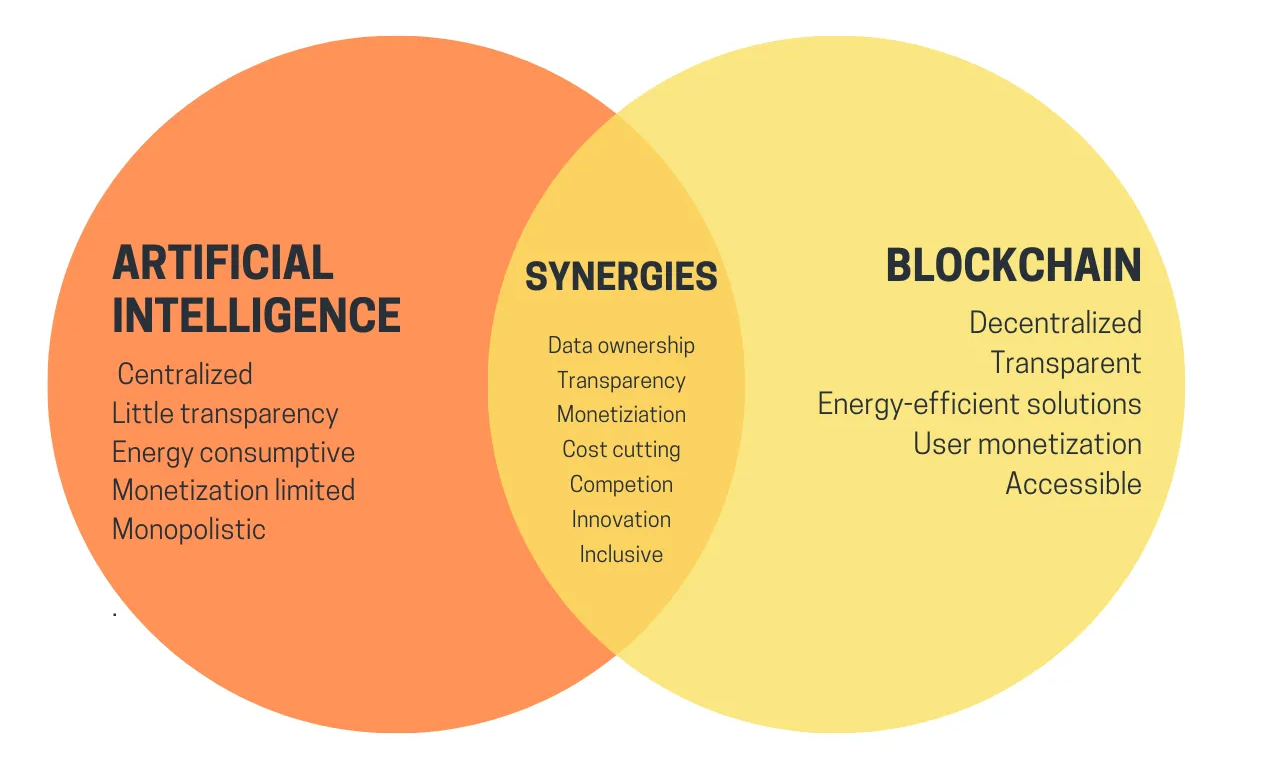
De vier grote categorieën
AI is een heel breed concept: je kunt ‘AI’ zien als de reeks algoritmen die je creëert, niet door ze expliciet te specificeren, maar eerder door een grote rekensoep te veroorzaken en een soort optimalisatiedruk uit te oefenen die de soep in de richting van het proces duwt. algoritmen produceren met de eigenschappen die u wilt. Deze beschrijving mag zeker niet afwijzend worden opgevat: het omvat de dat aangemaakt wij mensen in de eerste plaats! Maar het betekent wel dat AI-algoritmen een aantal gemeenschappelijke eigenschappen hebben: hun vermogen om extreem krachtige dingen te doen, samen met beperkingen in ons vermogen om te weten of te begrijpen wat er onder de motorkap gebeurt.
Er zijn veel manieren om AI te categoriseren; voor de doeleinden van dit bericht, waarin wordt gesproken over interacties tussen AI en blockchains (die zijn beschreven als een platform voor “spellen” maken), zal ik het als volgt categoriseren:
- AI als speler in een spel [hoogste levensvatbaarheid]: AI's nemen deel aan mechanismen waarbij de uiteindelijke bron van de prikkels afkomstig is van een protocol met menselijke input.
- AI als interface voor het spel [groot potentieel, maar met risico's]: AI's helpen gebruikers de cryptowereld om hen heen te begrijpen en ervoor te zorgen dat hun gedrag (dat wil zeggen ondertekende berichten en transacties) overeenkomt met hun bedoelingen en dat ze niet worden misleid of opgelicht.
- AI als de spelregels [zeer voorzichtig]: blockchains, DAO’s en soortgelijke mechanismen die rechtstreeks een beroep doen op AI’s. Denk bijv. “AI-juryleden”
- AI als doel van het spel [op langere termijn maar intrigerend]: het ontwerpen van blockchains, DAO’s en soortgelijke mechanismen met als doel een AI te construeren en te onderhouden die voor andere doeleinden kan worden gebruikt, waarbij de cryptobits worden gebruikt om training beter te stimuleren of om te voorkomen dat de AI privégegevens lekt of wordt misbruikt.
Laten we deze één voor één doornemen.
AI als speler in een spel
Dit is eigenlijk een categorie die al bijna tien jaar bestaat, althans sindsdien gedecentraliseerde uitwisselingen in de keten (DEX's) begon een aanzienlijk gebruik te zien. Elke keer dat er een uitwisseling plaatsvindt, is er een mogelijkheid om geld te verdienen via arbitrage, en bots kunnen veel beter aan arbitrage doen dan mensen. Deze use case bestaat al heel lang, zelfs met veel eenvoudigere AI’s dan wat we vandaag de dag hebben, maar uiteindelijk is het een zeer reëel AI+crypto kruispunt. Meer recentelijk hebben we MEV-arbitragebots gezien elkaar vaak uitbuiten. Elke keer dat je een blockchain-applicatie hebt waarbij veilingen of handel betrokken zijn, heb je te maken met arbitragebots.
Maar AI-arbitragebots zijn slechts het eerste voorbeeld van een veel grotere categorie, waarvan ik verwacht dat deze binnenkort ook veel andere toepassingen zal omvatten. Maak kennis met AIOmen, een demo van een voorspellingsmarkt waar AI's spelers zijn:
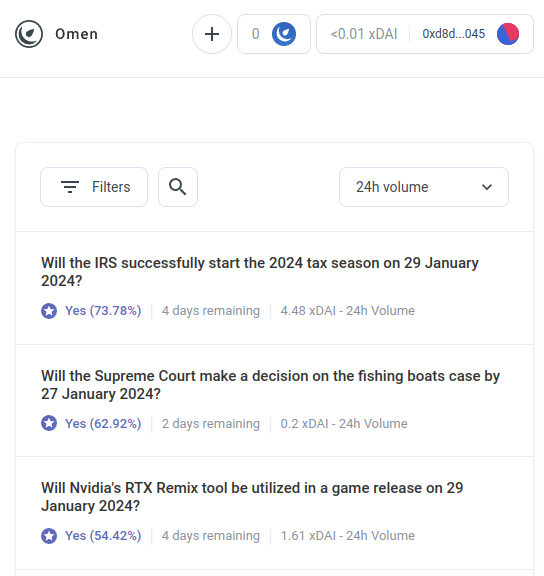
Eén reactie hierop is het wijzen op voortdurende UX-verbeteringen in Polymarkt of andere nieuwe voorspellingsmarkten, en hopen dat ze zullen slagen waar eerdere iteraties hebben gefaald. Het verhaal gaat immers dat mensen bereid zijn te wedden tientallen miljarden aan sport, dus waarom zouden mensen niet genoeg geld inzetten door te wedden op Amerikaanse verkiezingen of... LK99 dat het logisch begint te worden dat de serieuze spelers binnenkomen? Maar dit argument moet rekening houden met het feit dat, nou ja, eerdere iteraties hebben zijn er niet in geslaagd dit schaalniveau te bereiken (althans vergeleken met de dromen van hun voorstanders), en dus lijkt het erop dat je dat nodig hebt iets nieuws om voorspellingsmarkten te laten slagen. En dus is een ander antwoord het wijzen op één specifiek kenmerk van de ecosystemen van de voorspellingsmarkten die we in de jaren twintig van de twintigste eeuw kunnen verwachten en die we in de jaren tien van de vorige eeuw niet zagen: de mogelijkheid van alomtegenwoordige deelname van AI’s.
AI's zijn bereid om voor minder dan één dollar per uur te werken en beschikken over de kennis van een encyclopedie. En alsof dat nog niet genoeg is, kunnen ze zelfs worden geïntegreerd met realtime zoekmogelijkheden op internet. Als je een markt creëert en een liquiditeitssubsidie van $ 1 verstrekt, zullen mensen niet genoeg geven om te bieden, maar duizenden AI's zullen gemakkelijk over de vraag zwermen en de beste gok maken die ze kunnen. De prikkel om een vraag goed te beantwoorden is misschien klein, maar de prikkel om een AI te maken die goede voorspellingen doet in het algemeen kan in de miljoenen lopen. Houd er rekening mee dat mogelijk je hebt niet eens mensen nodig om de meeste vragen te beantwoorden: u kunt een meerrondengeschilsysteem gebruiken, vergelijkbaar met augur of Kleros, waar AI's ook aan eerdere rondes zouden deelnemen. Mensen zouden alleen hoeven te reageren in die paar gevallen waarin een reeks escalaties heeft plaatsgevonden en grote hoeveelheden geld door beide partijen zijn gepleegd.
Dit is een krachtige primitief, want zodra een ‘voorspellingsmarkt’ op zo’n microscopische schaal kan werken, kun je de ‘voorspellingsmarkt’-primitief voor veel andere soorten vragen hergebruiken:
- Is dit bericht op sociale media aanvaardbaar onder de [gebruiksvoorwaarden]?
- Wat gebeurt er met de prijs van aandeel X (zie bijv U zult nummeren)
- Is dit account dat mij momenteel berichten stuurt eigenlijk Elon Musk?
- Is deze werkinzending op een online takenmarktplaats acceptabel?
- Is de dapp op https://examplefinance.network oplichting?
- Is
0x1b54....98c3eigenlijk het adres van het “Casinu Inu” ERC20-token?
Het zal je misschien opvallen dat veel van deze ideeën in de richting gaan van wat ik ‘informatie verdediging" in . In grote lijnen is de vraag: hoe kunnen we gebruikers helpen ware en valse informatie van elkaar te onderscheiden en oplichting op te sporen, zonder een gecentraliseerde autoriteit in staat te stellen te beslissen wat goed en kwaad is, wie dan misbruik zou kunnen maken van dat standpunt? Op microniveau kan het antwoord ‘AI’ zijn. Maar op macroniveau is de vraag: wie bouwt de AI? AI is een weerspiegeling van het proces dat het heeft gecreëerd en kan dus niet voorkomen dat er sprake is van vooroordelen. Daarom is er behoefte aan een spel op een hoger niveau dat beoordeelt hoe goed de verschillende AI's het doen, waarbij AI's als spelers aan het spel kunnen deelnemen..
Dit gebruik van AI, waarbij AI’s deelnemen aan een mechanisme waarbij ze uiteindelijk worden beloond of bestraft (probabilistisch) door een mechanisme in de keten dat input van mensen verzamelt (noem het gedecentraliseerde, op de markt gebaseerde RLHF?), is iets waarvan ik denk dat het echt de moeite waard is om ernaar te kijken. Dit is het juiste moment om meer naar dit soort gebruiksscenario’s te kijken, omdat het opschalen van blockchain eindelijk slaagt, waardoor ‘micro’ alles eindelijk levensvatbaar maakt in de keten, terwijl dat voorheen vaak niet het geval was.
Een verwante categorie toepassingen gaat in de richting van zeer autonome agenten blockchains gebruiken om beter samen te werken, hetzij via betalingen, hetzij via het gebruik van slimme contracten om geloofwaardige toezeggingen te doen.
AI als interface voor het spel
Eén idee dat ik in mijn geschriften op is het idee dat er een marktmogelijkheid bestaat om gebruikersgerichte software te schrijven die de belangen van gebruikers zou beschermen door de gevaren in de online wereld waarin de gebruiker navigeert te interpreteren en te identificeren. Een reeds bestaand voorbeeld hiervan is de zwendeldetectiefunctie van Metamask:
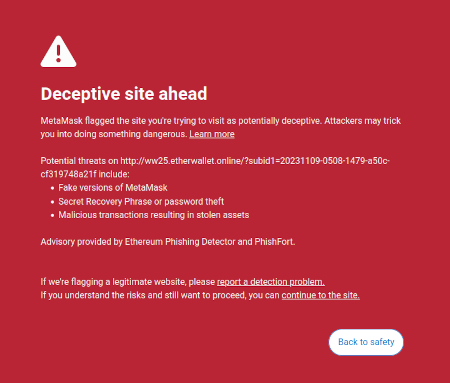
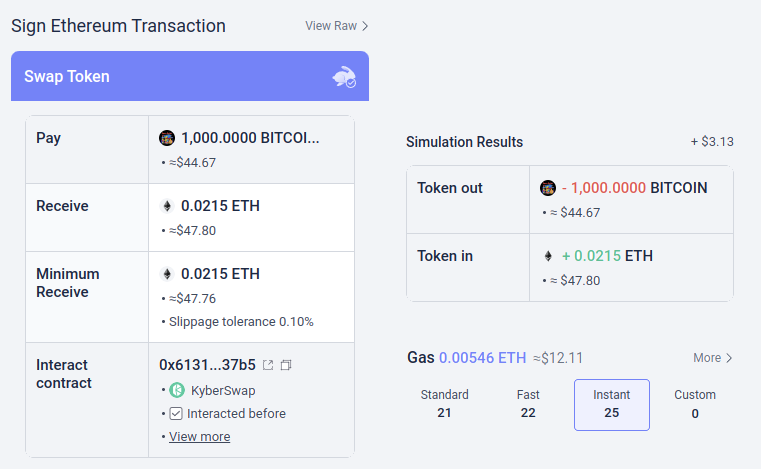
Mogelijk kunnen dit soort tools een superlading krijgen met AI. AI zou een veel rijkere mensvriendelijke verklaring kunnen geven van aan wat voor soort dapp je deelneemt, de gevolgen van ingewikkeldere operaties die je ondertekent, of een bepaald token al dan niet echt is (bijv. BITCOIN is niet zomaar een reeks tekens, het is de naam van een daadwerkelijke cryptocurrency, die geen ERC20-token is en die een prijs heeft die veel hoger is dan $ 0.045, en een moderne LLM zou dat weten), enzovoort. Er zijn projecten die helemaal in deze richting beginnen te gaan (bijv. de LangChain-portemonnee, dat AI gebruikt als een primair koppel). Mijn eigen mening is dat pure AI-interfaces op dit moment waarschijnlijk te riskant zijn, omdat ze het risico vergroten anders soorten fouten, maar AI die een meer conventionele interface aanvult, wordt zeer haalbaar.
Er is één specifiek risico dat het vermelden waard is. Ik zal hier meer op ingaan in het gedeelte over “AI als spelregels” hieronder, maar het algemene probleem is vijandig machinaal leren: als een gebruiker toegang heeft tot een AI-assistent in een open-source portemonnee, zullen de slechteriken ook toegang hebben tot die AI-assistent, en dus hebben ze onbeperkte mogelijkheden om hun oplichting te optimaliseren om niet te activeren de verdediging van die portemonnee. Alle moderne AI's hebben ergens bugs, en het is niet zo moeilijk voor een trainingsproces, zelfs niet als je er maar één hebt beperkte toegang tot het model, om ze te vinden.
Dit is waar “AI’s die deelnemen aan micromarkten in de keten” beter werken: elke individuele AI is kwetsbaar voor dezelfde risico’s, maar je creëert opzettelijk een open ecosysteem van tientallen mensen die deze voortdurend herhalen en verbeteren. Bovendien is elke individuele AI gesloten: de veiligheid van het systeem komt voort uit de openheid van de regels van de spel, niet de interne werking van elk speler.
Overzicht: AI kan gebruikers in gewone taal helpen begrijpen wat er aan de hand is, het kan dienen als een realtime docent, het kan gebruikers beschermen tegen fouten, maar wees gewaarschuwd als je het rechtstreeks probeert te gebruiken tegen kwaadwillende, verkeerd geïnformeerde mensen en oplichters.
AI als spelregels
Nu komen we bij de toepassing waar veel mensen enthousiast over zijn, maar waarvan ik denk dat deze het meest riskant is, en waar we het meest voorzichtig mee moeten omgaan: wat ik AI noem, is onderdeel van de spelregels. Dit sluit aan bij de opwinding onder de reguliere politieke elites over ‘AI-rechters’ (zie bijv dit artikel op de website van de “World Government Summit”), en er zijn analogen van deze verlangens in blockchain-toepassingen. Als een op blockchain gebaseerd slim contract of een DAO een subjectieve beslissing moet nemen (is een bepaald werkproduct bijvoorbeeld acceptabel in een huurcontract? Wat is de juiste interpretatie van een grondwet in natuurlijke taal zoals het Optimisme Wet van ketens?), zou je ervoor kunnen zorgen dat een AI eenvoudigweg deel uitmaakt van het contract of de DAO om deze regels te helpen handhaven?
Dit is waar vijandige machine learning wordt een uiterst zware uitdaging. Het fundamentele argument van twee zinnen waarom is als volgt:
Als een AI-model dat een sleutelrol speelt in een mechanisme gesloten is, kun je de interne werking ervan niet verifiëren, en dus is het niet beter dan een gecentraliseerde applicatie. Als het AI-model open is, kan een aanvaller het lokaal downloaden en simuleren, en sterk geoptimaliseerde aanvallen ontwerpen om het model te misleiden, die hij vervolgens op het live netwerk kan afspelen.

Nu zijn de frequente lezers van deze blog (of de bewoners van de cryptoverse) mij misschien al voor en denken: maar wacht! We hebben mooie nulkennisbewijzen en andere echt coole vormen van cryptografie. We kunnen zeker wat crypto-magie doen en de innerlijke werking van het model verbergen, zodat aanvallers de aanvallen niet kunnen optimaliseren, maar tegelijkertijd bewijzen dat het model correct wordt uitgevoerd en is gebouwd met behulp van een redelijk trainingsproces op een redelijke set onderliggende gegevens!
Normaal gesproken is dit zo precies het soort denken dat ik zowel op deze blog als in mijn andere geschriften bepleit. Maar in het geval van AI-gerelateerde berekeningen zijn er twee belangrijke bezwaren:
- Cryptografische overhead: het is veel minder efficiënt om iets binnen een SNARK (of MPC of…) te doen dan om het “in het openbaar” te doen. Gegeven het feit dat AI al zeer rekenintensief is, is het toepassen van AI in cryptografische zwarte dozen dan überhaupt rekenkundig haalbaar?
- Black-box vijandige machine learning-aanvallen: er zijn manieren om aanvallen op AI-modellen te optimaliseren zelfs zonder veel te weten over de interne werking van het model. En als je je verbergt te veel, loop je het risico dat het te gemakkelijk wordt gemaakt voor degene die de trainingsgegevens kiest om het model mee te corrumperen vergiftiging aanvallen.
Dit zijn allebei ingewikkelde konijnenholen, dus laten we ze om de beurt bekijken.
Cryptografische overhead
Cryptografische gadgets, vooral voor algemene doeleinden zoals ZK-SNARK's en MPC, hebben een hoge overhead. Het duurt een paar honderd milliseconden voordat een client een Ethereum-blok rechtstreeks heeft geverifieerd, maar het genereren van een ZK-SNARK om de juistheid van zo'n blok te bewijzen kan uren duren. De typische overhead van andere cryptografische gadgets, zoals MPC, kan zelfs nog erger zijn. AI-berekeningen zijn al duur: de krachtigste LLM's kunnen individuele woorden slechts een klein beetje sneller produceren dan mensen ze kunnen lezen, om nog maar te zwijgen van de vaak miljoenen dollars aan rekenkosten van opleiding de modellen. Het kwaliteitsverschil tussen topmodellen en de modellen waar veel meer op wordt bezuinigd opleiding kosten or parameter tellen is groot. Op het eerste gezicht is dit een zeer goede reden om achterdochtig te zijn tegenover het hele project van pogingen om garanties aan AI toe te voegen door het in cryptografie te verpakken.
Maar gelukkig AI is een heel specifieke soort van berekeningen, waardoor het vatbaar is voor allerlei optimalisaties waar meer ‘ongestructureerde’ typen berekeningen zoals ZK-EVM’s niet van kunnen profiteren. Laten we de basisstructuur van een AI-model onderzoeken:

y = max(x, 0)). Asymptotisch nemen matrixvermenigvuldigingen het meeste werk in beslag: het vermenigvuldigen van twee N*N matrices kost �(�2.8) tijd, terwijl het aantal niet-lineaire bewerkingen veel kleiner is. Dit is erg handig voor cryptografie, omdat veel vormen van cryptografie lineaire bewerkingen kunnen uitvoeren (wat matrixvermenigvuldigingen zijn, tenminste als je het model codeert, maar niet de invoer ervan) bijna "gratis".
Als u een cryptograaf bent, heeft u waarschijnlijk al gehoord van een soortgelijk fenomeen in de context van homomorfe codering: het uitvoeren van toevoegingen op gecodeerde cijferteksten is heel eenvoudig, maar vermenigvuldigingen zijn ongelooflijk moeilijk en we hadden tot 2009 helemaal geen manier bedacht om dit met onbeperkte diepgang te doen.
Voor ZK-SNARK's is het equivalent protocollen zoals deze uit 2013, waaruit een blijkt minder dan 4x overhead bij het bewijzen van matrixvermenigvuldigingen. Helaas is de overhead op de niet-lineaire lagen nog steeds aanzienlijk, en de beste implementaties in de praktijk laten een overhead zien van ongeveer 200x. Maar er is hoop dat dit door verder onderzoek aanzienlijk kan worden verminderd; zien deze presentatie van Ryan Cao voor een recente aanpak gebaseerd op GKR, en de mijne vereenvoudigde uitleg van hoe het hoofdbestanddeel van GKR werkt.
Maar voor veel toepassingen willen we dat niet zomaar bewijzen dat een AI-uitvoer correct is berekend, willen we ook verberg het model. Er zijn naïeve benaderingen hiervoor: je kunt het model opsplitsen zodat een andere set servers elke laag redundant opslaat, en hopen dat sommige van de servers die sommige lagen lekken, niet te veel gegevens lekken. Maar er zijn ook verrassend effectieve vormen van gespecialiseerde meerpartijenberekening.
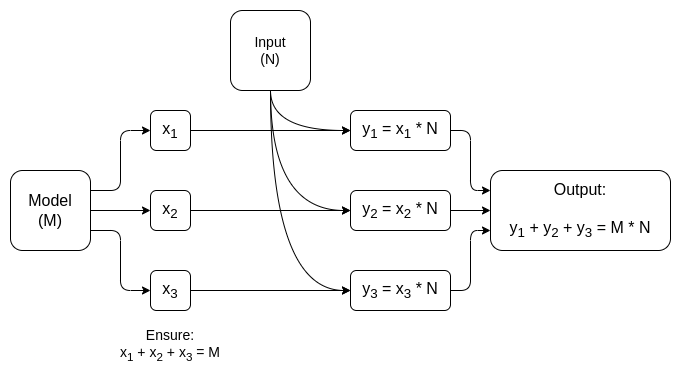
In beide gevallen is de moraal van het verhaal hetzelfde: Het grootste deel van een AI-berekening bestaat uit matrixvermenigvuldigingen, die mogelijk zijn zeer efficiënt ZK-SNARK's of MPC's (of zelfs FHE), en dus is de totale overhead van het plaatsen van AI in cryptografische dozen verrassend laag. Over het algemeen zijn het de niet-lineaire lagen die ondanks hun kleinere formaat het grootste knelpunt vormen; misschien nieuwere technieken zoals argumenten opzoeken kan helpen.
Machine learning in de black-box
Laten we nu eens kijken naar het andere grote probleem: het soort aanvallen dat je kunt uitvoeren zelfs indien de inhoud van het model wordt privé gehouden en u heeft alleen “API-toegang” tot het model. Citaat van een papier van 2016:
Veel machine learning-modellen zijn kwetsbaar voor vijandige voorbeelden: invoer die speciaal is ontworpen om ervoor te zorgen dat een machine learning-model een onjuiste uitvoer produceert. Tegenstrijdige voorbeelden die van invloed zijn op het ene model, hebben vaak invloed op een ander model, zelfs als de twee modellen een verschillende architectuur hebben of op verschillende trainingssets zijn getraind, zolang beide modellen maar zijn getraind om dezelfde taak uit te voeren. Een aanvaller kan daarom zijn eigen vervangingsmodel trainen, vijandige voorbeelden tegen de vervanger maken en deze overbrengen naar een slachtoffermodel, met zeer weinig informatie over het slachtoffer.
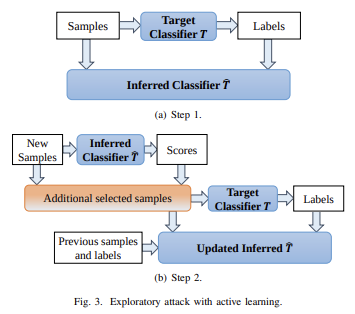
Potentieel kun je zelfs aanvallen creëren als je het weet alleen de trainingsgegevens, zelfs als u zeer beperkte of geen toegang heeft tot het model dat u probeert aan te vallen. Anno 2023 blijven dit soort aanvallen een groot probleem.
Om dit soort blackbox-aanvallen effectief te beperken, moeten we twee dingen doen:
- Echt beperk wie of wat het model kan bevragen en hoe veel. Zwarte dozen met onbeperkte API-toegang zijn niet veilig; zwarte dozen met zeer beperkte API-toegang kunnen dat zijn.
- Verberg de trainingsgegevens, met behoud van vertrouwen dat het proces dat wordt gebruikt om de trainingsgegevens te maken, niet beschadigd is.
Het project dat het meeste aan het eerste heeft bijgedragen is misschien Worldcoin, waarvan ik een eerdere versie (naast andere protocollen) uitvoerig analyseer. hier. Worldcoin maakt uitgebreid gebruik van AI-modellen op protocolniveau, om (i) irisscans om te zetten in korte “iriscodes” die gemakkelijk te vergelijken zijn op gelijkenis, en (ii) te verifiëren dat het ding dat het scant daadwerkelijk een mens is. De belangrijkste verdediging waar Worldcoin op vertrouwt is het feit dat het laat niemand zomaar het AI-model gebruiken: het gebruikt in plaats daarvan vertrouwde hardware om ervoor te zorgen dat het model alleen invoer accepteert die digitaal is ondertekend door de camera van de bol.
Het is niet gegarandeerd dat deze aanpak werkt: het blijkt dat je vijandige aanvallen kunt uitvoeren tegen biometrische AI in de vorm van fysieke patches of sieraden die u op uw gezicht kunt aanbrengen:

Maar de hoop is dat als jij combineer alle verdedigingen samen, door het AI-model zelf te verbergen, het aantal zoekopdrachten sterk te beperken en te vereisen dat elke zoekopdracht op de een of andere manier wordt geverifieerd, kun je vijandige aanvallen uitvoeren die zo moeilijk zijn dat het systeem veilig kan zijn.
En dit brengt ons bij het tweede deel: hoe kunnen we de trainingsgegevens verbergen? Dit is waar “DAO’s om AI democratisch te besturen” zou eigenlijk logisch kunnen zijn: we kunnen een on-chain DAO creëren die het proces regelt van wie trainingsgegevens mag indienen (en welke attesten vereist zijn voor de gegevens zelf), wie vragen mag stellen, en hoeveel, en cryptografische technieken zoals MPC kunnen gebruiken om de volledige pijplijn van het maken en uitvoeren van de AI te coderen, vanaf de trainingsinvoer van elke individuele gebruiker tot aan de uiteindelijke uitvoer van elke zoekopdracht. Deze DAO zou tegelijkertijd kunnen voldoen aan de zeer populaire doelstelling om mensen te compenseren voor het indienen van gegevens.
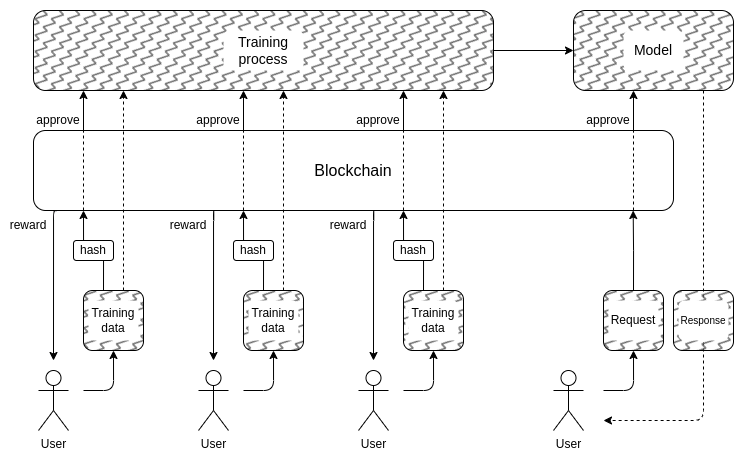
- De cryptografische overhead zou nog steeds te hoog kunnen uitvallen wil dit soort volledig black-box-architectuur concurrerend zijn met traditionele, gesloten ‘vertrouw me’-benaderingen.
- Dat zou kunnen blijken er is geen goede manier om het indieningsproces van trainingsgegevens gedecentraliseerd te maken en beschermd tegen vergiftigingsaanvallen.
- Computergadgets voor meerdere partijen kunnen kapot gaan hun veiligheids- of privacygaranties vanwege deelnemers die samenspannen: dit is tenslotte gebeurd met cross-chain cryptocurrency-bruggen weer en weer.
Eén reden waarom ik dit gedeelte niet begon met nog meer grote rode waarschuwingslabels met de tekst “DOEL GEEN AI-RECHTERS, DAT IS DYSTOPIAANS”, is dat onze samenleving al sterk afhankelijk is van onverantwoordelijke gecentraliseerde AI-rechters: de algoritmen die bepalen welke soorten berichten en politieke meningen worden op sociale media gestimuleerd en gedeprikkeld, of zelfs gecensureerd. Ik denk wel dat deze trend zich uitbreidt verder In dit stadium is dat een heel slecht idee, maar ik denk niet dat de kans daarop groot is de blockchain-gemeenschap experimenteert meer met AI’s zal het ding zijn dat ertoe bijdraagt dat het erger wordt.
In feite zijn er enkele vrij basale manieren waarop cryptotechnologie met een laag risico zelfs deze bestaande gecentraliseerde systemen beter kan maken, waar ik vrij zeker van ben. Een eenvoudige techniek is geverifieerde AI met vertraagde publicatie: wanneer een sociale-mediasite een op AI gebaseerde ranglijst van berichten maakt, kan deze een ZK-SNARK publiceren die de hash aantoont van het model dat die ranglijst heeft gegenereerd. De site zou zich ertoe kunnen verbinden zijn AI-modellen te onthullen na bijvoorbeeld. een jaar uitstel. Zodra een model is onthuld, kunnen gebruikers de hash controleren om te verifiëren dat het juiste model is vrijgegeven, en kan de gemeenschap tests op het model uitvoeren om de eerlijkheid ervan te verifiëren. De publicatievertraging zou ervoor zorgen dat tegen de tijd dat het model wordt onthuld, het al verouderd is.
Dus vergeleken met de gecentraliseerde wereld, de vraag is dat niet if we kunnen het beter doen, maar door hoeveel. Voor de gedecentraliseerde wereldHet is echter belangrijk om voorzichtig te zijn: als iemand bijv. een voorspellingsmarkt of een stablecoin die een AI-orakel gebruikt, en het blijkt dat het orakel aangevallen kan worden, dat is een enorme hoeveelheid geld die in een oogwenk zou kunnen verdwijnen.
AI als doel van het spel
Als de bovenstaande technieken voor het creëren van een schaalbare gedecentraliseerde private AI, waarvan de inhoud een zwarte doos is die niemand kent, daadwerkelijk kunnen werken, dan zou dit ook kunnen worden gebruikt om AI’s te creëren met een bruikbaarheid die verder gaat dan blockchains. Het NEAR-protocolteam maakt hiervan een kerndoelstelling van hun lopende werk.
Er zijn twee redenen om dit te doen:
- als u wel maken "betrouwbare black-box AI’sDoor het training- en gevolgtrekkingsproces uit te voeren met behulp van een combinatie van blockchains en MPC, kunnen veel toepassingen waarbij gebruikers zich zorgen maken dat het systeem bevooroordeeld is of hen bedriegt, hiervan profiteren. Veel mensen hebben hun wens geuit democratisch bestuur van systeemrelevante AI’s waar we afhankelijk van zullen zijn; cryptografische en op blockchain gebaseerde technieken zouden een manier kunnen zijn om dat te doen.
- Van een AI-veiligheid Vanuit dit perspectief zou dit een techniek zijn om een gedecentraliseerde AI te creëren die ook over een natuurlijke ‘kill switch’ beschikt, en die zoekopdrachten zou kunnen beperken die de AI voor kwaadaardig gedrag willen gebruiken.
Het is ook de moeite waard om op te merken dat “het gebruik van crypto-prikkels om het maken van betere AI te stimuleren” kan worden gedaan zonder ook maar het volledige konijnenhol in te gaan van het gebruik van cryptografie om het volledig te versleutelen: benaderingen zoals BitTensor vallen in deze categorie.
Conclusies
Nu zowel blockchains als AI’s krachtiger worden, is er een groeiend aantal gebruiksscenario’s op het kruispunt van de twee gebieden. Sommige van deze gebruiksscenario's zijn echter veel logischer en veel robuuster dan andere. Over het algemeen zijn er gevallen waarin het onderliggende mechanisme nog steeds ongeveer hetzelfde is ontworpen als voorheen, maar dan op het individu spelers AI’s worden, waardoor het mechanisme effectief op veel microschaal kan werken, zijn het meest veelbelovend en het gemakkelijkst te realiseren.
De grootste uitdaging om het goed te krijgen zijn applicaties die blockchains en cryptografische technieken proberen te gebruiken om een ‘singleton’ te creëren: een enkele gedecentraliseerde, vertrouwde AI waar een applicatie voor een bepaald doel op zou vertrouwen. Deze toepassingen zijn veelbelovend, zowel wat betreft functionaliteit als wat betreft het verbeteren van de AI-veiligheid op een manier die de centralisatierisico’s vermijdt die gepaard gaan met meer reguliere benaderingen van dat probleem. Maar er zijn ook veel manieren waarop de onderliggende aannames kunnen mislukken; Daarom is het de moeite waard om voorzichtig te werk te gaan, vooral als deze toepassingen in hoogwaardige en risicovolle contexten worden ingezet.
Ik kijk uit naar meer pogingen tot constructieve gebruiksscenario's van AI op al deze gebieden, zodat we kunnen zien welke ervan op grote schaal echt levensvatbaar zijn.
Auteur: Vitalik Buterin
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: Plato data-intelligentie.

