Introductie
Dit artikel introduceert het concept van datamodellering, een cruciaal proces dat schetst hoe gegevens worden opgeslagen, georganiseerd en toegankelijk zijn binnen een database of datasysteem. Het gaat om het omzetten van zakelijke behoeften uit de echte wereld naar een logisch en gestructureerd formaat dat kan worden gerealiseerd in een database of datawarehouse. We zullen onderzoeken hoe datamodellering een conceptueel raamwerk creëert voor het begrijpen van de relaties en onderlinge verbindingen van data binnen een organisatie of een specifiek domein. Daarnaast bespreken we het belang van het ontwerpen van datastructuren en relaties om efficiënte gegevensopslag, -herstel en -manipulatie te garanderen.

Gebruiksscenario's voor gegevensmodellering
Gegevensmodellering is van fundamenteel belang voor het effectief beheren en gebruiken van gegevens in verschillende scenario's. Hier volgen enkele typische gebruiksscenario's voor datamodellering, elk in detail uitgelegd:
Data Acquisition
Bij datamodellering houdt data-acquisitie in dat wordt gedefinieerd hoe gegevens worden verzameld of gegenereerd uit verschillende bronnen. Deze fase omvat het opzetten van de noodzakelijke datastructuur om de binnenkomende gegevens vast te houden, zodat deze efficiënt kunnen worden geïntegreerd en opgeslagen. Door in dit stadium gegevens te modelleren, kunnen organisaties ervoor zorgen dat de verzamelde gegevens zo zijn gestructureerd dat ze aansluiten bij hun analytische behoeften en bedrijfsprocessen. Het helpt bij het identificeren van het type gegevens dat nodig is, in welk formaat deze moeten zijn en hoe deze zullen worden verwerkt voor verder gebruik.
Gegevens laden
Zodra de gegevens zijn verzameld, moeten deze in het doelsysteem worden geladen, zoals een database. datawarehouseof datameer. Datamodellering speelt hier een cruciale rol door het schema of de structuur te definiëren waarin de gegevens zullen worden ingevoegd. Dit omvat onder meer het specificeren hoe gegevens uit verschillende bronnen worden toegewezen aan de tabellen en kolommen van de database en het opzetten van relaties tussen verschillende gegevensentiteiten. Een goede datamodellering zorgt ervoor dat gegevens optimaal worden geladen, waardoor efficiënte opslag, toegang en queryprestaties worden vergemakkelijkt.
Zakelijke berekening
Datamodellering is een integraal onderdeel van het opzetten van de raamwerken voor bedrijfsberekeningen. Deze berekeningen genereren inzichten, statistieken en Key Performance Indicators (KPI's) uit de opgeslagen gegevens. Door een duidelijk datamodel op te zetten, kunnen organisaties definiëren hoe gegevens uit verschillende bronnen kunnen worden samengevoegd, getransformeerd en geanalyseerd om complexe bedrijfsberekeningen uit te voeren. Dit zorgt ervoor dat de onderliggende gegevens de afleiding van zinvolle en nauwkeurige gegevens ondersteunen business intelligence, die de besluitvorming en strategische planning kunnen begeleiden.
Distributie
De distributiefase maakt de verwerkte gegevens beschikbaar voor eindgebruikers of andere systemen voor analyse, rapportage en besluitvorming. Datamodellering is in deze fase erop gericht ervoor te zorgen dat gegevens worden gestructureerd en geformatteerd op een manier die toegankelijk en begrijpelijk is voor het beoogde publiek. Dit kan het modelleren van gegevens in dimensionale schema's voor gebruik in business intelligence-tools omvatten, het creëren van API's voor programmatische toegang of het definiëren van exportformaten voor het delen van gegevens. Effectieve datamodellering zorgt ervoor dat gegevens eenvoudig kunnen worden gedistribueerd en geconsumeerd over verschillende platforms en door verschillende belanghebbenden, waardoor het nut en de waarde ervan worden vergroot.
Elk van deze gebruiksscenario’s illustreert het belang in de gehele levenscyclus van gegevens, van verzameling en opslag tot analyse en distributie. Door in elke fase zorgvuldig datastructuren en -relaties te ontwerpen, kunnen organisaties ervoor zorgen dat hun data-architectuur hun operationele en analytische behoeften efficiënt en effectief ondersteunt.
Data-ingenieurs/modelleurs
gegevens Engineers en Data Modelers spelen een cruciale rol in databeheer en -analyse, waarbij ze elk unieke vaardigheden en expertise inbrengen om de kracht van data binnen een organisatie te benutten. Het begrijpen van elkaars rollen en verantwoordelijkheden kan helpen verduidelijken hoe zij samenwerken om robuuste data-infrastructuren op te bouwen en te onderhouden.
gegevens Engineers
Data Engineers zijn verantwoordelijk voor het ontwerp, de constructie en het onderhoud van de systemen en architecturen die een efficiënte verwerking en toegankelijkheid van gegevens mogelijk maken. Hun rol omvat vaak:
- Datapijplijnen bouwen en onderhouden: Ze creëren de infrastructuur voor het extraheren, transformeren en laden van gegevens (ETL) uit verschillende bronnen.
- Gegevensopslag en -beheer: Ze ontwerpen en implementeren databasesystemen, datameren en andere opslagoplossingen om gegevens georganiseerd en toegankelijk te houden.
- Prestatie-optimalisatie: Data Engineers zorgen ervoor dat dataprocessen efficiënt verlopen, vaak door de gegevensopslag en de uitvoering van query's te optimaliseren.
- Samenwerking met belanghebbenden: Ze werken nauw samen met bedrijfsanalisten, datawetenschappers en andere gebruikers om de databehoeften te begrijpen en oplossingen te implementeren die datagestuurde besluitvorming mogelijk maken.
- Waarborgen van de kwaliteit en integriteit van gegevens: Ze implementeren systemen en processen om gegevens te monitoren, valideren en opschonen, zodat gebruikers toegang hebben tot betrouwbare en nauwkeurige informatie.
Datamodelleurs
Datamodelleurs richten zich op het ontwerpen van de blauwdruk voor gegevensbeheersystemen. Hun werk omvat het begrijpen van zakelijke vereisten en het vertalen ervan naar datastructuren die efficiënte gegevensopslag, -herstel en -analyse ondersteunen. De belangrijkste verantwoordelijkheden zijn onder meer:
- Conceptuele, logische en fysieke datamodellen ontwikkelen: Ze creëren modellen die definiëren hoe gegevens met elkaar in verband staan en hoe deze in databases worden opgeslagen.
- Gegevensentiteiten en relaties definiëren: Data Modelers identificeren de belangrijkste entiteiten die het datasysteem van een organisatie moet vertegenwoordigen en definiëren hoe deze entiteiten aan elkaar gerelateerd zijn.
- Zorgen voor consistentie en standaardisatie van gegevens: Ze stellen naamgevingsconventies en standaarden voor gegevenselementen vast om consistentie in de hele organisatie te garanderen.
- Samenwerking met data-ingenieurs en architecten: Data Modelers werken nauw samen met Data Engineers om ervoor te zorgen dat de data-architectuur de ontworpen modellen effectief ondersteunt.
- Databeheer en -strategie: Ze spelen vaak een rol bij databeheer en helpen bij het definiëren van beleid en standaarden voor databeheer binnen de organisatie.
Hoewel er enige overlap is in de vaardigheden en taken van Data Engineers en Data Modelers, vullen de twee rollen elkaar aan. Data Engineers richten zich op het bouwen en onderhouden van de infrastructuur die gegevensopslag en -toegang ondersteunt, terwijl Data Modelers de structuur en organisatie van gegevens binnen deze systemen ontwerpen. Ze zorgen ervoor dat de data-architectuur van een organisatie robuust en schaalbaar is en is afgestemd op de bedrijfsdoelstellingen, waardoor effectieve datagestuurde besluitvorming mogelijk is.
Belangrijkste componenten van datamodellering
Datamodellering is een cruciaal proces bij het ontwerpen en implementeren van databases en datasystemen die efficiënt en schaalbaar zijn en in staat zijn om aan de vereisten van verschillende applicaties te voldoen. De belangrijkste componenten omvatten entiteiten, attributen, relaties en sleutels. Het begrijpen van deze componenten is essentieel voor het creëren van een samenhangend en functioneel datamodel.
Entiteiten
Een entiteit vertegenwoordigt een object of concept uit de echte wereld dat duidelijk kan worden geïdentificeerd. In een database vertaalt een entiteit zich vaak in een tabel. Entiteiten worden gebruikt om de informatie die we willen opslaan te categoriseren. In een CRM-systeem (Customer Relationship Management) kunnen typische entiteiten bijvoorbeeld 'Klant', 'Bestelling' en 'Bestelling' zijn. Product.
Attributen
Attributen zijn de eigenschappen of kenmerken van een entiteit. Ze bieden details over de entiteit, waardoor deze vollediger kan worden beschreven. In een databasetabel vertegenwoordigen attributen de kolommen. Voor de entiteit 'Klant' kunnen attributen bestaan uit 'KlantID', 'Naam', 'Adres', 'Telefoonnummer', etc. Attributen definiëren het gegevenstype (zoals geheel getal, tekenreeks, datum, etc.) dat voor elke entiteit wordt opgeslagen. voorbeeld.
Relaties
Relaties beschrijven hoe entiteiten in een systeem met elkaar zijn verbonden en vertegenwoordigen hun interacties. Er zijn verschillende soorten relaties:
- Eén-op-één (1:1): Elk exemplaar van Entiteit A is gerelateerd aan slechts één exemplaar van Entiteit B, en omgekeerd.
- Eén-op-veel (1:N): Elk exemplaar van Entiteit A kan worden geassocieerd met nul, één of meerdere exemplaren van Entiteit B, maar elk exemplaar van Entiteit B is gerelateerd aan slechts één exemplaar van Entiteit A.
- Veel-op-veel (M:N): Elk exemplaar van Entiteit A kan worden geassocieerd met nul, één of meerdere exemplaren van Entiteit B, en elk exemplaar van Entiteit B kan worden geassocieerd met nul, één of meerdere exemplaren van Entiteit A.
Relaties zijn cruciaal voor het koppelen van gegevens die in verschillende entiteiten zijn opgeslagen, waardoor het ophalen en rapporteren van gegevens over meerdere tabellen wordt vergemakkelijkt.
Keys
Sleutels zijn specifieke attributen die worden gebruikt om records binnen een tabel op unieke wijze te identificeren en relaties tussen tabellen tot stand te brengen. Er zijn verschillende soorten sleutels:
- Hoofdsleutel: Een kolom of een reeks kolommen identificeert op unieke wijze elke tabelrecord. Binnen een tabel kunnen geen twee records dezelfde primaire sleutelwaarde hebben.
- Vreemde sleutel: Een kolom of een reeks kolommen in één tabel die verwijst naar de primaire sleutel van een andere tabel. Externe sleutels worden gebruikt om relaties tussen tabellen tot stand te brengen en af te dwingen.
- Samengestelde sleutel: Een combinatie van twee of meer kolommen in een tabel die kan worden gebruikt om elke record in de tabel uniek te identificeren.
- Kandidaat Sleutel: Elke kolom of reeks kolommen die in aanmerking kan komen als primaire sleutel in de tabel.
Het begrijpen en correct implementeren van deze belangrijke componenten is van fundamenteel belang voor het creëren van effectieve systemen voor gegevensopslag, -herstel en -beheer. Goede datamodellering leidt tot goed georganiseerde en geoptimaliseerde databases voor prestaties en schaalbaarheid, die de behoeften van zowel ontwikkelaars als eindgebruikers ondersteunen.
Fasen van datamodellen
Datamodellering ontvouwt zich doorgaans in drie hoofdfasen: het conceptuele datamodel, het logische datamodel en het fysieke datamodel. Elke fase dient een specifiek doel en bouwt voort op de vorige om abstracte ideeën geleidelijk om te zetten in een concreet databaseontwerp. Het begrijpen van deze fasen is van cruciaal belang voor iedereen die datasystemen maakt of beheert.
Conceptueel gegevensmodel
Het Conceptuele Datamodel is het meest abstracte niveau van datamodellering. Deze fase richt zich op het definiëren van de entiteiten op hoog niveau en de relaties daartussen, zonder in te gaan op de details van hoe de gegevens zullen worden opgeslagen. Het primaire doel is om de belangrijkste dataobjecten die relevant zijn voor het bedrijfsdomein en hun interacties te schetsen op een manier die niet-technische belanghebbenden begrijpen. Dit model wordt vaak gebruikt voor de initiële planning en communicatie, waarbij de zakelijke vereisten en de technische implementatie worden overbrugd.
Belangrijkste kenmerken zijn onder meer
- Identificatie van belangrijke entiteiten en hun relaties.
- Op hoog niveau, vaak met gebruikmaking van zakelijke terminologie.
- Onafhankelijk van welk databasebeheersysteem (DBMS) of technologie dan ook.
Logisch gegevensmodel
Het Logical Data Model voegt meer details toe aan het conceptuele model, specificeert de structuur van de data-elementen en legt de relaties daartussen vast. Het omvat de definitie van entiteiten, attributen van elke entiteit, primaire sleutels en externe sleutels. Het blijft echter nog steeds onafhankelijk van de technologie die voor de implementatie zal worden gebruikt. Het logische model is gedetailleerder en gestructureerder dan het conceptuele model en begint regels en beperkingen te introduceren die de gegevens beheersen.
Belangrijkste kenmerken zijn onder meer
- Gedetailleerde definitie van entiteiten, relaties en attributen.
- Het opnemen van primaire sleutels en externe sleutels is noodzakelijk om relaties tot stand te brengen.
- Normalisatieprocessen worden toegepast om de gegevensintegriteit te waarborgen en redundantie te verminderen.
- Nog steeds onafhankelijk van de specifieke DBMS-technologie.
Fysiek gegevensmodel
Het Physical Data Model is de meest gedetailleerde fase en omvat de implementatie van het datamodel binnen een specifiek databasebeheersysteem. Dit model vertaalt het logische datamodel naar een gedetailleerd schema dat in een database kan worden geïmplementeerd. Het bevat alle noodzakelijke details voor implementatie, zoals tabellen, kolommen, gegevenstypen, beperkingen, indexen, triggers en andere databasespecifieke functies.
Belangrijke kenmerken zijn onder meer
- Specifiek voor een bepaald DBMS en omvat databasespecifieke optimalisatie.
- Gedetailleerde specificaties van tabellen, kolommen, gegevenstypen en beperkingen.
- Overweging van fysieke opslagopties, indexeringsstrategieën en prestatie-optimalisatie.
Door deze fasen te doorlopen, is een nauwgezette planning en ontwerp mogelijk van een datasysteem dat is afgestemd op de zakelijke vereisten en is geoptimaliseerd voor prestaties binnen een specifieke technische omgeving. Het conceptuele model zorgt ervoor dat de algehele structuur aansluit bij de bedrijfsdoelen, het logische model overbrugt de kloof tussen conceptuele planning en fysieke implementatie, en het fysieke model zorgt ervoor dat de database wordt geoptimaliseerd voor daadwerkelijk gebruik.
Voorbeeld schooldataset
Entiteiten: studenten, docenten en klassen.
Conceptueel gegevensmodel
Dit conceptuele datamodel schetst een databasesysteem voor het beheren van schoolgegevens, met drie primaire entiteiten: leerling, leraar en klas. In dit model kunnen studenten aan meerdere docenten en klassen worden gekoppeld, terwijl docenten meerdere studenten kunnen instrueren en verschillende klassen kunnen leiden. Elke klas biedt plaats aan een groot aantal studenten, maar wordt gegeven door één leraar. Het ontwerp heeft tot doel het begrip van de relaties tussen entiteiten te vereenvoudigen voor zowel technische als niet-technische belanghebbenden, waardoor een duidelijk en intuïtief overzicht wordt geboden van de systeemstructuur. Door te beginnen met een conceptueel model is de geleidelijke integratie van meer gedetailleerde elementen mogelijk, waardoor een solide basis wordt gelegd voor de ontwikkeling van geavanceerde databasemodellen.
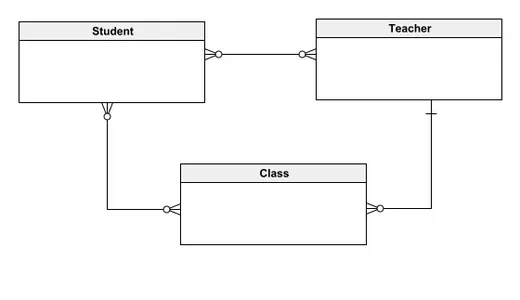
Logisch gegevensmodel
Het logische datamodel, zeer geliefd vanwege zijn evenwicht tussen duidelijkheid en detail, omvat entiteiten, relaties, attributen, PRIMARY KEYS en FOREIGN KEYS. Het schetst minutieus de logische voortgang van de gegevens binnen een database, waarbij gedetailleerde details worden verduidelijkt, zoals de samenstelling ervan of de gebruikte gegevenstypen. Het logische datamodel biedt voldoende basis voor softwareontwikkeling om met de daadwerkelijke databaseconstructie te beginnen.
Laten we, uitgaande van het eerder besproken conceptuele datamodel, een typisch logisch datamodel onderzoeken. In tegenstelling tot zijn conceptuele voorganger is dit model verrijkt met attributen en primaire sleutels. De studententiteit onderscheidt zich bijvoorbeeld door een StudentID als primaire sleutel en unieke identificatie, naast andere essentiële kenmerken zoals naam en leeftijd.
Deze aanpak wordt consequent toegepast op andere entiteiten, zoals Leraar en Klas, waarbij de relaties die in het conceptuele model zijn vastgelegd behouden blijven en het model toch wordt uitgebreid met een gedetailleerd schema dat attributen en sleutelidentificaties omvat.
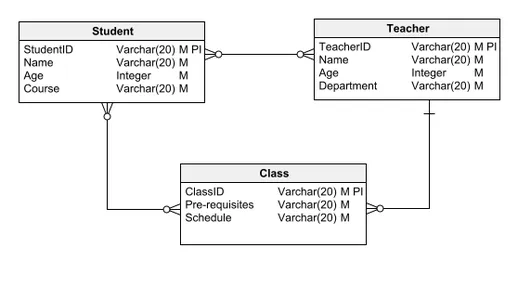
Fysiek gegevensmodel
Het fysieke datamodel is het meest gedetailleerd van de abstractieniveaus en bevat specifieke kenmerken die zijn afgestemd op het gekozen databasebeheersysteem, zoals PostgreSQL, Oracle of MySQL. In dit model worden entiteiten vertaald in tabellen en worden attributen kolommen, die de structuur van een daadwerkelijke database weerspiegelen. Aan elke kolom wordt een specifiek gegevenstype toegewezen, bijvoorbeeld INT voor gehele getallen, VARCHAR voor variabele tekenreeksen of DATE voor datums.
Gezien de gedetailleerde aard ervan, duikt het fysieke datamodel in de technische details die uniek zijn voor het gebruikte databaseplatform. Deze allesomvattende aspecten reiken verder dan het bestek van een overzicht op hoog niveau. Dit omvat overwegingen zoals opslagtoewijzing, indexeringsstrategieën en implementatiebeperkingen, die cruciaal zijn voor de prestaties en integriteit van de database, maar doorgaans te gedetailleerd zijn voor een voorafgaande discussie.

Fasen van datamodellering
- Begrijp zakelijke vereisten: Voer gedetailleerde discussies met belanghebbenden om het zakelijke doel van de database te begrijpen. Belangrijke overwegingen zijn onder meer het identificeren van het bedrijfsdomein, de behoeften aan gegevensopslag en de problemen die de database wil oplossen. Focus op het afstemmen van databaseontwerp op bedrijfsdoelstellingen met betrekking tot prestaties, kosten en beveiliging.
- Teamsamenwerking: Werk nauw samen met andere teams (bijvoorbeeld UX/UI-ontwerpers en ontwikkelaars) om ervoor te zorgen dat de database de bredere oplossing ondersteunt. Pas gegevensformaten en -typen aan om aan de toepassingsvereisten te voldoen, waarbij de nadruk ligt op samenwerkingsontwerp en communicatieve vaardigheden.
- Maak gebruik van industriestandaarden: Onderzoek bestaande modellen en standaarden om te voorkomen dat u helemaal opnieuw moet beginnen. Maak gebruik van best practices uit de branche om tijd en middelen te besparen, waarbij u unieke inspanningen richt op aspecten van uw database die deze onderscheiden van bestaande modellen.
- Begin met databasemodellering: Met een goed begrip van de bedrijfsbehoeften, de input van het team en de industriestandaarden kunt u beginnen met conceptuele modellering, vervolgens naar logisch modelleren en eindigen met het fysieke model. Deze gestructureerde aanpak zorgt voor een alomvattend inzicht in de vereiste entiteiten, attributen en relaties, waardoor een soepele database-implementatie mogelijk wordt gemaakt die is afgestemd op de bedrijfsdoelstellingen.
Tools voor datamodellering zijn essentieel voor het ontwerpen, onderhouden en ontwikkelen van organisatorische datastructuren. Deze tools bieden een reeks functionaliteiten ter ondersteuning van de gehele levenscyclus van databaseontwerp en -beheer. De belangrijkste kenmerken waar u op moet letten in tools voor gegevensmodellering zijn onder meer:
- Gegevensmodellen bouwen: Vergemakkelijk de creatie van conceptuele, logische en fysieke datamodellen, waardoor de duidelijke definitie van entiteiten, attributen en relaties mogelijk wordt. Deze kernfunctionaliteit ondersteunt het initiële en voortdurende ontwerp van databasearchitectuur.
- Samenwerking en centrale opslagplaats: Stel teamleden in staat samen te werken aan het ontwerp en de aanpassingen van datamodellen. Een centrale repository zorgt ervoor dat de nieuwste versies toegankelijk zijn voor alle belanghebbenden, wat de consistentie en efficiëntie bij de ontwikkeling bevordert.
- Reverse engineering: Bied de mogelijkheid om SQL-scripts te importeren of verbinding te maken met bestaande databases om datamodellen te genereren. Dit is met name handig voor het begrijpen en documenteren van oudere systemen of het integreren van bestaande databases.
- Voorwaartse techniek: Maakt het mogelijk om SQL-scripts of code uit het datamodel te genereren. Deze functie stroomlijnt de implementatie van wijzigingen in de databasestructuur en zorgt ervoor dat de fysieke database het nieuwste model weerspiegelt.
- Ondersteuning voor verschillende databasetypen: Bied compatibiliteit met meerdere databasebeheersystemen (DBMS), zoals MySQL, PostgreSQL, Oracle, SQL Server en meer. Deze flexibiliteit zorgt ervoor dat de tool in verschillende projecten en technologische omgevingen kan worden gebruikt.
- Versiebeheer: Voeg versiebeheersystemen toe of integreer ze om wijzigingen in datamodellen in de loop van de tijd bij te houden. Deze functie is cruciaal voor het beheren van iteraties van de databasestructuur en het vergemakkelijken van het terugdraaien naar eerdere versies indien nodig.
- Diagrammen in verschillende formaten exporteren: Stel gebruikers in staat datamodellen en diagrammen in verschillende formaten te exporteren (bijvoorbeeld PDF, PNG, XML), waardoor het delen en documenteren eenvoudig wordt. Dit zorgt ervoor dat ook niet-technische belanghebbenden de data-architectuur kunnen beoordelen en begrijpen.
Het kiezen van een datamodelleringstool met deze functies kan de efficiëntie, nauwkeurigheid en samenwerking van databeheerinspanningen binnen een organisatie aanzienlijk verbeteren, waardoor ervoor wordt gezorgd dat databases goed ontworpen, up-to-date en afgestemd op de zakelijke behoeften zijn.
ER/studio

Biedt uitgebreide modelleringsmogelijkheden en samenwerkingsfuncties en ondersteunt verschillende databaseplatforms.
IBM InfoSphere-gegevensarchitect

Biedt een robuuste omgeving voor het ontwerpen en beheren van datamodellen met ondersteuning voor integratie en synchronisatie met andere IBM-producten.
IBM InfoSphere Data Architect-link
Oracle SQL Developer Data Modeler

Een gratis tool die forward- en reverse-engineering, versiebeheer en ondersteuning voor meerdere databases ondersteunt.
Oracle SQL Developer Data Modeler-link
PowerDesigner (SAP)

Biedt uitgebreide modelleringsfuncties, waaronder ondersteuning voor gegevens, informatie en bedrijfsarchitectuur.
Navicat-gegevensmodeller
Het staat bekend om zijn gebruiksvriendelijke interface en ondersteuning voor een breed scala aan databases en maakt forward- en reverse-engineering mogelijk.
Deze tools stroomlijnen het datamodelleringsproces, verbeteren de samenwerking tussen teams en zorgen voor compatibiliteit tussen verschillende databasesystemen.
Lees ook: Interviewvragen voor gegevensmodellering
Conclusie
Dit artikel ging dieper in op de essentiële praktijk van datamodellering en benadrukte de cruciale rol ervan bij het organiseren, opslaan en benaderen van gegevens in databases en datasystemen. Door het proces op te splitsen in conceptuele, logische en fysieke modellen, hebben we geïllustreerd hoe datamodellering de bedrijfsbehoeften vertaalt in gestructureerde dataframeworks, waardoor efficiënte dataverwerking en inzichtelijke analyses worden vergemakkelijkt.
Belangrijke punten zijn onder meer het belang van het begrijpen van de bedrijfsvereisten, het collaboratieve karakter van databaseontwerp waarbij verschillende belanghebbenden betrokken zijn, en het strategische gebruik van datamodelleringstools om het ontwikkelingsproces te stroomlijnen. Datamodellering zorgt ervoor dat datastructuren worden geoptimaliseerd voor de huidige behoeften en biedt schaalbaarheid voor toekomstige groei.
Datamodellering vormt de kern van effectief databeheer, waardoor organisaties hun data kunnen inzetten voor strategische besluitvorming en operationele efficiëntie.
Veelgestelde Vragen / FAQ
Ant. Gegevensmodellering geeft visueel de gegevens van een systeem weer en schetst hoe deze worden opgeslagen, georganiseerd en toegankelijk. Het is van cruciaal belang voor het vertalen van zakelijke vereisten naar een gestructureerd databaseformaat, waardoor efficiënt gegevensgebruik mogelijk wordt.
Ant. Belangrijke gebruiksscenario's zijn onder meer het verzamelen, laden van gegevens, bedrijfsberekeningen en distributie, waardoor gegevens effectief worden verzameld, opgeslagen en gebruikt voor zakelijke inzichten.
Ant. Data-ingenieurs bouwen en onderhouden de data-infrastructuur, terwijl datamodelleurs de structuur en organisatie van de data ontwerpen om bedrijfsdoelen en data-integriteit te ondersteunen.
Ant. Het proces gaat van het begrijpen van de bedrijfsvereisten naar het samenwerken met teams, het benutten van industriestandaarden en het modelleren van de database via conceptuele, logische en fysieke fasen.
Ant. Deze tools vergemakkelijken het ontwerp, de samenwerking en de evolutie van datamodellen, ondersteunen verschillende databasetypen en maken reverse en forward engineering mogelijk voor efficiënt databasebeheer.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2024/03/data-modeling-demystified-crafting-efficient-databases-for-business-insights/

