Introductie
Retrieval Augmented-Generation (RAG) heeft de wereld vanaf het begin veroverd. RAG is wat nodig is voor de Large Language Models (LLM's) om nauwkeurige en feitelijke antwoorden te geven of te genereren. We lossen de feitelijkheid van LLM's op met behulp van RAG, waarbij we proberen de LLM een context te geven die contextueel vergelijkbaar is met de gebruikersvraag, zodat de LLM met deze context zal werken en een feitelijk correct antwoord zal genereren. We doen dit door onze gegevens en gebruikersquery's weer te geven in de vorm van vectorinbedding en door een cosinus-overeenkomst uit te voeren. Maar het probleem is dat alle traditionele benaderingen de gegevens in één enkele inbedding weergeven, wat misschien niet ten goede is ophaalsystemen. In deze handleiding zullen we kijken naar ColBERT, dat het ophalen met een grotere nauwkeurigheid uitvoert dan traditionele bi-encodermodellen.
leerdoelen
- Begrijp hoe ophalen in RAG op een hoog niveau werkt.
- Begrijp de beperkingen van enkele insluitingen bij het ophalen.
- Verbeter de ophaalcontext met de token-inbedding van ColBERT.
- Ontdek hoe de late interactie van ColBERT het ophalen verbetert.
- Leer hoe u met ColBERT kunt werken voor nauwkeurig ophalen.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Wat is RAG?
Hoewel LLM's tekst kunnen genereren die zowel betekenisvol als grammaticaal correct is, lijden deze LLM's aan een probleem dat hallucinatie wordt genoemd. Hallucinatie bij LLM's is het concept waarbij de LLM's zelfverzekerd verkeerde antwoorden genereren, dat wil zeggen dat ze verkeerde antwoorden verzinnen op een manier die ons doet geloven dat het waar is. Dit is een groot probleem sinds de introductie van de LLM's. Deze hallucinaties leiden tot onjuiste en feitelijk verkeerde antwoorden. Daarom werd Retrieval Augmented Generation geïntroduceerd.
In RAG nemen we een lijst met documenten/stukjes documenten en coderen deze tekstdocumenten in een numerieke representatie die vectorinbedding wordt genoemd, waarbij een enkele vectorinbedding een enkel stuk document vertegenwoordigt en deze opslaat in een database met de naam vector winkel. De modellen die nodig zijn voor het coderen van deze chunks in inbedding worden coderingsmodellen of bi-encoders genoemd. Deze encoders zijn getraind op een groot corpus aan gegevens, waardoor ze krachtig genoeg zijn om de delen van documenten te coderen in een enkele vector-inbeddingsrepresentatie.
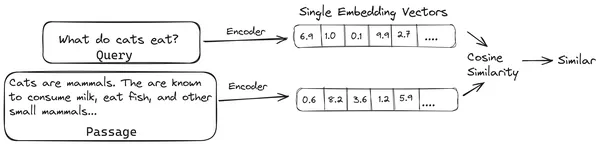
Wanneer een gebruiker nu een vraag aan de LLM stelt, geven we deze vraag aan dezelfde encoder om een enkele vectorinbedding te produceren. Deze inbedding wordt vervolgens gebruikt om de gelijkenisscore met verschillende andere vectorinbeddingen van de documentfragmenten te berekenen om het meest relevante deel van het document te verkrijgen. Het meest relevante deel of een lijst met de meest relevante delen wordt samen met de gebruikersquery aan de LLM gegeven. De LLM ontvangt vervolgens deze extra contextuele informatie en genereert vervolgens een antwoord dat is afgestemd op de context die is ontvangen van de gebruikersvraag. Dit zorgt ervoor dat de door de LLM gegenereerde inhoud feitelijk is en indien nodig herleidbaar.
Het probleem met traditionele bi-encoders
Het probleem met traditionele Encoder-modellen zoals de volledig miniLM, OpenAI inbeddingsmodel en andere encodermodellen is dat ze de volledige tekst comprimeren tot een enkele vectorinbeddingsrepresentatie. Deze representaties met enkele vectorinbedding zijn nuttig omdat ze helpen bij het efficiënt en snel ophalen van soortgelijke documenten. Het probleem ligt echter in de contextualiteit tussen de query en het document. Het insluiten van een enkele vector is mogelijk niet voldoende om de contextuele informatie van een documentdeel op te slaan, waardoor een informatieknelpunt ontstaat.
Stel je voor dat 500 woorden worden gecomprimeerd tot een enkele vector met een grootte van 782. Het kan zijn dat het niet voldoende is om zo'n brok weer te geven met een enkele vectorinbedding, waardoor in de meeste gevallen onvoldoende resultaten worden verkregen bij het ophalen. De enkele vectorrepresentatie kan ook mislukken in het geval van complexe query's of documenten. Eén zo'n oplossing zou zijn om het documentdeel of een query weer te geven als een lijst met inbeddingsvectoren in plaats van een enkele inbeddingsvector. Dit is waar ColBERT in beeld komt.
Wat is ColBERT?
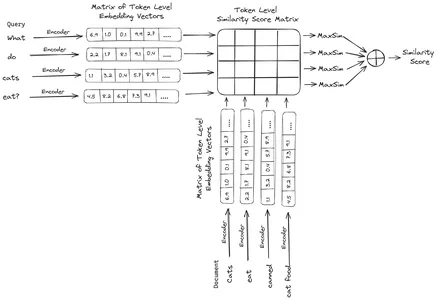
ColBERT (Contextual Late Interactions BERT) is een bi-encoder die tekst representeert in een representatie met meerdere vectoren. Het neemt een query of een deel van een document/een klein document op en creëert vectorinsluitingen op tokenniveau. Dat wil zeggen dat elk token zijn eigen vectorinbedding krijgt, en dat de query/het document wordt gecodeerd naar een lijst met vectorinbedding op tokenniveau. De insluitingen op tokenniveau worden gegenereerd op basis van een vooraf getrainde BERT model vandaar de naam BERT.
Deze worden vervolgens opgeslagen in de vectordatabase. Wanneer er nu een query binnenkomt, wordt er een lijst met insluitingen op tokenniveau voor gemaakt en wordt vervolgens een matrixvermenigvuldiging uitgevoerd tussen de gebruikersquery en elk document, wat resulteert in een matrix met gelijkenisscores. De algehele gelijkenis wordt bereikt door voor elk querytoken de som te nemen van de maximale gelijkenis tussen de documenttokens. De formule hiervoor is te zien op de onderstaande afbeelding:
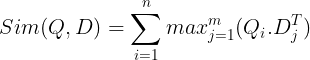
Hier in de bovenstaande vergelijking zien we dat we een puntproduct maken tussen de Query Tokens Matrix (met vectorinbedding op N-tokenniveau) en de Transpose of Document Tokens Matrix (die vectorinbedding op M-tokenniveau bevat), en dan nemen we de maximale gelijkenis kruis de documenttokens voor elk querytoken. Vervolgens nemen we de som van al deze maximale overeenkomsten, wat ons de uiteindelijke overeenkomstscore tussen het document en de zoekopdracht oplevert. De reden waarom dit effectief en nauwkeurig ophalen oplevert, is dat we hier te maken hebben met een interactie op tokenniveau, die ruimte geeft voor meer contextueel begrip tussen de query en het document.
Waarom de naam ColBERT?
Omdat we de lijst met inbeddingsvectoren vóór zichzelf berekenen en deze MaxSim-bewerking (maximale gelijkenis) alleen uitvoeren tijdens de modelinferentie, waardoor het een late interactiestap wordt genoemd, en omdat we meer contextuele informatie krijgen via interacties op tokenniveau, wordt dit contextueel genoemd. late interacties. Vandaar de naam Contextuele Late Interacties BERT of ColBERT. Deze berekeningen kunnen parallel worden uitgevoerd, waardoor ze efficiënt kunnen worden berekend. Ten slotte is er één zorg: de ruimte, dat wil zeggen dat er veel ruimte nodig is om deze lijst met vectorinbedding op tokenniveau op te slaan. Dit probleem is opgelost in de ColBERTv2, waarbij de inbeddingen worden gecomprimeerd via de techniek die residuele compressie wordt genoemd, waardoor de gebruikte ruimte wordt geoptimaliseerd.
Praktische ColBERT met voorbeeld
In deze sectie gaan we aan de slag met de ColBERT en controleren we zelfs hoe deze presteert in vergelijking met een regulier inbeddingsmodel.
Stap 1: Bibliotheken downloaden
We beginnen met het downloaden van de volgende bibliotheek:
!pip install ragatouille langchain langchain_openai chromadb einops sentence-transformers tiktoken- RAGatouille: Met deze bibliotheek kunnen we op een eenvoudig te gebruiken manier werken met de modernste (SOTA) ophaalmethoden zoals ColBERT. Het biedt opties om indexen over de datasets te maken, er query's op uit te voeren en ons zelfs in staat te stellen een ColBERT-model op onze data te trainen.
- LangChain: Deze bibliotheek laat ons werken met de open-source inbeddingsmodellen, zodat we kunnen testen hoe goed de andere inbeddingsmodellen werken in vergelijking met de ColBERT.
- langketen_openai: Installeert de LangChain afhankelijkheden voor OpenAI. We zullen zelfs werken met het OpenAI Embedding-model om de prestaties ervan te vergelijken met die van ColBERT.
- ChromaDB: Met deze bibliotheek kunnen we een vectorarchief in onze omgeving maken, zodat we de insluitingen die we in onze gegevens hebben gemaakt, kunnen opslaan en later een semantische zoekopdracht kunnen uitvoeren tussen de zoekopdracht en de opgeslagen insluitingen.
- einops: Deze bibliotheek is nodig voor efficiënte tensormatrixvermenigvuldigingen.
- zin-transformatoren en tiktoken bibliotheek zijn nodig om de open-source inbeddingsmodellen goed te laten werken.
Stap 2: Download het vooraf getrainde model
In de volgende stap downloaden we het vooraf getrainde ColBERT-model. Hiervoor zal de code zijn
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")- We importeren eerst de klasse RAGPretrainedModel uit de RAGatouille-bibliotheek.
- Vervolgens roepen we .from_pretrained() aan en geven we de modelnaam, bijvoorbeeld “colbert-ir/colbertv2.0”.
Als u de bovenstaande code uitvoert, wordt een ColBERT RAG-model geïnstantieerd. Laten we nu een Wikipedia-pagina downloaden en deze ophalen. Hiervoor wordt de code:
from ragatouille.utils import get_wikipedia_page
document = get_wikipedia_page("Elon_Musk")
print("Word Count:",len(document))
print(document[:1000])De RAGatouille wordt geleverd met een handige functie genaamd get_wikipedia_page, die een string opneemt en de corresponderende Wikipedia-pagina ophaalt. Hier downloaden we de Wikipedia-inhoud over Elon Musk en slaan deze op in het variabele document. Laten we het aantal woorden in het document en de eerste paar regels van het document afdrukken.
Hier kunnen we de output op de foto zien. We kunnen zien dat er in totaal 64,668 woorden op de Wikipedia-pagina van Elon Musk staan.
Stap 3: Indexeren
Nu gaan we een index op dit document maken.
RAG.index(
# List of Documents
collection=[document],
# List of IDs for the above Documents
document_ids=['elon_musk'],
# List of Dictionaries for the metadata for the above Documents
document_metadatas=[{"entity": "person", "source": "wikipedia"}],
# Name of the index
index_name="Elon2",
# Chunk Size of the Document Chunks
max_document_length=256,
# Wether to Split Document or Not
split_documents=True
)Hier roepen we de .index() van de RAG aan om ons document te indexeren. Hiervoor geven we het volgende door:
- verzameling: Dit is een lijst met documenten die we willen indexeren. Hier hebben we slechts één document, vandaar een lijst van één enkel document.
- document_ids: Elk document verwacht een unieke document-ID. Hier geven we de naam elon_musk door omdat het document over Elon Musk gaat.
- document_metadatas: Elk document heeft zijn metagegevens. Dit is opnieuw een lijst met woordenboeken, waarbij elk woordenboek een sleutel-waardepaar metagegevens voor een bepaald document bevat.
- indexnaam: De naam van de index die we maken. Laten we het Elon2 noemen.
- max_document_size: Dit is vergelijkbaar met de brokgrootte. We specificeren hoeveel elk documentstuk moet zijn. Hier geven we het de waarde 256. Als we geen waarde opgeven, wordt 256 als de standaard chunkgrootte genomen.
- gesplitste_documenten: Het is een Booleaanse waarde, waarbij True aangeeft dat we ons document willen splitsen op basis van de opgegeven chunkgrootte, en False aangeeft dat we het hele document als één enkel chunk willen opslaan.
Door de bovenstaande code uit te voeren, wordt ons document opgedeeld in groottes van 256 per stuk, en vervolgens ingebed via het ColBERT-model, dat voor elk stuk een lijst met vectorinsluitingen op tokenniveau zal produceren en deze uiteindelijk in een index zal opslaan. Het uitvoeren van deze stap kost enige tijd en kan worden versneld als u over een GPU beschikt. Ten slotte creëert het een map waarin onze index wordt opgeslagen. Hier zal de map “.ragatouille/colbert/indexes/Elon2” zijn
Stap 4: Algemene vraag
Nu zullen we beginnen met zoeken. Hiervoor zal de code zijn
results = RAG.search(query="What companies did Elon Musk find?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc["content"])- Hier roepen we eerst de .search() -methode van het RAG-object aan
- Hieraan geven we de variabelen die de naam van de zoekopdracht, k (aantal op te halen documenten) en de indexnaam om te doorzoeken bevatten
- Hier geven we de vraag “Welke bedrijven heeft Elon Musk gevonden?”. Het verkregen resultaat staat in een lijst met woordenboekindelingen, die de sleutels bevat zoals inhoud, score, rang, document_id, passage_id en document_metadata
- Daarom werken wij met onderstaande code om de opgehaalde documenten op een nette manier af te drukken
- Hier doorlopen we de lijst met woordenboeken en drukken we de inhoud van de documenten af
Het uitvoeren van de code levert de volgende resultaten op:
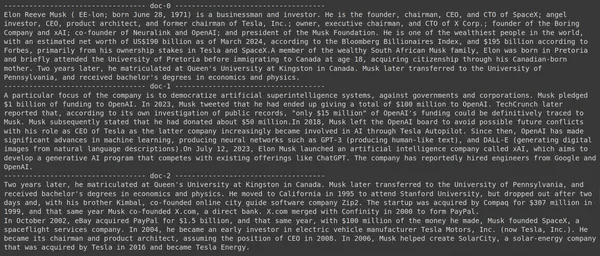
Op de foto kunnen we zien dat het eerste en het laatste document volledig de verschillende bedrijven bestrijken die door Elon Musk zijn opgericht. De ColBERT was in staat om de relevante chunks die nodig waren om de vraag te beantwoorden, correct op te halen.
Stap 5: Specifieke vraag
Laten we nu een stap verder gaan en een specifieke vraag stellen.
results = RAG.search(query="How much Tesla stocks did Elon sold in
Decemeber 2022?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------
------------------- doc-{i} ------------------------------------")
print(doc["content"])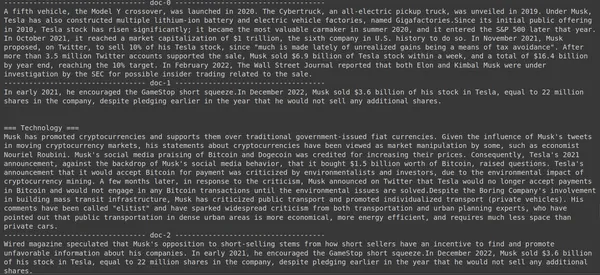
Hier in de bovenstaande code stellen we een zeer specifieke vraag over hoeveel aandelen Tesla Elon er in de maand december 2022 zijn verkocht. We kunnen de output hier zien. Het doc-1 bevat het antwoord op de vraag. Elon heeft voor 3.6 miljard dollar aan aandelen in Tesla verkocht. Opnieuw kon ColBERT met succes het relevante deel voor de gegeven zoekopdracht ophalen.
Stap 6: Andere modellen testen
Laten we nu dezelfde vraag proberen met de andere inbeddingsmodellen, zowel open-source als gesloten:
from langchain_community.embeddings import HuggingFaceEmbeddings
from transformers import AutoModel
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model_name = "jinaai/jina-embeddings-v2-base-en"
model_kwargs = {'device': 'cpu'}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
)
- We beginnen met het downloaden van het model eerst via de AutoModel-klasse uit de Transformers-bibliotheek.
- Vervolgens slaan we de model_name en de model_kwargs op in hun respectievelijke variabelen.
- Om nu met dit model in LangChain te werken, importeren we de HuggingFaceEmbeddings uit de LangChain en geef het de modelnaam en het model_kwargs.
Als u deze code uitvoert, wordt het Jina-insluitingsmodel gedownload en geladen, zodat we ermee kunnen werken
Stap 7: Maak insluitingen
Nu moeten we beginnen met het splitsen van ons document en er vervolgens insluitingen van maken en deze opslaan in de Chroma-vectorwinkel. Hiervoor werken we met de volgende code:
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=256,
chunk_overlap=0)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})- We beginnen met het importeren van de Chroma en de RecursiveCharacterTextSplitter uit de LangChain-bibliotheek
- Vervolgens instantiëren we een text_splitter door de .from_tiktoken_encoder van de RecursiveCharacterTextSplitter aan te roepen en deze de chunk_size en chunk_overlap door te geven
- Hier zullen we dezelfde chunk_size gebruiken die we aan de ColBERT hebben verstrekt
- Vervolgens roepen we de methode .split_text() van deze text_splitter aan en geven hem het document met Wikipedia-informatie over Elon Musk. Vervolgens wordt het document gesplitst op basis van de opgegeven blokgrootte en ten slotte wordt de lijst met documentblokken opgeslagen in de variabele splitsingen
- Ten slotte roepen we de functie .from_texts() van de klasse Chroma aan om een vectorarchief te maken. Aan deze functie geven we de splitsingen, het inbeddingsmodel en de collectienaam
- Nu maken we er een retriever van door de functie .as_retriever() van het vectoropslagobject aan te roepen. We geven 3 voor de k-waarde
Als u deze code uitvoert, wordt ons document opgesplitst in kleinere documenten met een grootte van 256 per stuk, en vervolgens deze kleinere stukken ingesloten met het Jina-inbeddingsmodel en deze inbeddingsvectoren opgeslagen in de chroma-vectoropslag.
Stap 8: Een retriever maken
Ten slotte maken we er een retriever van. Nu zullen we een vectorzoekopdracht uitvoeren en de resultaten controleren.
docs = retriever.get_relevant_documents("What companies did Elon Musk find?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)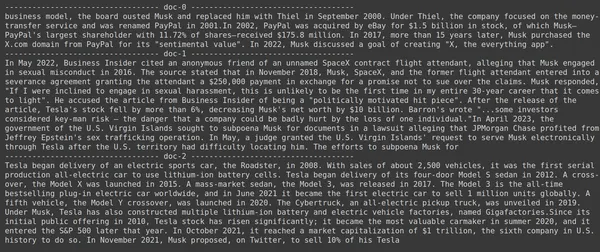
- We roepen de functie .get_relevent_documents() van het retriever-object aan en geven deze dezelfde vraag.
- Vervolgens printen wij de top 3 opgehaalde documenten netjes af.
- Op de foto kunnen we zien dat de Jina Embedder, ondanks dat het een populair inbeddingsmodel is, de vindbaarheid van onze zoekopdracht slecht is. Het lukte niet om de juiste documentfragmenten te verkrijgen.
We kunnen duidelijk het verschil zien tussen de Jina, het inbeddingsmodel dat elk deel representeert als een enkele vectorinbedding, en het ColBERT-model dat elk deel vertegenwoordigt als een lijst van inbeddingsvectoren op tokenniveau. De ColBERT presteert in dit geval duidelijk beter.
Stap 9: Het inbeddingsmodel van OpenAI testen
Laten we nu proberen een insluitingsmodel met gesloten bron te gebruiken, zoals het OpenAI Embedding-model.
import os
os.environ["OPENAI_API_KEY"] = "Your API Key"
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name = "gpt-4",
chunk_size = 256,
chunk_overlap = 0,
)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon_collection")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})Hier lijkt de code sterk op de code die we zojuist hebben geschreven
- Het enige verschil is dat we de OpenAI API-sleutel doorgeven om de omgevingsvariabele in te stellen.
- Vervolgens maken we een exemplaar van het OpenAI Embedding-model door het uit de LangChain te importeren.
- En tijdens het aanmaken van de collectienaam geven we een andere collectienaam, zodat de embeddings uit het OpenAI Embedding-model in een andere collectie worden opgeslagen.
Als u deze code uitvoert, worden onze documenten opnieuw in kleinere documenten van grootte 256 opgedeeld en vervolgens in een enkele vector-inbeddingsrepresentatie ingesloten met het OpenAI-inbeddingsmodel en uiteindelijk deze inbedding opgeslagen in de Chroma Vector Store. Laten we nu proberen de relevante documenten voor de andere vraag op te halen.
docs = retriever.get_relevant_documents("How much Tesla stocks did Elon sold in Decemeber 2022?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)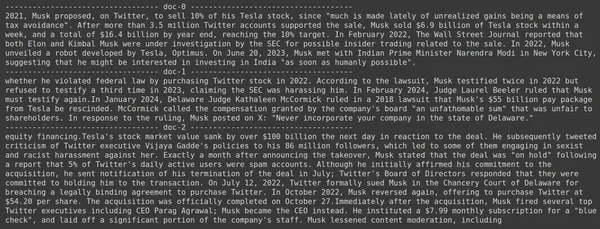
- We zien dat het antwoord dat we verwachten niet wordt gevonden in de opgehaalde chunks.
- Het eerste deel bevat informatie over Tesla-aandelen in 2022, maar er wordt niet gesproken over de verkoop van Elon.
- Hetzelfde is te zien bij de overige twee documentfragmenten, waar de informatie die ze bevatten gaat over Tesla en zijn aandelen, maar dit is niet de informatie die we verwachten.
- De hierboven opgehaalde brokken bieden niet de context voor de LLM om de door ons gestelde vraag te beantwoorden.
Zelfs hier kunnen we een duidelijk verschil zien tussen de inbeddingsrepresentatie met één vector versus de inbeddingsrepresentatie met meerdere vectoren. De multi-inbedding representaties leggen de complexe vragen duidelijk vast, wat resulteert in nauwkeurigere opzoekingen.
Conclusie
Concluderend demonstreert ColBERT een aanzienlijke vooruitgang in de ophaalprestaties ten opzichte van traditionele bi-encodermodellen door tekst weer te geven als multi-vector inbedding op tokenniveau. Deze aanpak zorgt voor een meer genuanceerd contextueel begrip tussen vragen en documenten, wat leidt tot nauwkeurigere ophaalresultaten en het verminderen van het probleem van hallucinaties die vaak worden waargenomen bij LLM's.
Key Takeaways
- RAG pakt het probleem van hallucinaties bij LLM's aan door contextuele informatie te bieden voor het genereren van feitelijke antwoorden.
- Traditionele bi-encoders hebben last van een informatieknelpunt doordat hele teksten worden gecomprimeerd in enkele vectorinbedding, wat resulteert in een ondermaatse ophaalnauwkeurigheid.
- ColBERT, met zijn inbeddingsrepresentatie op tokenniveau, vergemakkelijkt een beter contextueel begrip tussen query's en documenten, wat leidt tot verbeterde ophaalprestaties.
- De late interactiestap in ColBERT, gecombineerd met interacties op tokenniveau, verbetert de nauwkeurigheid van het ophalen door rekening te houden met contextuele nuances.
- ColBERTv2 optimaliseert de opslagruimte door restcompressie, terwijl de ophaaleffectiviteit behouden blijft.
- Praktische experimenten demonstreren de superioriteit van ColBERT op het gebied van ophaalprestaties vergeleken met traditionele en open-source inbeddingsmodellen zoals Jina en OpenAI Embedding.
Veelgestelde Vragen / FAQ
A. Traditionele bi-encoders comprimeren hele teksten tot enkele vectorinbedding, waardoor mogelijk contextuele informatie verloren gaat. Dit beperkt hun effectiviteit bij het ophalen van taken, vooral bij complexe query's of documenten.
A. ColBERT (Contextual Late Interactions BERT) is een bi-encodermodel dat tekst representeert met behulp van vectorinbedding op tokenniveau. Het zorgt voor een meer genuanceerd contextueel begrip tussen query's en documenten, waardoor de nauwkeurigheid van het ophalen wordt verbeterd.
A. ColBERT genereert insluitingen op tokenniveau voor query's en documenten, voert matrixvermenigvuldiging uit om gelijkenisscores te berekenen en selecteert vervolgens de meest relevante informatie op basis van maximale gelijkenis tussen tokens. Dit maakt effectief ophalen met contextueel begrip mogelijk.
A. ColBERTv2 optimaliseert de ruimte via de residuele compressiemethode, waardoor de opslagvereisten voor inbedding op tokenniveau worden verminderd, terwijl de ophaalnauwkeurigheid behouden blijft.
A. U kunt bibliotheken zoals RAGatouille gebruiken om eenvoudig met ColBERT te werken. Door documenten en query's te indexeren, kunt u efficiënte ophaaltaken uitvoeren en nauwkeurige antwoorden genereren die zijn afgestemd op de context.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2024/04/colbert-improve-retrieval-performance-with-token-level-vector-embeddings/

