Metrieken zijn een belangrijk onderdeel van machine learning. Met betrekking tot classificatietaken zijn er verschillende soorten metrische gegevens waarmee u de prestaties van machine learning-modellen kunt beoordelen. Het kan echter moeilijk zijn om de juiste te kiezen voor uw taak.
In dit artikel zal ik 4 algemene classificatiestatistieken doornemen: nauwkeurigheid, precisie, terugroepactie en ROC met betrekking tot logistieke regressie.
Laten we beginnen…
Logistieke regressie is een vorm van begeleid leren - wanneer het algoritme leert op een gelabelde dataset en de trainingsgegevens analyseert. Logistieke regressie wordt meestal gebruikt voor binaire classificatieproblemen op basis van zijn 'logistieke functie'.
Binaire classificatie kan hun klassen weergeven als: positief/negatief, 1/0 of waar/onwaar.
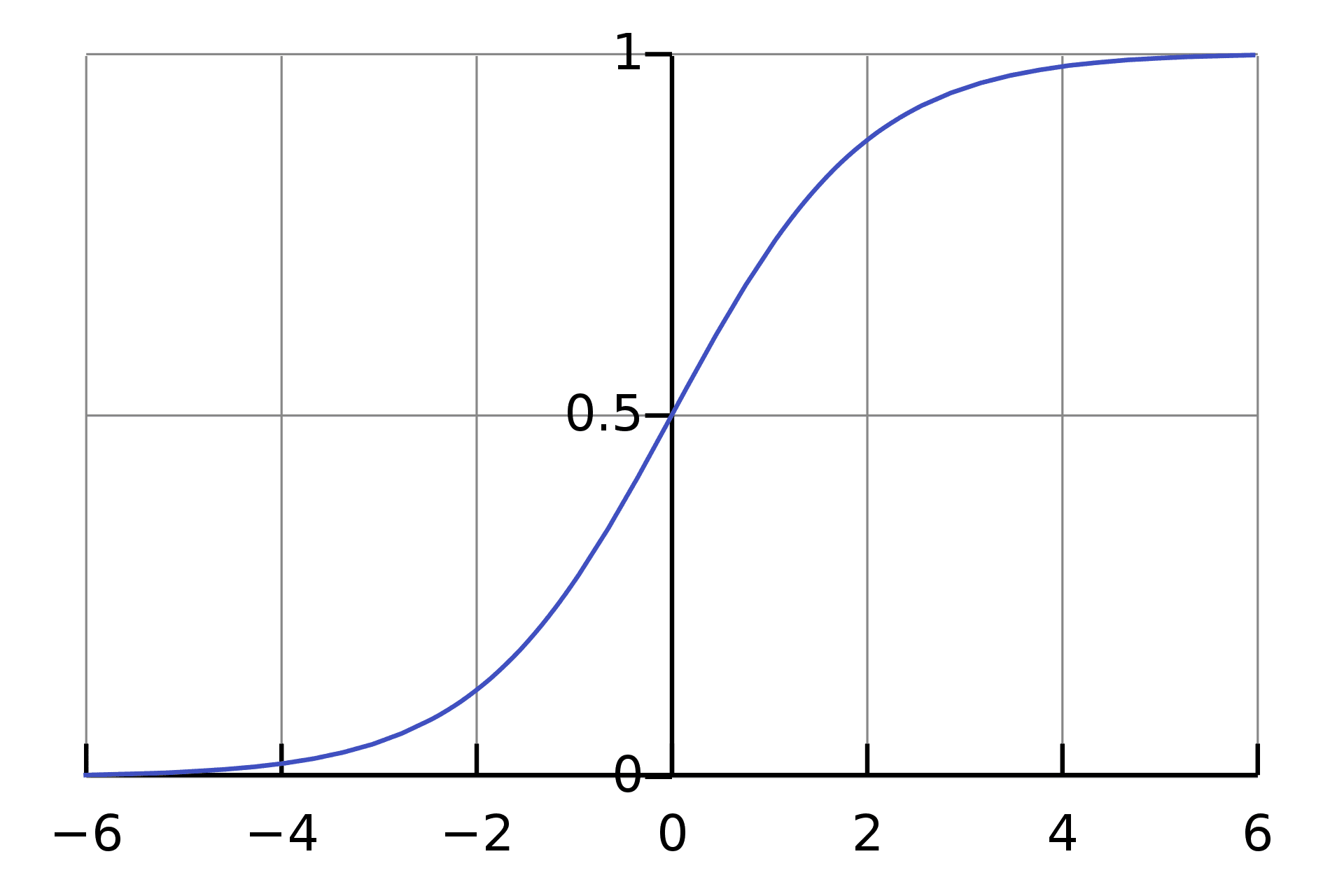
De logistische functie is ook bekend als de Sigmoid-functie die elk getal met een reële waarde neemt en dit toewijst aan een waarde tussen 0 en 1. Het kan wiskundig worden weergegeven als:
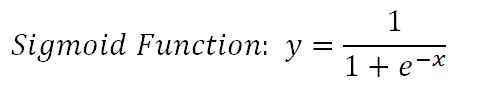
def sigmoid(z): return 1.0 / (1 + np.exp(-z))
Classificatie gaat over het voorspellen van een label en vervolgens identificeren tot welke categorie een object behoort op basis van verschillende parameters.
Om te meten hoe goed ons classificatiemodel het doet bij het maken van deze voorspellingen, gebruiken we classificatiestatistieken. Het meet de prestaties van ons machine learning-model, wat ons het vertrouwen geeft dat deze resultaten verder kunnen worden gebruikt in besluitvormingsprocessen.
De prestatie wordt normaal gesproken gepresenteerd in een bereik van 0 tot 1, waarbij een score van 1 perfectie vertegenwoordigt.
Als we een bereik van 0 tot 1 gebruiken om de prestaties van ons model weer te geven, wat gebeurt er dan als de waarde 0.5 is? Zoals we uit vroege wiskundelessen weten, als de kans groter is dan 0.5, ronden we deze af naar 1 (positief) - zo niet, dan is het 0 (negatief).
Dat klinkt goed, maar nu je classificatiemodellen gebruikt om de output van praktijkgevallen te helpen bepalen. We moeten er 100% zeker van zijn dat de output correct is geclassificeerd.
Logistieke regressie wordt bijvoorbeeld gebruikt om spam-e-mails te detecteren. Als de kans dat de e-mail spam is gebaseerd is op het feit dat deze hoger is dan 0.5, kan dit riskant zijn omdat we een belangrijke e-mail mogelijk in de spammap kunnen belanden. De wens en noodzaak dat de prestaties van het model zeer nauwkeurig zijn, wordt gevoeliger voor gezondheidsgerelateerde en financiële taken.
Daarom kan het gebruik van het drempelconcept van waarden boven de drempelwaarde 1 zijn en een waarde onder de drempelwaarde 0 zijn, kan problemen veroorzaken.
Hoewel er de mogelijkheid is om de drempelwaarde aan te passen, bestaat toch het risico dat we verkeerd classificeren. Als u bijvoorbeeld een lage drempel heeft, worden de meeste positieve klassen correct geclassificeerd, maar binnen de positieve zullen negatieve klassen worden opgenomen - vice versa als we een hoge drempel hadden.
Laten we dus eens kijken hoe deze classificatiestatistieken ons kunnen helpen bij het meten van de prestaties van ons logistische regressiemodel
Nauwkeurigheid
We beginnen met nauwkeurigheid omdat dit degene is die meestal het meest wordt gebruikt, vooral voor beginners.
Nauwkeurigheid wordt gedefinieerd als het aantal juiste voorspellingen over de totale voorspellingen:
nauwkeurigheid = correcte_voorspellingen / totale_voorspellingen
We kunnen dit echter verder uitbreiden met behulp van deze:
- True Positive (TP) – u voorspelde positief en het is eigenlijk positief
- True Negative (TN) - u voorspelde negatief en het is eigenlijk negatief
- False Positive (FP) – u voorspelde positief en het is eigenlijk negatief
- False Negative (FN) - u voorspelde negatief en het is eigenlijk positief
We kunnen dus zeggen dat de echte voorspellingen TN+TP zijn, terwijl de valse voorspelling FP+FN is. De vergelijking kan nu worden geherdefinieerd als:
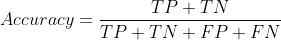
Om de nauwkeurigheid van uw model te vinden, doet u het volgende:
score = LogisticRegression.score(X_test, y_test) print('Test Accuracy Score', score)
Of je kunt ook gebruiken bibliotheek leren:
van sklearn.metrics import nauwkeurigheid_score nauwkeurigheid_score (y_train, y_pred)
Het is echter meestal niet voldoende om de nauwkeurigheidsmetriek te gebruiken om de prestaties van uw model te meten. Dit is waar we andere statistieken nodig hebben.
Precisie en terugroepen
Als we de "nauwkeurigheid" verder willen testen in verschillende klassen, waarbij we er zeker van willen zijn dat wanneer het model positief voorspelt, het ook echt positief is - we gebruiken precisie. We kunnen dit ook positieve voorspellingswaarde noemen, die kan worden gedefinieerd als:
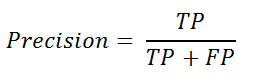
van sklearn.metrics precisiescore importeren
Als we de "nauwkeurigheid" in verschillende klassen verder willen testen, waarbij we er zeker van willen zijn dat wanneer het model negatief voorspelt, het daadwerkelijk negatief is - we gebruiken recall. Recall is dezelfde formule als gevoeligheid en kan worden gedefinieerd als:
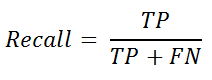
van sklearn.metrics import recall_score
Het gebruik van zowel precisie als recall zijn nuttige meetwaarden wanneer er een onbalans is in de waarnemingen tussen de twee klassen. Er zijn bijvoorbeeld meer van één klasse (1) en slechts enkele van de andere klasse (0) in de dataset.
Om de precisie van uw model te vergroten, hoeft u minder FP te hebben en hoeft u zich geen zorgen te maken over de FN. Terwijl je, als je meer terugroepacties wilt, minder FN nodig hebt en je geen zorgen hoeft te maken over de FP.
Het verhogen van de classificatiedrempel vermindert valse positieven en verhoogt de nauwkeurigheid. Het verhogen van de classificatiedrempel vermindert de echte positieven of houdt ze gelijk, terwijl de fout-negatieven worden verhoogd of gelijk gehouden. – terugroepen verminderen of constant houden.
Helaas is het niet mogelijk om een hoge precisie en terugroepwaarde te hebben. Als u de precisie verhoogt, zal het terugroepen verminderen - vice versa. Dit staat bekend als de precisie/recall-afweging.
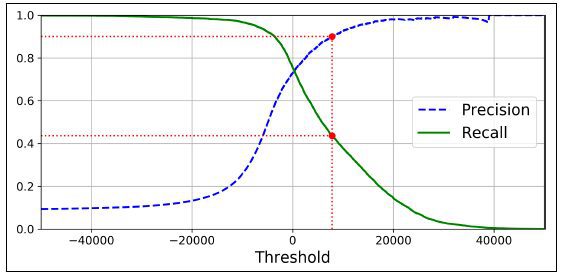
ROC-curve
Als het op precisie aankomt, geven we om het verlagen van de FP en voor terugroepen geven we om het verlagen van de FN. Er is echter een metriek die we kunnen gebruiken om zowel de FP als de FN te verlagen - dit wordt de Receiver Operating Characteristic-curve of ROC-curve genoemd.
Het zet het percentage fout-positieven (x-as) uit tegen het echt positieve percentage (y-as).
- Echt positief percentage = TP / (TP + FN)
- Vals-positief percentage = FP / (FP + TN)
Het percentage echte positieve is ook bekend als gevoeligheid en het percentage fout-positieve is ook bekend als het percentage omgekeerde specificiteit.
- Specificiteit = TN / (TN + FP)
Als de waarden op de x-as uit kleinere waarden bestaan, duidt dit op een lagere FP en een hogere TN. Als de waarden op de y-as uit grotere waarden bestaan, duidt dit op een hogere TP en een lagere FN.
Het ROC presenteert de prestaties van een classificatiemodel bij alle classificatiedrempels, als volgt:

Voorbeeld:

AUC
Als het gaat om de ROC-curve, heb je misschien ook wel eens Area Under the Curve (AUC) gehoord. Het is precies wat het zegt dat het is: het gebied onder de curve. Als u wilt weten hoe goed uw curve is, berekent u de ROC AUC-score. ??AUC meet de prestaties over alle mogelijke classificatiedrempels.
Hoe meer oppervlakte onder de curve, hoe beter - hoe hoger de ROC AUC-score. Dit is wanneer de FN en FP beide op nul staan - of als we verwijzen naar de bovenstaande grafiek, is het wanneer de werkelijke positieve snelheid 1 is en de fout-positieve snelheid 0 is.
van sklearn.metrics import roc_auc_score
De onderstaande afbeelding toont een oplopende volgorde van logistische regressievoorspellingen. Als de AUC-waarde 0.0 is, kunnen we zeggen dat de voorspellingen helemaal verkeerd zijn. Als de AUC-waarde 1.0 is, kunnen we zeggen dat de voorspellingen volledig correct zijn.

Om samen te vatten, we hebben gekeken naar wat logistieke regressie is, wat classificatiestatistieken zijn en problemen met de drempel met oplossingen, zoals nauwkeurigheid, precisie, terugroepactie en de ROC-curve.
Er zijn zoveel meer classificatiestatistieken, zoals verwarringsmatrix, F1-score, F2-score en meer. Deze zijn allemaal beschikbaar om u een beter inzicht te geven in de prestaties van uw model.
Nisha Arja is een datawetenschapper en freelance technisch schrijver. Ze is vooral geïnteresseerd in het geven van loopbaanadvies op het gebied van Data Science of tutorials en op theorie gebaseerde kennis rond Data Science. Ze wil ook de verschillende manieren onderzoeken waarop kunstmatige intelligentie de levensduur van de mens ten goede komt. Een scherpe leerling, die haar technische kennis en schrijfvaardigheid wil verbreden, terwijl ze anderen helpt te begeleiden.

