Een aantal experimenten suggereert dat ChatGPT, het populaire Large Language Model (LLM), nuttig zou kunnen zijn om verdedigers te helpen bij het beoordelen van potentiële beveiligingsincidenten en het vinden van beveiligingsproblemen in code, ook al is het kunstmatige-intelligentiemodel (AI) niet specifiek getraind voor dergelijke activiteiten. , volgens resultaten die deze week zijn vrijgegeven.
In een analyse op 15 februari van ChatGPT's hulpprogramma als tool voor incidentrespons, ontdekte Victor Sergeev, teamleider incidentrespons bij Kaspersky, dat ChatGPT kwaadaardige processen op gecompromitteerde systemen kon identificeren. Sergeev infecteerde een systeem met de Meterpreter- en PowerShell Empire-agenten, nam gemeenschappelijke stappen in de rol van tegenstander en voerde vervolgens een door ChatGPT aangedreven scanner uit tegen het systeem.
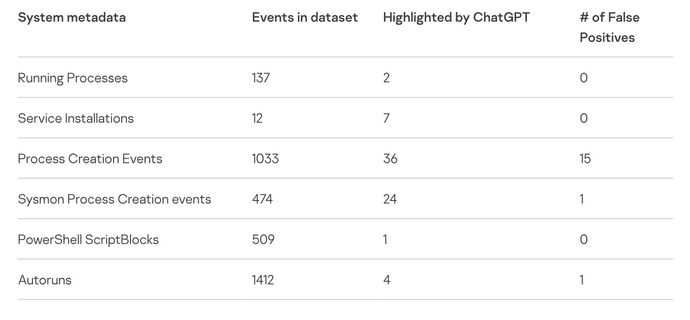
De LLM identificeerde twee kwaadaardige processen die op het systeem draaien en negeerde correct 137 goedaardige processen, waardoor de overhead mogelijk aanzienlijk werd verminderd, schreef hij in een blogpost waarin hij het experiment beschrijft.
"ChatGPT heeft met succes verdachte service-installaties geïdentificeerd, zonder valse positieven," Sergejev schreef. "Voor de tweede service leverde het een conclusie op waarom de service moest worden geclassificeerd als een indicator van een compromis."
Beveiligingsonderzoekers en AI-hackers hebben allemaal interesse getoond in ChatGPT en de LLM onderzocht op zwakke punten, terwijl andere onderzoekers, evenals cybercriminelen, hebben geprobeerd de LLM naar de duistere kant lokken, instellen op betere phishing-e-mailberichten produceren or malware genereren.
Toch kijken beveiligingsonderzoekers ook naar hoe het gegeneraliseerde taalmodel presteert op specifieke defensiegerelateerde taken. In december gebruikte digitaal forensisch bedrijf Cado Security ChatGPT om maak een tijdlijn van een compromis met behulp van JSON-gegevens van een incident, wat een goed - maar niet helemaal nauwkeurig - rapport opleverde. Beveiligingsadviesbureau NCC Group experimenteerde met ChatGPT as een manier om kwetsbaarheden in code te vinden, wat het deed, maar niet altijd nauwkeurig.
De conclusie is dat beveiligingsanalisten, ontwikkelaars en reverse engineers voorzichtig moeten zijn wanneer ze LLM's gebruiken, vooral voor taken die buiten hun mogelijkheden liggen, zegt Chris Anley, hoofdwetenschapper bij beveiligingsadviesbureau NCC Group.
"Ik denk absoluut dat professionele ontwikkelaars en andere mensen die met code werken, ChatGPT en vergelijkbare modellen zouden moeten verkennen, maar meer ter inspiratie dan voor absoluut correcte, feitelijke resultaten", zegt hij, eraan toevoegend dat "beveiligingscodebeoordeling niet iets is dat we zouden moeten doen." waarvoor je ChatGPT gebruikt, dus het is een beetje oneerlijk om te verwachten dat het de eerste keer perfect is.”
IoC's analyseren met AI
Het Kaspersky-experiment begon met het vragen van ChatGPT over verschillende tools van hackers, zoals Mimikatz en Fast Reverse Proxy. Het AI-model heeft die tools met succes beschreven, maar toen werd gevraagd om bekende hashes en domeinen te identificeren, mislukte het. De LLM kon bijvoorbeeld een bekende hash van de WannaCry-malware niet identificeren.
Het relatieve succes van het identificeren van kwaadaardige code op de host bracht Kasperky's Sergeev er echter toe om ChatGPT te vragen een PowerShell-script te maken om metadata en indicatoren van een systeem te verzamelen en deze in te dienen bij de LLM. Nadat hij de code handmatig had verbeterd, gebruikte Sergeev het script op het geïnfecteerde testsysteem.
In totaal gebruikte de Kaspersky-analist ChatGPT om de metadata van meer dan 3,500 gebeurtenissen op het testsysteem te analyseren, waarbij hij 74 potentiële indicatoren van een compromis vond, waarvan 17 fout-positieven. Het experiment suggereert dat ChatGPT nuttig zou kunnen zijn voor het verzamelen van forensische informatie voor bedrijven die geen endpoint-detectie- en responssysteem (EDR) gebruiken, code-obfuscatie detecteren of code-binaries reverse-engineeren.
Sergeev waarschuwde ook dat onnauwkeurigheden een zeer reëel probleem zijn. "Pas op voor valse positieven en valse negatieven die dit kan opleveren", schreef hij. "Uiteindelijk is dit gewoon weer een statistisch neuraal netwerk dat vatbaar is voor onverwachte resultaten."
In zijn analyse waarschuwde Cado Security dat ChatGPT doorgaans niet het vertrouwen van zijn resultaten kwalificeert. "Dit is een algemeen probleem met ChatGPT dat OpenAI zelf [heeft] opgeworpen - het kan hallucineren, en als het hallucineert, doet het dat met vertrouwen", aldus Cado's analyse.
Eerlijk gebruik en privacyregels moeten worden verduidelijkt
De experimenten werpen ook enkele kritieke problemen op met betrekking tot de gegevens die worden ingediend bij het ChatGPT-systeem van OpenAI. Bedrijven maken al bezwaar tegen het maken van datasets met behulp van informatie op internet, met bedrijven zoals Duidelijke AI en Stabiliteit AI geconfronteerd met rechtszaken om hun gebruik van hun machine learning-modellen te beperken.
Privacy is een ander probleem. Beveiligingsprofessionals moeten bepalen of ingediende indicatoren van compromittering gevoelige gegevens blootleggen, of dat het indienen van softwarecode voor analyse het intellectuele eigendom van een bedrijf schendt, zegt Anley van NCC Group.
"Of het een goed idee is om code in te dienen bij ChatGPT hangt sterk af van de omstandigheden", zegt hij. "Veel code is bedrijfseigen en valt onder verschillende wettelijke beschermingen, dus ik zou mensen niet aanraden om code aan derden te verstrekken, tenzij ze daarvoor toestemming hebben."
Sergeev gaf een gelijkaardige waarschuwing: het gebruik van ChatGPT om compromissen te detecteren, stuurt noodzakelijkerwijs gevoelige gegevens naar het systeem, wat een schending van het bedrijfsbeleid kan zijn en een bedrijfsrisico kan vormen.
"Door deze scripts te gebruiken, stuur je gegevens, inclusief gevoelige gegevens, naar OpenAI", zei hij, "dus wees voorzichtig en raadpleeg vooraf de systeemeigenaar."
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.darkreading.com/analytics/chatgpt-subs-security-analyst-hallucinates-occasionally

