U kunt gegevens van meerdere Internet of Things (IoT)-sensoren opnemen en integreren om inzichten te verkrijgen. Het kan echter zijn dat u gegevens van meerdere IoT-sensorapparaten moet integreren om analyses, zoals informatie over de gezondheid van apparatuur, van alle sensoren af te leiden op basis van gemeenschappelijke gegevenselementen. Elk van deze sensorapparaten kan gegevens verzenden met unieke schema's en verschillende attributen.
U kunt gegevens van al uw IoT-sensoren naar een centrale locatie overbrengen Amazon eenvoudige opslagservice (Amazone S3). Schema evolutie is een functie waarmee het schema van een databasetabel kan evolueren om rekening te houden met veranderingen in de kenmerken van de bestanden die worden opgenomen. Met de functionaliteit voor schema-evolutie beschikbaar in AWS lijm, Amazon Roodverschuivingsspectrum kan automatisch schemawijzigingen verwerken wanneer nieuwe attributen worden toegevoegd of bestaande attributen worden verwijderd. Dit wordt bereikt met een AWS Glue-crawler door schemawijzigingen te lezen op basis van de S3-bestandsstructuren. De crawler creëert een hybride schema dat werkt met zowel oude als nieuwe datasets. U kunt via één bestand alle opgenomen gegevensbestanden op een opgegeven Amazon S3-locatie met verschillende schema's lezen Amazon Roodverschuivingsspectrum tabel door te verwijzen naar de AWS Glue-metagegevenscatalogus.
In dit bericht laten we zien hoe u de AWS Glue-schema-evolutiefunctie kunt gebruiken om te lezen uit meerdere JSON-geformatteerde bestanden met verschillende schema's die zijn opgeslagen op een enkele Amazon S3-locatie. We laten ook zien hoe u deze gegevens kunt opvragen in Amazon S3 met Redshift Spectrum zonder het schema opnieuw te definiëren of de gegevens in Redshift-tabellen te laden.
Overzicht oplossingen
De oplossing bestaat uit de volgende stappen:
- Maak een Amazon Data-brandslang bezorgstroom met Amazon S3 als bestemming.
- Genereer voorbeeldstreamgegevens van de Amazon Kinesis-gegevensgenerator (KDG) met de Firehose-leveringsstroom als bestemming.
- Upload de initiële gegevensbestanden naar de Amazon S3-locatie.
- Creëer en voer een AWS Glue-crawler uit om de gegevenscatalogus te vullen met externe tabeldefinitie door de gegevensbestanden van Amazon S3 te lezen.
- Maak het aangeroepen externe schema
iotdb_extin Amazon Redshift en query's uitvoeren op de Data Catalog-tabel. - Voer een query uit op de externe tabel van Redshift Spectrum om gegevens uit het oorspronkelijke schema te lezen.
- Voeg extra gegevenselementen toe aan de KDG-sjabloon en stuur de gegevens naar de Firehose-leveringsstroom.
- Valideer dat de extra gegevensbestanden met extra gegevenselementen in Amazon S3 worden geladen.
- Voer een AWS Glue-crawler uit om de externe tabeldefinities bij te werken.
- Voer opnieuw een query uit op de externe tabel van Redshift Spectrum om de gecombineerde dataset uit twee verschillende schema's te lezen.
- Verwijder een gegevenselement uit de sjabloon en stuur de gegevens naar de Firehose-leveringsstroom.
- Valideer dat de extra gegevensbestanden in Amazon S3 worden geladen met één gegevenselement minder.
- Voer een AWS Glue-crawler uit om de externe tabeldefinities bij te werken.
- Voer een query uit op de externe tabel van Redshift Spectrum om de gecombineerde dataset uit drie verschillende schema's te lezen.
Deze oplossing wordt weergegeven in het volgende architectuurdiagram.

Voorwaarden
Deze oplossing vereist de volgende vereisten:
Implementeer de oplossing
Voer de volgende stappen uit om de oplossing te bouwen:
- Maak op de Kinesis-console een Firehose-leveringsstream met de volgende parameters:
- Voor bron, kiezen Directe PUT.
- Voor Bestemming, kiezen Amazon S3.
- Voor S3 emmer, voer uw S3-bucket in.
- Voor Dynamische partitieselecteer ingeschakeld.

-
- Voeg de volgende dynamische partitiesleutels toe:
- Sleuteljaar met expressie
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%Y") - Sleutelmaand met expressie
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%m") - Sleuteldag met expressie
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%d") - Sleuteluur met expressie
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%H")
- Sleuteljaar met expressie
- Voeg de volgende dynamische partitiesleutels toe:
-
- Voor S3-bucketvoorvoegsel, ga naar binnen
year=!{partitionKeyFromQuery:year}/month=!{partitionKeyFromQuery:month}/day=!{partitionKeyFromQuery:day}/hour=!{partitionKeyFromQuery:hour}/
- Voor S3-bucketvoorvoegsel, ga naar binnen

U kunt de details van uw bezorgstroom bekijken op de Kinesis Data Firehose-console.
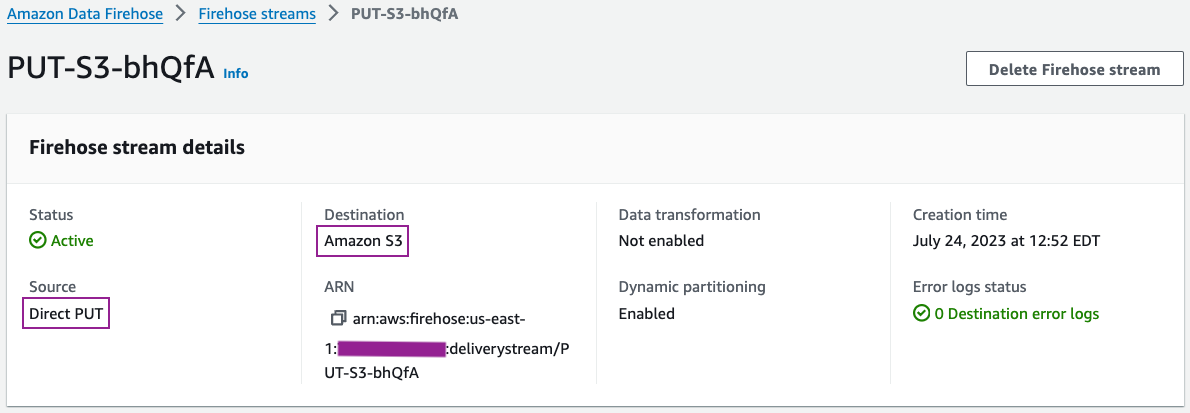
De configuratiegegevens van uw leveringsstroom moeten vergelijkbaar zijn met de volgende schermafbeelding.

- Genereer voorbeeldstroomgegevens van de KDG met de Firehose-leveringsstroom als bestemming met de volgende sjabloon:

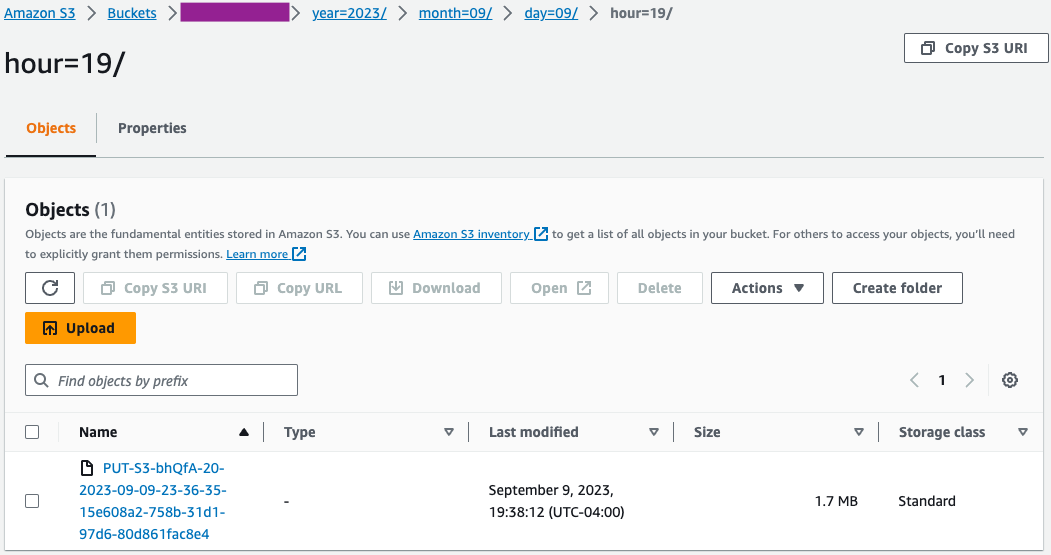
- Valideer op de Amazon S3-console of de eerste set bestanden in de S3-bucket is geladen.
- Op de AWS Glue-console, maak en voer een AWS Glue Crawler uit met de gegevensbron als de S3-bucket die u in de eerdere stap hebt gebruikt.
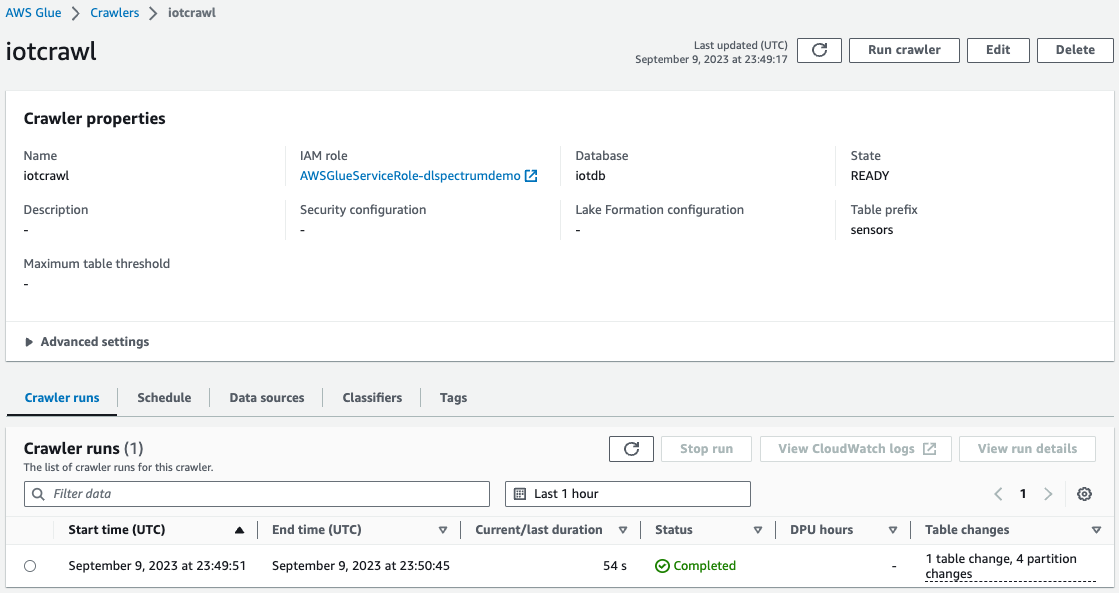
Wanneer de crawler voltooid is, kunt u valideren dat de tabel is gemaakt op de AWS Glue-console.

Probleem oplossen
Als de gegevens niet in Amazon S3 worden geladen nadat deze van de KDG-sjabloon naar de Firehose-bezorgstroom zijn verzonden, vernieuw dan en zorg ervoor dat u bent ingelogd bij de KDG.
Opruimen
Mogelijk wilt u uw S3-gegevens en Redshift-cluster verwijderen als u niet van plan bent deze verder te gebruiken om onnodige kosten voor uw AWS-account te voorkomen.
Conclusie
Met de opkomst van eisen voor voorspellende en prescriptieve analyses op basis van big data, is er een groeiende vraag naar dataoplossingen die gegevens uit meerdere heterogene datamodellen met minimale inspanning integreren. In dit bericht hebben we laten zien hoe u metrieken kunt afleiden uit algemene atomaire gegevenselementen uit verschillende gegevensbronnen met unieke schema's. U kunt gegevens uit alle gegevensbronnen opslaan op een gemeenschappelijke S3-locatie, in dezelfde map of in meerdere submappen per gegevensbron. U kunt een AWS Glue-crawler definiëren en plannen zodat deze met dezelfde frequentie wordt uitgevoerd als de gegevensvernieuwingsvereisten voor uw gegevensverbruik. Met deze oplossing kunt u een Redshift Spectrum-tabel maken om te lezen vanaf een S3-locatie met verschillende bestandsstructuren met behulp van de AWS Glue Data Catalog en schema-evolutiefunctionaliteit.
Als u vragen of suggesties heeft, kunt u uw feedback achterlaten in het opmerkingengedeelte. Als u meer hulp nodig heeft bij het bouwen van analyseoplossingen met gegevens van verschillende IoT-sensoren, neem dan contact op met uw AWS-accountteam.
Over de auteurs
 Swapna Bandla is een Senior Solutions Architect in het AWS Analytics Specialist SA-team. Swapna heeft een passie voor het begrijpen van de data- en analysebehoeften van klanten en het in staat stellen van cloudgebaseerde, goed ontworpen oplossingen. Buiten haar werk brengt ze graag tijd door met haar gezin.
Swapna Bandla is een Senior Solutions Architect in het AWS Analytics Specialist SA-team. Swapna heeft een passie voor het begrijpen van de data- en analysebehoeften van klanten en het in staat stellen van cloudgebaseerde, goed ontworpen oplossingen. Buiten haar werk brengt ze graag tijd door met haar gezin.
 Indira Balakrishnan is een Principal Solutions Architect in het AWS Analytics Specialist SA-team. Ze heeft een passie voor het helpen van klanten bij het bouwen van cloudgebaseerde analyseoplossingen om hun zakelijke problemen op te lossen met behulp van gegevensgestuurde beslissingen. Naast haar werk doet ze vrijwilligerswerk bij de activiteiten van haar kinderen en brengt ze tijd door met haar gezin.
Indira Balakrishnan is een Principal Solutions Architect in het AWS Analytics Specialist SA-team. Ze heeft een passie voor het helpen van klanten bij het bouwen van cloudgebaseerde analyseoplossingen om hun zakelijke problemen op te lossen met behulp van gegevensgestuurde beslissingen. Naast haar werk doet ze vrijwilligerswerk bij de activiteiten van haar kinderen en brengt ze tijd door met haar gezin.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/build-an-analytics-pipeline-that-is-resilient-to-schema-changes-using-amazon-redshift-spectrum/

