Introductie
Er is een enorme toename in het aantal toepassingen waarbij gebruik wordt gemaakt van AI-codeermiddelen. Met de toenemende kwaliteit van LLM's en de afnemende kosten van gevolgtrekkingen wordt het alleen maar eenvoudiger om capabele AI-agenten te bouwen. Bovendien evolueert het tooling-ecosysteem snel, waardoor het eenvoudiger wordt om complexe AI-codeeragenten te bouwen. Het Langchain-framework is op dit front toonaangevend geweest. Het beschikt over alle benodigde tools en technieken om productieklare AI-applicaties te creëren.
Maar tot nu toe ontbrak het aan één ding. En dat is een multi-agent samenwerking met cycliciteit. Dit is cruciaal voor het oplossen van complexe problemen, waarbij het probleem kan worden verdeeld en gedelegeerd aan gespecialiseerde agenten. Dit is waar LangGraph in beeld komt, een onderdeel van het Langchain-framework dat is ontworpen om stateful samenwerking tussen meerdere actoren tussen AI-codeeragenten mogelijk te maken. Verder zullen we in dit artikel LangGraph en zijn basisbouwstenen bespreken terwijl we er een agent mee bouwen.
leerdoelen
- Begrijp wat LangGraph is.
- Ontdek de basisprincipes van LangGraph voor het bouwen van stateful agenten.
- Verken TogetherAI om toegang te krijgen tot open-access-modellen zoals DeepSeekCoder.
- Bouw een AI-codeeragent met LangGraph om unit-tests te schrijven.

Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Wat is LangGraph?
LangGraph is een uitbreiding van het LangChain-ecosysteem. Hoewel LangChain het mogelijk maakt om AI-codeeragenten te bouwen die meerdere tools kunnen gebruiken om taken uit te voeren, kan het niet meerdere ketens of actoren over de stappen heen coördineren. Dit is cruciaal gedrag voor het creëren van agenten die complexe taken uitvoeren. LangGraph is ontworpen met deze dingen in gedachten. Het behandelt de Agent-workflows als een cyclische grafiekstructuur, waarbij elk knooppunt een functie of een Langchain Runnable-object vertegenwoordigt, en randen verbindingen tussen knooppunten zijn.
De belangrijkste kenmerken van LangGraph zijn onder meer
- Nodes: Elke functie of Langchain Runnable-object zoals een hulpmiddel.
- randen: definieert de richting tussen knooppunten.
- Statelijke grafieken: het primaire type grafiek. Het is ontworpen om statusobjecten te beheren en bij te werken terwijl het gegevens via zijn knooppunten verwerkt.
LangGraph maakt hiervan gebruik om een cyclische LLM-oproepuitvoering met statuspersistentie mogelijk te maken, wat cruciaal is voor agentisch gedrag. De architectuur ontleent er inspiratie aan Voorregel en Apache-straal.
In dit artikel zullen we een agent bouwen voor het schrijven van Pytest-eenheidstests voor een Python-klasse met methoden. En dit is de werkstroom.
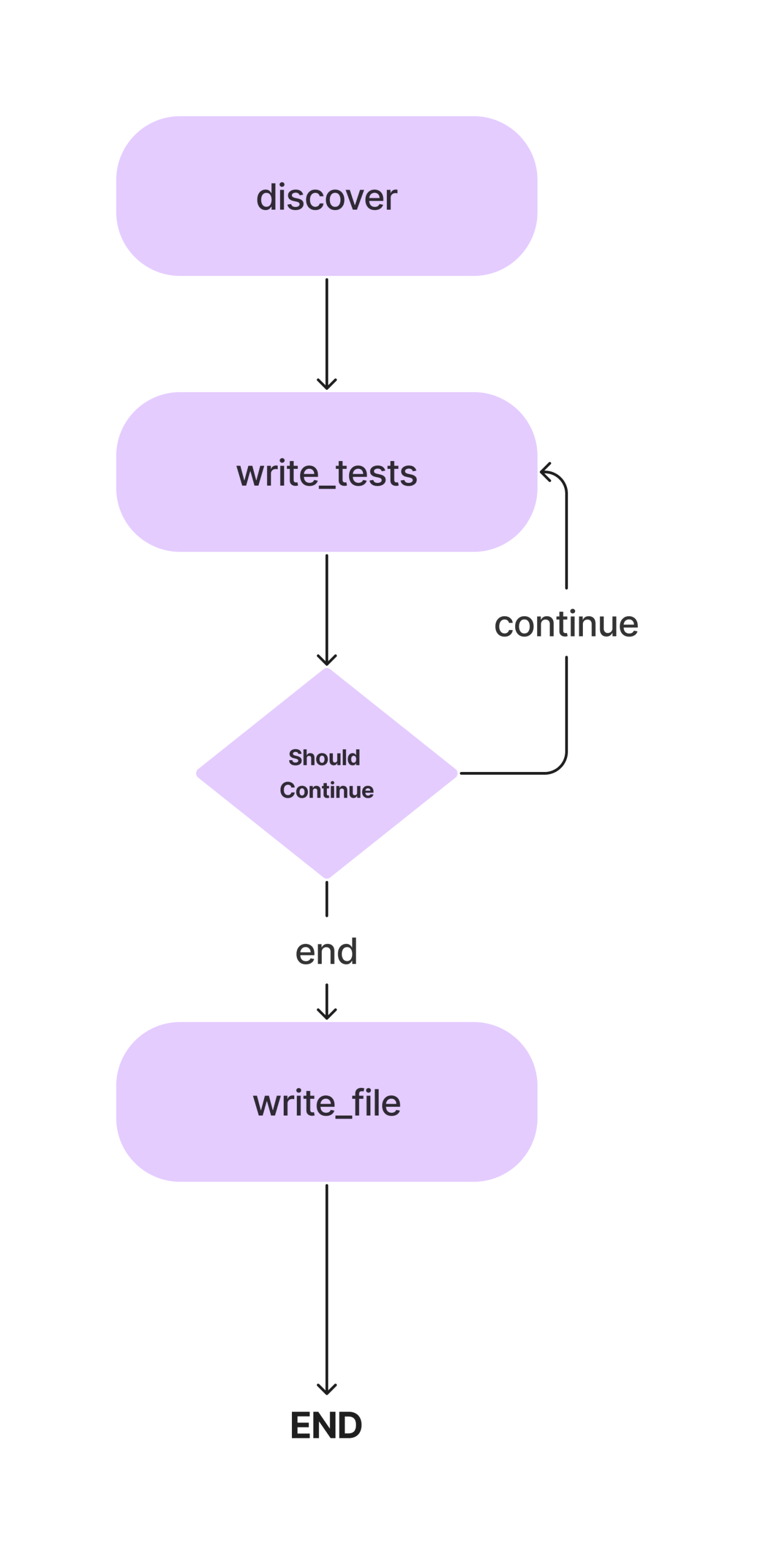
We zullen de concepten in detail bespreken terwijl we onze AI-coderingsagent bouwen voor het schrijven van eenvoudige unit-tests. Laten we dus naar het codeergedeelte gaan.
Maar laten we eerst onze ontwikkelomgeving opzetten.
Afhankelijkheden installeren
Het eerste wat eerst. Creëer, zoals bij elk Python-project, een virtuele omgeving en activeer deze.
python -m venv auto-unit-tests-writer
cd auto-unit-tests-writer
source bin/activateInstalleer nu de afhankelijkheden.
!pip install langgraph langchain langchain_openai coloramaImporteer alle bibliotheken en hun klassen.
from typing import TypedDict, List
import colorama
import os
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage
from langchain_core.messages import HumanMessage
from langchain_core.runnables import RunnableConfig
from langgraph.graph import StateGraph, END
from langgraph.pregel import GraphRecursionErrorWe willen ook de mappen en bestanden voor testgevallen maken. Je kunt handmatig bestanden aanmaken of daarvoor Python gebruiken.
# Define the paths.
search_path = os.path.join(os.getcwd(), "app")
code_file = os.path.join(search_path, "src/crud.py")
test_file = os.path.join(search_path, "test/test_crud.py")
# Create the folders and files if necessary.
if not os.path.exists(search_path):
os.mkdir(search_path)
os.mkdir(os.path.join(search_path, "src"))
os.mkdir(os.path.join(search_path, "test"))Werk nu het crud.py-bestand bij met code voor een CRUD-app in het geheugen. We zullen dit stukje code gebruiken om unit-tests te schrijven. U kunt hiervoor uw Python-programma gebruiken. We zullen het onderstaande programma toevoegen aan ons code.py-bestand.
#crud.py
code = """class Item:
def __init__(self, id, name, description=None):
self.id = id
self.name = name
self.description = description
def __repr__(self):
return f"Item(id={self.id}, name={self.name}, description={self.description})"
class CRUDApp:
def __init__(self):
self.items = []
def create_item(self, id, name, description=None):
item = Item(id, name, description)
self.items.append(item)
return item
def read_item(self, id):
for item in self.items:
if item.id == id:
return item
return None
def update_item(self, id, name=None, description=None):
for item in self.items:
if item.id == id:
if name:
item.name = name
if description:
item.description = description
return item
return None
def delete_item(self, id):
for index, item in enumerate(self.items):
if item.id == id:
return self.items.pop(index)
return None
def list_items(self):
return self.items"""
with open(code_file, 'w') as f:
f.write(code)LLM instellen
Nu zullen we de LLM specificeren die we in dit project zullen gebruiken. Welk model hier moet worden gebruikt, hangt af van de taken en de beschikbaarheid van middelen. U kunt eigen, krachtige modellen gebruiken, zoals GPT-4, Gemini Ultra of GPT-3.5. U kunt ook open-access-modellen gebruiken, zoals Mixtral en Llama-2. In dit geval kunnen we, omdat het gaat om het schrijven van codes, een verfijnd codeermodel gebruiken, zoals DeepSeekCoder-33B of Llama-2 coder. Nu zijn er meerdere platforms voor LLM-deferentie, zoals Anayscale, Abacus en Together. We zullen Together AI gebruiken om DeepSeekCoder af te leiden. Dus, neem een API sleutel van Samen voordat we verder gaan.
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(base_url="https://api.together.xyz/v1",
api_key="your-key",
model="deepseek-ai/deepseek-coder-33b-instruct")Omdat de Together API compatibel is met de OpenAI SDK, kunnen we de OpenAI SDK van Langchain gebruiken om te communiceren met modellen die op Together worden gehost door de parameter base_url te wijzigen in “https://api.together.xyz/v1”. Geef in api_key uw Together API-sleutel door, en in plaats van modellen, geef de naam van het model beschikbaar op Samen.
Definieer de agentstatus
Dit is een van de cruciale onderdelen van LangGraph. Hier definiëren we een AgentState, die verantwoordelijk is voor het bijhouden van de status van agenten tijdens de uitvoering. Dit is voornamelijk een TypedDict-klasse met entiteiten die de status van de agenten onderhouden. Laten we onze AgentState definiëren
class AgentState(TypedDict):
class_source: str
class_methods: List[str]
tests_source: strIn de bovenstaande AgentState-klasse slaat de class_source de originele Python-klasse op, class_methods voor het opslaan van methoden van de klasse, en tests_source voor eenheidstestcodes. We hebben deze gedefinieerd als AgentState om ze in alle uitvoeringsstappen te gebruiken.
Definieer nu de grafiek met de AgentState.
# Create the graph.
workflow = StateGraph(AgentState)Zoals eerder vermeld is dit een stateful grafiek, en nu hebben we ons state-object toegevoegd.
Definieer knooppunten
Nu we de AgentState hebben gedefinieerd, moeten we knooppunten toevoegen. Wat zijn knooppunten precies? In LangGraph zijn knooppunten functies of elk uitvoerbaar object, zoals Langchain-tools, die een enkele actie uitvoeren. In ons geval kunnen we verschillende knooppunten definiëren, zoals een functie voor het vinden van klassenmethoden, een functie voor het afleiden en bijwerken van unit-tests naar statusobjecten, en een functie voor het schrijven ervan naar een testbestand.
We hebben ook een manier nodig om codes uit een LLM-bericht te extraheren. Hier is hoe.
def extract_code_from_message(message):
lines = message.split("n")
code = ""
in_code = False
for line in lines:
if "```" in line:
in_code = not in_code
elif in_code:
code += line + "n"
return codeHet codefragment hier gaat ervan uit dat de codes tussen de drievoudige aanhalingstekens staan.
Laten we nu onze knooppunten definiëren.
import_prompt_template = """Here is a path of a file with code: {code_file}.
Here is the path of a file with tests: {test_file}.
Write a proper import statement for the class in the file.
"""
# Discover the class and its methods.
def discover_function(state: AgentState):
assert os.path.exists(code_file)
with open(code_file, "r") as f:
source = f.read()
state["class_source"] = source
# Get the methods.
methods = []
for line in source.split("n"):
if "def " in line:
methods.append(line.split("def ")[1].split("(")[0])
state["class_methods"] = methods
# Generate the import statement and start the code.
import_prompt = import_prompt_template.format(
code_file=code_file,
test_file=test_file
)
message = llm.invoke([HumanMessage(content=import_prompt)]).content
code = extract_code_from_message(message)
state["tests_source"] = code + "nn"
return state
# Add a node to for discovery.
workflow.add_node(
"discover",
discover_function
)
In het bovenstaande codefragment hebben we een functie gedefinieerd voor het ontdekken van codes. Het haalt de codes uit de AgentState klasse_bron element, ontleedt de klasse in individuele methoden en geeft deze met aanwijzingen door aan de LLM. De uitvoer wordt opgeslagen in de AgentState's tests_bron element. We laten het alleen importinstructies schrijven voor de unit-testgevallen.
We hebben ook het eerste knooppunt aan het StateGraph-object toegevoegd.
Nu, op naar het volgende knooppunt.
We kunnen ook enkele promptsjablonen instellen die we hier nodig hebben. Dit zijn voorbeeldsjablonen die u naar eigen wens kunt wijzigen.
# System message template.
system_message_template = """You are a smart developer. You can do this! You will write unit
tests that have a high quality. Use pytest.
Reply with the source code for the test only.
Do not include the class in your response. I will add the imports myself.
If there is no test to write, reply with "# No test to write" and
nothing more. Do not include the class in your response.
Example:
```
def test_function():
...
```
I will give you 200 EUR if you adhere to the instructions and write a high quality test.
Do not write test classes, only methods.
"""
# Write the tests template.
write_test_template = """Here is a class:
'''
{class_source}
'''
Implement a test for the method "{class_method}".
"""Definieer nu het knooppunt.
# This method will write a test.
def write_tests_function(state: AgentState):
# Get the next method to write a test for.
class_method = state["class_methods"].pop(0)
print(f"Writing test for {class_method}.")
# Get the source code.
class_source = state["class_source"]
# Create the prompt.
write_test_prompt = write_test_template.format(
class_source=class_source,
class_method=class_method
)
print(colorama.Fore.CYAN + write_test_prompt + colorama.Style.RESET_ALL)
# Get the test source code.
system_message = SystemMessage(system_message_template)
human_message = HumanMessage(write_test_prompt)
test_source = llm.invoke([system_message, human_message]).content
test_source = extract_code_from_message(test_source)
print(colorama.Fore.GREEN + test_source + colorama.Style.RESET_ALL)
state["tests_source"] += test_source + "nn"
return state
# Add the node.
workflow.add_node(
"write_tests",
write_tests_function
)Hier laten we de LLM testgevallen voor elke methode schrijven, deze bijwerken naar het tests_source-element van AgentState en ze toevoegen aan het workflow-StateGraph-object.
randen
Nu we twee knooppunten hebben, zullen we randen ertussen definiëren om de uitvoeringsrichting daartussen te specificeren. De LangGraph biedt voornamelijk twee soorten randen.
- Voorwaardelijke voorsprong: De uitvoeringsstroom hangt af van de reactie van de agenten. Dit is cruciaal voor het toevoegen van cycliciteit aan de workflows. De agent kan op basis van bepaalde voorwaarden beslissen welke knooppunten vervolgens worden verplaatst. Of u nu wilt terugkeren naar een vorig knooppunt, het huidige knooppunt wilt herhalen of naar het volgende knooppunt wilt gaan.
- Normale rand: Dit is het normale geval, waarbij een knooppunt altijd wordt aangeroepen na het aanroepen van eerdere knooppunten.
We hebben geen voorwaarde nodig om Discover en Write_tests met elkaar te verbinden, dus we zullen een normale edge gebruiken. Definieer ook een toegangspunt dat specificeert waar de uitvoering moet beginnen.
# Define the entry point. This is where the flow will start.
workflow.set_entry_point("discover")
# Always go from discover to write_tests.
workflow.add_edge("discover", "write_tests")De uitvoering begint met het ontdekken van de methoden en gaat over naar de functie van het schrijven van tests. We hebben een ander knooppunt nodig om de unit-testcodes naar het testbestand te schrijven.
# Write the file.
def write_file(state: AgentState):
with open(test_file, "w") as f:
f.write(state["tests_source"])
return state
# Add a node to write the file.
workflow.add_node(
"write_file",
write_file)Omdat dit ons laatste knooppunt is, zullen we een rand definiëren tussen write_tests en write_file. Dit is hoe we dit kunnen doen.
# Find out if we are done.
def should_continue(state: AgentState):
if len(state["class_methods"]) == 0:
return "end"
else:
return "continue"
# Add the conditional edge.
workflow.add_conditional_edges(
"write_tests",
should_continue,
{
"continue": "write_tests",
"end": "write_file"
}
)De add_conditional_edge-functie gebruikt de write_tests-functie, een Should_continue-functie die beslist welke stap moet worden genomen op basis van class_methods-invoer, en een mapping met strings als sleutels en andere functies als waarden.
De edge begint bij write_tests en voert, op basis van de uitvoer van Should_Continue, een van de opties in de mapping uit. Als de status[“class_methods”] bijvoorbeeld niet leeg is, hebben we niet voor alle methoden tests geschreven; we herhalen de write_tests-functie, en wanneer we klaar zijn met het schrijven van de tests, wordt het write_file uitgevoerd.
Wanneer de tests voor alle methoden zijn afgeleid LLM, worden de tests naar het testbestand geschreven.
Voeg nu de laatste rand toe aan het workflowobject voor de sluiting.
# Always go from write_file to end.
workflow.add_edge("write_file", END)Voer de werkstroom uit
Het laatste dat nog restte, was het compileren en uitvoeren van de workflow.
# Create the app and run it
app = workflow.compile()
inputs = {}
config = RunnableConfig(recursion_limit=100)
try:
result = app.invoke(inputs, config)
print(result)
except GraphRecursionError:
print("Graph recursion limit reached.")Hierdoor wordt de app aangeroepen. De recursielimiet is het aantal keren dat de LLM wordt afgeleid voor een bepaalde workflow. De workflow stopt wanneer de limiet wordt overschreden.
U kunt de logboeken bekijken op de terminal of in het notebook. Dit is het uitvoeringslogboek voor een eenvoudige CRUD-app.
Veel van het zware werk zal worden gedaan door het onderliggende model, dit was een demo-applicatie met het Deepseek-codeermodel, voor betere prestaties kun je GPT-4 of Claude Opus, haiku, enz. gebruiken.
U kunt ook Langchain-tools gebruiken voor surfen op het web, analyse van aandelenkoersen, enz.
LangChain versus LangGraph
De vraag is nu wanneer LangChain vs LangGraf.
Als het doel is om een multi-agentsysteem te creëren met onderlinge coördinatie, is LangGraph de juiste keuze. Als u echter DAG's of ketens wilt maken om taken te voltooien, is de LangChain Expression Language het meest geschikt.
Waarom LangGraph gebruiken?
LangGraph is een krachtig raamwerk dat veel bestaande oplossingen kan verbeteren.
- Verbeter RAG-pijpleidingen: LangGraph kan de RAG uitbreiden met zijn cyclische grafiekstructuur. We kunnen een feedbacklus introduceren om de kwaliteit van het opgehaalde object te evalueren en, indien nodig, de zoekopdracht verbeteren en het proces herhalen.
- Workflows voor meerdere agenten: LangGraph is ontworpen om workflows met meerdere agenten te ondersteunen. Dit is cruciaal voor het oplossen van complexe taken die zijn opgedeeld in kleinere deeltaken. Verschillende agenten met een gedeelde status en verschillende LLM's en tools kunnen samenwerken om één taak op te lossen.
- Mens-in-de-lus: LangGraph heeft ingebouwde ondersteuning voor de Human-in-the-loop-workflow. Dit betekent dat een mens de statussen kan bekijken voordat hij naar het volgende knooppunt gaat.
- Planbureau: LangGraph is zeer geschikt om planningsagenten te bouwen, waarbij een LLM-planner een gebruikersverzoek plant en ontleedt, een uitvoerder tools en functies aanroept, en de LLM antwoorden synthetiseert op basis van eerdere resultaten.
- Multimodale agenten: LangGraph kan multimodale agenten bouwen, zoals vision-enabled webnavigatoren.
Gebruiksscenario's uit de praktijk
Er zijn talloze gebieden waarop complexe AI-codeermiddelen nuttig kunnen zijn.
- Persoonlijke agents: Stel je voor dat je je eigen Jarvis-achtige assistent op je elektronische apparaten hebt, klaar om te helpen met taken die je binnen handbereik hebt, of dit nu via tekst, stem of zelfs een gebaar is. Dat is een van de meest opwindende toepassingen van AI-agenten!
- AI-instructeurs: Chatbots zijn geweldig, maar ze hebben hun grenzen. AI-agenten die zijn uitgerust met de juiste tools kunnen verder gaan dan eenvoudige gesprekken. Virtuele AI-instructeurs die hun lesmethoden kunnen aanpassen op basis van gebruikersfeedback kunnen baanbrekend zijn.
- Software-UX: De gebruikerservaring van software kan worden verbeterd met AI-agents. In plaats van handmatig door applicaties te navigeren, kunnen agenten taken uitvoeren met spraak- of gebarenopdrachten.
- Ruimtelijke Computing: Naarmate AR/VR-technologie steeds populairder wordt, zal de vraag naar AI-agenten groeien. De agenten kunnen omringende informatie verwerken en op verzoek taken uitvoeren. Dit kan binnenkort een van de beste gebruiksscenario's van AI-agenten zijn.
- LLM besturingssysteem: AI-eerste besturingssystemen waarbij agenten eersteklas burgers zijn. Agenten zullen verantwoordelijk zijn voor het uitvoeren van alledaagse tot complexe taken.
Conclusie
LangGraph is een efficiënt raamwerk voor het bouwen van cyclische stateful multi-actor agentsystemen. Het vult de leemte in het originele LangChain-framework op. Omdat het een verlengstuk is van LangChain, kunnen we profiteren van al het goede van het LangChain-ecosysteem. Naarmate de kwaliteit en mogelijkheden van LLM’s groeien, zal het veel eenvoudiger zijn om agentsystemen te creëren voor het automatiseren van complexe workflows. Hier zijn dus de belangrijkste conclusies uit het artikel.
Key Takeaways
- LangGraph is een uitbreiding van LangChain, waarmee we cyclische, stateful, multi-actor agentsystemen kunnen bouwen.
- Het implementeert een grafiekstructuur met knooppunten en randen. De knooppunten zijn functies of gereedschappen, en de randen zijn de verbindingen tussen knooppunten.
- Er zijn twee soorten randen: voorwaardelijk en normaal. Voorwaardelijke randen hebben voorwaarden tijdens het overgaan van de ene naar de andere, wat belangrijk is voor het toevoegen van cycliciteit aan de workflow.
- LangGraph heeft de voorkeur voor het bouwen van cyclische multi-actor agenten, terwijl LangChain beter is in het creëren van ketens of gerichte acyclische systemen.
Veelgestelde Vragen / FAQ
Ant. LangGraph is een open-sourcebibliotheek voor het bouwen van stateful cyclische multi-actor agentsystemen. Het is gebouwd bovenop het LangChain-ecosysteem.
Ant. LangGraph heeft de voorkeur voor het bouwen van cyclische multi-actor agenten, terwijl LangChain beter is in het creëren van ketens of gerichte acyclische systemen.
Ant. AI-agents zijn softwareprogramma's die communiceren met hun omgeving, beslissingen nemen en handelen om een einddoel te bereiken.
Ant. Dit is afhankelijk van uw gebruiksscenario's en budget. GPT 4 is het meest capabel, maar duur. Voor codering is DeepSeekCoder-33b een veel goedkopere optie.
Ant. De ketens zijn een reeks hardgecodeerde acties die moeten worden gevolgd, terwijl agenten LLM's en andere hulpmiddelen (ook ketens) gebruiken om te redeneren en te handelen op basis van de informatie
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2024/03/build-an-ai-coding-agent-with-langgraph-by-langchain/

