Apache Kafka staat bekend om zijn prestaties en afstembaarheid om te optimaliseren voor verschillende gebruikssituaties. Maar soms kan het een uitdaging zijn om de juiste infrastructuurconfiguratie te vinden die voldoet aan uw specifieke prestatie-eisen en tegelijkertijd de infrastructuurkosten te minimaliseren.
Dit bericht legt uit hoe de onderliggende infrastructuur de prestaties van Apache Kafka beïnvloedt. We bespreken strategieën voor de grootte van uw clusters om te voldoen aan uw vereisten voor doorvoer, beschikbaarheid en latentie. Onderweg beantwoorden we vragen als "wanneer is het zinvol om op te schalen versus uit te schalen?" We eindigen met richtlijnen voor het continu verifiëren van de grootte van uw productieclusters.
We gebruiken prestatietests om het effect en de afweging van verschillende strategieën voor de grootte van uw cluster te illustreren en uit te leggen. Maar zoals gewoonlijk is het belangrijk om niet blindelings te vertrouwen op benchmarks die u toevallig op internet vindt. We laten daarom niet alleen zien hoe u de resultaten kunt reproduceren, maar leggen ook uit hoe u a kader voor prestatietests om uw eigen tests uit te voeren voor uw specifieke werkbelastingkenmerken.
Grootte van Apache Kafka-clusters aanpassen
De meest voorkomende resource-knelpunten voor clusters vanuit een infrastructuurperspectief zijn netwerkdoorvoer, opslagdoorvoer en netwerkdoorvoer tussen brokers en de storage-backend voor brokers die gebruikmaken van netwerkgekoppelde opslag zoals Amazon elastische blokwinkel (Amazone-EBS).
In de rest van het bericht wordt uitgelegd hoe de aanhoudende doorvoerlimiet van een cluster niet alleen afhangt van de opslag- en netwerkdoorvoerlimieten van de makelaars, maar ook van het aantal makelaars en consumentengroepen en van de replicatiefactor r. We leiden de volgende formule af (in dit bericht ook wel vergelijking 1 genoemd) voor de theoretische aanhoudende doorvoerlimiet: tcluster gegeven de infrastructuurkenmerken van een specifiek cluster:
Voor productieclusters is het een best practice om de werkelijke doorvoer te richten op 80% van de theoretische aanhoudende doorvoerlimiet. Denk bijvoorbeeld aan een cluster met drie knooppunten met m5.12xlarge brokers, een replicatiefactor van 3, EBS-volumes met een baseline-doorvoer van 1000 MB/sec en twee consumentengroepen die verbruiken vanaf de punt van het onderwerp. Rekening houdend met al deze parameters, zou de aanhoudende doorvoer die door het cluster wordt geabsorbeerd, 800 MB/sec moeten zijn.
Deze doorvoerberekening biedt echter slechts een bovengrens voor workloads die zijn geoptimaliseerd voor scenario's met hoge doorvoer. Ongeacht hoe u uw onderwerpen configureert en de clients die lezen van en schrijven naar deze onderwerpen, het cluster kan niet meer doorvoer absorberen. Voor workloads met verschillende kenmerken, zoals latentiegevoelige of rekenintensieve workloads, is de daadwerkelijke doorvoer die door een cluster kan worden geabsorbeerd terwijl aan deze aanvullende vereisten wordt voldaan, vaak kleiner.
Om de juiste configuratie voor uw workload te vinden, moet u achteruit werken vanuit uw use case en de juiste vereisten voor doorvoer, beschikbaarheid, duurzaamheid en latentie bepalen. Gebruik vervolgens vergelijking 1 om de initiële grootte van uw cluster te verkrijgen op basis van uw doorvoer, duurzaamheid en opslagvereisten. Controleer deze initiële clustergrootte door prestatietests uit te voeren en pas vervolgens de clustergrootte, clusterconfiguratie en clientconfiguratie aan om aan uw andere vereisten te voldoen. Voeg ten slotte extra capaciteit toe voor productieclusters, zodat ze nog steeds de verwachte doorvoer kunnen opnemen, zelfs als het cluster op verminderde capaciteit draait, bijvoorbeeld tijdens onderhoud, schaling of verlies van een broker. Afhankelijk van uw werklast, kunt u zelfs overwegen om voldoende reservecapaciteit toe te voegen om een gebeurtenis te weerstaan die alle makelaars van een volledige Availability Zone treft.
De rest van de post gaat dieper in op de aspecten van clustergrootte. De belangrijkste aspecten zijn als volgt:
- Vaak is er de keuze tussen uitschalen of opschalen om de doorvoer en prestaties van een cluster te verhogen. Kleine makelaars geven u kleinere capaciteitsverhogingen en hebben een kleinere explosieradius voor het geval ze niet meer beschikbaar zijn. Maar het hebben van veel kleine makelaars vergroot de tijd die nodig is voor bewerkingen waarvoor een doorlopende update voor makelaars nodig is, en vergroot de kans op mislukking.
- Al het verkeer dat producenten naar een cluster sturen, wordt bewaard op schijf. Daarom kan de onderliggende doorvoer van het opslagvolume de bottleneck van het cluster worden. In dit geval is het zinvol om indien mogelijk de volumedoorvoer te verhogen of meer volumes aan het cluster toe te voegen.
- Alle gegevens die op EBS-volumes worden bewaard, gaan via het netwerk. Amazon EBS-geoptimaliseerde instances worden geleverd met speciale capaciteit voor Amazon EBS I/O, maar het speciale Amazon EBS-netwerk kan nog steeds de bottleneck van het cluster worden. In dit geval is het logisch om brokers op te schalen, omdat grotere brokers een hogere Amazon EBS-netwerkdoorvoer hebben.
- Hoe meer consumentengroepen van het cluster lezen, hoe meer gegevens er over de Amazon Elastic Compute-cloud (Amazon EC2) netwerk van de makelaars. Afhankelijk van het type en de grootte van de broker kan het Amazon EC2-netwerk de bottleneck van het cluster worden. In dat geval is het logisch om brokers op te schalen, omdat grotere brokers een hogere Amazon EC2-netwerkdoorvoer hebben.
- Voor p99 put-latenties is er een aanzienlijke prestatie-impact van het inschakelen van in-clusterversleuteling. Het opschalen van de brokers van een cluster kan de p99-putlatentie aanzienlijk verminderen in vergelijking met kleinere brokers.
- Wanneer consumenten achterblijven of historische gegevens opnieuw moeten verwerken, bevinden de gevraagde gegevens zich mogelijk niet langer in het geheugen en moeten makelaars gegevens ophalen van het opslagvolume. Dit veroorzaakt niet-sequentiële I/O-lezingen. Bij gebruik van EBS-volumes veroorzaakt dit ook extra netwerkverkeer naar het volume. Het gebruik van grotere brokers met meer geheugen of het inschakelen van compressie kan dit effect verminderen.
- Het gebruik van de burst-mogelijkheden van uw cluster is een zeer krachtige manier om plotselinge doorvoerpieken op te vangen zonder uw cluster te schalen, wat tijd kost om te voltooien. Burst-capaciteit helpt ook bij het reageren op operationele gebeurtenissen. Wanneer brokers bijvoorbeeld onderhoud ondergaan of partities opnieuw moeten worden gebalanceerd binnen het cluster, kunnen ze de burst-prestaties gebruiken om de bewerking sneller te voltooien.
- Bewaak of alarmeer belangrijke infrastructuurgerelateerde clusterstatistieken zoals:
BytesInPerSec,ReplicationBytesInPerSec,BytesOutPerSecenReplicationBytesOutPerSecom een melding te ontvangen wanneer de huidige clustergrootte niet langer optimaal is voor de huidige clustergrootte.
De rest van het bericht biedt extra context en legt de redenering achter deze aanbevelingen uit.
Inzicht in de prestatieknelpunten van Apache Kafka
Voordat we beginnen te praten over prestatieknelpunten vanuit een infrastructuurperspectief, gaan we nog eens kijken hoe gegevens binnen een cluster stromen.
Voor dit bericht gaan we ervan uit dat producenten en consumenten zich goed en volgens 'best practices', tenzij uitdrukkelijk anders vermeld. We gaan er bijvoorbeeld van uit dat de producenten de belasting tussen brokers gelijk verdelen, brokers hosten hetzelfde aantal partities, er zijn voldoende partities om de doorvoer op te nemen, consumenten consumeren rechtstreeks vanaf de punt van de stream, enzovoort. De makelaars krijgen dezelfde lading en doen hetzelfde werk. We richten ons daarom alleen op Broker 1 in het volgende diagram van een gegevensstroom binnen een cluster.

De producenten sturen een totale doorvoer van tcluster in het cluster. Omdat het verkeer zich gelijkmatig over brokers verspreidt, ontvangt Broker 1 een inkomende doorvoer van tcluster/3. Met een replicatiefactor van 3, Broker 1 repliceert het verkeer dat het rechtstreeks ontvangt naar de twee andere makelaars (de blauwe lijnen). Evenzo ontvangt Broker 1 replicatieverkeer van twee makelaars (de rode lijnen). Elke consumentengroep verbruikt het verkeer dat rechtstreeks in Broker 1 wordt geproduceerd (de groene lijnen). Al het verkeer dat binnenkomt in Broker 1 van producenten en replicatieverkeer van andere makelaars wordt uiteindelijk doorgezet naar opslagvolumes die aan de makelaar zijn gekoppeld.
Dienovereenkomstig zijn de doorvoer van het opslagvolume en het brokernetwerk beide nauw gekoppeld aan de algehele clusterdoorvoer en verdienen ze een nadere beschouwing.
Kenmerken van opslag-backend-doorvoer
Apache Kafka is ontworpen om grote sequentiële I/O-bewerkingen te gebruiken bij het schrijven van gegevens naar schijf. Producenten voegen alleen gegevens toe aan de punt van het logboek, waardoor sequentiële schrijfacties ontstaan. Bovendien spoelt Apache Kafka niet synchroon naar schijf. In plaats daarvan schrijft Apache Kafka naar de paginacache en laat het aan het besturingssysteem over om pagina's naar de schijf te spoelen. Dit resulteert in grote sequentiële I/O-bewerkingen, wat de schijfdoorvoer optimaliseert.
Voor veel praktische doeleinden kan de broker de volledige doorvoer van het volume aansturen en wordt hij niet beperkt door IOPS. We gaan ervan uit dat consumenten vanaf het puntje van het onderwerp lezen. Dit houdt in dat de prestaties van EBS-volumes doorvoergebonden zijn en niet I/O-gebonden, en dat leesbewerkingen worden uitgevoerd vanuit de paginacache.
De ingangsdoorvoer van de storage-backend is afhankelijk van de gegevens die producenten rechtstreeks naar de broker sturen plus het replicatieverkeer
ic de makelaar ontvangt van zijn collega's. Voor een geaggregeerde doorvoer geproduceerd in het cluster van tcluster en een replicatiefactor van r, is de doorvoer die wordt ontvangen door de opslag van de makelaar als volgt:
Daarom is de aanhoudende doorvoerlimiet van het hele cluster gebonden aan het volgende:
AWS biedt verschillende opties voor blokopslag: instance storage en Amazon EBS. Instantieopslag bevindt zich op schijven die fysiek zijn aangesloten op de hostcomputer, terwijl Amazon EBS op een netwerk is aangesloten.
Instantiefamilies die bij instantieopslag worden geleverd, behalen een hoge IOPS en schijfdoorvoer. Amazon EC2 I3-instanties bevatten bijvoorbeeld NVMe SSD-gebaseerde instantieopslag die is geoptimaliseerd voor lage latentie, zeer hoge willekeurige I/O-prestaties en hoge sequentiële leesdoorvoer. De volumes zijn echter gebonden aan makelaars. Hun kenmerken, met name hun grootte, zijn alleen afhankelijk van de instantiefamilie en de volumegrootte kan niet worden aangepast. Bovendien, wanneer een makelaar uitvalt en moet worden vervangen, gaat het opslagvolume verloren. De vervangende makelaar moet dan de gegevens van andere makelaars repliceren. Deze replicatie veroorzaakt extra belasting van het cluster naast de verminderde capaciteit door het verlies van de broker.
Daarentegen kunnen de kenmerken van EBS-volumes worden aangepast terwijl ze in gebruik zijn. U kunt deze mogelijkheden gebruiken om de opslag van brokers in de loop van de tijd automatisch te schalen in plaats van opslag voor pieken in te richten of extra brokers toe te voegen. Met sommige EBS-volumetypen, zoals gp3, io2 en st1, kunt u ook de doorvoer- en IOPS-kenmerken van bestaande volumes aanpassen. Bovendien is de levenscyclus van EBS-volumes onafhankelijk van de broker: als een broker uitvalt en moet worden vervangen, kan het EBS-volume opnieuw worden gekoppeld aan de vervangende broker. Dit vermijdt het grootste deel van het anders vereiste replicatieverkeer.
Het gebruik van EBS-volumes is daarom vaak een goede keuze voor veel voorkomende Apache Kafka-workloads. Ze bieden meer flexibiliteit en maken snellere schaal- en herstelbewerkingen mogelijk.
Amazon EBS-doorvoerkenmerken
Wanneer u Amazon EBS als opslagbackend gebruikt, kunt u uit verschillende volumetypen kiezen. De doorvoerkarakteristieken van de verschillende volumetypes variëren van 128 MB/sec tot 4000 MB/sec (raadpleeg voor meer informatie Amazon EBS-volumetypen). U kunt er zelfs voor kiezen om meerdere volumes aan een broker te koppelen om de doorvoer te vergroten die verder gaat dan wat met één volume kan worden geleverd.
Amazon EBS is echter netwerkgebonden opslag. Alle gegevens die een broker naar een EBS-volume schrijft, moeten het netwerk doorkruisen naar de Amazon EBS-backend. Instantiefamilies van de nieuwere generatie, zoals de M5-familie, zijn voor Amazon EBS geoptimaliseerde instances met speciale capaciteit voor Amazon EBS I/O. Maar er zijn limieten voor de doorvoer en de IOPS die afhankelijk zijn van de grootte van de instantie en niet alleen van de volumegrootte. De speciale capaciteit voor Amazon EBS zorgt voor een hogere baseline-doorvoer en IOPS voor grotere instanties. De capaciteit varieert van 81 MB/sec tot 2375 MB/sec. Voor meer informatie, zie: Ondersteunde instantietypen.
Wanneer we Amazon EBS gebruiken voor opslag, kunnen we de formule voor de aanhoudende doorvoerlimiet van het cluster aanpassen om een strakkere bovengrens te verkrijgen:
Amazon EC2-netwerkdoorvoer
Tot nu toe hebben we alleen gekeken naar netwerkverkeer naar het EBS-volume. Maar replicatie en de consumentengroepen veroorzaken ook Amazon EC2-netwerkverkeer uit de makelaar. Het verkeer dat producenten naar een makelaar sturen, wordt gerepliceerd naar: r-1 makelaars. Bovendien leest elke consumentengroep het verkeer dat een makelaar binnenkrijgt. Het totale uitgaande netwerkverkeer is daarom als volgt:
Als we dit verkeer in aanmerking nemen, krijgen we uiteindelijk een redelijke bovengrens voor de aanhoudende doorvoerlimiet van het cluster, die we al hebben gezien in vergelijking 1:
Voor productie-workloads raden we aan om de werkelijke doorvoer van uw workload onder 80% van de theoretische aanhoudende doorvoer limiet te houden, zoals deze wordt bepaald door deze formule. Verder gaan we ervan uit dat alle dataproducenten die naar het cluster worden gestuurd uiteindelijk worden gelezen door ten minste één consumentengroep. Wanneer het aantal consumenten groter of gelijk is aan 1, is het Amazon EC2-netwerkverkeer uit een makelaar altijd hoger dan het verkeer naar de makelaar. Daarom kunnen we dataverkeer naar brokers negeren als een potentieel knelpunt.
Met vergelijking 1 kunnen we verifiëren of een cluster met een bepaalde infrastructuur de doorvoer kan opnemen die nodig is voor onze werklast onder ideale omstandigheden. Raadpleeg voor meer informatie over de Amazon EC2-netwerkbandbreedte van m5.8xgrote en grotere instanties: Amazon EC2-instantietypen. Je kunt ook de Amazon EBS-bandbreedte van m5.4xgrote instanties op dezelfde pagina vinden. Kleinere instanties gebruiken op krediet gebaseerde systemen voor Amazon EC2-netwerkbandbreedte en de Amazon EBS-bandbreedte. Voor de bandbreedte van de Amazon EC2-netwerkbasislijn raadpleegt u: Netwerkprestaties. Raadpleeg voor de Amazon EBS-basisbandbreedte: Ondersteunde instantietypen.
De juiste grootte van uw cluster om te optimaliseren voor prestaties en kosten
Dus, wat nemen we hiervan op? Houd er vooral rekening mee dat deze resultaten alleen de aanhoudende doorvoerlimiet van een cluster onder ideale omstandigheden aangeven. Deze resultaten kunnen u een algemeen getal geven voor de verwachte aanhoudende doorvoer limiet van uw clusters. Maar u moet uw eigen experimenten uitvoeren om deze resultaten te verifiëren voor uw specifieke werkbelasting en configuratie.
We kunnen echter een paar conclusies trekken uit deze doorvoerschatting: het toevoegen van brokers verhoogt de aanhoudende clusterdoorvoer. Evenzo verhoogt het verlagen van de replicatiefactor de aanhoudende clusterdoorvoer. Het toevoegen van meer dan één consumentengroep kan de aanhoudende clusterdoorvoer verminderen als het Amazon EC2-netwerk het knelpunt wordt.
Laten we een paar experimenten uitvoeren om empirische gegevens te krijgen over praktische aanhoudende clusterdoorvoer die ook rekening houdt met latenties van producenten. Voor deze tests houden we de doorvoer binnen de aanbevolen 80% van de aanhoudende doorvoerlimiet van clusters. Wanneer u uw eigen tests uitvoert, merkt u misschien dat clusters zelfs een hogere doorvoer kunnen leveren dan we laten zien.
Meet Amazon MSK-clusterdoorvoer en zet latenties
Om de infrastructuur voor de experimenten te creëren, gebruiken we Amazon Managed Streaming voor Apache Kafka (Amazon MSK). Amazon MSK voorziet en beheert zeer beschikbare Apache Kafka-clusters die worden ondersteund door Amazon EBS-opslag. De volgende bespreking is daarom ook van toepassing op clusters die niet zijn ingericht via Amazon MSK, indien ondersteund door EBS-volumes.
De experimenten zijn gebaseerd op de kafka-producer-perf-test.sh en kafka-consumer-perf-test.sh tools die zijn opgenomen in de Apache Kafka-distributie. De tests gebruiken zes producenten en twee consumentengroepen met elk zes consumenten die gelijktijdig lezen en schrijven vanuit het cluster. Zoals eerder vermeld, zorgen we ervoor dat klanten en makelaars zich goed en volgens best practices gedragen: producenten verdelen de belasting tussen makelaars gelijkmatig, makelaars hosten hetzelfde aantal partities, consumenten consumeren rechtstreeks uit het puntje van de stroom, producenten en consumenten zijn overbevoorraad zodat ze geen bottleneck worden in de metingen, enzovoort.
We gebruiken clusters waarvan de brokers zijn geïmplementeerd in drie beschikbaarheidszones. Bovendien is replicatie ingesteld op: 3 en acks is ingesteld op all om een hoge duurzaamheid te bereiken van de gegevens die in het cluster worden bewaard. We hebben ook een geconfigureerd batch.size van 256 kB of 512 kB en set linger.ms tot 5 milliseconden, wat de overhead van het opnemen van kleine batches records vermindert en daarom de doorvoer optimaliseert. Het aantal partities wordt aangepast aan de brokergrootte en clusterdoorvoer.
De configuratie voor makelaars groter dan m5.2xlarge is aangepast volgens de richtlijnen van de Amazon MSK-ontwikkelaarsgids. In het bijzonder bij het gebruik van ingerichte doorvoer, is het essentieel om de clusterconfiguratie dienovereenkomstig te optimaliseren.
De volgende afbeelding vergelijkt putlatenties voor drie clusters met verschillende brokergroottes. Voor elk cluster voeren de producenten ongeveer een dozijn individuele prestatietests uit met verschillende doorvoerconfiguraties. Aanvankelijk produceren de producenten een gecombineerde doorvoer van 16 MB/sec in het cluster en verhogen geleidelijk de doorvoer bij elke afzonderlijke test. Elke individuele test duurt 1 uur. Voor instanties met burstable-prestatiekenmerken zijn de credits uitgeput voordat de daadwerkelijke prestatiemeting wordt gestart.

Voor brokers met meer dan 334 GB aan opslagruimte kunnen we aannemen dat het EBS-volume een baseline-doorvoer heeft van 250 MB/sec. De basisdoorvoer van het Amazon EBS-netwerk is 81.25, 143.75, 287.5 en 593.75 MB/sec voor de verschillende brokergroottes (zie voor meer informatie Ondersteunde instantietypen). De baseline-doorvoer van het Amazon EC2-netwerk is 96, 160, 320 en 640 MB/sec (zie voor meer informatie Netwerkprestaties). Merk op dat dit alleen rekening houdt met de aanhoudende doorvoer; we bespreken burst-prestaties in een later gedeelte.
Voor een cluster met drie knooppunten met replicatie 3 en twee consumentengroepen zijn de aanbevolen doorvoer limieten voor inkomend verkeer volgens vergelijking 1 als volgt.
| Maat makelaar: | Aanbevolen aanhoudende doorvoerlimiet |
| m5.groot | 58 MB / sec |
| m5.xgroot | 96 MB / sec |
| m5.2xgroot | 192 MB / sec |
| m5.4xgroot | 200 MB / sec |
Hoewel de m5.4xlarge-makelaars tweemaal zoveel vCPU's en geheugen hebben in vergelijking met m5.2xlarge-makelaars, neemt de aanhoudende doorvoerlimiet van het cluster nauwelijks toe bij het schalen van de makelaars van m5.2xlarge naar m5.4xlarge. Dat komt omdat met deze configuratie het EBS-volume dat door makelaars wordt gebruikt een knelpunt wordt. Onthoud dat we zijn uitgegaan van een basislijndoorvoer o
f 250 MB/sec voor deze volumes. Voor een cluster met drie knooppunten en een replicatiefactor van 3 moet elke broker hetzelfde verkeer naar het EBS-volume schrijven als naar het cluster zelf wordt verzonden. En omdat 80% van de basislijndoorvoer van het EBS-volume 200 MB/sec is, is de aanbevolen aanhoudende doorvoerlimiet van het cluster met m5.4xlarge brokers 200 MB/sec.
In de volgende sectie wordt beschreven hoe u ingerichte doorvoer kunt gebruiken om de basis doorvoer van EBS-volumes te verhogen en daarmee de aanhoudende doorvoer limiet van het hele cluster te verhogen.
Verhoog de doorvoer van brokers met ingerichte doorvoer
Uit de vorige resultaten kunt u zien dat er vanuit een puur doorvoerperspectief weinig voordeel is om de brokergrootte te vergroten van m5.2xlarge naar m5.4xlarge met de standaard clusterconfiguratie. De baseline-doorvoer van het EBS-volume dat door makelaars wordt gebruikt, beperkt hun doorvoer. Amazon MSK heeft onlangs echter de mogelijkheid gelanceerd om een opslagcapaciteit tot 1000 MB/sec te leveren. Voor zelfbeheerde clusters kunt u gp3-, io2- of st1-volumetypen gebruiken om een vergelijkbaar effect te bereiken. Afhankelijk van de grootte van de broker kan dit de algehele clusterdoorvoer aanzienlijk verhogen.
De volgende afbeelding vergelijkt de clusterdoorvoer en zet latenties van verschillende brokergroottes en verschillende ingerichte doorvoerconfiguraties.

Voor een cluster met drie knooppunten met replicatie 3 en twee consumentengroepen zijn de aanbevolen doorvoer limieten voor inkomend verkeer volgens vergelijking 1 als volgt.
| Maat makelaar: | Ingerichte doorvoerconfiguratie | Aanbevolen aanhoudende doorvoerlimiet |
| m5.4xgroot | - | 200 MB / sec |
| m5.4xgroot | 480 MB / sec | 384 MB / sec |
| m5.8xgroot | 850 MB / sec | 680 MB / sec |
| m5.12xgroot | 1000 MB / sec | 800 MB / sec |
| m5.16xgroot | 1000 MB / sec | 800 MB / sec |
De ingerichte doorvoerconfiguratie is zorgvuldig gekozen voor de gegeven werkbelasting. Met twee consumentengroepen die consumeren van het cluster, heeft het geen zin om de ingerichte doorvoer van m4.4xlarge brokers te verhogen tot boven de 480 MB/sec. Het Amazon EC2-netwerk, niet de EBS-volumedoorvoer, beperkt de aanbevolen aanhoudende doorvoerlimiet van het cluster tot 384 MB/sec. Maar voor workloads met een ander aantal consumenten kan het zinvol zijn om de ingerichte doorvoerconfiguratie verder te verhogen of te verlagen om overeen te komen met de basisdoorvoer van het Amazon EC2-netwerk.
Uitschalen om de schrijfsnelheid van het cluster te vergroten
Het uitschalen van het cluster verhoogt natuurlijk de clusterdoorvoer. Maar welke invloed heeft dit op de prestaties en de kosten? Laten we de doorvoer van twee verschillende clusters vergelijken: een drie-node m5.4xlarge en een zes-node m5.2xlarge cluster, zoals weergegeven in de volgende afbeelding. De opslaggrootte voor het m5.4xlarge cluster is aangepast zodat beide clusters dezelfde totale opslagcapaciteit hebben en daarom zijn de kosten voor deze clusters identiek.

Het cluster met zes knooppunten heeft bijna het dubbele van de doorvoer van het cluster met drie knooppunten en aanzienlijk lagere p99-putlatenties. Als u alleen naar de inkomende doorvoer van het cluster kijkt, kan het zinvol zijn om uit te schalen in plaats van op te schalen, als u meer dan 200 MB/sec aan doorvoer nodig hebt. De volgende tabel vat deze aanbevelingen samen.
| Aantal makelaars | Aanbevolen aanhoudende doorvoerlimiet | ||
| m5.groot | m5.2xgroot | m5.4xgroot | |
| 3 | 58 MB / sec | 192 MB / sec | 200 MB / sec |
| 6 | 115 MB / sec | 384 MB / sec | 400 MB / sec |
| 9 | 173 MB / sec | 576 MB / sec | 600 MB / sec |
In dit geval hadden we ook ingerichte doorvoer kunnen gebruiken om de doorvoer van het cluster te verhogen. Vergelijk bijvoorbeeld de aanhoudende doorvoerlimiet van het m5.2xlarge-cluster met zes knooppunten in de voorgaande afbeelding met die van het m5.4xlarge-cluster met drie knooppunten met ingerichte doorvoer uit het eerdere voorbeeld. De aanhoudende doorvoerlimiet van beide clusters is identiek, wat wordt veroorzaakt door dezelfde bandbreedtelimiet voor het Amazon EC2-netwerk die gewoonlijk evenredig groeit met de grootte van de broker.
Opschalen om de leesdoorvoer van het cluster te vergroten
Hoe meer consumentengroepen uit het cluster lezen, hoe meer gegevens er via het Amazon EC2-netwerk van de makelaars gaan. Grotere brokers hebben een hogere netwerk-baseline-doorvoer (tot 25 Gb/sec) en kunnen daarom meer consumentengroepen ondersteunen die uit het cluster lezen.
De volgende afbeelding vergelijkt hoe latentie en doorvoer veranderen voor het verschillende aantal consumentengroepen voor een m5.2xlarge-cluster met drie knooppunten.

Zoals blijkt uit deze afbeelding, verlaagt het verhogen van het aantal consumentengroepen dat van een cluster leest, de aanhoudende doorvoerlimiet. Hoe meer consumenten die consumentengroepen uit het cluster lezen, hoe meer gegevens er van de makelaars moeten uitgaan via het Amazon EC2-netwerk. De volgende tabel vat deze aanbevelingen samen.
| Consumentengroepen | Aanbevolen aanhoudende doorvoerlimiet | ||
| m5.groot | m5.2xgroot | m5.4xgroot | |
| 0 | 65 MB / sec | 200 MB / sec | 200 MB / sec |
| 2 | 58 MB / sec | 192 MB / sec | 200 MB / s ec |
| 4 | 38 MB / sec | 128 MB / sec | 200 MB / sec |
| 6 | 29 MB / sec | 96 MB / sec | 192 MB / sec |
De grootte van de broker bepaalt de doorvoer van het Amazon EC2-netwerk en er is geen andere manier om deze te vergroten dan opschalen. Om de lees doorvoer van het cluster te schalen, moet u de brokers opschalen of het aantal brokers vergroten.
Saldo makelaar grootte en aantal makelaars
Bij het dimensioneren van een cluster hebt u vaak de keuze om uit te schalen of omhoog te schalen om de doorvoer en prestaties van een cluster te verhogen. Ervan uitgaande dat de opslaggrootte dienovereenkomstig wordt aangepast, zijn de kosten van deze twee opties vaak identiek. Dus wanneer moet je uit- of opschalen?
Door kleinere brokers te gebruiken, kunt u de capaciteit in kleinere stappen schalen. Amazon MSK dwingt af dat brokers gelijkmatig verdeeld zijn over alle geconfigureerde beschikbaarheidszones. Je kunt dus alleen een aantal brokers toevoegen die een veelvoud zijn van het aantal Availability Zones. Als u bijvoorbeeld drie brokers toevoegt aan een drie-node m5.4xlarge cluster met ingerichte doorvoer, verhoogt u de aanbevolen aanhoudende doorvoerlimiet voor clusters met 100%, van 384 MB/sec tot 768 MB/sec. Als u echter drie brokers toevoegt aan een zes-node m5.2xlarge cluster, verhoogt u de aanbevolen doorvoerlimiet voor clusters met 50%, van 384 MB/sec tot 576 MB/sec.
Het hebben van te weinig zeer grote makelaars vergroot ook de explosieradius in het geval een enkele makelaar niet beschikbaar is voor onderhoud of vanwege een storing in de onderliggende infrastructuur. Voor een cluster met drie knooppunten komt een enkele broker bijvoorbeeld overeen met 33% van de clustercapaciteit, terwijl dit slechts 17% is voor een cluster met zes knooppunten. Bij het inrichten van clusters volgens best practices, hebt u voldoende reservecapaciteit toegevoegd om uw werkbelasting tijdens deze bewerkingen niet te beïnvloeden. Maar voor grotere makelaars moet u mogelijk meer reservecapaciteit toevoegen dan nodig is vanwege de grotere capaciteitsverhogingen.
Hoe meer brokers er deel uitmaken van het cluster, hoe langer het duurt voordat de onderhouds- en updatebewerkingen zijn voltooid. De service past deze wijzigingen achtereenvolgens op één broker tegelijk toe om de impact op de beschikbaarheid van het cluster te minimaliseren. Bij het inrichten van clusters volgens best practices, hebt u voldoende reservecapaciteit toegevoegd om uw werkbelasting tijdens deze bewerkingen niet te beïnvloeden. Maar de tijd die nodig is om de bewerking te voltooien, is nog steeds iets om rekening mee te houden, omdat u moet wachten tot de ene bewerking is voltooid voordat u een andere kunt uitvoeren.
U moet een balans vinden die past bij uw werkdruk. Kleine makelaars zijn flexibeler omdat ze u kleinere capaciteitsstappen geven. Maar als u te veel kleine makelaars heeft, duurt het langer voordat onderhoudswerkzaamheden zijn voltooid en neemt de kans op storingen toe. Clusters met minder grotere brokers voltooien update-operaties sneller. Maar ze worden geleverd met grotere capaciteitsverhogingen en een grotere explosieradius in het geval van een storing van de makelaar.
Opschalen voor CPU-intensieve workloads
Tot nu toe hebben we ons gericht op de netwerkdoorvoer van brokers. Maar er zijn andere factoren die de doorvoer en latentie van het cluster bepalen. Een daarvan is encryptie. Apache Kafka heeft verschillende lagen waar encryptie gegevens in transit en in rust kan beschermen: encryptie van de gegevens die zijn opgeslagen op de opslagvolumes, encryptie van verkeer tussen brokers en encryptie van verkeer tussen clients en brokers.
Amazon MSK versleutelt altijd uw gegevens in rust. U kunt de AWS Sleutelbeheerservice (AWS KMS) klanthoofdsleutel (CMK) die u wilt dat Amazon MSK gebruikt om uw gegevens in rust te versleutelen. Als u geen CMK opgeeft, maakt Amazon MSK een AWS beheerde CMK voor u en gebruikt het namens u. Voor gegevens die tijdens de vlucht zijn, kunt u ervoor kiezen om gegevensversleuteling tussen producenten en makelaars (versleuteling tijdens het transport), tussen makelaars (versleuteling in het cluster) of beide in te schakelen.
Het inschakelen van in-clusterversleuteling dwingt de makelaars om individuele berichten te versleutelen en ontsleutelen. Daarom kan het verzenden van berichten via het netwerk niet langer profiteren van de efficiënte nulkopie-bewerking. Dit resulteert in extra overhead voor CPU en geheugenbandbreedte.
De volgende afbeelding toont de prestatie-impact voor deze opties voor clusters met drie knooppunten met m5.large en m5.2xlarge brokers.
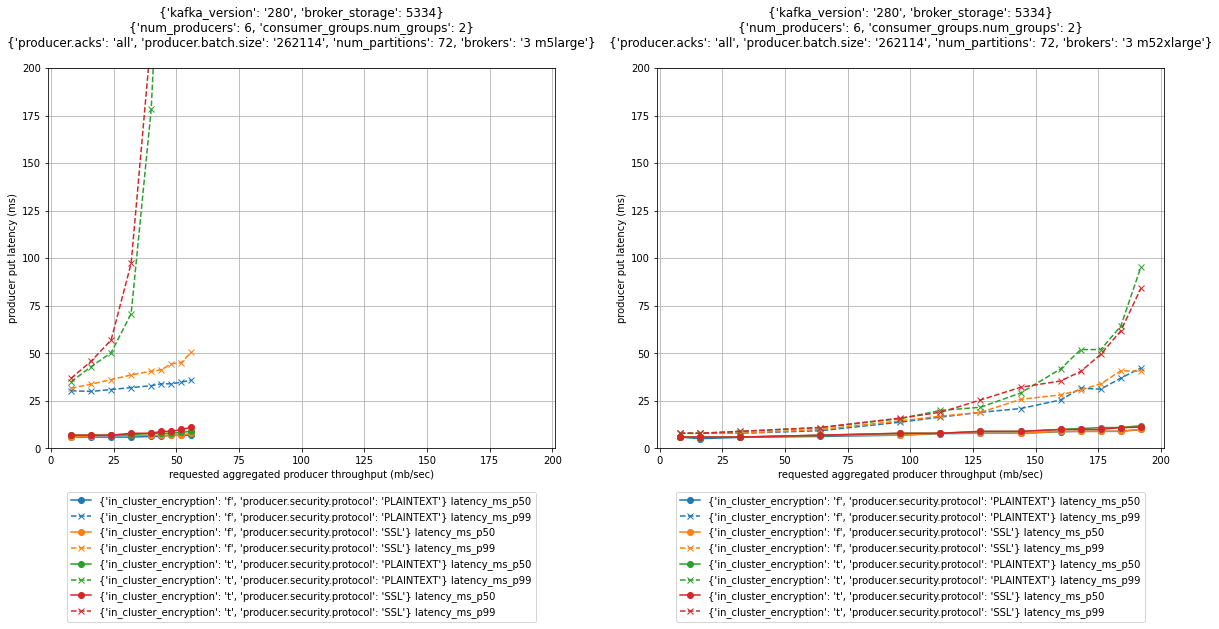
Voor p99 put-latenties is er een aanzienlijke prestatie-impact van het inschakelen van in-clusterversleuteling. Zoals in de voorgaande grafieken is te zien, kan het opschalen van brokers het effect verzachten. De p99 zet een latentie van 52 MB/sec doorvoer van een m5.large cluster met in-transit en in-cluster encryptie boven 200 milliseconden (rode en groene stippellijn in de linker grafiek). Door het cluster te schalen naar m5.2xlarge brokers wordt de p99-latentie bij dezelfde doorvoer teruggebracht tot minder dan 15 milliseconden (rode en groene stippellijn in de rechtergrafiek).
Er zijn andere factoren die de CPU-vereisten kunnen verhogen. Zowel compressie als logboekverdichting kunnen ook van invloed zijn op de belasting van clusters.
Opschalen voor een consument die niet leest vanaf het puntje van de stream
We hebben de prestatietests zo ontworpen dat consumenten altijd vanaf het puntje van het onderwerp lezen. Dit betekent in feite dat makelaars de reads van consumenten rechtstreeks vanuit het geheugen kunnen bedienen, zonder dat er lees-I/O naar Amazon EBS wordt veroorzaakt. In tegenstelling tot alle andere secties van de post, laten we deze veronderstelling vallen om te begrijpen hoe consumenten die achterop zijn geraakt de clusterprestaties kunnen beïnvloeden. Het volgende diagram illustreert dit ontwerp.

Wanneer een consument achterop raakt of moet herstellen van een storing, worden oudere berichten opnieuw verwerkt. In dat geval bevinden de pagina's met de gegevens zich mogelijk niet langer in de paginacache en moeten brokers de gegevens ophalen van het EBS-volume. Dat zorgt voor extra netwerkverkeer naar het volume en niet-sequentiële I/O-lezingen. Dit kan de doorvoer van het EBS-volume aanzienlijk beïnvloeden.
In het uiterste geval kan een opvulbewerking de volledige geschiedenis van gebeurtenissen opnieuw verwerken. In dat geval veroorzaakt de bewerking niet alleen extra I/O op het EBS-volume, maar laadt het ook veel pagina's met historische gegevens in de paginacache, waardoor pagina's met recentere gegevens effectief worden verwijderd. Bijgevolg kunnen consumenten die iets achterlopen op het punt van het onderwerp en normaal gesproken rechtstreeks uit de paginacache zouden lezen, nu extra I/O naar het EBS-volume veroorzaken, omdat de opvulbewerking de pagina die ze moeten lezen uit het geheugen heeft verwijderd.
Een optie om deze scenario's te beperken, is door compressie in te schakelen. Door de onbewerkte gegevens te comprimeren, kunnen makelaars meer gegevens in de paginacache bewaren voordat deze uit het geheugen worden verwijderd. Houd er echter rekening mee dat compressie meer CPU-bronnen vereist. Als u compressie niet kunt inschakelen of als het inschakelen van compressie dit scenario niet kan verhelpen, kunt u ook de grootte van de paginacache vergroten door het beschikbare geheugen voor brokers te vergroten door op te schalen.
Gebruik burst-prestaties om
verkeerspieken opvangen
Tot nu toe hebben we gekeken naar de aanhoudende doorvoerlimiet van clusters. Dat is de doorvoer die het cluster voor onbepaalde tijd kan volhouden. Voor streaming-workloads is het belang rijk om de basislijn van de doorvoer vereisten en de grootte dienovereenkomstig te begrijpen. Het Amazon EC2-netwerk, Amazon EBS-netwerk en Amazon EBS-opslagsysteem zijn echter gebaseerd op een kredietsysteem; ze bieden een bepaalde baseline-doorvoer en kunnen gedurende een bepaalde periode naar een hogere doorvoer barsten op basis van de instantiegrootte. Dit vertaalt zich direct in de doorvoer van MSK-clusters. MSK-clusters hebben een aanhoudende doorvoerlimiet en kunnen voor korte perioden naar een hogere doorvoer barsten.
De blauwe lijn in de volgende grafiek toont de totale doorvoer van een m5.large-cluster met drie knooppunten met twee consumentengroepen. Gedurende het hele experiment proberen producenten gegevens zo snel mogelijk het cluster in te sturen. Dus hoewel 80% van de aanhoudende doorvoerlimiet van het cluster rond 58 MB/sec ligt, kan het cluster bijna een half uur lang een doorvoer bereiken die ruim boven de 200 MB/sec ligt.

Zie het als volgt: wanneer u de onderliggende infrastructuur van een cluster configureert, richt u in feite een cluster in met een bepaalde aanhoudende doorvoerlimiet. Gezien de burst-mogelijkheden kan het cluster dan gedurende enige tijd onmiddellijk een veel hogere doorvoer opnemen. Als de gemiddelde doorvoer van uw werkbelasting bijvoorbeeld gewoonlijk rond de 50 MB/sec ligt, kan het m5.large-cluster met drie knooppunten in de voorgaande grafiek gedurende ongeveer een half uur meer dan vier keer de gebruikelijke doorvoer bereiken. En dat is zonder dat er wijzigingen nodig zijn. Deze burst naar een hogere doorvoer is volledig transparant en vereist geen schaalbewerking.
Dit is een zeer krachtige manier om plotselinge doorvoerpieken op te vangen zonder uw cluster te schalen, wat tijd kost om te voltooien. Bovendien helpt de extra capaciteit ook bij het inspelen op operationele gebeurtenissen. Wanneer brokers bijvoorbeeld onderhoud ondergaan of wanneer partities opnieuw in evenwicht moeten worden gebracht binnen het cluster, kunnen ze burst-prestaties gebruiken om brokers sneller online en weer synchroon te krijgen. De burst-capaciteit is ook zeer waardevol om snel te herstellen van operationele gebeurtenissen die een hele Availability Zone beïnvloeden en als reactie op de gebeurtenis veel replicatieverkeer veroorzaken.
Monitoring en continue optimalisatie
Tot nu toe hebben we ons gericht op de initiële grootte van uw cluster. Maar nadat u de juiste initiële clustergrootte hebt bepaald, mogen de inspanningen voor de grootte niet stoppen. Het is belangrijk om uw workload te blijven beoordelen nadat deze in productie is genomen om te weten of de brokergrootte nog steeds geschikt is. Uw aanvankelijke aannames gaan in de praktijk misschien niet meer op, of uw ontwerpdoelen zijn mogelijk gewijzigd. Een van de grote voordelen van cloud computing is immers dat je de onderliggende infrastructuur kunt aanpassen via een API-call.
Zoals we eerder hebben vermeld, moet de doorvoer van uw productieclusters gericht zijn op 80% van hun aanhoudende doorvoerlimiet. Wanneer de onderliggende infra structuur beperking begint te ervaren omdat deze de doorvoer limiet te lang heeft overschreden, moet u het cluster opschalen. In het ideale geval zou u het cluster zelfs schalen voordat het dit punt bereikt. Amazon MSK stelt standaard drie metrische gegevens beschikbaar die aangeven wanneer deze beperking wordt toegepast op de onderliggende infrastructuur:
- BurstBalans – Geeft het resterende saldo van I/O-burst-tegoeden voor EBS-volumes aan. Als deze statistiek begint te dalen, overweeg dan om de grootte van het EBS-volume te vergroten om de prestaties van de volumebasislijn te verbeteren. Als Amazon Cloud Watch deze statistiek niet voor uw cluster rapporteert, zijn uw volumes groter dan 5.3 TB en zijn ze niet langer onderhevig aan burst-tegoeden.
- CPUKredietsaldo – Alleen relevant voor makelaars van de T3-familie en geeft het aantal beschikbare CPU-credits aan. Wanneer deze statistiek begint te dalen, verbruiken makelaars CPU-credits om boven hun CPU-basislijnprestaties uit te komen. Overweeg het type makelaar te wijzigen in de M5-familie.
- VerkeerShaping – Een statistiek op hoog niveau die het aantal pakketten aangeeft dat is gevallen als gevolg van overschrijding van netwerktoewijzingen. Fijnere details zijn beschikbaar wanneer de
PER_BROKERbewakingsniveau is geconfigureerd voor het cluster. Schaal brokers op als deze statistiek wordt verhoogd tijdens uw typische workloads.
In het vorige voorbeeld zagen we de clusterdoorvoer aanzienlijk dalen nadat de netwerktegoeden waren opgebruikt en traffic shaping was toegepast. Zelfs als we de maximale aanhoudende doorvoerlimiet van het cluster niet kenden, geeft de TrafficShaping-metriek in de volgende grafiek duidelijk aan dat we de brokers moeten opschalen om verdere beperking op de Amazon EC2-netwerklaag te voorkomen.

Amazon MSK onthult aanvullende statistieken die u helpen te begrijpen of uw cluster te veel of te weinig is ingericht. Als onderdeel van de grootte-oefening hebt u de aanhoudende doorvoerlimiet van uw cluster bepaald. U kunt alarmen controleren of zelfs maken op de BytesInPerSec, ReplicationBytesInPerSec, BytesOutPerSec en ReplicationBytesInPerSec metrische gegevens van het cluster om een melding te ontvangen wanneer de huidige clustergrootte niet langer optimaal is voor de huidige werkbelastingkenmerken. Op dezelfde manier kunt u de CPUIdle metrische gegevens en alarm wanneer uw cluster te weinig of te veel is ingericht in termen van CPU-gebruik.
Dit zijn alleen de meest relevante metrische gegevens om de grootte van uw cluster te bewaken vanuit een infrastructuurperspectief. U moet ook de status van het cluster en de volledige werk belasting bewaken. Voor meer informatie over het monitoren van clusters, zie: Best Practices.
Een raamwerk voor het testen van Apache Kafka-prestaties
Zoals eerder vermeld, moet u uw eigen tests uitvoeren om te controleren of de prestaties van een cluster overeenkomen met uw specifieke werkbelastingkenmerken. We hebben een gepubliceerd prestatietestraamwerk op GitHub dat helpt bij het automatiseren van de planning en visualisatie van veel tests. We hebben hetzelfde raamwerk gebruikt om de grafieken te genereren die we in dit bericht hebben besproken.
Het raamwerk is gebaseerd op de kafka-producer-perf-test.sh en kafka-consumer-perf-test.sh tools die deel uitmaken van de Apache Kafka-distributie. Het bouwt automatisering en visualisatie rond deze tools.
Voor kleinere makelaars die onderhevig zijn aan bust-mogelijkheden, kunt u het framework ook configureren om eerst gedurende een langere periode overtollige belasting te genereren om netwerk-, opslag- of opslagnetwerktegoeden uit te putten. Nadat de kredietuitputting is voltooid, voert het raamwerk de daadwerkelijke prestatietest uit. Dit is belangrijk om de prestatie van cluster te meten
s die voor onbepaalde tijd kunnen worden volgehouden in plaats van piekprestaties te meten, die slechts enige tijd kunnen worden volgehouden.
Om uw eigen test uit te voeren, raadpleegt u de GitHub-repository, waar u de . kunt vinden AWS Cloud-ontwikkelingskit (AWS CDK)-sjabloon en aanvullende documentatie over het configureren, uitvoeren en visualiseren van de resultaten van prestatietests.
Conclusie
We hebben verschillende factoren besproken die bijdragen aan de prestaties van Apache Kafka vanuit een infrastructuurperspectief. Hoewel we ons hebben gericht op Apache Kafka, hebben we ook geleerd over Amazon EC2-netwerken en Amazon EBS-prestatiekenmerken.
Om de juiste grootte voor uw clusters te vinden, werkt u achteruit vanaf uw gebruiksscenario om de vereisten voor doorvoer, beschikbaarheid, duurzaamheid en latentie te bepalen.
Begin met een initiële grootte van uw cluster op basis van uw vereisten voor doorvoer, opslag en duurzaamheid. Schaal uit of gebruik ingerichte doorvoer om de schrijf doorvoer van het cluster te vergroten. Schaal op om het aantal consumenten dat van het cluster kan consumeren te vergroten. Schaal op om in-transit- of in-cluster-codering te vergemakkelijken en consumenten die niet lezen, vormen het topje van de stream.
Controleer deze initiële clustergrootte door prestatietests uit te voeren en stem vervolgens de clustergrootte en configuratie af op andere vereisten, zoals latentie. Voeg extra capaciteit toe voor productieclusters zodat ze het onderhoud of verlies van een makelaar kunnen weerstaan. Afhankelijk van uw werklast, kunt u zelfs overwegen een gebeurtenis te weerstaan die van invloed is op een hele beschikbaarheidszone. Blijf ten slotte de metrische gegevens van uw cluster in de gaten houden en wijzig het formaat van het cluster voor het geval uw aanvankelijke aannames niet langer gelden.
Over de auteur
 Steffen Hausman is Principal Streaming Architect bij AWS. Hij werkt samen met klanten over de hele wereld om streaming-architecturen te ontwerpen en te bouwen, zodat ze waarde kunnen halen uit het analyseren van hun streaminggegevens. Hij is gepromoveerd in computerwetenschappen aan de universiteit van München en in zijn vrije tijd probeert hij zijn dochters de techniek in te lokken met schattige stickers die hij op conferenties verzamelt.
Steffen Hausman is Principal Streaming Architect bij AWS. Hij werkt samen met klanten over de hele wereld om streaming-architecturen te ontwerpen en te bouwen, zodat ze waarde kunnen halen uit het analyseren van hun streaminggegevens. Hij is gepromoveerd in computerwetenschappen aan de universiteit van München en in zijn vrije tijd probeert hij zijn dochters de techniek in te lokken met schattige stickers die hij op conferenties verzamelt.
- Coinsmart. Europa's beste Bitcoin- en crypto-uitwisseling.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. GRATIS TOEGANG.
- CryptoHawk. Altcoin-radar. Gratis proefversie.
- Bron: https://aws.amazon.com/blogs/big-data/best-practices-for-right-sizing-your-apache-kafka-clusters-to-optimize-performance-and-cost/

