CCC ondersteunde drie wetenschappelijke sessies op de jaarlijkse AAAS-conferentie van dit jaar, en voor het geval u er niet persoonlijk bij kon zijn, zullen we elke sessie samenvatten. Deze week vatten we de hoogtepunten van de sessie samen: “Generatieve AI in de wetenschap: beloften en valkuilen.” In deel drie vatten we de presentatie samen van Dr. Duncan Watson-Parris, assistent-professor bij Scripps Institution of Oceanography en het Halıcıoğlu Data Science Institute aan UC San Diego.
Na de presentatie van Dr. Markus Buehler over generatieve AI in de mechanobiologie, richtte Dr. Watson-Parris de aandacht van het publiek op generatieve AI-toepassingen in de klimaatwetenschappen. Hij begon met het schetsen van het verschil tussen klimaat en weer. Weer verwijst naar atmosferische omstandigheden op korte termijn, terwijl klimaat atmosferische omstandigheden op lange termijn beschrijft. Kortom: het klimaat is wat je verwacht, het weer is wat je krijgt. “Een van de grootste problemen met klimaatmodellering,” zegt Watson-Parris, “is dat we alleen recente gegevens hebben van toen we begonnen met klimaatmetingen.” Het creëren van nauwkeurige modellen die toekomstige klimaatpatronen en weersgebeurtenissen voorspellen is bijzonder moeilijk, omdat we de resultaten in de echte wereld pas kunnen verifiëren als deze gebeurtenissen plaatsvinden. Voor voorspellingen op de kortere termijn, zoals weersvoorspellingen voor de komende drie dagen, kunnen we de nauwkeurigheid van deze modellen echter eenvoudig verifiëren.
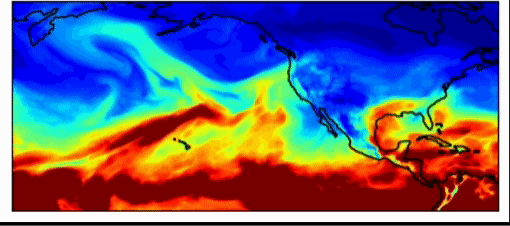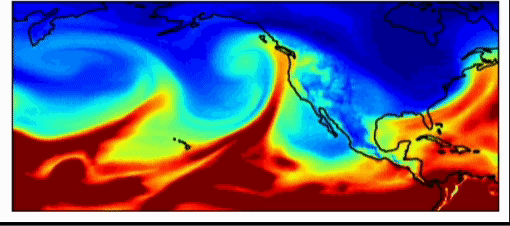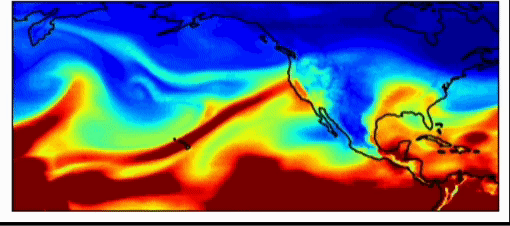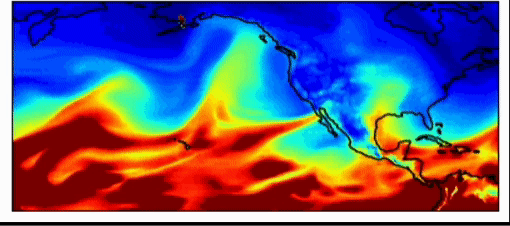
Weermodellen voor de industrie zijn al zeer nauwkeurig. Deze modellen presteren met evenveel nauwkeurigheid als de nationale weersvoorspellingsmodellen voor kortetermijnschattingen (voorspellingen van ongeveer 3-7 dagen). Een van de grootste problemen bij weersvoorspellingen is echter het bemonsteren van de initiële weersomstandigheden. Zoals Dr. Willett in haar lezing opmerkte, kunnen heel licht verschillende startomstandigheden enorm verschillende resultaten opleveren. Dit geldt ook voor weersimulaties, zegt dr. Watson-Parris, die in de praktijk belangrijke gevolgen kunnen hebben. Het weerpatroon, hieronder weergegeven, introduceerde in 2017 een atmosferische rivier in de regio Californië en Oregon, die zoveel regen genereerde dat de Oroville-dam barstte en miljoenen dollars aan schade veroorzaakte. Deze gebeurtenis was moeilijk te voorspellen, omdat het een extreme gebeurtenis was, een uitbijter. Met machine learning-voorspellingen kunnen we veel grotere hoeveelheden monsters nemen om extremere weersomstandigheden te voorspellen, waardoor we ons er beter op kunnen voorbereiden.
Wanneer onderzoekers nadenken over het klimaatsysteem, legt Dr. Watson-Parris uit, kijkend over grotere schaal en over langere tijdsperioden, zien ze uiteindelijk hoe gemiddelde wolken er over seizoenen uitzien en kunnen ze naar statistieken van systemen kijken. Deze statistieken worden bepaald door de randvoorwaarden van het aardsysteem: de hoeveelheid energie die binnenkomt en uitgaat. Wanneer het probleem op deze manier wordt ingekaderd, kunnen we gemiddeld voorspellen waar de wolken zich gedurende de seizoenen zullen bevinden, en er zijn mogelijkheden om machinaal leren te gebruiken om deze verschillende voorspellingen te verbeteren en te onderzoeken. Een van de taken van klimaatmodellen is het maken van projecties – om te begrijpen hoe het klimaat in de toekomst zal veranderen onder verschillende menselijke invloeden. Deze zijn ontworpen om mogelijke toekomsten te verkennen. Om dit te doen, genereren onderzoekers plausibelere sociaal-economische routes voor hoe de samenleving zich in de toekomst zou kunnen gedragen.
Hieronder ziet u een afbeelding die Dr. Watson-Parris heeft weergegeven, die enkele mogelijke trajecten weergeeft die de samenleving in de toekomst kan volgen en waarmee in deze klimaatmodellen rekening moet worden gehouden. Aan de linkerkant staat een duurzaamheidsmodel dat tegen het einde van de eeuw de klimaatforcering – de hoeveelheid opwarming die de mens aan het systeem oplegt – op een lager niveau houdt. Aan de andere kant is het ontwikkelingsscenario voor fossiele brandstoffen aan de rechterkant een soort worst case scenario. Dit is een zeer schaarse greep uit de manieren waarop de mensheid het jaar 2100 kan bereiken.

In de praktijk trainen onderzoekers bij het bepalen van het klimaatscenario en het communiceren met beleidsmakers die de impact van hun beslissingen willen begrijpen, eenvoudige emulators van klimaatmodellen. Deze emulators houden rekening met projecties voor verschillende emissies, zoals CO2 en methaan, en kortstondige klimaatkrachten zoals zwarte koolstof en sulfaat, en onderzoekers kunnen de reactie van deze klimaatmodellen emuleren op basis van trainingsgegevens. “We kunnen min of meer complexe modellen inpassen van de mondiale reactie van de mondiale gemiddelde temperatuur op deze emissies”, zegt Watson-Parris. “Deze modellen werken redelijk goed omdat wetenschappers een goed inzicht hebben in de onderliggende fysica. Maar niemand leeft in de wereldgemiddelde temperatuur, en we zullen al deze veranderingen anders voelen. Om regionale veranderingen te begrijpen, nemen wetenschappers dus het mondiale gemiddelde en schalen de patroonverandering naar regionale situaties. Deze modellen werken goed, maar verliezen de impact die deze emissies lokaal kunnen hebben. Vooral zwarte koolstof wordt bijvoorbeeld grotendeels in Zuid-Azië uitgestoten, en de gevolgen daarvan zullen vooral in Zuid-Azië voelbaar zijn.”
Als dit probleem wordt ingekaderd in een regressiesetting, zien we dat er mogelijk kansen zijn voor machinaal leren. "Als onderdeel van Klimaatbank In het artikel dat we een jaar geleden schreven,” zegt dr. Watson-Parris, “zeiden we dat we de uitstoot en concentraties van broeikasgassen en kaarten van de uitstoot van sulfaat en zwarte koolstof direct naar de klimaatmodellen kunnen overbrengen om voorspellingen te kunnen zien. We hoeven ons ook niet te beperken tot de temperatuur, we kunnen rekening houden met neerslag en andere variabelen. Op deze manier kunnen we emulators bouwen van de klimaatmodellen die voorspellen wat het klimaatmodel zal produceren voor een bepaalde hoeveelheid uitgestoten CO2, en ons in staat stellen deze modellen op een laptop te draaien in plaats van op een supercomputer.”
Dr. Watson-Parris liet vervolgens een beeld zien van drie verschillende realisaties van de mondiale temperatuurrespons in een terughoudend scenario voor het klimaatbeleid op de weg. De eerste twee kolommen zijn machine learning-emulators, en de derde is een klimaatmodelsimulatie met volledige complexiteit die een week duurde op een supercomputer. “De resultaten van elk van deze modellen zijn bijna niet van elkaar te onderscheiden”, zegt Watson-Parris. Deze klimaatmodellen zijn zeer goed in het nauwkeurig voorspellen van dit patroon van opwarming. Ze zijn zelfs goed in het voorspellen van neerslagpatronen. Deze modellen verbeteren de toegankelijkheid en participatie, en stellen kleinere organisaties en beleidsmakers in staat deel te nemen aan klimaatvoorspelling en -verkenning zonder dat daarvoor enorme hoeveelheden financiering of infrastructuur nodig zijn.

Deze modellen zijn geen generatieve AI, het zijn directe regressiemodellen, en een bepaalde invoer zal altijd hetzelfde resultaat opleveren. Tegenwoordig worden echter mogelijkheden onderzocht om generatieve en diffusiemodellen te gebruiken om de probabilistische verdelingen van het weer te gebruiken om weerstaten te genereren. Onderzoekers gebruiken deze modellen om het klimaat en de weerpatronen van de toekomst te voorspellen, gegeven verschillende klimaatforcerende scenario's. “Er blijven problemen bestaan”, zegt Dr. Watson-Parris, “omdat er nog steeds geen 'grondwaarheid' is om voorspellingen te verifiëren, en we nog steeds moeten uitzoeken hoe we statistische modellen kunnen kalibreren, maar dit is de toekomst van klimaatvoorspellingen, en ik Ik ben optimistisch dat deze instrumenten de toegankelijkheid, participatie en begrip van de toekomst van de klimaatwetenschap zullen vergroten.”
Bedankt voor het lezen, en houd ons morgen in de gaten voor het laatste bericht van deze blogreeks, waarin het vraag- en antwoordgedeelte van dit panel wordt samengevat.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://feeds.feedblitz.com/~/874057523/0/cccblog~CCC-AAAS-Generative-AI-in-Science-Promises-and-Pitfalls-Recap-%e2%80%93-Part-Three/

