Op het gebied van gegevensanalyse hebben organisaties vaak te maken met veel tabellen in verschillende databases en bestandsindelingen om gegevens voor verschillende bedrijfsfuncties te bewaren. Zakelijke behoeften sturen vaak de tabelstructuur, zoals schema-evolutie (toevoegen van nieuwe kolommen, verwijderen van bestaande kolommen, bijwerken van kolomnamen, enzovoort) voor sommige van deze tabellen in één bedrijfsfunctie waarvoor andere bedrijfsfuncties nodig zijn om dezelfde te repliceren . Dit bericht richt zich op dergelijke schemawijzigingen in op bestanden gebaseerde tabellen en laat zien hoe de schema-evolutie van gestructureerde gegevens van tabelindelingen in databases automatisch kan worden gerepliceerd naar de tabellen die zijn opgeslagen als bestanden op een kosteneffectieve manier.
AWS lijm is een serverloze data-integratieservice die het gemakkelijk maakt om data te ontdekken, voor te bereiden en te combineren voor analyse, machine learning (ML) en applicatie-ontwikkeling. In dit bericht laten we zien hoe te gebruiken Apache Hudi, een zelfsturende databaselaag op op bestanden gebaseerde datameren, in AWS Glue om automatisch gegevens in relationele vorm weer te geven en hun schema-evolutie op schaal te beheren met behulp van Amazon eenvoudige opslagservice (Amazone S3), AWS-databasemigratieservice (AWS-DMS), AWS Lambda, AWS lijm, Amazon DynamoDB, Amazon Aurora en Amazone Athene om schema-evolutie automatisch te identificeren en toe te passen om de gegevensbelasting op petabyte-schaal te beheren.
Apache Hudi ondersteunt ACID-transacties en CRUD-bewerkingen op een datameer. Dit legt de basis van een data lake-architectuur door transactieondersteuning en schema-evolutie en -beheer mogelijk te maken, opslag los te koppelen van rekenkracht en ondersteuning te bieden voor toegankelijkheid via BI-tools (Business Intelligence). In dit bericht implementeren we een architectuur om een transactioneel datameer te bouwen op basis van de eerder genoemde Hudi-functies.
Overzicht oplossingen
Dit bericht gaat uit van een scenario waarin meerdere tabellen aanwezig zijn in een brondatabase en we willen eventuele schemawijzigingen in een van die tabellen repliceren in Apache Hudi-tabellen in het datameer. Het gebruikt de native ondersteuning voor Apache Hudi op AWS Glue voor Apache Spark.
In dit bericht wordt de schema-evolutie van brontabellen in de Aurora-database vastgelegd via het AWS DMS incrementeel laden of wijzigen van gegevensverzameling (CDC) mechanisme, en dezelfde schema-evolutie wordt gerepliceerd in Apache Hudi-tabellen die zijn opgeslagen in Amazon S3. Apache Hudi-tabellen worden ontdekt door de AWS Glue Data Catalog en opgevraagd door Athena. Een AWS Glue-taak, ondersteund door een orkestratiepijplijn met behulp van Lambda en een DynamoDB-tabel, zorgt voor de geautomatiseerde replicatie van schema-evolutie in de Apache Hudi-tabellen.
We gebruiken Aurora als voorbeeldgegevensbron, maar elke gegevensbron die CRUD-bewerkingen (Creëren, lezen, bijwerken en verwijderen) ondersteunt, kan Aurora in uw use-case vervangen.
Het volgende diagram illustreert onze oplossingsarchitectuur.

De stroom van de oplossing is als volgt:
- Aurora, als voorbeeldgegevensbron, bevat een RDBMS-tabel met meerdere rijen, en AWS DMS laadt die gegevens volledig in een S3-bucket (die we de onbewerkte bucket noemen). We verwachten dat u meerdere brontabellen heeft, maar voor demonstratiedoeleinden gebruiken we in dit bericht slechts één brontabel.
- We activeren een Lambda-functie met de naam van de brontabel als een gebeurtenis, zodat de overeenkomstige parameters van de brontabel worden gelezen uit DynamoDB. Om deze operatie voor specifieke tijdsintervallen te plannen, hebben we rooster Amazon EventBridge om de Lambda te activeren met de tabelnaam als parameter.
- Er zijn veel tabellen in de brondatabase en we willen één AWS Glue-taak uitvoeren voor elke brontabel om de bewerkingen te vereenvoudigen. Omdat we elke AWS Glue-taak gebruiken om elke Apache Hudi-tabel bij te werken, gebruikt dit bericht een DynamoDB-tabel om de configuratieparameters vast te houden die door elke AWS Glue-taak voor elke Apache Hudi-tabel worden gebruikt. De DynamoDB-tabel bevat elke Apache Hudi-tabelnaam, bijbehorende AWS Glue-taaknaam, AWS Glue-taakstatus, laadstatus (volledig of delta), partitiesleutel, recordsleutel en schema om door te geven aan de AWS Glue Job van de overeenkomstige tabel. De waarden in de DynamoDB-tabel zijn statische waarden.
- Om elke AWS Glue-taak (10 G.1X DPU's) parallel te activeren om een Apache Hudi-specifieke code uit te voeren om gegevens in de overeenkomstige Hudi-tabellen in te voegen, geeft Lambda elke Apache Hudi-tabelspecifieke parameters die zijn gelezen van DynamoDB door aan elke AWS Glue-taak. De brongegevens komen uit tabellen in de Aurora-brondatabase via AWS DMS met volledige belasting en incrementele belasting of CDC.
Creëer resources met AWS CloudFormation
Wij bieden een AWS CloudFormatie sjabloon om de volgende bronnen te maken:
- Lambda en DynamoDB als orkestrators voor het beheer van de gegevensbelasting
- S3-buckets voor de onbewerkte, verfijnde zone en activa voor het bewaren van code voor schema-evolutie
- Een AWS Glue-taak om de Hudi-tabellen bij te werken en schema-evolutie uit te voeren, zowel voorwaarts als achterwaarts compatibel
De Aurora-tabel en de AWS DMS-replicatie-instantie worden niet geleverd via deze stapel. Raadpleeg voor instructies voor het instellen van Aurora Een Amazon Aurora DB-cluster maken.
Start de volgende stapel en geef uw stapelnaam op.
eu-west-1 |
Schema evolutie
Raadpleeg voor toegang tot uw Aurora-database Hoe maak ik verbinding met mijn Amazon RDS voor MySQL-instantie met behulp van MySQL Workbench. Voer vervolgens de volgende stappen uit:
- Maak een tabel met de naam object volgens de query's in de Aurora-database en wijzig het schema zodat we kunnen zien dat de evolutie van het schema wordt weerspiegeld op data lake-niveau:
Nadat u de stapels hebt gemaakt, zijn enkele handmatige stappen nodig om de oplossing end-to-end voor te bereiden.
- Maak een AWS DMS instantie, AWS-DMS eindpuntenen AWS DMS taak met de volgende configuraties:
- Voeg dataFormat toe als Parquet in het doeleindpunt.
- Wijs het doeleindpunt van AWS DMS naar de onbewerkte bucket, die is opgemaakt als
raw-bucket-<account_number>-<region_name>, en de mapnaam moet POC zijn.
- Start de AWS DMS-taak.
- Maak een testgebeurtenis aan in het
HudiLambdaLambda-functie met de inhoud van de gebeurtenis JSON asPOC.dbEn sla het op. - Voer de Lambda-functie uit.
In dit bericht wordt de schema-evolutie weerspiegeld door Hudi Hive-synchronisatie in AWS-lijm. Query's wijzig je niet apart in de data lake.
Nu voltooien we de volgende stappen om het schema bij de bron te wijzigen. Activeer na elke stap de Lambda-functie om een bestand te genereren in het POC/db/object map in de raw-bucket. AWS DMS pikt vrijwel onmiddellijk de schemawijzigingen op en rapporteert aan de onbewerkte bucket.
- Voeg een kolom toe met de naam
test_columnnaar de brontabelobjectin uw Aurora-database:
- Hernoem de kolom
new_field_1naarnew_field_2in het brontabelobject:
De kolom new_field_1 zal naar verwachting in de Hudi-tabel blijven, maar zonder dat er meer nieuwe waarden in worden ingevuld.
- Verwijder de kolom
new_field_2van het brontabelobject:
Vergelijkbaar met de vorige bewerking, de column new_field_2 zal naar verwachting in de Hudi-tabel blijven, maar zonder dat er meer nieuwe waarden in worden ingevuld.
Als u al hebt AWS Lake-formatie gegevenstoestemmingen ingesteld in uw account, kunt u problemen met toestemmingen tegenkomen. Geef in dat geval volledige toestemming (Super) aan de standaarddatabase (voordat de Lambda-functie wordt geactiveerd) en alle tabellen in de POC.db database (nadat het laden is voltooid).
Bekijk de resultaten
Wanneer de bovengenoemde uitvoering plaatsvindt na schemawijzigingen, worden de volgende resultaten gegenereerd in de verfijnde bucket. We kunnen de Apache Hudi-tabellen met hun inhoud bekijken in Athena. Raadpleeg voor het instellen van Athena Aan de slag.
De tabel en de database zijn beschikbaar in de AWS Glue Data Catalog en klaar om door het schema te bladeren.
Vóór de schemawijziging zien de Athena-resultaten eruit als de volgende schermafbeelding.

Nadat u de kolom hebt toegevoegd test_column en voeg een waarde in de test_column veld in de objecttabel in de Aurora-database, de nieuwe kolom (test_column) wordt weerspiegeld in de bijbehorende Apache Hudi-tabel in het datameer.
De volgende schermafbeelding toont de resultaten in Athena.

Nadat u de naam van de kolom hebt gewijzigd new_field_1 naar new_field_2 en voeg een waarde in de new_field_2 veld in de objecttabel, de hernoemde kolom (new_field_2) wordt weerspiegeld in de bijbehorende Apache Hudi-tabel in het datameer, en new_field_1 blijft in het schema en er wordt geen nieuwe waarde in de kolom ingevuld.
De volgende schermafbeelding toont de resultaten in Athena.
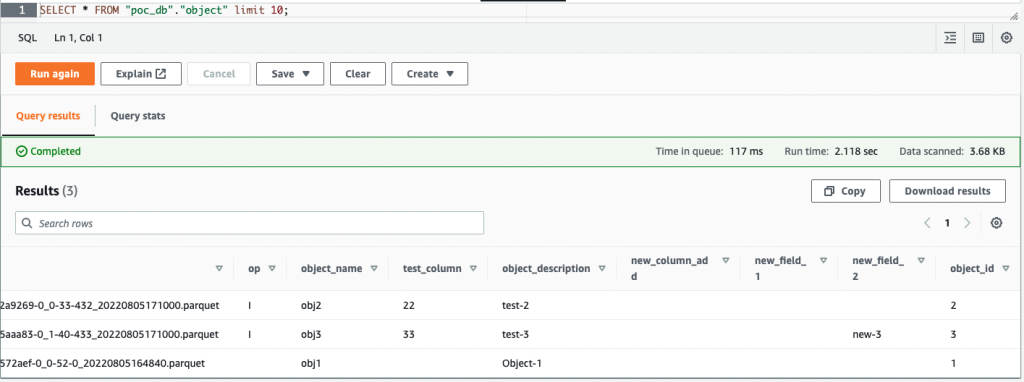
Nadat u de kolom hebt verwijderd new_field_2 in de objecttabel en voeg waarden in of werk deze bij onder kolommen in de objecttabel, de verwijderde kolom (new_field_2) blijft in het overeenkomstige Apache Hudi-tabelschema en er wordt geen nieuwe waarde in de kolom ingevuld.
De volgende schermafbeelding toont de resultaten in Athena.

Opruimen
Wanneer u klaar bent met deze oplossing, verwijdert u de voorbeeldgegevens in de onbewerkte en verfijnde S3-buckets en verwijdert u de buckets.
Verwijder ook de CloudFormation-stack om alle serviceresources te verwijderen die in deze oplossing worden gebruikt.
Conclusie
Dit bericht liet zien hoe schema-evolutie kan worden geïmplementeerd met een open-sourceoplossing met behulp van Apache Hudi in een AWS-omgeving met een orkestratiepijplijn.
Je kunt de verschillende ontdekken configuraties van AWS Glue om de taakstructuren van AWS Glue te wijzigen en te implementeren voor uw data-analyse en andere use cases.
Over de auteurs
 Subro Bose is een Senior Data Architect in Emergent Technologies en Intelligence Platform bij Amazon. Hij houdt ervan om wetenschappelijke problemen op te lossen met opkomende technologieën zoals AI/ML, big data, quantum en meer om bedrijven in verschillende branches te helpen slagen op hun innovatietraject. In zijn vrije tijd speelt hij graag tafeltennis, leert hij theorieën over milieueconomie en verkent hij de beste muffins in de stad.
Subro Bose is een Senior Data Architect in Emergent Technologies en Intelligence Platform bij Amazon. Hij houdt ervan om wetenschappelijke problemen op te lossen met opkomende technologieën zoals AI/ML, big data, quantum en meer om bedrijven in verschillende branches te helpen slagen op hun innovatietraject. In zijn vrije tijd speelt hij graag tafeltennis, leert hij theorieën over milieueconomie en verkent hij de beste muffins in de stad.
 Ketan Karalkar is een Big Data Solutions Consultant bij AWS. Hij heeft bijna 2 decennia ervaring met het helpen van klanten bij het ontwerpen en bouwen van data-analyse en database-oplossingen. Hij gelooft in het gebruik van technologie als hulpmiddel om echte zakelijke problemen op te lossen.
Ketan Karalkar is een Big Data Solutions Consultant bij AWS. Hij heeft bijna 2 decennia ervaring met het helpen van klanten bij het ontwerpen en bouwen van data-analyse en database-oplossingen. Hij gelooft in het gebruik van technologie als hulpmiddel om echte zakelijke problemen op te lossen.
 Eva Fang is een Data Scientist binnen Professional Services in AWS. Ze heeft een passie voor het gebruik van technologie om klanten waarde te bieden en zakelijke resultaten te behalen. Ze is gevestigd in Londen, in haar vrije tijd kijkt ze graag naar films en musicals.
Eva Fang is een Data Scientist binnen Professional Services in AWS. Ze heeft een passie voor het gebruik van technologie om klanten waarde te bieden en zakelijke resultaten te behalen. Ze is gevestigd in Londen, in haar vrije tijd kijkt ze graag naar films en musicals.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/automate-schema-evolution-at-scale-with-apache-hudi-in-aws-glue/

