Veel ondernemingen migreren hun lokale datastores naar de AWS Cloud. Tijdens de datamigratie is een belangrijke vereiste het valideren van alle gegevens die van bron naar doel zijn verplaatst. Deze gegevensvalidatie is een cruciale stap en als deze niet correct wordt uitgevoerd, kan dit resulteren in het mislukken van het hele project. Het ontwikkelen van aangepaste oplossingen om de nauwkeurigheid van de migratie te bepalen door de gegevens tussen de bron en het doel te vergelijken, kan echter vaak tijdrovend zijn.
In dit bericht doorlopen we een stapsgewijs proces om grote datasets na de migratie te valideren met behulp van een op configuratie gebaseerde tool die gebruikmaakt van Amazon EMR en de open source-bibliotheek van Apache Griffin. Griffin is een open source datakwaliteitsoplossing voor big data, die zowel batch- als streamingmodus ondersteunt.
In het huidige datagestuurde landschap, waar organisaties te maken hebben met petabytes aan data, is de behoefte aan geautomatiseerde datavalidatieframeworks steeds belangrijker geworden. Handmatige validatieprocessen zijn niet alleen tijdrovend, maar ook gevoelig voor fouten, vooral als het gaat om grote hoeveelheden gegevens. Geautomatiseerde datavalidatieframeworks bieden een gestroomlijnde oplossing door grote datasets efficiënt te vergelijken, discrepanties te identificeren en de nauwkeurigheid van data op schaal te garanderen. Met dergelijke raamwerken kunnen organisaties waardevolle tijd en middelen besparen en tegelijkertijd het vertrouwen in de integriteit van hun gegevens behouden, waardoor geïnformeerde besluitvorming mogelijk wordt en de algehele operationele efficiëntie wordt verbeterd.
De volgende zijn opvallende kenmerken van dit raamwerk:
- Maakt gebruik van een configuratiegestuurd raamwerk
- Biedt plug-and-play-functionaliteit voor naadloze integratie
- Voert tellingen uit om eventuele verschillen te identificeren
- Implementeert robuuste gegevensvalidatieprocedures
- Garandeert de kwaliteit van de gegevens door middel van systematische controles
- Biedt toegang tot een bestand met niet-overeenkomende records voor diepgaande analyse
- Genereert uitgebreide rapporten voor inzichten en trackingdoeleinden
Overzicht oplossingen
Deze oplossing maakt gebruik van de volgende services:
- Amazon eenvoudige opslagservice (Amazon S3) of Hadoop Distributed File System (HDFS) als bron en doel.
- Amazon EMR om het PySpark-script uit te voeren. We gebruiken een Python-wrapper bovenop Griffin om gegevens te valideren tussen Hadoop-tabellen die zijn gemaakt via HDFS of Amazon S3.
- AWS lijm om de technische tabel te catalogiseren, waarin de resultaten van de Griffin-taak worden opgeslagen.
- Amazone Athene om de uitvoertabel te doorzoeken om de resultaten te verifiëren.
We gebruiken tabellen die het aantal voor elke bron- en doeltabel opslaan en maken ook bestanden die het verschil tussen records tussen bron en doel laten zien.
Het volgende diagram illustreert de oplossingsarchitectuur.
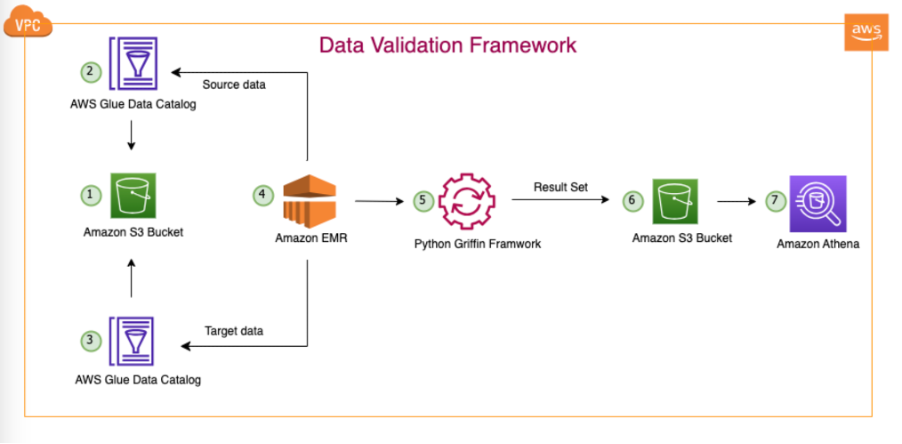
In de afgebeelde architectuur en ons typische data lake-gebruiksscenario bevinden onze gegevens zich in Amazon S3 of worden ze van lokaal naar Amazon S3 gemigreerd met behulp van replicatietools zoals AWS-gegevenssynchronisatie or AWS-databasemigratieservice (AWS-DMS). Hoewel deze oplossing is ontworpen om naadloos samen te werken met zowel Hive Metastore als de AWS Glue Data Catalog, gebruiken we de Data Catalog als voorbeeld in dit bericht.
Dit raamwerk werkt binnen Amazon EMR en voert dagelijks automatisch geplande taken uit, volgens de gedefinieerde frequentie. Het genereert en publiceert rapporten in Amazon S3, die vervolgens toegankelijk zijn via Athena. Een opvallend kenmerk van dit raamwerk is de mogelijkheid om niet-overeenkomende aantallen en gegevensverschillen te detecteren, naast het genereren van een bestand in Amazon S3 met volledige records die niet overeenkomen, wat verdere analyse mogelijk maakt.
In dit voorbeeld gebruiken we drie tabellen in een on-premises database om te valideren tussen bron en doel: balance_sheet, covid en survery_financial_report.
Voorwaarden
Voordat u begint, moet u ervoor zorgen dat u aan de volgende voorwaarden voldoet:
Implementeer de oplossing
Om het u gemakkelijk te maken om aan de slag te gaan, hebben we een CloudFormation-sjabloon gemaakt die de oplossing automatisch voor u configureert en implementeert. Voer de volgende stappen uit:
- Maak een S3-bucket aan in uw AWS-account genaamd
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}(geef uw AWS-account-ID en AWS-regio op). - Pak het volgende uit filet naar uw lokale systeem.
- Nadat u het bestand naar uw lokale systeem hebt uitgepakt, verandert u naar degene die u in uw account heeft aangemaakt (
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}) in de volgende bestanden:bootstrap-bdb-3070-datavalidation.shValidation_Metrics_Athena_tables.hqldatavalidation/totalcount/totalcount_input.txtdatavalidation/accuracy/accuracy_input.txt
- Upload alle mappen en bestanden in uw lokale map naar uw S3-bucket:
- Voer het volgende uit CloudFormation-sjabloon in uw account.
De CloudFormation-sjabloon maakt een database met de naam griffin_datavalidation_blog en een AWS Glue-crawler gebeld griffin_data_validation_blog bovenop de gegevensmap in het .zip-bestand.
- Kies Volgende.
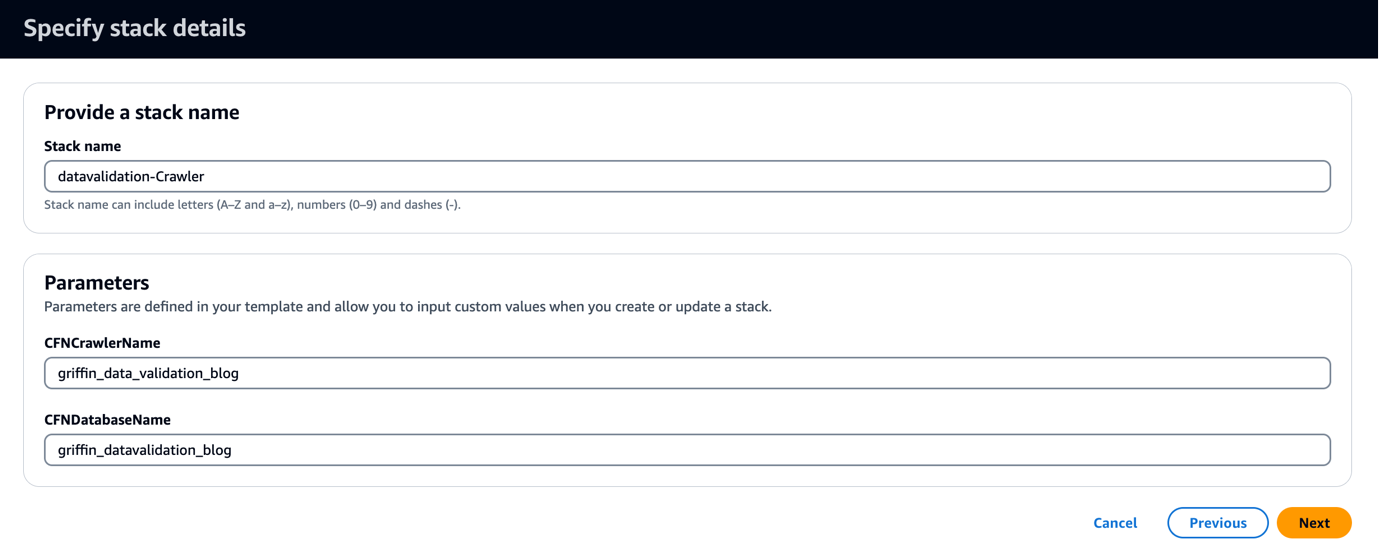
- Kies Volgende weer.
- Op de Beoordeling 4040 hand404040 details hand4040 hand 3 details hand40 hand40 hand details details details details hand 3 Ik erken dat AWS CloudFormation IAM-bronnen met aangepaste namen kan maken.
- Kies Maak een stapel.
Je kunt bekijk de stapeluitgangen op de AWS-beheerconsole of door de volgende AWS CLI-opdracht te gebruiken:
- Voer de AWS Glue-crawler uit en controleer of er zes tabellen zijn gemaakt in de gegevenscatalogus.
- Voer het volgende uit CloudFormation-sjabloon in uw account.
Met deze sjabloon wordt een EMR-cluster gemaakt met een bootstrap-script om Griffin-gerelateerde JAR's en artefacten te kopiëren. Het voert ook drie EMR-stappen uit:
- Maak twee Athena-tabellen en twee Athena-weergaven om de validatiematrix te bekijken die door het Griffin-framework is geproduceerd
- Voer tellingvalidatie uit voor alle drie de tabellen om de bron- en doeltabel te vergelijken
- Voer validaties op record- en kolomniveau uit voor alle drie de tabellen om de bron- en doeltabel te vergelijken
- Voor SubnetID, voer uw subnet-ID in.
- Kies Volgende.
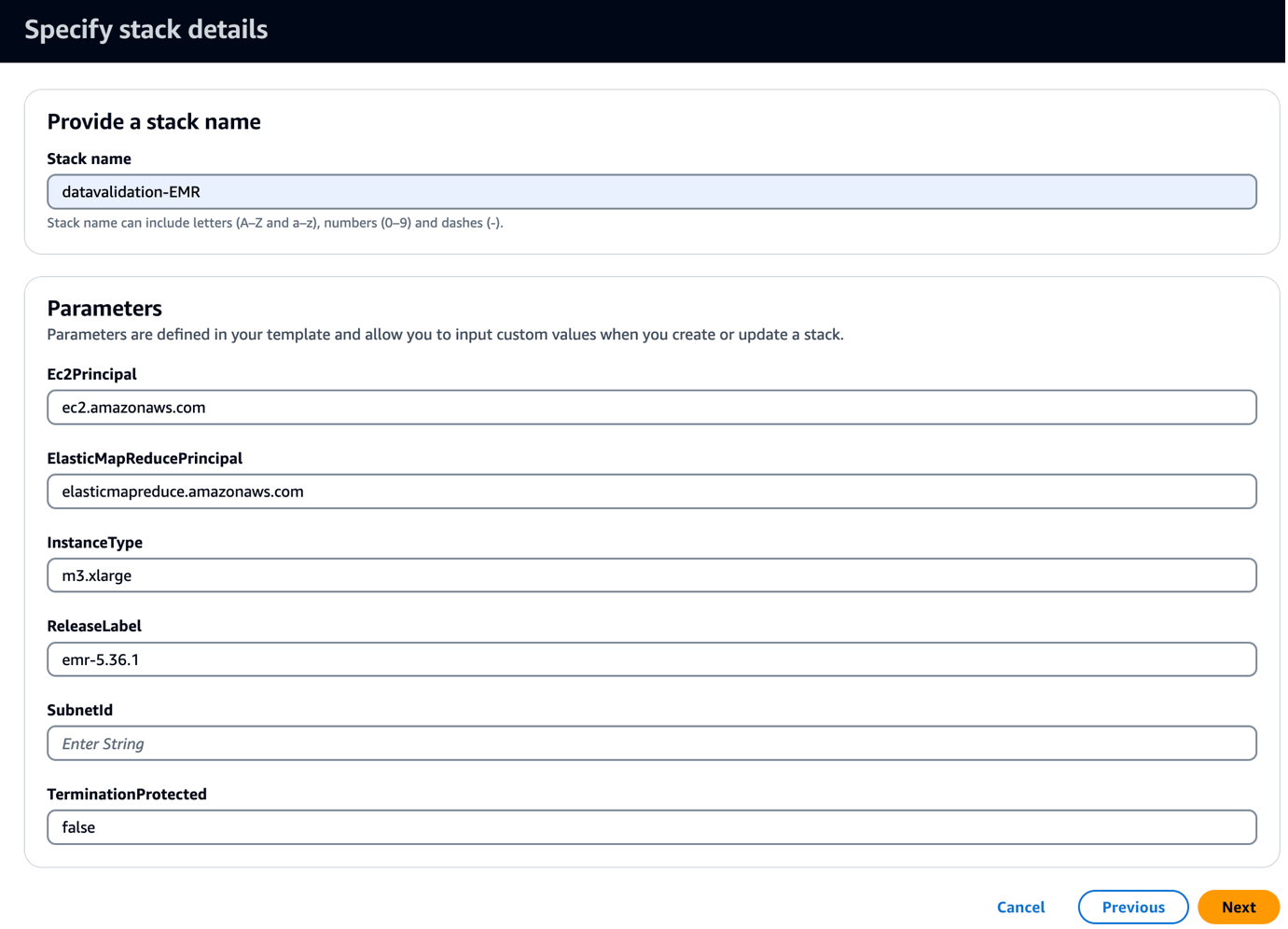
- Kies Volgende weer.
- Op de Beoordeling 4040 hand404040 details hand4040 hand 3 details hand40 hand40 hand details details details details hand 3 Ik erken dat AWS CloudFormation IAM-bronnen met aangepaste namen kan maken.
- Kies Maak een stapel.
U kunt de stapeluitvoer bekijken op de console of door de volgende AWS CLI-opdracht te gebruiken:
Het duurt ongeveer 5 minuten voordat de implementatie is voltooid. Wanneer de stapel compleet is, zou je de EMRCluster bron gelanceerd en beschikbaar in uw account.
Wanneer het EMR-cluster wordt gelanceerd, worden de volgende stappen uitgevoerd als onderdeel van de lancering na het cluster:
- Bootstrap-actie – Het installeert het Griffin JAR-bestand en de mappen voor dit raamwerk. Er worden ook voorbeeldgegevensbestanden gedownload voor gebruik in de volgende stap.
- Athena_Tabel_Creatie – Het maakt tabellen in Athena om de resultaatrapporten te lezen.
- Aantal_validatie – Het voert de taak uit om het aantal gegevens tussen bron- en doelgegevens uit de Data Catalog-tabel te vergelijken en slaat de resultaten op in een S3-bucket, die wordt gelezen via een Athena-tabel.
- Nauwkeurigheid – Het voert de taak uit om de gegevensrijen tussen de bron- en doelgegevens uit de Data Catalog-tabel te vergelijken en de resultaten op te slaan in een S3-bucket, die via de Athena-tabel wordt gelezen.
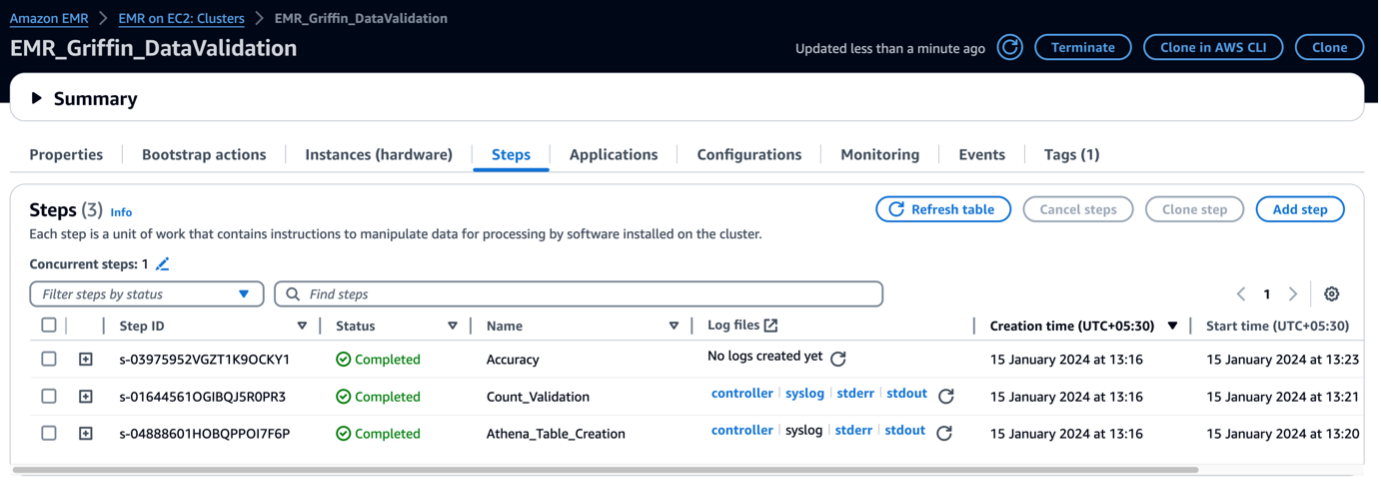
Wanneer de EMR-stappen zijn voltooid, is uw tabelvergelijking voltooid en kunt u deze automatisch bekijken in Athena. Er is geen handmatige tussenkomst nodig voor validatie.
Valideer gegevens met Python Griffin
Wanneer uw EMR-cluster gereed is en alle taken zijn voltooid, betekent dit dat de tellingsvalidatie en gegevensvalidatie zijn voltooid. De resultaten zijn opgeslagen in Amazon S3 en daarbovenop is de Athena-tabel al aangemaakt. U kunt de Athena-tabellen doorzoeken om de resultaten te bekijken, zoals weergegeven in de volgende schermafbeelding.
De volgende schermafbeelding toont de telresultaten voor alle tabellen.
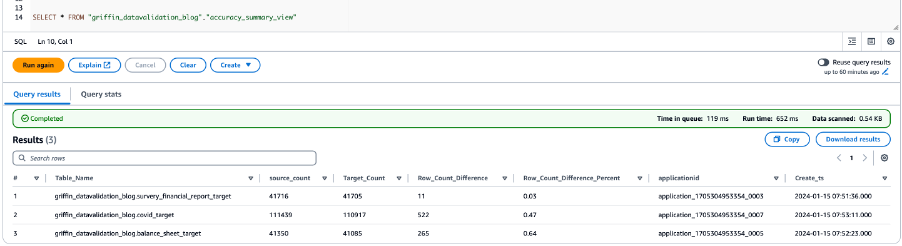
De volgende schermafbeelding toont de resultaten van de gegevensnauwkeurigheid voor alle tabellen.
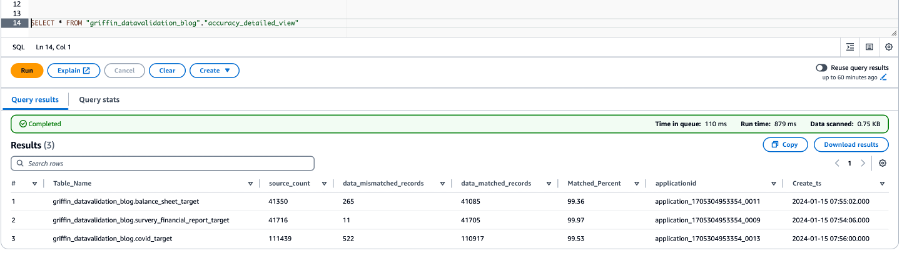
De volgende schermafbeelding toont de bestanden die voor elke tabel zijn gemaakt met niet-overeenkomende records. Voor elke tabel worden rechtstreeks vanuit de taak individuele mappen gegenereerd.
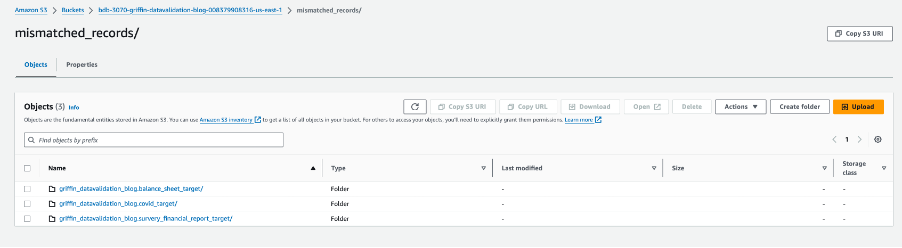
Elke tabelmap bevat een map voor elke dag waarop de taak wordt uitgevoerd.
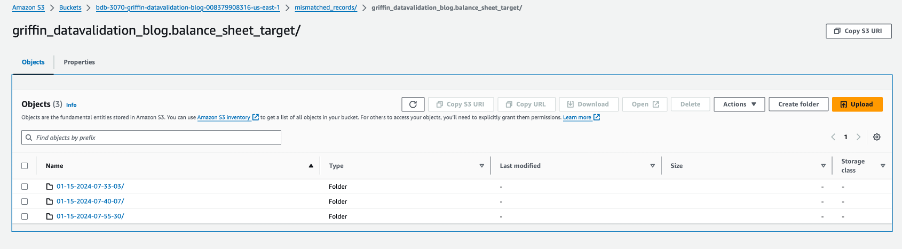
Binnen die specifieke datum wordt een bestand met de naam __missRecords bevat records die niet overeenkomen.

De volgende schermafbeelding toont de inhoud van het __missRecords bestand.

Opruimen
Om te voorkomen dat er extra kosten in rekening worden gebracht, voert u de volgende stappen uit om uw bronnen op te schonen wanneer u klaar bent met de oplossing:
- De AWS Glue-database verwijderen
griffin_datavalidation_blogen verwijder de databasegriffin_datavalidation_blogcascade. - Verwijder de voorvoegsels en objecten die u uit de bucket hebt gemaakt
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}. - Verwijder de CloudFormation-stack, waardoor uw extra bronnen worden verwijderd.
Conclusie
Dit bericht liet zien hoe u Python Griffin kunt gebruiken om het gegevensvalidatieproces na de migratie te versnellen. Python Griffin helpt u bij het berekenen van tellingen en validatie op rij- en kolomniveau, waardoor niet-overeenkomende records worden geïdentificeerd zonder code te schrijven.
Voor meer informatie over gebruiksscenario's voor gegevenskwaliteit raadpleegt u Aan de slag met AWS Glue Data Quality uit de AWS Glue Data Catalog en AWS Glue-gegevenskwaliteit.
Over de auteurs
 Dipal Mahajan fungeert als Lead Consultant bij Amazon Web Services en biedt deskundige begeleiding aan wereldwijde klanten bij het ontwikkelen van zeer veilige, schaalbare, betrouwbare en kostenefficiënte cloudapplicaties. Met een schat aan ervaring op het gebied van softwareontwikkeling, architectuur en analyse in diverse sectoren, zoals financiën, telecom, detailhandel en gezondheidszorg, brengt hij inzichten van onschatbare waarde in zijn rol. Buiten de professionele sfeer verkent Dipal graag nieuwe bestemmingen, aangezien hij al 14 van de 30 landen op zijn verlanglijstje heeft bezocht.
Dipal Mahajan fungeert als Lead Consultant bij Amazon Web Services en biedt deskundige begeleiding aan wereldwijde klanten bij het ontwikkelen van zeer veilige, schaalbare, betrouwbare en kostenefficiënte cloudapplicaties. Met een schat aan ervaring op het gebied van softwareontwikkeling, architectuur en analyse in diverse sectoren, zoals financiën, telecom, detailhandel en gezondheidszorg, brengt hij inzichten van onschatbare waarde in zijn rol. Buiten de professionele sfeer verkent Dipal graag nieuwe bestemmingen, aangezien hij al 14 van de 30 landen op zijn verlanglijstje heeft bezocht.
 Akhil is een hoofdconsultant bij AWS Professional Services. Hij helpt klanten bij het ontwerpen en bouwen van schaalbare data-analyseoplossingen en het migreren van datapipelines en datawarehouses naar AWS. In zijn vrije tijd houdt hij van reizen, spelletjes spelen en films kijken.
Akhil is een hoofdconsultant bij AWS Professional Services. Hij helpt klanten bij het ontwerpen en bouwen van schaalbare data-analyseoplossingen en het migreren van datapipelines en datawarehouses naar AWS. In zijn vrije tijd houdt hij van reizen, spelletjes spelen en films kijken.
 Ramesh Raghupatie is Senior Data Architect bij WWCO ProServe bij AWS. Hij werkt samen met AWS-klanten om datawarehouses en datameren op de AWS Cloud te ontwerpen, implementeren en migreren naar datawarehouses. Hoewel hij niet aan het werk is, houdt Ramesh van reizen, tijd doorbrengen met familie en yoga.
Ramesh Raghupatie is Senior Data Architect bij WWCO ProServe bij AWS. Hij werkt samen met AWS-klanten om datawarehouses en datameren op de AWS Cloud te ontwerpen, implementeren en migreren naar datawarehouses. Hoewel hij niet aan het werk is, houdt Ramesh van reizen, tijd doorbrengen met familie en yoga.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/automate-large-scale-data-validation-using-amazon-emr-and-apache-griffin/

