
Afbeelding door redacteur
Op 14 maart 2023 lanceerde OpenAI GPT-4, de nieuwste en krachtigste versie van hun taalmodel.
Binnen slechts enkele uren na de lancering verbaasde GPT-4 mensen door een handgetekende schets tot een functionele website, slagen voor het balie-examen en het genereren van nauwkeurige samenvattingen van Wikipedia-artikelen.
Het presteert ook beter dan zijn voorganger, GPT-3.5, bij het oplossen van wiskundige problemen en het beantwoorden van vragen op basis van logica en redenering.
ChatGPT, de chatbot die bovenop GPT-3.5 is gebouwd en voor het publiek is vrijgegeven, was berucht vanwege het 'hallucineren'. Het zou antwoorden genereren die ogenschijnlijk correct waren en zijn antwoorden verdedigen met "feiten", hoewel ze beladen waren met fouten.
Een gebruiker ging naar Twitter nadat het model volhield dat olifanteneieren de grootste van alle landdieren waren:
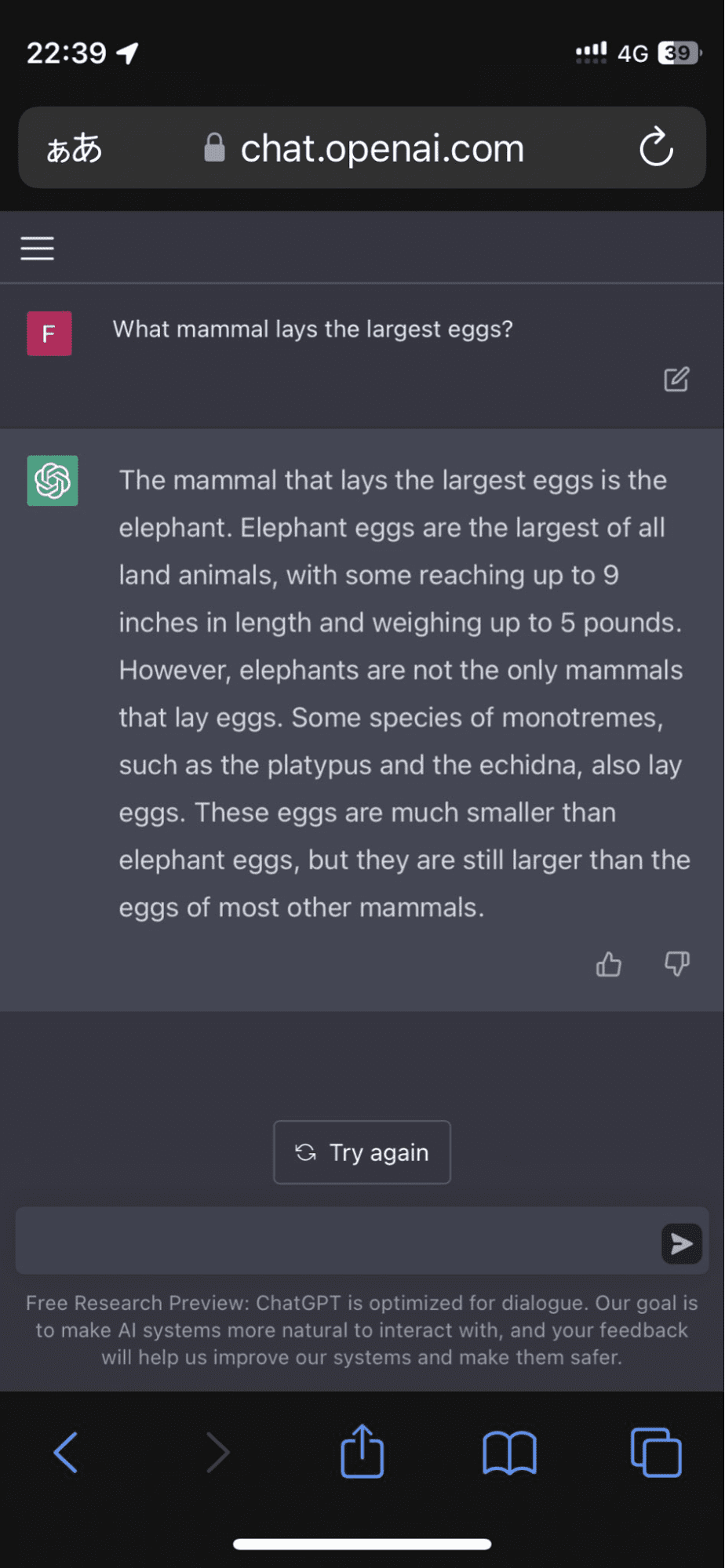
Afbeelding van FioraAeterna
En daar bleef het niet bij. Het algoritme bevestigde vervolgens zijn antwoord met verzonnen feiten die me bijna even overtuigd hadden.
GPT-4 daarentegen was getraind om minder vaak te 'hallucineren'. Het nieuwste model van OpenAI is moeilijker te misleiden en genereert niet zo vaak zelfverzekerd onwaarheden.
Als datawetenschapper moet ik voor mijn werk relevante databronnen vinden, grote datasets voorverwerken en zeer nauwkeurige machine learning-modellen bouwen die de bedrijfswaarde verhogen.
Ik besteed een groot deel van mijn dag aan het extraheren van gegevens uit verschillende bestandsindelingen en het consolideren ervan op één plek.
Nadat ChatGPT voor het eerst werd gelanceerd in november 2022, keek ik naar de chatbot voor wat begeleiding bij mijn dagelijkse workflows. Ik gebruikte de tool om de hoeveelheid tijd te besparen die ik aan ondergeschikt werk besteedde, zodat ik me kon concentreren op het bedenken van nieuwe ideeën en het maken van betere modellen.
Toen GPT-4 eenmaal was uitgebracht, was ik benieuwd of het een verschil zou maken in het werk dat ik deed. Waren er significante voordelen aan het gebruik van GPT-4 ten opzichte van zijn voorgangers? Zou het me helpen meer tijd te besparen dan ik al was met GPT-3.5?
In dit artikel laat ik je zien hoe ik ChatGPT gebruik om data science-workflows te automatiseren.
Ik zal dezelfde prompts maken en deze invoeren in zowel GPT-4 als GPT-3.5, om te zien of de eerste inderdaad beter presteert en meer tijd bespaart.
Als je alles wilt volgen wat ik in dit artikel doe, moet je toegang hebben tot GPT-4 en GPT-3.5.
GPT-3.5
GPT-3.5 is openbaar beschikbaar op de website van OpenAI. Navigeer eenvoudig naar https://chat.openai.com/auth/login, vul de vereiste gegevens in en u krijgt toegang tot het taalmodel:
Afbeelding van ChatGPT
GPT-4
GPT-4 daarentegen is momenteel verborgen achter een betaalmuur. Om toegang te krijgen tot het model, moet u upgraden naar ChatGPTPlus door op 'Upgrade naar Plus' te klikken.
Er zijn maandelijkse abonnementskosten van $ 20/maand die op elk moment kunnen worden geannuleerd:
Afbeelding van ChatGPT
Als je de maandelijkse abonnementskosten niet wilt betalen, kun je ook lid worden van de API-wachtlijst voor GPT-4. Zodra u toegang krijgt tot de API, kunt u volgen dit gids om het in Python te gebruiken.
Het is prima als je momenteel geen toegang hebt tot GPT-4.
Je kunt deze tutorial nog steeds volgen met de gratis versie van ChatGPT die GPT-3.5 gebruikt in de backend.
1. Gegevensvisualisatie
Bij het uitvoeren van verkennende data-analyse helpt het genereren van een snelle visualisatie in Python me vaak om de dataset beter te begrijpen.
Helaas kan deze taak ongelooflijk tijdrovend worden, vooral als u niet de juiste syntaxis kent om het gewenste resultaat te krijgen.
Ik merk dat ik vaak door de uitgebreide documentatie van Seaborn blader en StackOverflow gebruik om een enkele Python-plot te genereren.
Laten we eens kijken of ChatGPT dit probleem kan helpen oplossen.
We zullen de Diabetes van de Pima-indianen dataset in deze sectie. U kunt de dataset downloaden als u de door ChatGPT gegenereerde resultaten wilt volgen.
Laten we, na het downloaden van de dataset, deze in Python laden met behulp van de Pandas-bibliotheek en de kop van het dataframe afdrukken:
import pandas as pd df = pd.read_csv('diabetes.csv')
df.head()
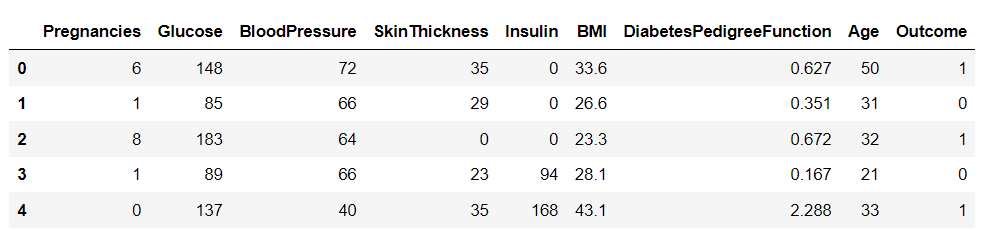
Er zijn negen variabelen in deze dataset. Een daarvan, "Uitkomst", is de doelvariabele die ons vertelt of een persoon diabetes zal ontwikkelen. De overige zijn onafhankelijke variabelen die worden gebruikt om de uitkomst te voorspellen.
Oké! Dus ik wil zien welke van deze variabelen van invloed zijn op het al dan niet ontwikkelen van diabetes.
Om dit te bereiken, kunnen we een geclusterd staafdiagram maken om de variabele "Diabetes" te visualiseren voor alle afhankelijke variabelen in de dataset.
Dit is eigenlijk vrij eenvoudig te coderen, maar laten we eenvoudig beginnen. We gaan verder met meer gecompliceerde prompts naarmate we verder komen in het artikel.
Datavisualisatie met GPT-3.5
Aangezien ik een betaald abonnement op ChatGPT heb, kan ik met de tool het onderliggende model selecteren dat ik wil gebruiken telkens wanneer ik het gebruik.
Ik ga GPT-3.5 selecteren:
Afbeelding van ChatGPT Plus
Als je geen abonnement hebt, kun je de gratis versie van ChatGPT gebruiken, aangezien de chatbot standaard GPT-3.5 gebruikt.
Laten we nu de volgende prompt typen om een visualisatie te genereren met behulp van de diabetesgegevensset:
Ik heb een dataset met 8 onafhankelijke variabelen en 1 afhankelijke variabele. De afhankelijke variabele, "Uitkomst", vertelt ons of een persoon diabetes zal ontwikkelen.
De onafhankelijke variabelen "Zwangerschappen", "Glucose", "Bloeddruk", "Huiddikte", "Insuline", "BMI", "DiabetesAfstammingsfunctie" en "Leeftijd" worden gebruikt om deze uitkomst te voorspellen.
Kun je Python-code genereren om al deze onafhankelijke variabelen per uitkomst te visualiseren? De uitvoer moet één geclusterd staafdiagram zijn dat is gekleurd door de variabele "Uitkomst". Er zouden in totaal 16 balken moeten zijn, 2 voor elke onafhankelijke variabele.
Hier is het antwoord van het model op de bovenstaande prompt:
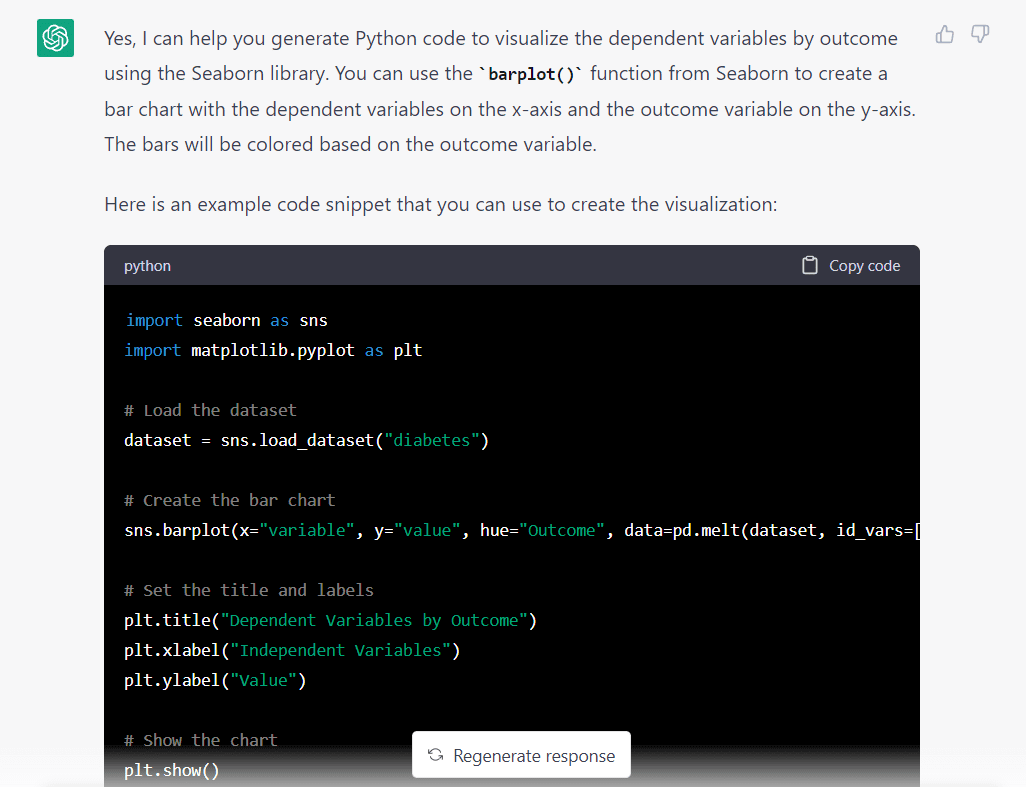
Wat meteen opvalt, is dat het model ervan uitging dat we een dataset uit Seaborn wilden importeren. Het heeft waarschijnlijk deze veronderstelling gemaakt sinds we het hebben gevraagd om de Seaborn-bibliotheek te gebruiken.
Dit is geen groot probleem, we hoeven slechts één regel te wijzigen voordat de codes worden uitgevoerd.
Hier is het volledige codefragment gegenereerd door GPT-3.5:
import seaborn as sns
import matplotlib.pyplot as plt # Load the dataset
dataset = pd.read_csv("diabetes.csv") # Create the bar chart
sns.barplot( x="variable", y="value", hue="Outcome", data=pd.melt(dataset, id_vars=["Outcome"]), ci=None,
) # Set the title and labels
plt.title("Dependent Variables by Outcome")
plt.xlabel("Independent Variables")
plt.ylabel("Value") # Show the chart
plt.show()
U kunt dit kopiëren en in uw Python IDE plakken.
Dit is het resultaat dat is gegenereerd na het uitvoeren van de bovenstaande code:
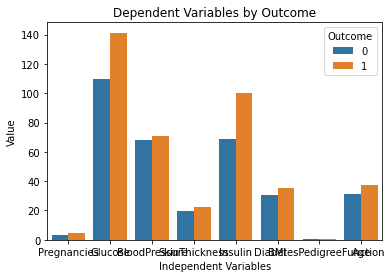
Deze grafiek ziet er perfect uit! Het is precies hoe ik het me had voorgesteld toen ik de prompt in ChatGPT typte.
Een probleem dat echter opvalt, is dat de tekst op deze kaart elkaar overlapt. Ik ga het model vragen of het ons kan helpen dit op te lossen door de volgende prompt te typen:
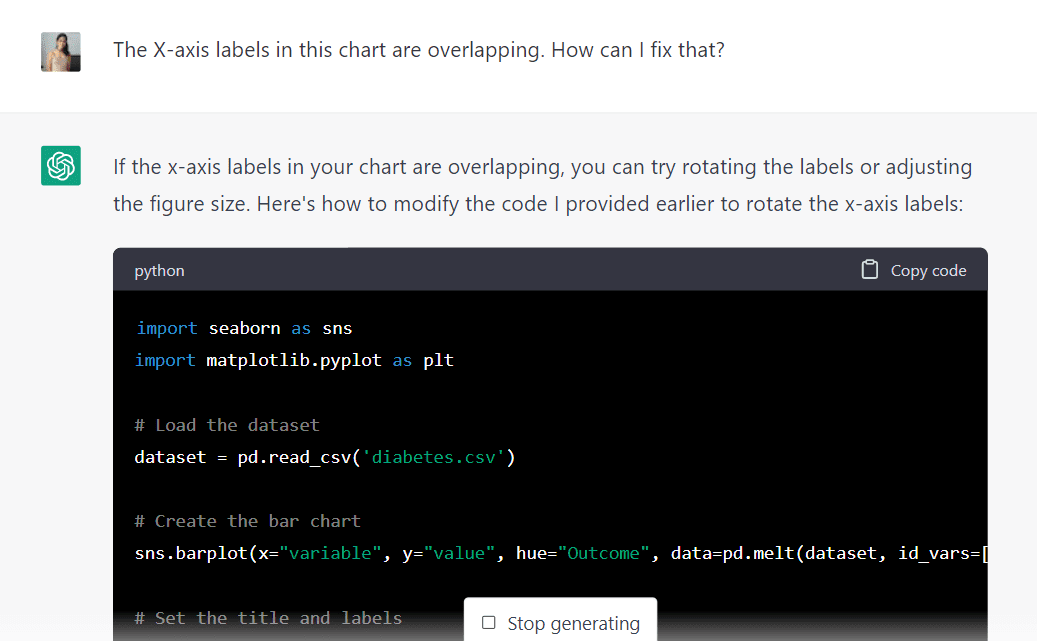
Het algoritme legde uit dat we deze overlap konden voorkomen door de diagramlabels te draaien of de figuurgrootte aan te passen. Het heeft ook nieuwe code gegenereerd om ons te helpen dit te bereiken.
Laten we deze code uitvoeren om te zien of het ons de gewenste resultaten geeft:
import seaborn as sns
import matplotlib.pyplot as plt # Load the dataset
dataset = pd.read_csv("diabetes.csv") # Create the bar chart
sns.barplot( x="variable", y="value", hue="Outcome", data=pd.melt(dataset, id_vars=["Outcome"]), ci=None,
) # Set the title and labels
plt.title("Dependent Variables by Outcome")
plt.xlabel("Independent Variables")
plt.ylabel("Value") # Rotate the x-axis labels by 45 degrees and set horizontal alignment to right
plt.xticks(rotation=45, ha="right") # Show the chart
plt.show()
De bovenstaande coderegels zouden de volgende uitvoer moeten genereren:
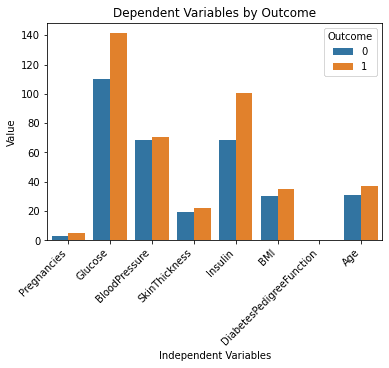
Dit ziet er geweldig uit!
Ik begrijp de dataset nu een stuk beter door simpelweg naar deze grafiek te kijken. Het lijkt erop dat mensen met een hoger glucose- en insulinegehalte meer kans hebben op het ontwikkelen van diabetes.
Merk ook op dat de variabele "DiabetesPedigreeFunction" ons geen informatie geeft in deze grafiek. Dit komt omdat de functie op een kleinere schaal is (tussen 0 en 2.4). Als je verder wilt experimenteren met ChatGPT, kun je het vragen om meerdere subplots binnen een enkel diagram te genereren om dit probleem op te lossen.
Datavisualisatie met GPT-4
Laten we nu dezelfde prompts invoeren in GPT-4 om te zien of we een ander antwoord krijgen. Ik ga het GPT-4-model selecteren in ChatGPT en typ dezelfde prompt als hiervoor:
Merk op dat GPT-4 er niet van uitgaat dat we een dataframe gaan gebruiken dat is ingebouwd in Seaborn.
Het vertelt ons dat het een dataframe met de naam "df" zal gebruiken om de visualisatie te bouwen, wat een verbetering is ten opzichte van de respons die wordt gegenereerd door GPT-3.5.
Hier is de volledige code die door dit algoritme is gegenereerd:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt # Assuming your DataFrame is called df
# First, you need to melt the DataFrame to make # it suitable for creating a clustered bar chart
melted_df = pd.melt( df, id_vars=["Outcome"], var_name="Independent Variable", value_name="Value",
) # Create the clustered bar chart
plt.figure(figsize=(12, 6))
sns.barplot( data=melted_df, x="Independent Variable", y="Value", hue="Outcome", ci=None,
) # Customize the plot
plt.title("Independent Variables by Outcome")
plt.ylabel("Average Value")
plt.xlabel("Independent Variables")
plt.legend(title="Outcome", loc="upper right") # Show the plot
plt.show()
De bovenstaande code zou de volgende plot moeten genereren:
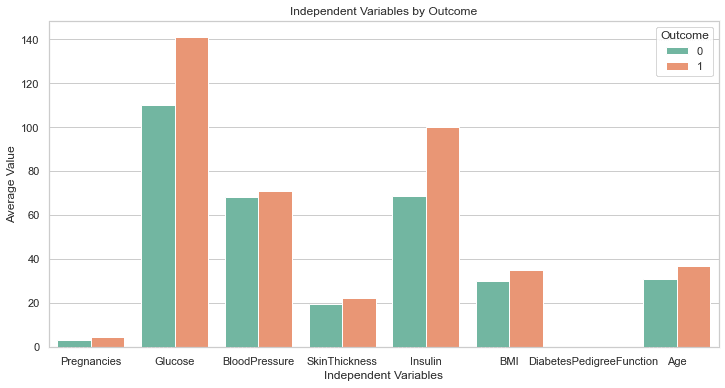
Dit is perfect!
Ook al hebben we er niet om gevraagd, GPT-4 heeft een regel code toegevoegd om de plotgrootte te vergroten. De labels op deze grafiek zijn allemaal duidelijk zichtbaar, dus we hoeven niet terug te gaan om de code te wijzigen zoals we eerder deden.
Dit is een stap hoger dan het antwoord dat wordt gegenereerd door GPT-3.5.
Over het algemeen lijkt het er echter op dat GPT-3.5 en GPT-4 beide effectief zijn in het genereren van code om taken als datavisualisatie en -analyse uit te voeren.
Het is belangrijk op te merken dat aangezien u geen gegevens kunt uploaden naar de interface van ChatGPT, u het model een nauwkeurige beschrijving van uw dataset moet geven voor optimale resultaten.
2. Werken met PDF-documenten
Hoewel dit geen gebruikelijke use-case voor datawetenschap is, heb ik ooit tekstgegevens uit honderden pdf-bestanden moeten extraheren om een sentimentanalysemodel te bouwen. De gegevens waren ongestructureerd en ik besteedde veel tijd aan het extraheren en voorbewerken ervan.
Ik werk ook vaak samen met onderzoekers die inhoud lezen en creëren over actuele gebeurtenissen in specifieke bedrijfstakken. Ze moeten op de hoogte blijven van het nieuws, bedrijfsrapporten analyseren en lezen over mogelijke trends in de branche.
In plaats van 100 pagina's van een bedrijfsrapport te lezen, is het niet eenvoudiger om gewoon woorden te extraheren waarin u geïnteresseerd bent en alleen zinnen te lezen die die trefwoorden bevatten?
Of als u geïnteresseerd bent in trends, kunt u een geautomatiseerde workflow maken die de groei van zoekwoorden in de loop van de tijd laat zien in plaats van elk rapport handmatig door te nemen.
In deze sectie zullen we ChatGPT gebruiken om PDF-bestanden in Python te analyseren. We zullen de chatbot vragen om de inhoud van een pdf-bestand te extraheren en naar een tekstbestand te schrijven.
Nogmaals, dit wordt gedaan met zowel GPT-3.5 als GPT-4 om te zien of er een significant verschil is in de gegenereerde code.
PDF-bestanden lezen met GPT-3.5
In deze sectie analyseren we een openbaar beschikbaar PDF-document met de titel Een korte introductie tot machine learning voor ingenieurs. Zorg ervoor dat u dit bestand downloadt als u wilt coderen voor deze sectie.
Laten we eerst het algoritme vragen om Python-code te genereren om gegevens uit dit PDF-document te extraheren en op te slaan in een tekstbestand:
Hier is de volledige code van het algoritme:
import PyPDF2 # Open the PDF file in read-binary mode
with open("Intro_to_ML.pdf", "rb") as pdf_file: # Create a PDF reader object pdf_reader = PyPDF2.PdfFileReader(pdf_file) # Get the total number of pages in the PDF file num_pages = pdf_reader.getNumPages() # Create a new text file with open("output_file.txt", "w") as txt_file: # Loop through each page in the PDF file for page_num in range(num_pages): # Get the text from the current page page_text = pdf_reader.getPage(page_num).extractText() # Write the text to the text file txt_file.write(page_text)
(Opmerking: Zorg ervoor dat u de naam van het PDF-bestand wijzigt in de naam die u hebt opgeslagen voordat u deze code uitvoert.)
Helaas kwam ik na het uitvoeren van de door GPT-3.5 gegenereerde code de volgende unicode-fout tegen:

Laten we teruggaan naar GPT-3.5 en kijken of het model dit kan oplossen:
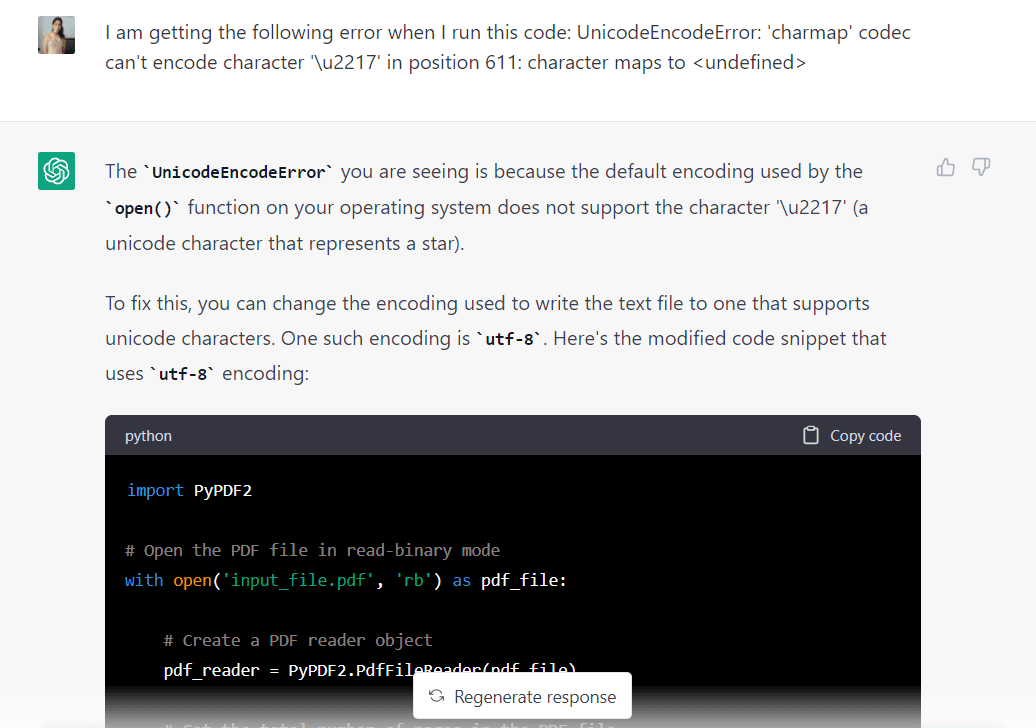
Ik plakte de fout in ChatGPT en het model antwoordde dat het kon worden opgelost door de gebruikte codering te wijzigen in 'utf-8'. Het gaf me ook een gewijzigde code die deze wijziging weerspiegelde:
import PyPDF2 # Open the PDF file in read-binary mode
with open("Intro_to_ML.pdf", "rb") as pdf_file: # Create a PDF reader object pdf_reader = PyPDF2.PdfFileReader(pdf_file) # Get the total number of pages in the PDF file num_pages = pdf_reader.getNumPages() # Create a new text file with utf-8 encoding with open("output_file.txt", "w", encoding="utf-8") as txt_file: # Loop through each page in the PDF file for page_num in range(num_pages): # Get the text from the current page page_text = pdf_reader.getPage(page_num).extractText() # Write the text to the text file txt_file.write(page_text)
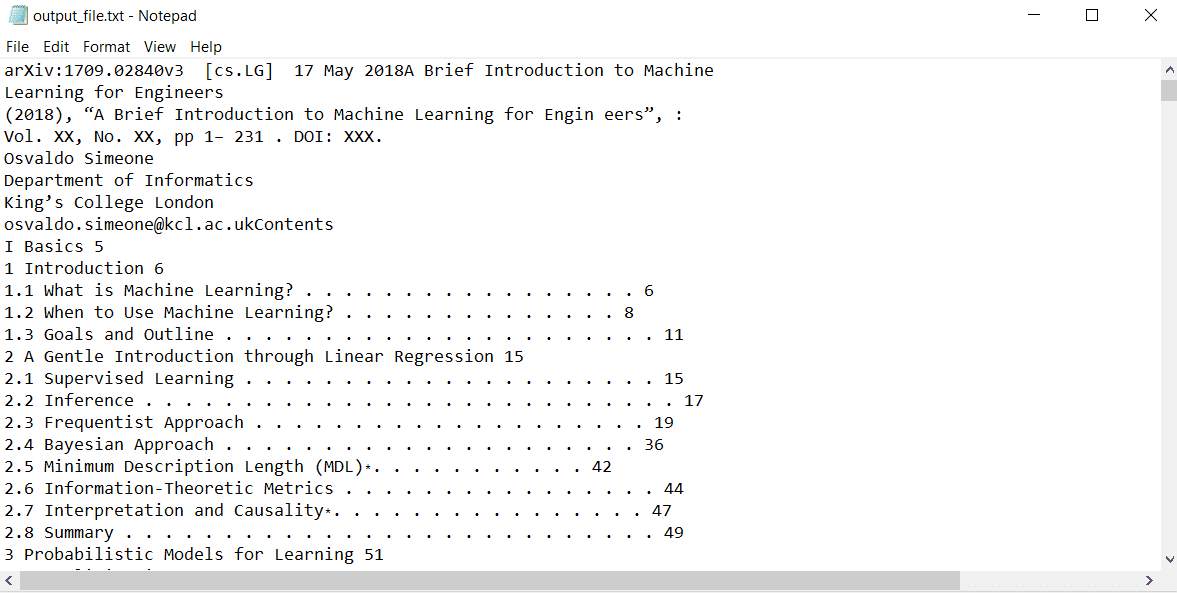
Deze code is met succes uitgevoerd en heeft een tekstbestand met de naam "output_file.txt" gemaakt. Alle inhoud in het PDF-document is naar het bestand geschreven:
PDF-bestanden lezen met GPT-4
Nu ga ik dezelfde prompt in GPT-4 plakken om te zien wat het model bedenkt:
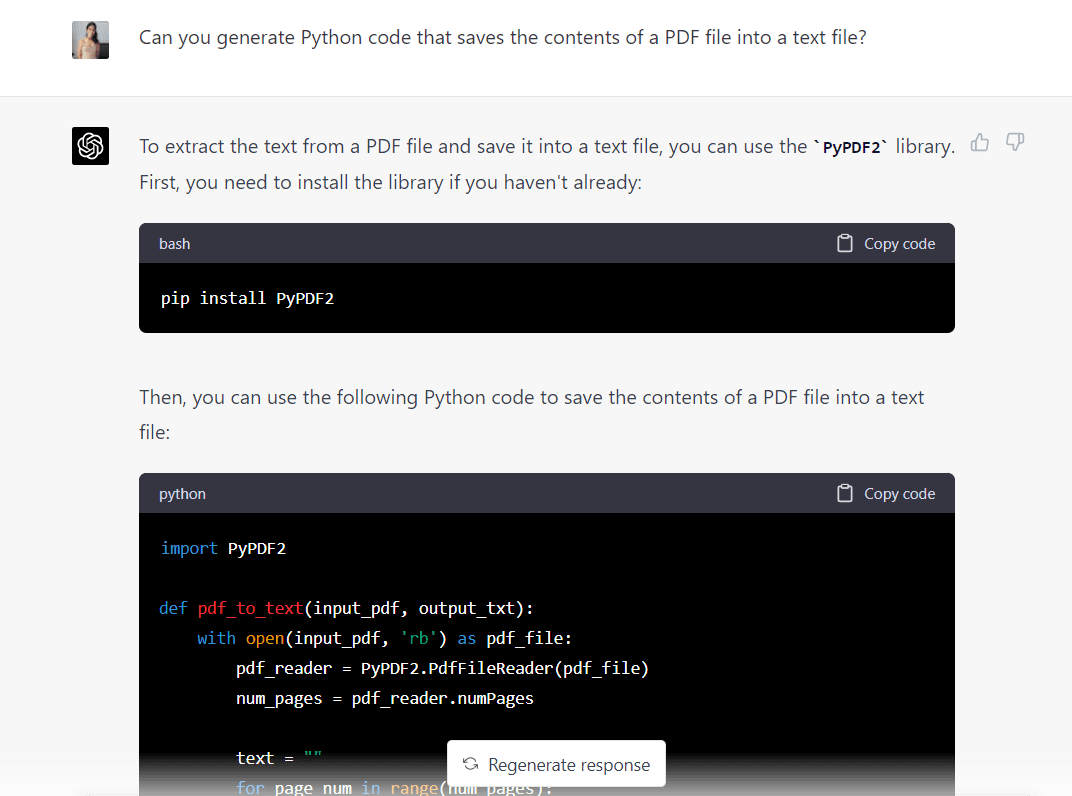
Hier is de volledige code gegenereerd door GPT-4:
import PyPDF2 def pdf_to_text(input_pdf, output_txt): with open(input_pdf, "rb") as pdf_file: pdf_reader = PyPDF2.PdfFileReader(pdf_file) num_pages = pdf_reader.numPages text = "" for page_num in range(num_pages): page = pdf_reader.getPage(page_num) text += page.extractText() with open(output_txt, "w", encoding="utf-8") as text_file: text_file.write(text) input_pdf = "Intro_to_ML.pdf"
output_txt = "output_gpt4.txt"
pdf_to_text(input_pdf, output_txt)
Moet je zien!
In tegenstelling tot GPT-3.5 heeft GPT-4 al gespecificeerd dat "utf-8"-codering moet worden gebruikt om het tekstbestand te openen. We hoeven niet terug te gaan en de code te wijzigen zoals we eerder deden.
De code die door GPT-4 wordt geleverd, zou met succes moeten worden uitgevoerd en u zou de inhoud van het PDF-document moeten zien in het tekstbestand dat is gemaakt.
Er zijn veel andere technieken die u kunt gebruiken om PDF-documenten met Python te automatiseren. Als je dit verder wilt onderzoeken, zijn hier enkele andere prompts die je in ChatGPT kunt typen:
- Kun je Python-code schrijven om twee PDF-bestanden samen te voegen?
- Hoe kan ik het voorkomen van een specifiek woord of een specifieke woordgroep in een PDF-document tellen met Python?
- Kun jij Python-code schrijven om tabellen uit pdf's te extraheren en in Excel te schrijven?
Ik stel voor om een aantal hiervan in je vrije tijd te proberen - je zou verbaasd zijn hoe snel GPT-4 je kan helpen bij het uitvoeren van ondergeschikte taken die gewoonlijk uren in beslag nemen.
3. Geautomatiseerde e-mails verzenden
Ik besteed uren van mijn werkweek aan het lezen en beantwoorden van e-mails. Dit is niet alleen tijdrovend, maar het kan ook ongelooflijk stressvol zijn om op de hoogte te blijven van e-mails wanneer u krappe deadlines najaagt.
En hoewel je ChatGPT niet al je e-mails voor je kunt laten schrijven (ik wens), kun je het nog steeds gebruiken om programma's te schrijven die geplande e-mails op een specifiek tijdstip verzenden of om een enkele e-mailsjabloon aan te passen die naar meerdere mensen kan worden verzonden .
In deze sectie krijgen we GPT-3.5 en GPT-4 om ons te helpen een Python-script te schrijven om geautomatiseerde e-mails te verzenden.
Geautomatiseerde e-mails verzenden met GPT-3.5
Laten we eerst de volgende prompt typen om codes te genereren om een geautomatiseerde e-mail te verzenden:
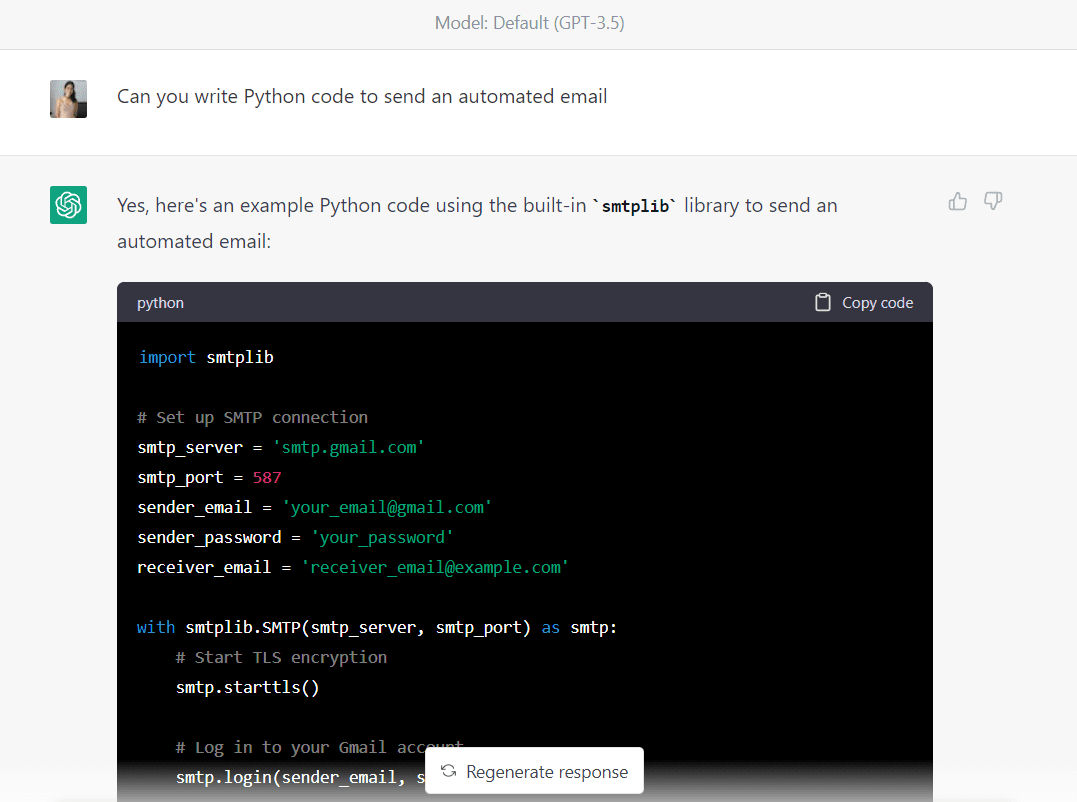
Hier is de volledige code gegenereerd door GPT-3.5 (Zorg ervoor dat u de e-mailadressen en het wachtwoord wijzigt voordat u deze code uitvoert):
import smtplib # Set up SMTP connection
smtp_server = "smtp.gmail.com"
smtp_port = 587
sender_email = "your_email@gmail.com"
sender_password = "your_password"
receiver_email = "receiver_email@example.com" with smtplib.SMTP(smtp_server, smtp_port) as smtp: # Start TLS encryption smtp.starttls() # Log in to your Gmail account smtp.login(sender_email, sender_password) # Compose your email message subject = "Automated email" body = "Hello,nnThis is an automated email sent from Python." message = f"Subject: {subject}nn{body}" # Send the email smtp.sendmail(sender_email, receiver_email, message)
Helaas is deze code bij mij niet succesvol uitgevoerd. Het genereerde de volgende fout:
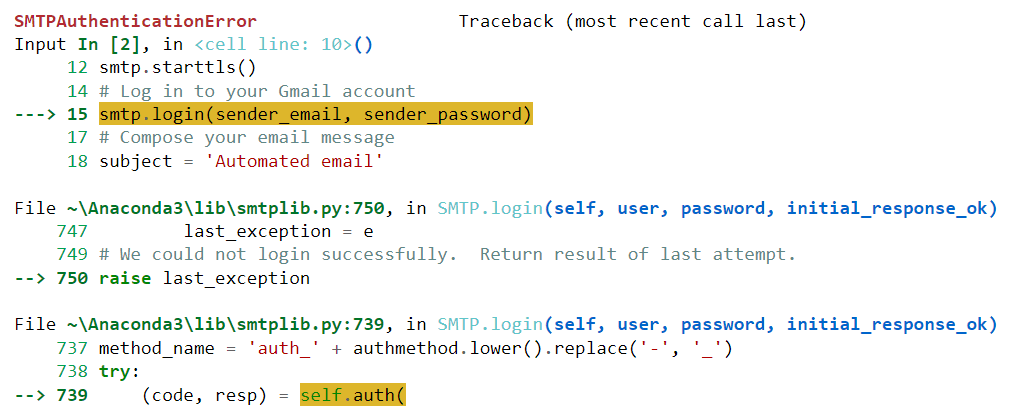
Laten we deze fout in ChatGPT plakken en kijken of het model ons kan helpen deze op te lossen:

Oké, dus het algoritme wees op een paar redenen waarom we deze fout zouden kunnen tegenkomen.
Ik weet zeker dat mijn inloggegevens en e-mailadressen geldig waren en dat er geen typefouten in de code stonden. Dus deze redenen kunnen worden uitgesloten.
GPT-3.5 suggereert ook dat het toestaan van minder veilige apps dit probleem zou kunnen oplossen.
Als je dit probeert, vind je echter geen optie in je Google-account om toegang te verlenen tot minder goed beveiligde apps.
Dit komt omdat Google niet meer laat gebruikers minder veilige apps toestaan vanwege beveiligingsproblemen.
Ten slotte vermeldt GPT-3.5 ook dat een app-wachtwoord moet worden gegenereerd als tweefactorauthenticatie is ingeschakeld.
Ik heb geen tweefactorauthenticatie ingeschakeld, dus ik ga dit model (tijdelijk) opgeven en kijken of GPT-4 een oplossing heeft.
Geautomatiseerde e-mails verzenden met GPT-4
Oké, dus als je dezelfde prompt in GPT-4 typt, zul je merken dat het algoritme code genereert die erg lijkt op wat GPT-3.5 ons gaf. Dit veroorzaakt dezelfde fout die we eerder tegenkwamen.
Laten we eens kijken of GPT-4 ons kan helpen deze fout op te lossen:

De suggesties van GPT-4 lijken erg op wat we eerder zagen.
Deze keer geeft het ons echter een stapsgewijs overzicht van hoe elke stap moet worden uitgevoerd.
GPT-4 stelt ook voor om een app-wachtwoord te maken, dus laten we het eens proberen.
Ga eerst naar uw Google-account, navigeer naar "Beveiliging" en schakel tweefactorauthenticatie in. Vervolgens zou u in hetzelfde gedeelte een optie moeten zien met de tekst 'App-wachtwoorden'.
Klik hierop en het volgende scherm verschijnt:
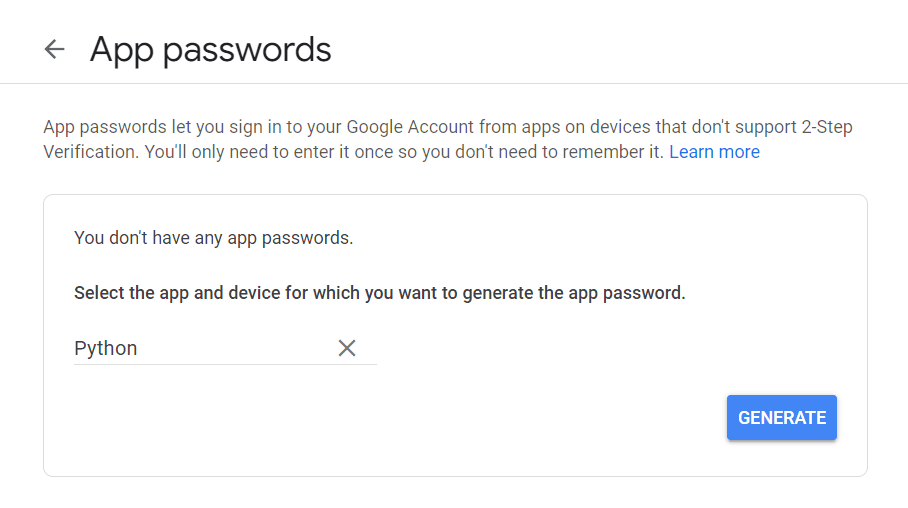
U kunt elke gewenste naam invoeren en op "Genereren" klikken.
Er verschijnt een nieuw app-wachtwoord.
Vervang uw bestaande wachtwoord in de Python-code door dit app-wachtwoord en voer de code opnieuw uit:
import smtplib # Set up SMTP connection
smtp_server = "smtp.gmail.com"
smtp_port = 587
sender_email = "your_email@gmail.com"
sender_password = "YOUR_APP_PASSWORD"
receiver_email = "receiver_email@example.com" with smtplib.SMTP(smtp_server, smtp_port) as smtp: # Start TLS encryption smtp.starttls() # Log in to your Gmail account smtp.login(sender_email, sender_password) # Compose your email message subject = "Automated email" body = "Hello,nnThis is an automated email sent from Python." message = f"Subject: {subject}nn{body}" # Send the email smtp.sendmail(sender_email, receiver_email, message)
Het zou deze keer met succes moeten werken en uw ontvanger ontvangt een e-mail die er als volgt uitziet:
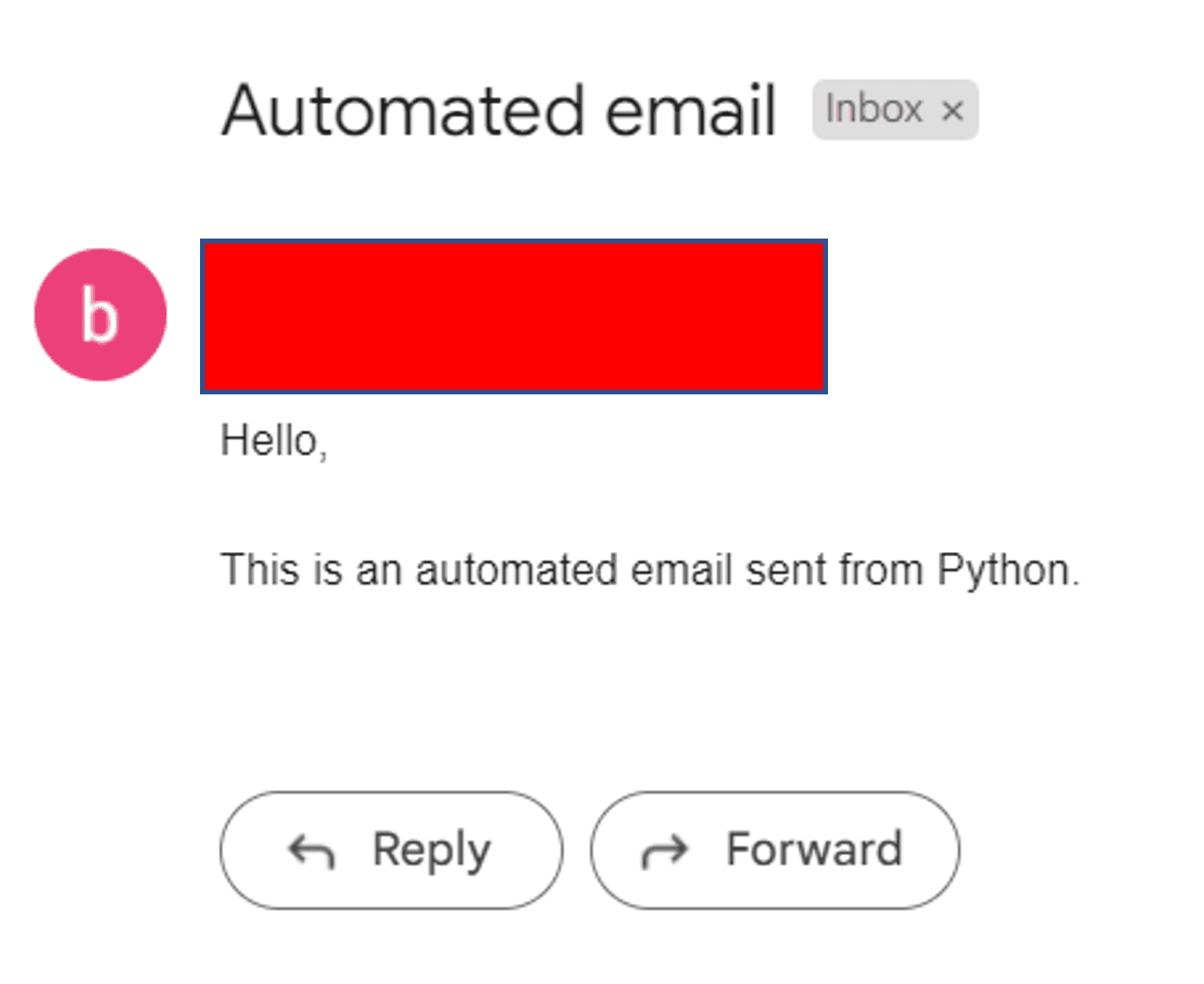
Perfect!
Dankzij ChatGPT hebben we met succes een geautomatiseerde e-mail met Python verzonden.
Als u nog een stap verder wilt gaan, stel ik voor om prompts te genereren waarmee u:
- Stuur bulk-e-mails tegelijkertijd naar meerdere ontvangers
- Stuur geplande e-mails naar een vooraf gedefinieerde lijst met e-mailadressen
- Stuur ontvangers een aangepaste e-mail die is afgestemd op hun leeftijd, geslacht en locatie.
Natasha Selvaraj is een autodidactische datawetenschapper met een passie voor schrijven. Je kunt contact met haar opnemen op LinkedIn.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/03/automate-boring-stuff-chatgpt-python.html?utm_source=rss&utm_medium=rss&utm_campaign=automate-the-boring-stuff-with-chatgpt-and-python

