We leven in het tijdperk van realtime data en inzichten, aangedreven door datastreaming-applicaties met lage latentie. Tegenwoordig verwacht iedereen een persoonlijke ervaring in elke toepassing, en organisaties innoveren voortdurend om de snelheid van hun bedrijfsvoering en besluitvorming te verhogen. De hoeveelheid geproduceerde tijdgevoelige gegevens neemt snel toe, waarbij verschillende gegevensformaten worden geïntroduceerd in nieuwe bedrijven en klantgebruiksscenario's. Daarom is het van cruciaal belang voor organisaties om een schaalbare en betrouwbare infrastructuur voor datastreaming met lage latentie te omarmen om realtime bedrijfsapplicaties en betere klantervaringen te leveren.
Dit is het eerste bericht in een blogreeks die gemeenschappelijke architectuurpatronen biedt bij het bouwen van realtime datastreaminginfrastructuren met behulp van Kinesis Data Streams voor een breed scala aan gebruiksscenario's. Het is bedoeld om een raamwerk te bieden voor het creëren van streaming-applicaties met lage latentie op de AWS Cloud Amazon Kinesis-gegevensstromen en Speciaal gebouwde data-analysediensten van AWS.
In dit bericht zullen we de algemene architectuurpatronen van twee gebruiksscenario's bekijken: Time Series Data Analysis en Event Driven Microservices. In het volgende bericht in onze serie zullen we de architecturale patronen onderzoeken bij het bouwen van streaming-pijplijnen voor realtime BI-dashboards, contactcenteragenten, grootboekgegevens, gepersonaliseerde realtime aanbevelingen, loganalyses, IoT-gegevens, het vastleggen van wijzigingsgegevens en echte -time marketinggegevens. Al deze architectuurpatronen zijn geïntegreerd met Amazon Kinesis Data Streams.
Realtime streaming met Kinesis Data Streams
Amazon Kinesis Data Streams is een cloud-native, serverloze streaming-dataservice waarmee u eenvoudig realtime gegevens op elke schaal kunt vastleggen, verwerken en opslaan. Met Kinesis Data Streams kunt u honderden gigabytes aan gegevens per seconde verzamelen en verwerken uit honderdduizenden bronnen, waardoor u eenvoudig applicaties kunt schrijven die informatie in realtime verwerken. De verzamelde gegevens zijn in milliseconden beschikbaar om gebruiksscenario's voor realtime analyses mogelijk te maken, zoals realtime dashboards, realtime detectie van afwijkingen en dynamische prijzen. Standaard worden de gegevens binnen de Kinesis Data Stream 24 uur bewaard met een optie om de gegevensretentie te verhogen naar 365 dagen. Als klanten dezelfde gegevens in realtime met meerdere applicaties willen verwerken, kunnen ze de functie Enhanced Fan-Out (EFO) gebruiken. Vóór deze functie deelde elke toepassing die gegevens uit de stream verbruikte de uitvoer van 2 MB/seconde/shard. Door streamconsumenten te configureren om verbeterde fan-out te gebruiken, ontvangt elke dataconsument een speciale leesdoorvoer van 2 MB/seconde per shard om de latentie bij het ophalen van gegevens verder te verminderen.
Voor hoge beschikbaarheid en duurzaamheid bereikt Kinesis Data Streams een hoge duurzaamheid door de gestreamde gegevens synchroon te repliceren over drie beschikbaarheidszones in een AWS-regio en geeft u de mogelijkheid om gegevens maximaal 365 dagen te bewaren. Voor de veiligheid biedt Kinesis Data Streams versleuteling aan de serverzijde, zodat u kunt voldoen aan strenge vereisten voor gegevensbeheer door uw gegevens in rust en Amazon Virtual Private Cloud (VPC) interface-eindpunten te versleutelen om het verkeer tussen uw Amazon VPC en Kinesis Data Streams privé te houden.
Kinesis Data Streams heeft native integraties met andere AWS-services zoals AWS lijm en Amazon EventBridge om realtime streaming-applicaties op AWS te bouwen. Raadpleeg Amazon Kinesis Data Streams-integraties voor aanvullende details.
Moderne datastreamingarchitectuur met Kinesis Data Streams
Een moderne streaming data-architectuur met Kinesis Data Streams kan worden ontworpen als een stapel van vijf logische lagen; elke laag bestaat uit meerdere speciaal gebouwde componenten die aan specifieke vereisten voldoen, zoals geïllustreerd in het volgende diagram:

De architectuur bestaat uit de volgende belangrijke componenten:
- Streamingbronnen – Uw bron van streaminggegevens omvat gegevensbronnen zoals clickstreamgegevens, sensoren, sociale media, Internet of Things (IoT)-apparaten, logbestanden die zijn gegenereerd door uw web- en mobiele applicaties te gebruiken, en mobiele apparaten die semi-gestructureerde en ongestructureerde gegevens genereren als continue stromen met hoge snelheid.
- Streamopname – De stroomopnamelaag is verantwoordelijk voor het opnemen van gegevens in de stroomopslaglaag. Het biedt de mogelijkheid om gegevens uit tienduizenden gegevensbronnen te verzamelen en in realtime op te nemen. U kunt gebruik maken van de Kinesis-SDK voor het opnemen van streaminggegevens via API's, de Kinesis Producer-bibliotheek voor het bouwen van hoogwaardige en langlopende streamingproducenten, of a Kinesis-agent voor het verzamelen van een reeks bestanden en het opnemen ervan in Kinesis Data Streams. Daarnaast kun je gebruik maken van veel pre-build integraties zoals AWS Database Migratieservice (AWS DMS), Amazon DynamoDB en AWS IoT-kern om gegevens zonder code op te nemen. U kunt ook gegevens opnemen van platforms van derden, zoals Apache Spark en Apache Kafka Connect
- Streamopslag – Kinesis Data Streams bieden twee modi om de gegevensdoorvoer te ondersteunen: On-Demand en Provisioned. De On-Demand-modus, nu de standaardkeuze, kan elastisch worden geschaald om variabele doorvoer te absorberen, zodat klanten zich geen zorgen hoeven te maken over capaciteitsbeheer en niet hoeven te betalen op basis van gegevensdoorvoer. De On-Demand-modus schaalt automatisch twee keer de streamcapaciteit op ten opzichte van de historische maximale gegevensopname om voldoende capaciteit te bieden voor onverwachte pieken in de gegevensopname. Als alternatief kunnen klanten die gedetailleerde controle willen over streamresources de Provisioned-modus gebruiken en het aantal Shards proactief op- en afschalen om aan hun doorvoervereisten te voldoen. Bovendien kan Kinesis Data Streams standaard streaminggegevens tot 2 uur opslaan, maar kan afhankelijk van de gebruikssituatie tot 24 dagen of 7 dagen worden verlengd. Meerdere applicaties kunnen dezelfde stream verbruiken.
- Streamverwerking – De stroomverwerkingslaag is verantwoordelijk voor het transformeren van gegevens in een verbruikbare staat door middel van gegevensvalidatie, opschoning, normalisatie, transformatie en verrijking. De streamingrecords worden gelezen in de volgorde waarin ze zijn geproduceerd, waardoor realtime analyses mogelijk zijn, gebeurtenisgestuurde applicaties kunnen worden gebouwd of ETL kunnen worden gestreamd (uitpakken, transformeren en laden). Je kunt gebruiken Amazon Managed Service voor Apache Flink voor complexe stroomgegevensverwerking, AWS Lambda voor verwerking van staatloze stroomgegevens, en AWS lijm & Amazon EMR voor bijna realtime computergebruik. Je kunt er ook consumentenapplicaties op maat mee bouwen Kinesis Consumentenbibliotheek, die veel complexe taken zal uitvoeren die verband houden met gedistribueerd computergebruik.
- Bestemming - De bestemmingslaag is een soort speciaal gebouwde bestemming, afhankelijk van uw gebruiksscenario. U kunt gegevens rechtstreeks naar streamen Amazon roodverschuiving voor datawarehousing en Amazon EventBridge voor het bouwen van gebeurtenisgestuurde applicaties. Je kan ook gebruiken Amazon Kinesis-gegevens Firehose voor streaming-integratie waarbij u de verwerking van streams met AWS Lambda kunt verlichten en vervolgens verwerkte streaming kunt leveren naar bestemmingen zoals Amazon S3 data lake, OpenSearch Service voor operationele analyses, een Redshift-datawarehouse, No-SQL-databases zoals Amazon DynamoDB en relationele databases zoals Amazon RDS om real-time streams in bedrijfsapplicaties te consumeren. De bestemming kan een gebeurtenisgestuurde applicatie zijn voor realtime dashboards, automatische beslissingen op basis van verwerkte streaminggegevens, realtime wijzigingen en meer.
Realtime analysearchitectuur voor tijdreeksen
Tijdreeksgegevens zijn een reeks gegevenspunten die gedurende een tijdsinterval zijn geregistreerd voor het meten van gebeurtenissen die in de loop van de tijd veranderen. Voorbeelden zijn aandelenkoersen in de loop van de tijd, klikstreams op webpagina's en apparaatlogboeken in de loop van de tijd. Klanten kunnen tijdreeksgegevens gebruiken om veranderingen in de loop van de tijd te monitoren, zodat ze afwijkingen kunnen detecteren, patronen kunnen identificeren en kunnen analyseren hoe bepaalde variabelen in de loop van de tijd worden beïnvloed. Tijdreeksgegevens worden doorgaans in grote hoeveelheden uit meerdere bronnen gegenereerd en moeten op kosteneffectieve wijze en vrijwel in realtime worden verzameld.
Normaal gesproken zijn er drie primaire doelen die klanten willen bereiken bij het verwerken van tijdreeksgegevens:
- Krijg realtime inzicht in de systeemprestaties en detecteer afwijkingen
- Begrijp het gedrag van eindgebruikers om trends te volgen en op basis van deze inzichten visualisaties op te vragen/te bouwen
- Zorg voor een duurzame opslagoplossing voor het opnemen en opslaan van zowel archiefgegevens als veelgebruikte gegevens.
Met Kinesis Data Streams kunnen klanten continu terabytes aan tijdreeksgegevens uit duizenden bronnen vastleggen voor opschoning, verrijking, opslag, analyse en visualisatie.
Het volgende architectuurpatroon illustreert hoe real-time analyses kunnen worden bereikt voor Time Series-gegevens met Kinesis Data Streams:
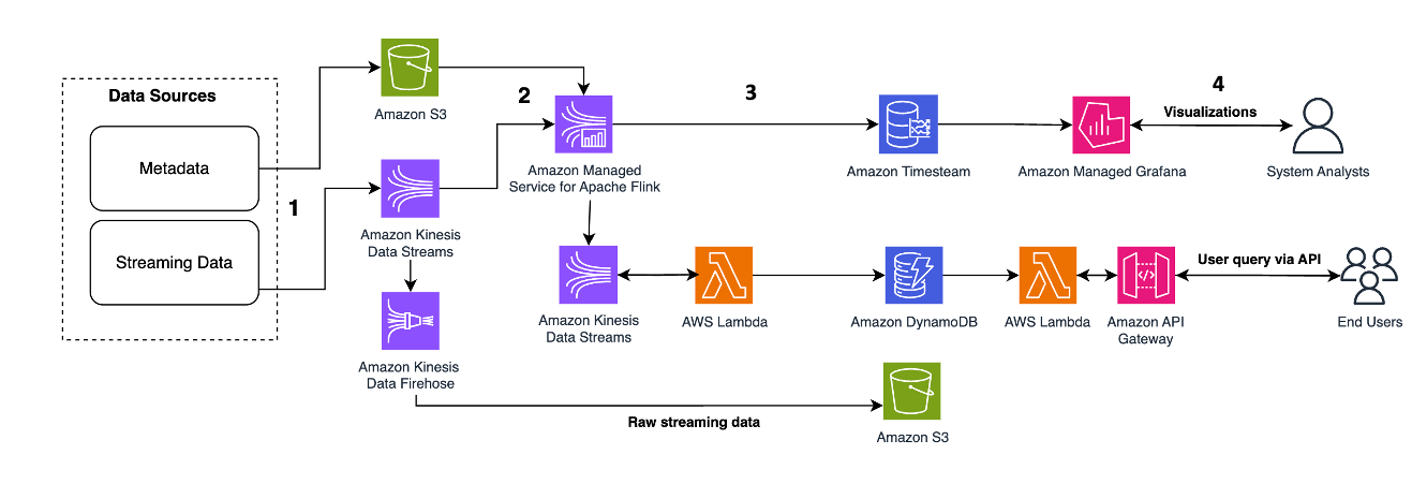
De workflowstappen zijn als volgt:
- Gegevensopname en -opslag – Kinesis Data Streams kan continu terabytes aan gegevens uit duizenden bronnen vastleggen en opslaan.
- Streamverwerking – Een applicatie gemaakt met Amazon Managed Service voor Apache Flink kan de records uit de datastroom lezen om eventuele fouten in de tijdreeksgegevens op te sporen en op te schonen en de gegevens te verrijken met specifieke metadata om operationele analyses te optimaliseren. Het gebruik van een datastroom in het midden biedt het voordeel dat de tijdreeksgegevens tegelijkertijd in andere processen en oplossingen worden gebruikt. Met deze gebeurtenissen wordt vervolgens een Lambda-functie aangeroepen, die tijdreeksberekeningen in het geheugen kan uitvoeren.
- Bestemmingen – Na het opschonen en verrijken kunnen de verwerkte tijdreeksgegevens naar gestreamd worden Amazone-tijdstroom database voor realtime dashboarding en analyse, of opgeslagen in databases zoals DynamoDB voor zoekopdrachten van eindgebruikers. De onbewerkte gegevens kunnen voor archivering naar Amazon S3 worden gestreamd.
- Visualisatie & Inzicht verkrijgen – Klanten kunnen waarschuwingen opvragen, visualiseren en creëren met behulp van Amazon beheerde service voor Grafana. Grafana ondersteunt gegevensbronnen die opslagbackends zijn voor tijdreeksgegevens. Om toegang te krijgen tot uw gegevens vanuit Timestream, moet u de Timestream-plug-in voor Grafana installeren. Eindgebruikers kunnen gegevens uit de DynamoDB-tabel opvragen met Amazon API-gateway optreden als proxy.
Verwijzen naar Bijna realtime verwerking met Amazon Kinesis, Amazon Timestream en Grafana presentatie van een serverloze streamingpijplijn voor het verwerken en opslaan van apparaattelemetrie-IoT-gegevens in een voor tijdreeksen geoptimaliseerde gegevensopslag zoals Amazon Timestream.
Gegevens in realtime verrijken en afspelen voor microservices voor evenementensourcing
Microservices zijn een architecturale en organisatorische benadering van softwareontwikkeling waarbij software is samengesteld uit kleine onafhankelijke services die communiceren via goed gedefinieerde API's. Bij het bouwen van gebeurtenisgestuurde microservices willen klanten 1. hoge schaalbaarheid bereiken om het volume aan binnenkomende gebeurtenissen te kunnen verwerken en 2. betrouwbaarheid van de gebeurtenisverwerking en het behouden van de systeemfunctionaliteit bij storingen.
Klanten maken gebruik van microservice-architectuurpatronen om innovatie en time-to-market voor nieuwe functies te versnellen, omdat applicaties daardoor gemakkelijker te schalen en sneller te ontwikkelen zijn. Het is echter een uitdaging om de gegevens in een netwerkoproep naar een andere microservice te verrijken en opnieuw af te spelen, omdat dit de betrouwbaarheid van de applicatie kan beïnvloeden en het moeilijk kan maken om fouten te debuggen en op te sporen. Om dit probleem op te lossen is event-sourcing een effectief ontwerppatroon dat historische records van alle statuswijzigingen centraliseert voor verrijking en herhaling, en de lees- en schrijfwerklast loskoppelt. Klanten kunnen Kinesis Data Streams gebruiken als de gecentraliseerde gebeurtenisopslag voor microservices voor gebeurtenissourcing, omdat KDS gigabytes aan gegevensdoorvoer per seconde per stream kan verwerken en de gegevens in milliseconden kan streamen, om te voldoen aan de eis van hoge schaalbaarheid en bijna realtime latentie, 1/ integreren met Flink en S2 voor gegevensverrijking en -prestaties terwijl ze volledig zijn losgekoppeld van de microservices, en 3/ opnieuw proberen en asynchroon lezen op een later tijdstip mogelijk maken, omdat KDS het gegevensrecord standaard 3 uur bewaart, en optioneel tot 24 dagen.
Het volgende architectuurpatroon is een algemene illustratie van hoe Kinesis Data Streams kunnen worden gebruikt voor Event-Sourcing Microservices:
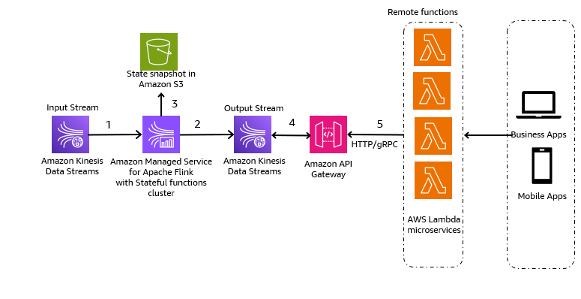
De stappen in de workflow zijn als volgt:
- Gegevensopname en -opslag – U kunt de input van uw microservices samenvoegen naar uw Kinesis Data Streams voor opslag.
- Streamverwerking - Apache Flink Stateful-functies vereenvoudigt het bouwen van gedistribueerde, stateful, gebeurtenisgestuurde applicaties. Het kan de gebeurtenissen ontvangen van een invoer-Kinesis-gegevensstroom en de resulterende stroom routeren naar een uitvoergegevensstroom. U kunt met Apache Flink een stateful functiescluster maken op basis van de bedrijfslogica van uw applicatie.
- Statusmomentopname in Amazon S3 – U kunt de momentopname van de status opslaan in Amazon S3 voor tracking.
- Uitvoerstromen – De uitvoerstromen kunnen worden verbruikt via externe Lambda-functies via het HTTP/gRPC-protocol via API Gateway.
- Lambda-afstandsbedieningsfuncties – Lambda-functies kunnen fungeren als microservices voor verschillende applicatie- en bedrijfslogica om bedrijfsapplicaties en mobiele apps te bedienen.
Om te leren hoe andere klanten hun op gebeurtenissen gebaseerde microservices hebben gebouwd met Kinesis Data Streams, raadpleegt u het volgende:
Belangrijkste overwegingen en best practices
Hier volgen enkele overwegingen en best practices waarmee u rekening moet houden:
- Het ontdekken van gegevens zou uw eerste stap moeten zijn bij het bouwen van moderne toepassingen voor gegevensstreaming. U moet de bedrijfswaarde definiëren en vervolgens uw streaminggegevensbronnen en gebruikerspersona's identificeren om de gewenste bedrijfsresultaten te bereiken.
- Kies uw tool voor het opnemen van streaminggegevens op basis van uw steaming-gegevensbron. U kunt bijvoorbeeld gebruik maken van de Kinesis-SDK voor het opnemen van streaminggegevens via API's, de Kinesis Producer-bibliotheek voor het bouwen van hoogwaardige en langlopende streamingproducenten, a Kinesis-agent voor het verzamelen van een reeks bestanden en het opnemen ervan in Kinesis Data Streams, AWS DMS voor gebruiksscenario's voor CDC-streaming, en AWS IoT-kern voor het opnemen van IoT-apparaatgegevens in Kinesis Data Streams. U kunt streaminggegevens rechtstreeks in Amazon Redshift opnemen om streaming-applicaties met lage latentie te bouwen. U kunt ook bibliotheken van derden, zoals Apache Spark en Apache Kafka, gebruiken om streaminggegevens in Kinesis Data Streams op te nemen.
- U moet uw streaminggegevensverwerkingsdiensten kiezen op basis van uw specifieke gebruiksscenario en zakelijke vereisten. U kunt Amazon Kinesis Managed Service voor Apache Flink bijvoorbeeld gebruiken voor geavanceerde streaminggebruiksscenario's met meerdere streamingbestemmingen en complexe stateful streamverwerking of als u bedrijfsstatistieken in realtime (zoals elk uur) wilt volgen. Lambda is goed voor op gebeurtenissen gebaseerde en staatloze verwerking. Je kunt gebruiken Amazon EMR voor het verwerken van streaminggegevens om uw favoriete open source big data-frameworks te gebruiken. AWS Glue is goed voor vrijwel realtime streaminggegevensverwerking voor gebruiksscenario's zoals streaming ETL.
- Kinesis Data Streams on-demand-modus wordt in rekening gebracht op basis van gebruik en schaalt automatisch de resourcecapaciteit op, dus het is goed voor piekerige streaming-workloads en handsfree onderhoud. De ingerichte modus wordt in rekening gebracht op basis van capaciteit en vereist proactief capaciteitsbeheer, dus het is goed voor voorspelbare streaming-workloads.
- U kunt gebruik maken van de Kinesis gedeelde rekenmachine om het aantal shards te berekenen dat nodig is voor de ingerichte modus. Met de on-demand-modus hoeft u zich geen zorgen te maken over shards.
- Bij het verlenen van machtigingen bepaalt u wie welke machtigingen krijgt voor welke Kinesis Data Streams-bronnen. U schakelt specifieke acties in die u wilt toestaan voor die bronnen. Daarom moet u alleen de machtigingen verlenen die nodig zijn om een taak uit te voeren. U kunt de gegevens in rust ook versleutelen met behulp van een door de klant beheerde KMS-sleutel (CMK).
- Je kunt de bewaartermijn bijwerken via de Kinesis Data Streams-console of door gebruik te maken van de VerhoogStreamRetentiePeriode en VerlaagStreamRetentionPeriod bewerkingen op basis van uw specifieke gebruiksscenario's.
- Kinesis Data Streams ondersteunt herharden. De aanbevolen API voor deze functie is UpdateShardCount, waarmee u het aantal shards in uw stream kunt aanpassen aan veranderingen in de snelheid van de gegevensstroom door de stream. De resharding-API's (Split en Merge) worden doorgaans gebruikt voor het verwerken van hot shards.
Conclusie
Dit bericht demonstreerde verschillende architecturale patronen voor het bouwen van streaming-applicaties met lage latentie met Kinesis Data Streams. U kunt uw eigen steaming-applicaties met lage latentie bouwen met Kinesis Data Streams met behulp van de informatie in dit bericht.
Raadpleeg de volgende bronnen voor gedetailleerde architectuurpatronen:
Als je een datavisie en -strategie wilt opbouwen, bekijk dan de AWS datagestuurd alles (D2E) programma.
Over de auteurs
 Raghavarao Sodabathina is een Principal Solutions Architect bij AWS, met de nadruk op Data Analytics, AI/ML en cloudbeveiliging. Hij werkt samen met klanten om innovatieve oplossingen te creëren die de zakelijke problemen van klanten aanpakken en de adoptie van AWS-diensten te versnellen. In zijn vrije tijd brengt Raghavarao graag tijd door met zijn gezin, leest hij boeken en kijkt hij films.
Raghavarao Sodabathina is een Principal Solutions Architect bij AWS, met de nadruk op Data Analytics, AI/ML en cloudbeveiliging. Hij werkt samen met klanten om innovatieve oplossingen te creëren die de zakelijke problemen van klanten aanpakken en de adoptie van AWS-diensten te versnellen. In zijn vrije tijd brengt Raghavarao graag tijd door met zijn gezin, leest hij boeken en kijkt hij films.
 Hang Zuo is Senior Product Manager in het Amazon Kinesis Data Streams-team bij Amazon Web Services. Hij is gepassioneerd door het ontwikkelen van intuïtieve productervaringen die complexe klantproblemen oplossen en klanten in staat stellen hun zakelijke doelen te bereiken.
Hang Zuo is Senior Product Manager in het Amazon Kinesis Data Streams-team bij Amazon Web Services. Hij is gepassioneerd door het ontwikkelen van intuïtieve productervaringen die complexe klantproblemen oplossen en klanten in staat stellen hun zakelijke doelen te bereiken.
 Shwetha Radhakrishnan is een Solutions Architect voor AWS met een focus op Data Analytics. Ze heeft oplossingen gebouwd die de adoptie van de cloud stimuleren en organisaties helpen datagestuurde beslissingen te nemen binnen de publieke sector. Buiten haar werk houdt ze van dansen, tijd doorbrengen met vrienden en familie en reizen.
Shwetha Radhakrishnan is een Solutions Architect voor AWS met een focus op Data Analytics. Ze heeft oplossingen gebouwd die de adoptie van de cloud stimuleren en organisaties helpen datagestuurde beslissingen te nemen binnen de publieke sector. Buiten haar werk houdt ze van dansen, tijd doorbrengen met vrienden en familie en reizen.
 Bretagne Ly is een oplossingsarchitect bij AWS. Ze richt zich op het helpen van zakelijke klanten bij hun adoptie- en moderniseringstraject naar de cloud en heeft interesse in het gebied van beveiliging en analyse. Buiten haar werk brengt ze graag tijd door met haar hond en speelt ze pickleball.
Bretagne Ly is een oplossingsarchitect bij AWS. Ze richt zich op het helpen van zakelijke klanten bij hun adoptie- en moderniseringstraject naar de cloud en heeft interesse in het gebied van beveiliging en analyse. Buiten haar werk brengt ze graag tijd door met haar hond en speelt ze pickleball.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/architectural-patterns-for-real-time-analytics-using-amazon-kinesis-data-streams-part-1/

