Het vermogen om enorme hoeveelheden documenten effectief te verwerken en te verwerken is essentieel geworden voor ondernemingen in de moderne wereld. Door de voortdurende toestroom van informatie waar alle ondernemingen mee te maken hebben, is het handmatig classificeren van documenten niet langer een haalbare optie. Modellen voor documentclassificatie kunnen de procedure automatiseren en organisaties helpen tijd en middelen te besparen. Traditionele categoriseringstechnieken, zoals handmatige verwerking en zoeken op basis van trefwoorden, worden minder efficiënt en tijdrovender naarmate het volume van documenten toeneemt. Deze inefficiëntie veroorzaakt een lagere productiviteit en hogere bedrijfskosten. Bovendien kan het voorkomen dat cruciale informatie toegankelijk is wanneer dat nodig is, wat kan leiden tot een slechte klantervaring en impact op de besluitvorming. Bij AWS re:Invent 2022, Amazon begrijpt het, een natuurlijke taalverwerkingsservice (NLP) die machine learning (ML) gebruikt om inzichten uit tekst te ontdekken, gelanceerd ondersteuning voor native documenttypen. Deze nieuwe functie gaf je de mogelijkheid om documenten te classificeren in native formaten (PDF, TIFF, JPG, PNG, DOCX) met behulp van Amazon Comprehend.
Vandaag zijn we verheugd aan te kondigen dat Amazon Comprehend nu aangepaste classificatiemodeltraining ondersteunt met documenten zoals PDF-, Word- en afbeeldingsindelingen. U kunt nu op maat gemaakte documentclassificatiemodellen trainen op native documenten die naast tekst ook lay-out ondersteunen, waardoor de nauwkeurigheid van de resultaten toeneemt.
In dit bericht geven we een overzicht van hoe je aan de slag kunt gaan met het trainen van een Amazon Comprehend aangepast documentclassificatiemodel.
Overzicht
Het vermogen om de relatieve plaatsingen van objecten binnen een gedefinieerde ruimte te begrijpen, wordt aangeduid als lay-out bewustzijn. In dit geval helpt het het model om te begrijpen hoe kopteksten, subkopjes, tabellen en afbeeldingen zich binnen een document tot elkaar verhouden. Het model kan een document effectiever categoriseren op basis van de inhoud als het zich bewust is van de structuur en lay-out van de tekst.
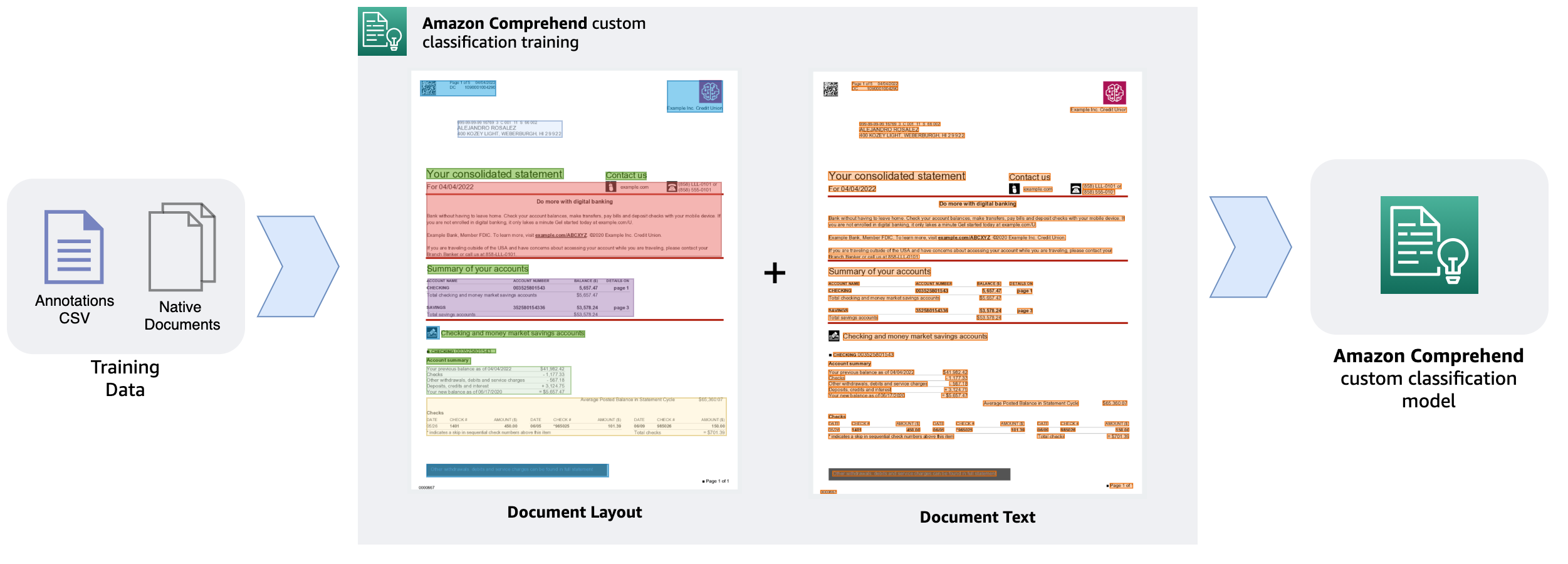
In dit bericht doorlopen we de betrokken stappen voor gegevensvoorbereiding, demonstreren we het modeltrainingsproces en bespreken we de voordelen van het gebruik van het nieuwe aangepaste documentclassificatiemodel in Amazon Comprehend. Als best practice dient u de volgende punten in overweging te nemen voordat u begint met het trainen van het aangepaste documentclassificatiemodel.
Evalueer uw behoeften op het gebied van documentclassificatie
Identificeer de verschillende soorten documenten die u mogelijk moet classificeren, samen met de verschillende klassen of categorieën om uw use case te ondersteunen. Bepaal de geschikte classificatiestructuur of taxonomie na evaluatie van het aantal en de soorten documenten die moeten worden gecategoriseerd. Documenttypen kunnen variëren van PDF, Word, afbeeldingen, enzovoort. Zorg ervoor dat u geautoriseerde toegang hebt tot een gevarieerde set gelabelde documenten via een documentbeheersysteem of andere opslagmechanismen.
Bereid uw gegevens voor
Zorg ervoor dat de documentbestanden die u voor modeltraining wilt gebruiken, niet zijn versleuteld of vergrendeld. Zorg er bijvoorbeeld voor dat uw PDF-bestanden niet zijn versleuteld en vergrendeld met een wachtwoord. U moet dergelijke bestanden decoderen voordat u ze voor trainingsdoeleinden kunt gebruiken. Label een voorbeeld van uw documenten met de juiste categorieën of labels (klassen). Bepaal of single-label classificatie (multi-class modus) Of classificatie met meerdere labels geschikt is voor uw gebruikssituatie. De multiklassemodus koppelt slechts één klasse aan elk document, terwijl de multilabelmodus een of meer klassen aan een document koppelt.
Overweeg modelevaluatie
Gebruik de gelabelde dataset om het model te trainen, zodat het nieuwe documenten nauwkeurig kan leren classificeren en kan evalueren hoe de nieuw getrainde modelversie presteert door inzicht te krijgen in de metrische gegevens van het model. Raadpleeg voor meer informatie over de metrische gegevens die worden geleverd door Amazon Comprehend post-model training Aangepaste classificatiestatistieken. Nadat het trainingsproces is voltooid, kunt u beginnen met het asynchroon of in realtime classificeren van documenten. In de volgende secties wordt uitgelegd hoe u een aangepast classificatiemodel traint.
Bereid de trainingsgegevens voor
Voordat we ons aangepaste classificatiemodel trainen, moeten we de trainingsgegevens voorbereiden. Trainingsgegevens bestaan uit een set gelabelde documenten. Dit kunnen vooraf geïdentificeerde documenten zijn uit een documentopslagplaats waartoe u al toegang hebt. Voor ons voorbeeld hebben we een aangepast classificatiemodel getraind met een paar verschillende documenttypen die doorgaans worden aangetroffen in een beoordelingsproces voor claims van een ziektekostenverzekering: samenvatting van het ontslag van een patiënt, facturen, kwitanties, enzovoort. We moeten ook een annotatiebestand in CSV-indeling voorbereiden. Hieronder volgt een voorbeeld van een annotatiebestand met CSV-gegevens die nodig zijn voor de training:
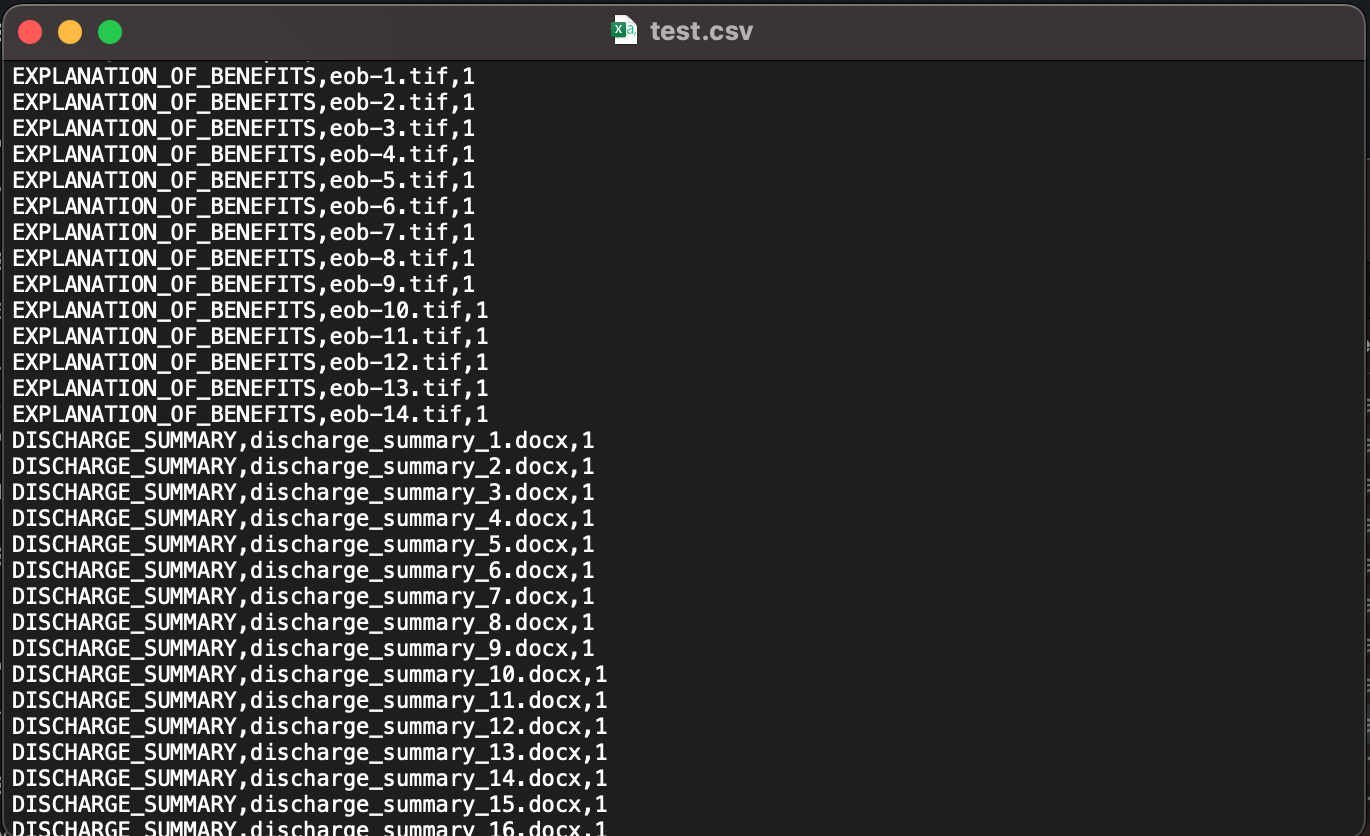
Het CSV-bestand met annotaties moet drie kolommen bevatten. De eerste kolom bevat de gewenste klasse (label) voor het document, de tweede kolom is de documentnaam (bestandsnaam) en de laatste kolom is het paginanummer van het document dat u wilt opnemen in de trainingsdataset. Omdat het trainingsproces native PDF- en DOCX-bestanden met meerdere pagina's ondersteunt, moet u het paginanummer opgeven als het document een document met meerdere pagina's is. Als u alle pagina's van een document met meerdere pagina's in de trainingsgegevensset wilt opnemen, moet u elke pagina als een afzonderlijke regel in het CSV-annotatiebestand opgeven. In het voorgaande annotatiebestand bijvoorbeeld, invoice-1.pdf is een document van twee pagina's en we willen beide pagina's opnemen in de classificatiegegevensset. Omdat bestanden zoals PDF, PNG en TIFF afbeeldingsindelingen zijn, moet het paginanummer (derde kolom) altijd 1 zijn. Als uw gegevensset TIF-bestanden met meerdere frames (meerdere pagina's) bevat, moet u deze splitsen in afzonderlijke TIF-bestanden in om ze te gebruiken in het trainingsproces.
We hebben een annotatiebestand gemaakt met de naam test.csv met de juiste gegevens om een aangepast classificatiemodel te trainen. Voor elk voorbeelddocument bevat het CSV-bestand de klasse waartoe het document behoort, de locatie van het document Amazon eenvoudige opslagservice (Amazon S3), zoals path/to/prefix/document.pdfen het paginanummer (indien van toepassing). Omdat de meeste van onze documenten DOCX-, PDF- of TIF-, JPG- of PNG-bestanden van één pagina zijn, is het toegewezen paginanummer 1. Omdat onze CSV-annotaties en voorbeelddocumenten allemaal onder hetzelfde Amazon S3-voorvoegsel staan, doen we dat niet Het is niet nodig om het voorvoegsel in de tweede kolom expliciet op te geven. We maken ook ten minste 10 documentvoorbeelden of meer voor elke klas, en we gebruikten een mix van JPG-, PNG-, DOCX-, PDF- en TIF-bestanden om het model te trainen. Houd er rekening mee dat het meestal wordt aanbevolen om een gevarieerde set voorbeelddocumenten te hebben voor modeltraining om te voorkomen dat het model te veel wordt aangepast, wat van invloed is op het vermogen om nieuwe documenten te herkennen. Het wordt ook aanbevolen om het aantal samples per klasse in evenwicht te houden, hoewel het niet vereist is om exact hetzelfde aantal samples per class te hebben. Vervolgens uploaden we de test.csv annotatiesbestand en alle documenten in Amazon S3. De volgende afbeelding toont een deel van ons CSV-bestand met annotaties.
Train een aangepast classificatiemodel
Nu we het annotatiebestand en al onze voorbeelddocumenten klaar hebben, zetten we een aangepast classificatiemodel op en trainen we dit. Voordat u begint met het opzetten van aangepaste classificatiemodeltraining, moet u ervoor zorgen dat de annotaties CSV en voorbeelddocumenten aanwezig zijn op een Amazon S3-locatie.
- Kies op de Amazon Comprehend-console Aangepaste classificatie in het navigatievenster.
- Kies Nieuw model maken.

- Voor Modelnaam, voer een unieke naam in.
- Voor Versie naam, voer een unieke versienaam in.
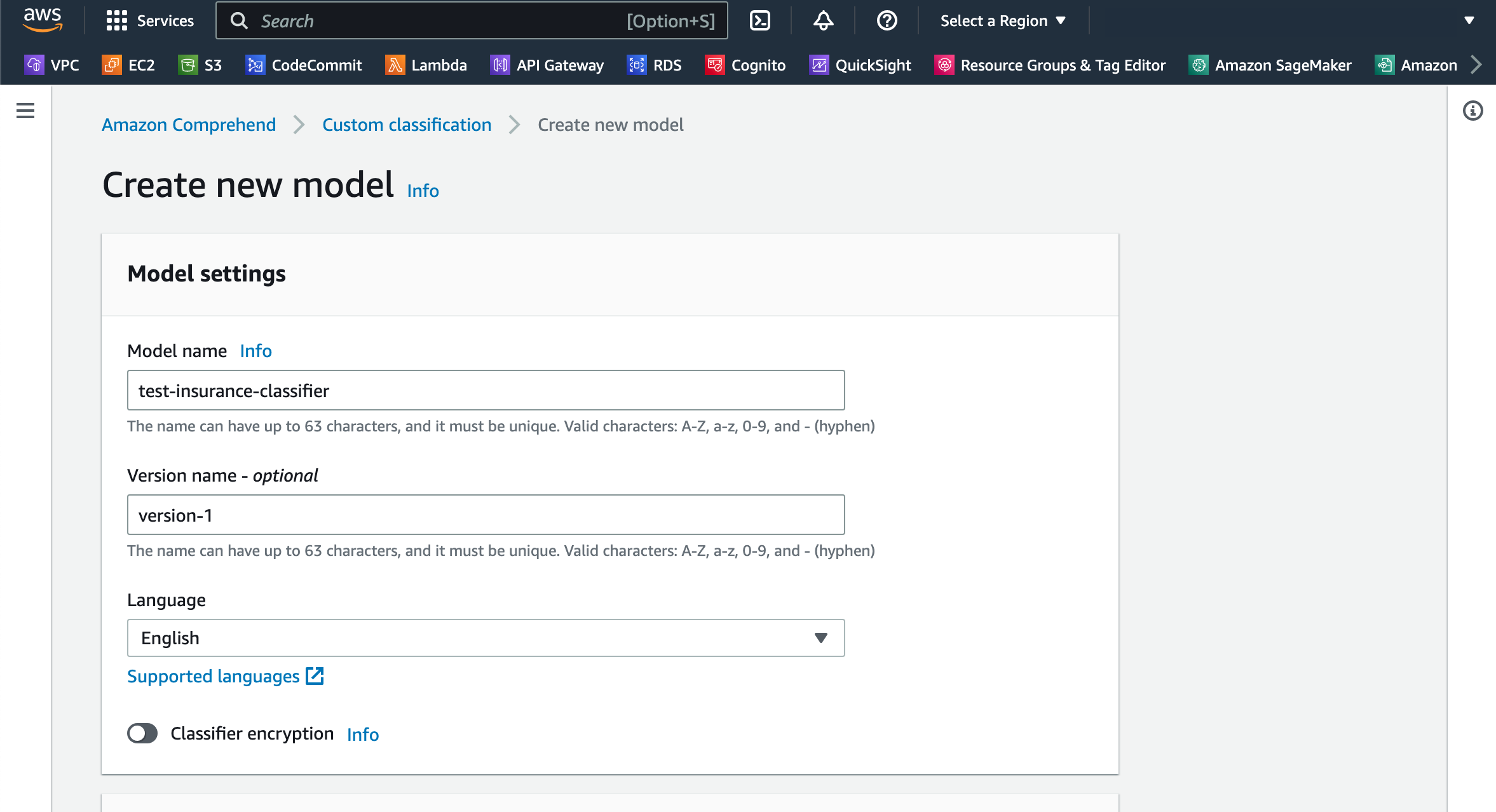
- Voor Type trainingsmodelselecteer Inheemse documenten.
Dit vertelt Amazon Comprehend dat je van plan bent native documenttypes te gebruiken om het model te trainen in plaats van geserialiseerde tekst.
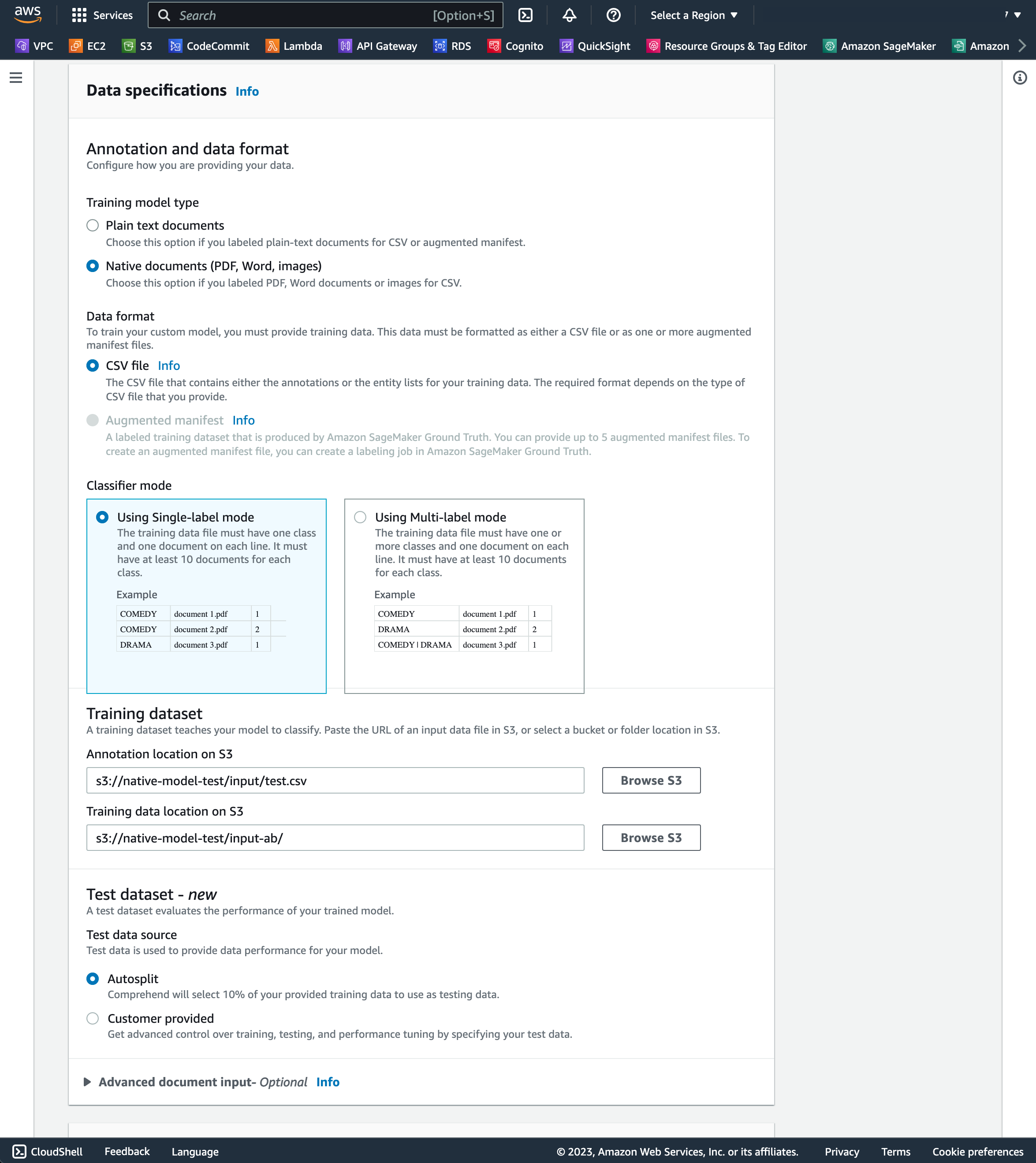
- Voor Classificatiemodusselecteer Single-label-modus gebruiken.
Deze modus vertelt de classificator dat we van plan zijn documenten in een enkele klasse te classificeren. Als u een model moet trainen met de modus voor meerdere labels, wat betekent dat een document tot een of meer klassen kan behoren, moet u het annotatiebestand op de juiste manier instellen door de klassen van het document op te geven, gescheiden door een speciaal teken in de annotaties CSV bestand. In dat geval kiest u voor de De modus voor meerdere labels gebruiken optie.
- Voor Annotatielocatie op S3, voer het pad van het CSV-bestand met annotaties in.
- Voor Locatie van trainingsgegevens op S3, voer de Amazon S3-locatie in waar uw documenten zich bevinden.
- Laat alle andere opties standaard in deze sectie.
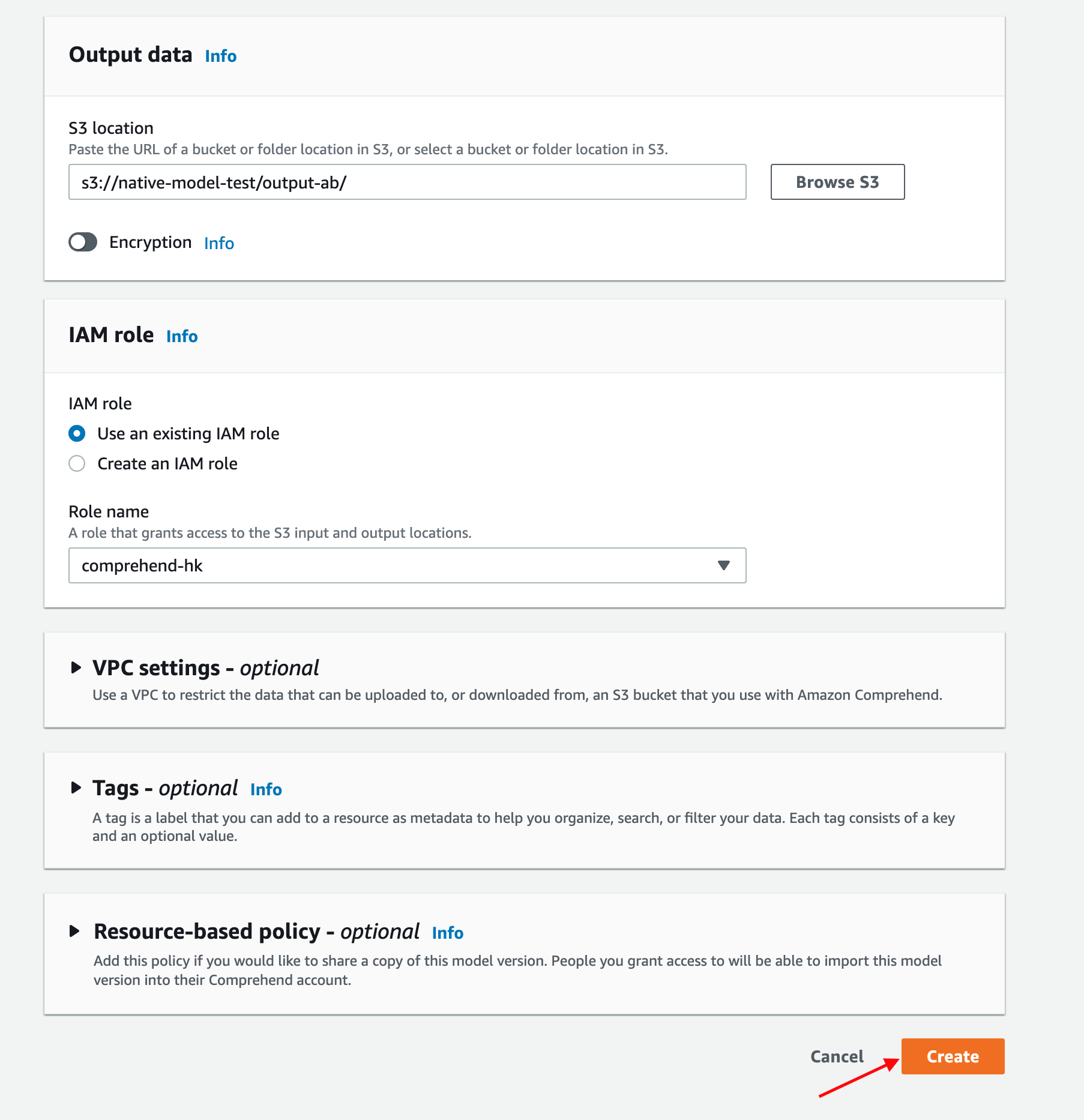
- In het Gegevens uitvoeren sectie, geeft u een Amazon S3-locatie op voor uw uitvoer.
Dit is optioneel, maar het is een goede gewoonte om een uitvoerlocatie op te geven, omdat Amazon Comprehend de trainingsevaluatiestatistieken na het model op deze locatie genereert. Deze gegevens zijn handig om modelprestaties te evalueren, te herhalen en de nauwkeurigheid van uw model te verbeteren.
- In het IAM-rol sectie, kies een geschikt AWS Identiteits- en toegangsbeheer (IAM) rol waarmee Amazon Comprehend toegang heeft tot de Amazon S3-locatie en er van kan schrijven en lezen.
- Kies creëren om de modeltraining te starten.
Het trainen van het model kan enkele minuten duren, afhankelijk van het aantal klassen en de grootte van de dataset. U kunt de trainingsstatus bekijken op de Aangepaste classificatie bladzijde. Het trainingsproces zal een Ingezonden status direct nadat het trainingsproces is gestart en verandert in Trainingen status wanneer het trainingsproces begint. Nadat uw model is getraind, wordt het Versiestatus zal veranderen in getraind. Als Amazon Comprehend inconsistenties vindt in uw trainingsgegevens, wordt de status weergegeven Ten onrechte samen met een waarschuwing die de juiste foutmelding toont, zodat u corrigerende maatregelen kunt nemen en het trainingsproces opnieuw kunt starten met de gecorrigeerde gegevens.
In dit bericht hebben we de stappen gedemonstreerd om een aangepast classificatiemodel te trainen met behulp van de Amazon Comprehend-console. U kunt ook de AWS-SDK in elke taal (bijvoorbeeld Boto3 voor Python) of de AWS-opdrachtregelinterface (AWS CLI) om een aangepaste classificatiemodeltraining te starten. Met de SDK of AWS CLI kunt u de CreateDocumentClassifier API om de modeltraining te initiëren en vervolgens de BeschrijfDocumentClassifier API om de status van het model te controleren.
Nadat het model is getraind, kunt u beide uitvoeren realtime analyse or asynchrone (batch) analysetaken op nieuwe documenten. Om real-time classificatie op documenten uit te voeren, moet u een Amazon Comprehend real-time eindpunt implementeren met het getrainde aangepaste classificatiemodel. Realtime eindpunten zijn het meest geschikt voor gebruiksscenario's die real-time gevolgtrekkingsresultaten met lage latentie vereisen, terwijl voor het classificeren van een grote reeks documenten een asynchrone analysetaak geschikter is. Voor meer informatie over het uitvoeren van asynchrone gevolgtrekkingen op nieuwe documenten met behulp van een getraind classificatiemodel, raadpleegt u Introductie van classificatie in één stap en entiteitsherkenning met Amazon Comprehend voor intelligente documentverwerking.
Voordelen van het lay-outbewuste aangepaste classificatiemodel
Het nieuwe classificatiemodel biedt een aantal verbeteringen. Het is niet alleen makkelijker om het nieuwe model te trainen, maar je kunt ook een nieuw model trainen met slechts een paar voorbeelden voor elke klas. Bovendien hoeft u niet langer geserialiseerde platte tekst uit gescande of digitale documenten zoals afbeeldingen of pdf's te extraheren om de trainingsdataset voor te bereiden. Hieronder volgen enkele aanvullende opmerkelijke verbeteringen die u kunt verwachten van het nieuwe classificatiemodel:
- Verbeterde nauwkeurigheid – Het model houdt nu rekening met de lay-out en structuur van documenten, wat leidt tot een beter begrip van de structuur en inhoud van de documenten. Dit helpt onderscheid te maken tussen documenten met vergelijkbare tekst maar verschillende lay-outs of structuren, wat resulteert in een grotere classificatienauwkeurigheid.
- robuustheid – Het model verwerkt nu variaties in documentstructuur en opmaak. Dit maakt het beter geschikt voor het classificeren van documenten uit verschillende bronnen met verschillende lay-outs of opmaakstijlen, wat een veelvoorkomende uitdaging is bij documentclassificatietaken in de echte wereld. Het is standaard compatibel met verschillende documenttypen, waardoor het veelzijdig en toepasbaar is in verschillende industrieën en use-cases.
- Minder handmatige tussenkomst – Hogere nauwkeurigheid leidt tot minder handmatige tussenkomst in het classificatieproces. Dit kan tijd en middelen besparen en de operationele efficiëntie van uw documentverwerkingswerklast verhogen.
Conclusie
Het nieuwe documentclassificatiemodel van Amazon Comprehend, dat lay-outbewustzijn omvat, is een doorbraak voor bedrijven die met grote hoeveelheden documenten te maken hebben. Door de structuur en lay-out van documenten te begrijpen, biedt dit model verbeterde classificatienauwkeurigheid en efficiëntie. Het implementeren van een robuuste en nauwkeurige oplossing voor documentclassificatie met behulp van een lay-outbewust model kan uw bedrijf helpen tijd te besparen, operationele kosten te verlagen en besluitvormingsprocessen te verbeteren.
Als volgende stap raden we je aan om het nieuwe aangepaste classificatiemodel van Amazon Comprehend te proberen via de Amazon begrijpt console. We raden ook aan om onze aangepaste classificatiemodelverbeteringsaankondigingen van opnieuw te bekijken afgelopen jaar en bezoek de GitHub-repository voor codevoorbeelden.
Over de auteurs
 Anjan Biswas is een Senior AI Services Solutions Architect met een focus op AI/ML en Data Analytics. Anjan maakt deel uit van het wereldwijde AI-serviceteam en werkt samen met klanten om hen te helpen bij het begrijpen en ontwikkelen van oplossingen voor zakelijke problemen met AI en ML. Anjan heeft meer dan 14 jaar ervaring in het werken met wereldwijde supply chain-, productie- en retailorganisaties en helpt klanten actief om aan de slag te gaan en op te schalen met AWS AI-services.
Anjan Biswas is een Senior AI Services Solutions Architect met een focus op AI/ML en Data Analytics. Anjan maakt deel uit van het wereldwijde AI-serviceteam en werkt samen met klanten om hen te helpen bij het begrijpen en ontwikkelen van oplossingen voor zakelijke problemen met AI en ML. Anjan heeft meer dan 14 jaar ervaring in het werken met wereldwijde supply chain-, productie- en retailorganisaties en helpt klanten actief om aan de slag te gaan en op te schalen met AWS AI-services.
 Godwin Sahayaraj Vincent is een Enterprise Solutions Architect bij AWS met een passie voor Machine Learning en het bieden van begeleiding aan klanten bij het ontwerpen, implementeren en beheren van hun AWS-workloads en architecturen. In zijn vrije tijd speelt hij graag cricket met zijn vrienden en tennis met zijn drie kinderen.
Godwin Sahayaraj Vincent is een Enterprise Solutions Architect bij AWS met een passie voor Machine Learning en het bieden van begeleiding aan klanten bij het ontwerpen, implementeren en beheren van hun AWS-workloads en architecturen. In zijn vrije tijd speelt hij graag cricket met zijn vrienden en tennis met zijn drie kinderen.
 Wrick Talukdar is een Senior Architect bij het Amazon Comprehend Service-team. Hij werkt samen met AWS-klanten om hen te helpen machine learning op grote schaal toe te passen. Naast zijn werk houdt hij van lezen en fotograferen.
Wrick Talukdar is een Senior Architect bij het Amazon Comprehend Service-team. Hij werkt samen met AWS-klanten om hen te helpen machine learning op grote schaal toe te passen. Naast zijn werk houdt hij van lezen en fotograferen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/amazon-comprehend-document-classifier-adds-layout-support-for-higher-accuracy/

