Dit bericht is geschreven in samenwerking met Sherwin Chu van Alida.
Alida helpt 's werelds grootste merken zeer betrokken onderzoeksgemeenschappen te creëren om feedback te verzamelen die betere klantervaringen en productinnovatie stimuleert.
De klanten van Alida ontvangen tienduizenden betrokken reacties op één enkele enquête. Daarom heeft het Alida-team ervoor gekozen machine learning (ML) in te zetten om hun klanten op grote schaal te bedienen. Toen ze echter gebruik maakten van traditionele modellen voor natuurlijke taalverwerking (NLP), ontdekten ze dat deze oplossingen moeite hadden om de genuanceerde feedback uit de antwoorden op open enquêtes volledig te begrijpen. De modellen legden vaak alleen oppervlakkige onderwerpen en sentimenten vast, en misten de cruciale context die nauwkeurigere en betekenisvollere inzichten mogelijk zou maken.
In dit bericht leren we hoe het Claude Instant-model van Anthropic werkt Amazonebodem stelde het Alida-team in staat snel een schaalbare service te bouwen die het onderwerp en sentiment binnen complexe enquêtereacties nauwkeuriger bepaalt. De nieuwe service zorgde voor een vier tot zes keer betere onderwerpbevestiging door strak te clusteren op enkele tientallen belangrijke onderwerpen versus honderden luidruchtige NLP-trefwoorden.
Amazon Bedrock is een volledig beheerde service die via één API een keuze biedt uit goed presterende funderingsmodellen (FM's) van toonaangevende AI-bedrijven, zoals AI21 Labs, Anthropic, Cohere, Meta, Stability AI en Amazon, samen met een brede reeks mogelijkheden die u nodig hebt om generatieve AI-applicaties te bouwen met beveiliging, privacy en verantwoorde AI.
Door Amazon Bedrock te gebruiken, kon Alida hun service sneller op de markt brengen dan wanneer ze andere aanbieders of leveranciers van machine learning (ML) hadden gebruikt.
De uitdaging
Enquêtes met een combinatie van meerkeuzevragen en open vragen stellen marktonderzoekers in staat een meer holistisch beeld te krijgen door zowel kwantitatieve als kwalitatieve gegevenspunten vast te leggen.
Meerkeuzevragen zijn gemakkelijk op grote schaal te analyseren, maar missen nuance en diepgang. Ingestelde antwoordopties kunnen ook leiden tot vertekenende of priming-reacties van deelnemers.
Met open enquêtevragen kunnen respondenten context en onverwachte feedback geven. Deze kwalitatieve gegevenspunten verdiepen het begrip van onderzoekers verder dan wat meerkeuzevragen alleen kunnen vastleggen. De uitdaging met de vrije tekst is dat deze kan leiden tot complexe en genuanceerde antwoorden die voor traditionele NLP moeilijk volledig te begrijpen zijn. Bijvoorbeeld:
“Ik heb onlangs een aantal ontberingen van het leven meegemaakt en was erg neerslachtig en teleurgesteld. Toen ik binnenkwam, was het personeel altijd erg aardig voor me. Het heeft mij door een aantal moeilijke tijden heen geholpen!”
Traditionele NLP-methoden identificeren onderwerpen als ‘ontberingen’, ‘teleurgesteld’, ‘vriendelijk personeel’ en ‘door moeilijke tijden komen’. Er kan geen onderscheid worden gemaakt tussen de algehele huidige negatieve levenservaringen van de responder en de specifieke positieve winkelervaringen.
De bestaande oplossing van Alida verwerkte automatisch grote hoeveelheden open antwoorden, maar ze wilden dat hun klanten een beter contextueel begrip zouden krijgen en op een hoger niveau konden infereren over onderwerpen.
Amazonebodem
Vóór de introductie van LLM's was de weg voorwaarts voor Alida om hun bestaande oplossing met één model te verbeteren, nauw samen te werken met experts uit de industrie en nieuwe modellen te ontwikkelen, trainen en verfijnen, specifiek voor elk van de verticale sectoren waarin Alida's klanten actief waren. Dit was zowel een tijd- als een kostenintensieve onderneming.
Een van de doorbraken die LLM’s zo krachtig maken, is het gebruik van aandachtsmechanismen. LLM's gebruiken zelfaandachtsmechanismen die de relaties tussen woorden in een bepaalde prompt analyseren. Hierdoor kunnen LLM's beter omgaan met het onderwerp en sentiment uit het eerdere voorbeeld en wordt een opwindende nieuwe technologie gepresenteerd die kan worden gebruikt om de uitdaging aan te gaan.
Met Amazon Bedrock kunnen teams en individuen onmiddellijk basismodellen gaan gebruiken, zonder zich zorgen te hoeven maken over het inrichten van infrastructuur of het opzetten en configureren van ML-frameworks. U kunt aan de slag met de volgende stappen:
- Controleer of uw gebruiker of rol toestemming heeft om Amazon Bedrock-bronnen te maken of te wijzigen. Voor details, zie Op identiteit gebaseerde beleidsvoorbeelden voor Amazon Bedrock
- Log in op de Amazonebodem console.
- Op de Toegang tot modellen pagina, bekijk de EULA en schakel de gewenste FM's in uw account in.
- Begin met de interactie met de FM's via de volgende methoden:
Het managementteam van Alida wilde graag een early adopter zijn van Amazon Bedrock, omdat ze erkenden dat het in staat was hun teams te helpen nieuwe generatieve AI-aangedreven oplossingen sneller op de markt te brengen.
Vincy William, de Senior Director of Engineering bij Alida en die leiding geeft aan het team dat verantwoordelijk is voor het bouwen van de dienst voor onderwerp- en sentimentanalyse, zegt:
“LLM's bieden een grote sprong voorwaarts in kwalitatieve analyse en doen dingen (op een schaal die menselijkerwijs niet mogelijk is). Amazon Bedrock is een game changer, het stelt ons in staat om LLM’s te benutten zonder de complexiteit.”
Het technische team ervoer het onmiddellijke gemak om aan de slag te gaan met Amazon Bedrock. Ze konden kiezen uit verschillende basismodellen en zich gaan richten op snelle engineering in plaats van tijd te besteden aan het op maat maken, inrichten, inzetten en configureren van resources om de modellen uit te voeren.
Overzicht oplossingen
Sherwin Chu, hoofdarchitect van Alida, deelde de microservices-architectuuraanpak van Alida. Alida heeft de onderwerp- en sentimentclassificatie ontwikkeld als een service, met enquêteresponsanalyse als eerste toepassing. Met deze aanpak worden algemene uitdagingen bij de LLM-implementatie, zoals de complexiteit van het beheer van prompts, tokenlimieten, verzoekbeperkingen en nieuwe pogingen, weggenomen, en zorgt de oplossing ervoor dat verbruikende applicaties over een eenvoudige en stabiele API kunnen beschikken om mee te werken. Deze abstractielaagbenadering stelt de service-eigenaren ook in staat om voortdurend de interne implementatiedetails te verbeteren en API-brekende wijzigingen te minimaliseren. Ten slotte maakt de servicebenadering het mogelijk om op één enkel punt elk databeheer- en beveiligingsbeleid te implementeren dat evolueert naarmate het AI-beheer in de organisatie volwassener wordt.
Het volgende diagram illustreert de oplossingsarchitectuur en -stroom.
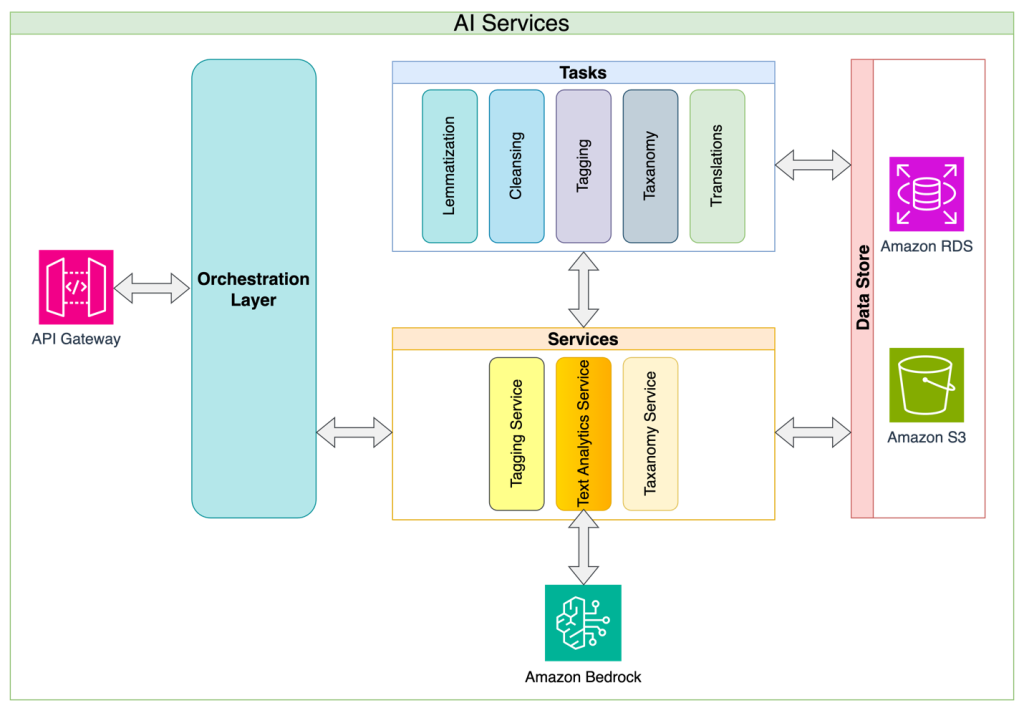
Alida evalueerde LLM's van verschillende aanbieders en vond Claude Instant van Anthropic de juiste balans tussen kosten en prestaties. In nauwe samenwerking met het snelle engineeringteam pleitte Chu voor de implementatie van een snelle ketenstrategie, in tegenstelling tot een snelle aanpak met één enkele monoliet.
Met promptchaining kunt u het volgende doen:
- Verdeel uw doelstelling in kleinere, logische stappen
- Maak voor elke stap een prompt
- Geef de aanwijzingen opeenvolgend door aan de LLM
Hierdoor ontstaan extra inspectiepunten, wat de volgende voordelen heeft:
- Het is eenvoudig om de wijzigingen die u aanbrengt in de invoerprompt systematisch te evalueren
- U kunt bij elke stap een gedetailleerdere tracking en monitoring van de nauwkeurigheid en prestaties implementeren
Belangrijke overwegingen bij deze strategie zijn onder meer de toename van het aantal verzoeken aan de LLM en de daaruit voortvloeiende toename van de totale tijd die nodig is om de doelstelling te bereiken. Voor Alida's gebruiksscenario kozen ze ervoor om een verzameling open antwoorden in één enkele prompt aan de LLM te groeperen, wat ze kozen om deze effecten te compenseren.
NLP versus LLM
De bestaande NLP-oplossing van Alida is gebaseerd op clusteralgoritmen en statistische classificatie om open enquêtereacties te analyseren. Wanneer het werd toegepast op voorbeeldfeedback voor de mobiele app van een coffeeshop, werden onderwerpen geëxtraheerd op basis van woordpatronen, maar het ontbrak aan echt begrip. De volgende tabel bevat enkele voorbeelden waarin NLP-reacties worden vergeleken met LLM-reacties.
| Enquêtereactie | Bestaande traditionele NLP | Amazon Bedrock met Claude Instant | |
| Thema | Thema | Sentiment | |
| Ik bestel mijn drankjes bijna uitsluitend via de app, voor het gemak en het is minder gênant om super op maat gemaakte drankjes te bestellen lol. En ik vind het leuk om beloningen te verdienen! | ['app bc gemak', 'drinken', 'beloning'] | Mobiel bestelgemak | positief |
| De app werkt redelijk goed, de enige klacht die ik heb is dat ik niet het gewenste bedrag aan mijn cadeaubon kan toevoegen. Waarom moet het specifiek $ 10 zijn om bij te vullen? | ['klacht', 'app', 'cadeaubon', 'nummergeld'] | Mobiele orderverwerkingssnelheid | negatief |
De voorbeeldresultaten laten zien hoe de bestaande oplossing relevante zoekwoorden kon extraheren, maar niet in staat was een meer algemene onderwerpgroeptoewijzing te realiseren.
Met behulp van Amazon Bedrock en Anthropic Claude Instant kan de LLM met in-contexttraining daarentegen de antwoorden toewijzen aan vooraf gedefinieerde onderwerpen en sentiment toewijzen.
Naast het bieden van betere antwoorden aan de klanten van Alida, bespaarde het zoeken naar een oplossing met behulp van een LLM in plaats van traditionele NLP-methoden voor deze specifieke gebruikssituatie een enorme hoeveelheid tijd en moeite in het trainen en onderhouden van een geschikt model. De volgende tabel vergelijkt het trainen van een traditioneel NLP-model met de in-contexttraining van een LLM.
| . | Gegevensvereiste: | Opleidingsproces | Aanpassingsvermogen van modellen |
| Trainen van een traditioneel NLP-model | Duizenden met mensen gelabelde voorbeelden |
Combinatie van geautomatiseerde en handmatige feature-engineering. Iteratieve trein- en evaluatiecycli. |
Langzamere doorlooptijd vanwege de noodzaak om het model opnieuw te trainen |
| In-context training van LLM | Verschillende voorbeelden |
On-the-fly getraind binnen de prompt. Beperkt door de grootte van het contextvenster. |
Snellere iteraties door de prompt aan te passen. Beperkte retentie vanwege de contextvenstergrootte. |
Conclusie
Alida's gebruik van het Claude Instant-model van Anthropic op Amazon Bedrock demonstreert de krachtige mogelijkheden van LLM's voor het analyseren van open enquêtereacties. Alida was in staat een superieure service op te bouwen die vier tot zes keer nauwkeuriger was in onderwerpanalyse vergeleken met hun NLP-aangedreven service. Bovendien verkortte het gebruik van in-context prompt engineering voor LLM's de ontwikkeltijd aanzienlijk, omdat ze geen duizenden door mensen gelabelde datapunten hoefden te beheren om een traditioneel NLP-model te trainen. Hierdoor kan Alida haar klanten uiteindelijk sneller rijkere inzichten geven!
Als je klaar bent om te beginnen met het bouwen van je eigen basismodelinnovatie met Amazon Bedrock, bekijk dan deze link naar Stel Amazon Bedrock in. Als je meer wilt lezen over andere intrigerende Amazon Bedrock-applicaties, kijk dan op de specifieke sectie Amazon Bedrock van de AWS Machine Learning-blog.
Over de auteurs
 Kinman Lam is een ISV/DNB Solution Architect voor AWS. Hij heeft 17 jaar ervaring in het bouwen en laten groeien van technologiebedrijven op het gebied van smartphones, geolocatie, IoT en open source software. Bij AWS gebruikt hij zijn ervaring om bedrijven te helpen een robuuste infrastructuur op te bouwen om aan de toenemende eisen van groeiende bedrijven te voldoen, nieuwe producten en diensten te lanceren, nieuwe markten te betreden en hun klanten tevreden te stellen.
Kinman Lam is een ISV/DNB Solution Architect voor AWS. Hij heeft 17 jaar ervaring in het bouwen en laten groeien van technologiebedrijven op het gebied van smartphones, geolocatie, IoT en open source software. Bij AWS gebruikt hij zijn ervaring om bedrijven te helpen een robuuste infrastructuur op te bouwen om aan de toenemende eisen van groeiende bedrijven te voldoen, nieuwe producten en diensten te lanceren, nieuwe markten te betreden en hun klanten tevreden te stellen.
 Sherwin Chu is de hoofdarchitect bij Alida en helpt productteams met architecturale richting, technologiekeuze en het oplossen van complexe problemen. Hij is een ervaren software-ingenieur, architect en leider met meer dan 20 jaar ervaring in de SaaS-ruimte voor verschillende industrieën. Hij heeft talloze B2B- en B2C-systemen gebouwd en beheerd op AWS en GCP.
Sherwin Chu is de hoofdarchitect bij Alida en helpt productteams met architecturale richting, technologiekeuze en het oplossen van complexe problemen. Hij is een ervaren software-ingenieur, architect en leider met meer dan 20 jaar ervaring in de SaaS-ruimte voor verschillende industrieën. Hij heeft talloze B2B- en B2C-systemen gebouwd en beheerd op AWS en GCP.
 Marc Roy is een Principal Machine Learning Architect voor AWS en helpt klanten bij het ontwerpen en bouwen van AI/ML en generatieve AI-oplossingen. Sinds begin 2023 richt hij zich op het leiden van oplossingsarchitectuurinspanningen voor de lancering van Amazon Bedrock, het vlaggenschip van AWS op het gebied van generatieve AI voor bouwers. Het werk van Mark omvat een breed scala aan gebruiksscenario's, met een primaire interesse in generatieve AI, agenten en het opschalen van ML binnen de hele onderneming. Hij heeft bedrijven geholpen in de verzekeringssector, financiële dienstverlening, media en entertainment, gezondheidszorg, nutsvoorzieningen en productie. Voordat hij bij AWS kwam, was Mark ruim 25 jaar architect, ontwikkelaar en technologieleider, waarvan 19 jaar in de financiële dienstverlening. Mark heeft zes AWS-certificeringen, waaronder de ML Specialty-certificering.
Marc Roy is een Principal Machine Learning Architect voor AWS en helpt klanten bij het ontwerpen en bouwen van AI/ML en generatieve AI-oplossingen. Sinds begin 2023 richt hij zich op het leiden van oplossingsarchitectuurinspanningen voor de lancering van Amazon Bedrock, het vlaggenschip van AWS op het gebied van generatieve AI voor bouwers. Het werk van Mark omvat een breed scala aan gebruiksscenario's, met een primaire interesse in generatieve AI, agenten en het opschalen van ML binnen de hele onderneming. Hij heeft bedrijven geholpen in de verzekeringssector, financiële dienstverlening, media en entertainment, gezondheidszorg, nutsvoorzieningen en productie. Voordat hij bij AWS kwam, was Mark ruim 25 jaar architect, ontwikkelaar en technologieleider, waarvan 19 jaar in de financiële dienstverlening. Mark heeft zes AWS-certificeringen, waaronder de ML Specialty-certificering.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/alida-gains-deeper-understanding-of-customer-feedback-with-amazon-bedrock/

