Amazon Kendra is een zeer nauwkeurige en gebruiksvriendelijke intelligente zoekservice die wordt aangedreven door machine learning (ML). Amazon Kendra biedt een reeks gegevensbronconnectoren om het proces van het opnemen en indexeren van uw inhoud te vereenvoudigen, waar deze zich ook bevindt.
Waardevolle data in organisaties wordt opgeslagen in zowel gestructureerde als ongestructureerde repositories. Amazon Kendra kan gegevens uit verschillende gestructureerde en ongestructureerde kennisbankrepository's samenbrengen om te indexeren en te doorzoeken.
Een van die kennisbanken is Microsoft SharePoint, en we zijn verheugd aan te kondigen dat we de SharePoint-connector voor Amazon Kendra hebben bijgewerkt om nog meer mogelijkheden toe te voegen. In deze nieuwe versie (V2.0) hebben we ondersteuning toegevoegd voor SharePoint Subscription Edition en meerdere verificatie- en synchronisatiemodi om inhoud te indexeren op basis van nieuwe, gewijzigde of verwijderde inhoud.
U kunt nu ook OAuth 2.0 kiezen om te authenticeren met SharePoint Online. Er zijn meerdere synchronisatieopties beschikbaar om uw index bij te werken wanneer de inhoud van uw gegevensbron verandert. U kunt de zoekresultaten filteren op basis van de gebruikers- en groepsinformatie om ervoor te zorgen dat uw zoekresultaten alleen worden weergegeven op basis van gebruikerstoegangsrechten.
In dit bericht laten we zien hoe u inhoud van SharePoint kunt indexeren met behulp van de Amazon Kendra SharePoint-connector V2.0.
Overzicht oplossingen
U kunt Amazon Kendra gebruiken als centrale locatie om de inhoud van verschillende gegevensbronnen te indexeren voor intelligent zoeken. In de volgende secties doorlopen we de stappen om een index te maken, de SharePoint-connector toe te voegen en de oplossing te testen.
Voorwaarden
Om te beginnen heb je het volgende nodig:
Maak een Amazon Kendra-index
Voer de volgende stappen uit om een Amazon Kendra-index te maken:
- Kies op de Amazon Kendra-console Maak een index.

- Voor Indexnaam, voer een naam in voor de index (bijvoorbeeld
my-sharepoint-index). - Voer een optionele beschrijving in.
- Kies Maak een nieuwe rol.
- Voor Rol naam, voer een IAM-rolnaam in.
- Configureer optionele coderingsinstellingen en tags.
- Kies Volgende.

- Voor Instellingen voor toegangscontrole, kiezen Ja.
- Voor Tokenconfiguratie, stel in Tokentype naar JSON en laat de standaardwaarden voor Gebruikersnaam en Groepen.
- Voor Uitbreiding gebruikersgroep, laat de standaardwaarden staan.
- Kies Volgende.

- Voor Specificeer inrichtingselecteer Developer-editie, die geschikt is voor het bouwen van een proof of concept en experimenten, en kies creëren.

Voeg een SharePoint-gegevensbron toe aan uw Amazon Kendra-index
Een van de voordelen van het implementeren van Amazon Kendra is dat u een set vooraf gebouwde connectoren kunt gebruiken voor gegevensbronnen zoals Amazon eenvoudige opslagservice (Amazone S3), Amazon relationele databaseservice (Amazon RDS), SharePoint Online en Salesforce.
Voer de volgende stappen uit om een SharePoint-gegevensbron aan uw index toe te voegen:
- Navigeer op de Amazon Kendra-console naar de index die u hebt gemaakt.
- Kies Data bronnen in het navigatievenster.
- Onder SharePoint-connector V2.0, kiezen Connector toevoegen.

- Voor Naam gegevensbron, voer een naam in (bijvoorbeeld
my-sharepoint-data-source). - Voer een optionele beschrijving in.
- Kies Engels (nl) For Standaard taal.
- Voer optionele tags in.
- Kies Volgende.

Kies de juiste hostingmethode, afhankelijk van de hostingoptie die uw SharePoint-toepassing gebruikt. De vereiste kenmerken voor de connectorconfiguratie worden weergegeven op basis van de hostingmethode die u kiest.
- Als u selecteert SharePoint Online, voert u de volgende stappen uit:
- Voer de URL in voor uw SharePoint Online-repository.
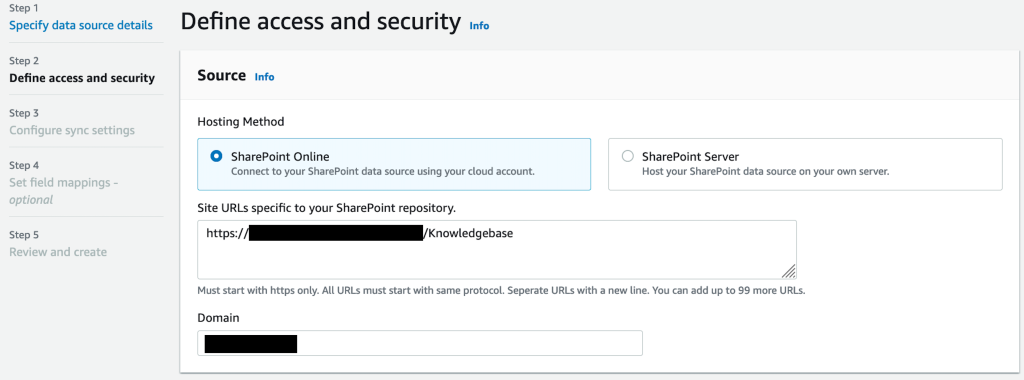
- Kies uw authenticatie-optie (deze authenticatiegegevens worden door de SharePoint-connector gebruikt om te integreren met uw SharePoint-toepassing).
- Voer de Tenant-ID van uw SharePoint Online-toepassing in.
- Voor AWS Secrets Manager geheim, kies het geheim met inloggegevens voor de SharePoint Online-toepassing of maak een nieuw geheim en voeg de verbindingsdetails toe (bijvoorbeeld
AmazonKendra-SharePoint-my-sharepoint-online-secret).
- Voer de URL in voor uw SharePoint Online-repository.
Om meer te leren over AWS Secrets Manager, verwijzen naar Aan de slag met Secrets Manager.
De SharePoint-connector gebruikt de clientId, clientSecret, userName en password informatie om te verifiëren met de SharePoint Online-toepassing. Deze gegevens zijn te vinden op de App-registraties pagina op de Azure-portal, als de SharePoint Online-toepassing al is geregistreerd.

- Als u selecteert SharePoint-server, voert u de volgende stappen uit:
- Kies je SharePoint-versie (we gebruiken bijvoorbeeld SharePoint 2019 voor deze post).
- Voer de site-URL voor uw SharePoint Server-opslagplaats in.
- Voor Locatie van SSL-certificaat, voer het pad in naar het S3-bucketbestand waar het SharePoint Server SSL-certificaat zich bevindt.

- Voer de hostnaam van de webproxy en het poortnummer in als de SharePoint-server een proxyverbinding vereist.
Voor dit bericht wordt geen webproxy gebruikt omdat de SharePoint-toepassing die voor dit voorbeeld wordt gebruikt, een openbare toepassing is.
-
- Selecteer de autorisatieoptie voor de configuratie van de toegangsbeheerlijst (ACL).

- Selecteer de autorisatieoptie voor de configuratie van de toegangsbeheerlijst (ACL).
Deze authenticatiegegevens worden door de SharePoint-connector gebruikt om te integreren met uw SharePoint-instantie.
- Voor AWS Secrets Manager geheim, kies het geheim dat SharePoint Server-referenties heeft of maak een nieuw geheim en voeg de verbindingsdetails toe (bijvoorbeeld
AmazonKendra-my-sharepoint-server-secret).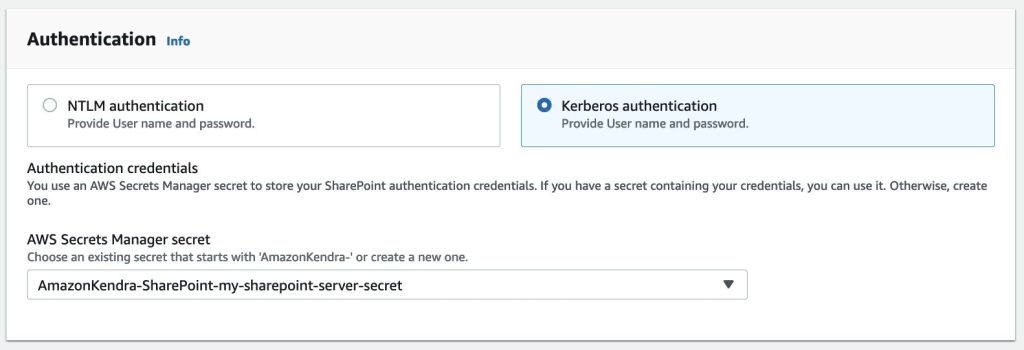
De SharePoint-connector gebruikt de gebruikersnaam en het wachtwoord om te verifiëren met de SharePoint Server-toepassing. Als u een e-mail-ID met domeinformulier IDP als ACL-instelling gebruikt, zijn ook het LDAP-servereindpunt, de zoekbasis, de LDAP-gebruikersnaam en het LDAP-wachtwoord vereist.
Om een gedetailleerd niveau van controle over de doorzoekbare en weer te geven inhoud te bereiken, is de identiteitscrawlerfunctionaliteit geïntroduceerd in de SharePoint-connector V2.0.
- Schakel de identiteitscrawler in en selecteer Crawl lokale groepstoewijzing en Crawl AD-groepstoewijzing.

- Voor Virtuele privécloud (VPC), kies de VPC waarmee de SharePoint-toepassing bereikbaar is vanaf uw SharePoint-connector.
Voor dit bericht kiezen we Geen VPC omdat de SharePoint-toepassing die voor dit voorbeeld wordt gebruikt, een openbare toepassing is waarop is geïmplementeerd Amazon Elastic Compute-cloud (Amazon EC2) -instanties.
- Chose Een nieuwe rol maken (aanbevolen) en geef een rolnaam op, zoals
AmazonKendra-sharepoint-v2. - Kies Volgende.

- Selecteer entiteiten die u wilt opnemen voor indexering. Je kan kiezen Alles of specifieke entiteiten op basis van uw use case. Voor deze post kiezen we Alles.
U kunt ook documenten opnemen of uitsluiten door reguliere expressies te gebruiken. U kunt patronen definiëren die Amazon Kendra gebruikt om bepaalde documenten uit te sluiten van indexering of om alleen documenten met dat patroon op te nemen. Voor meer informatie, zie SharePoint-configuratie.
- Selecteer uw synchronisatiemodus om de index bij te werken wanneer de inhoud van uw gegevensbron verandert.
U kunt alle inhoud in alle entiteiten synchroniseren en indexeren, ongeacht het vorige synchronisatieproces door te selecteren Volledige synchronisatie, of synchroniseer alleen nieuwe, gewijzigde of verwijderde inhoud, of synchroniseer alleen nieuwe of gewijzigde inhoud. Voor deze post selecteren we Volledige synchronisatie.
- Kies een frequentie om het synchronisatieschema uit te voeren, zoals Rennen op aanvraag.
- Kies Volgende.

In deze volgende stap kunt u veldtoewijzingen maken om een extra laag metadata aan uw documenten toe te voegen. Hierdoor kunt u de nauwkeurigheid verbeteren door middel van handmatige afstemming, filteringen facetten.
- Bekijk de standaardveldtoewijzingsinformatie en kies Volgende.

- Bekijk als laatste stap de configuratiedetails en kies Gegevensbron toevoegen om de gegevensbron van de SharePoint-connector te maken voor de Amazon Kendra-index.
Test de oplossing
Nu bent u klaar om de Amazon Kendra-zoekfuncties voor te bereiden en te testen met behulp van de SharePoint-connector.
Voor deze post worden AWS Getting Started-documenten toegevoegd aan de SharePoint-gegevensbron. De voorbeelddataset die voor dit bericht is gebruikt, kan worden gedownload van AWS_Whitepapers.zip. Deze dataset bevat PDF-documenten die zijn gecategoriseerd in meerdere mappen op basis van het type document (bijvoorbeeld documenten met betrekking tot AWS-databaseopties, beveiliging en ML).
Ook zijn voorbeeldgegevenssetmappen in SharePoint geconfigureerd met e-mail-ID's van gebruikers en groepsdetails, zodat alleen de gebruikers en groepen met machtigingen toegang hebben tot specifieke mappen of individuele bestanden.
Om controle op granulair niveau over de zoekresultaten te krijgen, crawlt de SharePoint-connector de lokale of Active Directory (AD) groepstoewijzing in de SharePoint-gegevensbron naast de inhoud wanneer de identiteitscrawler is ingeschakeld met de lokale en AD-groepstoewijzingsopties geselecteerd . Met deze mogelijkheid is door Amazon Kendra geïndexeerde inhoud doorzoekbaar en weer te geven op basis van de toegangsbeheermachtigingen van de gebruikers en groepen.
Voer de volgende stappen uit om onze index te synchroniseren met SharePoint-inhoud:
- Navigeer op de Amazon Kendra-console naar de index die u hebt gemaakt.
- Kies Data bronnen in het navigatievenster en selecteer de SharePoint-gegevensbron.
- Kies Synchroniseer nu om het proces te starten om de inhoud van de SharePoint-toepassing te indexeren en wacht tot het proces is voltooid.
Als u synchronisatieproblemen ondervindt, raadpleegt u Problemen met gegevensbronnen oplossen voor meer informatie.
Wanneer het synchronisatieproces is geslaagd, wordt de waarde for Laatste synchronisatiestatus wordt ingesteld op Succesvol – service werkt normaal. De inhoud van de SharePoint-toepassing is nu geïndexeerd en klaar voor query's.
- Kies Doorzoek geïndexeerde inhoud (Onder Gegevensbeheer) in het navigatievenster.

- Voer een testquery in het zoekveld in en druk op Enter.
Een testquery zoals "Wat is de duurzaamheid van S3?" biedt de volgende door Amazon Kendra voorgestelde antwoorden. Houd er rekening mee dat de resultaten voor deze query afkomstig zijn van alle geïndexeerde inhoud. Dit komt omdat er geen context is van gebruikersnaam of groepsinformatie voor deze query.
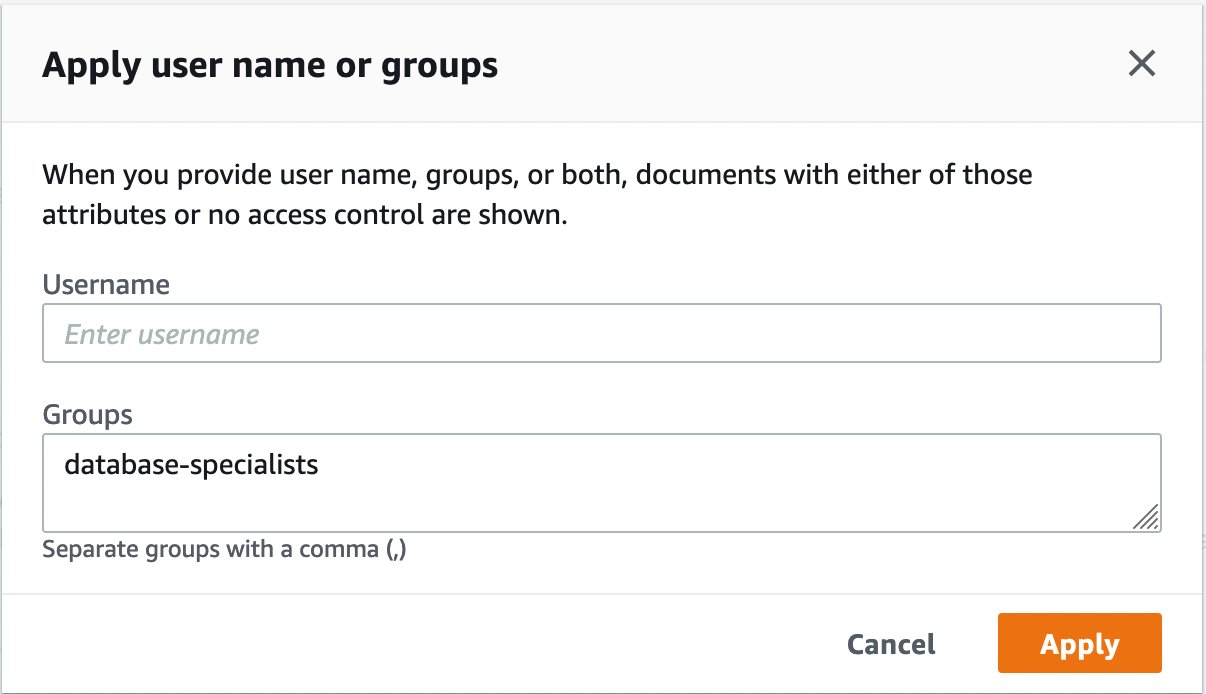
- Vouw uit om het zoeken met toegangsbeheer te testen Testquery met gebruikersnaam of groepen En kies Gebruikersnaam of groepen toepassen om een gebruikersnaam (e-mail-ID) of groepsinformatie toe te voegen.

Wanneer een Experience Builder-app wordt gebruikt, bevat deze de gebruikerscontext en hoeft u dus niet expliciet gebruikers- of groeps-ID's toe te voegen.
- Voor deze functie is toegang tot de databases-directory op de SharePoint-site alleen beschikbaar voor de groep databasespecialisten.
- Voer een nieuwe testquery in en druk op Enter.
In dit voorbeeld wordt alleen de inhoud in de map Databases doorzocht en worden de resultaten weergegeven. De groep database-specialisten heeft namelijk alleen toegang tot de directory Databases.
Gefeliciteerd! Je hebt met succes Amazon Kendra gebruikt om antwoorden en inzichten naar boven te halen op basis van de inhoud die is geïndexeerd vanuit je SharePoint-toepassing.
Amazon Kendra Experience-bouwer
U kunt een Amazon Kendra-zoektoepassing bouwen en implementeren zonder dat u enige front-endcode nodig heeft. Amazon Kendra Experience Builder helpt je met het bouwen en implementeren van een volledig functionele zoekapplicatie in een paar klikken, zodat je meteen kunt beginnen met zoeken.
Verwijzen naar Een zoekervaring bouwen zonder code voor meer informatie.
Opruimen
Om toekomstige kosten te voorkomen, ruimt u de bronnen op die u als onderdeel van deze oplossing hebt gemaakt. Als je tijdens het testen van deze oplossing een nieuwe Amazon Kendra-index hebt gemaakt, verwijder deze dan als je deze niet langer nodig hebt. Als u alleen een nieuwe gegevensbron hebt toegevoegd met behulp van de Amazon Kendra-connector voor SharePoint, verwijdert u die gegevensbron nadat uw oplossingsbeoordeling is voltooid.
Verwijzen naar Een index en gegevensbron verwijderen voor meer informatie.
Conclusie
In dit bericht hebben we laten zien hoe u documenten van uw SharePoint-toepassing kunt opnemen in uw Amazon Kendra-index. We hebben ook enkele van de nieuwe functies bekeken die zijn geïntroduceerd in de nieuwe versie van de SharePoint-connector.
Raadpleeg voor meer informatie over de Amazon Kendra-connector voor SharePoint Microsoft SharePoint-connector V2.0.
Vergeet ten slotte niet om de andere blogberichten over Amazon Kendra!
Over de auteur
 Udaya Jaladi is een Solutions Architect bij Amazon Web Services (AWS), gespecialiseerd in het assisteren van klanten van Independent Software Vendor (ISV). Met expertise op het gebied van cloudstrategieën, AI/ML-technologieën en operaties, fungeert Udaya als een vertrouwde adviseur voor leidinggevenden en ingenieurs, die gepersonaliseerde begeleiding biedt bij het maximaliseren van het potentieel van de cloud en het stimuleren van innovatieve productontwikkeling. Gebruikmakend van zijn achtergrond als Enterprise Architect (EA) in diverse bedrijfsdomeinen, blinkt Udaya uit in het ontwerpen van schaalbare cloudoplossingen die zijn toegesneden op de specifieke behoeften van ISV-klanten.
Udaya Jaladi is een Solutions Architect bij Amazon Web Services (AWS), gespecialiseerd in het assisteren van klanten van Independent Software Vendor (ISV). Met expertise op het gebied van cloudstrategieën, AI/ML-technologieën en operaties, fungeert Udaya als een vertrouwde adviseur voor leidinggevenden en ingenieurs, die gepersonaliseerde begeleiding biedt bij het maximaliseren van het potentieel van de cloud en het stimuleren van innovatieve productontwikkeling. Gebruikmakend van zijn achtergrond als Enterprise Architect (EA) in diverse bedrijfsdomeinen, blinkt Udaya uit in het ontwerpen van schaalbare cloudoplossingen die zijn toegesneden op de specifieke behoeften van ISV-klanten.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Koop en verkoop aandelen in PRE-IPO-bedrijven met PREIPO®. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/announcing-the-updated-microsoft-sharepoint-connector-v2-0-for-amazon-kendra/

