De snelle wereld van vandaag vereist tijdige inzichten en beslissingen, wat het belang van het streamen van gegevens vergroot. Streaminggegevens verwijzen naar gegevens die continu worden gegenereerd uit verschillende bronnen. De bronnen van deze gegevens, zoals clickstream-gebeurtenissen, change data capture (CDC), applicatie- en servicelogs en Internet of Things (IoT)-datastromen nemen toe. Snowflake biedt twee opties om streaminggegevens naar zijn platform te brengen: Snowpipe en Snowflake Snowpipe Streaming. Snowpipe is geschikt voor gebruiksscenario's voor bestandsopname (batching), zoals het laden van grote bestanden uit Amazon eenvoudige opslagservice (Amazon S3) naar Sneeuwvlok. Snowpipe Streaming, een nieuwere functie die in maart 2023 is uitgebracht, is geschikt voor gebruiksscenario's voor het opnemen van rijensets (streaming), zoals het laden van een continue stroom gegevens van Amazon Kinesis-gegevensstromen or Amazon Managed Streaming voor Apache Kafka (Amazone MSK).
Vóór Snowpipe Streaming gebruikten AWS-klanten Snowpipe voor beide gebruiksscenario's: bestandsopname en rijsetopname. Eerst heb je streaminggegevens opgenomen in Kinesis Data Streams of Amazon MSK, vervolgens Amazon Data Firehose gebruikt om streams te verzamelen en naar Amazon S3 te schrijven, gevolgd door Snowpipe om de gegevens in Snowflake te laden. Dit uit meerdere stappen bestaande proces kan echter resulteren in vertragingen van maximaal een uur voordat gegevens beschikbaar zijn voor analyse in Snowflake. Bovendien is het duur, vooral als je kleine bestanden hebt die Snowpipe moet uploaden naar het Snowflake-klantencluster.
Om dit probleem op te lossen, integreert Amazon Data Firehose nu met Snowpipe Streaming, waardoor je datastromen van Kinesis Data Streams, Amazon MSK en Firehose Direct PUT binnen enkele seconden tegen lage kosten kunt vastleggen, transformeren en leveren aan Snowflake. Met een paar klikken op de Amazon Data Firehose-console kunt u een Firehose-stream instellen om gegevens aan Snowflake te leveren. Er zijn geen verplichtingen of investeringen vooraf om Amazon Data Firehose te gebruiken, en u betaalt alleen voor de hoeveelheid gestreamde gegevens.
Enkele belangrijke kenmerken van Amazon Data Firehose zijn onder meer:
- Volledig beheerde serverloze service – U hoeft geen bronnen te beheren, en Amazon Data Firehose schaalt automatisch om de doorvoer van uw gegevensbron te evenaren, zonder doorlopend beheer.
- Eenvoudig te gebruiken zonder code – U hoeft geen applicaties te schrijven.
- Real-time gegevenslevering – U kunt gegevens binnen enkele seconden snel en efficiënt naar uw bestemmingen sturen.
- Integratie met meer dan 20 AWS-services – Naadloze integratie is beschikbaar voor veel AWS-services, zoals Kinesis Data Streams, Amazon MSK, Amazon VPC Flow Logs, AWS WAF logs, Amazon CloudWatch Logs, Amazon EventBridge, AWS IoT Core en meer.
- Pay-as-you-go-model – U betaalt alleen voor het datavolume dat Amazon Data Firehose verwerkt.
- Connectiviteit – Amazon Data Firehose kan verbinding maken met openbare of privé-subnetten in uw VPC.
In dit bericht wordt uitgelegd hoe u binnen enkele seconden streaminggegevens van AWS naar Snowflake kunt overbrengen om geavanceerde analyses uit te voeren. We verkennen gemeenschappelijke architecturen en illustreren hoe je een low-code, serverloze, kosteneffectieve oplossing voor datastreaming met lage latentie kunt opzetten.
Overzicht van de oplossing
Hieronder volgen de stappen om de oplossing voor het streamen van gegevens van AWS naar Snowflake te implementeren:
- Maak een Snowflake-database, -schema en -tabel.
- Creëer een Kinesis-gegevensstroom.
- Creëer een Firehose-leveringsstroom met Kinesis Data Streams als bron en Snowflake als bestemming met behulp van een beveiligde privélink.
- Om de installatie te testen, genereert u voorbeeldstreamgegevens van de Amazon Kinesis-gegevensgenerator (KDG) met de Firehose-leveringsstroom als bestemming.
- Voer een query uit op de Snowflake-tabel om de gegevens te valideren die in Snowflake zijn geladen.
De oplossing wordt weergegeven in het volgende architectuurdiagram.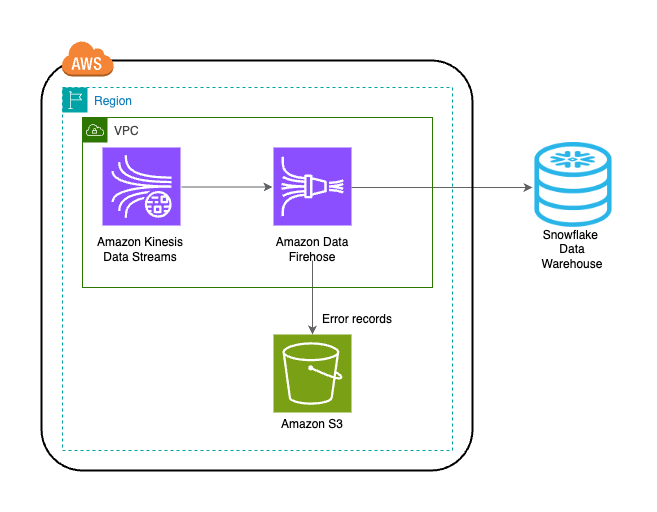
Voorwaarden
U moet de volgende vereisten hebben:
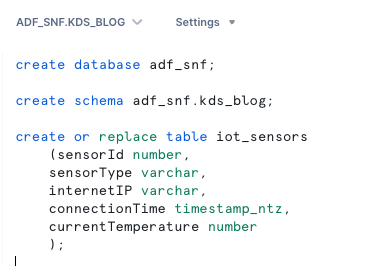
Maak een Snowflake-database, -schema en -tabel
Voer de volgende stappen uit om uw gegevens in Snowflake in te stellen:
- Log in op uw Snowflake-account en maak de database:
- Maak een schema in de nieuwe database:
- Maak een tabel in het nieuwe schema:
Een Kinesis-gegevensstroom maken
Voer de volgende stappen uit om uw gegevensstroom te maken:
- Kies op de Kinesis Data Streams-console Gegevensstromen in het navigatievenster.
- Kies Maak een datastroom.

- Voer bij Naam gegevensstroom een naam in (bijvoorbeeld
KDS-Demo-Stream). - Laat de overige instellingen standaard staan.
- Kies Gegevensstroom maken.

Maak een Firehose-leveringsstroom
Voer de volgende stappen uit om een Firehose-leveringsstroom te maken met Kinesis Data Streams als bron en Snowflake als bestemming:
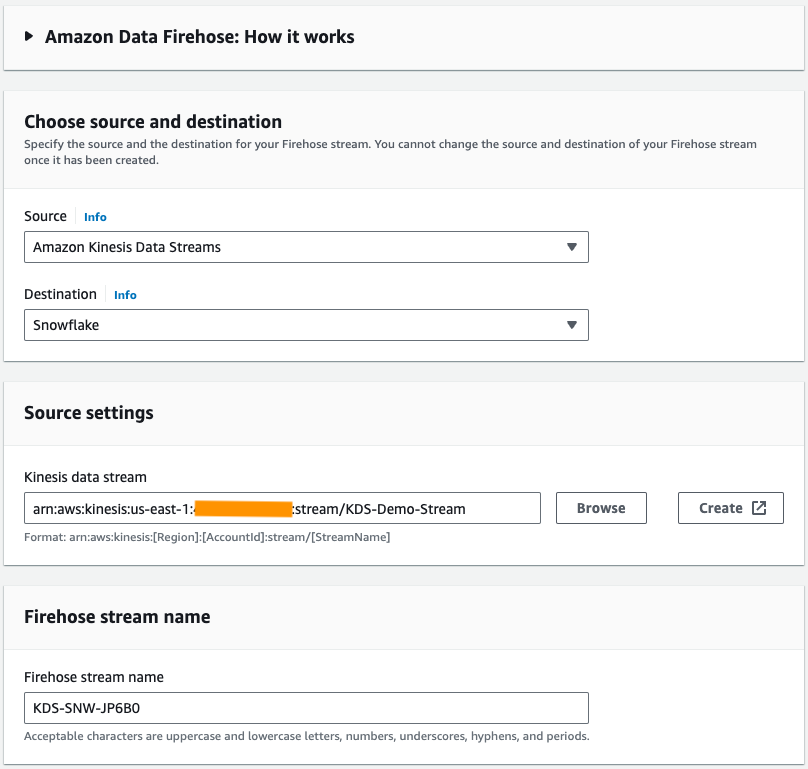
- Kies op de Amazon Data Firehose-console Maak een Firehose-stream.
- Voor bron, kiezen Amazon Kinesis-gegevensstromen.
- Voor Bestemming, kiezen Sneeuwvlok.
- Voor Kinesis-gegevensstroombladert u naar de gegevensstroom die u eerder hebt gemaakt.
- Voor Firehose-streamnaam, laat de standaard gegenereerde naam staan of voer een naam van uw voorkeur in.
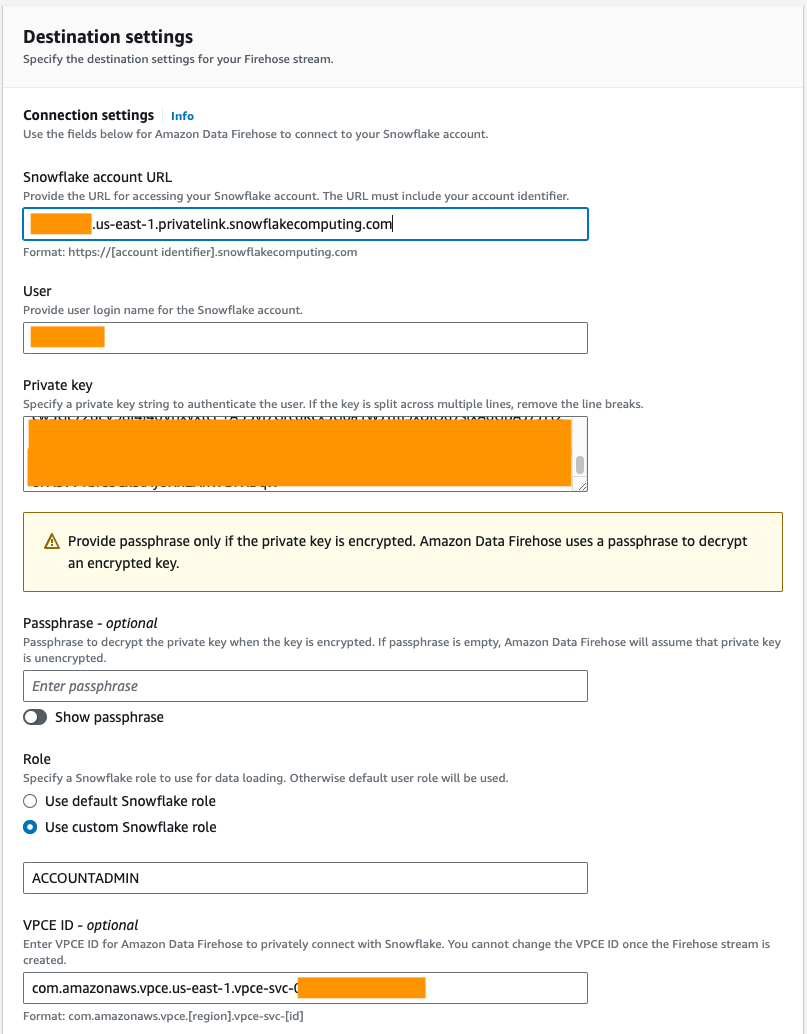
- Onder Verbindingsinstellingen, geef de volgende informatie op om Amazon Data Firehose met Snowflake te verbinden:
- Voor URL van Snowflake-account, voer de URL van uw Snowflake-account in.
- Voor GebruikerVoer de gebruikersnaam in die is gegenereerd in de vereisten.
- Voor PrivésleutelVoer de privésleutel in die is gegenereerd in de vereisten. Zorg ervoor dat de privésleutel de PKCS8-indeling heeft. Neem de PEM niet mee
header-BEGINvoorvoegsel enfooter-ENDachtervoegsel als onderdeel van de privésleutel. Als de sleutel over meerdere regels is verdeeld, verwijdert u de regeleinden. - Voor Rolselecteer Gebruik een aangepaste Sneeuwvlokrol en voer de IAM-rol in die toegang heeft om naar de databasetabel te schrijven.
U kunt verbinding maken met Snowflake via openbare of privéconnectiviteit. Als u geen VPC-eindpunt opgeeft, is de standaardconnectiviteitsmodus openbaar. Om de lijst met Firehose-IP's in uw Snowflake-netwerkbeleid toe te staan, raadpleegt u Kies Sneeuwvlok als uw bestemming. Als u een privélink-URL gebruikt, geeft u de VPCE-ID op met behulp van SYSTEEM$GET_PRIVATELINK_CONFIG:
Deze functie retourneert een JSON-weergave van de Snowflake-accountgegevens die nodig zijn om de zelfbedieningsconfiguratie van privéconnectiviteit met de Snowflake-service te vergemakkelijken, zoals weergegeven in de volgende schermafbeelding.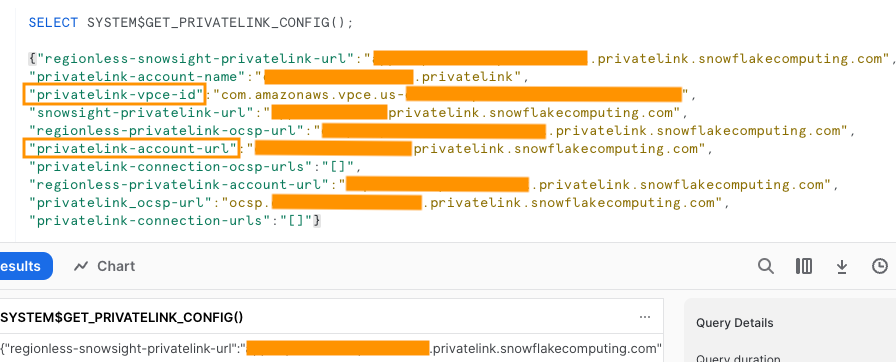
- Voor dit bericht gebruiken we een privélink, dus voor VPCE-ID, voer de VPCE-ID in.
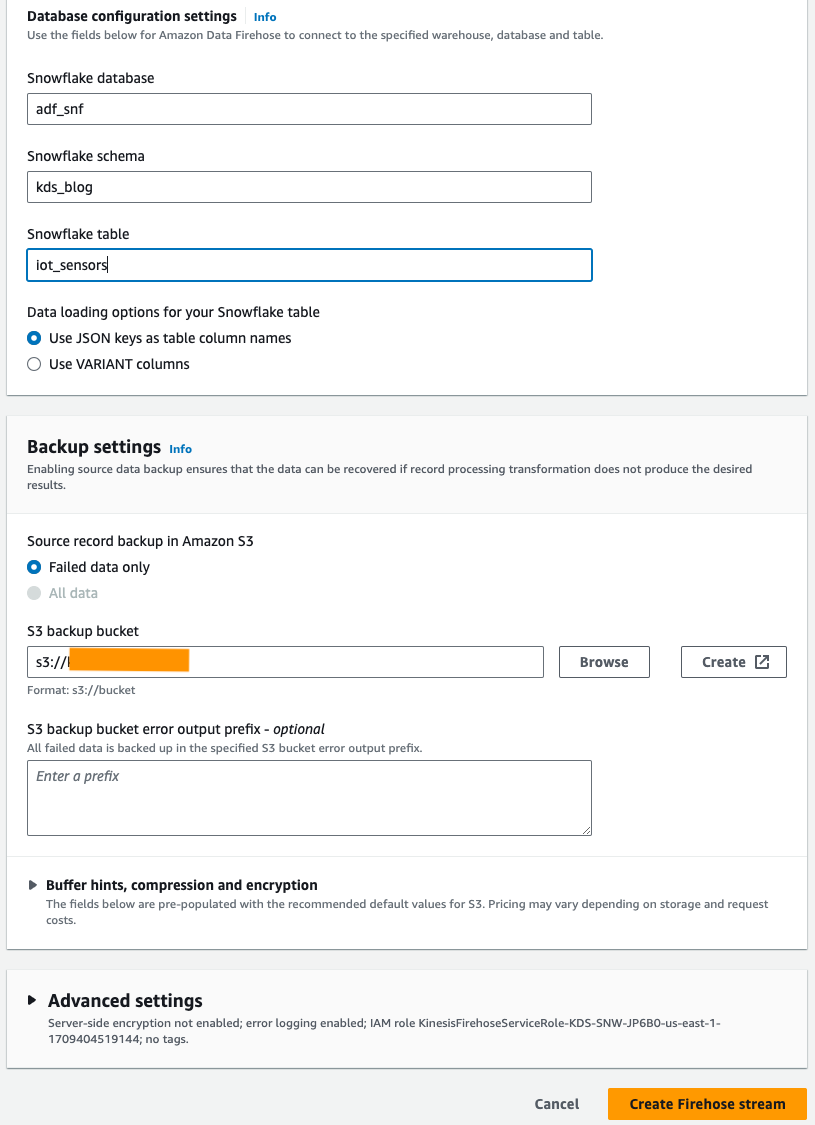
- Onder Instellingen voor databaseconfiguratie, voer uw Snowflake-database-, schema- en tabelnamen in.
- In het Back-upinstellingen sectie, voor S3-back-upbucketVoer de bucket in die u hebt gemaakt als onderdeel van de vereisten.
- Kies Maak een Firehose-stream.
Als alternatief kunt u een AWS CloudFormatie sjabloon om de Firehose-bezorgstroom te maken met Snowflake als bestemming in plaats van de Amazon Data Firehose-console te gebruiken.
Om de CloudFormation-stack te gebruiken, kiest u
![]()
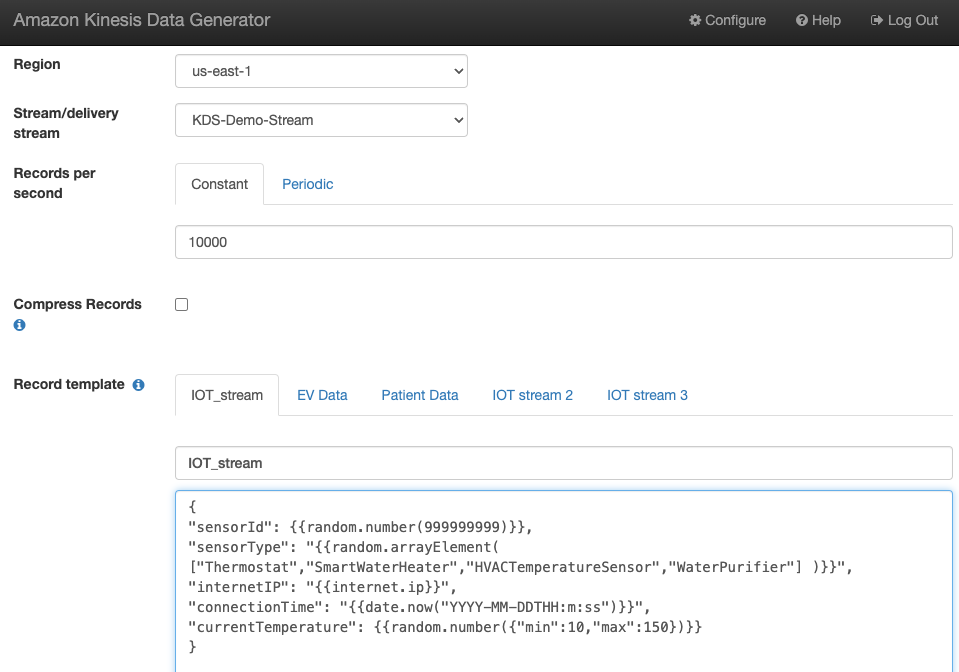
Genereer voorbeeldstroomgegevens
Genereer voorbeeldstroomgegevens van de KDG met de Kinesis-gegevensstroom die u hebt gemaakt:
Vraag de Sneeuwvloktabel op
Query uitvoeren in de Sneeuwvloktabel:
U kunt bevestigen dat de gegevens die zijn gegenereerd door de KDG en die naar Kinesis Data Streams zijn verzonden, in de Snowflake-tabel worden geladen via Amazon Data Firehose.

Probleem oplossen
Als er geen gegevens in Kinesis Data Steams worden geladen nadat de KDG gegevens naar de Firehose-leveringsstream heeft verzonden, vernieuw dan en zorg ervoor dat u bent ingelogd bij de KDG.
Als u wijzigingen hebt aangebracht in de definitie van de Snowflake-bestemmingstabel, maakt u de Firehose-leveringsstroom opnieuw.
Opruimen
Om te voorkomen dat er in de toekomst kosten in rekening worden gebracht, verwijdert u de bronnen die u als onderdeel van deze oefening hebt gemaakt als u niet van plan bent ze verder te gebruiken.
Conclusie
Amazon Data Firehose biedt een eenvoudige manier om gegevens aan Snowpipe Streaming te leveren, waardoor u kosten kunt besparen en de latentie tot seconden kunt terugbrengen. Om Amazon Kinesis Firehose met Snowflake te proberen, raadpleegt u het Amazon Data Firehose met Snowflake als bestemmingslab.
Over de auteurs
 Swapna Bandla is een Senior Solutions Architect in het AWS Analytics Specialist SA-team. Swapna heeft een passie voor het begrijpen van de data- en analysebehoeften van klanten en het in staat stellen van cloudgebaseerde, goed ontworpen oplossingen. Buiten haar werk brengt ze graag tijd door met haar gezin.
Swapna Bandla is een Senior Solutions Architect in het AWS Analytics Specialist SA-team. Swapna heeft een passie voor het begrijpen van de data- en analysebehoeften van klanten en het in staat stellen van cloudgebaseerde, goed ontworpen oplossingen. Buiten haar werk brengt ze graag tijd door met haar gezin.
 Mostafa Mansoer is Principal Product Manager – Tech bij Amazon Web Services, waar hij werkt aan Amazon Kinesis Data Firehose. Hij is gespecialiseerd in het ontwikkelen van intuïtieve productervaringen die complexe uitdagingen voor klanten op grote schaal oplossen. Als hij niet hard aan het werk is op Amazon Kinesis Data Firehose, vind je Mostafa waarschijnlijk op de squashbaan, waar hij het graag opneemt tegen uitdagers en zijn dropshots perfectioneert.
Mostafa Mansoer is Principal Product Manager – Tech bij Amazon Web Services, waar hij werkt aan Amazon Kinesis Data Firehose. Hij is gespecialiseerd in het ontwikkelen van intuïtieve productervaringen die complexe uitdagingen voor klanten op grote schaal oplossen. Als hij niet hard aan het werk is op Amazon Kinesis Data Firehose, vind je Mostafa waarschijnlijk op de squashbaan, waar hij het graag opneemt tegen uitdagers en zijn dropshots perfectioneert.
 Bosco Albuquerque is een Sr. Partner Solutions Architect bij AWS en heeft meer dan 20 jaar ervaring in het werken met database- en analyseproducten van leveranciers van bedrijfsdatabases en cloudproviders. Hij heeft technologiebedrijven geholpen bij het ontwerpen en implementeren van oplossingen en producten voor data-analyse.
Bosco Albuquerque is een Sr. Partner Solutions Architect bij AWS en heeft meer dan 20 jaar ervaring in het werken met database- en analyseproducten van leveranciers van bedrijfsdatabases en cloudproviders. Hij heeft technologiebedrijven geholpen bij het ontwerpen en implementeren van oplossingen en producten voor data-analyse.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/uplevel-your-data-architecture-with-real-time-streaming-using-amazon-data-firehose-and-snowflake/

