In de dynamische wereld van cloud computing is het waarborgen van de veerkracht en beschikbaarheid van kritieke applicaties van het allergrootste belang. ramp herstel (DR) is het proces waarmee een organisatie technologiegerelateerde rampen anticipeert en aanpakt. Voor organisaties die kritieke werklastorkestratie implementeren met behulp van Door Amazon beheerde workflows voor Apache Airflow (Amazon MWAA), is het van cruciaal belang om een DR-plan te hebben om de bedrijfscontinuïteit te garanderen.
In deze serie onderzoeken we de noodzaak van Amazon MWAA-rampenherstel en schrijven we oplossingen voor die Amazon MWAA-omgevingen beschermen tegen onbedoelde verstoringen. Hierdoor kunt u verstoringsrisico's definiëren, vermijden en aanpakken als onderdeel van uw bedrijfscontinuïteitsplan. Dit bericht richt zich op het ontwerpen van de algehele DR-architectuur. Een toekomstige post in deze serie zal zich richten op het implementeren van de afzonderlijke componenten met behulp van AWS-services.
De noodzaak van Amazon MWAA-rampherstel
Amazon MWAA, een volledig beheerde service voor Apache-luchtstroom, biedt organisaties enorme waarde door de workfloworkestratie te automatiseren voor extractie, transformatie en belasting (ETL), DevOps en machine learning (ML)-workloads. Amazon MWAA heeft een gedistribueerde architectuur met meerdere componenten zoals planner, medewerker, webserver, wachtrij en database. Dit maakt het moeilijk om een alomvattende DR-strategie te implementeren.
Een actieve Amazon MWAA-omgeving parseert Airflow voortdurend Gerichte acyclische grafieken (DAG's), deze lezen vanaf een geconfigureerd Amazon eenvoudige opslagservice (Amazon S3) bak. Het niet beschikbaar zijn van de DAG-bron vanwege onbereikbaarheid van het netwerk, onbedoelde corruptie of verwijdering leidt tot langere downtime en verstoring van de service.
Binnen Airflow is de metadatadatabase een kerncomponent waarin configuratievariabelen, rollen, machtigingen en DAG-rungeschiedenis worden opgeslagen. Een gezonde metadatadatabase is daarom van cruciaal belang voor uw Airflow-omgeving. Zoals bij elke kerncomponent van Airflow is het essentieel dat er een back-up- en noodherstelplan voor de metadatadatabase aanwezig is.
Amazon MWAA implementeert Airflow-componenten op meerdere Beschikbaarheidszones binnen uw VPC in uw voorkeur AWS-regio. Dit biedt fouttolerantie en automatisch herstel bij één enkele Beschikbaarheidszone-fout. Voor missiekritieke werklasten is het bovendien belangrijk om veerkrachtig te zijn tegen de beperkingen van een unitaire regio door middel van implementaties in meerdere regio's om hoge beschikbaarheid en bedrijfscontinuïteit te garanderen.
Het balanceren tussen de kosten voor het onderhouden van redundante infrastructuren, complexiteit en hersteltijd is essentieel voor Amazon MWAA-omgevingen. Organisaties streven naar kosteneffectieve oplossingen die de kosten minimaliseren Hersteltijd doelstelling (RTO) en Doelstelling herstelpunt (RPO) om aan hun service level overeenkomsten te voldoen, economisch levensvatbaar te zijn en aan de eisen van hun klanten te voldoen.
Detecteer rampen in de primaire omgeving: proactieve monitoring via statistieken en alarmen
Een snelle detectie van rampen in de primaire omgeving is cruciaal voor een tijdig herstel na een ramp. Het monitoren van de Amazon Cloud Watch SchedulerHeartbeat-statistiek biedt inzicht in de luchtstroomgezondheid van een actieve Amazon MWAA-omgeving. U kunt andere statistieken voor de statuscontrole toevoegen aan de evaluatiecriteria, zoals het controleren van de beschikbaarheid van upstream- of downstream-systemen en de netwerkbereikbaarheid. Gecombineerd met CloudWatch-alarmen, kunt u meldingen verzenden wanneer deze drempelwaarden gedurende een aantal perioden niet worden gehaald. U kunt alarmen toevoegen aan dashboards om waarschuwingen te controleren en te ontvangen over uw AWS-bronnen en -applicaties in meerdere regio's.
AWS publiceert onze meest actuele informatie over de beschikbaarheid van diensten op de website Servicestatusdashboard. U kunt op elk moment controleren of er actuele statusinformatie is, of u abonneren op een RSS-feed om op de hoogte te worden gehouden van onderbrekingen van elke afzonderlijke dienst in uw operationele regio. De AWS-gezondheidsdashboard biedt informatie over AWS Health-gebeurtenissen die van invloed kunnen zijn op uw account.
Door metrische monitoring, beschikbare dashboards en automatische alarmering te combineren, kunt u onmiddellijk de onbeschikbaarheid van uw primaire omgeving detecteren, waardoor proactieve maatregelen mogelijk worden om over te stappen naar uw DR-plan. Het is van cruciaal belang om de detectie, melding, escalatie, ontdekking en aangifte van incidenten mee te nemen in uw DR-planning en -implementatie om realistische en haalbare doelstellingen te bieden die bedrijfswaarde opleveren.
In de volgende secties bespreken we twee Amazon MWAA DR-strategieoplossingen en hun architectuur.
DR-strategieoplossing 1: Back-up en herstel
De back-up- en herstelstrategie omvat het genereren van back-ups van Airflow-componenten in dezelfde of een andere regio als uw primaire Amazon MWAA-omgeving. Om de continuïteit te garanderen, kunt u deze asynchroon repliceren naar uw DR-regio, met minimale impact op de prestaties van uw primaire Amazon MWAA-omgeving. In het geval van een zeldzame primaire regionale verstoring of serviceonderbreking zal deze strategie een nieuwe Amazon MWAA-omgeving creëren en historische gegevens daarin herstellen vanuit bestaande back-ups. Het is echter belangrijk op te merken dat er tijdens het herstelproces een periode zal zijn waarin er geen Airflow-omgevingen operationeel zijn om workflows te verwerken totdat de nieuwe omgeving volledig is ingericht en gemarkeerd als beschikbaar.
Deze strategie biedt een goedkope en weinig complexe oplossing die ook geschikt is om gegevensverlies of corruptie binnen uw primaire regio te beperken. De hoeveelheid gegevens waarvan een back-up wordt gemaakt en de tijd om een nieuwe Amazon MWAA-omgeving te creëren (doorgaans 20-30 minuten) zijn van invloed op hoe snel herstel kan plaatsvinden. Om ervoor te zorgen dat de infrastructuur snel en zonder fouten opnieuw kan worden geïmplementeerd, kunt u gebruik maken van infrastructuur als code (IaC). Zonder IaC kan het complex zijn om een analoge DR-omgeving te herstellen, wat zal leiden tot langere hersteltijden en mogelijk uw RTO zal overschrijden.
Laten we eens kijken welke configuratie vereist is wanneer uw primaire Amazon MWAA-omgeving actief actief is, zoals weergegeven in de volgende afbeelding.
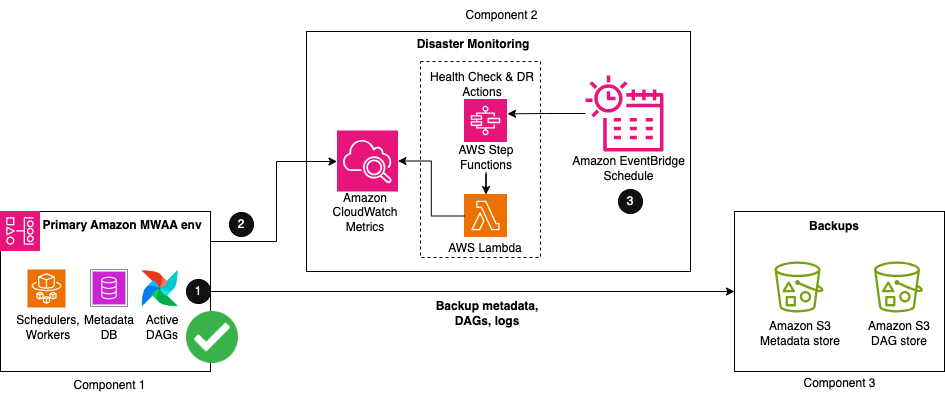
De oplossing bestaat uit drie belangrijke componenten. Het eerste onderdeel is de primaire omgeving, waar de Airflow-workflows in eerste instantie worden geïmplementeerd en actief worden uitgevoerd. Het tweede onderdeel is het onderdeel voor rampenmonitoring, bestaande uit CloudWatch en een combinatie van een AWS Stap Functies staatsmachine en a AWS Lambda functie. Het derde onderdeel is bedoeld voor het maken en opslaan van back-ups van alle configuraties en metagegevens die nodig zijn om te herstellen. Dit kan zich in dezelfde regio bevinden als uw primaire regio of worden gerepliceerd naar uw DR-regio met behulp van S3 Replicatie tussen regio's (CRR). Voor CRR betaalt u ook voor gegevensoverdracht tussen regio's vanuit Amazon S3 naar elke bestemmingsregio.
De eerste drie stappen in de workflow zijn als volgt:
- Als onderdeel van uw back-upproces worden Airflow-metagegevens gerepliceerd naar een S3-bucket met behulp van een DAG exporteren hulpprogramma, periodiek uitgevoerd op basis van uw RPO-interval.
- Uw bestaande primaire Amazon MWAA-omgeving verzendt automatisch de status van de gezondheid van de planner naar de CloudWatch PlannerHartslag metriek.
- Een uit meerdere stappen bestaande stapfuncties staat machine wordt geactiveerd vanuit een periodieke Amazon EventBridge rooster om de gezondheidsstatus van de planner te controleren. Als primaire stap van de toestandsmachine evalueert een Lambda-functie de status van de PlannerHartslag metriek. Als de statistiek als gezond wordt beschouwd, wordt er geen actie ondernomen.
De volgende afbeelding illustreert de extra stappen in de oplossingsworkflow.
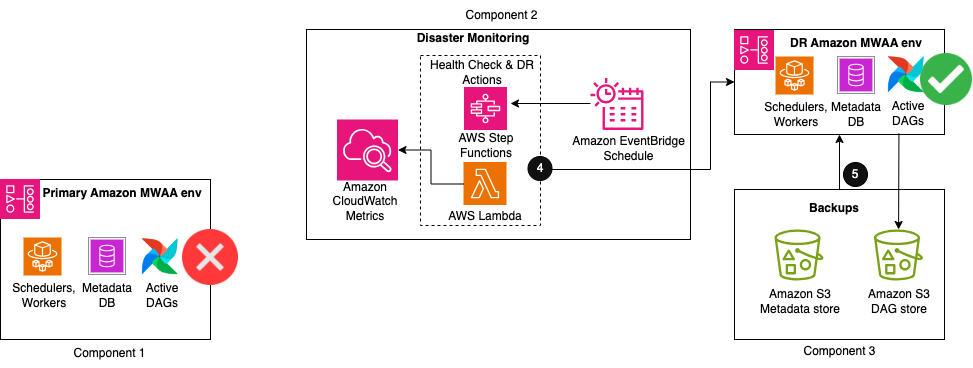
- Wanneer het aantal hartslagen gedurende een bepaalde periode afwijkt van het normale aantal, wordt een reeks acties gestart om te herstellen naar een nieuwe Amazon MWAA-omgeving in de DR-regio. Deze acties omvatten onder meer het starten van de creatie van een nieuwe Amazon MWAA-omgeving, het repliceren van de configuraties van de primaire omgeving en vervolgens wachten tot de nieuwe omgeving beschikbaar komt.
- Wanneer de omgeving beschikbaar is, kan een DAG importeren Er wordt een hulpprogramma uitgevoerd om de metagegevensinhoud van de back-ups te herstellen. Alle DAG-uitvoeringen die zijn onderbroken tijdens de verstoring van de primaire omgeving moeten handmatig opnieuw worden uitgevoerd om de serviceniveau-overeenkomsten te behouden. Toekomstige DAG-uitvoeringen worden in de wachtrij geplaatst om te worden uitgevoerd volgens het volgende geconfigureerde schema.
DR-strategieoplossing 2: Actief-passieve omgevingen met periodieke gegevenssynchronisatie
De actief-passieve omgevingen met periodieke gegevenssynchronisatiestrategie richten zich op het onderhouden van terugkerende gegevenssynchronisatie tussen een actieve primaire en een passieve Amazon MWAA DR-omgeving. Door periodiek DAG-archieven en metadatadatabases bij te werken en te synchroniseren, zorgt deze strategie ervoor dat de DR-omgeving actueel of bijna actueel blijft met de primaire. De DR-regio kan dezelfde of een andere regio zijn dan uw primaire Amazon MWAA-omgeving. In het geval van een ramp zijn er back-ups beschikbaar om terug te keren naar een eerder bekende goede staat om gegevensverlies of corruptie te minimaliseren.
Deze strategie biedt een lage RTO en RPO met frequente synchronisatie, waardoor snel herstel met minimaal gegevensverlies mogelijk is. De infrastructuurkosten en code-implementaties worden verhoogd om zowel de primaire als DR Amazon MWAA-omgevingen te onderhouden. Uw DR-omgeving is onmiddellijk beschikbaar om DAG's op te draaien.
De volgende afbeelding illustreert de vereiste configuratie wanneer uw primaire Amazon MWAA-omgeving actief actief is.
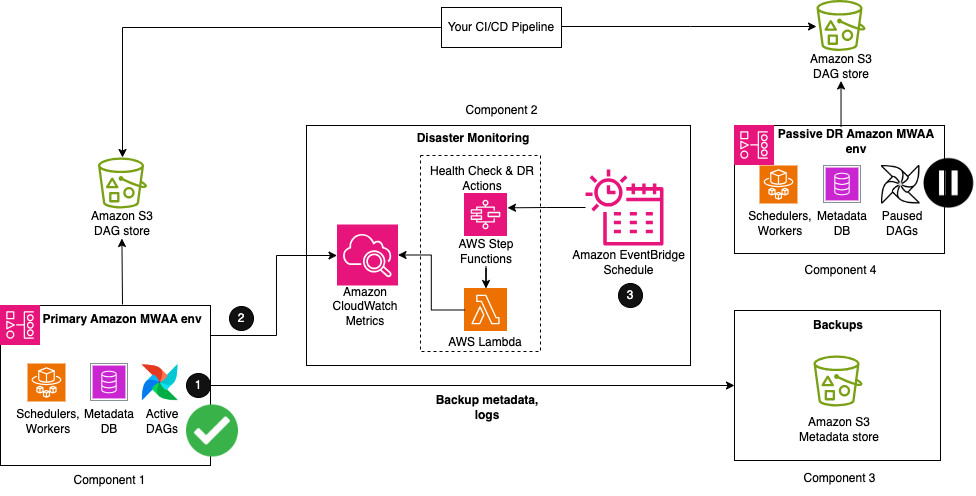
De oplossing bestaat uit vier belangrijke componenten. Net als bij de back-up- en hersteloplossing is het eerste onderdeel de primaire omgeving, waar de workflow in eerste instantie wordt geïmplementeerd en actief wordt uitgevoerd. Het tweede onderdeel is het rampenmonitoringonderdeel, bestaande uit CloudWatch en een combinatie van een Step Functions-statusmachine en Lambda-functie. Het derde onderdeel maakt en bewaart back-ups voor alle configuraties en metadata die nodig zijn voor de databasesynchronisatie. Dit kan zich in dezelfde regio bevinden als uw primaire regio of worden gerepliceerd naar uw DR-regio met behulp van Amazon S3 Cross-Region Replication. Zoals eerder vermeld, betaalt u voor CRR ook voor gegevensoverdracht tussen regio's vanuit Amazon S3 naar elke bestemmingsregio. Het laatste onderdeel is een passieve Amazon MWAA-omgeving die dezelfde Airflow-code en omgevingsconfiguraties heeft als de primaire. De DAG's worden geïmplementeerd in de DR-omgeving met behulp van dezelfde pijplijn voor continue integratie en continue levering (CI/CD) als de primaire. In tegenstelling tot de primaire worden DAG's in een gepauzeerde status gehouden om geen dubbele uitvoeringen te veroorzaken.
De eerste stappen van de workflow zijn vergelijkbaar met de back-up- en herstelstrategie:
- Als onderdeel van uw back-upproces worden Airflow-metagegevens gerepliceerd naar een S3-bucket met behulp van een export DAG-hulpprogramma, dat periodiek wordt uitgevoerd op basis van uw RPO-interval.
- Uw bestaande primaire Amazon MWAA-omgeving verzendt automatisch de status van de gezondheid van de planner naar CloudWatch PlannerHartslag metriek.
- Een uit meerdere stappen bestaande Step Functions-statusmachine wordt geactiveerd vanuit een periodiek Amazon EventBridge-schema om de gezondheidsstatus van de planner te controleren. Als primaire stap van de toestandsmachine evalueert een Lambda-functie de status van de PlannerHartslag metriek. Als de statistiek als gezond wordt beschouwd, wordt er geen actie ondernomen.
De volgende afbeelding illustreert de laatste stappen van de workflow.
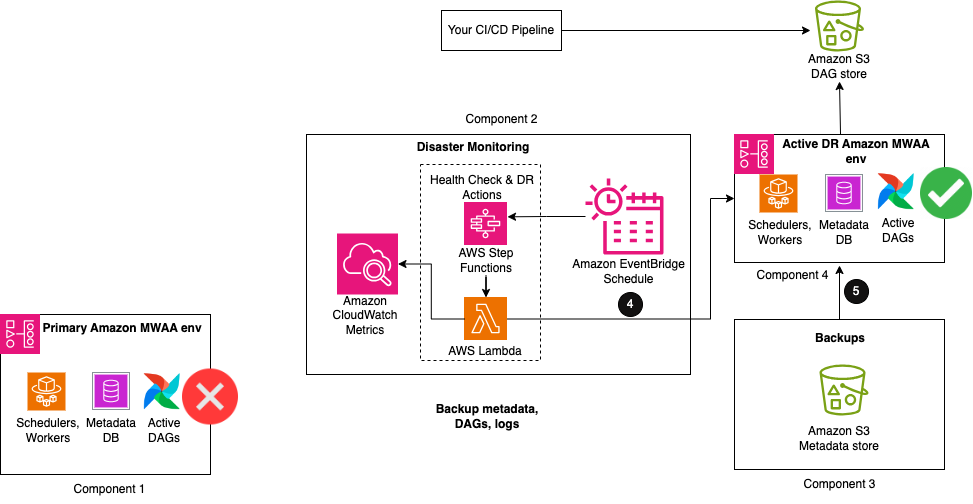
- Wanneer de hartslagtelling gedurende een bepaalde periode afwijkt van de normale telling, worden DR-acties gestart.
- Als eerste stap activeert een Lambda-functie een import-DAG-hulpprogramma om de metadata-inhoud van de back-ups naar de passieve Amazon MWAA DR-omgeving te herstellen. Wanneer het importeren is voltooid, kan dezelfde DAG de andere Airflow DAG's hervatten, waardoor ze actief worden voor toekomstige runs. Alle DAG-uitvoeringen die zijn onderbroken tijdens de verstoring van de primaire omgeving moeten handmatig opnieuw worden uitgevoerd om de serviceniveau-overeenkomsten te behouden. Toekomstige DAG-uitvoeringen worden in de wachtrij geplaatst om te worden uitgevoerd volgens het volgende geconfigureerde schema.
Best practices om de veerkracht van Amazon MWAA te verbeteren
Om de veerkracht van uw Amazon MWAA-omgeving te vergroten en een soepel noodherstel te garanderen, kunt u overwegen de volgende best practices te implementeren:
- Robuuste back-up- en herstelmechanismen – Het implementeren van uitgebreide back-up- en herstelmechanismen voor Amazon MWAA-gegevens is essentieel. Het regelmatig verwijderen van bestaande metagegevens op basis van het bewaarbeleid van uw organisatie verkort de back-uptijden en maakt uw Amazon MWAA-omgeving beter presterend.
- Automatisering met IaC – Het gebruik van automatiserings- en orkestratietools zoals AWS CloudFormatie AWS Cloud-ontwikkelingskit (AWS CDK), of Terraform kan de implementatie en het configuratiebeheer van Amazon MWAA-omgevingen stroomlijnen. Dit zorgt voor consistentie, reproduceerbaarheid en sneller herstel tijdens DR-scenario's.
- Idempotente DAG's en taken – In Airflow wordt een DAG als idempotent beschouwd als het meerdere keren opnieuw uitvoeren van dezelfde DAG met dezelfde invoer hetzelfde effect heeft als het slechts één keer uitvoeren ervan. Het ontwerpen van idempotente DAG's en het atomair houden van taken verkort de hersteltijd na fouten wanneer u een onderbroken DAG handmatig opnieuw moet uitvoeren in uw herstelde omgeving.
- Regelmatig testen en valideren – Een robuuste Amazon MWAA DR-strategie moet regelmatige test- en validatieoefeningen omvatten. Door rampscenario's te simuleren, kunt u eventuele hiaten in uw DR-plannen identificeren, processen verfijnen en ervoor zorgen dat uw Amazon MWAA-omgevingen volledig herstelbaar zijn.
Conclusie
In dit bericht hebben we de uitdagingen voor Amazon MWAA-rampherstel onderzocht en best practices besproken om de veerkracht te verbeteren. We hebben twee DR-strategieoplossingen onderzocht: back-up en herstel en actief-passieve omgevingen met periodieke gegevenssynchronisatie. Door deze oplossingen te implementeren en best practices te volgen, kun je je Amazon MWAA-omgevingen beschermen, downtime minimaliseren en de impact van rampen beperken. Regelmatig testen, valideren en aanpassen aan veranderende eisen zijn cruciaal voor een effectieve Amazon MWAA DR-strategie. Door uw noodherstelplannen voortdurend te evalueren en te verfijnen, kunt u de veerkracht en ononderbroken werking van uw Amazon MWAA-omgevingen garanderen, zelfs bij onvoorziene gebeurtenissen.
Voor aanvullende details en codevoorbeelden op Amazon MWAA raadpleegt u de Amazon MWAA-gebruikershandleiding en Amazon MWAA-voorbeelden GitHub-repo.
Over de auteurs
 Parnab Basak is een Senior Solutions Architect en een Serverless Specialist bij AWS. Hij is gespecialiseerd in het creëren van nieuwe oplossingen die cloud-native zijn, waarbij gebruik wordt gemaakt van moderne softwareontwikkelingspraktijken zoals serverless, DevOps en analytics. Parnab werkt nauw samen op het gebied van analyse- en integratiediensten en helpt klanten bij het adopteren van AWS-diensten voor hun behoeften op het gebied van workfloworkestratie.
Parnab Basak is een Senior Solutions Architect en een Serverless Specialist bij AWS. Hij is gespecialiseerd in het creëren van nieuwe oplossingen die cloud-native zijn, waarbij gebruik wordt gemaakt van moderne softwareontwikkelingspraktijken zoals serverless, DevOps en analytics. Parnab werkt nauw samen op het gebied van analyse- en integratiediensten en helpt klanten bij het adopteren van AWS-diensten voor hun behoeften op het gebied van workfloworkestratie.
 Chandan Rupakheti is een Solutions Architect en een Serverless Specialist bij AWS. Hij is een gepassioneerd technisch leider, onderzoeker en mentor met een talent voor het bouwen van innovatieve oplossingen in de cloud en het samenbrengen van belanghebbenden op hun cloudreis. Buiten zijn professionele leven brengt hij naast het luisteren en spelen van muziek graag tijd door met zijn familie en vrienden.
Chandan Rupakheti is een Solutions Architect en een Serverless Specialist bij AWS. Hij is een gepassioneerd technisch leider, onderzoeker en mentor met een talent voor het bouwen van innovatieve oplossingen in de cloud en het samenbrengen van belanghebbenden op hun cloudreis. Buiten zijn professionele leven brengt hij naast het luisteren en spelen van muziek graag tijd door met zijn familie en vrienden.
 Vinod Jayendra is een Enterprise Support Lead in ISV-accounts bij Amazon Web Services, waar hij klanten helpt bij het oplossen van hun architectonische, operationele en kostenoptimalisatie-uitdagingen. Met een bijzondere focus op serverloze technologieën put hij uit zijn uitgebreide achtergrond in applicatieontwikkeling om oplossingen van het hoogste niveau te leveren. Naast zijn werk vindt hij vreugde in quality time met het gezin, het ondernemen van fietsavonturen en het coachen van jeugdsportteams.
Vinod Jayendra is een Enterprise Support Lead in ISV-accounts bij Amazon Web Services, waar hij klanten helpt bij het oplossen van hun architectonische, operationele en kostenoptimalisatie-uitdagingen. Met een bijzondere focus op serverloze technologieën put hij uit zijn uitgebreide achtergrond in applicatieontwikkeling om oplossingen van het hoogste niveau te leveren. Naast zijn werk vindt hij vreugde in quality time met het gezin, het ondernemen van fietsavonturen en het coachen van jeugdsportteams.
 Rupesh Tiwari is een Senior Solutions Architect bij AWS in New York City, met een focus op financiële dienstverlening. Hij heeft meer dan 18 jaar IT-ervaring in de financiële, verzekerings- en onderwijsdomeinen, en is gespecialiseerd in het ontwerpen van grootschalige applicaties en cloud-native big data-workloads. In zijn vrije tijd zingt Rupesh graag karaoke, kijkt hij naar komische tv-series en creëert hij vreugdevolle momenten met zijn gezin.
Rupesh Tiwari is een Senior Solutions Architect bij AWS in New York City, met een focus op financiële dienstverlening. Hij heeft meer dan 18 jaar IT-ervaring in de financiële, verzekerings- en onderwijsdomeinen, en is gespecialiseerd in het ontwerpen van grootschalige applicaties en cloud-native big data-workloads. In zijn vrije tijd zingt Rupesh graag karaoke, kijkt hij naar komische tv-series en creëert hij vreugdevolle momenten met zijn gezin.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/disaster-recovery-strategies-for-amazon-mwaa-part-1/

