Introductie

Afbeeldingsbron: https://www.wallpaperflare.com
Tijdreeksanalyse geeft inzicht in het patroon of de kenmerken van tijdreeksgegevens. Tijdreeksgegevens kunnen worden ontleed in drie componenten:
- Trend - Dit toont de tendens van de gegevens over een lange periode, deze kan opwaarts, neerwaarts of stabiel zijn.
- Seizoensgebondenheid - Het is de variatie die periodiek optreedt en zich elk jaar herhaalt.
- Ruis of willekeurig – Fluctuaties in de gegevens die grillig zijn.

Afbeeldingsbron: https://www.researchgate.net
Het voorspellen van de gegevens voor een bepaalde tijd in de toekomst staat bekend als Time Series Forecasting. Het is een van de krachtige modellen voor machinaal leren die veel worden gebruikt op het gebied van financiën, weersvoorspellingen, de gezondheidssector, milieustudies, het bedrijfsleven, de detailhandel, enz. om tot strategische beslissingen te komen.
In realtime bestaan de meeste gegevens uit meerdere variabelen, waarbij onafhankelijke variabelen mogelijk afhankelijk zijn van andere onafhankelijke variabelen, deze relaties zullen een impact hebben op de voorspellingen of prognoses. Meestal worden mensen over het algemeen misleid en bouwen ze in dergelijke gevallen multilineaire regressiemodellen. Een hoge R-kwadraatwaarde zal verder misleiden en een slechte voorspelling opleveren.
Valse regressie
Lineaire regressie kan wijzen op een sterke relatie tussen twee of meer variabelen, maar deze variabelen kunnen in werkelijkheid totaal niet gerelateerd zijn. Voorspellingen mislukken als het gaat om domeinkennis, dit scenario staat bekend als valse regressie.
Er is een sterke relatie tussen de consumptie van kippen en de export van ruwe olie in de onderstaande grafiek, ook al zijn ze niet gerelateerd.

Sterke trend / niet-stationair en hoger R-kwadraat worden waargenomen in valse regressie. Valse regressie moet worden geëlimineerd tijdens het bouwen van het model, omdat ze geen verband houden en geen causaal verband hebben.
Multilineaire regressie maakt gebruik van een correlatiematrix om de afhankelijkheid tussen alle onafhankelijke variabelen te controleren. Als de waarde van de correlatiecoëfficiënt tussen twee variabelen hoog is, wordt een variabele behouden en wordt een andere weggegooid om de afhankelijkheid te verwijderen. In de dataset, wanneer tijd een verstorende factor is, faalt multilineaire regressie, de correlatiecoëfficiënt die wordt gebruikt om de variabele te elimineren, is niet tijdgebonden, maar geeft alleen de correlatie tussen de twee variabelen weer.

Beschouw de bovenstaande tijdreeksgrafiek, variabele X heeft een directe invloed op variabele Y, maar er is een vertraging van 5 tussen X en Y, in welk geval we de correlatiematrix niet kunnen gebruiken. Voor bijv. een toename van het aantal positieve gevallen van coronavirus in de stad en een toename van het aantal mensen dat in het ziekenhuis wordt opgenomen. Voor een betere voorspelling willen we hier graag weten of er een causaal verband is.

Granger Causality komt te hulp
Prof. Clive WJ Granger, ontvanger van de Nobelprijs voor de economie in 2003, ontwikkelde het concept van causaliteit om de prestaties van voorspellingen te verbeteren.
Het is in feite een econometrische hypothetische test voor het verifiëren van het gebruik van de ene variabele bij het voorspellen van een andere in multivariate tijdreeksgegevens met een bepaalde vertraging.
Een voorwaarde voor het uitvoeren van de Granger Causality-test is dat de gegevens stationair moeten zijn, dat wil zeggen dat ze een constant gemiddelde, constante variantie en geen seizoenscomponent moeten hebben. Transformeer de niet-stationaire gegevens naar stationaire gegevens door ze te differentiëren, hetzij eerste-orde- hetzij tweede-ordedifferentiatie. Ga niet verder met de Granger-causaliteitstest als de gegevens niet stationair zijn na differentiëring van de tweede orde.
Laten we eens kijken naar drie variabelen Xt , Yt en Wt vooraf ingesteld in tijdreeksgegevens.
Geval 1: Prognose Xt + 1 gebaseerd op waarden uit het verleden Xt .
Geval 2: Prognose Xt + 1 gebaseerd op waarden uit het verleden Xt en Yt.
Case3: Prognose Xt + 1 gebaseerd op waarden uit het verleden Xt , Yt , en Wt, waarbij variabele Yt heeft directe afhankelijkheid van variabele Wt.
Hier is Case 1 univariate tijdreeksen, ook bekend als het autoregressieve model waarin er een enkele variabele is en prognoses worden gedaan op basis van dezelfde variabele die achterblijft bij bijvoorbeeld volgorde p.
De vergelijking voor het auto-regressieve model van orde p (RESTRICTED MODEL, RM)
Xt = α + 𝛾1 X𝑡−1 +2X𝑡−2 + ⋯ +𝑝X𝑡-𝑝
waarbij p parameters (vrijheidsgraden) geschat moeten worden.
In geval 2 de waarden uit het verleden van Y bevatten informatie voor prognoses Xt + 1. Ent wordt gezegd dat "Granger oorzaak" Xt + 1 mits Yt komt eerder voor Xt + 1 en het bevat gegevens voor prognoses Xt + 1.
Vergelijking met een voorspeller Yt (ONBEPERKTE MODEL, UM)
Xt = α + 𝛾1 X𝑡−1 +2X𝑡−2 + ⋯ +𝑝X𝑡-𝑝 +1Yt-1+ ⋯ +𝑝 Ytp
2p parameters (vrijheidsgraden) te schatten.
Als Yt veroorzaakt Xt, dan moet Y voorafgaan aan X, wat impliceert:
- Achtergebleven waarden van Y moeten significant gerelateerd zijn aan X.
- Achtergebleven waarden van X zouden niet significant gerelateerd moeten zijn aan Y.
Geval 3 kan niet worden gebruikt om Granger-causaliteit te vinden, aangezien variabele Yt wordt beïnvloed door variabele Wt.
Hypothesetest
Nul-hypothese (H.0): Yt niet "Granger veroorzaken" Xt+1 dat wil zeggen,1 =2 = ⋯ =𝑝 = 0
Alternatieve hypothese (HA): Yt doet "Granger oorzaak" Xt+1, dat wil zeggen, ten minste één van de vertragingen van Y is significant.
Bereken de f-statistiek
Fp,n-2𝑝−1 = (𝐸𝑠𝑡𝑖𝑚𝑎𝑡𝑒 𝑜𝑓 𝑜𝑓 𝐸𝑥𝑝𝑙𝑎𝑖𝑛𝑒𝑑 𝑉𝑎𝑟𝑖𝑎𝑛𝑐𝑒) / (𝐸𝑠𝑡𝑖𝑚𝑎𝑡𝑒 𝑜𝑓 𝑈𝑛𝑒𝑥𝑝𝑙𝑎𝑖𝑛𝑒𝑑 𝑉𝑎𝑟𝑖𝑎𝑛𝑐𝑒 𝑉𝑎𝑟𝑖𝑎𝑛𝑐𝑒 𝑉𝑎𝑟𝑖𝑎𝑛𝑐𝑒)
Fp,n-2𝑝−1 = ( (𝑆𝑆𝐸𝑅𝑀-𝑆𝑆𝐸𝑈𝑀) /𝑝) /(𝑆𝑆𝐸𝑈𝑀 /𝑛−2𝑝−1)
waarbij n het aantal waarnemingen is en
SSE is de som van gekwadrateerde fouten.
Als de p-waarden lager zijn dan een significantieniveau (0.05) voor ten minste één van de vertragingen, verwerp dan de nulhypothese.
Voer een test uit voor zowel de richting Xt->Yt en Yt->Xt.
Probeer verschillende vertragingen (p). De optimale lag kan worden bepaald met behulp van AIC.
Beperking
- Granger-causaliteit geeft geen inzicht in de relatie tussen de variabele, daarom is het geen echte causaliteit in tegenstelling tot 'oorzaak en gevolg'-analyse.
- Granger-causaliteit kan niet voorspellen wanneer er een onderlinge afhankelijkheid is tussen twee of meer variabelen (zoals vermeld in casus 3).
- Granger-causaliteitstest kan niet worden uitgevoerd op niet-stationaire gegevens.
Probleem met kip en ei oplossen
Laten we Granger-causaliteit toepassen om te controleren of het ei eerst kwam of de kip eerst.
Bibliotheken importeren
importeer matplotlib.pyplot als plt importeer seaborn als sns importeer numpy als np importeer panda's als pd
Gegevensset laden
De gegevens zijn afkomstig van het Amerikaanse ministerie van landbouw. Het bestaat uit twee-tijdreeksvariabelen van 1930 tot 1983, een van de Amerikaanse eierproductie en de andere van de geschatte Amerikaanse kippenpopulatie.
df = pd.read_csv('chickegg.csv')
De dataset verkennen
df.head ()

df.dtypes

df.vorm
(53, 3)
df.describe ()

Controleer of de gegevens stationair zijn, zo niet, maak ze stationair om door te gaan.
# Draw Plot def plot_df(df, x, y, title="", xlabel='Date', ylabel='Waarde', dpi=100): plt.figure(figsize=(16,5), dpi=dpi) plt.plot(x, y, color='tab:red') plt.gca().set(title=title, xlabel=xlabel, ylabel=ylabel) plt.show() plot_df(df, x=df.Year , y=df.chicken, title='Polulation of the chicken in US') plot_df(df, x=df.Year, y=df.egg, title='Egg Produciton')

Bij visuele inspectie zijn zowel de kip- als eigegevens niet stationair. Laten we dit bevestigen door Augmented Test (ADF-test) uit te voeren.
(ADF-test)
ADF-test is een populaire statistische test om te controleren of de Time Series stationair is of niet, die werkt op basis van de unit root-test. Het aantal eenheidswortels in de reeks geeft het aantal differentiatiebewerkingen aan dat nodig is om het stationair te maken
Beschouw de hypothesetest waarbij:
Nul-hypothese (H.0): Reeks heeft een eenheidswortel en is niet-stationair.
Alternatieve hypothese (HA): Reeks heeft geen eenheidswortel en is stationair.
van statsmodels.tsa.stattools import adfuller result = adfuller(df['chicken']) print(f'Test Statistics: {result[0]}') print(f'p-value: {result[1]}') print(f'critical_values: {resultaat[4]}')
if result[1] > 0.05: print("Serie is niet stationair") else: print("Serie is stationair")


resultaat = adfuller(df['ei'])
print(f'Test Statistics: {result[0]}') print(f'p-value: {result[1]}') print(f'critical_values: {result[4]}') if result[1] > 0.05: print("Serie is niet stationair") else: print("Serie is stationair")


p-waarden van zowel de ei- als de kipvariabelen zijn groter dan de significante waarde (0.05), de nulhypothese is geldig en de reeks is niet stationair.
Datatransformatie
Granger-causaliteitstest wordt alleen uitgevoerd op stationaire gegevens, daarom moeten we de gegevens transformeren door ze te differentiëren om ze stationair te maken. Laten we de eerste-orde differentiatie uitvoeren op kip- en eigegevens.
df_transformed = df.diff().dropna() df = df.iloc[1:] print(df.shape) df_transformed.shape

df_getransformeerd.head()

plot_df(df_transformed, x=df.Year, y=df_transformed.chicken, title='Polulation of the chicken in US') plot_df(df_transformed, x=df.Year, y=df_transformed.egg, title='Egg Produciton')

Herhaal de ADF-test opnieuw op gedifferentieerde gegevens om te controleren op stationariteit.
resultaat = adfuller(df_transformed['chicken']) print(f'Test Statistics: {result[0]}') print(f'p-value: {result[1]}') print(f'critical_values: {resultaat [4]}') if result[1] > 0.05: print("Serie is niet stationair") else: print("Serie is stationair")

resultaat = adfuller(df_transformed['egg']) print(f'Test Statistics: {result[0]}') print(f'p-value: {result[1]}') print(f'critical_values: {resultaat [4]}') if result[1] > 0.05: print("Serie is niet stationair") else: print("Serie is stationair")
Getransformeerde kip- en eigegevens zijn stationair, dus er is geen noodzaak voor differentiatie van de tweede orde.
Test de Granger Causaliteit
Er zijn verschillende manieren om de optimale lag te vinden, maar laten we voor de eenvoud vanaf nu de 4e lag overwegen.
Veroorzaken Eggs Granger kippen?
Nul-hypothese (H.0) : eieren veroorzaken geen kip.
Alternatieve hypothese (HA) : eieren granger veroorzaken kip.
van statsmodels.tsa.stattools importeer grangercausalitytests
grangercausalitytests(df_transformed[['chicken', 'egg']], maxlag=4)
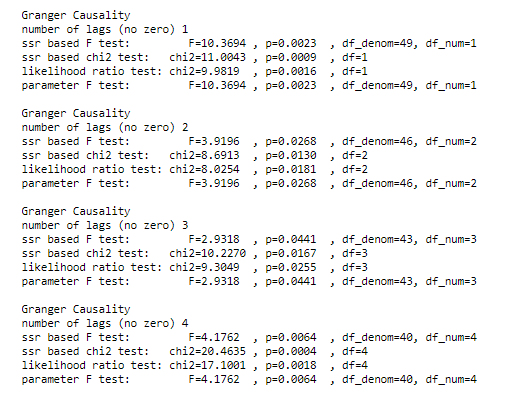
p-waarde is erg laag, nulhypothese wordt verworpen, vandaar dat eieren kippen veroorzaken.
Dat betekent dat eieren eerst kwamen.
Herhaal nu de Granger-causaliteitstest in de tegenovergestelde richting.
Veroorzaken kippen griffel eieren bij lag 4?
Nul-hypothese (H.0) : kip veroorzaakt geen eieren.
Alternatieve hypothese (HA) : kippengriffel veroorzaakt eieren.
grangercausalitytests(df_transformed[['ei', 'kip']], maxlag=4)

De p-waarde is aanzienlijk hoog, dus kippen griezelen niet en veroorzaken geen eieren.
De bovenstaande analyse concludeert dat het ei eerst kwam en niet de kip.
Zodra de analyse is voltooid, is de volgende stap om te beginnen met voorspellen met behulp van voorspellingsmodellen voor tijdreeksen.
EndNote
Telkens wanneer u tijdgebonden gegevens met meerdere variabelen tegenkomt, moet u op uw hoede zijn voor hoge R2 en mogelijke valse regressie. Maak gebruik van de tijdreeksvoorspelling voor betere prestaties. Controleer op bidirectionele Granger-causaliteit tussen elke variabele en elimineer de variabele op basis van testresultaten voordat u doorgaat met voorspellingstechnieken. Ik hoop dat je het artikel leuk vond en inzicht hebt gekregen in het Granger-causaliteitsconcept. Laat uw suggesties of vragen achter in het opmerkingengedeelte.
Bedankt voor het lezen!
over de auteur
Hallo, Pallavi Padav uit Mangalore met een PG-graad in Data Science van INSOFE. Gepassioneerd door deelname aan Data Science hackathons, blogathons en workshops.
Zou je graag willen pakken Linkedin. Stuur me een bericht hier voor eventuele vragen.
Verwant
PlatoAi. Web3 opnieuw uitgevonden. Gegevensintelligentie versterkt.
Klik hier om toegang te krijgen.

