Amazon OpenSearch-service heeft onlangs de OpenSearch Optimized Instance-familie (OR1) geïntroduceerd, die tot 30% prijs-prestatieverbetering levert ten opzichte van bestaande, voor geheugen geoptimaliseerde instances in interne benchmarks, en gebruikt Amazon eenvoudige opslagservice (Amazon S3) voor een duurzaamheid van 11 9s. Met deze nieuwe instancefamilie maakt OpenSearch Service gebruik van OpenSearch-innovatie en AWS-technologieën om opnieuw te bedenken hoe gegevens worden geïndexeerd en opgeslagen in de cloud.
Tegenwoordig maken klanten op grote schaal gebruik van de OpenSearch Service voor operationele analyses vanwege het vermogen om grote hoeveelheden gegevens op te nemen en tegelijkertijd rijke en interactieve analyses te bieden. Om deze voordelen te bieden, is OpenSearch ontworpen als een grootschalig gedistribueerd systeem met meerdere onafhankelijke instanties die gegevens indexeren en verzoeken verwerken. Naarmate de datasnelheid en het datavolume van uw operationele analyses toenemen, kunnen er knelpunten ontstaan. Om een hoog indexeringsvolume duurzaam te ondersteunen en duurzaamheid te bieden, hebben we de OR1-instancefamilie gebouwd.
In dit bericht bespreken we hoe de opnieuw ontworpen gegevensstroom werkt met OR1-instanties en hoe deze een hoge indexeringsdoorvoer en duurzaamheid kan bieden met behulp van een nieuw fysiek replicatieprotocol. We duiken ook diep in enkele van de uitdagingen die we hebben opgelost om de juistheid en gegevensintegriteit te behouden.
Ontwerpen voor hoge doorvoer met een duurzaamheid van 11 9s
OpenSearch Service beheert tienduizenden OpenSearch-clusters. We hebben inzicht gekregen in typische clusterconfiguraties die klanten gebruiken om hoge doorvoer- en duurzaamheidsdoelen te bereiken. Om een hogere doorvoer te bereiken, kiezen klanten er vaak voor om replica-kopieën te laten vallen om te besparen op de replicatielatentie; deze configuratie resulteert echter in het opofferen van beschikbaarheid en duurzaamheid. Andere klanten vereisen een hoge duurzaamheid en moeten daarom meerdere replica-kopieën onderhouden, wat voor hen tot hogere bedrijfskosten leidt.
De OpenSearch Optimized Instance-familie biedt extra duurzaamheid en houdt tegelijkertijd de kosten lager door een kopie van de gegevens op Amazon S3 op te slaan. Met OR1-instanties kunt u meerdere replica-kopieën configureren voor een hoge leesbeschikbaarheid terwijl de indexeringsdoorvoer behouden blijft.
Het volgende diagram illustreert een indexeringsstroom waarbij een metagegevensupdate in OR1 betrokken is
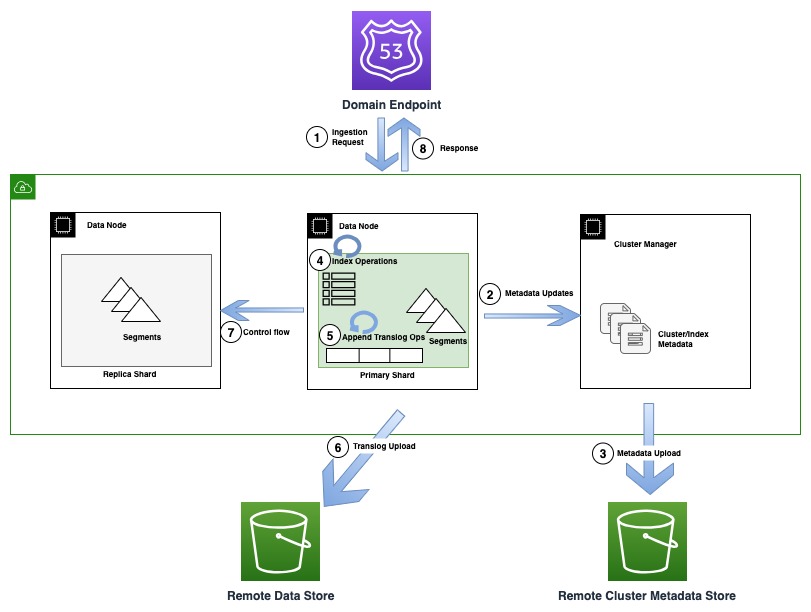
Tijdens indexeringsbewerkingen worden individuele documenten geïndexeerd in Lucene en ook toegevoegd aan een vooruitschrijflogboek, ook wel translog genoemd. Voordat een bevestiging naar de klant wordt teruggestuurd, worden alle translogbewerkingen voortgezet naar de externe gegevensopslag die wordt ondersteund door Amazon S3. Als er replica-kopieën zijn geconfigureerd, voert de primaire kopie om correctheidsredenen controles uit om de mogelijkheid van meerdere schrijvers (controlestroom) op alle replica-kopieën te detecteren.
Het volgende diagram illustreert de stroom voor het genereren en repliceren van segmenten in OR1-instanties
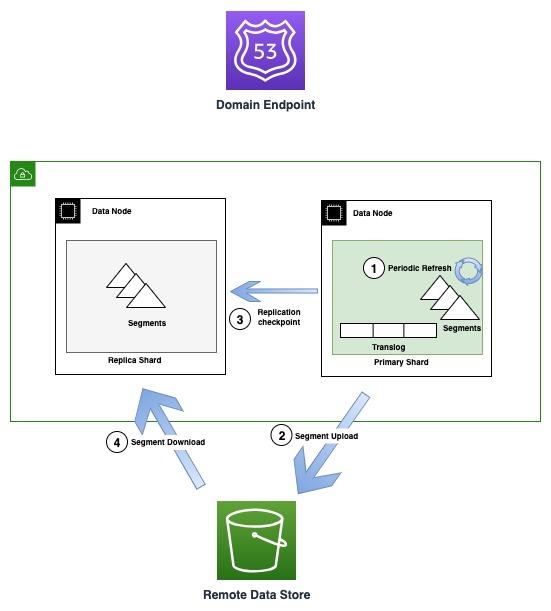
Van tijd tot tijd, als er nieuwe segmentbestanden worden aangemaakt, kopieert de OR1 die segmenten naar Amazon S3. Wanneer de overdracht is voltooid, publiceert de primaire versie nieuwe controlepunten voor alle replica-kopieën, waarbij hen wordt geïnformeerd dat er een nieuw segment beschikbaar is om te downloaden. De replica-kopieën downloaden vervolgens nieuwere segmenten en maken ze doorzoekbaar. Dit model ontkoppelt de gegevensstroom die plaatsvindt met Amazon S3 en de controlestroom (controlepuntpublicatie en termvalidatie) die plaatsvindt via transportcommunicatie tussen knooppunten.
Het volgende diagram illustreert de herstelstroom in OR1-instanties
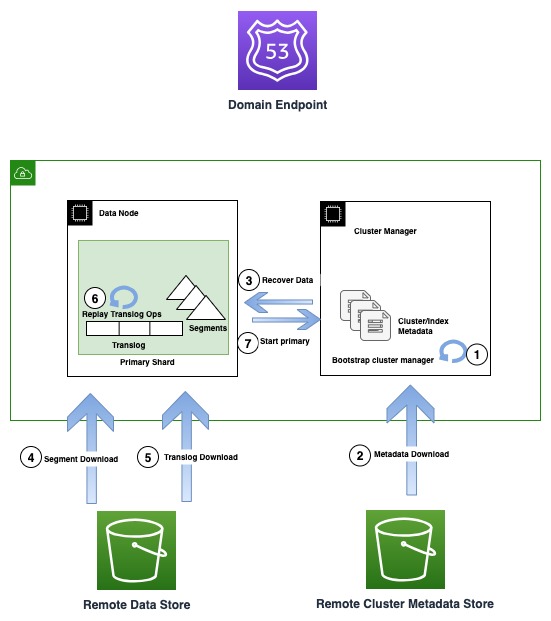
OR1-instanties bewaren niet alleen de gegevens, maar ook de clustermetagegevens zoals indextoewijzingen, sjablonen en instellingen in Amazon S3. Dit zorgt ervoor dat in het geval van verlies van het quorum van de clustermanager, wat een veelvoorkomend probleem is in niet-specifieke clustermanageropstellingen, OpenSearch op betrouwbare wijze de laatste bevestigde metadata kan herstellen.
In het geval van een infrastructuurstoring kan een OpenSearch-domein uiteindelijk een of meer knooppunten verliezen. In een dergelijk geval garandeert de nieuwe instancefamilie het herstel van zowel de clustermetagegevens als de indexgegevens tot aan de laatst erkende bewerking. Wanneer nieuwe vervangende knooppunten zich bij het cluster voegen, start het interne clusterherstelmechanisme de nieuwe set knooppunten op en herstelt vervolgens de nieuwste clustermetagegevens uit de externe clustermetagegevensopslag. Nadat de clustermetagegevens zijn hersteld, begint het herstelmechanisme de ontbrekende segmentgegevens te hydrateren en te translogeren vanuit Amazon S3. Vervolgens worden alle niet-vastgelegde translogbewerkingen, tot aan de laatste bevestigde bewerking, opnieuw afgespeeld om de verloren kopie te herstellen.
Het nieuwe ontwerp verandert niets aan de manier waarop zoekopdrachten werken. Query's worden normaal verwerkt door de primaire of replica-shard voor elke shard in de index. Mogelijk ziet u langere vertragingen (in het bereik van 10 seconden) voordat alle kopieën consistent zijn op een bepaald tijdstip, omdat de gegevensreplicatie Amazon S3 gebruikt.
Een belangrijk voordeel van deze architectuur is dat deze dient als fundamentele bouwsteen voor toekomstige innovaties, zoals de scheiding van lezers en schrijvers, en helpt bij het scheiden van computer- en opslaglagen.
Hoe het opnieuw definiëren van de replicatiestrategie de indexeringsdoorvoer verhoogt
OpenSearch ondersteunt twee replicatiestrategieën: logische (document) en fysieke (segment) replicatie. In het geval van logische replicatie worden de gegevens onafhankelijk van elkaar op alle kopieën geïndexeerd, wat leidt tot redundante berekeningen op het cluster. De OR1-instanties gebruiken het new fysieke replicatie model, waarbij gegevens alleen op de primaire kopie worden geïndexeerd en extra kopieën worden gemaakt door gegevens uit de primaire kopie te kopiëren. Met een groot aantal replica-kopieën heeft het knooppunt dat de primaire kopie host een aanzienlijke netwerkbandbreedte nodig, waarbij het segment naar alle kopieën wordt gerepliceerd. De nieuwe OR1-instanties lossen dit probleem op door het segment duurzaam te behouden voor Amazon S3, dat is geconfigureerd als een externe opslag keuze. Ze helpen ook bij het schalen van replica's zonder knelpunten op het primaire systeem.
Nadat de segmenten zijn geüpload naar Amazon S3, verzendt de primaire een controlepuntverzoek, waarbij alle replica's worden geïnformeerd dat ze de nieuwe segmenten moeten downloaden. De replicakopieën moeten vervolgens de incrementele segmenten downloaden. Omdat dit proces computerresources op replica's vrijmaakt, die anders nodig zijn om data redundant te indexeren en netwerkoverhead op primaire data te repliceren, kan het cluster meer doorvoer genereren. In het geval dat de replica's de nieuw gemaakte segmenten niet kunnen verwerken vanwege overbelasting of trage netwerkpaden, worden de replica's voorbij een punt gemarkeerd als mislukt om te voorkomen dat ze verouderde resultaten retourneren.
Waarom hoge duurzaamheid een goed idee is, maar moeilijk om goed te doen
Hoewel alle vastgelegde segmenten duurzaam worden bewaard in Amazon S3 wanneer ze worden aangemaakt, is een van de belangrijkste uitdagingen bij het bereiken van hoge duurzaamheid het synchroon schrijven van alle niet-vastgelegde bewerkingen naar een vooruitschrijflogboek op Amazon S3, voordat het verzoek aan de klant wordt bevestigd, zonder dat dit ten koste gaat van doorvoer. De nieuwe semantiek introduceert extra netwerklatentie voor individuele verzoeken, maar de manier waarop we ervoor hebben gezorgd dat er geen impact is op de doorvoer is door verzoeken op één thread te batchen en leeg te laten lopen gedurende een bepaald interval, terwijl we ervoor zorgen dat andere threads blijven indexeren verzoeken. Als gevolg hiervan kunt u een hogere doorvoer realiseren met meer gelijktijdige clientverbindingen door uw bulkpayloads optimaal in batches te plaatsen.
Andere uitdagingen bij het ontwerpen van een zeer duurzaam systeem zijn onder meer het te allen tijde afdwingen van de gegevensintegriteit en -correctheid. Hoewel sommige gebeurtenissen, zoals netwerkpartities, zeldzaam zijn, kunnen ze de correctheid van het systeem aantasten en daarom moet het systeem voorbereid zijn op het omgaan met deze storingsmodi. Daarom hebben we bij de overstap naar het nieuwe segmentreplicatieprotocol ook een aantal andere protocolwijzigingen geïntroduceerd, zoals het detecteren van meerdere schrijvers op elke replica. Het protocol zorgt ervoor dat een geïsoleerde schrijver een schrijfverzoek niet kan bevestigen, terwijl een andere onlangs gepromoveerde primaire, gebaseerd op het clustermanagerquorum, tegelijkertijd nieuwere schrijfbewerkingen accepteert.
De nieuwe instancefamilie detecteert automatisch het verlies van een primaire shard tijdens het herstellen van gegevens, en voert uitgebreide controles uit op de netwerkbereikbaarheid voordat de gegevens opnieuw kunnen worden gehydrateerd vanuit Amazon S3 en het cluster weer in een gezonde staat wordt gebracht.
Voor de gegevensintegriteit worden alle bestanden uitgebreid gecontroleerd om er zeker van te zijn dat we netwerk- of bestandssysteemcorruptie kunnen detecteren en voorkomen, waardoor gegevens onleesbaar kunnen worden. Bovendien zijn alle bestanden, inclusief metagegevens, ontworpen om onveranderlijk te zijn, wat extra veiligheid biedt tegen corruptie, en zijn er versies gemaakt om onbedoelde muterende wijzigingen te voorkomen.
Een nieuwe kijk op de manier waarop gegevens stromen
De OR1-instanties hydrateren kopieën rechtstreeks vanuit Amazon S3 om verloren shards te herstellen tijdens een infrastructuurstoring. Door Amazon S3 te gebruiken, kunnen we de netwerkbandbreedte, schijfdoorvoer en rekenkracht van het primaire knooppunt vrijmaken, en daardoor een meer naadloze in-place schaling en blauw/groene implementatie-ervaring bieden door het hele proces te orkestreren met minimale coördinatie van het primaire knooppunt.
OpenSearch Service biedt automatische zogenaamde gegevensback-ups snapshots met tussenpozen van een uur, wat betekent dat u in geval van onbedoelde wijzigingen in de gegevens de mogelijkheid heeft om terug te gaan naar een vorig tijdstip. Met de nieuwe OpenSearch-instantiefamilie hebben we echter besproken dat de gegevens al duurzaam bewaard blijven op Amazon S3. Dus hoe werken snapshots als we de gegevens al op Amazon S3 hebben?
Met de nieuwe instancefamilie dienen snapshots als controlepunten, waarbij wordt verwezen naar de reeds aanwezige segmentgegevens zoals deze op een bepaald moment bestaan. Dit maakt snapshots lichter en sneller omdat ze geen extra gegevens opnieuw hoeven te uploaden. In plaats daarvan uploaden ze metadatabestanden die de weergave van de segmenten op dat moment vastleggen, wat we noemen ondiepe momentopnames. Het voordeel van oppervlakkige snapshots strekt zich uit tot alle bewerkingen, namelijk het maken, verwijderen en klonen van snapshots. U hebt nog steeds de mogelijkheid om een onafhankelijke kopie te maken handmatige momentopnamen voor andere administratieve handelingen.
Samengevat
OpenSearch is open source, gemeenschapsgestuurde software. De meeste fundamentele veranderingen, waaronder het replicatiemodel, opslag op afstand en metadata van clusters op afstand, zijn bijgedragen aan open source; in feite volgen we een open source first ontwikkelingsmodel.
Inspanningen om de doorvoer en betrouwbaarheid te verbeteren zijn een eindeloze cyclus waarin we blijven leren en verbeteren. De nieuwe geoptimaliseerde OpenSearch-instanties dienen als fundamentele bouwsteen en maken de weg vrij voor toekomstige innovaties. We zijn verheugd om onze inspanningen voort te zetten in het verbeteren van de betrouwbaarheid en prestaties en om te zien welke nieuwe en bestaande oplossingenbouwers kunnen creëren met behulp van de OpenSearch Service. We hopen dat dit leidt tot een dieper inzicht in de nieuwe OpenSearch-instantiefamilie, hoe dit aanbod een hoge duurzaamheid en betere doorvoer bereikt, en hoe het u kan helpen clusters te configureren op basis van de behoeften van uw bedrijf.
Als je graag wilt bijdragen aan OpenSearch, open dan een GitHub-probleem en laat ons uw mening weten. We horen ook graag uw succesverhalen over het behalen van een hoge doorvoer en duurzaamheid op de OpenSearch Service. Als u nog andere vragen heeft, kunt u een reactie achterlaten.
Over de auteurs
 Bukhtawar Khan is een hoofdingenieur die werkt aan de Amazon OpenSearch-service. Hij is geïnteresseerd in het bouwen van gedistribueerde en autonome systemen. Hij is een onderhouder en levert een actieve bijdrage aan OpenSearch.
Bukhtawar Khan is een hoofdingenieur die werkt aan de Amazon OpenSearch-service. Hij is geïnteresseerd in het bouwen van gedistribueerde en autonome systemen. Hij is een onderhouder en levert een actieve bijdrage aan OpenSearch.
 Gaurav Bafna is een Senior Software Engineer die werkt aan OpenSearch bij Amazon Web Services. Hij is gefascineerd door het oplossen van problemen in gedistribueerde systemen. Hij is een onderhouder en levert een actieve bijdrage aan OpenSearch.
Gaurav Bafna is een Senior Software Engineer die werkt aan OpenSearch bij Amazon Web Services. Hij is gefascineerd door het oplossen van problemen in gedistribueerde systemen. Hij is een onderhouder en levert een actieve bijdrage aan OpenSearch.
 Sachin Boerenkool is een senior softwareontwikkelingsingenieur bij AWS die aan OpenSearch werkt.
Sachin Boerenkool is een senior softwareontwikkelingsingenieur bij AWS die aan OpenSearch werkt.
 Rohin Bhargava is Senior Product Manager bij het Amazon OpenSearch Service-team. Zijn passie bij AWS is om klanten te helpen de juiste mix van AWS-services te vinden om succes te behalen voor hun zakelijke doelen.
Rohin Bhargava is Senior Product Manager bij het Amazon OpenSearch Service-team. Zijn passie bij AWS is om klanten te helpen de juiste mix van AWS-services te vinden om succes te behalen voor hun zakelijke doelen.
 Ranjith Ramachandra is een Senior Engineering Manager die werkt aan Amazon OpenSearch Service. Hij is gepassioneerd door zeer schaalbare gedistribueerde systemen, krachtige en veerkrachtige systemen.
Ranjith Ramachandra is een Senior Engineering Manager die werkt aan Amazon OpenSearch Service. Hij is gepassioneerd door zeer schaalbare gedistribueerde systemen, krachtige en veerkrachtige systemen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/amazon-opensearch-service-under-the-hood-opensearch-optimized-instancesor1/

