Vandaag maken wij dat met trots bekend Amazon DataZone is nu in staat om gegevenskwaliteitsinformatie voor gegevensassets te presenteren. Deze informatie stelt eindgebruikers in staat weloverwogen beslissingen te nemen over het al dan niet gebruiken van specifieke activa.
Veel organisaties maken er al gebruik van AWS Glue-gegevenskwaliteit om gegevenskwaliteitsregels voor hun gegevens te definiëren en af te dwingen, valideer gegevens aan de hand van vooraf gedefinieerde regels, gegevenskwaliteitsstatistieken bijhouden, en de gegevenskwaliteit in de loop van de tijd bewaken met behulp van kunstmatige intelligentie (AI). Andere organisaties bewaken de kwaliteit van hun gegevens via oplossingen van derden.
Amazon DataZone integreert nu rechtstreeks met AWS Glue om datakwaliteitsscores voor AWS Glue Data Catalog-middelen weer te geven. Bovendien biedt Amazon DataZone nu API's voor het importeren van gegevenskwaliteitsscores uit externe systemen.
In dit bericht bespreken we de nieuwste features van Amazon DataZone voor datakwaliteit, de integratie tussen Amazon DataZone en AWS Glue Data Quality en hoe je datakwaliteitsscores geproduceerd door externe systemen via API in Amazon DataZone kunt importeren.
Uitdagingen
Een van de meest voorkomende vragen die we van klanten krijgen, heeft betrekking op het weergeven van gegevenskwaliteitsscores in de Amazon DataZone-catalogus voor bedrijfsgegevens om zakelijke gebruikers inzicht te geven in de gezondheid en betrouwbaarheid van de datasets.
Nu data steeds belangrijker worden voor het nemen van zakelijke beslissingen, zijn Amazon DataZone-gebruikers zeer geïnteresseerd in het bieden van de hoogste normen op het gebied van datakwaliteit. Ze erkennen het belang van nauwkeurige, volledige en tijdige gegevens om geïnformeerde besluitvorming mogelijk te maken en het vertrouwen in hun analyse- en rapportageprocessen te bevorderen.
Amazon DataZone-gegevensmiddelen kunnen met verschillende frequenties worden bijgewerkt. Terwijl gegevens worden vernieuwd en bijgewerkt, kunnen er veranderingen optreden via upstream-processen waardoor het risico bestaat dat de beoogde kwaliteit niet wordt behouden. Gegevenskwaliteitsscores helpen u te begrijpen of gegevens het verwachte kwaliteitsniveau hebben behouden dat gegevensconsumenten kunnen gebruiken (via analyse of downstream-processen).
Vanuit het perspectief van een producent kunnen datastewards nu Amazon DataZone instellen om automatisch de datakwaliteitsscores van AWS Glue Data Quality te importeren (gepland of op aanvraag) en deze informatie op te nemen in de Amazon DataZone-catalogus om te delen met zakelijke gebruikers. Bovendien kunt u nu nieuwe Amazon DataZone API's gebruiken om datakwaliteitsscores geproduceerd door externe systemen in de data-assets te importeren.
Met de nieuwste verbetering kunnen Amazon DataZone-gebruikers nu het volgende bereiken:
- Krijg rechtstreeks toegang tot inzichten over datakwaliteitsnormen via het Amazon DataZone-webportaal
- Bekijk gegevenskwaliteitsscores op verschillende KPI's, waaronder de volledigheid, uniciteit en nauwkeurigheid van gegevens
- Zorg ervoor dat gebruikers een holistisch beeld hebben van de kwaliteit en betrouwbaarheid van hun gegevens.
In het eerste deel van dit bericht doorlopen we de integratie tussen AWS Glue Data Quality en Amazon DataZone. We bespreken hoe u gegevenskwaliteitsscores in Amazon DataZone kunt visualiseren, AWS Glue Data Quality kunt inschakelen bij het maken van een nieuwe Amazon DataZone-gegevensbron en hoe u gegevenskwaliteit voor een bestaand gegevensmiddel kunt inschakelen.
In het tweede deel van dit bericht bespreken we hoe u via API gegevenskwaliteitsscores die door externe systemen zijn geproduceerd, in Amazon DataZone kunt importeren. In dit voorbeeld gebruiken we Amazon EMR Serverloos in combinatie met de open source bibliotheek Pydeequ om te fungeren als een extern systeem voor datakwaliteit.
Visualiseer AWS Glue Data Quality-scores in Amazon DataZone
U kunt nu AWS Glue Data Quality-scores visualiseren in data-assets die zijn gepubliceerd in de Amazon DataZone-bedrijfscatalogus en die doorzoekbaar zijn via het Amazon DataZone-webportaal.
Als voor het asset AWS Glue Data Quality is ingeschakeld, kunt u de datakwaliteitsscore nu snel direct in het zoekvenster van de catalogus visualiseren.

Door het overeenkomstige item te selecteren, kunt u de inhoud ervan begrijpen via het leesmij-bestand, woordenlijst termen en technische en zakelijke metadata. Bovendien wordt de algehele kwaliteitsscore-indicator weergegeven in de Itemdetails pagina.

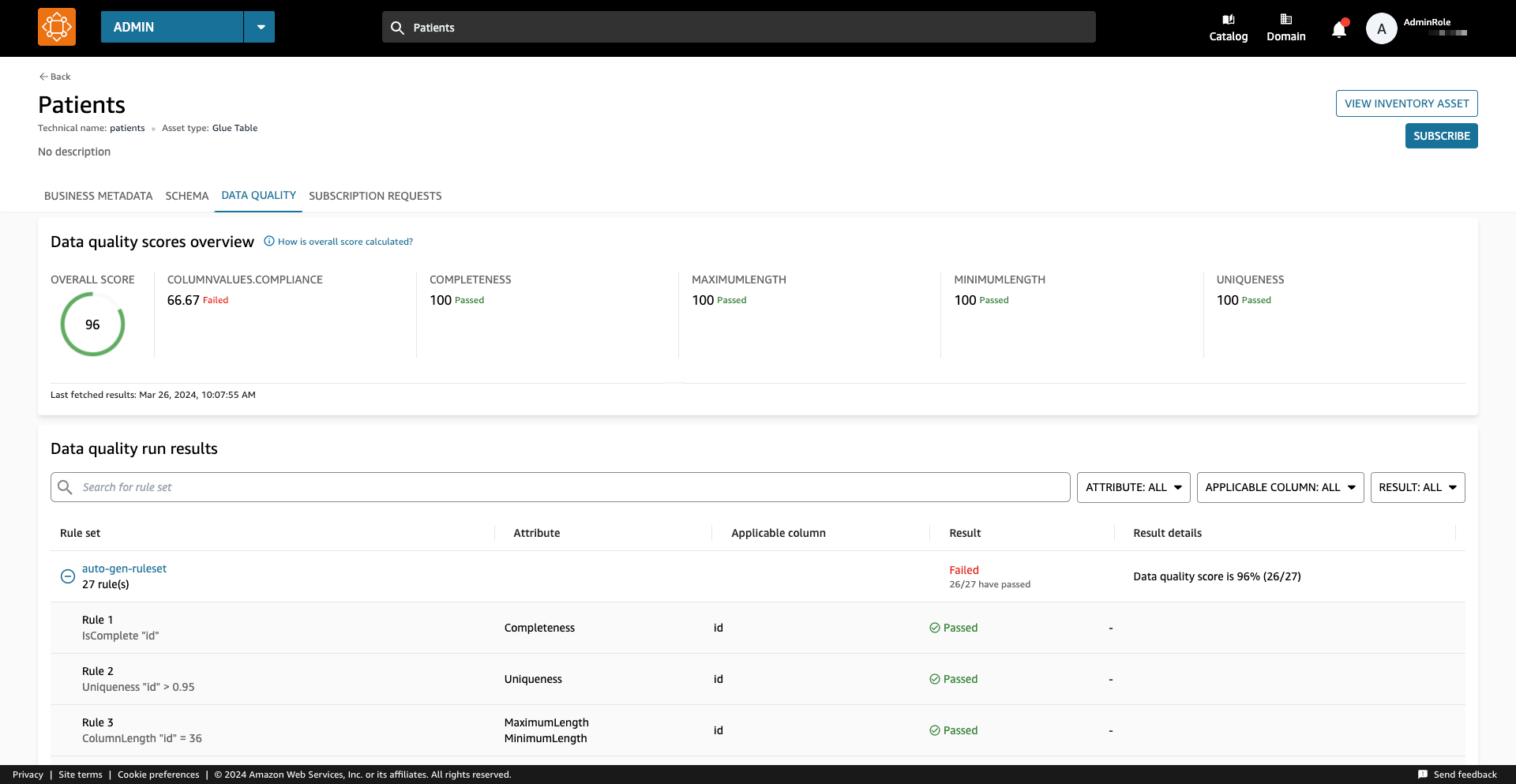
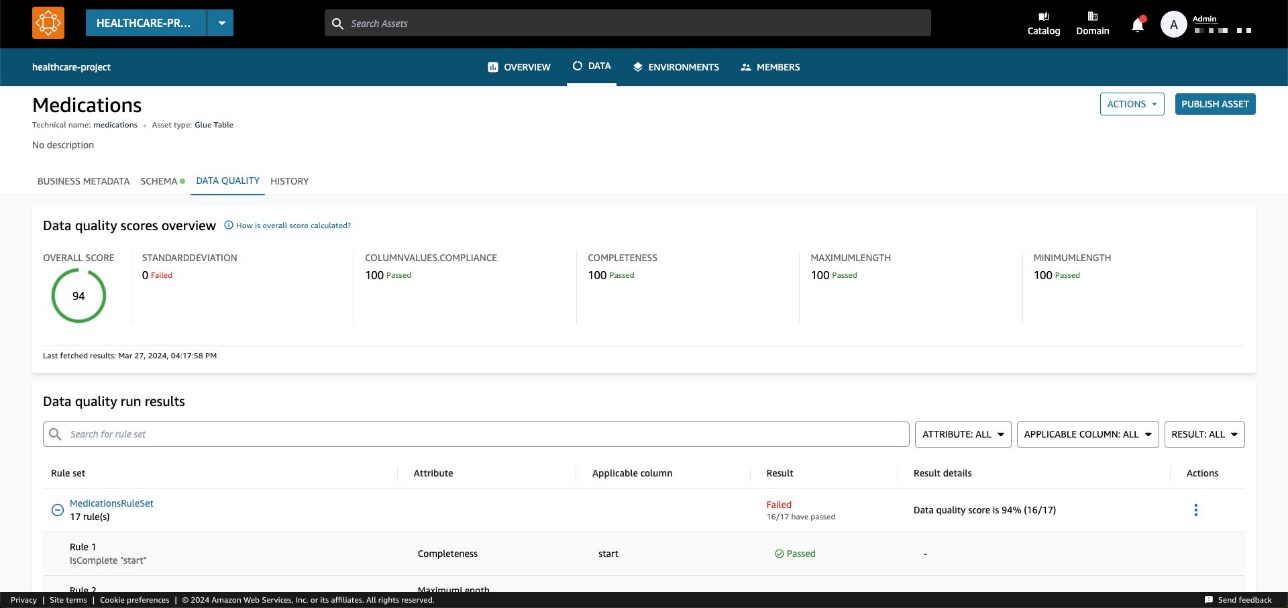
Een datakwaliteitsscore dient als een algemene indicator van de kwaliteit van een dataset, berekend op basis van de regels die u definieert.
Op de Data kwaliteit tabblad heeft u toegang tot de details van de overzichtsindicatoren voor gegevenskwaliteit en de resultaten van de gegevenskwaliteitsruns.
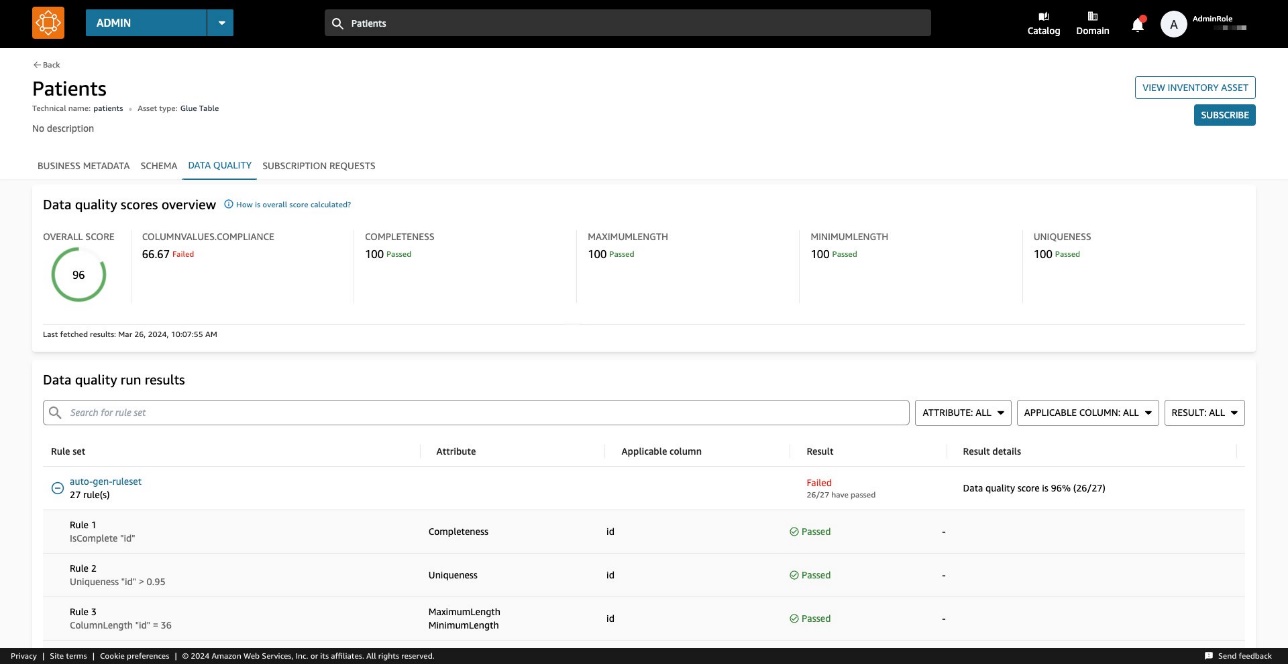
De indicatoren die worden weergegeven op de Overzicht tabblad worden berekend op basis van de resultaten van de regelsets van de gegevenskwaliteitsruns.
Aan elke regel wordt een attribuut toegewezen dat bijdraagt aan de berekening van de indicator. Regels met bijvoorbeeld de Completeness attribuut zal bijdragen aan de berekening van de overeenkomstige indicator op de Overzicht Tab.
Als u de resultaten van de gegevenskwaliteit wilt filteren, kiest u de Toepasselijke kolom vervolgkeuzemenu en kies de gewenste filterparameter.

U kunt ook de gegevenskwaliteit op kolomniveau visualiseren, beginnend op de Schema Tab.

Wanneer gegevenskwaliteit is ingeschakeld voor het asset, worden de gegevenskwaliteitsresultaten beschikbaar, waardoor inzichtelijke kwaliteitsscores worden verkregen die de integriteit en betrouwbaarheid van elke kolom binnen de gegevensset weerspiegelen.
Wanneer u een van de koppelingen naar gegevenskwaliteitresultaten kiest, wordt u doorgestuurd naar de gegevenskwaliteitdetailpagina, gefilterd op de geselecteerde kolom.

Historische resultaten van gegevenskwaliteit in Amazon DataZone
De gegevenskwaliteit kan om verschillende redenen in de loop van de tijd veranderen:
- Dataformaten kunnen veranderen als gevolg van veranderingen in de bronsystemen
- Naarmate gegevens zich in de loop van de tijd ophopen, kunnen ze verouderd of inconsistent raken
- De gegevenskwaliteit kan worden beïnvloed door menselijke fouten bij gegevensinvoer, gegevensverwerking of gegevensmanipulatie
In Amazon DataZone kun je nu de gegevenskwaliteit in de loop van de tijd volgen om de betrouwbaarheid en nauwkeurigheid te bevestigen. Door de momentopname van het historische rapport te analyseren, kunt u verbeterpunten identificeren, wijzigingen doorvoeren en de effectiviteit van die wijzigingen meten.

Schakel AWS Glue Data Quality in bij het maken van een nieuwe Amazon DataZone-gegevensbron
In dit gedeelte doorlopen we de stappen om AWS Glue Data Quality in te schakelen bij het maken van een nieuwe Amazon DataZone-gegevensbron.
Voorwaarden
Om mee te gaan, zou u een domein voor Amazon DataZone, een Amazon DataZone-project en een nieuw domein moeten hebben Amazon DataZone-omgeving (met een DataLakeProfile). Voor instructies, zie Amazon DataZone-snelstart met AWS Glue-gegevens.
U moet ook een regelset definiëren en uitvoeren op basis van uw gegevens. Dit is een set gegevenskwaliteitsregels in AWS Glue Data Quality. Raadpleeg de volgende berichten om de regels voor gegevenskwaliteit in te stellen en voor meer informatie over dit onderwerp:
Nadat u de regels voor gegevenskwaliteit hebt gemaakt, zorgt u ervoor dat Amazon DataZone de machtigingen heeft om toegang te krijgen tot de AWS Glue-database die wordt beheerd via AWS Lake-formatie. Voor instructies, zie Configureer Lake Formation-machtigingen voor Amazon DataZone.
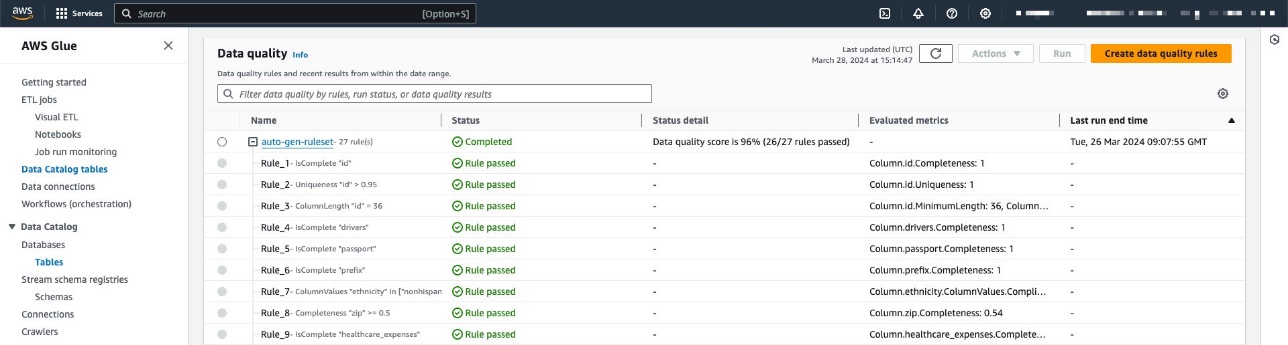
In ons voorbeeld hebben we een regelset geconfigureerd voor een tabel met patiëntgegevens binnen een synthetische dataset voor de gezondheidszorg gegenereerd met behulp van synthea. Synthea is een synthetische patiëntgenerator die realistische patiëntgegevens en bijbehorende medische dossiers creëert die kunnen worden gebruikt voor het testen van softwaretoepassingen in de gezondheidszorg.
De regelset bevat 27 individuele regels (waarvan er één faalt), dus de algehele datakwaliteitsscore is 96%.
Als u door Amazon DataZone beheerd beleid gebruikt, hoeft u geen actie te ondernemen, omdat dit automatisch wordt bijgewerkt met de benodigde acties. Anders moet u Amazon DataZone de vereiste machtigingen geven om AWS Glue Data Quality-resultaten weer te geven en te verkrijgen, zoals weergegeven in de Amazon DataZone-gebruikershandleiding.
Maak een gegevensbron waarvoor gegevenskwaliteit is ingeschakeld
In deze sectie creëren we een gegevensbron en maken we gegevenskwaliteit mogelijk. U kunt ook een bestaande gegevensbron bijwerken om de gegevenskwaliteit mogelijk te maken. We gebruiken deze gegevensbron om metadata-informatie met betrekking tot onze datasets te importeren. Amazon DataZone importeert ook gegevenskwaliteitsinformatie met betrekking tot de (een of meer) activa in de gegevensbron.
- Kies op de Amazon DataZone-console Data bronnen in het navigatievenster.
- Kies Maak een gegevensbron.

- Voor Naam, voer een naam in voor uw gegevensbron.
- Voor Type gegevensbronselecteer AWS lijm.
- Voor Milieu, kies uw omgeving.

- Voor Database naam, voer een naam in voor de database.
- Voor Tabelselectiecriteria, kies uw criteria.
- Kies Volgende.

- Voor Data kwaliteitselecteer Schakel gegevenskwaliteit in voor deze gegevensbron.
Als de gegevenskwaliteit is ingeschakeld, haalt Amazon DataZone automatisch gegevenskwaliteitsscores op van AWS Glue bij elke gegevensbronrun.
- Kies Volgende.

Nu kunt u de gegevensbron uitvoeren.

Terwijl de gegevensbron wordt uitgevoerd, importeert Amazon DataZone de laatste 100 AWS Glue Data Quality-runresultaten. Deze informatie is nu zichtbaar op de assetpagina en zal zichtbaar zijn voor alle Amazon DataZone-gebruikers na publicatie van het asset.
Maak datakwaliteit mogelijk voor een bestaande data-asset
In deze sectie schakelen we gegevenskwaliteit in voor een bestaand asset. Dit kan handig zijn voor gebruikers die al over gegevensbronnen beschikken en de functie achteraf willen inschakelen.
Voorwaarden
Om verder te gaan, zou u de gegevensbron al moeten hebben uitgevoerd en een AWS Glue-tabelgegevensitem moeten hebben geproduceerd. Bovendien had u een regelset moeten definiëren in AWS Glue Data Quality voor de doeltabel in de Data Catalog.

Voor dit voorbeeld hebben we de datakwaliteitstaak meerdere keren tegen de tabel uitgevoerd, waarbij de gerelateerde AWS Glue Data Quality-scores werden geproduceerd, zoals weergegeven in de volgende schermafbeelding.

Importeer datakwaliteitsscores in de data-asset
Voer de volgende stappen uit om de bestaande AWS Glue Data Quality-scores te importeren in de data-asset in Amazon DataZone:
- Navigeer binnen het Amazon DataZone-project naar het Voorraadgegevens deelvenster en kies de gegevensbron.
Als u de optie selecteert Data kwaliteit Op het tabblad kunt u zien dat er nog steeds geen informatie is over de gegevenskwaliteit, omdat AWS Glue Data Quality-integratie nog niet is ingeschakeld voor dit gegevensitem.
- Op de Data kwaliteit tabblad, kies Maak datakwaliteit mogelijk.

- In het Data kwaliteit sectie, selecteer Schakel gegevenskwaliteit in voor deze gegevensbron.
- Kies Bespaar.

Nu, terug in het deelvenster Voorraadgegevens, ziet u een nieuw tabblad: Data kwaliteit.
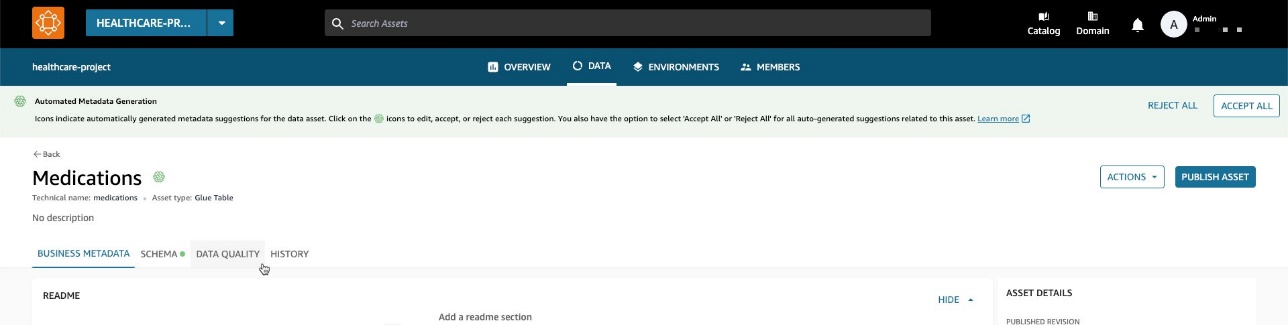
Op de Data kwaliteit Op het tabblad kunt u gegevenskwaliteitsscores bekijken die zijn geïmporteerd uit AWS Glue Data Quality.
Neem gegevenskwaliteitsscores op van een externe bron met behulp van Amazon DataZone API's
Veel organisaties maken al gebruik van systemen die de datakwaliteit berekenen door tests en beweringen uit te voeren op hun datasets. Amazon DataZone ondersteunt nu het importeren van gegevenskwaliteitsscores van derden via API, waardoor gebruikers die door het webportaal navigeren, deze informatie kunnen bekijken.
In deze sectie simuleren we een systeem van derden dat datakwaliteitsscores via API's naar Amazon DataZone stuurt Boto3 (Python SDK voor AWS).
Voor dit voorbeeld gebruiken we hetzelfde synthetische dataset zoals eerder, gegenereerd met synthea.
Het volgende diagram illustreert de oplossingsarchitectuur.

De workflow bestaat uit de volgende stappen:
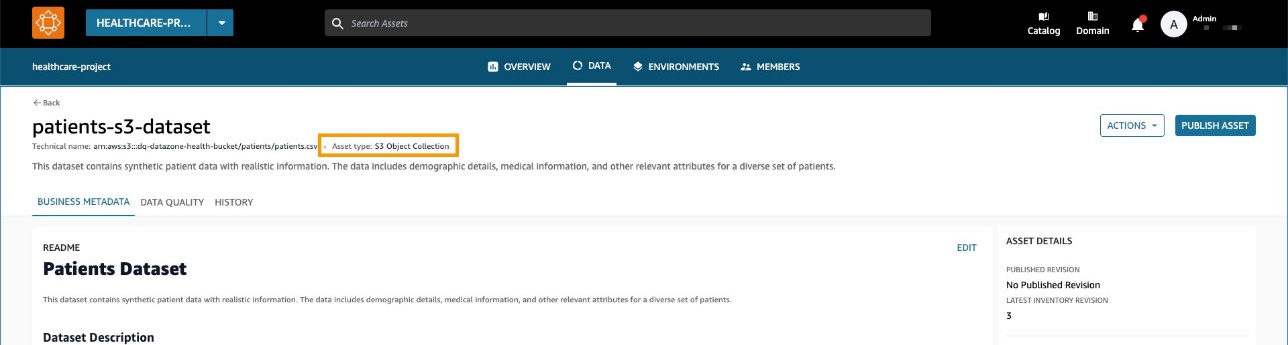
- Lees een dataset van patiënten in Amazon eenvoudige opslagservice (Amazon S3) rechtstreeks vanuit Amazon EMR met Spark.
De dataset wordt gemaakt als een generieke S3-activaverzameling in Amazon DataZone.
- Voer in Amazon EMR gegevensvalidatieregels uit voor de dataset.
- De statistieken worden opgeslagen in Amazon S3 om een blijvende uitvoer te hebben.
- Gebruik Amazon DataZone API's via Boto3 om aangepaste metagegevens van gegevenskwaliteit te pushen.
- Eindgebruikers kunnen de datakwaliteitsscores bekijken door naar het dataportaal te navigeren.
Voorwaarden
Wij gebruiken Amazon EMR Serverloos en Pydeequ om een volledig beheerd beheer uit te voeren Vonk omgeving. Voor meer informatie over Pydeequ als raamwerk voor het testen van gegevens, zie Gegevenskwaliteit op schaal testen met Pydeequ.
Om Amazon EMR toe te staan gegevens naar het Amazon DataZone-domein te verzenden, moet u ervoor zorgen dat de IAM-rol die door Amazon EMR wordt gebruikt, de machtigingen heeft om het volgende te doen:
- Lees van en schrijf naar de S3-buckets
- Bel de
post_time_series_data_pointsactie voor Amazon DataZone:
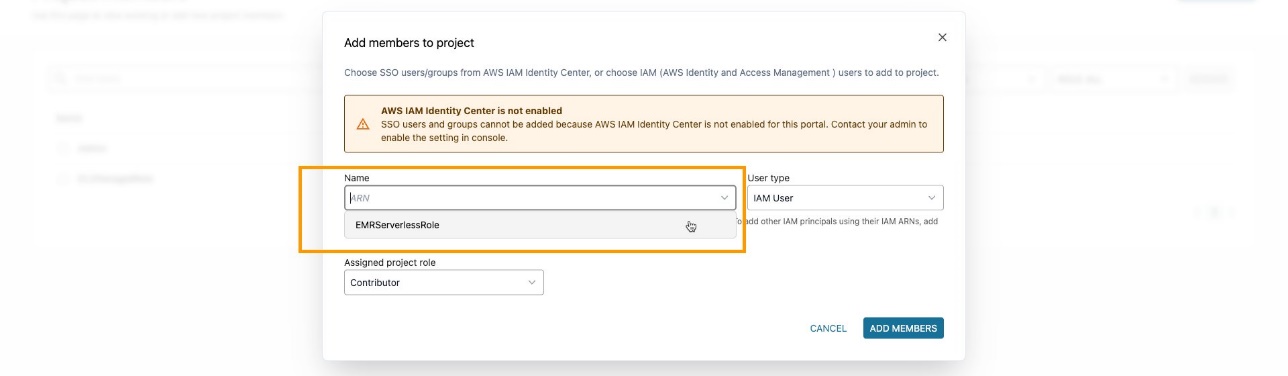
Zorg ervoor dat u de EMR-rol hebt toegevoegd als een projectlid in het Amazon DataZone-project. Navigeer op de Amazon DataZone-console naar het Projectleden pagina en kies leden toevoegen.

Voeg de EMR-rol toe als bijdrager.
PySpark-code opnemen en analyseren
In deze sectie analyseren we de PySpark-code die we gebruiken om gegevenskwaliteitscontroles uit te voeren en de resultaten naar Amazon DataZone te sturen. U kunt het volledige downloaden PySpark-script.
Om het script volledig uit te voeren, kunt u een taak indienen bij EMR Serverless. De service zorgt voor het plannen van de taak en het automatisch toewijzen van de benodigde middelen, zodat u de taak kunt volgen statussen van taakuitvoering gedurende het hele proces.
Je kunt verzend een taak naar EMR binnen de Amazon EMR-console met behulp van EMR Studio of programmatisch, met behulp van de AWS CLI of gebruik een van de AWS SDK's.
In Apache Spark wordt een SparkSession is het startpunt voor interactie met DataFrames en de ingebouwde functies van Spark. Het script begint met het initialiseren van a SparkSession:
We lezen een dataset van Amazon S3. Voor meer modulariteit kunt u de scriptinvoer gebruiken om naar het S3-pad te verwijzen:
Vervolgens hebben we een gegevensopslagplaats opgezet. Dit kan handig zijn om de runresultaten in Amazon S3 te behouden.
Met Pydeequ kunt u datakwaliteitsregels maken met behulp van het builder-patroon, een bekend ontwerppatroon voor software-engineering, waarbij instructies worden samengevoegd om een VerificationSuite voorwerp:
Het volgende is de uitvoer voor de gegevensvalidatieregels:
Op dit punt willen we deze gegevenskwaliteitswaarden in Amazon DataZone invoegen. Hiervoor gebruiken wij de post_time_series_data_points functie in de Boto3 Amazon DataZone-client.
De PostTimeSeriesDataPoints DataZone-API Hiermee kunt u nieuwe tijdreeksgegevenspunten invoegen voor een bepaald item of een bepaalde vermelding, zonder een nieuwe revisie te maken.
Op dit moment wilt u wellicht ook meer informatie over welke velden als invoer voor de API worden verzonden. U kunt gebruik maken van de APIs om de specificatie voor Amazon DataZone-formuliertypen te verkrijgen; in ons geval wel amazon.datazone.DataQualityResultFormType.
U kunt ook de AWS CLI gebruiken om de API aan te roepen en de formulierstructuur weer te geven:
Deze uitvoer helpt bij het identificeren van de vereiste API-parameters, inclusief velden en waardelimieten:
Om de juiste formuliergegevens te verzenden, moeten we de Pydeequ-uitvoer converteren zodat deze overeenkomt met de DataQualityResultsFormType contract. Dit kan worden bereikt met een Python-functie die de resultaten verwerkt.
Voor elke DataFrame-rij extraheren we informatie uit de beperkingskolom. Neem bijvoorbeeld de volgende code:
Wij converteren het naar het volgende:
Zorg ervoor dat u een output verzendt die overeenkomt met de KPI's die u wilt volgen. In ons geval voegen we toe _custom aan de statistieknaam, wat resulteert in het volgende formaat voor KPI's:
Completeness_customUniqueness_custom
In een realistisch scenario wilt u misschien een waarde instellen die overeenkomt met uw datakwaliteitsframework in relatie tot de KPI's die u wilt volgen in Amazon DataZone.
Na het toepassen van een transformatiefunctie hebben we een Python-object voor elke regelevaluatie:
We gebruiken ook de constraint_status kolom om de totaalscore te berekenen:
In ons voorbeeld resulteert dit in een slagingspercentage van 85.71%.
Deze waarde stellen we in in de passingPercentage invoerveld samen met de andere informatie met betrekking tot de evaluaties in de invoer van de Boto3-methode post_time_series_data_points:
Boto3 roept de Amazon DataZone-API's. In deze voorbeelden hebben we Boto3 en Python gebruikt, maar je kunt een van de volgende kiezen AWS SDK's ontwikkeld in de taal van uw voorkeur.
Nadat we het juiste domein en item-ID hebben ingesteld en de methode hebben uitgevoerd, kunnen we op de Amazon DataZone-console controleren of de kwaliteit van de itemgegevens nu zichtbaar is op de itempagina.
We kunnen vaststellen dat de algehele score overeenkomt met de API-invoerwaarde. We kunnen ook zien dat we aangepaste KPI's konden toevoegen op het tabblad Overzicht via aangepaste parameterwaarden voor typen.
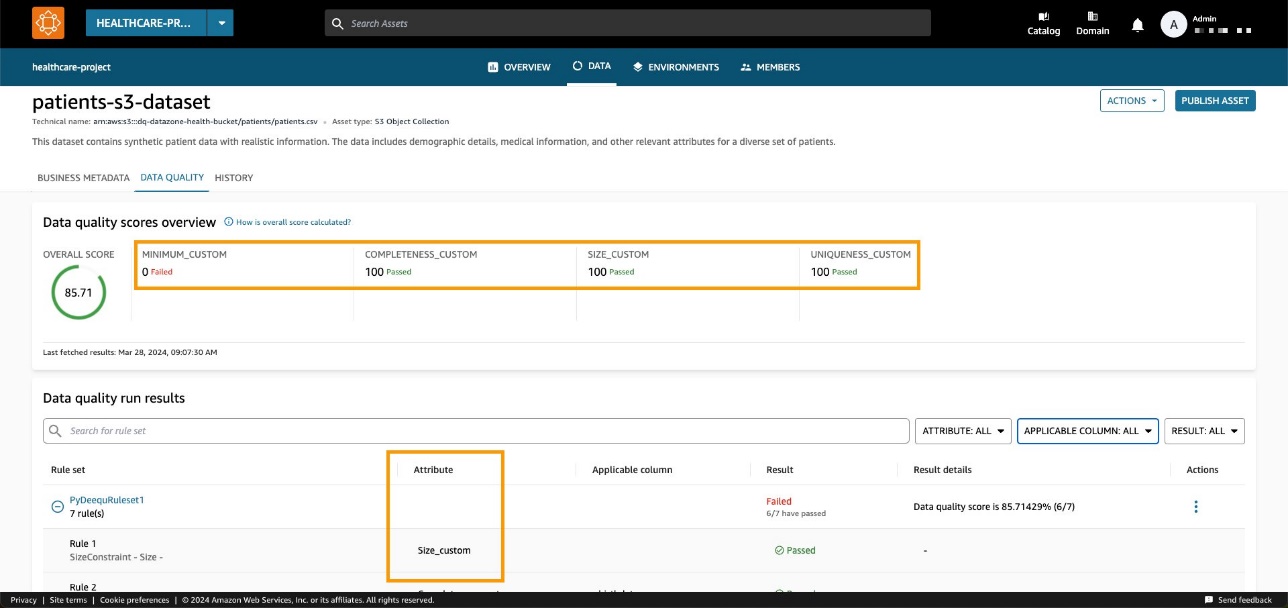
Met de nieuwe Amazon DataZone API's kun je datakwaliteitsregels van systemen van derden in een specifiek data-asset laden. Met deze mogelijkheid kunt u met Amazon DataZone de soorten indicatoren die aanwezig zijn in AWS Glue Data Quality (zoals volledigheid, minimum en uniciteit) uitbreiden met aangepaste indicatoren.
Opruimen
We raden u aan potentieel ongebruikte bronnen te verwijderen om onverwachte kosten te voorkomen. Dat kan bijvoorbeeld verwijder het Amazon DataZone-domein en EMR-applicatie die u tijdens dit proces hebt gemaakt.
Conclusie
In dit bericht hebben we de nieuwste functies van Amazon DataZone voor datakwaliteit belicht, waardoor eindgebruikers verbeterde context en zichtbaarheid in hun data-assets krijgen. Verder hebben we ons verdiept in de naadloze integratie tussen Amazon DataZone en AWS Glue Data Quality. U kunt de Amazon DataZone API's ook gebruiken om te integreren met externe leveranciers van datakwaliteit, zodat u een uitgebreide en robuuste datastrategie binnen uw AWS-omgeving kunt onderhouden.
Voor meer informatie over Amazon DataZone raadpleegt u de Amazon DataZone-gebruikershandleiding.
Over de auteurs
 Andrea Filippo is een Partner Solutions Architect bij AWS en ondersteunt partners en klanten uit de publieke sector in Italië. Hij richt zich op moderne data-architecturen en helpt klanten hun cloudreis te versnellen met serverloze technologieën.
Andrea Filippo is een Partner Solutions Architect bij AWS en ondersteunt partners en klanten uit de publieke sector in Italië. Hij richt zich op moderne data-architecturen en helpt klanten hun cloudreis te versnellen met serverloze technologieën.
 Emanuele is Solutions Architect bij AWS, gevestigd in Italië, na meer dan 5 jaar in Spanje te hebben gewoond en gewerkt. Hij helpt grote bedrijven graag met de adoptie van cloudtechnologieën, waarbij zijn expertisegebied vooral ligt op Data Analytics en Data Management. Buiten zijn werk houdt hij van reizen en het verzamelen van actiefiguren.
Emanuele is Solutions Architect bij AWS, gevestigd in Italië, na meer dan 5 jaar in Spanje te hebben gewoond en gewerkt. Hij helpt grote bedrijven graag met de adoptie van cloudtechnologieën, waarbij zijn expertisegebied vooral ligt op Data Analytics en Data Management. Buiten zijn werk houdt hij van reizen en het verzamelen van actiefiguren.
 Varsha Velagapudi is een Senior Technical Product Manager bij Amazon DataZone bij AWS. Ze richt zich op het verbeteren van de datadetectie en -beheer die nodig zijn voor data-analyse. Ze heeft een passie voor het vereenvoudigen van het AI/ML- en analysetraject van klanten om hen te helpen slagen in hun dagelijkse taken. Buiten haar werk houdt ze van de natuur en buitenactiviteiten, lezen en reizen.
Varsha Velagapudi is een Senior Technical Product Manager bij Amazon DataZone bij AWS. Ze richt zich op het verbeteren van de datadetectie en -beheer die nodig zijn voor data-analyse. Ze heeft een passie voor het vereenvoudigen van het AI/ML- en analysetraject van klanten om hen te helpen slagen in hun dagelijkse taken. Buiten haar werk houdt ze van de natuur en buitenactiviteiten, lezen en reizen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/amazon-datazone-now-integrates-with-aws-glue-data-quality-and-external-data-quality-solutions/

