Amazon Aurora zero-ETL-integratie met Amazon roodverschuiving werd aangekondigd op AWS re: uitvind 2022 en is nu beschikbaar in openbare preview voor Amazon Aurora MySQL-compatibele editie 3 (compatibel met MySQL 8.0) in regio's us-east-1, us-east-2, us-west-2, ap-northeast-1 en eu-west-1. Voor meer details, zie de Wat is er nieuw bericht.
In dit bericht bieden we stapsgewijze richtlijnen voor het aan de slag gaan met bijna realtime operationele analyses met behulp van deze functie.

Uitdagingen
Klanten in verschillende sectoren zijn tegenwoordig op zoek naar manieren om hun omzet en klantbetrokkenheid te vergroten door gebruiksscenario's voor bijna realtime analyses te implementeren, zoals personalisatiestrategieën, fraudedetectie, voorraadbewaking en nog veel meer. Er zijn twee brede benaderingen voor het analyseren van operationele gegevens voor deze use cases:
- Analyseer de aanwezige gegevens in de operationele database (bijv. leesreplica's, federatieve query's, analyseversnellers)
- Verplaats de gegevens naar een datastore die is geoptimaliseerd voor het uitvoeren van analytische query's, zoals een datawarehouse
De zero-ETL-integratie is gericht op het vereenvoudigen van de laatste benadering.
Een veelvoorkomend patroon voor het verplaatsen van gegevens van een operationele database naar een analytisch datawarehouse is via extract, transform en load (ETL), een proces waarbij gegevens uit meerdere bronnen worden gecombineerd in een grote, centrale opslagplaats (datawarehouse). ETL-pijplijnen kunnen duur zijn om te bouwen en complex om te beheren. Met meerdere contactpunten kunnen intermitterende fouten in ETL-pijplijnen tot lange vertragingen leiden, waardoor applicaties die afhankelijk zijn van deze gegevens die beschikbaar zijn in het datawarehouse verouderde of ontbrekende gegevens bevatten, wat verder leidt tot gemiste zakelijke kansen.
Voor klanten die uniforme analyses moeten uitvoeren op gegevens uit meerdere operationele databases, kunnen oplossingen die gegevens ter plekke analyseren uitstekend werken voor het versnellen van query's op een enkele database, maar dergelijke systemen hebben de beperking dat ze geen gegevens uit meerdere operationele databases kunnen aggregeren .
Nul-ETL
Bij AWS hebben we gestage vooruitgang geboekt bij het brengen van onze nul-ETL visie tot leven. Met Aurora zero-ETL-integratie met Amazon Redshift kun je de transactiegegevens van Aurora samenbrengen met de analysemogelijkheden van Amazon Redshift. Het minimaliseert het werk van het bouwen en beheren van aangepaste ETL-pijplijnen tussen Aurora en Amazon Redshift. Data-engineers kunnen nu gegevens uit meerdere Aurora-databaseclusters repliceren naar dezelfde of een nieuwe Amazon Redshift-instantie om holistische inzichten te verkrijgen over veel applicaties of partities. Updates in Aurora worden automatisch en continu doorgegeven aan Amazon Redshift, zodat de data-engineers bijna in realtime over de meest recente informatie beschikken. Bovendien kan het hele systeem serverloos zijn en dynamisch op- en afschalen op basis van het datavolume, zodat er geen infrastructuur hoeft te worden beheerd.
Wanneer u een Aurora zero-ETL-integratie met Amazon Redshift maakt, blijft u betalen voor het gebruik van Aurora en Amazon Redshift met de bestaande prijzen (inclusief gegevensoverdracht). De Aurora zero-ETL-integratie met de Amazon Redshift-functie is zonder extra kosten beschikbaar.
Met Aurora zero-ETL-integratie met Amazon Redshift repliceert de integratie gegevens van de brondatabase naar het beoogde datawarehouse. De gegevens zijn binnen enkele seconden beschikbaar in Amazon Redshift, waardoor gebruikers gebruik kunnen maken van de analysefuncties van Amazon Redshift en mogelijkheden zoals het delen van gegevens, automatische werklastoptimalisatie, concurrency-scaling, machine learning en nog veel meer. U kunt real-time transactieverwerking uitvoeren op gegevens in Aurora en tegelijkertijd Amazon Redshift gebruiken voor analytische werklasten zoals rapportage en dashboards.
Het volgende diagram illustreert deze architectuur.

Overzicht oplossingen
Laat ons nadenken TICKIT, een fictieve website waar gebruikers online kaartjes kopen en verkopen voor sportevenementen, shows en concerten. De transactiegegevens van deze website worden geladen in een Aurora MySQL 3.03.1 (of hogere versie) database. De bedrijfsanalisten van het bedrijf willen meetgegevens genereren om kaartbewegingen in de loop van de tijd, succespercentages voor verkopers en de bestverkopende evenementen, locaties en seizoenen te identificeren. Ze willen deze statistieken bijna in realtime ontvangen met behulp van een zero-ETL-integratie.
De integratie is opgezet tussen Amazon Aurora MySQL-Compatible Edition 3.03.1 (bron) en Amazon Redshift (bestemming). De transactiegegevens van de bron worden bijna in realtime vernieuwd op de bestemming, die analytische vragen verwerkt.
U kunt de ingerichte of serverloze optie gebruiken voor zowel Amazon Aurora MySQL-Compatible Edition als Amazon Redshift. Voor deze illustratie gebruiken we een ingerichte Aurora-database en een Amazon Redshift Serverloos datawarehouse. Raadpleeg de functie voor de volledige lijst met overwegingen voor openbare previews AWS-documentatie.
Het volgende diagram illustreert de architectuur op hoog niveau.

Hieronder volgen de stappen die nodig zijn om zero-ETL-integratie in te stellen. Raadpleeg de volgende documentatiekoppelingen voor volledige handleidingen om aan de slag te gaan Aurora en Amazone roodverschuiving.
- Configureer de Aurora MySQL-bron met een aangepaste DB-clusterparametergroep.
- Configureer de Amazon Redshift Serverless-bestemming met het vereiste bronbeleid voor de naamruimte.
- Werk de Redshift Serverless-werkgroep bij om hoofdlettergevoelige identifiers in te schakelen.
- Configureer de vereiste machtigingen.
- Maak de nul-ETL-integratie.
- Maak een database van de integratie in Amazon Redshift.
Configureer de Aurora MySQL-bron met een aangepaste DB-clusterparametergroep
Voer de volgende stappen uit om een Aurora MySQL-database te maken:
- Maak op de Amazon RDS-console een DB-clusterparametergroep met de naam
zero-etl-custom-pg.
Zero-ETL-integraties vereisen specifieke waarden voor de Aurora DB-clusterparameters die binaire logboekregistratie (binlog) regelen. De verbeterde binlog-modus moet bijvoorbeeld zijn ingeschakeld (aurora_enhanced_binlog=1).
- Stel de volgende binlog-clusterparameterinstellingen in:
binlog_backup=0binlog_replication_globaldb=0binlog_format=RIJaurora_enhanced_binlog=1binlog_row_metadata= VOLbinlog_row_image= VOL
- Kies Wijzigingen opslaan.

- Kies databases in het navigatievenster en kies vervolgens Maak een database.

- Voor Beschikbare versies, kiezen Aurora MySQL3.03.1 (of hoger).

- Voor Sjablonenselecteer Productie.
- Voor DB-cluster-ID, ga naar binnen
zero-etl-source-ams.
- Onder Instantie configuratieselecteer Geheugen geoptimaliseerde klassen en kies een geschikte instantiegrootte (standaard is
db.r6g.2xlarge).
- Onder Aanvullende configuratievoor DB-clusterparametergroep, kies de parametergroep die u eerder hebt gemaakt (
zero-etl-custom-pg).
- Kies Maak een database.
Binnen een paar minuten zou het een Aurora MySQL-database moeten opstarten als de bron voor zero-ETL-integratie.

Configureer de Redshift Serverless-bestemming
Maak voor onze use case een Redshift Serverless datawarehouse door de volgende stappen uit te voeren:
- Kies op de Amazon Redshift-console Serverloos dashboard in het navigatievenster.
- Kies Maak een preview-werkgroep.

- Voor Werkgroep naam, ga naar binnen
zero-etl-target-rs-wg.
- Voor namespaceselecteer Een nieuwe naamruimte maken en ga naar binnen
zero-etl-target-rs-ns.
- Navigeer naar de naamruimte
zero-etl-target-rs-nsEn kies de Middelenbeleid Tab. - Kies Gemachtigde opdrachtgevers toevoegen.
- Voer de Amazon Resource Name (ARN) van de AWS-gebruiker of -rol in, of de AWS-account-ID (IAM-principals) die integraties in deze naamruimte mogen maken.
Een account-ID wordt opgeslagen als een ARN met rootgebruiker.

- Voeg een geautoriseerde integratiebron toe aan de naamruimte en geef de ARN op van het Aurora MySQL DB-cluster dat de gegevensbron is voor de zero-ETL-integratie.
- Kies Wijzigingen opslaan.

U kunt de ARN voor de Aurora MySQL-bron krijgen op de Configuratie tabblad zoals weergegeven in de volgende schermafbeelding.

Werk de Redshift Serverless-werkgroep bij om hoofdlettergevoelige identifiers in te schakelen
Gebruik de AWS-opdrachtregelinterface (AWS CLI) om het update-werkgroep actie:
Je kunt gebruiken AWS-cloudshell of een andere interface zoals Amazon Elastic Compute-cloud (Amazon EC2) met een AWS-gebruikersconfiguratie die de parametergroep Redshift Serverless kan bijwerken. De volgende schermafbeelding illustreert hoe u dit op CloudShell kunt uitvoeren.

De volgende schermafbeelding laat zien hoe u het update-workgroup commando op Amazon EC2.

Configureer vereiste machtigingen
Om een zero-ETL-integratie te creëren, moet uw gebruiker of rol een gekoppeld op identiteit gebaseerd beleid met de juiste AWS Identiteits- en toegangsbeheer (IAM) machtigingen. Met het volgende voorbeeldbeleid kan de gekoppelde principal de volgende acties uitvoeren:
- Maak zero-ETL-integraties voor het Aurora DB-broncluster.
- Bekijk en verwijder alle zero-ETL-integraties.
- Creëer inkomende integraties in het beoogde datawarehouse. Deze toestemming is niet vereist als hetzelfde account eigenaar is van het Amazon Redshift-datawarehouse en dit account een geautoriseerde opdrachtgever is voor dat datawarehouse. Merk ook op dat Amazon Redshift een ander ARN-formaat heeft voor ingericht en serverloos:
- Ingericht cluster -
arn:aws:redshift:{region}:{account-id}:namespace:namespace-uuid - Serverless -
arn:aws:redshift-serverless:{region}:{account-id}:namespace/namespace-uuid
- Ingericht cluster -
Voer de volgende stappen uit om de machtigingen te configureren:
- Kies op de IAM-console Policies in het navigatievenster.
- Kies Maak beleid.
- Maak een nieuw beleid met de naam
rds-integrationsmet behulp van de volgende JSON:
Beleidsvoorbeeld:

Als u IAM-beleidswaarschuwingen ziet voor de RDS-beleidsacties, wordt dit verwacht omdat de functie in openbare preview is. Deze acties worden onderdeel van IAM-beleid wanneer de functie algemeen beschikbaar is. Het is veilig om verder te gaan.
- Koppel het beleid dat u hebt gemaakt aan uw IAM-gebruikers- of rolmachtigingen.
Maak de nul-ETL-integratie
Voer de volgende stappen uit om de zero-ETL-integratie te maken:
- Kies op de Amazon RDS-console Zero-ETL-integraties in het navigatievenster.
- Kies Creëer zero-ETL-integratie.

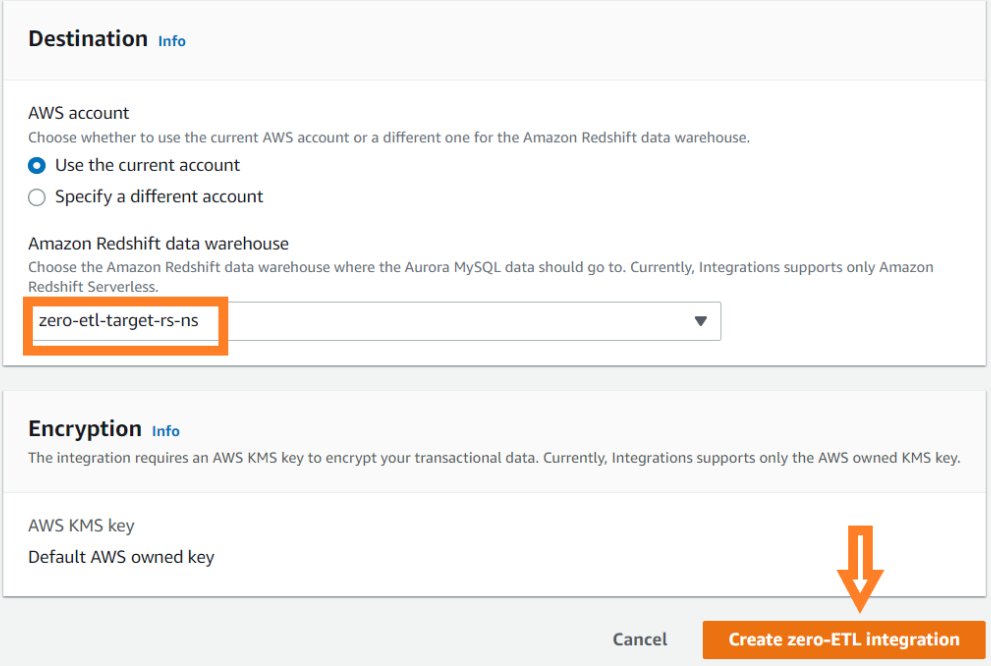
- Voor Integratie naam, voer bijvoorbeeld een naam in
zero-etl-demo. - Voor Aurora MySQL-broncluster, blader en kies het broncluster
zero-etl-source-ams.
- Onder Bestemmingvoor Amazon Redshift-datawarehouse, kies de Redshift Serverless bestemmingsnaamruimte (
zero-etl-target-rs-ns). - Kies Creëer zero-ETL-integratie.
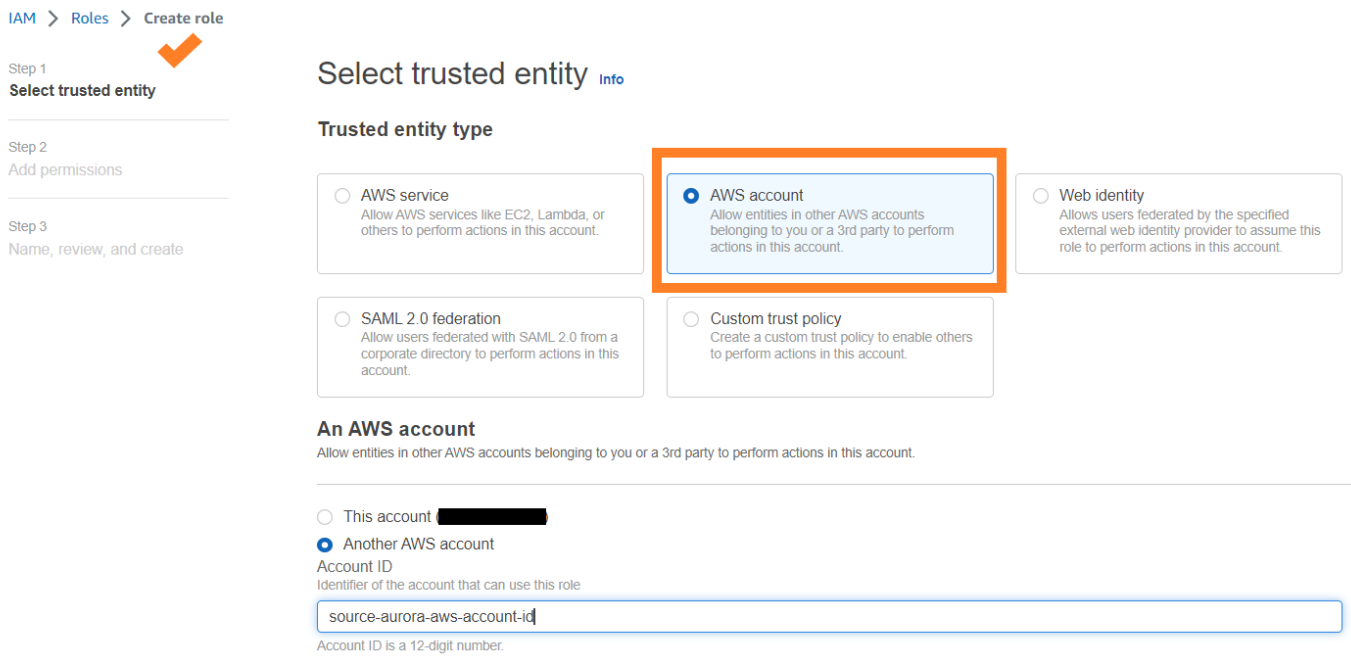
Om een Amazon Redshift-doeldatawarehouse op te geven dat zich in een ander AWS-account bevindt, moet u een rol maken waarmee gebruikers in het huidige account toegang hebben tot bronnen in het doelaccount. Voor meer informatie, zie Toegang verlenen aan een IAM-gebruiker in een ander AWS-account waarvan u de eigenaar bent.
Maak een rol aan in het doelaccount met de volgende machtigingen:
De rol moet het volgende vertrouwensbeleid hebben, dat de doelaccount-ID specificeert. U kunt dit doen door een rol te maken met een vertrouwde entiteit als een AWS-account-ID in een ander account.
De volgende schermafbeelding illustreert het maken hiervan op de IAM-console.
Kies vervolgens tijdens het maken van de zero-ETL-integratie de bestemmingsaccount-ID en de naam van de rol die u hebt gemaakt om verder te gaan, bijvoorbeeld Geef een ander account op optie.
U kunt de integratie kiezen om de details te bekijken en de voortgang te volgen. Het duurt een paar minuten om de status te wijzigen van Wij creëren naar Actief. De tijd varieert afhankelijk van de grootte van de dataset die al beschikbaar is in de bron.

Maak een database van de integratie in Amazon Redshift
Voer de volgende stappen uit om uw database aan te maken:
- Navigeer op het Redshift Serverless-dashboard naar de
zero-etl-target-rs-ns namespace. - Kies Gegevens opvragen om Query-editor v2.

- Maak verbinding met het voorbeeld Redshift Serverless datawarehouse door te kiezen Verbinding maken.

- Verkrijg het
integration_idvan hetsvv_integrationsysteem tafel: - Gebruik de
integration_idvan de vorige stap om een nieuwe database te maken vanuit de integratie:

De integratie is nu voltooid en een volledige momentopname van de bron zal worden weergegeven zoals in de bestemming. Lopende wijzigingen worden bijna in realtime gesynchroniseerd.
Analyseer de bijna realtime transactiegegevens
Nu kunnen we analyses uitvoeren op de operationele gegevens van TICKIT.
Vul de bron-TICKIT-gegevens in
Voer de volgende stappen uit om de brongegevens in te vullen:
- Maak verbinding met uw Aurora MySQL-cluster en maak een database/schema voor het TICKIT-gegevensmodel, controleer of de tabellen in dat schema een primaire sleutel hebben en start het laadproces:

U kunt het volgende script gebruiken HTML-bestand om de voorbeelddatabase te maken demodb (de ... gebruiken tikit.db model) in Amazon Aurora MySQL-compatibele editie.
- Voer het script uit om het tikit.db modeltafels in de
demodbdatabase/schema:
- Gegevens laden van Amazon eenvoudige opslagservice (Amazon S3), noteer de eindtijd voor validaties van change data capture (CDC) op de bestemming en observeer hoe actief de integratie was.

De volgende zijn veel voorkomende fouten geassocieerd met belasting van Amazon S3:
- Voor de huidige versie van het Aurora MySQL-cluster moeten we de
aws_default_s3_roleparameter in de parametergroep DB-cluster naar de rol ARN die de benodigde toegangsrechten voor Amazon S3 heeft.
- Als u een foutmelding krijgt voor ontbrekende inloggegevens (bijvoorbeeld
Error 63985 (HY000): S3 API returned error: Missing Credentials: Cannot instantiate S3 Client), hebt u uw IAM-rol waarschijnlijk niet aan het cluster gekoppeld. Voeg in dit geval de beoogde IAM-rol toe aan het Aurora MySQL-broncluster.
Analyseer de bron TICKIT-gegevens in de bestemming
Open Query Editor v2 op het Redshift Serverless-dashboard met behulp van de database die u hebt gemaakt als onderdeel van de integratie-instellingen. Gebruik de volgende code om de seed- of CDC-activiteit te valideren:

Kies het cluster of de werkgroep en de database die is gemaakt op basis van integratie in het vervolgkeuzemenu en voer uit tickit.db voorbeelden van analytische query's.

Monitoren
U kunt de volgende systeemweergaven en tabellen in Amazon Redshift opvragen om informatie te krijgen over uw Aurora zero-ETL-integraties met Amazon Redshift:
Om de integratiegerelateerde statistieken te bekijken die zijn gepubliceerd naar Amazon CloudWatch, navigeert u naar de Amazon Redshift-console. Kies Zero-ETL-integraties in het linkernavigatievenster en klik op de integratielinks om activiteitsstatistieken weer te geven.

Beschikbare statistieken op de Redshift-console zijn integratiestatistieken en tabelstatistieken, waarbij tabelstatistieken details geven van elke tabel die is gerepliceerd van Aurora MySQL naar Amazon Redshift.

Integratiestatistieken bevatten het aantal geslaagde/mislukte tabelreplicaties en vertragingsdetails:
Opruimen
Wanneer u een zero-ETL-integratie verwijdert, verwijdert Aurora deze uit uw Aurora-cluster. Uw transactiegegevens worden niet verwijderd uit Aurora of Amazon Redshift, maar Aurora stuurt geen nieuwe gegevens naar Amazon Redshift.
Voer de volgende stappen uit om een nul-ETL-integratie te verwijderen:
- Kies op de Amazon RDS-console Zero-ETL-integraties in het navigatievenster.
- Selecteer de zero-ETL-integratie die u wilt verwijderen en kies Verwijder.
- Kies om de verwijdering te bevestigen Verwijder.

Conclusie
In dit bericht hebben we je laten zien hoe je Aurora zero-ETL-integratie instelt van Amazon Aurora MySQL-Compatible Edition naar Amazon Redshift. Dit minimaliseert de noodzaak om complexe datapijplijnen te onderhouden en maakt near-real-time analyses van transactionele en operationele data mogelijk.
Ga voor meer informatie over Aurora zero-ETL-integratie met Amazon Redshift naar documentatie voor Aurora en Amazon roodverschuiving.
Over de auteurs
 Rohit Vashishtha is een Senior Analytics Specialist Solutions Architect bij AWS in Dallas, Texas. Hij heeft 17 jaar ervaring met het ontwerpen, bouwen, leiden en onderhouden van big data-platforms. Rohit helpt klanten hun analytische werklast te moderniseren met behulp van de brede AWS-services en zorgt ervoor dat klanten de beste prijs/prestatieverhouding krijgen met de grootst mogelijke beveiliging en gegevensbeheer.
Rohit Vashishtha is een Senior Analytics Specialist Solutions Architect bij AWS in Dallas, Texas. Hij heeft 17 jaar ervaring met het ontwerpen, bouwen, leiden en onderhouden van big data-platforms. Rohit helpt klanten hun analytische werklast te moderniseren met behulp van de brede AWS-services en zorgt ervoor dat klanten de beste prijs/prestatieverhouding krijgen met de grootst mogelijke beveiliging en gegevensbeheer.
 Vijay Karumajji is een Database Solutions Architect bij Amazon Web Services. Hij werkt samen met AWS-klanten om begeleiding en technische assistentie te bieden bij databaseprojecten, zodat ze de waarde van hun oplossingen bij het gebruik van AWS kunnen verbeteren.
Vijay Karumajji is een Database Solutions Architect bij Amazon Web Services. Hij werkt samen met AWS-klanten om begeleiding en technische assistentie te bieden bij databaseprojecten, zodat ze de waarde van hun oplossingen bij het gebruik van AWS kunnen verbeteren.
 BP ja is Sr Partner Solutions Architect bij AWS. Hij is gepassioneerd in het helpen van klanten bij het ontwerpen van big data-oplossingen om gegevens op grote schaal te verwerken. Voordat hij bij AWS kwam, hielp hij Amazon.com Supply Chain Optimization Technologies bij het migreren van het Oracle-datawarehouse naar Amazon Redshift en het bouwen van het volgende generatie big data-analyseplatform met behulp van AWS-technologieën.
BP ja is Sr Partner Solutions Architect bij AWS. Hij is gepassioneerd in het helpen van klanten bij het ontwerpen van big data-oplossingen om gegevens op grote schaal te verwerken. Voordat hij bij AWS kwam, hielp hij Amazon.com Supply Chain Optimization Technologies bij het migreren van het Oracle-datawarehouse naar Amazon Redshift en het bouwen van het volgende generatie big data-analyseplatform met behulp van AWS-technologieën.
 Jyoti Aggarwal is een productmanager van het Amazon Redshift-team in Seattle. Ze heeft de afgelopen 10 jaar aan meerdere producten in de datawarehouse-industrie gewerkt.
Jyoti Aggarwal is een productmanager van het Amazon Redshift-team in Seattle. Ze heeft de afgelopen 10 jaar aan meerdere producten in de datawarehouse-industrie gewerkt.
 Adam Levin is een productmanager van het Amazon Aurora-team in Californië. Hij heeft de afgelopen 10 jaar gewerkt aan verschillende clouddatabaseservices.
Adam Levin is een productmanager van het Amazon Aurora-team in Californië. Hij heeft de afgelopen 10 jaar gewerkt aan verschillende clouddatabaseservices.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/getting-started-guide-for-near-real-time-operational-analytics-using-amazon-aurora-zero-etl-integration-with-amazon-redshift/

