Afbeelding door auteur
De Data Engineering met GCP is een compleet spiekbriefje voor de levenscyclus van data voor ervaren personen die de essentiële concepten van het data engineering-ecosysteem en de tools willen doornemen.

Afbeelding van Cheatsheet
In deze spiekbrief leer je:
- Basisconcepten van Data Engineering
- Hadoop-ecosysteem
- Google rekenplatform
- Identiteitstoegangsbeheer
- Sleutelbegrippen
- Bereken keuzes
- Stapelstuurprogramma
- Opslag, Big table, BigQuery en Cloud SQL
- DataStore, DataProc en DataFlow
- Pub / Sub
Cheatsheet van PySpark bevat handige opdrachten voor het omgaan met DataFrames in Python met voorbeelden. De cheat behandelt de basiswerking van Apache Spark DataFrames, van het initialiseren van de SparkSession tot het uitvoeren van query's en het opslaan van de gegevens.

Afbeelding van Cheatsheet
In deze spiekbrief leer je:
- SparkSession wordt geïnitialiseerd
- Dataframes maken in Python
- Filtering
- Waarden dupliceren
- Spark-query's uitvoeren
- Query's programmatisch uitvoeren
- De kolommen aanpassen
- Omgaan met ontbrekende waarden
- Opnieuw partitioneren
- Groeperen op en sorteren
- De gegevens inspecteren, de uitvoer opslaan en de sessie stoppen.
De dbt-opdrachten (tool voor gegevensopbouw). spiekbriefje biedt eenvoudige voorbeelden van verschillende opdrachten die u kunt gebruiken om de gegevens te transformeren. dbt is een transformatietool, het laadt of extraheert niet.

Afbeelding van Cheatsheet
In deze spiekbrief leer je:
- Inleiding tot dbt
- dbt generieke commando's
- Wordt uitgevoerd op basis van de modelnaam
- Wordt uitgevoerd op basis van de mapnaam
- Wordt uitgevoerd op basis van de mapnaam
- Meerdere modelinvoeren in de dbt-opdracht
- Speciale opdrachten
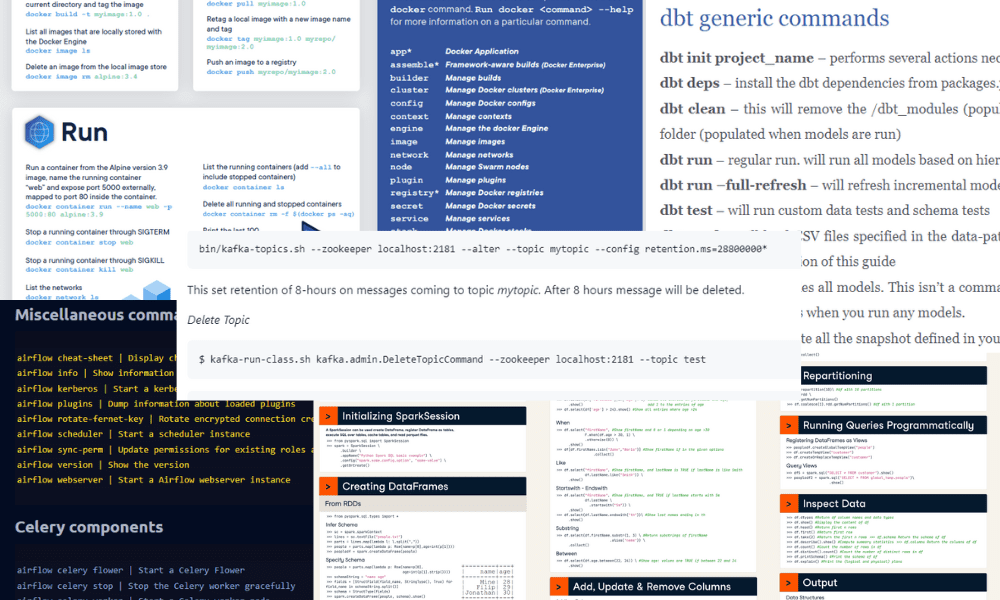
Apache Kafka is een op commando's gebaseerd spiekbriefje dat de essentiële commando's voor gedistribueerde datastreaming behandelt.
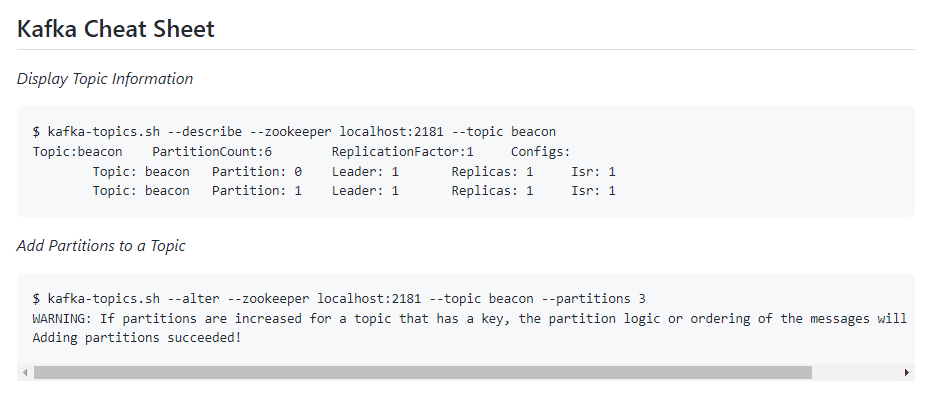
Afbeelding van Cheatsheet
In deze spiekbrief leer je:
- Onderwerpinformatie weergeven
- Wijzig onderwerpretentie
- Maak een lijst van bestaande onderwerpen
- Een onderwerp opschonen
- Een onderwerp verwijderen
- Vroegste offset nog steeds in een onderwerp
- Laatste offset nog steeds in een onderwerp
- Berichten consumeren
- Verkrijg de consumentencompensaties voor een onderwerp
- Kafka consumentengroepen
- Kafkakat
- Dierentuinmedewerker
De Google BigQuery is een op opdrachten gebaseerd spiekbriefje waarin elke BigQuery-functie in detail wordt uitgelegd. BigQuery is een volledig beheerd datawarehouse met geavanceerde functies zoals geospatiale analyse, BI-tooling en machine learning.

Afbeelding van Cheatsheet
In deze spiekbrief leer je:
- BigQuery-resources initialiseren met DDL
- Schema's veranderen
- Tabellen veranderen
- Veranderende weergaven
- Gematerialiseerde weergaven wijzigen
- BigQuery-gegevenstypen
- Numerieke typen
- BigQuery-gegevens toevoegen en bewerken
- Veelvoorkomende vragen
De Luchtstroom is een op opdrachten gebaseerd spiekbriefje met essentiële opdrachten voor het maken, plannen en bewaken van workflows. Apache Airflow is een veelgebruikte datapijplijntool in de branche. Het biedt schaalbaarheid, uitbreidbaarheid en dynamische pijplijngeneratie.
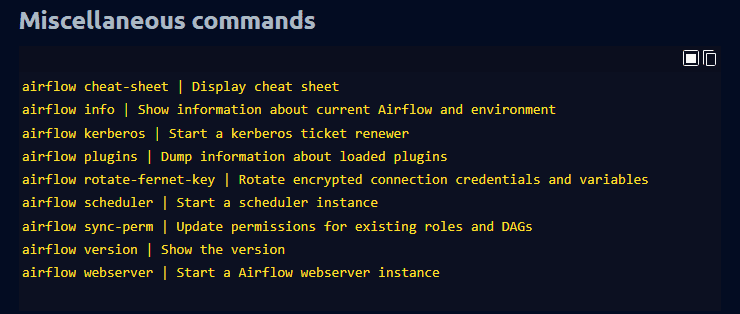
Afbeelding van Cheatsheet
In deze spiekbrief leer je:
- Diverse commando's
- Selderij componenten
- Configuratie bekijken
- Beheer verbindingen
- DAG's beheren
- Database operaties
- Tools om de KubernetesExecutor te helpen uitvoeren
- Beheer zwembaden
- Aanbieders weergeven
- Beheer rollen, taken, gebruikers en variabelen
De Docker spiekbriefje behandelt de basisfunctionaliteit van het bouwen, uitvoeren en beheren van Docker-images. Docker biedt virtualisatie op besturingssysteemniveau om software te leveren in pakketten die containers worden genoemd. Het wordt gebruikt voor reproduceerbaarheid en beheer van beschikbare bronnen.
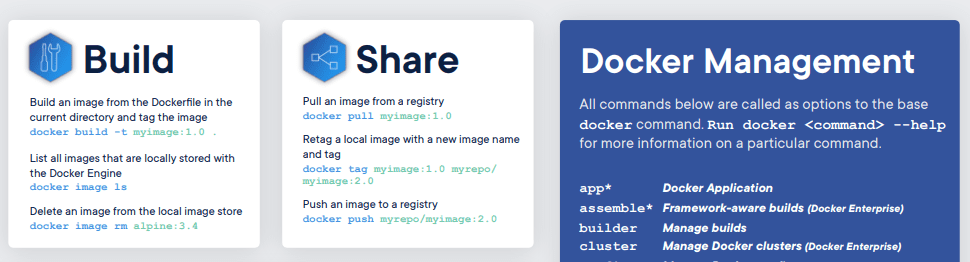
Afbeelding van Cheatsheet
In deze spiekbrief leer je:
- Bouw de docker-image
- De docker-afbeelding delen
- Het runnen van de container
- Beheer van build, configuraties, afbeeldingen en services
Dagelijks voert data-engineering data-opname, datawarehousing, analytische engineering, workflowbeheer, batchverwerking en streaming uit. Om alle taken uit te voeren, hebt u de kennis van de tools en de commando's nodig. De 7 spiekbriefjes helpen je verschillende tools, commando's en concepten te herzien. Bovendien zal het u helpen om met minimale inspanning de technische interviewfase van data-engineering te doorstaan.
Ik hoop dat je de spiekbriefjes leuk vindt. Vergeet me niet te volgen Twitter en LinkedIn, waar ik boeiende blogs over datawetenschap post.
Abid Ali Awan (@1abidaliawan) is een gecertificeerde datawetenschapper-professional die dol is op het bouwen van machine learning-modellen. Momenteel richt hij zich op het creëren van content en het schrijven van technische blogs over machine learning en data science-technologieën. Abid heeft een Master in Technologie Management en een Bachelor in Telecommunicatie Engineering. Zijn visie is om een AI-product te bouwen met behulp van een grafisch neuraal netwerk voor studenten die worstelen met een psychische aandoening.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.kdnuggets.com/2022/12/7-essential-cheat-sheets-data-engineering.html?utm_source=rss&utm_medium=rss&utm_campaign=7-essential-cheat-sheets-for-data-engineering

